Unicode 和JS中的字符串
计算机内部使用二进制存储数据,只认识0和1两个数字,计算机的世界只有0和1。但我们的世界却充满着文字,如a, b, c。怎样才能让计算机显示文字,供我们使用和交流?只能先把文字转化成数字进行存储,然后再把数字转化成文字进行显示,但一个文字怎么转化成数字,转化成哪个数字,或者用哪一个数字代表哪一个文字呢?
如果在我的计算机上,1 表示A,2 表示B,3 表示C, 依次类推。我写HELLO,实际存储到计算机中的是数字8, 5, 12, 12, 15,我发HELLO给你,实际就是把这些数字(8, 5, 12, 12, 15)通过网络发送给你。但在你的计算机上,0表示A,1表示B,当你的计算机接受到(8, 5, 12, 12, 15)并解析时,8表示的却是I, 最终你收到的是IFMMP,意思完全变了,不同的计算机之间没有办法进行沟通。为了有效沟通,我们需要制定一个标准来规定哪一个数字代表哪一个文字,对文字进行编码,并且所有计算机都要遵守这个标准。
19世纪60年代, 美国标准委员会制定了ASCII码,使用7个bit(7-bit)来编码一个文字. 7个bit(从0000000 to 1111111)能够表示128个值(0-127),所以ASCII码有足够的空间来表示大写字母,小写字母,数字等。在1968年,美国所有的计算机都使用ASCII码。当我再发送HELLO 给你,HELLO编码成了72, 69,76,76, 79 ,在计算机内部使用二进制表示就是1001000,10000101,1001100,1001100,1001111。这些数字到达你的计算机,由于也是使用ASCII 码进行解析,所以能够正常显示为HELLO,我们能用计算机地进行有效沟通了。
19世纪70年代,计算机普及到了欧洲,欧洲各国也想使用计算机表示自己的文字,比如希腊人想表示欧米茄ω. 俄罗斯人想表示Я,这些都是ASCII 码中没有的。这时计算机硬件也得到了发展,CPU能一次处理8个bit,计算机的最小存储单位也变成了8bit(一个字节)。8个bit能表示256个值(0-255), 而ASCII码最多使用到127, 还剩下128-255 是没有用到。他们就想用这些没有用到的数字来表示各自的文字。最开始的时候,IBM就用128-255 这些数字表示一些有符号的字字母和希腊字母,比如224表示希腊字母α。然而不像ASCII码,128-255能表示什么字符从来没有被标准化。欧洲各国开始,自己造自己的数字与字母的对应关系(字符集),于是出现了个各种各样的字符集。比如俄罗斯人用244表示俄语 Я, 然而希腊人却用它来用表示小写的欧米茄,ω. 计算机之间的交流又陷入了混乱。
19世纪90年代末,做了一次标准化的尝试和努力,创造出了15种不同的的字符集,它们都使用8个bit表示一个字符,叫做ISO-8859-1, ISO-8859-2, 直到 ISO-8859-16,中间的ISO-8859-12被废弃了。俄罗斯人使用的是ISO-8859-5, 224 表示字符 p,207 代表Я。 如果俄罗斯朋友给你发送了一封邮件或一份文档,最好知道他使用的是哪一种字符集。我们接受的邮件或文档是序例化的数字,数字224代表可能代表a, p 或 Я。如果我们使用了错误的字符编码打开文档,看到就是乱码。
信息可以在不同的计算机上交流,但是你要确定使用的是哪一个字符编码。但随着计算机的进一步普及,它来到了亚洲,中日韩有大量的文字,8个bit, 256个值根本放不下,于是中国创造了GBK, 使用两个字节进行表示。国际化的到来,国与国之间沟通更为频繁,使得这种知道编码的交流方式愈发麻烦。
Unicode诞生了。它的想法很简单,就是给世界上每一个国家的每一个文字都分配一个独一无二的数字,这个数字称之为码点(code point), 前127个码点和ASCII一样,128-255基本上和ISO-8859-1一致,256之后就是其它有符号的字符,880 之后是希腊字母,中国,日本和韩国字符从11904开始。这样就不会产生混乱了,不管是哪个国家,哪种字符,都有一个唯一数字进行对应。俄罗斯的Я 永远都是1071.希腊字母阿尔法α永远都给是945。不过官方的unicode码点是用16进制进行表示,前面加上U+(表示unicode), H的unicode码点通常写成U+0048,而不是10进制的72。字符串Hello, 在unicode中对应5个码点:U+0048 U+0065 U+006C U+006C U+006F,但他们仅仅是数字,并没有说怎么存储到计算机中。Unicode只是提供了一个设想,并没有提供具体的实现,Unicode 最大的问题是它包含了太多的字符,大大超出了256,8个bits已经放不下了。
最初(19世纪90年代)的时候,由于各国的文字都比较少,只有7,161 个,而在计算机中,两个字节(16个bit)可以表示6万多个值,足够表示7千多个数字了, 所以决定使用两个字节来存储一个码点,这就是UCS-2编码, Hello变成了00 48 00 65 00 6C 00 6C 00 6F。但有一个比较尴尬的事情是,由于一个字符占用两个字节,对欧美人来说,有点浪费存储空间,他们也不愿意转换成unicode。有很长一段时间,他们忽略了unocide.
但是随着时间的推移,尤其是亚洲国家把大量的象形文字也加入到Unicode 编码中,65536的数量也放不下这些文字,于是Unicode 编码字符集也相应的进行了扩充,它把整个字符集分成了17个平面,每一个平面都能放2^16 个文字, 每一个平面的码点从U+n0000 到U+nFFFF结束。n是用0x0 到0x10, 16进制表示
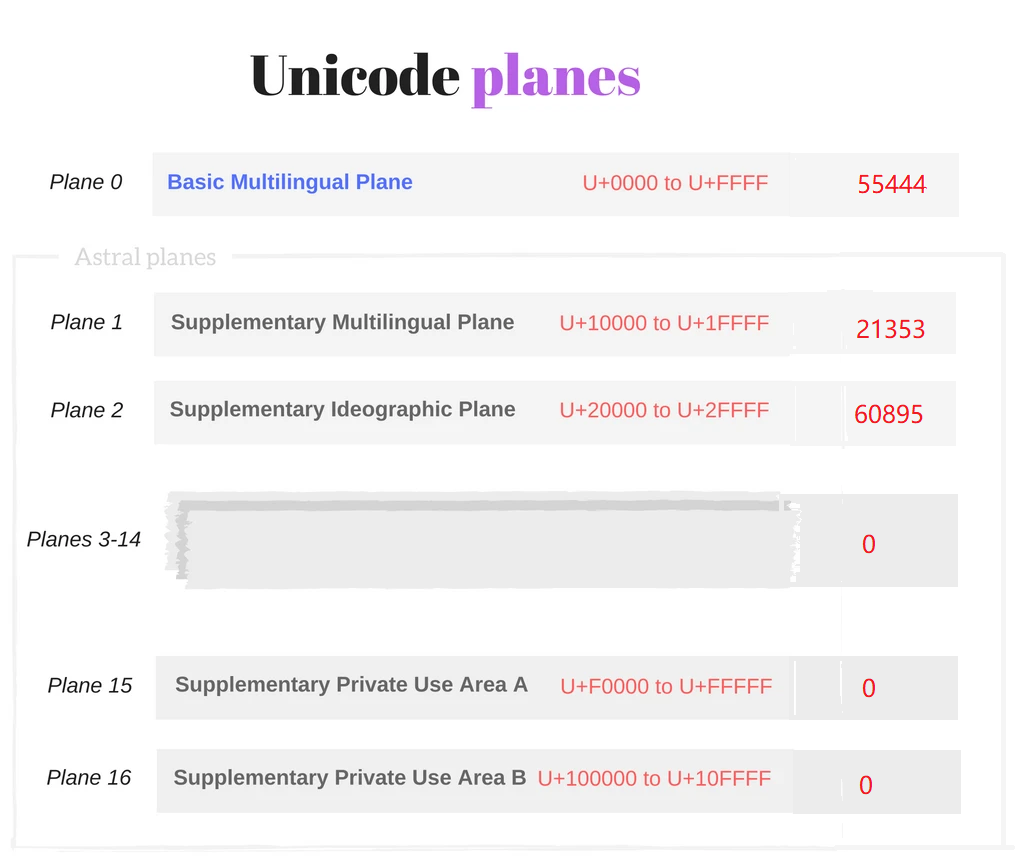
第一个平面Plane 0放置的就是最初的UCS-2编码中所定义的文字(最常用的文字),叫做基本多语言平面Basic Multilingual Plane (or BMP),基本多语言平面码点的取值范围是0x0000 - 0xFFFF, 其他的16个平面称为补充平面(Supplementary Planes or Astral Planes), 它们的取值范围从0x10000 开始 (0xFFFF + 1 就等于0x10000, 16进制的计算)。针对这种多平面的字符集,UCS-2编码方式肯定是不合适了。最简单的方式,使用更多的字节来存储一个文字。此时计算机也得到了发展,CPU都是32bit 或64-bit, 一次能处理32个字节或64个字节。那为什么不能用更多的bit来表示一个字符? 当然可以,UTF-16, UTF-32 出现了,取代了UCS-2
UTF-16 就是对于在BMP 平面的文字用两个字节(16个bit)进行存储,然后对于其他平面的文字用四个字节进行存储。
UTF-32 则是用32个bit, 4个字节来存储一个字符,所有的字符都占用4个字节。
使用UTF-16或UTF-32有什么问题呢?文件转输。如果你写的都是英文字符,使用一个字节进行存储就可以了,但如果使用UTF-16,那就要占两个字节,UTF-32 就要使用4个字节,浪费带宽。最终UTF-8 出现,才解决这个问题。UTF-8 使用的是变长字节。码点从0-127 使用一个字节进行存储,只有码点大于128,才会用2个,3个,最大到6个字节进行存储。使用ASCII码写的文档,也是有效的UTF-8文档。 Hello的码点是 U+0048 U+0065 U+006C U+006C U+006F, 存储码计算机中 48 65 6C 6C 6F, 和 ASCII 一样。
前端开发,使用的是UTF-8和UTF-16。无论写什么,html, css, 或是js, 首先要做的就是把文档格式改为UTF-8, vs code 右下角的select Encoding

HTML 文档的meta 标签也要设置成UTF-8,
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf-8">
为什么呢?就是因为UTF-8可以减少文件大小,浏览网页,实际上是向服务器请求html, js 等静态资源文件,文件越小,传输越快。当浏览器得到这些资源文件时,要对其进行解析,文件是用UTF-8 写的,也要用UTF-8 进行解析,否则出现乱码。那怎么告诉浏览器用UTF-8 进行解析?charset 设定字符编码。浏览器解析html文档时,先按操作系统默认字符编码进行解析,如果它碰到<meta http-equiv="Content-Type" content="text/html; charset=utf-8">,它会停止解析,按charset 设置的utf-8 重新进行解析,这也要求设置charset的meta标签尽可能早的出现在<head> 标签中。
这时,可能会有疑问,书写JS代码使用UTF-8, 但JavaScript 内部使用的是UTF-16,这怎么理解?JS引擎在内部做了一次UTF-8到UTF-16的转换。当浏览器解析完js代码,js引擎执行js代码的时候,如果它碰到字符串,它就会把它转成换UTF-16. JavaScript 的源代码文件也可以是任意格式,但源代码中的字符串一定是UTF-16. While a javascript source file can have any kind of encoding, JavaScript will then covert it internally to UTF-16 before executing it. JavaScript strings are all UTF-16 sequences, as the ECMAScript standard says:
When a String contains actual textual data, each element is considered to be a single UTF-16 code unit
JavaScript使用UTF-16, 重点说一下UTF-16。UTF-16,以16-bit为基础进行存储,如果16-bit 存储不了,再增加一个16-bit 进行存储,以16-bit为单位进行递增。对于unicode 字符集来说,BMP 平面中的文字用一个16-bit进行存储,因为BMP平面最多存放65536个字符,16个bit完全可以搞定,其他平面的文字就要用(2个16-bit)进行存储。16-bit 也称为码元(code unit)。一个16bit 就是一个码元, 两个16-bit 就是两个码元。码点是unicode字符集中的术语,仅仅是一个普通的数字,没有涉及到任何计算机的存储,码元则是指字符在计算机中所占的物理存储空间,占了多大内存。UTF-16 等编码,就是规定字符或码点是怎么存储到计算机中的,一个字符,到底占用多少个bit,多大的内存空间,把码点转化成码元。
其他平面中的文字怎么用两个码元(16-bit)来显示呢? 先看一下目前Unicode 非基本面的有多少个字, 一共16个面, 一个面是2^16 个字,那也就是说,一共有16 * 2^16 个字, 就是2^20个字符, 也就需要20个二进制bit 位,一个码元只能16bit 位,那只能把20bit 位进行拆分成2个部分,一个部分占10个bit, 这样一个码元就可以表示了。但这又存在另外一个问题,当计算机去读取字符的时候,它碰到一个字节就去读取一个字节,它并不知道,你这个字节是拆分出来的,你会发现,本来一个字,确显示出了毫不相干的两个字,这怎么办呢?在BMP平面,它所定义的Unicode 字符(55444个)并没有完全使用了2个字节,有一部分是空的,并没有对应任何字符,这一段是0xD800 到 0xDFFF(55296 - 57343), 这也就意味着,使用这一段上的码元没有任何问题。那我们就想办法,让非基本面的码点对应到这一段上来。对应的逻辑是这样的,首先把0xD800 - 0xDFFF 分为两个部分,0xD800 到 0xDBFF 和0xDC00 到 0xDFFF,然后再用码点减去65536, 把剩下的数用二进制表示,如果二进制不够20位,可以在前面补0. 再把20位二进制分为两个部分,每个部分占用10个bit, 前10个bit 对应到0xD800 - 0xDFFF, 称为高位(H), 后10个bit 对应到0xDC00 到 0xDFFF 称为低位(L), 这样一个码点就可以用两个码元(高位, 低位)进行表示了。映射比较复杂,不过Unicode 提供了一个公式,可以直接通过码点得到高低位码元。
H = Math.floor((c-0x10000) / 0x400)+0xD800 // c 是码点 0x10000 就是65536 0x400 就是1024, 0xD800 就是H 开始位置 L = (c - 0x10000) % 0x400 + 0xDC00 // 0xDC00 L 位开始的位置。
举一个小例子,汉字"𠮷"的码点为134071, 大于65535, 它要用4个字节(2个码元)进行表示。把码点134071代入到上面的c 中, 由于浏览器的控制台可以直接计算16进制,我们把134071 转化成16进制 0x20BB7

得到十进制55362, 转化成16进制为0xD842, 此为高位

十进制57271,转化成16进制为0xDFB7, 此为低位。
汉字"𠮷"的 UTF-16 编码为0xD842 0xDFB7 ,称之为surrogate pairs(代理对),一对16bit 码元来表示一个码点。当使用这种方式用两个码元去表示一个码点时,计算机也不会出错,因为当它读取到第一个码元的时候,发现并没有对应的字符,它会就继续向下取第二个码元,两个码元连起来,就是对应的码点,就可以显示一个字了。
JavaScript 使用UTF-16, 这也就意味着,Js中的所有字符串都按UTF-16进行编码,在内存中就是一个个16bit的码元有序排列组合,对字符串的所有操作就是对码元的所有操作。比如length, 它就是计算字符串占了多个码元。
console.log('a'.length); // 1
console.log('𠮷'.length); // 2
由于是码元的组合,我们在字符串中可以直接写码元\uxxxx, \u表示unicode, xxxx 是四位16进制数,这也叫unicode 转义序列。
const s1 = '\u00E9'; // é
const s2 = '\u0065\u0301' //é如果这么写字符串就会带来一个问题,同样是é,但有两种不同的写法,s1是使用一个码元,s2使用了两个,它们会被认为两个不同的字符串,如果比较相等,它们两个肯定不相等。这种有语调符号的文字在西欧国家常见,e上面符号称为组合符号,它不能单独使用,它只对它前面的字符起作用。如果非要比较相等,就要进行标准化,是按照拆分后的两个字符进行比较,还是按照合并后的一个字符进行比较。ES015提供了normalize() 方法来进行标准化, 它有四个参数
'NFC': Normalization Form Canonical Composition
'NFD': Normalization Form Canonical Decomposition
'NFKC': Normalization Form Compatibility Composition
'NFKD': Normalization Form Compatibility Decomposition
Unicode 定义了两个字符的相等规则:Canonical equivalence和 Compatibiltiy equivalence。 Canonical equivalence:对于同一个抽象字符,一个字符也能表示,
多个字符有序组合也能表示,如果多个字符有序组合显示到屏幕的时候和一个字符显示到屏幕的时候一模一样,就表示这一个字符和多个字符组合相等。

Compatibiltiy 就是显示的时候,不用一模一样,只要近似就表示相等

Composition: 合成, Decomposition 拆分。NFC就表示,按照Canonical equivalence对字符串进行合成。 那么多个字符组合就变成了一个字符。NFD 按照Canonical equivalence 对字符串地进行拆分,一个字符就会变成多个字符组合。NFKC 和NFKD 就是按照Compatibiltiy equivalence 进行合行和分解。对于é 可以调用normalize() , 下面都返回true
console.log(s1 === s2.normalize()); console.log(s1.normalize('NFD') === s2); console.log(s1 === s2.normalize('NFKC')); console.log(s1.normalize('NFKD') === s2);

 浙公网安备 33010602011771号
浙公网安备 33010602011771号