
爬虫初级 33号
用requests库访问某个网站20次
requests库是一个简洁且简单的处理HTTP请求的第三方库,最大的优点是程序编写更接近正常URL访问过程。
requests库解析
requests库中网页请求函数
| 函数 | 描述 |
| get(url[,timeout=n) | 对应于HTTP的GET方式,获取网页最常用的方法,可以增加timeout=n参数,设定每次请求超时时间为n秒 |
| post(url,data={'key':'value'}) | 对应于HTTP的POST方式,其中字典用于传递客户数据 |
| delete(url) | 对应于HTTP的DELETE方式 |
| options(url) | 对应于HTTP的OPTIONS方式 |
| head(url) | 对应于HTTP的HEAD方式 |
| put(url,data={'key':'value') | 对应于HTTP的PUT方式,其中字典用于传递客户数据 |
get()书获取网页的最常用的方式,在调用requests.get()函数后,返回网页内容会保存为一个Response对象,其中,get()函数的参数(url)链接必须采用HTTP或HTTPS方式访问。
response对象的属性
| 属性 | 描述 |
| status——code | HTTP返回的状态,整数,200表示连接成功,404表示失败 |
| text | HTTP响应内容的字符串形式,即url对应的页面内容 |
| encoding | HTTP响应的编码方式 |
| content |
HTTP响应内容为二进制形式 |
response对象的方法
| 方法 | 描述 |
| json() | 如果HTTP相应内容包含json格式数据,则该方法解析json数据 |
| raise_for status() | 如果不是200,则产生异常 |
搜狗主页访问状态
import requests
r=requests.get("https://www.sogou.com/")
print(r.status_code)
print(type(r))
![]()
搜狗主页访问20次
# -*- coding: utf-8 -*-
"""
Created on Mon May 20 10:41:27 2019
"""
Created on Mon May 20 10:41:27 2019
@author: 18605
"""
"""
import requests
def gethtmltext(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.enconding='utf-8'
return r.text
except:
print("Error")
url="https://www.sogou.com/"
for i in range(20):
gethtmltext(url)
print(gethtmltext(url))
def gethtmltext(url):
try:
r=requests.get(url,timeout=30)
r.raise_for_status()
r.enconding='utf-8'
return r.text
except:
print("Error")
url="https://www.sogou.com/"
for i in range(20):
gethtmltext(url)
print(gethtmltext(url))
部分结果
beautifulsoup库使用
简单来说,Beautiful Soup是python的一个库,最主要的功能是从网页抓取数据。官方解释如下:
Beautiful Soup提供一些简单的、python式的函数用来处理导航、搜索、修改分析树等功能。它是一个工具箱,通过解析文档为用户提供需要抓取的数据,因为简单,所以不需要多少代码就可以写出一个完整的应用程序。Beautiful Soup自动将输入文档转换为Unicode编码,输出文档转换为utf-8编码。你不需要考虑编码方式,除非文档没有指定一个编码方式,这时,Beautiful Soup就不能自动识别编码方式了。然后,你仅仅需要说明一下原始编码方式就可以了。Beautiful Soup已成为和lxml、html6lib一样出色的python解释器,为用户灵活地提供不同的解析策略或强劲的速度。
使用BeautifulSoup()创建一个BeautifulSoup对象
import requests from bs4 import BeautifulSoup r=requests.get("http://www.baidu.com") r.encoding="utf-8" soup=BeautifulSoup(r.text) print(type(soup)) ######################结果########################## #<class 'bs4.BeautifulSoup'>
BeautifulSoup常用属性
| 属性 | 描述 |
| head | HTML页面的<head>内容 |
| title | HTML页面标题,在<head>之中,由<title>标记 |
| body | HTML页面的<body>内容 |
| p | HTML页面第一个<p>内容 |
| strings | HTML页面所有呈现在Web上的字符串,及标签的内容 |
| stripped_strings | HTML页面所有呈现在Web上的非空格字符串 |
标签对象的常用属性
| 属性 | 描述 |
| name | 字符串,标签的名字,比如div |
| attrs | 字典,包含了原来页面Tag的所有属性,比如href |
| contents | 列表,这个Tag下所有子Tag的内容 |
| string | 字符串,Tag所包围的文本,网页中的真实文字 |
实例
# -*- coding: utf-8 -*- """ Created on Thu May 23 14:52:00 2019 @author: 18605 """ import requests import re from bs4 import BeautifulSoup html=""" <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> <table border="1"> <tr> <td>row 1,cell 1</td> <tr> <td>row 1,cell 2</td> </tr> </table> </html> """ soup=BeautifulSoup(html) print(soup.head) #打印head标签 title=soup.title print(soup.body) #获取body标签的内容 print(title.string) print(soup.find(id="first")) #获取id为first的标签对象 print(soup.get_text()) #获取并打印html页面中的字符
显示结果
<head> <meta charset="utf-8"/> <title>菜鸟教程(runoob.com)</title> </head> <body> <h1>我的第一个标题</h1> <p id="first">我的第一个段落。</p> </body> 菜鸟教程(runoob.com) <p id="first">我的第一个段落。</p> 菜鸟教程(runoob.com) 我的第一个标题 我的第一个段落。 row 1,cell 1 row 1,cell 2
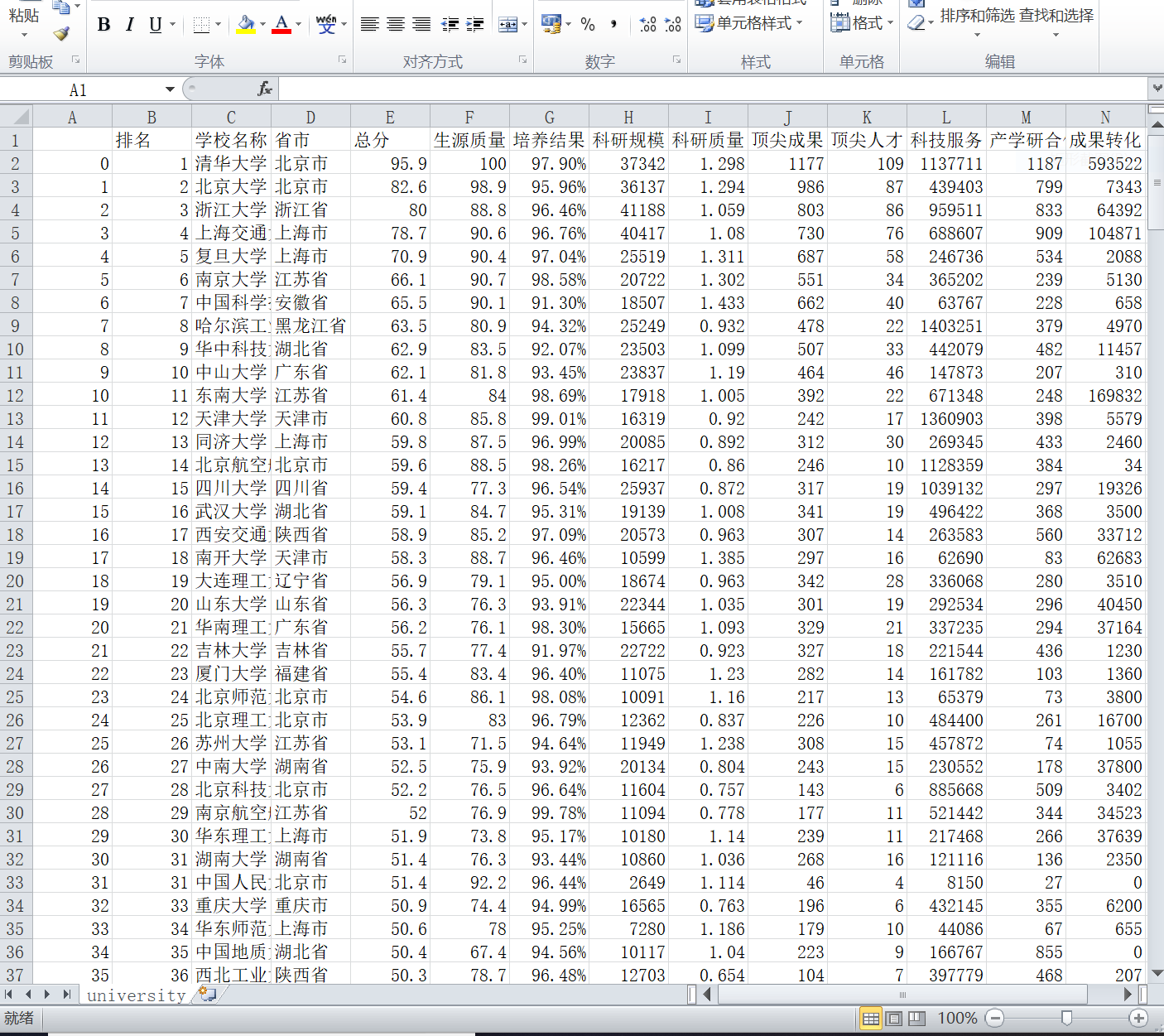
爬取中国大学排名网站的内容并将其存为CSV文件
代码展示
import requests from bs4 import BeautifulSoup allUniv=[] def getHTMLText(url): try: r=requests.get(url,timeout=30) r.raise_for_status() r.encoding="utf-8" return r.text except: return "" ####代码中每个td标签包含大学排名表格的夜歌列数值,与表头一一对应。要获取其中数据要先找到<tr></tr>标签,并遍历其中每一个<td></td>标签,获取其值写入程序的数据结构中########## def fillUnivList(soup): data=soup.find_all('tr') #找到所有的tr标签 for tr in data: ltd=tr.find_all('td') #在每个tr标签中找到所有的td标签 if len(ltd)==0: continue singleUniv=[] #创建空列表对象,储存当前<tr>标签表示大学的数据 for td in ltd: singleUniv.append(td.string) #提取td标签中的信息 allUniv.append(singleUniv) def printUnivList(num): print("{1:^2}{2:{0}^10}{3:{0}^6}{4:{0}^4}{5:{0}^10}".format(chr(12288),"排名","学校名称","省市","总分","培养规模")) a=[] for i in range(num): u=allUniv[i] print("{1:^4}{2:{0}^10}{3:{0}^5}{4:{0}^8}{5:{0}^10}".format(chr(12288),u[0],u[1],u[2],u[3],u[6])) def main(num): url='http://www.zuihaodaxue.com/zuihaodaxuepaiming2016.html' html=getHTMLText(url) soup=BeautifulSoup(html,"html.parser") fillUnivList(soup) printUnivList(num) main(30) list=allUniv name=["排名","学校名称","省市","总分","生源质量","培养结果","科研规模","科研质量","顶尖成果","顶尖人才","科技服务","产学研合作","成果转化"] test=pd.DataFrame(columns=name,data=list) test.to_csv('university.csv',encoding='gbk')
显示结果截图

csv文件截图
![]()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号