

python -爬虫学习2:获取数据requests 库
上一篇介绍的主要是爬虫的工作原理,大致分为四个步骤:获取数据 解析数据 提取数据 存储数据 。这一篇主要就从获取数据介绍起。
获取数据
1.requests 库下载安装
MAC :电脑打开终端软件,输入pip3 install requests
winds:打开命令提示符(windows +r 快捷键,输入cmd),输入pip install requests
requests 库可以帮助下载网页源代码,文本,图片,音频~
下载就是说向服务器发送请求并得到回应
2.requests 方法介绍
reuqests.get()方法
import requests #引入requests 库 res = requests.get('URL') # requests.get 是在调用requests库中的get() 方法,然后向服务器发送请求,括号里的参数是你需要的数据的网址,服务会对请求作出响应,返回一个response对象, 然后存储到变量res里
重点看一下注释。
python 语法里有个方法type,不了解的童鞋请自行百度,通过type()方法可以得到数据类型
import requests
res = requests.get('URL')
print(type(res))
终端显示:requests.models.Response
这代表着:res 是一个对象,属于requests.models.Response类。
3.requests 对象的常用属性
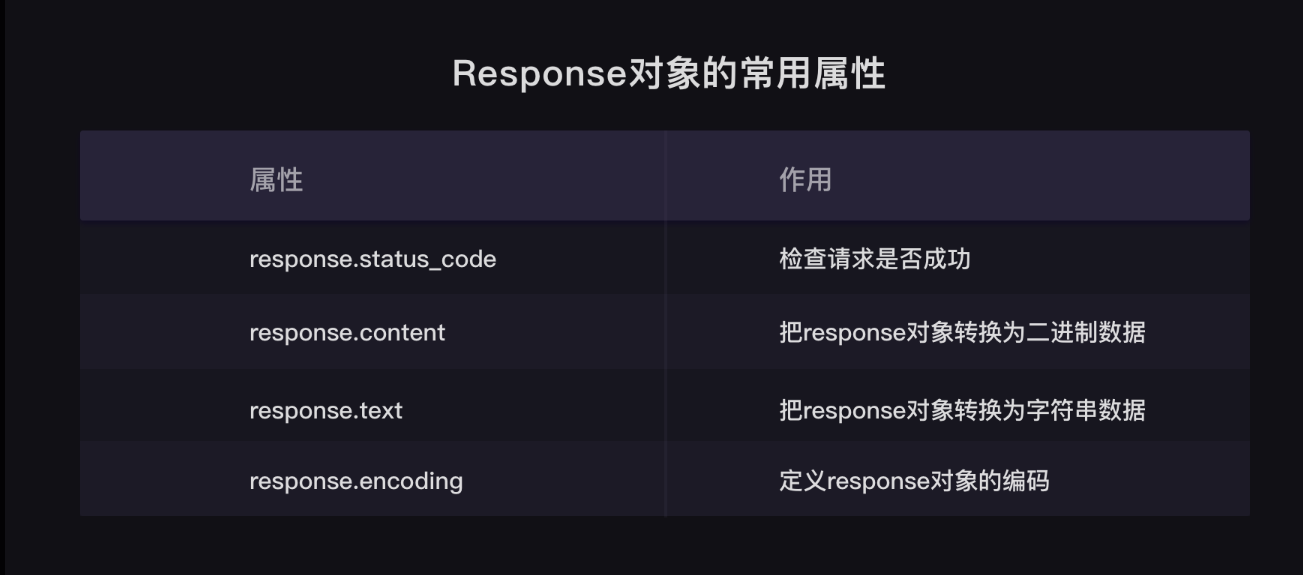
- response.status_code
拿百度(https://www.baidu.com/)为例
import requests res = requests.get('https://www.baidu.com/') print(res.status_code) #打印res 的响应状态码,检查请求是否成功
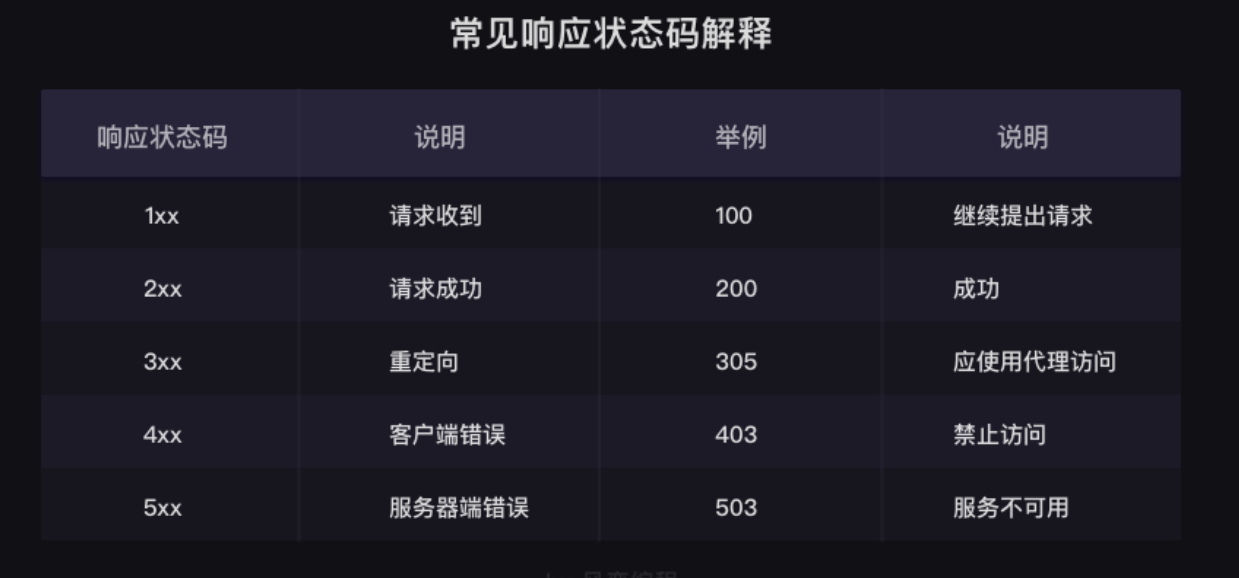
终端运行的结果显示:200
200 :代表服务器同意请求,然后返回了数据给我们
除了200之外,还有其他的状态码,具体可以参考下图:遇到时候可以查表,不一样要都记住,还想要再具体一点的状态码解释的童鞋请自行百度~
注意!!!res 是我随机定义的变量名,可以根据自己需要随便去定义,但是要符合变量的命名规则
response.status_code 的格式
print(变量.status_code) #检查请求是否正确响应,如果响应状态码是200,则请求成功
- response.content
response.content 是把reponse 对象的内容以二进制数据的形式返回,适用于图片,音频,视频的下载。(需要注意的是它的下载范围)
右键复制图片的url: https://www.baidu.com/img/sjdhdong_2f0815641b0fb86e10289d06a632f3f1.gif
import requests #引入requests 库 res = requests.get(' https://www.baidu.com/img/sjdhdong_2f0815641b0fb86e10289d06a632f3f1.gif') #发出请求,并且把返回的结果放在变量res里 pic = res.content # 把response 对象的内容以二进制数据格式的形式返回 p =open('ppt.gif','wb') #没加路径,会在当前程序运行的目录下新建一个ppt.gif 的文件, 图片内容需要以二进制wb读写。需要修改存放位置的话就是在ppt.gif 名字前加上路径,D:\sougo\ppt.gif 那就会在相应的目录下生成这个文件 p.write(pic) #把pic 写入到p 文件里 p.close() #关闭文件,释放资源
终端输出:

- response.text
把response 对象的内容以字符串的形式返回,适用于文字,网页源代码的下载
举例:下载小说《三国演义》的第一章 文章url:https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md
import requests res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md') novel =res.text #把response 对象的内容以字符串的形式返回 print(novel[:800])#打印小说前800字,涉及到列表的用法,陌生的话参考一下python 列表部分的知识
打印全部内容然后存储在文件里
import requests res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md') novel =res.text t =open('《三国演义》.txt','a+',encoding='utf-8') #创建一个《三国演义》的txt 文档,然后在文件末追加内容,我这里新加了encoding='utf-8',是因为打印出来内容是乱码,所以规定了编码方式为utf-8 t.write(novel) #把获取到的文件写入t 文件夹里 t.close()
同提取图片的链接类似,会在同级目录下生成一个《三国演义》的txt 文件,如果需要更改存储位置就增加路径。
- response.encoding
在打印三国演义的例子里已经用到了,实际还有另一种写法
import requests res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md') res.encoding = 'gbk' novel =res.text print(novel[:800])
但是输出结果是一串乱码,原因是我定义的编码方式是gbk,大多数网页的编码方式都是utf-8,但是我定义成gbk 之后,它就不会按照utf-8来编码。所以如果出现乱码格式的话,优先检查一下编码格式。
所以上述的代码如果要正常显示文字格式的话,就是res.encoding='utf-8'
import requests res = requests.get('https://localprod.pandateacher.com/python-manuscript/crawler-html/sanguo.md') res.encoding = 'utf-8' novel =res.text print(novel[:800])
到这里,requests 获取数据的过程就结束了。
爬虫伦理Robots 协议
通常情况下,服务器不太会在意小爬虫,但是,服务器会拒绝频率很高的大型爬虫和恶意爬虫,因为这会给服务器带来极大的压力或伤害。
不过,服务器在通常情况下,对搜索引擎是欢迎的态度。当然,这是有条件的,而这些条件会写在Robots协议。
Robots协议是互联网爬虫的一项公认的道德规范,它的全称是“网络爬虫排除标准”(Robots exclusion protocol),这个协议用来告诉爬虫,哪些页面是可以抓取的,哪些不可以。
如何查看网页的robots 协议?
就是在网址域名后加上 /robots.txt
这里有截取百度和谷歌对淘宝网爬虫的robots 协议
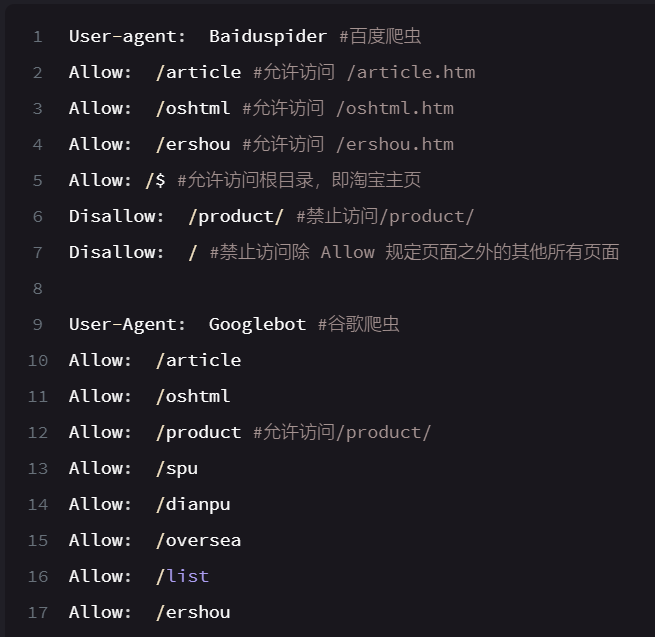
实际操作方法: 这个是百度界面的robots 协议
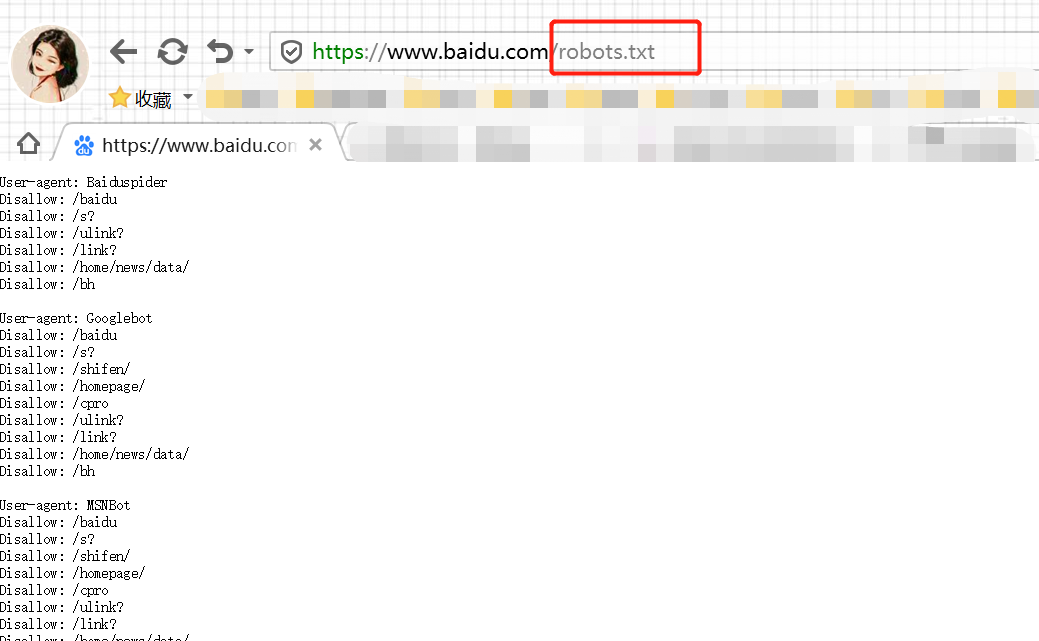
最后就是,童鞋们爬数据的时候要遵守robots 协议鸭~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号