

python-爬虫学习3:BeautifulSoup 库解析提取数据
第一篇讲到爬虫的四个步骤:获取数据 解析数据 提取数据 存储数据
第二篇有讲到利用requests 库去获取数据;
这篇主要是讲利用BeautifulSoup 库解析提取数据
一、解析数据和提取数据
- 解析数据
平常使用浏览器上网,浏览器会把服务器返回的HTML源代码翻译成我们看得懂的样子,然后我们才能在网页上继续操作,所以爬虫的时候,也要使用能读懂html 的工具,才能拿到想要的数据。这个过程就叫解析数据
- 提取数据
提取数据就是把需要的数据从一大堆的数据里挑出来我们想要的。这个过程叫做提取数据。
二、BeautifulSoup 库解析数据
1.BeautifulSoup 库安装
- winds: pip install BeautifulSoup4
- mac: pip3 install BeautifulSoup4
2.BeautifulSoup 用法
bs 对象 = BeautifulSoup(要解析的文本,‘解析器’)
!!!要注意的点:要解析的文本必须是字符串;解析器的话这里列举一个‘html.parser’,用这个是因为这个解析器相对简单一点,容易上手,还有其他解析器,后续会补充进来。
3.代码实操
实例链接:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
取这个网址的书籍类型,书名,链接和书籍介绍
import requests from bs4 import BeautifulSoup #导入bs4 库 res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html') print(res.status_code) #输出请求的响应状态码 html =res.text # 把res内容转化为字符串形式输出 soup = BeautifulSoup(res.text,'html.parser') #把网页解析为BeautifulSoup 对象 print(type(soup)) print(soup)
其中导入bs4 库和解析BeautifulSoup 对象这两行是新加的代码。
运行输出soup的数据类型<class 'bs4.BeautifulSoup'>,这个可以手敲代码然后运行在终端看一下,说明soup 是一个BeautifulSoup对象。
最后一行打印出来的soup 就是我们请求的网页的源代码。源代码里包含书名,链接,书籍内容等数据。
4.BeautifulSoup用法
from bs4 import BeautifulSoup
soup = BeautifulSoup(字符串,‘html.parser’)
解析数据整体就是这么个过程,接着看提取数据
三、提取数据
提取数据的话主要涉及到两大部分:find()与find_all(),以及Tag对象
- find() 和find_all()
- 都可以匹配html 的标签和属性,把BeautifulSoup 对象里符合要求的数据都提取数来
find(): 只提取首个满足要求的数据
find_all(): 提取所有满足要求的数据
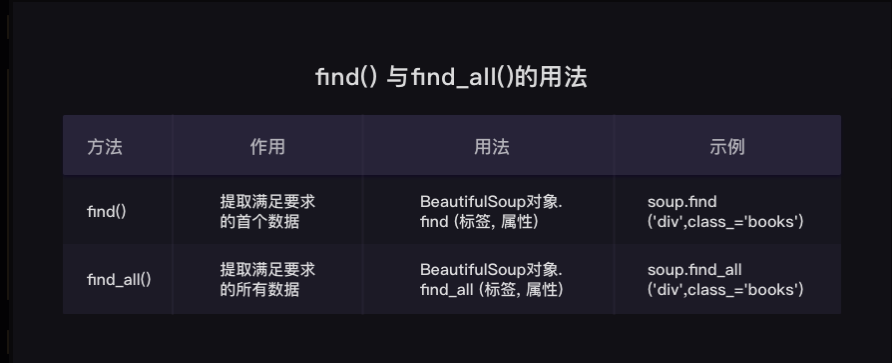
!!!注意:示例中的class_,是包含下划线的,为了和python 语法里类 class 区分开;除了可以用class 属性去匹配外,还可以用其他属性;标签和属性可以任选其一,也可以两个搭配一起使用。
实例:https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html
find() 练习:
import requests from bs4 import BeautifulSoup url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html' res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') item = soup.find('div') #使用find()方法提取首个<div>元素 print(item) #打印item print(type(item)) #打印item 数据类型
终端输出:
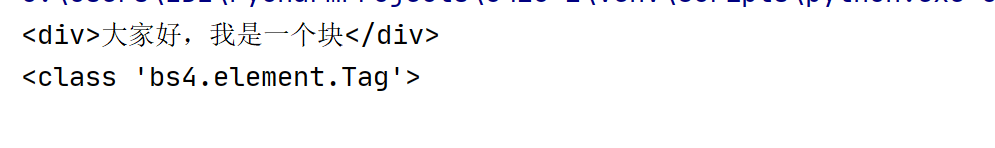
这里item 的数据类型<class 'bs4.element.Tag'>,说明这是一个Tag 类对象
find_all() 练习:
import requests from bs4 import BeautifulSoup url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spder-men0.0.html' res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') item = soup.find_all('div') #使用find_all()方法提取所有<div>元素 print(item) #打印item print(type(item)) #打印item 数据类型
终端运行:

item 的数据类型显示为<class 'bs4.element.ResultSet'>,是一个ResultSet 类的对象。其中Tag 对象以列表的结构储存起来,可以当做列表使用
四、代码实操
url:https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html
目标:爬取网页中的三本书的书名,链接,书籍介绍。
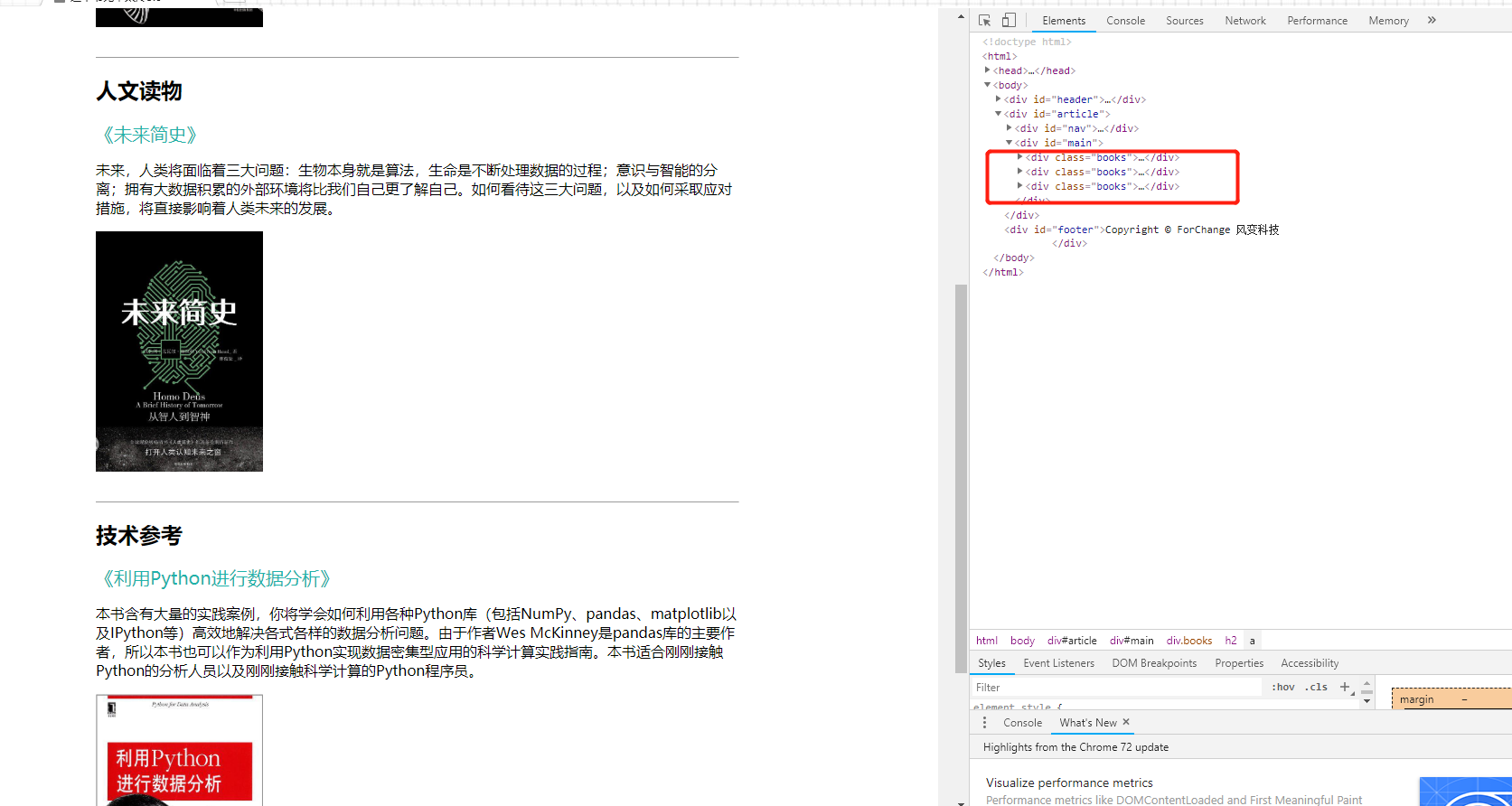
首先,右键单击打开开发者选项(F12),然后观察代码结构,三本书分别在三个class = 'books'里,这里要提取三本书的全部信息的话,首选find_all()
import requests from bs4 import BeautifulSoup url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html' res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') item = soup.find_all('div',class_ = 'books') #使用find_all()方法提取所有<div>元素 print(item) #打印item
这里提取出来的是个列表格式的数据,包含了三本书的所有信息,为了提取单本书的信息,我们可以用for 循环进行遍历列表,进行数据提取
import requests from bs4 import BeautifulSoup url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html' res = requests.get(url) soup = BeautifulSoup(res.text,'html.parser') item = soup.find_all('div',class_ = 'books') #使用find_all()方法提取所有<div>元素 for i in item: print('所有要的数据:',i)
这时候打印出来的是一个个包含html 标签的数据。
要进一步进行数据提取操作,就需要用到Tag 对象。

对于刚刚遍历之后打印出来带有html 标签的数据(Tag 对象--可以通过print(type(i))查看输出的类型),取中间的一个Tag 对象
<div class="books"> <h2><a name="type3">技术参考</a></h2> <a class="title" href="https://book.douban.com/subject/25779298/">《利用Python进行数据分析》</a> <p class="info">本书含有大量的实践案例,你将学会如何利用各种Python库(包括NumPy、pandas、matplotlib以及IPython等)高效地解决各式各样的数据分析问题。由于作者Wes McKinney是pandas库的主要作者,所以本书也可以作为利用Python实现数据密集型应用的科学计算实践指南。本书适合刚刚接触Python的分析人员以及刚刚接触科学计算的Python程序员。</p> <img class="img" src="./spider-men5.0_files/s27275372.jpg"/> <br/> <br/> <hr size="1"/> </div>
书籍类型:<h2><a name="type3">技术参考</a></h2>
链接和书名:<a class="title" href="https://book.douban.com/subject/25779298/">《利用Python进行数据分析》</a>
简介:<p class="info">本书含有大量的实践案例,你将学会如何利用各种Python库(包括NumPy、pandas、matplotlib以及IPython等)高效地解决各式各样的数据分析问题。由于作者Wes McKinney是pandas库的主要作者,所以本书也可以作为利用Python实现数据密集型应用的科学计算实践指南。本书适合刚刚接触Python的分析人员以及刚刚接触科学计算的Python程序员。</p>
import requests
from bs4 import BeautifulSoup
url = 'https://localprod.pandateacher.com/python-manuscript/crawler-html/spider-men5.0.html'
res = requests.get(url)
soup = BeautifulSoup(res.text,'html.parser')
item = soup.find_all('div',class_ = 'books') #使用find_all()方法提取所有<div>元素
for i in item:
type = i.find('h2').text
book = i.find(class_ ='title').text #这里我直接用了tag.text 去提取文字
details = i.find(class_ = 'info').text #在列表中的每个元素里,匹配属性class_='info'提取出数据
print(book,'\n',type,'\n',details)
终端输出:
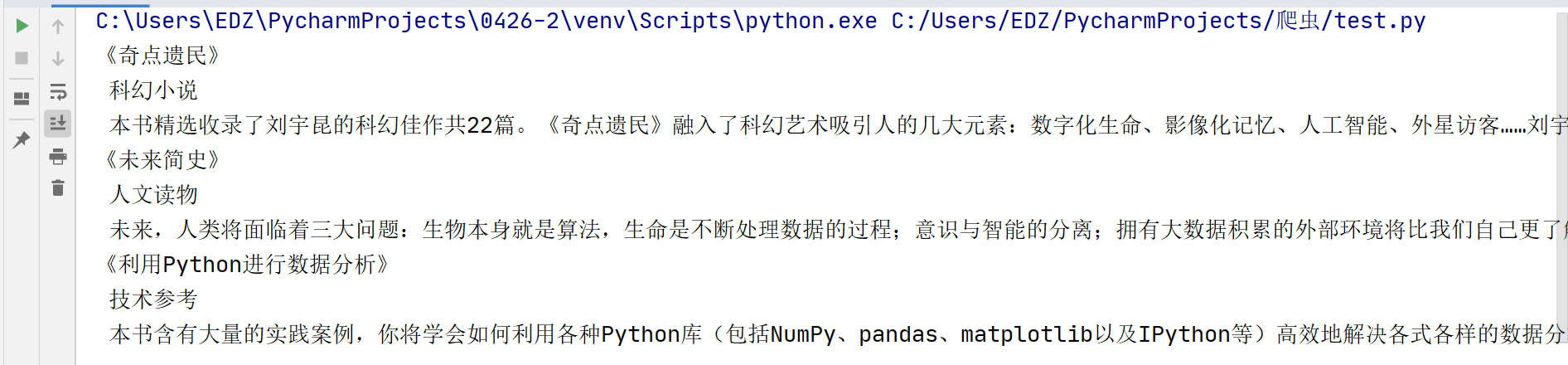
看一下 已经都是文本数据啦
整个解析数据提取数据的过程就结束了。
六、复习
爬虫的整个流程前面三大部分:requests 去获取数据;BeautifulSoup 进行数据解析;利用find/find_all进行数据提取操作。
- requests 对象:
- reponse = requests.get(url)
- 这里的get 要注意,因为用到的是get 请求,所以用的是get.之后可能还有post 请求,就要使用requests.post (url) 了
- bs 对象:
- bs对象 = BeautifulSoup(要解析的文本,‘解析器’)
- 这里选了‘html.paeser’
- find/find_all 对象:
- find
- 提取满足条件的单个数据---BeautifulSoup 对象.find(标签,属性)---soup.find('div',class_='books') 要注意class_ 的下划线
- find_all
- 提取满足条件的单个数据---BeautifulSoup 对象.find_all(标签,属性)---soup.find_all('div',class_='books') 要注意class_ 的下划线
- find
- Tag 对象:
- Tag.find() / Tag.find_all() 提取Tag 中的Tag
- Tag.text 提取Tag 中的文字
- Tag['属性名'] 输入参数:属性名,可以提取Tag 中的属性值
- Tag.find() / Tag.find_all() 提取Tag 中的Tag
之后还会用有利用excel 和csv 进行数据存储,获取cookie 等。不要急,慢慢来。
贴的知识点部分是要重点,需要理解和掌握的,
对于贴的代码,仅供参考,主要是明白逻辑和流程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号