
昨天我们的词向量分解得出了如下的txt文件
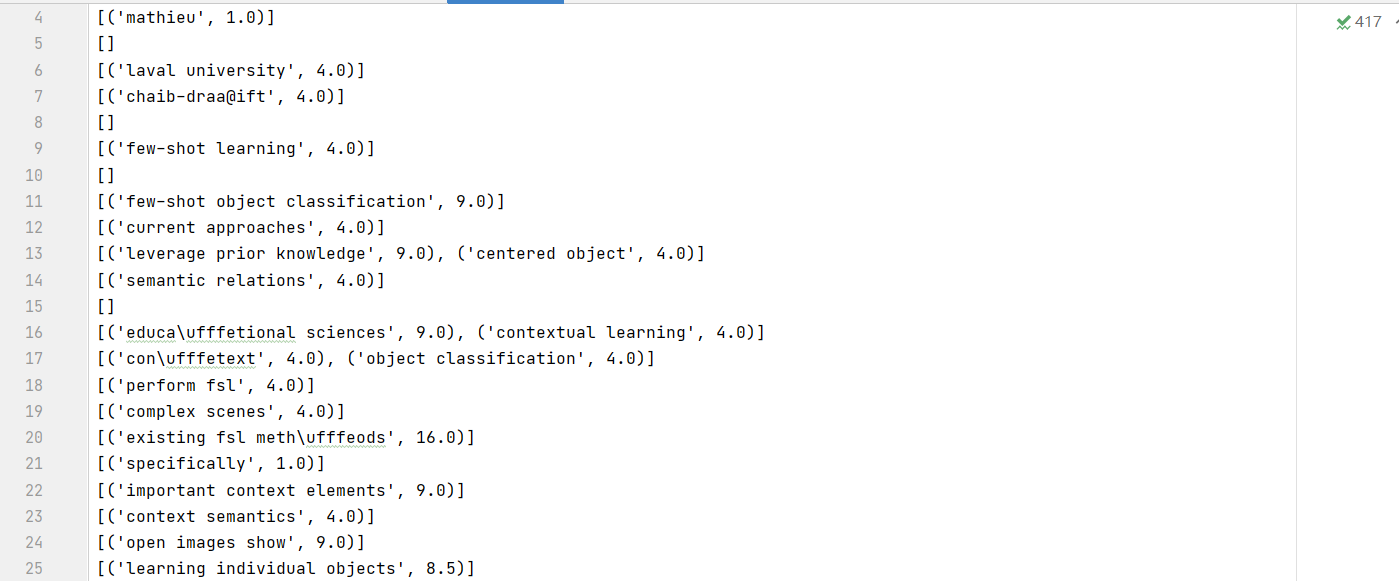
那么这种文件我们要如何将其写入数据库呢?我们可以先将其转化为json之后按照数组读取进数据库
def no_other(c): i=0 s='' for i in range(0,len(c)): if c[i]=='(': s=s+'{"name":' else: if c[i]==')': s=s+'},' else: if (c[i]==',')&(c[i-1]=='\''): s=s+',"value":' else: if c[i]=='\'': s=s+'"' else:s=s+c[i]; return s
这样就可以得出这种结果:
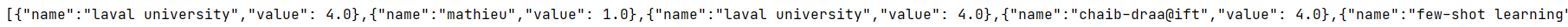
之后读取进数据库:
for p in range(0,len(res)): print(res[p]['name']) print(int(res[p]['value']*10)) data_p.append([res[p]['name'],str(int(res[p]['value']*10+(uniform(10,100))))]) sql = "insert into iccvfenci(vec,times) values (%s,%s)" try: cursor.executemany(sql, data_p) conn.commit() except: conn.rollback()
我们就得到了一个数据库啦

 浙公网安备 33010602011771号
浙公网安备 33010602011771号