2025 软件设计师复习笔记(已通过)
0x01 计算机组成原理与体系结构
(1)数据的表示
进制转换
- R 进制转换十进制采用按权展开法
- 二进制:\((110.01)_2 = 1\times 2^2 +1\times 2^1 +0\times 2^0 + 0\times 2^{-1} + 1\times 2^{-2} = (6.25)_{10}\)
- 十进制转换 R 进制采用短除法
- 二进制:十进制数每次除以 2 的余数的倒序排列
- 二进制转八进制:从右开始,每 3 位转换为十进制
- 二进制转十六进制:从右开始,每 4 位转换为十进制
- 反之同理
码
- 原码:一个数字的二进制表达方式,并且首位表示符号(正 0 负 1),通常使用 8 位,即一个字节
- 反码:正数反码与原码一致,负数反码除符号位外全部取反
- 补码:正数补码与原码一致,负数补码是其反码加 1
- 移码(用于作为浮点运算的阶码):补码基础上,符号位取反
| 1 | -1 | 1+(-1) | |
|---|---|---|---|
| 原码 | 0000 0001 | 1000 0001 | 1000 0010 |
| 反码 | 0000 0001 | 1111 1110 | 1111 1111 |
| 补码 | 0000 0001 | 1111 1111 | 0000 0000 |
| 移码 | 1000 0001 | 0111 1111 | 1000 0000 |
- 表示范围:(\(n\) 表示位数)
- 原码:\(-(2^{n-1}-1)\ 到\ 2^{n-1}-1\)
- 反码:\(-(2^{n-1}-1)\ 到\ 2^{n-1}-1\)
- 补码:\(-2^{n-1}\ 到\ 2^{n-1}-1\)
浮点运算
- 浮点数 \(N = M\times R^e\),如:\(1234 = 1.234\times 10^3\)
- M:尾数,1.234
- e:指数,3
- R:基数,10
- 运算顺序:对阶 → 尾数计算 → 结果格式化,以 \(1234 + 111\) 为例
- 对阶:统一浮点数的指数(阶码),一般将小的指数转换为大的指数,即 \(1.11\times 10^2\) 转换为 \(0.111\times 10^3\)
- 尾数计算:即 \((1.234+0.111)\times 10^3 = 1.345\times 10^3\)
- 结果格式化:使小数点前有且仅有一位非 0 的数字
(2)计算机结构
- 计算机由主机与外设构成,主机由 CPU 与主储存器构成,CPU 由运算器和控制器构成
- 运算器包括:
- 算术逻辑单元 ALU:算术运算与逻辑运算
- 累加寄存器 AC:暂存中间结果
- 数据缓冲寄存器 DR:暂存读写存储器的数据
- 状态条件寄存器 PSW:保存运算结果状态信息,如:进位、零、奇偶等
- 控制器包括:
- 程序计数器 PC:存放当前要执行指令的地址
- 指令寄存器 IR:暂存当前正在执行的指令
- 指令译码器:将 IR 中的指令代码翻译为控制信号
- 时序部件:产生 CPU 操作的时间控制信号
(3)Flynn 分类法
- 一种计算机体系结构分类
| 体系结构类型 | 结构 (控制部分、处理器、主存模块) |
关键特性 | 代表 |
|---|---|---|---|
| 单指令流单数据流 SISD |
1 1 1 | 单处理器系统 | |
| 单指多数 SIMD |
1 多 多 | 各处理器异步执行同一指令 | 并行处理机 阵列处理机 超级向量处理机 |
| 多指单数 MISD |
多 1 多 | 无法实现 | 流水线计算机 |
| 多指多数 MIMD |
多 多 多 | 各级全面并行 | 多处理机系统 多计算机 |
(4)CISC 与 RISC
| 指令系统类型 | 指令 | 寻址 | 实现 | 其他 |
|---|---|---|---|---|
| CISC (复杂指令集) |
数量多 使用频率差别大 可变长格式(指令的二进制编码长度可变) |
多 | 微程序控制技术 (微码) |
研制周期长 |
| RISC (精简指令集) |
数量少 使用频率接近 定长格式 大部分为单周期指令 操作寄存器,只有 Load/Store 操作内存 |
少 | 增加了通用寄存器 硬布线逻辑控制为主 适合采用流水线 |
优化编译 支持高级语言 |
- CISC 用于早期、特定用途的计算机
- RISC 用于现代、通用的计算机
- 排除了 CISC 一些复杂、不常用的指令
- 通过引入寄存器来提高效率,大部分操作通过寄存器完成
(5)流水线技术
- 流水线:在程序执行时,多条指令重叠进行操作的 一种准并行处理实现技术
| 周期 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|
| 取指 | 指令1 | 指令2 | 指令3 | ||
| 分析 | 指令1 | 指令2 | 指令3 | ||
| 执行 | 指令1 | 指令2 | 指令3 |
- 流水线周期:各部分中时间最长的一段
- 流水线执行时间:
- 理论:\(各部分时长之和+(指令条数-1)\times流水线周期\)
- 实践:\((各部分数+指令条数-1)\times流水线周期\)
- 流水线吞吐率:单位时间内,流水线完成任务的数量/输出结果的数量
- 吞吐率:\(TP=\frac {指令条数}{流水线执行时间}\)
- 最大吞吐率:\(TP_\max=\lim\limits_{n \to \infty}\frac n{(k+n-1)\Delta t}=\frac 1{\Delta t}\)(流水线周期倒数)
- 流水线加速比:\(S=\frac {不使用流水线执行时间}{使用流水线执行时间}\)
- 流水线效率:流水线设备利用率
- \(E=\frac {n 个任务占用的时空区}{k 个流水段的总时空区}=\frac {指令条数\times各部分时长之和}{各部分数\times流水线执行时间}=\frac {T_0}{kT_k}\)
例:指令流水线分为三部分,用时分别为:取指 2 ns,分析 3ns,执行 1 ns
- 流水线的周期为:\(max(2,3,1)=3\) ns
- 100 条指令总时长理论为:\((2+3+1)+(100-1)\times3=303\) ns
- 100 条指令总时长实践为:\([(1+1+1)+100-1]\times3=306\) ns
- 100 条指令吞吐率为:\(\frac {100}{303}\)
- 100 条指令最大吞吐率为:\(\frac 13\)
- 100 条指令加速比为:\(\frac {600}{303}\)
- 100 条指令时流水线效率为:\(\frac {100\times(2+3+1)}{3\times306}\)
(6)存储系统
- 层次化存储(速度由快到慢,容量由小到大):
- CPU,即寄存器
- Cache(缓存),按内容存取
- 内存(主存)
- 外存(辅存),如:硬盘、光盘、U 盘等
- 以读操作为例,使用“Cache + 主存储器”的系统平均周期:\(t_3=h\times t_1+(1-h)\times t_2\),其中:
- \(h\) 表示 Cache 的访问命中率
- \((1-h)\) 表示失效率
- \(t_1\) 表示 Cache 的周期时间
- \(t_2\) 表示主存周期时间
- \(h\) 表示 Cache 的访问命中率
局部性
- 局部性原理:在程序执行过程中,访问内存的地址往往呈现出局部聚集的特性
- 程序倾向于在短时间内重复访问某些特定的内存区域
- 工作集:进程运行时被频繁访问的页面集合
- 时空局部性
- 时间局部性:如果程序访问了一个内存单元,那么近期,它很可能会再次访问这个内存单元
- 近期访问同一单元
- 空间局部性:如果程序访问了一个内存单元,那么近期,它很可能会访问与该内存单元相邻的内存单元
- 近期方位邻近单元
- 时间局部性:如果程序访问了一个内存单元,那么近期,它很可能会再次访问这个内存单元
主存
- 分类
- 随机存储器 RAM
- DRAM:动态
- SRAM:静态
- 只读存储器 ROM
- MROM:掩模式
- PROM:一次可编程
- EPROM:可擦除
- Flash Memory:闪存
- 随机存储器 RAM
- 编址
- \(8\times4\) 位存储器:8 个地址(000 到 111),每个地址存储 4 bit 数据
例:
内存地址从 AC000H 到 C7FFFH,共有多少 K 个地址单元 \(\frac {(C7FFFH + 1)-AC000H}{2^{10}}=\frac {C8000H-AC000H}{2^{10}}=\frac {1C000H}{2^{10}}=\frac {7\times2^{14}}{2^{10}}=7\times16=112\)
该内存地址按 16bit 编址,由 28 片存储器芯片构成,每片有 16K 个存储单元,则该芯片每个存储单元存储多少位
- 设需要 \(x\) 位
- 则有 \(1=\frac {112K\times16bit}{28\times16K\times x}\)
- 解得 \(x=4bit\)
- 即 4 位
磁盘
- 磁盘工作原理:磁头在磁盘片的磁道上存取数据,每个磁盘片有一个磁道和多个扇区
- \(磁盘存取时间=寻道时间+等待时间\)
- 寻道时间:磁头移动到磁道的时间
- 等待时间:目标扇区转到磁头下的时间
- 磁盘开始工作后会一直旋转,如果缓冲区中的内容没有处理完成,则无法从磁盘读取数据,此时磁盘会继续旋转,直至缓冲区为空且磁头旋转至目标扇区
例:某磁盘的每个磁道划分为 11 个物理块(扇区),每块存放 1 个逻辑记录,逻辑记录 \(R_0,R_1,\cdots,R_{10}\) 依次存放在同一个磁道上,即物理块 \(n\) 存放逻辑记录 \(R_{n-1}\),磁盘的旋转周期为 33ms,磁头当前处在 \(R_0\) 开始处,系统使用单缓冲区顺序处理这些记录,每个记录处理时间为 3ms
- 处理这 11 个记录的最长时间为:\(33\times(11-1)+\frac {33}{11}+3=336\)
- 磁头从准备处理 \(R_{n-1}\) 到准备处理 \(R_n\) 需要 33ms,共计 \((11-1)\) 个,直至磁头准备处理 \(R_{10}\),\(\frac {33}{11}\)ms 读取,3ms 处理
- 对信息存储优化分布后,处理这 11 个记录的最短时间为:\((\frac {33}{11}+3)\times11=66\)
- 存放顺序为交错存储,即 0 6 1 7 2 8 3 9 4 10 5(类似栅栏密码)
(7)总线系统
- 内部总线:计算机内部各功能模块之间用于传输数据和控制信号的通道
- 系统总线:连接计算机系统中主要部件的公共通信线路
- 数据总线:数据传输
- 地址总线:地址信息传输
- 32 位地址总线可以寻址 \(2^{32}\) 个不同的内存地址
- 控制总线:控制信号传输
- 外部总线:计算机与外部设备之间用于数据传输的接口总线
(8)可靠性
- 串联系统
- 系统可靠性:每个子系统的可靠性之积,\(R=R_1\times R_2\times\cdots\times R_n\)
- 系统失效率:每个子系统的失效率之和,\(\lambda=\lambda_1+\lambda_2+\cdots+\lambda_n\)
- 并联系统
- 系统可靠性:\(R=1-(1-R_1)\times(1-R_2)\times\cdots\times(1-R_n)\)
- 系统失效率:\(\mu=\frac 1{\frac 1\lambda\sum\limits_{j=1}^{n}\frac 1j}\) 或 \(1-R\)
(9)校验码
-
码距:编码系统中任意两个码字的最小距离(两个码字之间不同的个数)
- 检测 \(e\) 个误码需要最小码距为 \(d\ge e+1\)
- 纠正 \(t\) 个误码需要最小码距为 \(d\ge 2t+1\)
-
循环校验码 CRC
-
能检错,不能纠错
-
采用模二除法,按位异或,如:10111 对 110 进行模二除法$$\begin{array}{l}10111\110\\hline0111\\ \ 110\\hline\ \ 0011\end{array}$$
-
例:原始报文为 110 0101 0101,其生成的多项式为 \(x^4+x^3+x+1\),则 CRC 编码结果为:
- \(x^4+x^3+x+1\) 的二进制表示为 11011
- 对原始报文尾部添加 \((生成多项式长度-1)\) 个 0,即 110 0101 0101 0000
- 新生成的报文对多项式的二进制表示进行模二除法,余数为 0011
- 用余数替换后补 0,得到编码结果,是 110 0101 0101 0011
- 海明校验码
例:计算 1011 的海明码
根据公式 \(2^r\ge信息长度+r+1\) 得出 \(r\ge3\),即校验码至少需要 3 位,分别位于 \(2^0\)、\(2^1\)、\(2^2\) 位
此时得到如下表格:
7 6 5 4 3 2 1 位数 \(I_4=1\) \(I_3=1\) \(I_2=0\) \(I_1=1\) 信息位 \(r_2\) \(r_1\) \(r_0\) 校验位
每个信息位的二进制多项式表示为:\(7=2^2+2^1+2^0\)、\(6=2^2+2^1\)、\(5=2^2+2^0\)、\(3=2^1+2^0\)
将包含相同多项式的信息位进行异或,得到该多项式对应的校验位的值:
\[2^2:r_2=I_4\oplus I_3\oplus I_2=1\oplus1\oplus0=0\\ 2^1:r_1=I_4\oplus I_3\oplus I_1=1\oplus1\oplus1=1\\ 2^0:r_0=I_4\oplus I_2\oplus I_1=1\oplus0\oplus1=0 \]
- 因此海明码是 0110011
例:对信息 0110111 纠错
依次对应 \(r_0=0,r_1=1,I_1=1,r_2=0,I_2=1,I_3=1,I_4=1\)
偶校验:
\[2^2:r_2\oplus I_4\oplus I_3\oplus I_2=0\oplus1\oplus1\oplus1=1\\ 2^1:r_1\oplus I_4\oplus I_3\oplus I_1=1\oplus1\oplus1\oplus1=0\\ 2^0:r_0\oplus I_4\oplus I_2\oplus I_1=0\oplus1\oplus1\oplus1=1 \]
- 即第 5 位(101)发生错误,需要取反
0x02 操作系统
- 功能
- 管理系统的软硬件、数据资源
- 控制程序运行
- 人机之间、应用软件与硬件之间的接口
- 管理职能:进程管理、存储管理、文件管理、作业管理、设备管理
- 微内核操作系统:虚设备与 spooling 技术
(1)进程管理
进程状态转换图
-
五态模型
graph LR 1[静止就绪]--恢复或挂起-->2[活跃就绪]--挂起-->1 3[运行]--挂起-->1 3--时间片到达-->2--调度-->3 4[静止阻塞]--等待事件发生-->1 4--恢复或激活-->5[活跃阻塞]--挂起-->4 3--等待某个事件-->5--等待事件发生-->2 -
其中活跃就绪(就绪)、运行、活跃阻塞(等待)构成三态模型
前趋图
-
用于表达任务的并行关系和递进关系,如:
flowchart LR 1((需求分析))-->2((项目设计))-->31((前端开发)) & 32((后端开发))-->4((代码测试))-->5((部署上线))
进程的同步与互斥
- 同步:多个进程之间按照一定的顺序协调运行,确保某些操作按特定顺序完成
- 互斥:多个进程不能同时访问共享资源,以避免数据冲突或不一致
PV 操作
-
临界资源:各进程间需要互斥方式对其进行共享的资源
-
临界区:每个进程中访问临界资源的代码
-
信号量:一种特殊变量
-
PV 操作
graph LR subgraph 进程队列 q[[ ]] end subgraph P 操作 p1[S=S-1]-->p2{S<0}--T-->q end subgraph V 操作 v1[S=S+1]-->v2{S<=0} q--T-->v2 end- 其中,S 是信号量
例 1:单缓冲区生产者、消费者问题 PV 原语描述:S1 初值为 1,S2 初值为 0
生产者 消费者 生产一个产品 P(S2),S2=1-1=0 P(S1),S1=1-1=0 从缓冲区取产品 送产品到缓冲区 V(S1),S1=0+1=1 V(S2),S2=0+1=1 消费产品
例 2:书店有一个收银员和 n 个顾客,信号量 S1、S2、Sn 初值分别为 0,0,n
顾客进程 i(i=1,2,...,n):
graph LR subgraph 付款 a1 & a2 end p["P(Sn)"]-->购书-->a1-->a2-->v["V(Sn)"]收银员进程:
graph LR b1-->收费-->b2-->b1
- a1、a2 分别为 V(S1)、P(S2)
- V(S1) 用于唤醒收银员
- P(S2) 用于支付
- b1、b2 分别为 P(S1)、V(S2)
- P(S1) 用于响应唤醒
- V(S2) 用于收款
例 3:根据前趋图描述 PV 原语,S1=0,S2=0,S3=0,S4=0
graph LR 1((1)) & 2((2)) & 3((3))-->4((4))-->5((5))
- 进程 1:V(S1)
- 进程 2:V(S2)
- 进程 3:V(S3)
- 进程 4:P(S1) P(S2) P(S3) V(S4)
- 进程 5:P(S4)
死锁问题
- 当一个进程在等待一件不可能的事件时,发生了死锁;任一进程死锁都会导致系统死锁
- 当系统至少有 \(1+\sum\limits_{i=1}^{n}(各进程数需要资源数-1)\) 个资源时,不可能发生死锁
例:系统有 3 个进程,各自都需要 5 个系统资源,为完全避免死锁,系统执行需要 \(1+[(5-1)+(5-1)+(5-1)]=13\) 个资源
- 产生死锁的必要条件:互斥、占有和等待、非抢占、环路等待
- 避免死锁:有序资源分配、银行家算法
银行家算法
- 分配资源的原则:
- 当进程对资源的最大需求不超过系统中的资源数时可以接纳(\(进程需求\lt系统总量\))
- 进程可以分期请求资源,但请求的总数不能超过最大需求量(\(\sum分期资源\lt总需求\))
- 当前不能满足,可以延迟分配,但总能使进程在有限时间内获得资源
例:系统内三类互斥资源 R1、R2、R3,可用资源数分别为 9、8、5,T0 时有 P1~P5 五个进程,安全序列为:
最大需求量 已分配资源 R1 R2 R3 R1 R2 R3 P1 6 5 2 1 2 1 P2 2 2 1 2 1 1 P3 8 1 1 2 1 0 P4 1 2 1 1 2 0 P5 3 4 4 1 1 3
- 系统剩余资源:
\[ R_1=9-(1+2+2+1+1)=2\\R_2=8-(2+1+1+2+1)=1\\R_3=5-(1+1+0+0+3)=0 \]
- 进程还需资源:
R1 R2 R3 P1 5 3 1 P2 0 1 0 P3 6 0 1 P4 0 0 1 P5 2 3 1
- 如果按序列 \(P_2\rightarrow P_4\rightarrow P_5\rightarrow P_1\rightarrow P_3\),则
现有资源 需要资源 已经分配 现有+已经分配 完成 R1 R2 R3 R1 R2 R3 R1 R2 R3 R1 R2 R3 P2 2 1 0 0 1 0 2 1 1 4 2 1 True P4 4 2 1 0 0 1 1 2 0 5 4 1 True P5 5 4 1 2 3 1 1 1 3 6 5 4 True P1 6 5 4 5 3 1 1 2 1 7 7 5 True P3 7 7 5 6 0 1 2 1 0 9 8 5 True (如果现有资源大于需要资源,则可以假定该进程可以完成,并释放已经分配的资源,从而提高现有资源数量)
(2)存储管理
分区存储组织
- 首次适应法:从头开始,在首次能够容纳新作业空间的区块,切割空间并分配给该作业
- 最佳适应法:将所有空闲区块按从小到大连接成链,依次找到能够容纳新作业空间的区块并切割
- 最差适应法:在最大空闲区块中切割(避免小块空闲区块过多)
- 循环首次适应法:将所有空闲区块,从最后一次分配开始,按顺序连接成环,进行首次适应法
段页式存储
页式存储
- 将用户程序等分为大小相同的页并编号,通过页表将页号与物理块号(页帧号)进行映射,指向对应的物理地址
- 逻辑地址:页号+页内地址
- 优点:利用率高、碎片小、分配与管理简单
- 缺点:增加系统开销、可能产生抖动现象
例:进程 P 有 6 个页面,页号从 0 到 5,页面大小 4K,页面变换表如下,状态位 1 和 0 分别表示页面在和不在内存:
页号 页帧号 状态为 访问位 修改位 0 2 1 1 0 1 3 1 0 1 2 5 1 1 0 3 - 0 0 0 4 - 0 0 0 5 6 1 1 1
- 如果系统分配给该进程 4 个存储块,该进程要访问的逻辑地址为 5A29H,则变换后的物理地址为:
- 由于 \(4K=2^{12}\),则页内地址共 12 位,高于 12 位的部分为页号
- 因此 5A29H 地址的
A29为页内地址,页号为5- 页号 5 对应的页帧号(物理块号)为 6
- 则变换后的物理地址为 6A29H
- 如果该进程要访问的页面 4 不存在,则需要淘汰的页面的页号为:
- 由于页面 4 的状态位为 0,表示页面 4 不在内存,则需要淘汰的页面必然在内存中,即 0、1、2、5 之一
- 由于页面 1 的访问位为 0,可以被淘汰;而其他页面的访问位均为 1 不可淘汰
- 则需要淘汰的页面的页号为 1
段式存储
- 将用户程序按逻辑结构分为大小可能不同的段并编号,通过段表将段号、段长与基址进行映射,指向对应的物理地址
- 逻辑地址:段号+段内地址
- 优点:多道程序共享内存、各段程序修改互不影响
- 缺点:内存利用率低、内存碎片浪费大
段页式存储
- 将程序的逻辑地址空间划分为多个逻辑段,每个段再被划分为固定大小的页面,内存地址空间也被划分为固定大小的页面帧
- 程序运行时,段被加载到内存中,段内的页面被映射到内存的页面帧中;通过段表和页表的两级映射机制,将逻辑地址转换为物理地址
- 优点:空间浪费小、存储共享容易、存储保护容易、能动态连接
- 缺点:复杂和开销随管理软件的增加而增加,所需硬件与占用内容也会增加,继而降低执行速度
页面置换算法
-
最优算法 OPT、随机算法 RAND、先进先出算法 FIFO、最近最少使用算法 LRU
-
FIFO 抖动现象:分配更多的资源反而效率变低
-
3 页
访问顺序 4 3 2 1 4 3 5 4 3 2 1 5 1 4 4 4 3 2 1 4 4 4 3 5 5 2 3 3 2 1 4 3 3 3 5 2 2 3 2 1 4 3 5 5 5 2 1 1 缺页 √ √ √ √ √ √ √ √ √ 共计缺页 9 次
-
4 页
访问顺序 4 3 2 1 4 3 5 4 3 2 1 5 1 4 4 4 4 4 4 3 2 1 5 4 3 2 3 3 3 3 3 2 1 5 4 3 2 3 2 2 2 2 1 5 4 3 2 1 4 1 1 1 5 4 3 2 1 5 缺页 √ √ √ √ √ √ √ √ √ √ 共计缺页 10 次
-
例 1:内存空间 3 页,初始内存为空,访问序列为 5 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 5 0 1
FIFO
5 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 5 0 1 1 5 5 5 0 0 1 2 3 0 4 2 2 2 3 0 0 0 1 2 5 2 0 0 1 1 2 3 0 4 2 3 3 3 0 1 1 1 2 5 0 3 1 2 2 3 0 4 2 3 0 0 0 1 2 2 2 5 0 1 缺页 √ √ √ √ √ √ √ √ √ √ √ √ √ √ √ LRU
5 0 1 2 0 3 0 4 2 3 0 3 2 1 2 0 1 5 0 1 1 5 5 5 2 2 2 2 4 4 4 0 0 0 1 1 1 1 1 1 1 2 0 0 0 0 0 0 0 0 3 2 2 2 2 2 2 2 5 5 5 3 1 1 1 3 3 3 2 2 3 3 3 3 3 0 0 0 0 0 缺页 √ √ √ √ √ √ √ √ √ √ √ √
例 2:有按字节编址的 8 位计算机系统,采用虚拟页式存储管理方案,页面大小位 1KB,无快表。用户程序中,
swap A,B占用页号 0 和 1,A占用页号 2 和 3,B占用页号 4 和 5。swap A,B是 16 位指令,A和B表示该指令的两个 16 位操作数。swap指令存放在内存的 1023 单元,A存放在内存的 3071 单元,B存放在内存的 5119 单元
- 执行
swap指令需要访问内存的次数为:
- “无快表” 说明每次从页表读取对应物理块需要访问两次,因此上述执行该指令需要访问内存 \(2\times6=12\) 次
- 上述行为将产生的缺页中断次数为:
- 指令虽然跨页,但仅计算一次缺页中断
- 两个操作数都跨页,都计算两次缺页中断
- 则总的缺页中断次数为 \(1+2+2=5\) 次
(3)文件管理
文件
- 属性:
- R:只读属性
- A:存档属性
- S:系统文件
- H:隐藏文件
- 文件名:驱动器号、路径、主文件名、扩展名
索引文件结构
-
从索引节点到物理盘块称为直接索引,其中增加的 N 次索引节点,则称为 N 级间接索引
-
如果索引节点有 13 个节点中,则:
索引节点 索引方式 0 直接索引 1 直接索引 2 直接索引 3 直接索引 4 直接索引 5 直接索引 6 直接索引 7 直接索引 8 直接索引 9 直接索引 10 一级间接索引 11 二级间接索引 12 三次间接索引 此时,当一个物理盘块大小为 \(4K\),每个索引节点为 4 字节,那么按上述索引方法,能够存储的文件最大为:\(4K\times10+4K\times\frac {4K}{4字节}+4K\times(\frac {4K}{4字节})^2+4K\times(\frac {4K}{4字节})^3\)
-
-
相应的,间接存储层次越多,能够存放的文件大小越大,读取效率越低
例:索引节点有 8 个 4 字节地址项:0~7,其中 0~4 采用直接索引,5、6 采用一级间接索引,7 采用二级间接索引。磁盘索引块与磁盘数据块大小均为 1KB 字节,某文件的索引为:
索引节点 二级间接索引地址 一级间接索引地址 直接索引地址 0 50 1 67 2 68 3 78 4 89 5 58……136 90 6 187……129 91 7 156:261……516
……
168:518……1021156……168 101
若访问该文件逻辑块号 5 和 261 的信息,则对应的物理块号分别为:
0 节点对应的物理块号为 0,1 对应 1,……,5 的 0 对应 6,5 的 1 对应 7,……
一个一级间接索引能够存储 \(\frac {磁盘索引块:1K}{地址项大小:4} = 2^8 = 256\) 个地址
\(261=256(一个一级间接索引地址数)+5(5个直接索引数)\) 说明逻辑块 261 对应 6 节点的第 0 个索引节点
即
逻辑块 物理块 5 58 261 187 101 物理块号存放的是:二级地址索引表
树形目录结构
- 绝对路径:从盘符开始的路径
- 相对路径:从当前路径开始的路径
位示图法
- 空闲存储空间管理方法:空闲区表法、空闲链表法、位示图法、成组链接法
- 位示图中,0 表示已占用,1 表示未占用(空闲)
例:磁盘上物理块编号依次为 0、1、2、……,系统中字长为 32 位,每一位对应文件存储器的一个物理块,0 空闲 1 占用,位示图如下,如果 4195 号物理块分配给某文件,则
31 30 …… 4 3 2 1 0 0 1 …… 1 0 0 0 1
- 该物理块的使用情况在位示图的第几个字的描述:
- \(4195 号物理块=第 4196 个物理块\)
- \(\frac {4196}{32}=131.125>131\)
- 向上取整(即前 131 个字要填满),该物理块位于第 132 个字
- 系统应将:
- \(131\times32=4192\),即第 132 字的第 0 位置为 4192
- 依此类推,4195 位于第 132 字的第 3 位置
- 系统应将该字的第 3 位置置 1
(4)设备管理
数据传输控制方式
- 包括:程序控制方式、程序中断方式、DMA、通道、输入输出处理机
(5)微内核操作系统
| 实质 | 优点 | 缺点 | |
|---|---|---|---|
| 单体内核 | 将图形、设备驱动及文件系统等功能全部在内核中实现,运行在内核状态和同一地址空间 | 减少进程间通信和状态切换的系统开销,获得较高的运行效率 | 内核庞大,占用资源多 不易剪裁 系统的稳定性和安全性不好 |
| 微内核 | 只实现基本功能,其他功能防止内核外 | 内核精炼,便于剪裁和移植 系统服务程序运行在用户地址空间,系统的可靠性、稳定性和安全性较高 可用于分布式系统 |
用户状态和内核状态需要频繁切换,从而导致系统效率不如单体内核 |
0x03 数据库系统
(1)三级模式、两级映射
- 三级模式:
- 外模式:用户级数据库、用户视图
- 视图 View
- 概念模式:概念级数据库、DBA 视图
- 表 Table
- 内模式:物理级数据库、内部视图
- 数据存储
- 外模式:用户级数据库、用户视图
- 两级映射:外模式-概念模式映射、概念模式-内模式映射
(2)设计过程
- 需求分析:产出数据流图、数据字典、需求说明书
- 概念结构设计:产出 E-R 模型
- 逻辑结构设计:产出关系模式
- 物理设计
(3)E-R 模型
-
方框表示实体、椭圆表示属性、菱形表示联系,如:
graph LR s1([学号]) & s2([姓名]) & s3([性别])---s[学生] c[课程]---c1([课程编号]) & c2([课程名]) & c3([授课教师]) s--M---sc{选课}--N---c sc---sc1([成绩])- M、N 表示学生与课程间存在多对多关系
-
集成
- 方法:
- 多个局部 E-R 图一次集成
- 逐步集成,每次集成两个局部 E-R 图
- 产生的冲突
- 属性冲突:属性域冲突、属性取值冲突
- 命名冲突:同名异义、异名同义
- 结构冲突:同一对象在不同应用具有不同的抽象、同一实体在不同局部 E-R 图中所包含的属性个数与属性排列次序不一致
- 方法:
-
一个实体型转换为一个关系模式
- \(1:1\) 联系
- \(1:n\) 联系
- \(m:n\) 联系
例:对于三个不同实体集和它们之间的多对多关系 \(m:n:p\),最少可以转换的关系模式个数为:
graph LR A--m---l{ }--n---B l--p---C
- 每个实体转成一个关系模式:3
- 联系转为多对多关系模式:1
- 因此最少可以转换为 \(3+1=4\) 个关系模式
(4)关系代数
- 并:\(S1\cup S2\),两个数据中的所有内容(去重)
- 交:\(S1\cap S2\),两个数据中相同的内容
- 差:\(S1-S2\),S1 中除去包含在 S2 的数据(结果为 S1 有而 S2 没有的),如:\(\{1,2\}-\{1\}=\{2\}\)
- 笛卡尔积:\(S1\times S2\),S1 的每项与 S2 的每项全排列,如:\(\{1,2\}\times\{3,4\}=\{13,14,23,24\}\)
- 投影:\(\Pi_{S_{p1},S_{p2}}(S1)\),取出 S1 中的 \(S_{p1}\) 列和 \(S_{p_2}\) 列
- 选择:\(\sigma_{S_p=x}(S1)\),取出 S1 中满足 \(S_p\) 列值为 \(x\) 的所有行
- 连接:\(S1\Join_{S1.S_p=S2.S_p} S2\),取出 S1 中 \(S_p\) 的值和 S2 中 \(S_p\) 的值相同的所有行及其在两个表中所有列的值,如:\(\{12,34\}\Join_{1=1}\{17,68,39\}=\{127,349\}\)
- 没有条件则称为自然连接,即把两个表中相同列做等值
(5)规范化理论
- 设 \(R(U)\) 是属性 \(U\) 上的一个关系模式,\(X\) 和 \(Y\) 是 \(U\) 的子集,\(r\) 为 \(R\) 的任意关系,如果对于 \(r\) 中的任意两个元组 \(u\)、\(v\),只要有 \(u[X]=v[X]\),就有 \(u[Y]=v[Y]\),则称 \(X\) 函数决定 \(Y\),\(Y\) 函数依赖于 \(Y\),记为 \(X\rightarrow Y\)
- 部分函数依赖:函数 \(A\) 与函数 \(B\) 共同决定函数 \(C\),且函数 \(A\) 也可以决定函数 \(C\)
- 传递函数依赖:函数 \(A\) 决定函数 \(B\),函数 \(B\) 决定函数 \(C\),且函数 \(B\) 不能决定函数 \(A\)
- 非规范化可能会导致:数据冗余、更新异常、插入异常、删除异常
- 键包括:
- 超键:唯一标识元组
- 候选键:超键消除多余属性的结果
- 根据函数依赖关系图,以入度为 0 的属性为起点尝试遍历该关系图,如果遍历成功则该属性可以作为候选键;如果遍历失败,但加入其中的一些中间结点可以遍历成功,则这些结点的集合作为候选键
- 没有入度为 0 的结点,则可以选取任一结点
- 主键:候选键任选之一
- 外键:其他关系的主键
例 1:关系 R 如下,R 的候选关键字(候选键)为:A1
graph LR A1-->A2-->A3-->A2-->A4
例 2:关系 P 如下,候选码为:\(\{A,B,C,D\}\)
graph LR A & B & D--ABD-->E A & B--AB-->G-->H B-->F C-->J C & J--CJ-->I
例 3:关系 R 如下,候选关键字为:A 和 B
graph LR A-->B & C B-->A & C
- 范式 NF(主属性是候选键的一部分)
- 第一范式 1NF:属性值都是不可分的原子值
- 第二范式 2NF:1NF 消除非主属性对候选键的部分依赖
- 第三范式 3NF:2NF 消除非主属性对候选键的传递依赖
- BC 范式 BCNF:3NF 消除主属性对候选键的传递依赖
例 4:某公司有部门(部门号、部门名、负责人、电话)、商品(商品号、商品名、单价、库存量)、职工(职工号、姓名、住址)三个实体,假设每个部门有一个负责人、一个电话、若干员工,每个商品只由一个部门负责销售
- 部门关系不属于 3NF 的原因:
- 部门号可以作为该表的主键,即不存在部分依赖
- 因此不属于 3NF 的原因是未消除传递函数依赖
- 如果要得到表(职工号、姓名、部门名、月销售额),需要:
- 职工与部门存在多对一的关系,新增的要在“多”的一边
- 因此需要在职工表中新增部门号
- 在构建上述的表时,需要增加的关系模式是:销售(职工号、商品号、日期、数量)
- 设数据库模式 \(\rho=\{R1,R2,\cdots,Rk\}\) 是关系模式 R 的一个分解,F 是 R 上的函数依赖集,\(\rho\) 中每个模式 Ri 上的 FD 集是 Fi,如果 \(\{F1,F2,\cdots,Fk\}\) 与 F 是等价的,那么长分解 \(\rho\) 保持 FD
- 无损分解:可以还原的分解
- 如:
成绩(学号、姓名、课程号、课程名、成绩)的无损分解可以是成绩(学号、课程号、分数),学生(学号、姓名),课程(课程号、课程名)
- 如:
- 如果 R 的分解为 \(\rho=\{R_1, R_2\}\),F 为 R 满足的函数依赖集合,分解 \(\rho\) 具有无损连接性的充要条件是 \(R_1\cap R_2\rightarrow(R_1-R_2)\) 或 \(R_1\cap R_2\rightarrow(R_2-R_1)\)
例 5:设 \(R=ABC, F=\{A\rightarrow B\}\),则 \(\rho_1=\{R_1(AB), R_2(AC)\}, \rho_2=\{R_1(AB), R_3(BC)\}\) 是不是无损分解
- 对于 \(\rho_1\),\(R_1\cap R_2=A,R_1-R_2=B,R_2-R_1=C\),满足 \(A\rightarrow B\) 或 \(A\rightarrow C\)
- 对于 \(\rho_1\),\(R_1\cap R_3=B,R_1-R_3=A,R_3-R_1=C\),满足 \(B\rightarrow A\) 或 \(B\rightarrow C\)
- 由于 \(F\) 中仅有 \(A\rightarrow B\),因此仅有 \(\rho_1\) 是无损分解
(6)并发控制
- 事务的 ACID:
- 原子性:事务不可拆分
- 一致性:事务执行前后,数据保持一致,没有丢失
- 隔离性:事务间相互隔离
- 持续性:事务的结果持续影响
- 并发产生的问题:
- 丢失更新:在多个事务中对同一数据更新操作,某些操作可能会丢失,即被后来的操作覆盖
- 不可重复读:在同一事务的两次读取中,期间可能数据被其他事务更新,导致两次读取结果不一致
- 脏数据读出:某个事务中产生的临时数据,会被其他事务作为实际数据读出
- 封锁协议(X 锁:写锁,S 锁:读锁)
- 一级封锁协议:事务在修改数据前加 X 锁,直至事务结束后释放(防止丢失更新)
- 二级封锁协议:一级封锁协议基础上,事务在读取数据前加 S 锁,直至读取完成后释放(+防止脏数据读出)
- 三级封锁协议:一级封锁协议基础上,事务在读取数据前加 S 锁,直至事务结束后释放(+防止不可重复读)
- 两段锁协议:可串行化,但可能会死锁
- 死锁的预防、解除
(7)完整性约束
- 包括:
- 实体完整性约束
- 参照完整性约束
- 用户自定义完整性约束
- 触发器(Trigger):通过脚本实现更加复杂的完整性约束
(8)安全
| 措施 | 说明 |
|---|---|
| 用户标识与鉴定 | 用户账户、口令、随机数检验 |
| 存取控制 | 用户授权(包括操作类型、数据对象的权限) |
| 密码存储与传输 | 对远程终端信息用密码传输 |
| 视图保护 | 视图授权 |
| 审计 | 记录用户操作 |
(9)备份与恢复
备份
-
按备份方式:
- 冷备份(静态备份):在数据库关闭情况下,将数据库的所有文件备份
- 热备份(动态备份):在数据库运行情况下,通过备份软件,将数据库的所有文件备份
方式 优点 缺点 冷备份 方法简易、易于归档、易于恢复、低维护、高安全 单时间点恢复
不能进行其他工作
不能按表或按用户恢复热备份 可在表空间或数据库文件级备份,用时短
备份时数据库可用于其他工作
可对几乎所有数据库实体做恢复
恢复速度快错误后果严重
失败的结果无法用于时间点恢复
难于维护 -
按备份量:
- 完全备份:备份所有数据
- 差量备份:仅备份上一次完全备份后变化的数据
- 增量备份:备份上一次备份后变化的数据
-
静态/动态 海量/增量 转储
- 系统中是否允许事务运行分为动态(是)与静态(否)
- 每次转储全部(海量)或上一次转储后更新的数据(增量)
故障与恢复
| 故障关系 | 故障原因 | 解决方法 |
|---|---|---|
| 事务本身可预期故障 | 自身逻辑 | 程序中预先设置 rollback |
| 事务本身不可预故障 | 算术溢出、违反存储保护 | 由 DBMS 的恢复子系统通过日志,撤销事务对数据库的修改,回退到事务初始状态 |
| 系统故障 | 系统停止运作 | 检查点法 |
| 介质故障 | 外存被破坏 | 根据日志重做业务 |
(10)数据仓库与数据挖掘
-
数据仓库特点:面向主题、集成、相对稳定、反映历史变化
-
数据仓库构建流程:
graph LR 数据源--抽取/清理/装载/刷新-->数据仓库<-->OLAP服务器 数据仓库--服务--->数据挖掘工具等数据集市:部门级子数据仓库
-
数据挖掘方法:决策树、神经网络、遗传算法、关联规则挖掘算法
-
数据挖掘分类:
- 关联分析:数据间相互关系
- 序列模式分析:数据间先后(因果)关系
- 分类分析:为每个记录赋予标记后,按标记分类
- 聚类分析:分类分析逆过程
(11)反规范化
- 用于解决系统多次连接表实现查询的低效率问题
- 方法:增加派生性冗余、增加冗余列、重新组表、分割表
(12)大数据
-
大数据的 4V:
- 数据量 Volume
- 速度 Velocity
- 多样性 Variety
- 值 Value
-
大数据处理系统的重要特征
- 高可扩展
- 高性能
- 高容错
- 支持异构环境
- 较短的分析延迟
- 易用且开放的接口
- 低成本
- 向下兼容
-
对比传统数据:
维度 传统数据 大数据 数据量 GB、TB PB+ 数据分析需求 现有数据的分析与检测 深度分析 硬件平台 高端服务器 集群
0x04 计算机网络
(1)OSI/RM 七层模型
| 层次 | 名称 | 主要功能 | 主要设备及协议 |
|---|---|---|---|
| 7 | 应用层 | 实现具体的应用功能 | POP3、FTP、HTTP、Telnet、SMTP、DHCP、TFTP、SNMP、DNS |
| 6 | 表示层 | 数据的格式与表达、加密、压缩 | |
| 5 | 会话层 | 建立、管理、终止会话 | |
| 4 | 传输层 | 端到端的连接 | TCP、UDP |
| 3 | 网络层 | 分组传输和路由选择 | 三层交换机、路由器 ARP、RARP、IP、ICMP、IGMP |
| 2 | 数据链路层 | 传送以帧为单位的信息 | 网桥、交换机、网卡 PPTP、L2TP、SLIP、PPP |
| 1 | 物理层 | 二进制传输 | 中继器、集线器 |
- 局域网:物理层、数据链路层
例:网络如下,IP 全局广播分组不能够通过的路径:
graph TB 计算机P-->21{网桥} & 3{路由器} 21-->1{集线器} & 计算机Q 1-->计算机R 3-->22{交换机} & 计算机S 22-->计算机T
- 计算机 P 通过网桥、集线器可以到达计算机 R、Q
- 计算机 P 通过路由器不可以到达计算机 T、S
- 计算机 R、Q 通过集线器可以到达对方
- 计算机 T、S 通过交换机可以到达对方
(2)标准与协议
协议簇
多个协议的整合体
-
TCP/IP 协议:Internet 标准协议簇
- 特点:可扩展、可靠、应用广泛、牺牲速度和效率
-
IPX/SPX 协议:局域网联机
-
NETBEUI 协议:不支持路由,速度较快
TCP
-
三次握手
sequenceDiagram participant A participant B A->>B: SYN(SEQ=x) B->>A: SYN(SEQ=y, ACK=x+1) A->>B: SYN(SEQ=x+1, ACK=y+1)其中,TCP 连接状态依次为:SYN_RECV、SYN_RECV、ESTABLISHED
-
四次挥手
sequenceDiagram participant A participant B A->>B: FIN B->>A: ACK A->>B: FIN B->>A: ACK
DHCP
- 用于 IP 地址动态分配
- 采用客户机/服务器模型
- 租约(地址可使用有效期)默认为 8 天
- 当租约过半的时候需向 DHCP 服务器申请续租
- 当租约超过 87.5% 时未续约或没有和当初提供 IP 的 DHCP 服务器联系上时,则开始联系其他 DHCP 服务器
- 分配策略包括:固定分配、动态分配、自动分配
- 当 IP 为 169.254.0.0/16 或 0.0.0.0 时,分别在 Windows 和 Linux 系统中表示 DHCP 失效
DNS
- 用于客户端查询域名服务器中域名对应的 IP
- 主机向本地域名服务器的查询采用递归查询
- 递归查询:服务器必须回答目标 IP 与域名的映射关系
- 本地域名服务器向根域名服务器的查询采用迭代查询
- 迭代查询:服务器收到一次迭代查询回复一次结果,结果可能是目标 IP 与域名的映射关系或其他 DNS 服务器地址
例:主机 1 对主机 2 进行域名查询的过程如下,说明:
graph TB 根域名服务器<-->本地域名服务器<-->主机1 & z[中介域名服务器] z<-->授权域名服务器---主机2
- 根域名服务器采用迭代查询
- 中介域名服务器采用递归查询
(3)类型与拓扑结构
- 按分布范围:
- 局域网:LAN
- 城域网:MAN
- 广域网:WAN
- 因特网
- 按拓扑结构:总线型、星型、环型
(4)规划与设计
-
规划原则:实用性、开放性、先进性
-
设计任务:
- 确定网络总体目标
- 确定总体设计原则
- 通信子网设计
- 资源子网设计
- 设备选型
- 网络操作系统与服务器资源设备
- 网络安全设计
-
设计原则:
- 可用性:网络或网络设备可用于执行预期任务时间所占总量的百分比
- 可靠性:网络设备或计算机持续执行预订功能的可能性
- 可恢复性:网络从故障中恢复的难易程度与时间
- 适应性:在用户改变应用要求时,网络的应变能力
- 可伸缩性:网络技术或设备随着用户需求的增长而扩充的能力
-
实施原则:可靠性、安全性、高效性、可扩展性
-
实施步骤:
graph LR 工程实施计划-->网络设备到货验收-->设备安装-->系统测试-->系统试运行-->用户培训-->系统转换 -
其他设计
-
逻辑网络设计:逻辑网络设计图,IP 地址方案,安全方案,具体的软硬件、广域网连接设备和基本服务,招聘和培训网络员工的具体说明、对软硬件、服务、员工和培训的费用初步估计
-
物理网络设计:网络物理结构图和布线方案、设备和部件的详细列表清单、软硬件和安装费用的估算、安装日程表、安装后的测试计划、用户培训计划
-
分层设计:
-
接入层:向本地网段提供用户接入
-
汇聚层:网络访问策略控制、数据包处理、过滤、寻址
-
核心层:数据交换
graph TB Internet--防火墙---核心交换机---1[汇聚交换机] & 2[汇聚交换机] 1---11[接入交换机] & 12[接入交换机] 2---21[接入交换机] & 22[接入交换机]
-
-
(5)IP 与子网划分
IP 地址及其分类
IPv4
| 类别 | 点分十进制 | 二进制 |
|---|---|---|
| A 类 | 0.0.0.0~ 127.255.255.255 |
00000000 00000000 00000000 00000000~ 01111111 11111111 11111111 11111111 (0 开头) |
| B 类 | 128.0.0.0~ 191.255.255.255 |
10000000 00000000 00000000 00000000~ 10111111 11111111 11111111 11111111 (10 开头) |
| C 类 | 192.0.0.0~ 223.255.255.255 |
11000000 00000000 00000000 00000000~ 11011111 11111111 11111111 11111111 (110 开头) |
| D 类组播 | 224.0.0.0~ 239.255.255.255 |
11100000 00000000 00000000 00000000~ 11101111 11111111 11111111 11111111 (1110 开头) |
| E 类保留 | 240.0.0.0~ 255.255.255.255 |
11110000 00000000 00000000 00000000~ 11111111 11111111 11111111 11111111 (1111 开头) |
- 其中,全 0 和全 1 都不能表示主机,因此每类地址最多能够表示的主机台数为:\(2^{主机号数}-(1个全零地址+1个全一地址)\)
- A 类地址前 8 位是网络号,其余 24 位是主机号,最多表示 \((2^{32-8}-2)\) 台主机
- B 类地址前 16 位是网络号,最多表示 \((2^{32-16}-2)\) 台主机
- C 类地址前 24 位是网络号,最多表示 \((2^{32-24}-2)\) 台主机
X.X.X.X/24中 24 表示 IP 地址中,前 24 位表示网络号,即后 8 位表示主机号最多表示 \((2^8-2=254)\) 台主机
子网
- 通过子网掩码实现子网划分与合并
- 划分:取部分主机号作为子网号,将一个网络划分为多个子网
- 合并:取部分网络号作为主机号,将多个网络合并为一个大网络
- 子网掩码中,
1对应的部分表示网络号,0对应的部分表示主机号- \(子网个数=2^{除分类外网络号位数}\)
例 1:将 B 类 IP 地址
168.195.0.0划为 27 个子网,子网掩码为:
- B 类网络前 16 位是网络号,因此子网掩码前 16 位是 255(
11111111)- \(2^4<27<2^5\),说明至少 5 位网络号才能支持 27 个子网
- 综上,子网掩码为
255.255.248.0(11111111 11111111 11111000 00000000)
例 2:将 B 类 IP 地址
168.195.0.0划为若干个子网,每个子网有主机 700 台,子网掩码为:
- B 类网络前 16 位是网络号,因此子网掩码前 16 位是 255(
11111111)- \(2^9-2<700<2^{10}-2\),说明至少 10 位主机号才能支持 700 台主机,即网络号至多为 \(32-16-10=6\) 位
- 综上,子网掩码为
255.255.252.0(11111111 11111111 11111100 00000000)
例 3:某网络地址块为
210.115.192.0/20,则可以被划分的 C 类子网个数为:
- 网络号有 20 位,主机号有 12 位
- C 类子网指网络号要有 24 位,主机号则有 8 位
- 因此可以有 4 位用来划分子网,对应的有 \(2^4=16\) 个 C 类子网
特殊含义的 IP 地址
| IP | 说明 |
|---|---|
| 127 网段 | 回播地址 |
| 网络号全 0 地址 | 当前子网中的主机 |
| 网络号全 1 地址 | 本地子网的广播 |
| 主机号全 1 地址 | 特定子网的广播 |
| 10.0.0.0/8 | 10.0.0.1~10.255.255.254 |
| 172.16.0.0/12 | 172.16.0.1~172.31.255.254 |
| 192.168.0.0/16 | 192.168.255.254 |
| 169.254.0.0 | 保留地址,用于 DHCP 失效(Windows) |
| 0.0.0.0 | 保留地址,用于 DHCP 失效(Linux) |
(6)HTML
- 超文本标记语言
(7)无线网
- 优势:移动、灵活、低成本、易扩充
- 接入方式:有接入点模式、无接入点模式
- 分类
- 无线局域网:WLAN,802.11,WiFi
- 无线城域网:WMAN,802.16,WiMax
- 无线广域网:WWAN,3G / 4G
- 无线个人网:WPAN,802.15,蓝牙
(8)网络接入技术
- 有线接入
- PSTN:公用交换电话网络
- DDN:数字数据网络
- ISDN:综合业务数字网络
- ADSL:非对称数字用户线路
- HFC:同轴光纤技术
- 无线接入
- WiFi:IEEE 802.11
- 蓝牙:IEEE 802.15
- IrDA:红外
- WAPI
- 3G / 4G
- 3G
- WCDMA
- CDMA 2000
- TD-SCDMA
- 4G
- LTE-Advanced
- WiMAX:802.16m
- 3G
(9)IPv6
- 目的:用于替代 IPv4
- 特点:
- 地址长度为 128 位
- 灵活、简洁的 IP 报文头部格式
- 高安全性
- 支持更多服务类型
- 允许协议演变,可扩展
- 地址分类:
- 单播地址:用于单个接口的标识符
- 任播地址:泛播地址,一组接口的标识符
- 组播地址:用于将数据包同时发送给一组特定的接收者,与 IPv4 组播类似
0x05 系统安全分析与设计
(1)信息系统安全属性
- 保密性:最小授权原则、防暴露、信息加密、物理保密
- 完整性:安全协议、校验码、密码校验、数字签名、公证
- 可用性:综合保障(IP 过滤、业务流控制、路由选择控制、审计跟踪)
- 不可抵赖性:数字签名
(2)对称加密与非对称加密
对称加密
-
原理:发送方将明文通过密钥加密为密文,接收方将密文通过同一密钥解密为明文
graph LR 1[明文]--加密密钥:1234-->密文--解密密钥:1234-->明文 -
缺陷:
- 加密强度不高
- 密钥分发困难
-
常见算法:DES、AES、RC-5、IDEA 等
非对称加密
-
原理:发送方将明文通过公钥加密为密文,接收方通过私钥解密为明文
graph LR 1[明文]--加密公钥:1234-->密文--解密私钥:5678-->明文 -
缺陷:加密速度慢
-
常见算法:RSA、Elgamal、ECC 等
(3)信息摘要
- 信息摘要是原始信息的特征值,当原始信息变化时,信息摘要也随之改变
- 用于验证信息是否被篡改
- 信息摘要采用单向散列函数(单向 Hash 函数)与固定长度的散列值
- 单向指无法通过信息摘要还原出明文
- 常用算法:MD5、SHA 等
- MD5 与 SHA 的散列值分别为 128 位和 160 位,由于 SHA 的密钥长度更长,SHA 安全性较 MD5 更高
(4)数字签名
-
实现不可抵赖性
-
实现方法:
graph LR subgraph A 11[明文]--产生信息摘要-->摘要--加密(数字签名)A的私钥-->12[密文] end 11--传输-->21 12--传输数字签名-->22 subgraph B 21[明文]--产生信息摘要-->产生的摘要<-->解密的摘要 22[密文]--解密(签名验证)A的公钥-->解密的摘要 end
(5)数字证书与 PGP
- 数字证书用于对称加密的密钥传输
- 产生数字证书:发送方将明文用对称密钥加密传输,并将对称密钥通过接收方的公钥加密成数字证书并发送
- 使用数字证书:接收方通过私钥解密数字证书得到对称密钥,再用对称密钥解密密文得到明文
- PGP(优良报名协议)用于消息加密与验证,应用于电子邮件、文件存储等
- PGP 承认的证书格式
- PGP 证书:包含 PGP 版本号,证书持有者的公钥、信息,证书拥有者的数字签名,证书的有效期,密钥首选的对称加密算法
- X.509 证书:包含证书的版本、序列号、有效期、发行商名、主体名,主体公钥信息,签名算法标识,发布者数字签名
例:设计一个邮件系统,要求邮件以加密方式传输,最大附件内容 500MB,发送者不可抵赖,被第三方截获后不可被篡改
- 设发送方 A 的公钥为 Ea、私钥为 Da;接收方 B 的公钥为 Eb、私钥为 Db
- 附件内容采用对称加密,生成密钥 K
- 对称加密密钥 K 通过数字证书传输:A 用 Eb 加密后传输,B 用 Db 解密
- 对附件内容生成信息摘要,防止篡改
- 对信息摘要生成数字签名,保证不可抵赖:A 用 Da 加密后传输,B 用 Ea 解密并与邮件的信息摘要对比
(6)各网络层次的安全保障
- 物理层:隔离与屏蔽
- 数据链路层:链路加密、PPTP、L2TP
- 网络层:防火墙、IPSec
- 传输层:SSL、TLS、SET
- 会话层:SSL
- 表示层:SSL
- 应用层:SSL、PGP、HTTPS
(7)网络威胁与攻击
| 名称 | 说明 |
|---|---|
| 重放攻击 ARP | 截获并重新发送 |
| 拒绝服务攻击 DoS | 合法访问被无条件阻止 |
| 窃听 | 窃听系统中信息资源与敏感信息 |
| 业务流分析 | 监听并统计通信频度、信息流向、总量变化等 |
| 信息泄露 | 信息被泄露或透露给非授权实体 |
| 破坏信息完整性 | 信息被非授权地修改、增删 |
| 非授权访问 | 信息被非授权的实体访问 |
| 假冒 | 欺骗通信系统,冒充合法用户 |
| 旁路控制 | 利用安全漏洞获取非授权的权力 |
| 授权侵犯(内部攻击) | 使用被授予的权力做被允许以外的事 |
| 特洛伊木马 | 恶意程序伪装成或包含在无害的程序 |
| 陷阱门(后门攻击) | 触发预置恶意程序 |
| 抵赖 | 否认自己发布的信息 |
(8)防火墙技术
-
屏蔽路由器:
graph LR 内部网络---屏蔽路由器---Internet -
双穴主机:
graph LR 内部网络---双穴主机---Internet -
屏蔽主机:
graph TB Internet---屏蔽路由器---主机 & 堡垒主机 & 内部网络 主机-.->堡垒主机-.->屏蔽路由器 -
屏蔽子网:
graph LR subgraph DMZ 1[路由器]---被屏蔽子网---2[路由器] 被屏蔽子网---堡垒主机 end Internet---1 2---内部网络
0x06 数据结构与算法基础
参考《数据结构 | 博客园-SRIGT》(Java 版)
0x07 编译原理
(1)编译过程
- 错误分类
- 词法错误:非法字符、关键字或标识符拼写错误
- 语法错误:语法结构错误、if/endif 不匹配、分号缺失
- 语义错误:死循环、零除数、逻辑错误
- 词法分析通过正规式、有限自动机进行
- 中间代码转低级语言代码需要考虑硬件系统结构
(2)文法
-
一个形式文法是一个有序四元组 \(G=(V,T,S,P)\),其中:
- \(V\):非终结符,可理解为占位符
- \(T\):终结符,语言的最终结果,\(V\cap T=\empty\)
- \(S\):起始符,语言开始的符号
- \(P\):产生式,用终结符代替非终结符的规则,形如 \(\alpha\rightarrow\beta\)
-
正则闭包:所有幂的并,\(A^+=A^1\cup A^2\cup A^3\cup\dots\cup A^n\cup\dots\)
- 闭包:正则闭包基础上增加 \(A^0=\{\varepsilon\}\),\(A^*=A^0\cup A^+\)
- 如:\(a^*=\{a,aa,aaa,\dots,\varepsilon\}\),\((ab)^*=\{ab,abab,ababab,\dots,\varepsilon\}\)
- 闭包:正则闭包基础上增加 \(A^0=\{\varepsilon\}\),\(A^*=A^0\cup A^+\)
-
文法分类
类型 别称 说明 对应的自动机 0 型 短语语法 \(G\) 的每条产生式 \(\alpha\rightarrow\beta\) 满足 \(\alpha\) 属于 \(V\) 的正则闭包,且至少含有一个非终结符,而 \(\beta\) 属于 V 的闭包 图灵机 1 型 上下文有关语法 \(G\) 的任何产生式 \(\alpha\rightarrow\beta\) 满足 $ \alpha 2 型 上下文无关语法 \(G\) 的任何产生式 \(A\rightarrow\beta\),\(A\) 为终结符,\(\beta\) 为 \(V\) 的闭包 3 型 正规文法、正规式 \(G\) 的任何产生式 \(A\rightarrow\alpha B\) 或 \(A\rightarrow\alpha\),\(\alpha\) 属于非终结符的闭包,\(A\)、\(B\) 都属于终结符 有限自动机 -
语法推导树应具有以下特征:
- 每个节点都有一个标记,标记是 \(V\) 的一个符号
- 根的标记是 \(S\)
- 若某节点 \(n\) 至少有一个他自己除外的子孙,并且有标记 \(A\),则 \(A\) 肯定在 \(V_N\) 中
- 如果节点 \(n\) 的直接子孙从左到右的次序是节点 \(n_1,n_2,\dots,n_k\),其标记依次为 \(A_1,A_2,\dotsm,A_k\),那么 \(A\rightarrow A_1A_2\dots A_k\) 一定是 \(P\) 中的一个产生式
例:文法 \(G=(\{a,b\},\{S,A\},S,P)\),其中:\(S\rightarrow aAS|a\),\(A\rightarrow SbA|SS|ba\),则句型 \(aabAa\) 的推导树为:
\(\{a,b\}\) 为终结符,\(\{S,A\}\) 为非终结符
根据 \(S\rightarrow aAS\)、\(A\rightarrow SbA\)、\(S\rightarrow a\) 得到如下推导树
graph TB S1[S]---a1[a] & A1[A] & S2[S] A1---S & b & A S---a2[a] S2---a3[a]从左到右的叶子节点依次为 \(aabAa\),符合句型
(3)有限自动机
-
有限自动机可以表示为四元组 \(M=(S,\Sigma,\delta,S_0,Z)\)
- \(S\) 是一个有限集,每个元素为一个状态
- \(\Sigma\) 是一个有穷字母表,每个元素为一个输入字符
- \(\delta\) 是转换函数,是一个单值对照
- \(S_0\) 属于 \(S\),是其唯一的初始态
- \(Z\) 是一个终态集,可空
-
有限自动机可以通过状态转换图表示
-
如:\(DFA=(\{S,A,B,C,f\},\{1,0\},\delta,S,\{f\})\),其中:\(\delta(S,0)=B,\delta(S,1)=A,\delta(A,0)=f,\delta(A,1)=C,\delta(B,0)=C,\delta(B,1)=f,\delta(C,0)=f,\delta(C,1)=f\)
graph LR S--1-->A--0-->f((f)) A--1-->C B--0-->C --0,1-->f S--0-->B--1-->f
-
例:有限自动机如下,A 是初态,C 是终态,串 0000、1111、0101、1010 中该自动机可识别的是:
graph LR A--1-->A--0-->B--0-->B--1-->C C--1-->A C--0-->B
- A 的出度为 2,除自反外,串中至少有一个 0 时才存在可能,排除 1111
- C 的入度为 1,对应地,串的最后一位为 1 时才存在可能,排除 0000、1010
- 因此,该自动机可识别 0101(ABCBC)
(4)※ 正规式
-
描述程序语言单词的表达式,对于字母 \(\Sigma\),其上的正规式及其表示的正规集可以递归定义如下:
-
\(\varepsilon\) 是一个正规式,其表示集合 \(L(\varepsilon)=\{\varepsilon\}\)
-
若 \(a\) 是 \(\Sigma\) 上的字符,则 \(a\) 是一个正则式,表示的正规集 \(L(a)=\{a\}\)
-
若正规式 \(r\) 和 \(s\) 分别表示正规集 \(L(r)=L(s)\),则:
正规式 表示集合 $r s$ \(r\cdot s\) \(L(r)L(s)\) \(r^*\) \((L(r))^*\) \((r)\) \(L(r)\)
-
-
正规式一般由字母、或、连接、闭包运算符组成,或者为空
- 闭包运算符 \(*\) 具有最高优先级,连接运算符 \(\cdot\) 次之,或运算符 \(|\) 最低
例:文法 \(G[S]\) 如下:\(G[S]:\ S\rightarrow aA|bB,\ A\rightarrow bS|b,\ B\rightarrow aS|a\)
- 串 \(ababab\)、\(bababa\)、\(abbaab\)、\(babba\) 中无法识别的是:
- \(ababab\):\(S\rightarrow aA,\ A\rightarrow bS\)
- \(bababa\):\(S\rightarrow bB,\ B\rightarrow aS\)
- \(abbaab\):\(S\rightarrow aA,\ A\rightarrow bS,\ S\rightarrow bB,\ B\rightarrow aS\)
- \(babba\):无法识别
- 正规式 \((a|b)^*\)、\((ab)^*\)、\((ab|ba)^*\)、\((ab)^*(ba)^*\) 中,该文法对应的正规式为:
- 根据上一问的结果,可得 \((ab|ba)^*\)
(5)※ 表达式
- 对于上述的树,三种表达式的结果为:
- 前缀表达式:+ab(中左右)
- 中缀表达式:a+b(左中右)
- 后缀表达式:ab+(左右中)
例:表达式 \((a-b)*(c+5)\) 的后缀式为:\(ab-c5+*\)
(6)※ 函数调用
-
函数的组成包括:
int function(float x) {}int:返回值类型function:过程名float x:形式参数(列表){ }:过程体
-
函数的调用分为:
传递方式 主要特点 传值调用 形参取的是实参的值,形参的改变不会导致调用点所传的实参值发生改变 传址调用
引用调用形参取的是实参的地址,形参的改变会导致调用点所传的实参值发生改变
(7)常见程序语言特点
- Fortran:科学计算,执行效率高
- Pascal:用于教学,表达能力强
- Lisp:用于人工智能,函数式程序语言,符号处理
- Prolog:用于逻辑推理,简洁,表达能力,数据库和专家系统
- C:指针操作强,高效
- C++:面向对象,高效
- Java:面向对象,中间代码,跨平台
- C#:面向对象,中间代码,.Net 平台
0x08 法律法规
(1)概述
- 相关法律法规:著作权法、计算机软件保护条例、商标法、专利法
- 知识产权包括:著作权及邻接权、专利权、工业品外观设计权、商标权、地理标志权、集成电路布图设计权
(2)保护期限
| 客体类型 | 权力类型 | 保护期限 |
|---|---|---|
| 公民作品 | 署名、修改、保护作品完整权 | 无 |
| 发表、使用、获得报酬权 | 终生与死后 50 年 | |
| 单位作品 | 发表、使用、获得报酬权 | 首次发表后 50 年,未发表则不保护 |
| 公民软件产品 | 署名、修改权 | 无 |
| 发表、复制、发行、出租、信息网络传播、翻译、使用许可、获得报酬、转让权 | 终生与死后 50 年,若合作则以最长寿的死后 50 年 | |
| 单位软件产品 | 发表、复制、发行、出租、信息网络传播、翻译、使用许可、获得报酬、转让权 | 首次发表后 50 年,未发表则不保护 |
| 注册商标 | 10 年,注册人死亡或倒闭 1 年后,未转移则可注销,满 6 个月必须续注 | |
| 发明专利权 | 申请日开始 20 年 | |
| 实用新型和外观设计专利权 | 申请日开始 10 年 | |
| 商业秘密 | 不定,公开后不保护 | |
(3)知识产权所有人
| 情况说明 | 判断说明 | 归属 | |
|---|---|---|---|
| 作品 | 职务作品 | 利用单位的物质技术条件进行创作,并由单位承担责任 | 除著名权,其他著作权归单位 |
| 有合同约定,其著作权属于单位 | |||
| 其他 | 作者拥有著作权,单位有权在其业务范围内优先使用 | ||
| 软件 | 属于本职工作中明确规定的开发目标 | 单位享有著作权 | |
| 属于从事本职工作获得的结果 | |||
| 使用了单位资金、专用设备、未公开的信息等物质、技术条件,并由单位或组织承担责任的软件 | |||
| 专利权 | 本职工作中作出的发明创造 | 单位享有专利 | |
| 履行本单位交付的本职工作之外的任务所作出的发明创造 | |||
| 离职、退休或调动工作 1 年后,与原单位工作相关 | |||
| 作品软件 | 委托创作 | 有合同约定,著作权归委托方 | 委托方 |
| 合同中未约定著作权归属 | 创作方 | ||
| 合作开发 | 只进行组织、提供咨询意见、物质条件、或进行其他辅助工作的 | 不享有著作权 | |
| 共同创作的 | 共同享有,按人数比例 成果可分割的,可分开申请 |
||
| 商标 | 谁先申请谁拥有(除知名商标非法抢注) 同时申请,根据谁先使用(需提供证据) 无法提供证据,协商归属,协商无效时使用抽签 |
||
| 专利 | 谁先申请谁拥有 同时申请则协商归属,不能同时驳回 |
||
(4)侵权判定
- 中国公民、法人、其他组织的作品,无论是否发表,都享有著作权
- 开发软件所用的思想、处理过程、操作方法、数学概念不受保护
- 著作权法不适用于:
- 法律、法规,国家机关的决议、决定、命令等具有立法、行政、司法性质的文件,及其官方正式译文
- 时事新闻
- 历法、通用数表、通用表格和公式
| 侵权 | 不侵权 |
|---|---|
| 未经许可发表他人作品 未经合作作者许可,将与他人合作创作的作品当作自己单独创作的作品发表 未参加创作,在他人作品上署名 歪曲、篡改他人作品 使用他人作品未支付报酬 未经出版者许可,使用其出版图书、期刊的版式设计 |
个人学习、研究、欣赏 适当引用 公开演讲内容 用于教学或科学研究 复制馆藏作品 免费表演他人作品 室外公共场所艺术品临摹、绘画、摄影、录像 将汉语作品译成少数民族语言作品或盲文出版 |
(5)标准
分类
- 国际标准:ISO、IEC 等
- 国家标准:GB(中国)、ANSI(美国)、BS(英国)、JIS(日本)
- 区域标准:PASC(太平洋)、CEN(欧洲)、ASAC(亚洲)、ARSO(非洲)
- 行业标准:GJB(中国军用)、MIT-S(美国军用)、IEEE(电气电子工程师学会)
- 地方标准
- 企业标准
- 项目规范
编号
- 国际、外国标准编号:标准代号+专业类号+顺序号+年代号
- 中国:
- 强制标准:GB
- 推荐标准:GB/T
- 指定标准:GB/Z
- 实物标准:GSB
- 行业:汉语拼音大写字母
- 电子行业:SJ
- 地方:DB+省级行政区划代码前两位
- 企业:Q+企业代号
0x09 多媒体
(1)概念
音频
- 声音的带宽:声波频率范围
- 人耳:20Hz~20kHz
- 说话:300Hz~3400Hz(4k)
- 采样:将声音的模拟信号转换为数字信号
- 采样频率:一定时间内的采样次数
- 应为声音最高频率的两倍,如:固话为 8k
- 采样精度:频率划分的密度
- 采样频率:一定时间内的采样次数
图像
- 亮度:图像明亮程度
- 色调:图像颜色偏向
- 饱和度:图像色彩艳丽程度
- 彩色空间:
- RGB:三原色光
- YUV:用于彩色电视兼容黑白电视
- CMY(CMYK):印刷
- Cyan:艳青
- Magenta:洋红
- Yellow:黄色
- K:黑色
- HSV(HSB):艺术
媒体
- 感觉媒体:人们接触信息的感觉形式
- 视、听、触、嗅、味
- 表示媒体:信息的表现形式
- 文字、音频、图形、图像、动画、视频等
- 显示(表现)媒体:表现和获取信息的物理设备
- 输入:键盘、鼠标、麦克风等输入设备
- 输出:显示器、打印机、音响等输出设备
- 存储媒体:存储信息的物理设备
- 磁盘、光盘、内存等
- 传输媒体:传输信息的物理设备
- 电缆、光纤、交换设备等
(2)容量计算
- 图像:
- 像素、位数:\(横向像素\times纵向像素\times单像素位数\div单字节位数\)
- 如:图像 \(640\times480\),像素 16 位,则容量为:\(640\times480\times16\div8=614400B\)
- 像素、色数:\(横向像素\times纵向像素\times\log_2(色数)\div单字节位数\)
- 如:图像 \(640\times480\),256 色,则容量为:\(640\times480\times\log_2(256)\div8=307200B\)
- 像素、位数:\(横向像素\times纵向像素\times单像素位数\div单字节位数\)
- 音频:\(采样频率\times量化\div采样位数\times声道数\div单字节位数\)
- 如:采样频率 44.1kHz,样本精度 16bit,双声道立体声,则未压缩的数据传输率为:\(\frac {44.1kHz\times16bit\times2}{1s}=1411.2kb/s\)
- 视频:\((每帧图像容量\times每秒帧数+音频容量)\times时间\)
- 如:每帧 6.4MB,帧速率 30fps,则 10s 的视频信息的原始数据量为:\((6.4MB\times30)\times10=1920MB\)
(3)常见多媒体标准
- JPEG
- 有损压缩
- 离散余弦算法
- JPEG-2000
- 有损&无损
- 高压缩比
- 小波变换算法
- 应用:医学图像
- MPEG-1
- 离散余弦算法
- 应用:VCD、MP3
- MPEG-2
- 离散余弦算法、哈夫曼
- 应用:DVD、AAC、有线/卫星电视
- MPEG-4:多媒体传输集成框架
- 特点:强交互性、具备数码权限管理
- 应用:无线通信、网络应用、可视电话
- MPEG-7:多媒体内容描述接口
- 特点:具备描述功能
- MPEG-21:标准集成
(4)数据压缩技术
- 数据压缩的目的是减少冗余
- 冗余包括:空间(几何)、时间、视觉、信息熵、结构、知识
- 有损压缩(熵压缩法)
- 预测编码(运动补偿、自适应、线性、非线性预测、\(\delta\) 调制)
- 变换编码(KLT、DCT、ADCT、DWT)
- 基于模型编码(分形、轮廓、识别合成编码)
- 直接影射(矢量量化、神经网络)
- 无损压缩(冗余压缩法、熵编码法)
- 变长编码
- 行程编码
- 算术编码
0x0A 软件工程
(1)软件开发模型
瀑布模型 SDLC
- 阶段分割
- 定义阶段:软件计划、需求分析
- 开发阶段:软件设计、程序编码、软件测试
- 维护阶段:运行维护
- 缺点:无法灵活应对需求的变化
原型模型、演化模型、增量模型
- 原型法:通过预先制作简易的系统,向客户进行演示,从而清楚客户的需求
- 主要应用于需求分析阶段,解决需求不明确
- 演化模型:基于原型不断演化和改进,得到最终产品
- 逐步完善
- 增量模型:结合原型与瀑布模型,先完成核心需求,并将此作为原型逐步增加功能,得到最终产品
- 逐步新增
螺旋模型
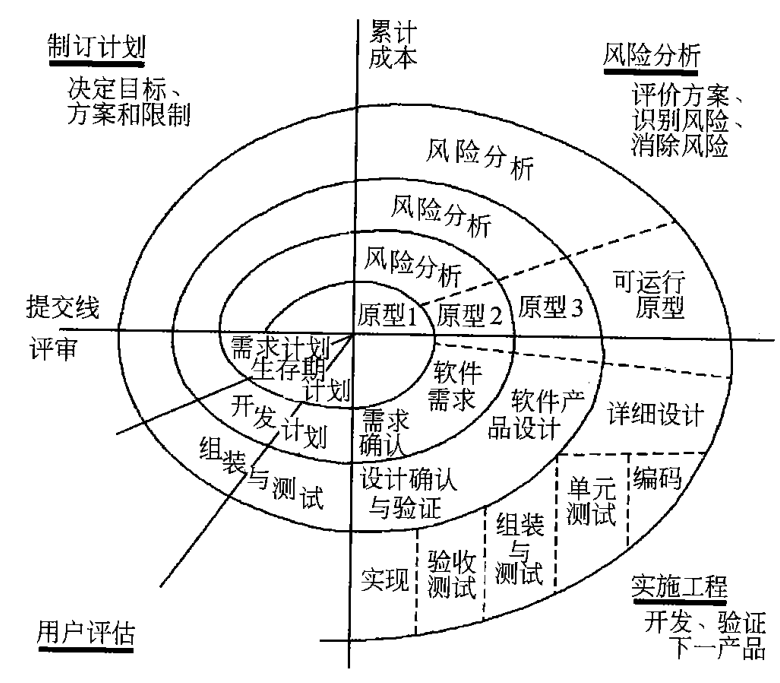
- 主要特征:引入了风险分析
V 模型
- 与瀑布模型区别在于,强调测试的重要性
- 需求分析期间准备验收测试、系统测试的计划;概要设计期间准备集成测试的计划;详细设计期间准备单元测试的计划
喷泉模型
- 面向对象的开发模型
- 迭代
- 无间隙
构建组装模型 CBSD
- 优势:提高软件开发的复用性,能够降本增效
- 构件标准:CORBA、COM/DCOM/COM+、EJB
快速开发模型 RAD
- 结合瀑布开发模型与构件组装模型
(2)软件开发方法
统一过程开发方法 UP
- 特点:
- 以用例为驱动
- 以架构为核心
- 迭代和增量
- 初始阶段:
- 确定项目的范围和边界
- 识别系统的关键用例
- 展示系统的候选架构
- 估计项目费用和时间
- 评估项目风险
- 细化阶段:
- 分析系统问题领域
- 建立软件架构基础
- 淘汰最高风险元素
- 构建阶段:
- 开发剩余的构件
- 构件组装与测试
- 交付阶段:
- 进行 \(\beta\) 测试
- 制作发布版本
- 用户文档定稿
- 确认新系统
- 培训与调整产品
敏捷开发方法
- 敏捷开发方法包括:自适应开发、水晶方法、特征驱动开发、SCRUM、极限编程
- 适用于小型项目
- 基本原则:短平快会议、小型版本发布、较少的文档、合作为重、客户直接参与、自动化测试、适应性计划调整、结对编程、测试驱动开发、持续集成、重构
- 价值观:沟通、简单、反馈、勇气
- 原则:快速反馈、简单性假设、逐步修改、提倡更改、优质工作
- 最佳实践:计划游戏、小型发布、隐喻、简单设计、测试先行、重构、结对编程、集体代码所有制、持续集成、周作 40h、现场客户、编码标准
信息系统开发方法
- 结构化法
- 用户至上
- 严格区分工作阶段,每阶段有任务和成果
- 强调系统开发过程的整体性和全局性
- 系统开发过程工程化,文档资料标准化
- 自顶向下,逐步分解
- 原型法
- 适用于需求不明确
- 分为:抛弃式原型、演化式原型
- 面向对象方法
- 高复用
- 建立全面、合理、统一的模型
- 阶段分为:分析、设计、实现
- 面向服务方法
- 主要抽象级别:操作、服务、业务流程
- 层次:
- 基础设计层:底层服务构件
- 应用结构层:服务间接口、服务级协定
- 业务组织层:业务流程建模、服务流程编排
- 服务建模的阶段分为:服务发现、服务规约、服务实现
(3)需求开发
- 需求分类:
- 方式一:
- 业务需求
- 用户需求
- 系统需求
- 功能需求、性能需求、设计约束
- 方式二(QFD):
- 基本需求、期望需求、兴奋需求
- 方式一:
- 需求获取方法:
- 收集资料、联合需求计划、用户访谈、书面调查、情节串联板、现场观摩、参加业务实践、阅读历史文档、抽空调查
(4)结构化设计
-
结构化设计分为概要设计与详细设计
-
设计原则:
-
自顶向下、逐步求精
-
信息隐蔽
-
模块独立(高内聚、低耦合、复杂度)
-
内聚
类型 说明 功能内聚 完成单一功能,各部分协同工作,缺一不可 顺序内聚 处理元素相关,且必须顺序执行 通信内聚 所有处理元素集中在一个数据结构的区域上 过程内聚 处理元素相关,且必须按特定顺序执行 瞬时内聚
时间内聚所包含的任务必须在同一时间间隔内执行 逻辑内聚 完成逻辑上相关的一组任务 偶然内聚
巧合内聚完成一组无关系或松散关系的任务 -
耦合
类型 说明 非直接耦合 两模块无直接关系,其联系通过主模块的控制和调用来实现 数据耦合 一组模块借助参数表传递简单数据 标记耦合 一组模块通过参数表传递记录信息 控制耦合 模块间传递的信息中包含用于控制模块内逻辑的信息 外部耦合 一组模块都访问同一全局简单变量,且不通过参数表传递该全局变量的信息 公共耦合 多模块都访问同一公共数据环境 内容耦合 一个模块直接访问另一模块内的数据
一个模块不通过正常入口转到另一模块内
两个模块有部分代码重叠
一个模块有多入口
-
-
-
实现方法:
- 保持模块大小适中
- 尽可能减少调用的深度
- 多扇入,少扇出
- 单入口,多出口
- 模块的作用域应在模块内
- 功能应可预测
(5)软件测试
https://www.bilibili.com/video/BV17K4y1w7wH?t=0.6&p=146
原则
- 尽早且不断地进行测试
- 避免测试自己设计的程序
- 充分考虑有效和无效、合理和不合理的数据
- 修改后应进行回归测试
- 未发现错误数与已发现错误数成正比
类型
- 动态测试
- 黑盒测试
- 灰盒测试
- 白盒测试
- 静态测试
- 桌前检查
- 代码走查
- 代码审查
用例设计
-
黑盒测试
- 等价类划分
- 边界值分析
- 错误推测
- 因果图
-
白盒测试
- 基本路径测试
- 循环覆盖测试
- 逻辑覆盖测试
逻辑覆盖测试包括:语句覆盖、判断覆盖、条件覆盖、条件判定覆盖、修正的条件判定覆盖、条件组合覆盖、点覆盖、边覆盖、路径覆盖
(6)测试阶段
-
测试流程:
graph LR 测试用例-->驱动模块 & 被测模块-->测试结果 subgraph 被测模块-->1[桩模块] & 2[桩模块] & 3[桩模块] end -
测试阶段包括:
graph LR 单元测试-->集成测试-->确认测试---系统测试- 以上测试阶段的顺序称为 “冒烟测试”
- 确认测试与系统测试的顺序和取舍根据实际情况分析
-
单元测试通常用于测试模块的功能
-
集成测试通常用于测试模块之间的接口组装,组装方法包括:
- 一次性组装
- 增量式组装:自顶向下、自底向上、混合式
-
确认测试通常用于测试软件是否按照需求完成,包括:
- 内部确认测试、Alpha 测试、Beta 测试、验收测试
-
集成测试通常用于测试软硬件以及网络之间的集成,包括:
- 恢复测试、安全性测试、压力测试、性能测试、可靠性测试、可用性测试、可维护性测试、安装测试
性能测试包括:负载测试、强度测试、容量测试
(7)McCabe 复杂度
-
McCabe 复杂度公式为:\(V(G)=E-N+2P\)(有向图 \(G\) 的环路复杂度)
- \(E\):控制流图中边的数量
- \(N\):节点数
- \(P\):连通分量数,通常为 \(1\),此时公式简化为 \(V(G)=E-N+2\)
-
计算前需要将流程图转换为控制流图,对与缺失的节点需要补充
-
举例:流程图为
graph TB 1-->2{2}-->3{3}-->4 2 & 3 & 4 -->7{7}-->9 & 10{10}-->12 10-->9此时,控制流图为
graph TB 1((1))-->2((2))-->3((3)) & 6((6)) 3-->4((4)) & 5((5)) 4-->5-->6-->7((7))-->8((8)) & 10((10)) 8-->9((9))-->11((11))-->12((12)) 10-->8 & 11
-
(8)系统运行与维护
- 软件维护:需要提供软件支持的全部活动
- 交付前完成的活动:交付后运行的计划和维护计划等
- 交付后完成的活动:软件修改、培训、帮助资料等
- 软件的可维护性主要考虑以下几点:
- 易分析性、易改变性、稳定性、易测试性
- 软件的维护类型包括:
- 改正性维护、适应性维护、完善性维护、预防性维护
(9)软件过程改进 CMMI
-
软件的开发成熟度模型(Capability Maturity Model for software,简称 CMM)
- CMMI 在 CMM 基础上进行了扩充
-
组织能力成熟度
等级(阶段式) 过程域 已管理级 需求管理、项目计划、配置管理、项目监督与控制、供应商合同管理、度量和分析、过程和产品质量保证 已定义级 需求开发、技术解决方案、产品集成、验证、确认、组织级过程焦点、组织级过程定义、组织级培训、集成项目管理、风险管理、集成化的团队、决策分析和解决方案、组织级集成环境 定量管理级 组织级过程性能、定量项目管理 优化级 组织级改革与实施、因果分析和解决方案 -
软件过程能力
分组(连续式) 过程域 过程管理 组织级过程焦点、组织级过程定义、组织级培训、组织级过程性能、组织级改革与实施 项目管理 项目计划、项目监督与控制、供应商合同管理、集成项目管理、风险管理、集成化团队、定量项目管理 工程 需求管理、需求开发、技术解决方案、产品集成、验证、确认 支持 配置管理、度量和分析、过程和产品质量保证、决策分析和解决方案、组织级集成环境、因果分析和解决方案
(10)项目管理
- 项目管理包括:范围管理、时间管理、成本管理、质量管理、人力资源管理、沟通管理、风险管理、采购管理、整体管理
- 进度安排的常用图形描述方法包括:
- Gantt 图:不能清晰描述任务之间的逻辑关系
- PERT 图:可以给出哪些任务完成后才能开始另一些任务
- 风险主要指损失或伤害的可能性
- 风险包括:项目风险、技术风险、商业风险
- \(风险曝光度=风险出现概率\times风险可能造成的损失\)
0x0B 面向对象系统设计
(1)概述
- 对象:对现实世界中事物或概念的抽象表示,封装了数据(属性)和可以操作这些数据的行为(方法),是类的具体实例
- 类:定义对象的蓝图或模板,描述了一组具有相同属性和方法的对象的共同特征和行为
- 如:实体类、边界类、控制类
- 抽象:通过提取事物的核心特征和行为,忽略细节,从而创建出通用的类或接口来表示一类对象的共性
- 封装:将对象的属性和方法组合在一起,隐藏对象的内部实现细节,仅通过定义好的接口(如方法)与外部交互
- 继承:允许一个类(子类)继承另一个类(父类)的属性和方法,从而实现代码复用和类的层次化组织
- 泛化:继承的一种表现形式,子类是父类的一种更具体的实现
- 多态:同一个接口可以被不同的实例以不同的方式实现
- 接口:定义了一组方法的签名(即方法的名称、参数类型和返回类型),但不提供方法的具体实现
- 消息:一个对象向另一个对象发送的请求,用于调用目标对象的方法或访问其属性
- 组件:封装了特定的功能或行为,并通过定义好的接口与其他组件进行交互
- 模式:描述了一种经过验证的、有效的设计方法或架构
- 复用:重复使用已有的代码、组件、模块或设计思想
(2)设计原则
- 单一职责原则:设计目的单一的类
- 开闭原则:对扩展开发,对修改封闭
- 里氏替换原则:子类可以替换父类
- 依赖倒置原则:依赖抽象而非具体实现,针对接口编程而非实现
- 接口隔离原则:多个专门的接口
- 合成复用原则:选择组合而非继承
- 迪米特原则:一个对象尽少对其他对象的了解
(3)设计模式
概念
- 架构模式:软件设计中的高层决策,反映了开发软件系统过程中所作的基本设计决策
- 如:C/S 架构
- 设计模式:主要关注软件系统的设计,与具体的实现语言无关
- 惯用法:关注软件系统的设计与实现,实现时通过某种特定的程序设计语言来描述构件与构件之间的关系
分类
有下划线的模式表示可以是类模式或对象模式,其他仅表示对象模式
- 创建型模式
- 工厂方法模式:定义创建对象的接口,由子类决定实例化哪个类
- 抽象工厂模式:创建相关或依赖对象的家族,而不需明确指定具体类
- 原型模式:通过复制现有实例来创建新实例,而不是通过新建实例
- 单例模式:确保一个类只有一个实例,并提供一个全局访问点
- 构建器模式:逐步构建一个复杂的对象,允许用户只通过指定复杂对象的类型和内容就能构建它们
- 结构型模式
- 适配器模式:将一个类的接口转换成客户端所期望的另一种接口,使原本不兼容的类可以合作(转换接口)
- 桥接模式:将抽象与实现解耦,让它们可以独立变化(继承树拆分)
- 组合模式:将对象组合成树形结构以表示“部分-整体”的层次结构,使用户对单个对象和组合对象的使用具有一致性(树形目录结构)
- 装饰器模式:动态地给对象添加额外的职责,而不改变其结构(附加职责)
- 外观模式:为子系统中的一组接口提供一个一致的高层接口,使子系统更容易使用(对外统一接口)
- 享元模式:通过共享来高效地支持大量细粒度的对象
- 代理模式:为其他对象提供一种代理,以控制对这个对象的访问
- 行为型模式
- 职责链模式:使多个对象都有机会处理请求,从而避免请求的发送者和接收者之间的耦合关系(传递职责)
- 命令模式:将请求封装为一个对象,从而使用户可用不同的请求对客户进行参数化(可撤销的日志记录)
- 解释器模式:定义语言的文法规则,并提供解释器来解析语言中的句子
- 迭代器模式:顺序访问一个聚合对象中的各个元素,而不暴露其内部的表示
- 中介者模式:通过中介者对象协调多个对象的交互,减少对象间的直接耦合(间接引用)
- 备忘录模式:在不破坏封装性的前提下,捕获一个对象的内部状态,并在该对象之外保存这个状态
- 观察者模式:对象间的一对多依赖关系,当一个对象状态改变时,所有依赖于它的对象都会得到通知并自动更新
- 状态模式:允许一个对象在其内部状态改变时改变其行为,对象看起来好像修改了其类(状态作为类)
- 策略模式:定义一系列算法,把它们一个个封装起来,并使它们可互换,让算法的变化独立于使用算法的客户(多方案切换)
- 模板方法模式:定义一个操作中的算法骨架,将一些步骤延迟到子类中实现
- 访问者模式:为一个对象结构中的对象添加新的能力,而不改变对象的结构
0x0C 数据流图
(1)基本概念
| 元素 | 说明 | 图元 |
|---|---|---|
| 数据流 | 由一组固定成分的数据组成,表示数据的流向 每个数据流通常有一个合适的名词,反映数据流的含义 |
箭头 |
| 加工 | 描述输入数据流到输出数据流之间的变换 | 圆、圆角矩形 |
| 数据存储 (文件) |
表示暂时存储的数据 流向文件的数据表示写文件,流出的表示读文件 |
平行线、无右边框矩形 |
| 外部实体 | 只存在于软件系统外的人员或组织 | 矩形 |

(2)分层

-
结合上述数据流图:
-
顶层图:
graph LR 仓库管理员--事务-->采购子系统--订货报表-->采购员 -
0 层图:
graph LR 仓库管理员--事务-->库存管理 订货管理--订货报表-->采购员 D1库存清单<-->库存管理 库存管理--订货信息-->D2订货信息--订货信息-->订货管理 -
1 层图:
-
(3)数据字典
| 符号 | 说明 | 举例 |
|---|---|---|
| \(=\) | 被定义为 | |
| \(+\) | 与 | \(x=a+b\) 表示 \(x\) 由 \(a\) 和 \(b\) 组成 |
| \([\dots,\dots]\) 或 \([\dots|\dots]\) | 或 | \(x=[a,b]\) 表示 \(x\) 由 \(a\) 或 \(b\) 组成 |
| \(\{\dots\}\) | 重复 | \(x=\{a\}\) 表示 \(x\) 由 0 个或多个 \(a\) 组成 |
| \((\dots)\) | 可选 | \(x=(a)\) 表示 \(x\) 可以含有 \(a\) 或不含有 |
(4)平衡原则
- 父图与子图平衡:在分层中,子图(如 \(L0\) 层图)中输入和输出的数据流必须与父图(如顶层图)中的对应数据流保持一致
- 子图内平衡:任一加工必须既有输入也有输出
- 黑洞:只有输入
- 奇迹:只有输出
0x0D 数据库设计
(1)设计过程
- 理论依据:
- 需求分析、概念结构设计:数据处理要求、当前和未来的数据要求
- 逻辑结构设计:数据处理要求、转换规则、规范化理论、DBMS 特性、用户的数据模型
- 物理设计:数据处理要求、DBMS 特性、硬件特性、OS 特性、视图、完整性约束、应用处理说明书
- 应用工具与产出:
- 需求分析:数据流图、数据字典、需求说明书
- 概念结构设计:E-R 模型
- 逻辑结构设计:关系模式
(2)E-R 模型
- 实体间联系类型:一对一、一对多、多对多
- E-R 图向关系模型转换的基本原则:实体和联系分别转换成关系,属性转换成相应关系的属性
0x0E UML
- UML 建模包括:用例图、类图与对象图、顺序图、活动图、状态图、通信图、构件图
(1)用例图
- 主要展示包含关系
<<include>>、扩展关系<<extend>>、泛化关系 - 图例:
- 人:参与者
- 椭圆:用例
(2)类图与对象图
-
多重度:
1:表示一个集合中的一个对象对应另一个集合中一个对象0..*:表示一个集合中的一个对象对应另一个集合中零个或多个对象(可以不对应)1..*:表示一个集合中的一个对象对应另一个集合中一个或多个对象(至少对应一个)*:表示一个集合中的一个对象对应另一个集合中多个对象
-
关系表示:
-
虚线实心三角箭头:依赖关系
-
实线空心三角箭头:泛化关系
-
虚线空心三角箭头:实现关系
-
实线实心菱形箭头:组合关系
-
实线空心菱形箭头:聚合关系
组合关系与聚合关系统称关联关系
-
(3)顺序图
图例:
- 顶部矩形:对象
- 竖向虚线:生命线
- 实线箭头:调用
- 上方文字:消息
- 虚线箭头:返回
- 叉:生命线结束
(4)活动图
- 类似程序流程图
- 图例:
- 实心圆:开始节点
- 圆角矩形:活动节点
- 菱形:判断节点
- 粗线:散发/归拢分支
- 实心圆环:结束节点
(5)状态图
图例:
- 实心圆:开始节点
- 圆角矩形:状态节点
- 箭头始发侧为源状态,结束侧为目标状态
- 箭头:转换
- 上方文字格式:
触发条件[监护条件]/动作
- 上方文字格式:
- 实心圆环:结束节点
(6)通信图
- 与顺序图类似,又称协作图
- 图例:
- 矩形:通信节点
- 实线箭头:调用
- 虚线箭头:返回
0x0F 算法
参考《JavaScript 数据结构与基础算法 | 博客园-SRIGT》第 0x05 至 0x07 章的内容

 浙公网安备 33010602011771号
浙公网安备 33010602011771号