

P15.神经网路的基本骨架——nn.Module的使用
打开PyTorch官网
1.找到troch.nn的Containers


2.打开pycharm:代码-生成-重写方法-选择第一个要初始化的方法__init__



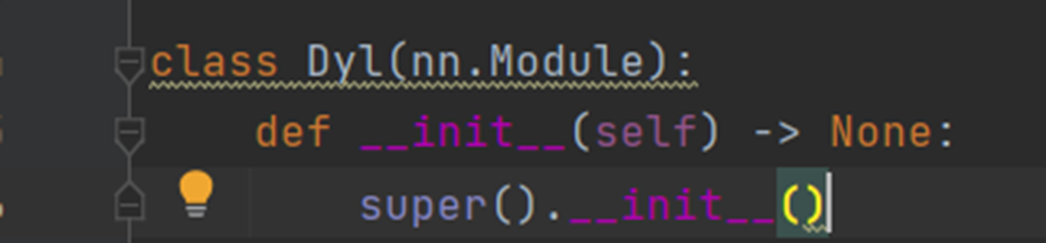
3.pycharm运行代码如下
点击查看代码
import torch
from torch import nn
#1.定义神经网络的模板
class Dyl(nn.Module): #定义一个名为Dyl的神经网络类,继承自nn.Module
#-> None:类型注解,表示该方法不返回值; super().__init__():调用父类nn.Module的初始化方法
def __init__(self) -> None:
super().__init__()
def forward(self,input):
output = input + 1
return output
#2.创建神经网络
dyl = Dyl() #创建Dyl类的一个实例(对象),dyl现在是一个可用的神经网络
x = torch.tensor(1.0) #x作为输入
output = dyl(x) #将x放在神经网络里面即dyl(x)作为输出
print(output)
4.输出结果
点击查看代码
D:\anaconda3\envs\pytorch\python.exe D:/DeepLearning/Learn_torch/P15_nnModule.py
tensor(2.)
进程已结束,退出代码0
5.debug一下:在“dyl = Dyl()”处设置断点
(1)【deepseek总结】完整的执行流程总结:
- 创建Dyl实例 → 自动调用__init__ → 调用父类初始化
- 创建输入张量 x = 1.0
- 调用dyl(x) → 触发__call__方法 → 调用forward方法
- 在forward中执行计算:1.0 + 1 = 2.0
- 返回计算结果
- 打印输出结果
(2)第一步:super().init()
原因:当创建 Dyl 类的实例时,Python会自动调用 init 方法
具体内容:
super() 获取父类 nn.Module 的引用
.init() 调用父类的构造函数
作用:初始化神经网络的基础设施,包括参数管理、钩子函数、设备设置等
必要性:所有继承 nn.Module 的类都必须调用父类构造函数

(3)第二步:x = torch.tensor(1.0)
原因:需要为神经网络创建输入数据
具体内容:
torch.tensor(1.0) 创建一个值为1.0的PyTorch张量
数据类型:自动推断为 torch.float32
作用:作为神经网络的输入,模拟实际应用中的数据
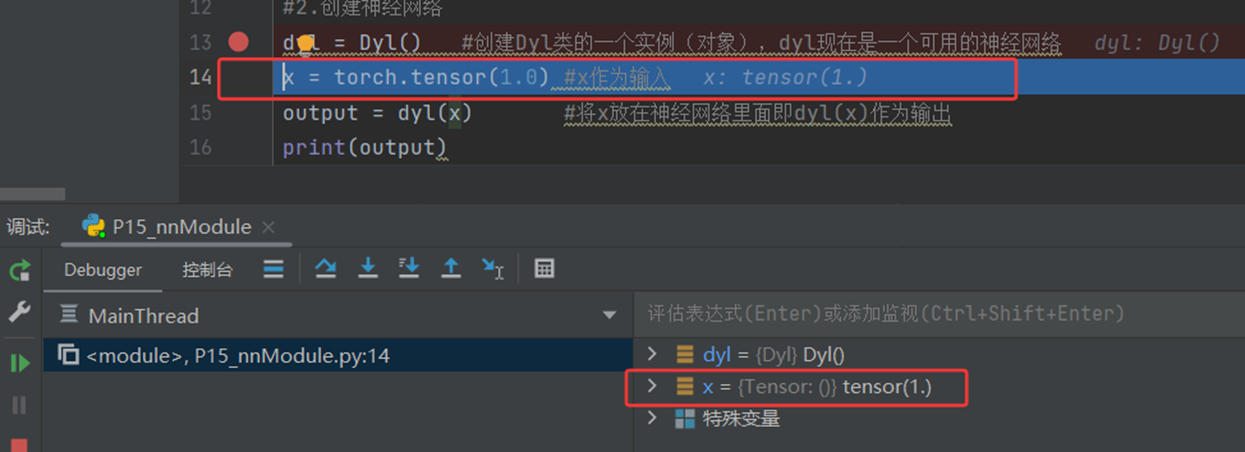
(4)第三步:output = dyl(x)
原因:调用神经网络进行前向传播计算
具体内容:
dyl(x) 实际上调用的是 dyl.call(x)
PyTorch的 nn.Module 重写了 call 方法
内部过程:
设置网络为适当模式(训练/评估)
调用钩子函数(如果有)
最终调用 forward 方法


(5)第四步:output = input + 1(在forward方法内)
原因:执行神经网络的实际计算逻辑
具体内容:
input 是从上一步传入的 x(值为1.0的张量)
input + 1 执行张量加法运算
计算过程:1.0 + 1 = 2.0
注意:这里使用的是PyTorch张量运算,不是普通的Python加法
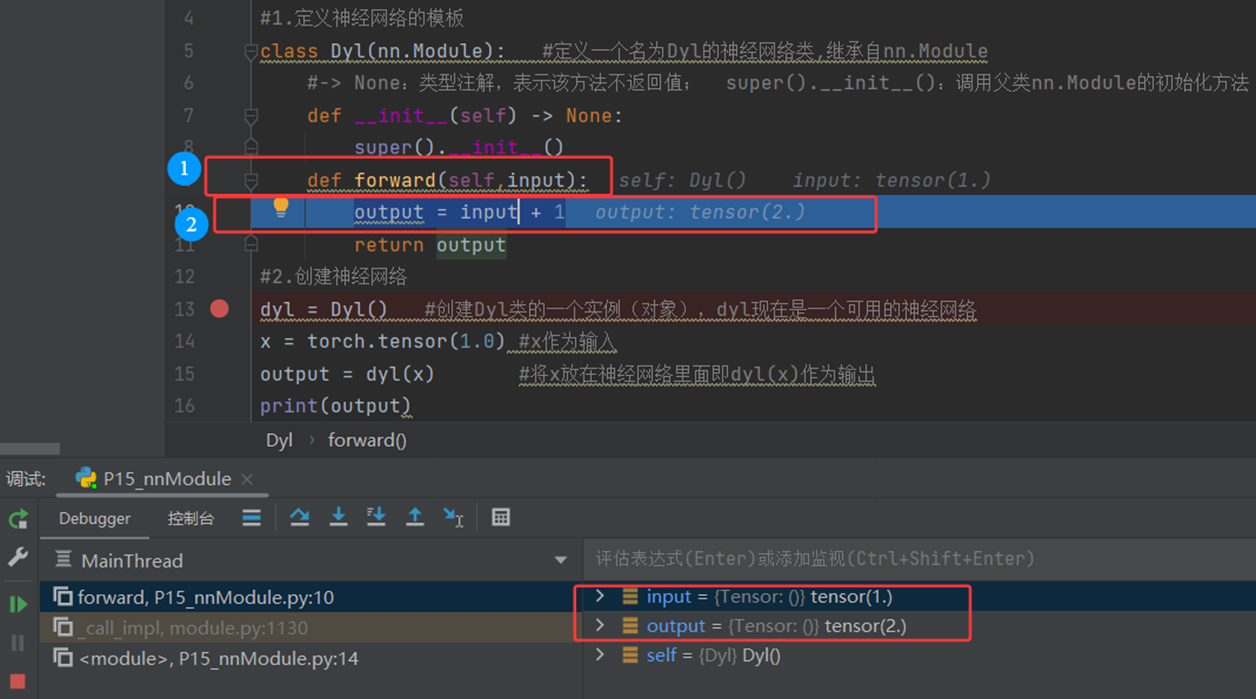
(6)第五步:return output
原因:将计算结果返回给调用者
具体内容:
返回值为 2.0 的PyTorch张量
这个返回值被赋值给变量 output
(7)第六步:print(output)
原因:显示神经网络的输出结果
具体内容:
打印 output 变量,即 tensor(2.)
显示格式:PyTorch为了简洁,将 2.0 显示为 2.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号