WebGPU
0x01 概述
(1)简介
-
WebGPU 使 Web 开发人员能够使用底层系统的 GPU(图形处理器)进行高性能计算并绘制可在浏览器中渲染的复杂图形
- 作为 WebGL 的继任者,为现代 GPU 提供更好的兼容、支持更通用的 GPU 计算、更快的操作以及能够访问到更高级的 GPU 特性
-
WebGPU 解决了 WebGL 的一些基本问题,问题包括:
- 不能兼容新一代原生 GPU API(如 Direct3D 12、Metal、Vulkan)
- 不能很好地处理通用 GPU 的计算
- 3D 图形 APP 需求逐渐提高
-
通用模型:设备 GPU 和运行 WebGPU 的 Web 浏览器之间有多个抽象层
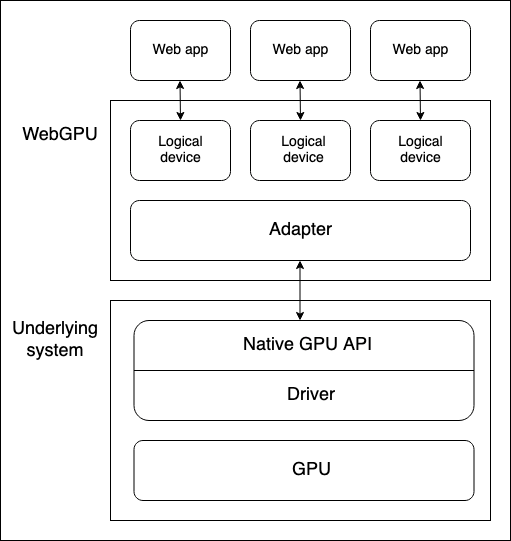
- 设备 GPU 类型包括:集成显卡、独立显卡、软件 GPU
-
GPU 权限检测与访问
if (!navigator.gpu) throw new Error("不支持 WebGPU"); const adapter = await navigator.gpu.requestAdapter(); if (!adapter) throw new Error("无法请求 WebGPU 适配器"); const device = await adapter.requestDevice(); if (!device) throw new Error("无法请求 WebGPU 设备"); console.log("WebGPU 初始化成功", device);- Chrome 113 Beta 版开始默认支持 WebGPU
-
相关文档:
(2)使用流程
- 获取 GPU 适配器
- 获取 GPU 设备
- 创建画布
- 获取画布像素格式
- 关联画布
- 创建着色器
- 创建顶点着色器
- 进行几何处理(图元装配)
- 光栅化
- 片元着色器
- 渲染
- 命令编码
- 打开通道
- 绘制
- 完成编码
- 提交命令
(3)环境准备
-
浏览器:Google Chrome 137
-
IDE:VSCode + 插件
-
index.html
<!DOCTYPE html> <html> <head> <meta charset="UTF-8" /> </head> <body> <canvas id="canvas" width="500" height="500"></canvas> <script type="module" src="./script.js"></script> </body> </html> -
script.js
(async function () { // 检查浏览器是否支持 WebGPU if (!navigator.gpu) throw new Error("不支持 WebGPU"); // 请求 WebGPU 适配器 const adapter = await navigator.gpu.requestAdapter(); if (!adapter) throw new Error("无法请求 WebGPU 适配器"); // 请求 WebGPU 设备 const device = await adapter.requestDevice(); if (!device) throw new Error("无法请求 WebGPU 设备"); // 获取 canvas 和 context const canvas = document.querySelector("canvas"); // 获取 canvas 元素 const context = canvas.getContext("webgpu"); // 获取 WebGPU 上下文 const format = navigator.gpu.getPreferredCanvasFormat(); // 获取 canvas 的像素格式 // 配置 canvas context.configure({ device, // WebGPU 渲染器适用 GPU 设备对象 format, // canvas 的最佳格式 }); })();
0x02 从零渲染
(1)坐标系与投影
-
WebGPU 坐标系在 Canvas 画布中,采用标准化设备坐标系(NDC)
- 坐标原点:画布中央
- \(x\) 轴:水平,正方向向左
- 取值范围为 \([-1,\ 1]\),画布左边界为 -1,画布右边界为 1
- \(y\) 轴:竖直,正方向向上
- 取值范围为 \([-1,\ 1]\),画布下边界为 -1,画布上边界为 1
- \(z\) 轴:垂直于画布,正方向向内
- 取值范围为 \([0,\ 1]\),画布表面为 0,画布一定深度为 1
-
投影指 3D 空间的物体被位于且垂直于 \(z\) 轴上的面光源投影到 \(XOY\) 面的结果
(2)顶点缓冲区与渲染管线
-
顶点缓冲区:在内存(显存)中规划用于存储顶点数据的空间
(async function () { // ... // 创建顶点数据类型化数组 const vertexArray = new Float32Array([ 0.0, 0.0, 0.0, // 顶点 1 x,y,z 1.0, 0.0, 0.0, // 顶点 2 x,y,z 0.0, 1.0, 0.0, // 顶点 3 x,y,z ]); // 创建顶点缓冲区 const vertexBuffer = device.createBuffer({ // 缓冲区字节长度 size: vertexArray.byteLength, // 顶点数据字节长度 // 顶点缓冲区用途 usage: GPUBufferUsage.VERTEX | // 顶点数据缓冲区 GPUBufferUsage.COPY_DST, // 顶点数据拷贝目的地 }); // 将顶点数据写入 GPU 显存缓冲区,0 表示写入的起始位置 device.queue.writeBuffer(vertexBuffer, 0, vertexArray); })(); -
渲染管线:提供 3D 渲染不同功能单元
(async function () { // ... // 创建渲染管线 const pipeline = device.createRenderPipeline({ layout: "auto", // 渲染管线布局 vertex: { // 顶点着色器 buffers: [ { arrayStride: 3 * 4, // 每组顶点数据间隔字节数,3 个分量 4 个字节 attributes: [ { // 顶点位置属性 shaderLocation: 0, // GPU 显存上顶点缓冲区标记的存储位置 offset: 0, // 顶点数据偏移量 format: "float32x3", // 顶点数据格式,每个顶点数据需要 3 个 32 浮点数 }, ], }, ], }, }); })();
(3)着色器语言 WGSL
a. 概述
-
WGSL:Web Gpu Shading Language
- WGSL 语法与 TypeScript、C 等静态语言相似,但有自身的特殊性
-
相关文档:
- W3C:https://www.w3.org/TR/WGSL/
- 中文版(Orillusion 团队翻译):https://www.orillusion.com/zh/wgsl.html
-
常用数据类型
符号 数据类型 bool布尔 u32无符号整数 i32有符号整数 f1616 位浮点数 f3232 位浮点数 - 参与运算的变量必须保持同数据类型
-
每个语句必须以
;结尾 -
WGSL 代码在 JavaScript/TypeScript 中以字符串的形式使用,通常采用 ES6 语法提供的模板字符串
``
b. 基本语法
-
var:声明变量var a: u32; a = 2; var b: f32 = 2.0; // 直接赋值 var c = false; // 自动推断类型 -
fn:声明函数fn init() {} // 传参与返回 fn add(x: f32, y: f32) -> f32 { var z: f32 = x + y; return z; } -
if:选择语句var result: bool; var number = 2.0; if (number > 1.0) { result = true; } else { result = false; } -
for:循环语句var number: u32 = 10; var sum: f32 = 0.0 for(var i: u32 = 0; i < number; i++) { sum += 0.05; } -
vec2<T>:数据类型T的二维向量var pos2: vec2<f32> = vec2<f32>(1.0, 0.0); // 二维坐标vec3<T>:数据类型T的三维向量var pos3: vec3<f32> = vec3<f32>(pos2, 0.0); // 三维坐标vec4<T>:数据类型T的四维向量var color: vec4<f32> = vec4<f32>(1.0, 0.0, 0.0, 1.0); // #ff0000ff- 四维向量表示坐标时,第四分量表示齐次坐标
-
struct:声明结构体struct pointLight { color: vec3<f32>, // 光源颜色 intensity: f32, // 光源强度 }; var light: pointLight; light.color = vec3(1.0, 1.0, 1.0); light.intensity = 1.0;
(4)顶点着色器
-
功能:对顶点数据进行变换和处理
-
@vertex:表示字符串变量中的代码是顶点着色器代码const vertex = /* wgsl */ ` @vertex fn main() {} `其中,
/* wgsl */用于引入插件 WGSL Literal,实现 WGSL 语法高亮 -
@location():location是 WGSL 关键字,指定顶点缓冲区相关的顶点数据,小括号内设置参数@location(0)表示 GPU 显存中标记为 0 的顶点缓冲区中的顶点数据
-
position是 WGSL 内置变量,表示顶点数据 -
@builtin():builtin是 WGSL 关键字,用于声明内置变量,小括号内设置参数 -
完整代码:
const vertex = /* wgsl */ ` @vertex fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> { var pos2 = vec4<f32>(pos, 1.0); // 转齐次坐标 // 顶点计算操作 pos2.x -= 0.2; // 如:所有顶点位置向左平移 0.2 个单位 return pos2; // 返回顶点位置 } `; -
着色器代码块方法
createShaderModule将顶点着色器代码转换为 GPU 着色器代码库块对象(async function () { // ... const vertexShader = /* wgsl */ ` @vertex fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> { return vec4<f32>(pos, 1.0); } `; const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { buffers: [ // ... ], module: device.createShaderModule({ code: vertexShader, }), entryPoint: "main", // 指定入口函数 }, }); })();
(5)图元装配
-
功能:在顶点着色器处理后,将顶点组装成图元(如点、线、三角形),为光栅化阶段做准备
-
渲染管线参数属性
primitive.topology可以设置 WebGPU 如何绘制顶点数据,即图元装配-
该属性取值说明:
取值 说明 point-list绘制点 line-strip把多个顶点首尾相接连接(不闭合) triangle-list绘制三角形面
(async function () { // ... const pipeline = device.createRenderPipeline({ // ... primitive: { topology: "triangle-list", // 顶点组装方式 }, }); })(); -
-
光栅化:生成几何图形对应的片元
(6)片元着色器
-
功能:对光栅化生成的每个片元进行颜色、深度和纹理等计算,输出最终的像素颜色值
-
@fragment:表示字符串变量中的代码是片元着色器代码(async function () { // ... const fragmentShader = /* wgsl */ ` @fragment fn main() -> @location(0) vec4<f32> { return vec4<f32>(1.0, 0.0, 0.0, 1.0); } `; const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { // ... }, fragment: { // 片元着色器 module: device.createShaderModule({ code: fragmentShader, }), entryPoint: "main", targets: [ { format: format, // 颜色格式,和 WebGPU 上下文配置一致 }, ], }, primitive: { topology: "triangle-list", }, }); })();
(7)渲染命令
包括上文完整代码
(async function () {
if (!navigator.gpu) throw new Error("不支持 WebGPU");
const adapter = await navigator.gpu.requestAdapter();
if (!adapter) throw new Error("无法请求 WebGPU 适配器");
const device = await adapter.requestDevice();
if (!device) throw new Error("无法请求 WebGPU 设备");
const canvas = document.querySelector("canvas");
const context = canvas.getContext("webgpu");
const format = navigator.gpu.getPreferredCanvasFormat();
context.configure({ device, format });
const vertexArray = new Float32Array([
0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0,
]);
const vertexBuffer = device.createBuffer({
size: vertexArray.byteLength,
usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST,
});
device.queue.writeBuffer(vertexBuffer, 0, vertexArray);
const vertexShader = /* wgsl */ `
@vertex
fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> {
return vec4<f32>(pos, 1.0);
}
`;
const fragmentShader = /* wgsl */ `
@fragment
fn main() -> @location(0) vec4<f32> {
return vec4<f32>(1.0, 0.0, 0.0, 1.0);
}
`;
const pipeline = device.createRenderPipeline({
layout: "auto",
vertex: {
buffers: [
{
arrayStride: 3 * 4,
attributes: [
{
shaderLocation: 0,
offset: 0,
format: "float32x3",
},
],
},
],
module: device.createShaderModule({
code: vertexShader,
}),
entryPoint: "main",
},
fragment: {
module: device.createShaderModule({
code: fragmentShader,
}),
entryPoint: "main",
targets: [
{
format: format,
},
],
},
primitive: {
topology: "triangle-list",
},
});
// 创建 GPU 命令编码器对象
const commandEncoder = device.createCommandEncoder();
// 创建渲染通道
const renderPass = commandEncoder.beginRenderPass({
colorAttachments: [
{
view: context.getCurrentTexture().createView(), // 获取当前 WebGPU 上下文视图
clearValue: { r: 0, g: 0, b: 0, a: 1 }, // 背景颜色,#000000ff
loadOp: "clear", // 使背景颜色生效,取值 "load" 表示不生效
storeOp: "store", // 将像素数据写入颜色缓冲区,取值 "discard" 表示不写入
},
],
});
renderPass.setPipeline(pipeline); // 设置渲染通道对应的渲染管线
renderPass.setVertexBuffer(0, vertexBuffer); // 设置顶点缓冲区,0 表示绑定到位置 0 的顶点缓冲区
renderPass.draw(3); // 绘制顶点
renderPass.end(); // 结束渲染通道
const commandBuffer = commandEncoder.finish(); // 命令编码器创建命令缓冲区,将生成的 GPU 指令存入缓冲区
device.queue.submit([commandBuffer]); // 将命令缓冲区提交到 GPU 执行
})();
(8)绘制矩形
-
矩形本质上是由两个三角面拼接而成
- 任何三维物体都可以通过三角面拼接而成
-
三角面拼接需要注意正反面,即三角形顶点顺序必须同时为顺时针或逆时针
-
基于上述代码修改
(async function () { // ... const vertexArray = new Float32Array([ 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, // 三角面 1 0.0, 1.0, 0.0, 1.0, 0.0, 0.0, 1.0, 1.0, 0.0, // 三角面 2 ]); // ... renderPass.draw(6); // 改为绘制 6 个顶点 // ... })();
0x03 几何变换
(0)线性代数-矩阵基础
- \(m\times n\) 矩阵表示 \(m\) 行 \(n\) 列的矩阵
- 如:\(2\times3\) 矩阵 \(\begin{bmatrix}1&2&3\\4&5&6\end{bmatrix}\)
- 单位矩阵:对角线上都为 1
- 如:四阶单位矩阵 \(\begin{bmatrix}1&0&0&0\\0&1&0&0\\0&0&1&0\\0&0&0&1\end{bmatrix}\)
- 矩阵乘法法则
- \(\begin{bmatrix}a&b\\c&d\end{bmatrix}\times\begin{bmatrix}x\\y\end{bmatrix}=\begin{bmatrix}ax+by\\cx+dy\end{bmatrix}\)
- \(\begin{bmatrix}a&b\\c&d\end{bmatrix}\times\begin{bmatrix}x&u\\y&v\end{bmatrix}=\begin{bmatrix}ax+by&au+bv\\cx+dy&cu+dv\end{bmatrix}\)
- \(单位矩阵\times一般矩阵=一般矩阵\)
- 平移
- 假定 \(x\)、\(y\)、\(z\) 分别平移 \(T_x\)、\(T_y\)、\(T_z\) ,则平移后的坐标为 \((x+T_x,\ y+T_y,\ z+T_z)\)
- 坐标 \((x,\ y,\ z)\) 的齐次坐标为 \((x,\ y,\ z,\ 1)\) ,则平移后的齐次坐标为 \(\begin{bmatrix}1&0&0&T_x\\0&1&0&T_y\\0&0&1&T_z\\0&0&0&1\end{bmatrix}\times\begin{bmatrix}x\\y\\z\\1\end{bmatrix}=\begin{bmatrix}x+T_x\\y+T_y\\z+T_z\\1\end{bmatrix}\)
- 缩放
- 假定 \(x\)、\(y\)、\(z\) 分别缩放 \(S_x\)、\(S_y\)、\(S_z\) ,则平移后的坐标为 \((xS_x,\ yS_y,\ zS_z)\)
- 坐标 \((x,\ y,\ z)\) 的齐次坐标为 \((x,\ y,\ z,\ 1)\) ,则缩放后的齐次坐标为 \(\begin{bmatrix}S_x&0&0&0\\0&S_y&0&0\\0&0&S_z&0\\0&0&0&1\end{bmatrix}\times\begin{bmatrix}x\\y\\z\\1\end{bmatrix}=\begin{bmatrix}xS_x\\yS_y\\zS_z\\1\end{bmatrix}\)
- 旋转
- 假定 \((x,\ y,\ z)\)
- 绕 \(x\) 轴旋转 \(\alpha\) 度 ,则旋转后的坐标为 \((x,\ y\cos\alpha-z\sin\alpha,\ y\sin\alpha+z\cos\alpha)\)
- 绕 \(y\) 轴旋转 \(\beta\) 度 ,则旋转后的坐标为 \((z\sin\beta+x\cos\beta,\ y,\ z\cos\beta-x\sin\beta)\)
- 绕 \(z\) 轴旋转 \(\gamma\) 度 ,则旋转后的坐标为 \((x\cos\gamma-y\sin\gamma,\ x\sin\gamma+y\cos\gamma,\ z)\)
- 坐标 \((x,\ y,\ z)\) 的齐次坐标为 \((x,\ y,\ z,\ 1)\) ,则绕 \(x\) 轴旋转 \(\alpha\) 度后的齐次坐标为 \(\begin{bmatrix}1&0&0&0\\0&\cos\alpha&-\sin\alpha&0\\0&\sin\alpha&\cos\alpha&0\\0&0&0&1\end{bmatrix}\times\begin{bmatrix}x\\y\\z\\1\end{bmatrix}=\begin{bmatrix}x\\y\cos\alpha-z\sin\alpha\\y\sin\alpha+z\cos\alpha\\1\end{bmatrix}\)
- 假定 \((x,\ y,\ z)\)
- 模型矩阵:平移、缩放、旋转矩阵相乘得到的复合矩阵,即所有变换矩阵的乘积结果
- 同操作不同顺序的变换,得到的模型矩阵不一致
- \(原矩阵\times模型矩阵=新矩阵\)
(1)顶点着色器矩阵变换
const vertex = /* wgsl */ `
@vertex
fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> {
// 矩阵按列输入
var T = mat4x4<f32>(
1, 0, 0, 0,
0, 1, 0, 0,
0, 0, 1, 0,
-0.5, -0.5, 0, 1
); // 平移矩阵
var S = mat4x4<f32>(
0.5, 0, 0, 0,
0, 0.5, 0, 0,
0, 0, 1, 0,
0, 0, 0, 1
); // 缩放矩阵
return T * S * vec4<f32>(pos, 1.0);
}
`;
(2)传递 uniform 数据
-
uniform 数据:存储在GPU中的一组只读常量数据,由 CPU 设置并在渲染过程中供着色器统一访问,用于传递如变换矩阵、光照参数等全局不变的渲染信息
graph LR 顶点缓冲区--uniform数据-->顶点着色器 uniform数据 & 纹理缓冲区-->片元着色器 -
创建变换矩阵并使用
-
创建 uniform 数据并写入缓冲区
(async function () { // ... const vertexArray = new Float32Array([ /* ... */ ]); const vertexBuffer = device.createBuffer({ /* ... */ }); device.queue.writeBuffer(vertexBuffer, 0, vertexArray); // uniform 数据 const mat4TArray = new Float32Array([ 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, -0.5, -0.5, 0, 1, ]); // 平移矩阵 const mat4SArray = new Float32Array([ 0.5, 0, 0, 0, 0, 0.5, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, ]); // 缩放矩阵 // 创建 uniform buffer const mat4TBuffer = device.createBuffer({ size: mat4TArray.byteLength, usage: GPUBufferUsage.UNIFORM | // uniform 数据缓冲区 GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(mat4TBuffer, 0, mat4TArray); const mat4SBuffer = device.createBuffer({ size: mat4SArray.byteLength, usage: GPUBufferUsage.UNIFORM | // uniform 数据缓冲区 GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(mat4SBuffer, 0, mat4SArray); // ... })(); -
创建 uniform 数据绑定组
(async function () { // ... // 创建渲染管道 const pipeline = device.createRenderPipeline({ /* ... */ }); // 创建 uniform 数据绑定组 const uniformBindGroup = device.createBindGroup({ layout: pipeline.getBindGroupLayout(0), // 绑定标记为 0 的组 entries: [ // 每个元素绑定的 uniform 数据 { binding: 0, // 绑定标记为 0 resource: { buffer: mat4TBuffer }, }, { binding: 1, // 绑定标记为 1 resource: { buffer: mat4SBuffer }, }, ], }); // 以下为渲染命令 const commandEncoder = device.createCommandEncoder(); // ... })(); -
修改顶点着色器
const vertexShader = /* wgsl */ ` @group(0) @binding(0) var<uniform> T: mat4x4<f32>; @group(0) @binding(1) var<uniform> S: mat4x4<f32>; @vertex fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> { return T * S * vec4<f32>(pos, 1.0); } `;其中:
@group选择绑定的组,参数与组的layout一致,如:@group(0)对应.getBindGroupLayout(0)@binding选择绑定标记,参数与每个数据的binding属性一致<uniform>指定变量为 uniform 数据
-
修改渲染通道
// 设置顶点缓冲区对应的绑定组 renderPass.setBindGroup(0, uniformBindGroup); // 第一参数与组的 layout 一致完整代码(注释
// new对应的代码块存在新增或修改)(async function () { if (!navigator.gpu) throw new Error("不支持 WebGPU"); const adapter = await navigator.gpu.requestAdapter(); if (!adapter) throw new Error("无法请求 WebGPU 适配器"); const device = await adapter.requestDevice(); if (!device) throw new Error("无法请求 WebGPU 设备"); const canvas = document.querySelector("canvas"); const context = canvas.getContext("webgpu"); const format = navigator.gpu.getPreferredCanvasFormat(); context.configure({ device, format }); const vertexArray = new Float32Array([ 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, ]); const vertexBuffer = device.createBuffer({ size: vertexArray.byteLength, usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(vertexBuffer, 0, vertexArray); // new const mat4TArray = new Float32Array([ 1, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 0, -0.5, -0.5, 0, 1, ]); const mat4SArray = new Float32Array([ 0.5, 0, 0, 0, 0, 0.5, 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, ]); const mat4TBuffer = device.createBuffer({ size: mat4TArray.byteLength, usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(mat4TBuffer, 0, mat4TArray); const mat4SBuffer = device.createBuffer({ size: mat4SArray.byteLength, usage: GPUBufferUsage.UNIFORM | // uniform 数据缓冲区 GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(mat4SBuffer, 0, mat4SArray); // new const vertexShader = /* wgsl */ ` @group(0) @binding(0) var<uniform> T: mat4x4<f32>; @group(0) @binding(1) var<uniform> S: mat4x4<f32>; @vertex fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> { return T * S * vec4<f32>(pos, 1.0); } `; const fragmentShader = /* wgsl */ ` @fragment fn main() -> @location(0) vec4<f32> { return vec4<f32>(1.0, 0.0, 0.0, 1.0); } `; const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { buffers: [ { arrayStride: 3 * 4, attributes: [ { shaderLocation: 0, offset: 0, format: "float32x3", }, ], }, ], module: device.createShaderModule({ code: vertexShader, }), entryPoint: "main", }, fragment: { module: device.createShaderModule({ code: fragmentShader, }), entryPoint: "main", targets: [ { format: format, }, ], }, primitive: { topology: "triangle-list", }, }); // new const uniformBindGroup = device.createBindGroup({ layout: pipeline.getBindGroupLayout(0), entries: [ { binding: 0, resource: { buffer: mat4TBuffer }, }, { binding: 1, resource: { buffer: mat4SBuffer }, }, ], }); const commandEncoder = device.createCommandEncoder(); const renderPass = commandEncoder.beginRenderPass({ colorAttachments: [ { view: context.getCurrentTexture().createView(), clearValue: { r: 0, g: 0, b: 0, a: 1 }, loadOp: "clear", storeOp: "store", }, ], }); renderPass.setPipeline(pipeline); renderPass.setVertexBuffer(0, vertexBuffer); renderPass.setBindGroup(0, uniformBindGroup); // new renderPass.draw(3); renderPass.end(); const commandBuffer = commandEncoder.finish(); device.queue.submit([commandBuffer]); })();
-
(3)gl-matrix
a. 概述
-
gl-matrix 是一个开源的矩阵计算库,包括:向量计算、矩阵计算、四元数计算等计算函数
-
相关网站:
-
引入方法
- CDN:在 index.html 的
<head>中,添加<script src="https://cdn.jsdelivr.net/npm/gl-matrix@3.4.3/gl-matrix-min.min.js"></script>引入 - Github 仓库:下载并引入
- NPM:使用命令
npm install -S gl-matrix
以下采用 CDN 方法
- CDN:在 index.html 的
b. 使用
-
创建 \(4\times4\) 矩阵 \(\begin{bmatrix}1&0&0&1\\0&1&0&2\\0&0&1&3\\0&0&0&1\end{bmatrix}\)
const mat4T = glMatrix.mat4.fromValues( 1, 0, 0, 0, // 第一列 0, 1, 0, 0, // 第二列 0, 0, 1, 0, // 第三列 1, 2, 3, 1 // 第四列 ); // 按列传参 console.log(mat4T); -
创建四阶单位矩阵
const mat4 = glMatrix.mat4.create(); console.log(mat4); -
自动生成变换矩阵
-
平移矩阵
const mat4 = glMatrix.mat4.create(); // 创建四阶单位矩阵 const mat4T = glMatrix.mat4.create(); // 创建四阶单位矩阵作为原始状态 glMatrix.mat4.translate(mat4T, mat4, [1, 2, 3]); // x,y,z 轴分别平移 1,2,3 个单位 console.log(mat4T); -
缩放矩阵
const mat4 = glMatrix.mat4.create(); const mat4S = glMatrix.mat4.create(); glMatrix.mat4.scale(mat4S, mat4, [1, 2, 3]); // x,y,z 轴分别缩放 1,2,3 倍 console.log(mat4S); -
旋转矩阵
const mat4 = glMatrix.mat4.create(); const mat4R = glMatrix.mat4.create(); glMatrix.mat4.rotateX(mat4R, mat4, Math.PI / 4); // 绕 x 轴旋转 45 度 // glMatrix.mat4.rotateY(mat4R, mat4, Math.PI / 2); // 绕 y 轴旋转 90 度 // glMatrix.mat4.rotateZ(mat4R, mat4, Math.PI); // 绕 z 轴旋转 180 度 console.log(mat4R);
-
-
矩阵乘法运算
// 单位矩阵 const mat4 = glMatrix.mat4.create(); // 变换矩阵 const mat4T = glMatrix.mat4.create(); glMatrix.mat4.translate(mat4T, mat4, [1, 0, 0]); const mat4S = glMatrix.mat4.create(); glMatrix.mat4.scale(mat4S, mat4, [1, 2, 1]); // 模型矩阵 const modelMatrix = glMatrix.mat4.mul(mat4, mat4T, mat4S); // 先平移后缩放 console.log(modelMatrix); -
创建三维向量
const unitVec = glMatrix.vec3.create(); // 单位向量 (0, 0, 0) const vec = glMatrix.vec3.fromValues(1, 2, 3); // 指定向量 (1, 2, 3)
c. 生成顶点着色器矩阵
(async function () {
// ...
const mat4Array = glMatrix.mat4.create(); // 创建单位矩阵
glMatrix.mat4.translate(mat4Array, mat4Array, [-0.5, -0.5, 0]); // 平移
glMatrix.mat4.scale(mat4Array, mat4Array, [0.5, 0.5, 1]); // 缩放
const matBuffer = device.createBuffer({
size: mat4Array.byteLength,
usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST,
});
device.queue.writeBuffer(matBuffer, 0, mat4Array);
const vertexShader = /* wgsl */ `
@group(0) @binding(0) var<uniform> M: mat4x4<f32>;
@vertex
fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> {
return M * vec4<f32>(pos, 1.0);
}
`;
const fragmentShader = /* ... */;
const pipeline = device.createRenderPipeline({ /* ... */ });
const uniformBindGroup = device.createBindGroup({
layout: pipeline.getBindGroupLayout(0),
entries: [
{
binding: 0,
resource: { buffer: matBuffer },
},
],
});
// ...
renderPass.setBindGroup(0, uniformBindGroup); // 传入绑定组
// ...
})();
(4)动画
-
通过在
requestAnimationFrame()中修改 uniform 数据实现动画效果- 即循环渲染
-
矩形绕 \(z\) 轴旋转:
(async function () { if (!navigator.gpu) throw new Error("不支持 WebGPU"); const adapter = await navigator.gpu.requestAdapter(); if (!adapter) throw new Error("无法请求 WebGPU 适配器"); const device = await adapter.requestDevice(); if (!device) throw new Error("无法请求 WebGPU 设备"); const canvas = document.querySelector("canvas"); const context = canvas.getContext("webgpu"); const format = navigator.gpu.getPreferredCanvasFormat(); context.configure({ device, format }); const vertexArray = new Float32Array([ 0.0, 0.0, 0.0, 0.5, 0.0, 0.0, 0.0, 0.5, 0.0, // 三角面 1 0.0, 0.5, 0.0, 0.5, 0.0, 0.0, 0.5, 0.5, 0.0, // 三角面 2 ]); const vertexBuffer = device.createBuffer({ size: vertexArray.byteLength, usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(vertexBuffer, 0, vertexArray); const vertexShader = /* wgsl */ ` @group(0) @binding(0) var<uniform> M: mat4x4<f32>; @vertex fn main(@location(0) pos: vec3<f32>) -> @builtin(position) vec4<f32> { return M * vec4<f32>(pos, 1.0); } `; const fragmentShader = /* wgsl */ ` @fragment fn main() -> @location(0) vec4<f32> { return vec4<f32>(1.0, 0.0, 0.0, 1.0); } `; const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { buffers: [ { arrayStride: 3 * 4, attributes: [ { shaderLocation: 0, offset: 0, format: "float32x3", }, ], }, ], module: device.createShaderModule({ code: vertexShader, }), entryPoint: "main", }, fragment: { module: device.createShaderModule({ code: fragmentShader, }), entryPoint: "main", targets: [ { format: format, }, ], }, primitive: { topology: "triangle-list", }, }); let angle = 0.0; // 初始角度 // 循环渲染实现动画效果 function render() { angle += 0.01; // 旋转角度 const mat4Array = glMatrix.mat4.create(); glMatrix.mat4.rotateZ(mat4Array, mat4Array, angle); const matBuffer = device.createBuffer({ size: mat4Array.byteLength, usage: GPUBufferUsage.UNIFORM | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(matBuffer, 0, mat4Array); const uniformBindGroup = device.createBindGroup({ layout: pipeline.getBindGroupLayout(0), entries: [ { binding: 0, resource: { buffer: matBuffer }, }, ], }); const commandEncoder = device.createCommandEncoder(); const renderPass = commandEncoder.beginRenderPass({ colorAttachments: [ { view: context.getCurrentTexture().createView(), clearValue: { r: 0, g: 0, b: 0, a: 1 }, loadOp: "clear", storeOp: "store", }, ], }); renderPass.setPipeline(pipeline); renderPass.setVertexBuffer(0, vertexBuffer); renderPass.setBindGroup(0, uniformBindGroup); renderPass.draw(6); renderPass.end(); const commandBuffer = commandEncoder.finish(); device.queue.submit([commandBuffer]); requestAnimationFrame(render); } render(); })();
(5)片元
a. 屏幕坐标系
-
片元在 Canvas 画布上的位置可以使用屏幕坐标系描述
-
屏幕坐标系(二维):
- 坐标原点:画布左上角
- \(x\) 轴:水平,正方向向右,单位 px
- \(y\) 轴:竖直,正方向向下,单位 px
-
通过主函数
main()的参数,片元着色器可以获取光栅化后的片元的屏幕坐标- 可以根据坐标值改变片元的颜色
(async function () { // ... const vertexArray = new Float32Array([ -1.0, -1.0, 0.0, 1.0, -1.0, 0.0, -1.0, 1.0, 0.0, // 三角面 1 -1.0, 1.0, 0.0, 1.0, -1.0, 0.0, 1.0, 1.0, 0.0, // 三角面 2 ]); // ... const fragmentShader = /* wgsl */ ` @fragment fn main(@builtin(position) fragCoord: vec4<f32>) -> @location(0) vec4<f32> { var x = fragCoord.x; // 片元在 x 轴屏幕坐标 var y = fragCoord.y; // 片元在 y 轴屏幕坐标 // 画布大小为 500 则画布中心的屏幕坐标为 (250, 250) if (x > 250 && y < 250) { return vec4<f32>(1.0, 0.0, 0.0, 1.0); // 第一象限绘制红色 } else if (x < 250 && y > 250) { return vec4<f32>(0.0, 1.0, 0.0, 1.0); // 第二象限绘制绿色 } else if (x > 250 && y > 250) { return vec4<f32>(0.0, 0.0, 1.0, 1.0); // 第三象限绘制蓝色 } else { return vec4<f32>(1.0, 1.0, 0.0, 1.0); // 第四象限绘制黄色 } } `; // ... renderPass.draw(6); // ... })();
b. 深度值与深度缓冲区
-
片元深度值主要指 \(z\) 轴坐标
-
片元的深度缓冲区存储片元的深度值
- 帧缓冲区包括深度缓冲区和存储片元颜色的颜色缓冲区
-
通过主函数
main()的参数,片元着色器可以获取光栅化后的片元的深度值- 可以根据深度值改变片元的透明度
(async function () { // ... const vertexArray = new Float32Array([ 1.0, 0.0, 0.0, 0.0, 1.0, 0.0, 0.0, 0.0, 1.0, ]); // ... const fragmentShader = /* wgsl */ ` @fragment fn main(@builtin(position) fragCoord: vec4<f32>) -> @location(0) vec4<f32> { var z = fragCoord.z; // 片元的深度值 return vec4<f32>(1 - z, 0.0, 0.0, 1.0); } `; // ... renderPass.draw(3); // ... })();
(6)插值计算
使用 WGSL 中的结构体语法,设置主函数 main() 返回一个结构体,如:
struct Out {
@builtin(position) pos: vec4<f32>
}
@vertex
fn main(@location(0) pos: vec3<f32>) -> Out {
var out: Out;
out.pos = vec4<f32>(pos, 1.0);
return out;
}
当函数参数过多时,也可以采用结构体进行传参
a. 顶点位置数据
-
声明变量
vPos表示片元的坐标struct Out { @builtin(position) pos: vec4<f32>, @location(0) vPos: vec3<f32> } -
插值计算,生成每个片元的坐标
@vertex fn main(@location(0) pos: vec3<f32>) -> Out { var out: Out; out.pos = vec4<f32>(pos, 1.0); out.vPos = pos; // 插值计算 return out; } -
在片元着色器中使用插值计算的结果
@fragment fn main(@location(0) vPos: vec3<f32>) -> @location(0) vec4<f32> { return vec4<f32>(vPos.x, 1.0, 1.0 - vPos.x, 1.0); }函数参数中
@location()的参数值与结构体的@location()的参数值一致
b. 顶点颜色数据
-
创建顶点颜色缓冲区
const colorArray = new Float32Array([ 1.0, 0.0, 0.0, // 红色 0.0, 1.0, 0.0, // 绿色 0.0, 0.0, 1.0, // 蓝色 ]); const colorBuffer = device.createBuffer({ size: colorArray.byteLength, usage: GPUBufferUsage.VERTEX | GPUBufferUsage.COPY_DST, }); device.queue.writeBuffer(colorBuffer, 0, colorArray); -
在渲染管线配置顶点颜色数据
const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { buffers: [ { // 顶点位置数据配置 // ... }, { // 顶点颜色数据配置 arrayStride: 3 * 4, attributes: [ { shaderLocation: 1, // 标记加一 offset: 0, format: "float32x3", }, ], }, ], module: device.createShaderModule({ code: vertexShader, }), entryPoint: "main", }, fragment: { // ... }, primitive: { // ... }, }); -
在渲染通道设置顶点颜色数据
renderPass.setVertexBuffer(1, colorBuffer); -
修改顶点着色器
const vertexShader = /* wgsl */ ` struct Out { @builtin(position) pos: vec4<f32>, @location(0) vColor: vec3<f32> } @vertex fn main(@location(0) pos: vec3<f32>, @location(1) color: vec3<f32>) -> Out { var out: Out; out.pos = vec4<f32>(pos, 1.0); out.vColor = color; // 插值计算 return out; } `; -
修改片元着色器
const fragmentShader = /* wgsl */ ` @fragment fn main(@location(0) vColor: vec3<f32>) -> @location(0) vec4<f32> { return vec4<f32>(vColor, 1.0); } `;
(7)共享缓冲区
-
主要指顶点位置数据和顶点颜色数据共享同一个顶点缓冲区
-
具体实现
(async function () { if (!navigator.gpu) throw new Error("不支持 WebGPU"); const adapter = await navigator.gpu.requestAdapter(); if (!adapter) throw new Error("无法请求 WebGPU 适配器"); const device = await adapter.requestDevice(); if (!device) throw new Error("无法请求 WebGPU 设备"); const canvas = document.querySelector("canvas"); const context = canvas.getContext("webgpu"); const format = navigator.gpu.getPreferredCanvasFormat(); context.configure({ device, format }); const vertexArray = new Float32Array([ 1.0, 0.0, 0.0, 1.0, 0.0, 0.0, // 位置 + 颜色 0.0, 1.0, 0.0, 0.0, 1.0, 0.0, // 位置 + 颜色 0.0, 0.0, 1.0, 0.0, 0.0, 1.0, // 位置 + 颜色 ]); // 顶点着色器代码不变 // ... const pipeline = device.createRenderPipeline({ layout: "auto", vertex: { buffers: [ { arrayStride: 6 * 4, // 6 个分量 attributes: [ { shaderLocation: 0, offset: 0, format: "float32x3", }, { shaderLocation: 1, // 标记加一 offset: 3 * 4, // 偏移 3 个分量 4 个字节 format: "float32x3", }, ], }, ], // ... }, // ... }); // ... renderPass.setVertexBuffer(0, vertexBuffer); // 只保留一个 // ... })();其中,
.setVertexBuffer()第一个参数对应的是渲染管道 buffers 数组中元素的索引值

 浙公网安备 33010602011771号
浙公网安备 33010602011771号