微服务01SpringCloud Eureka Ribbon Nacos Feign Gateway服务网关

微服务技术栈导学
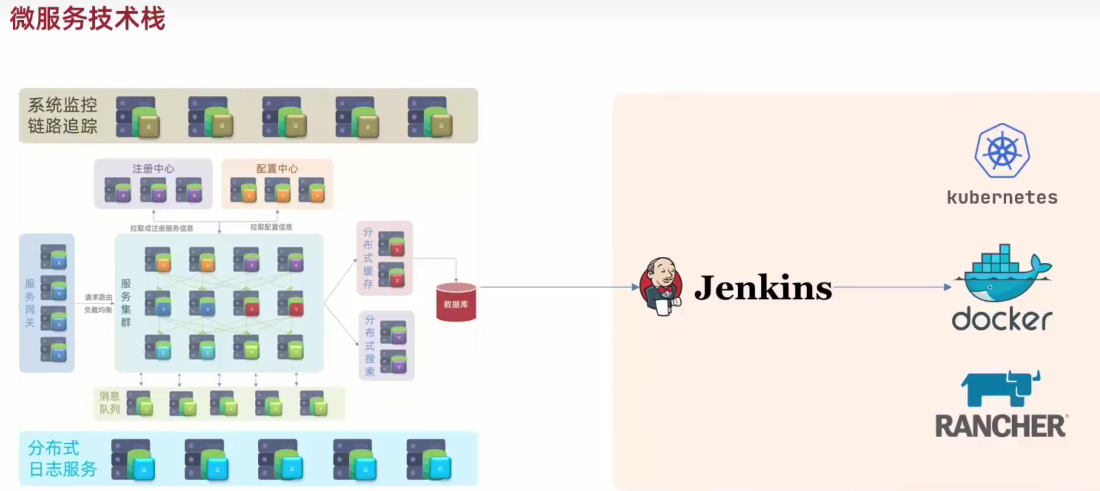
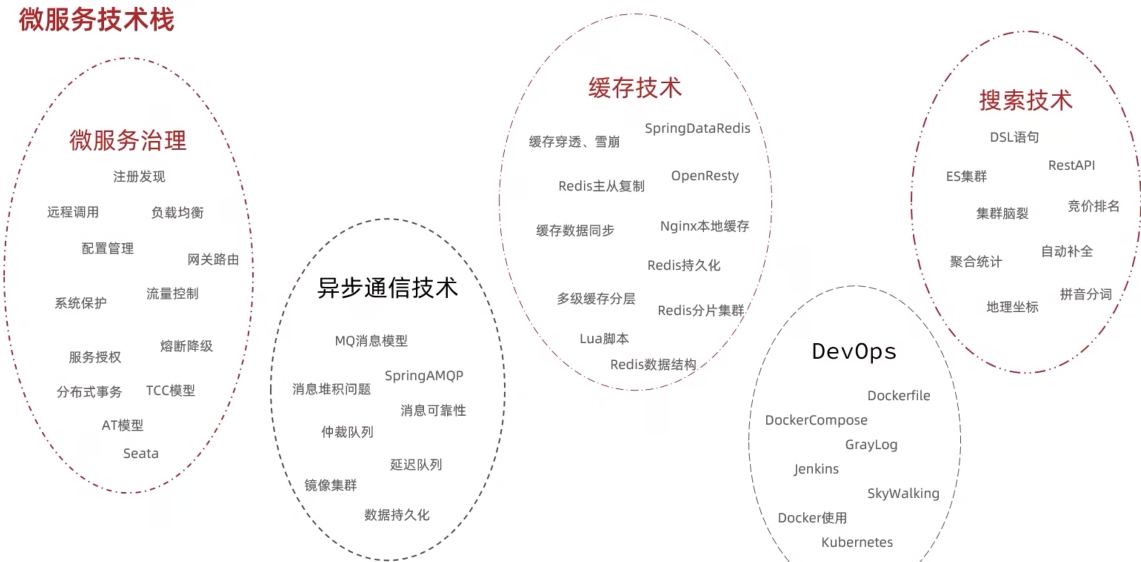


SpringCloud01
1.认识微服务
随着互联网行业的发展,对服务的要求也越来越高,服务架构也从单体架构逐渐演变为现在流行的微服务架构。这些架构之间有怎样的差别呢?
1.1.单体架构
单体架构:将业务的所有功能集中在一个项目中开发,打成一个包部署。
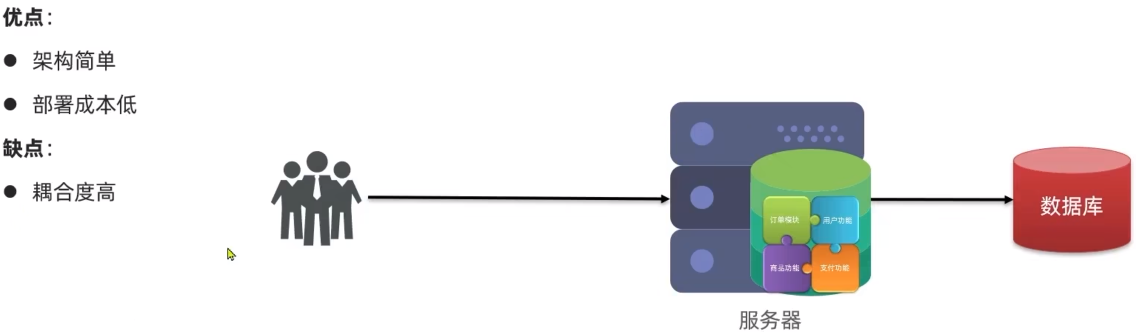
1.2.分布式架构
分布式架构:根据业务功能对系统做拆分,每个业务功能模块作为独立项目开发,称为一个服务。
分布式架构的优缺点:
优点:
降低服务耦合
有利于服务升级和拓展
缺点:
服务调用关系错综复杂
分布式架构虽然降低了服务耦合,但是服务拆分时也有很多问题需要思考:
服务拆分的粒度如何界定?
服务之间如何调用?
服务的调用关系如何管理?
人们需要制定一套行之有效的标准来约束分布式架构。
1.3.微服务
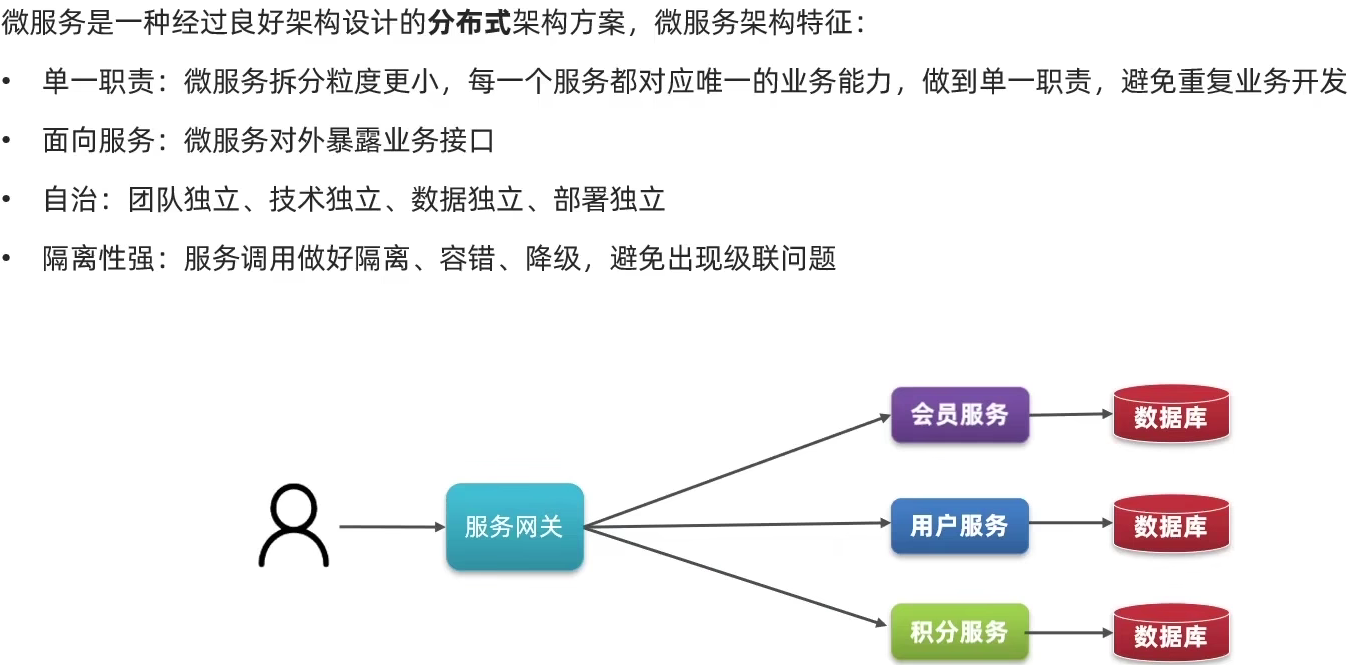
微服务的上述特性其实是在给分布式架构制定一个标准,进一步降低服务之间的耦合度,提供服务的独立性和灵活性。做到高内聚,低耦合。
因此,可以认为微服务是一种经过良好架构设计的分布式架构方案 。
但方案该怎么落地?选用什么样的技术栈?全球的互联网公司都在积极尝试自己的微服务落地方案。
其中在Java领域最引人注目的就是SpringCloud提供的方案了。
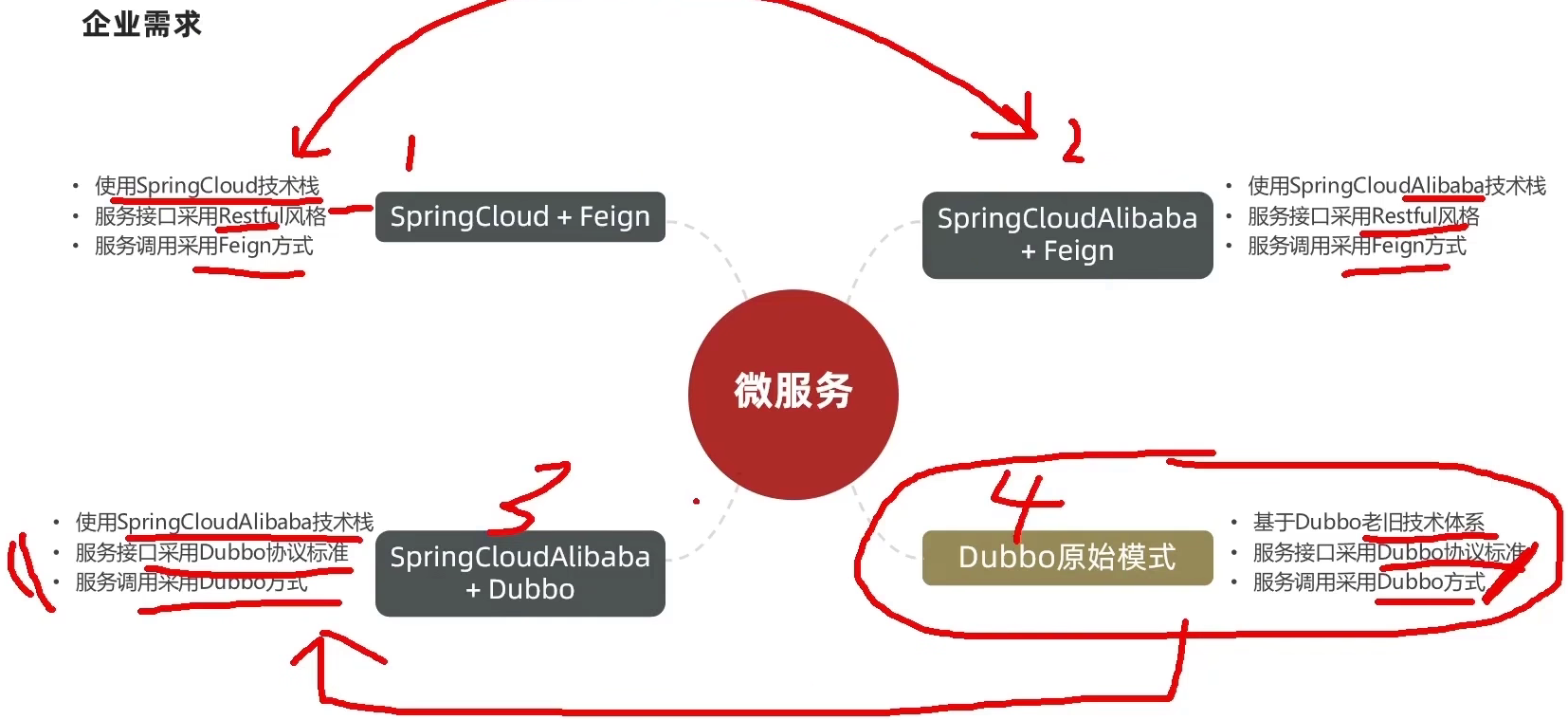
微服务技术对比


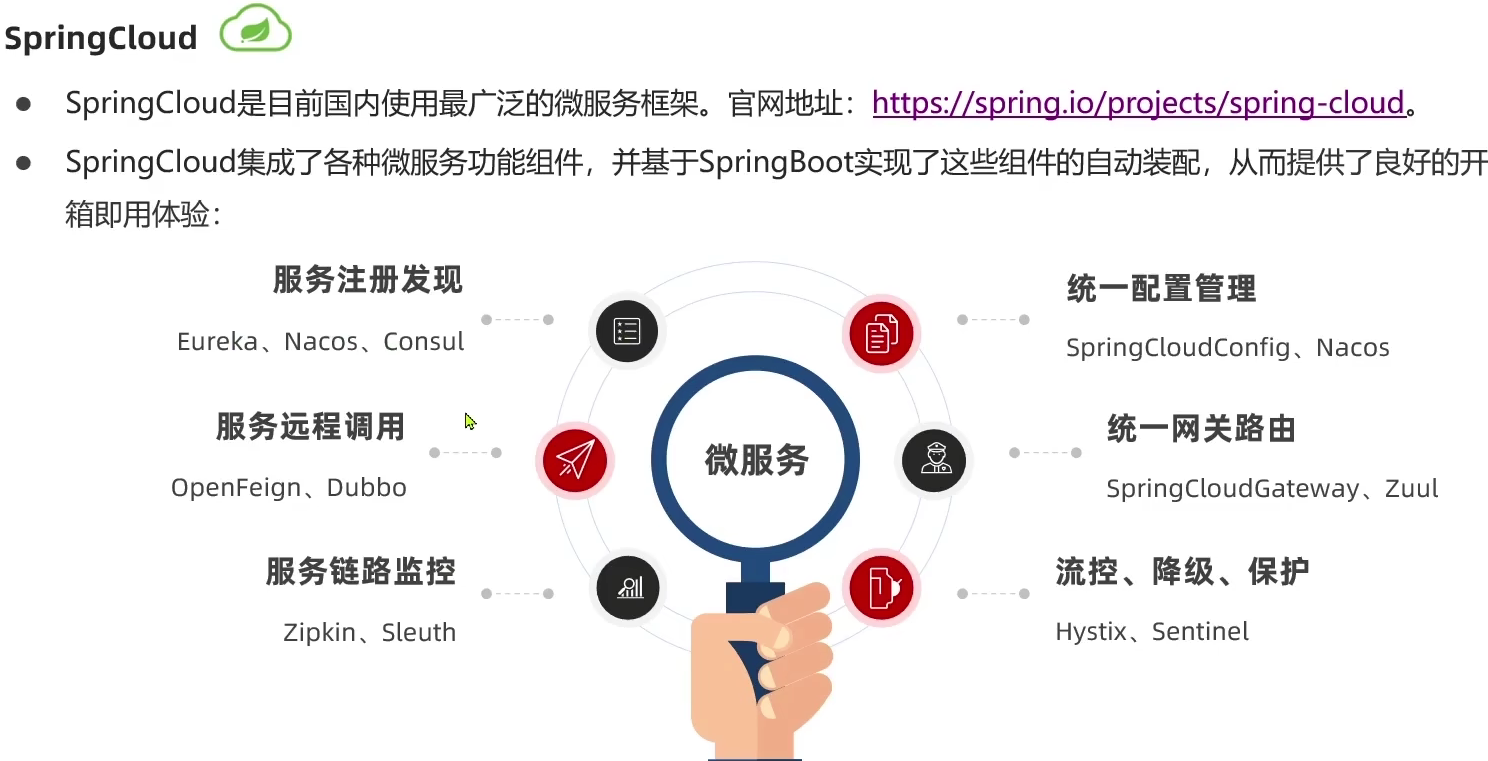
1.4.SpringCloud
官网地址:https://spring.io/projects/spring-cloud。
SpringCloud底层是依赖于SpringBoot的,并且有版本的兼容关系,如下:
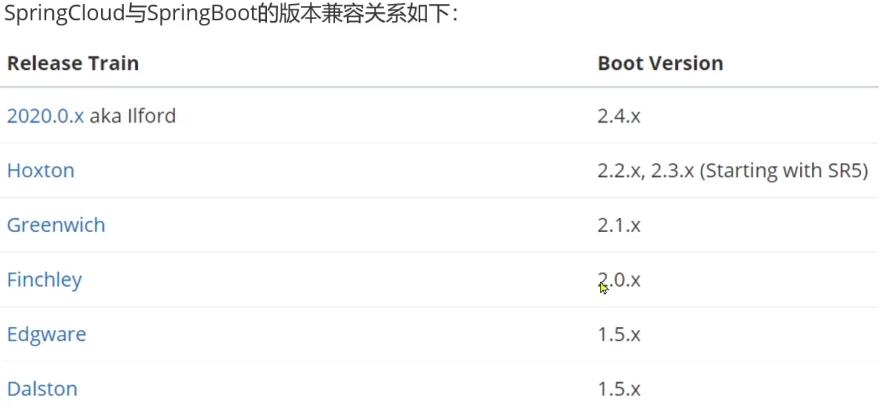
我们课堂学习的版本是 Hoxton.SR10,因此对应的SpringBoot版本是2.3.x版本。
1.5.总结

SpringCloud是微服务架构的一站式解决方案,集成了各种优秀微服务功能组件
2.服务拆分和远程调用
任何分布式架构都离不开服务的拆分,微服务也是一样。
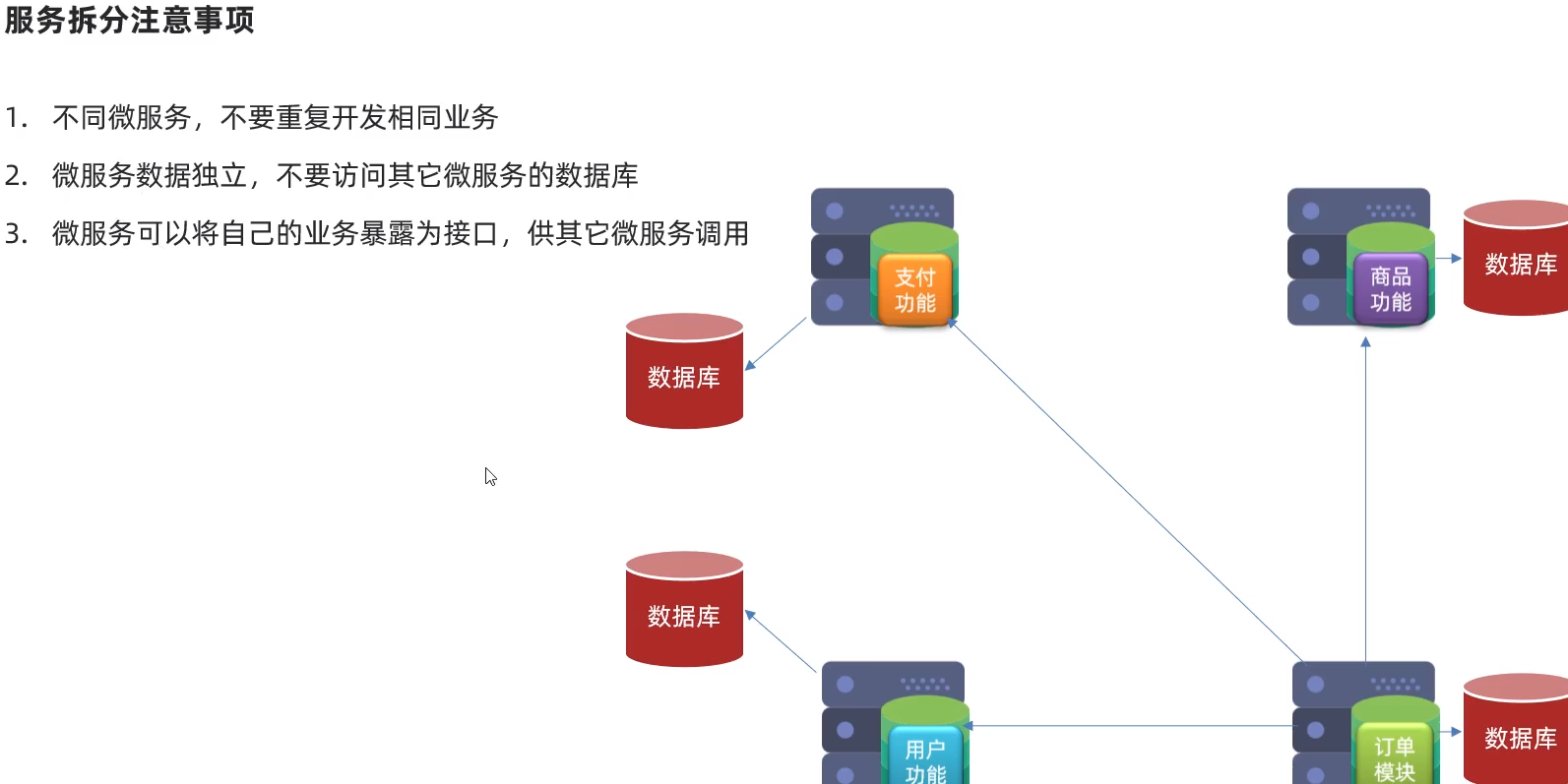
2.1.服务拆分原则
2.2.服务拆分示例
以课前资料中的微服务cloud-demo为例,其结构如下:

cloud-demo:父工程,管理依赖
order-service:订单微服务,负责订单相关业务
user-service:用户微服务,负责用户相关业务
要求:
订单微服务和用户微服务都必须有各自的数据库,相互独立
订单服务和用户服务都对外暴露Restful的接口
订单服务如果需要查询用户信息,只能调用用户服务的Restful接口,不能查询用户数据库
2.3.1.案例需求:
修改order-service中的根据id查询订单业务,要求在查询订单的同时,根据订单中包含的userId查询出用户信息,一起返回。
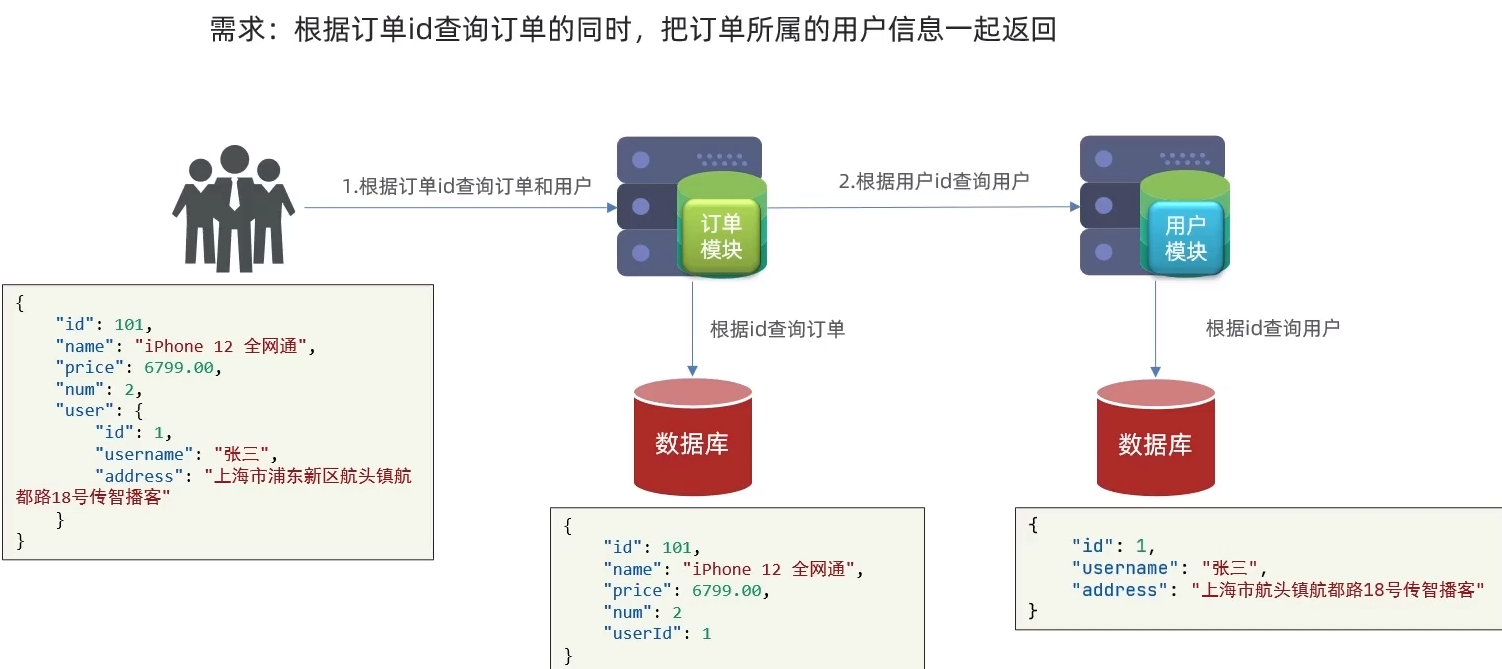
因此,我们需要在order-service中 向user-service发起一个http的请求,调用http://localhost:8081/user/{userId}这个接口。
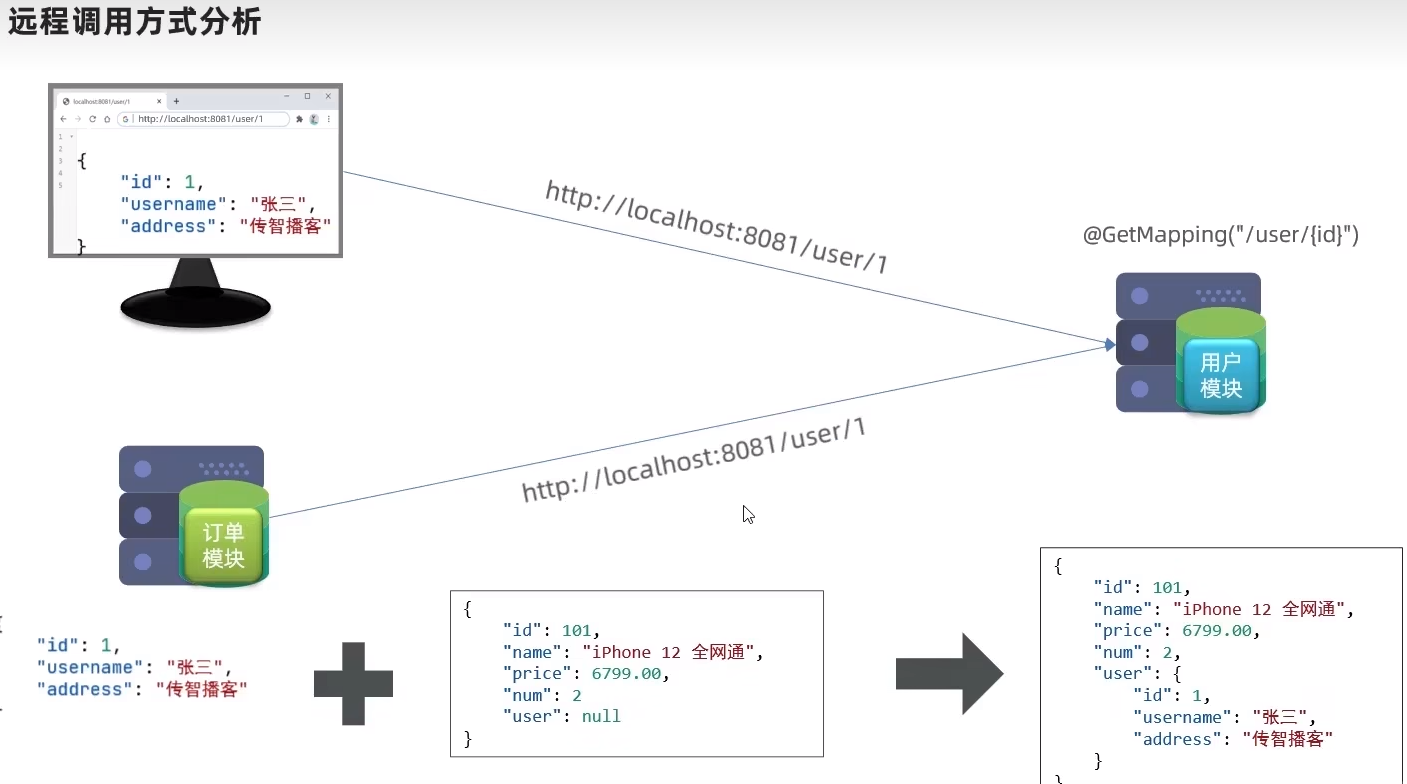
大概的步骤是这样的:
注册一个RestTemplate的实例到Spring容器
修改order-service服务中的OrderService类中的queryOrderById方法,根据Order对象中的userId查询User
将查询的User填充到Order对象,一起返回
2.3.2.注册RestTemplate
首先,我们在order-service服务中的OrderApplication启动类中,注册RestTemplate实例:
package cn.itcast.order;
import org.mybatis.spring.annotation.MapperScan;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
import org.springframework.context.annotation.Bean;
import org.springframework.web.client.RestTemplate;
@MapperScan("cn.itcast.order.mapper")
@SpringBootApplication
public class OrderApplication {
public static void main(String[] args) {
SpringApplication.run(OrderApplication.class, args);
}
@Bean
public RestTemplate restTemplate() {
return new RestTemplate();
}
}
2.3.3.实现远程调用
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法:

2.4.提供者与消费者
在服务调用关系中,会有两个不同的角色:
服务提供者:一次业务中,被其它微服务调用的服务。(提供接口给其它微服务)
服务消费者:一次业务中,调用其它微服务的服务。(调用其它微服务提供的接口)

但是,服务提供者与服务消费者的角色并不是绝对的,而是相对于业务而言。
如果服务A调用了服务B,而服务B又调用了服务C,服务B的角色是什么?
对于A调用B的业务而言:A是服务消费者,B是服务提供者
对于B调用C的业务而言:B是服务消费者,C是服务提供者
因此,服务B既可以是服务提供者,也可以是服务消费者。
3.Eureka注册中心 官方停更
假如我们的服务提供者user-service部署了多个实例,如图:

大家思考几个问题:
order-service在发起远程调用的时候,该如何得知user-service实例的ip地址和端口?
有多个user-service实例地址,order-service调用时该如何选择?
order-service如何得知某个user-service实例是否依然健康,是不是已经宕机?
3.1.Eureka的结构和作用
这些问题都需要利用SpringCloud中的注册中心来解决,其中最广为人知的注册中心就是Eureka,其结构如下:
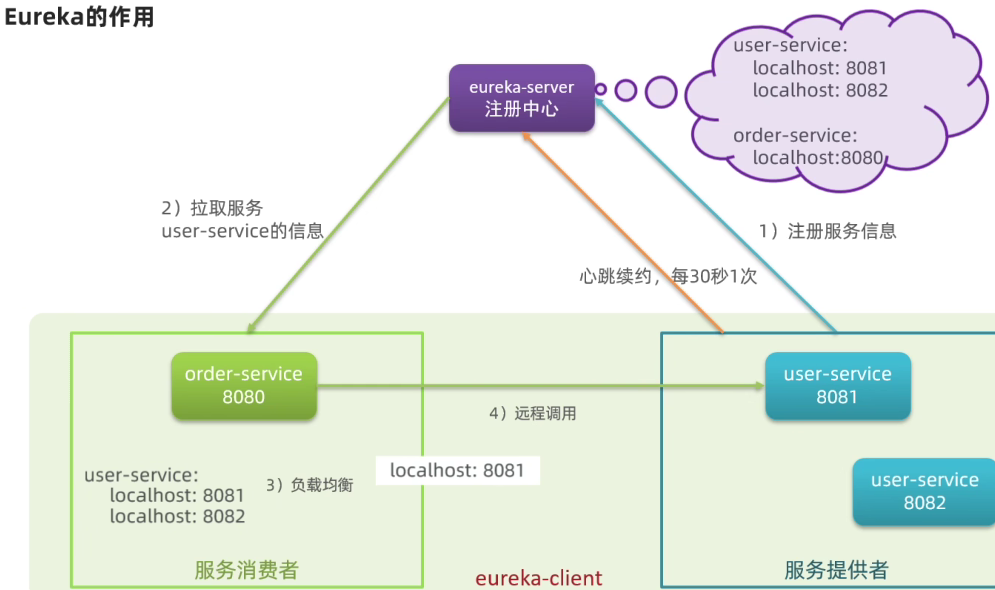


注意:一个微服务,既可以是服务提供者,又可以是服务消费者,因此eureka将服务注册、服务发现等功能统一封装到了eureka-client端
因此,接下来我们动手实践的步骤包括:
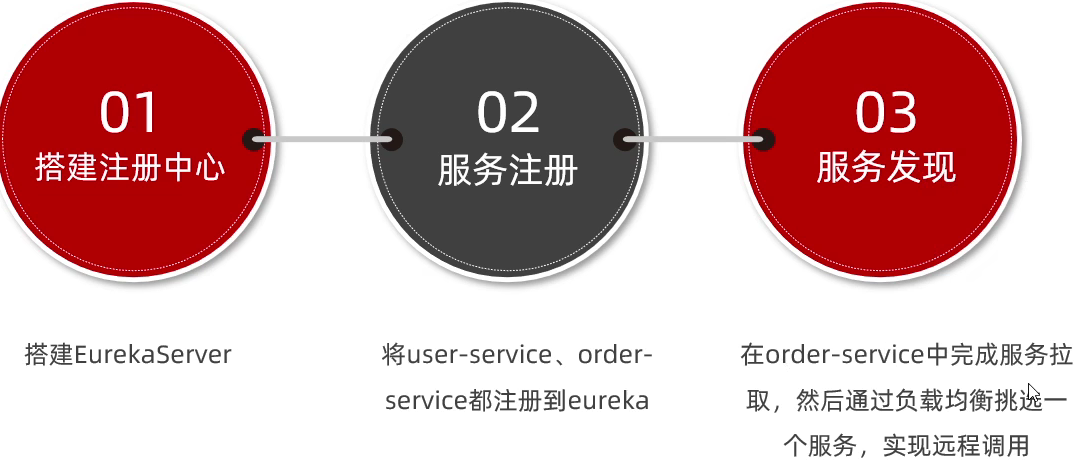
3.2.搭建eureka-server
首先大家注册中心服务端:eureka-server,这必须是一个独立的微服务
3.2.1.创建eureka-server服务
在cloud-demo父工程下,创建一个子模块:

3.2.2.引入eureka依赖
引入SpringCloud为eureka提供的starter依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-server</artifactId>
</dependency>3.2.3.编写启动类
给eureka-server服务编写一个启动类,一定要添加一个@EnableEurekaServer注解,开启eureka的注册中心功能:
@SpringBootApplication
@EnableEurekaServer
public class EurekaApplication {
public static void main(String[] args) {
SpringApplication.run(EurekaApplication.class, args);
}
}3.2.4.编写配置文件
编写一个application.yml文件,内容如下:
server:
port: 10086 # 服务端口
spring:
application:
name: eureka-server # Eureka服务名称
eureka:
client:
service-url: # Eureka地址信息
defaultZone: http://127.0.0.1:10086/eureka 3.2.5.启动服务
启动微服务,然后在浏览器访问:http://127.0.0.1:10086
看到下面结果应该是成功了:
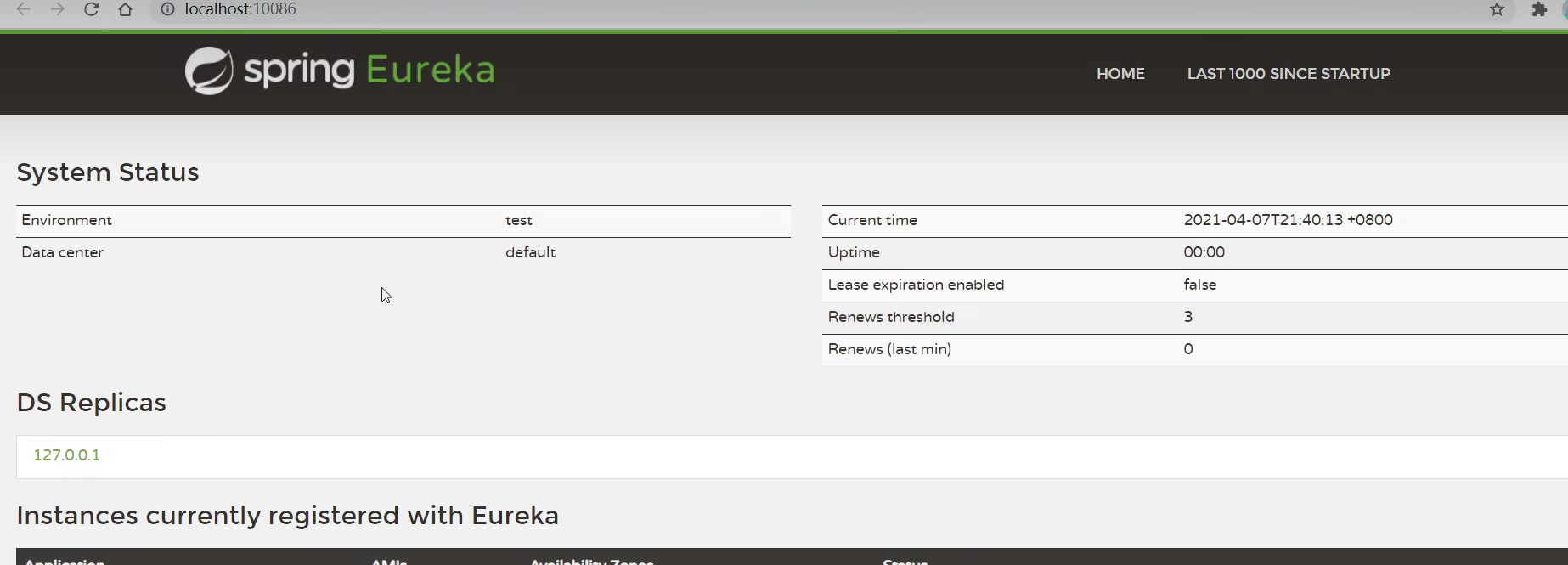
3.3.服务注册
下面,我们将user-service注册到eureka-server中去。
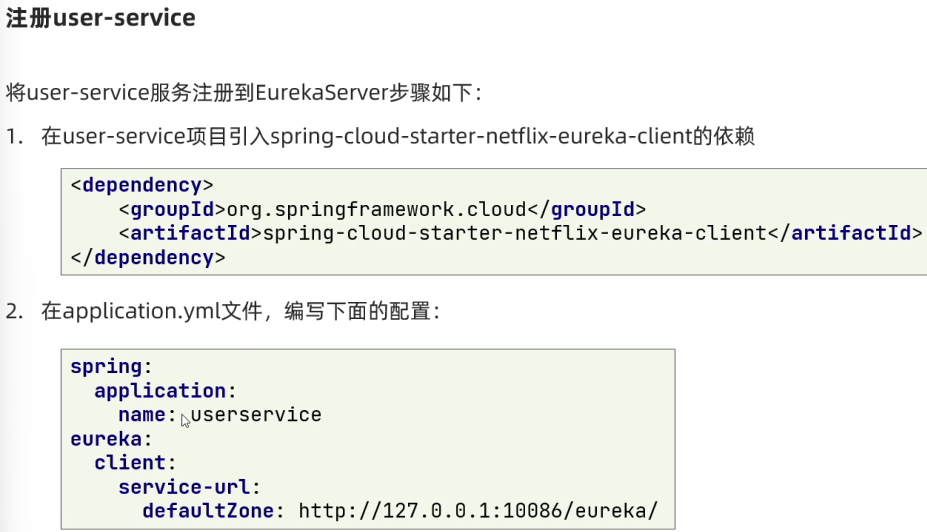
1)引入依赖
在user-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2)配置文件
在user-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: userservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka3)启动多个user-service实例
为了演示一个服务有多个实例的场景,我们添加一个SpringBoot的启动配置,再启动一个user-service。
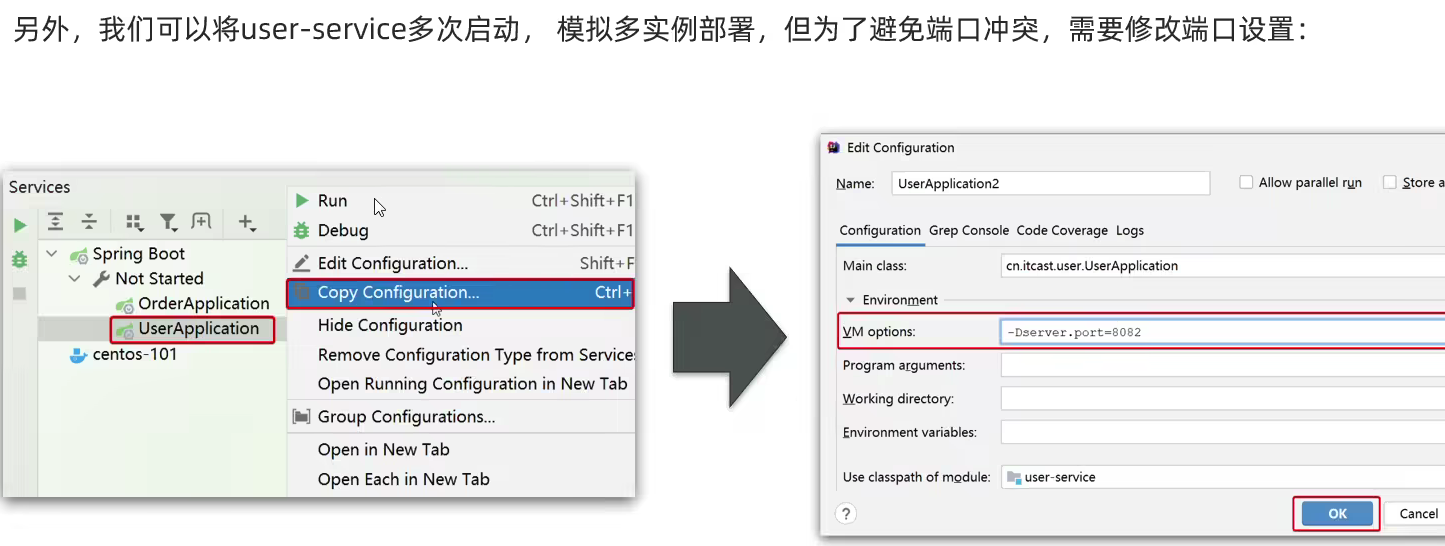
首先,复制原来的user-service启动配置:
然后,在弹出的窗口中,填写信息:
现在,SpringBoot窗口会出现两个user-service启动配置:
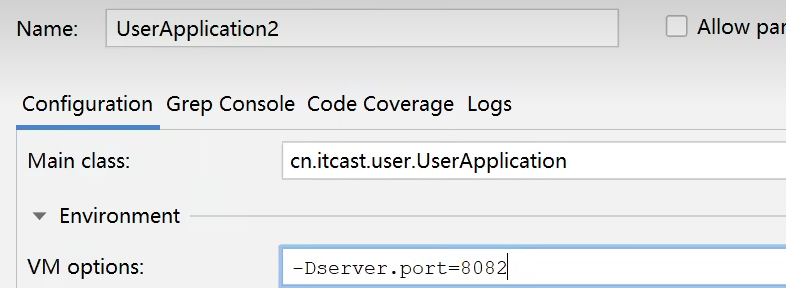
不过,第一个是8081端口,第二个是8082端口。
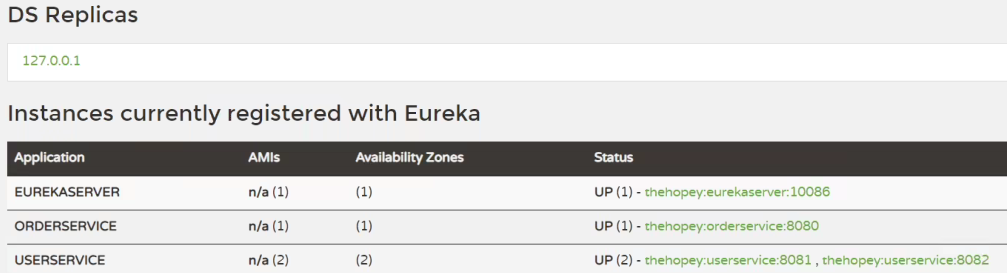
启动两个user-service实例:
查看eureka-server管理页面:

3.4.服务发现
下面,我们将order-service的逻辑修改:向eureka-server拉取user-service的信息,实现服务发现。
1)引入依赖
之前说过,服务发现、服务注册统一都封装在eureka-client依赖,因此这一步与服务注册时一致。
在order-service的pom文件中,引入下面的eureka-client依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-netflix-eureka-client</artifactId>
</dependency>2)配置文件
服务发现也需要知道eureka地址,因此第二步与服务注册一致,都是配置eureka信息:
在order-service中,修改application.yml文件,添加服务名称、eureka地址:
spring:
application:
name: orderservice
eureka:
client:
service-url:
defaultZone: http://127.0.0.1:10086/eureka3)服务拉取和负载均衡
最后,我们要去eureka-server中拉取user-service服务的实例列表,并且实现负载均衡。
不过这些动作不用我们去做,只需要添加一些注解即可。
在order-service的OrderApplication中,给RestTemplate这个Bean添加一个@LoadBalanced注解:
修改order-service服务中的cn.itcast.order.service包下的OrderService类中的queryOrderById方法。修改访问的url路径,用服务名代替ip、端口:

spring会自动帮助我们从eureka-server端,根据userservice这个服务名称,获取实例列表,而后完成负载均衡。

4.Ribbon负载均衡
上一节中,我们添加了@LoadBalanced注解,即可实现负载均衡功能,这是什么原理呢?
4.1.负载均衡原理
SpringCloud底层其实是利用了一个名为Ribbon的组件,来实现负载均衡功能的。
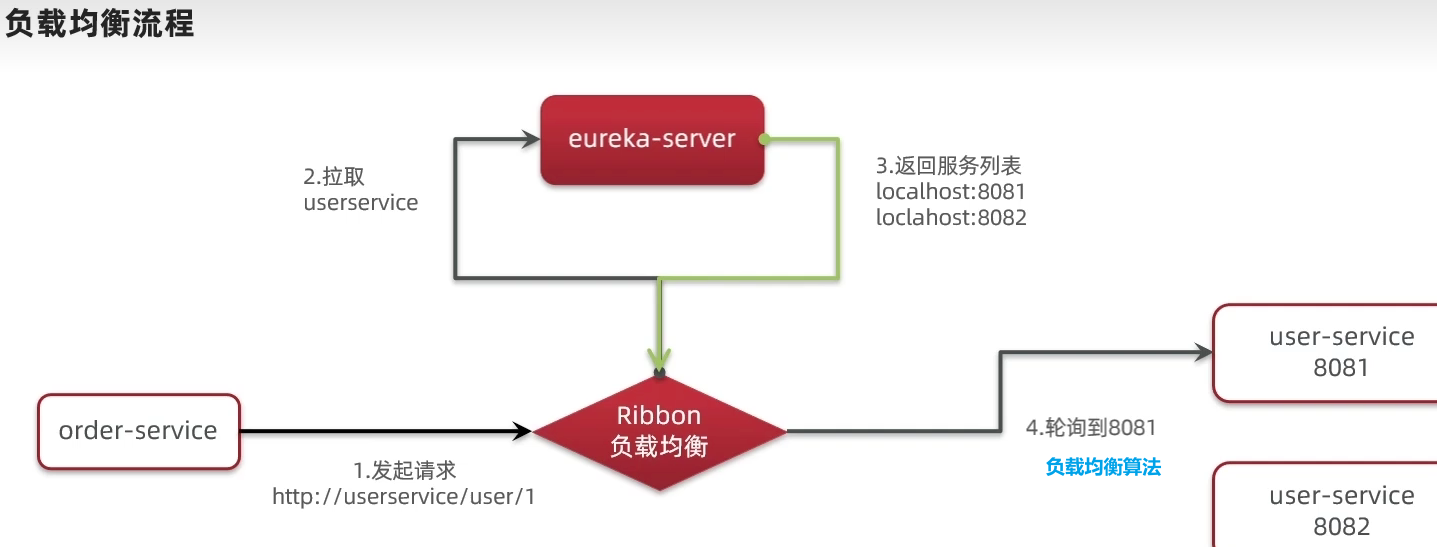
那么我们发出的请求明明是http://userservice/user/1,怎么变成了http://localhost:8081的呢?
4.2.源码跟踪
为什么我们只输入了service名称就可以访问了呢?之前还要获取ip和端口。
显然有人帮我们根据service名称,获取到了服务实例的ip和端口。它就是LoadBalancerInterceptor,这个类会在对RestTemplate的请求进行拦截,然后从Eureka根据服务id获取服务列表,随后利用负载均衡算法得到真实的服务地址信息,替换服务id。
我们进行源码跟踪:
LoadBalancerIntercepor
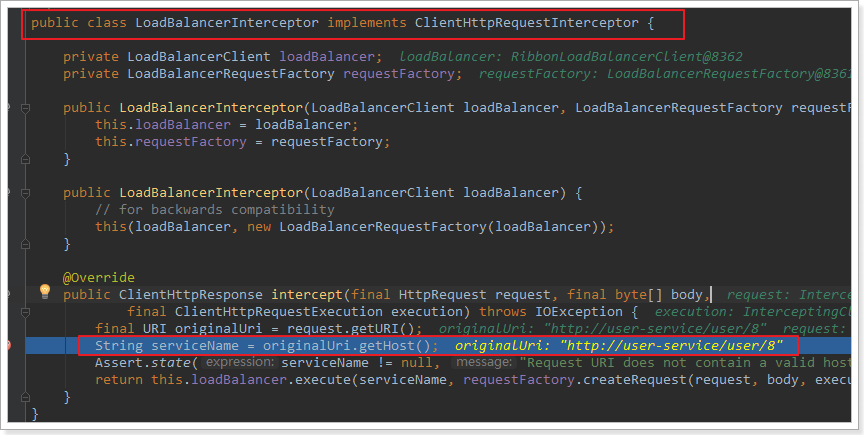
可以看到这里的intercept方法,拦截了用户的HttpRequest请求,然后做了几件事:
request.getURI():获取请求uri,本例中就是 http://user-service/user/8
originalUri.getHost():获取uri路径的主机名,其实就是服务id,user-service
this.loadBalancer.execute():处理服务id,和用户请求。
这里的this.loadBalancer是LoadBalancerClient类型,我们继续跟入。
2)LoadBalancerClient
继续跟入execute方法:
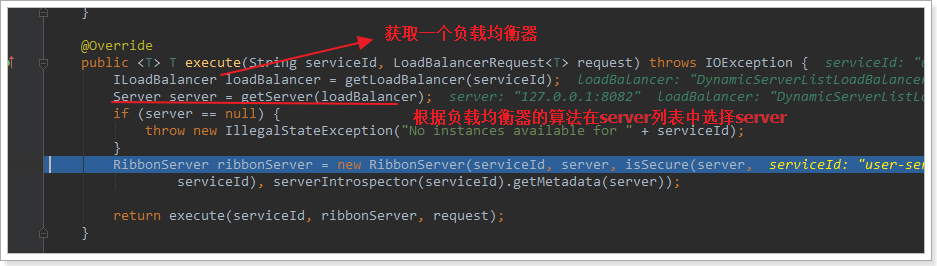
代码是这样的:
getLoadBalancer(serviceId):根据服务id获取ILoadBalancer,而ILoadBalancer会拿着服务id去eureka中获取服务列表并保存起来。
getServer(loadBalancer):利用内置的负载均衡算法,从服务列表中选择一个。本例中,可以看到获取了8082端口的服务
放行后,再次访问并跟踪,发现获取的是8081:
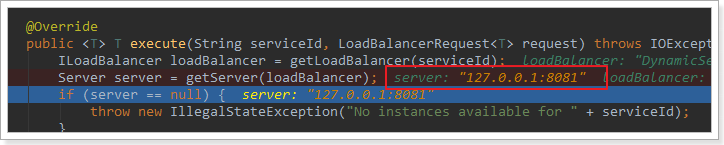
果然实现了负载均衡。
3)负载均衡策略IRule
在刚才的代码中,可以看到获取服务使通过一个getServer方法来做负载均衡:
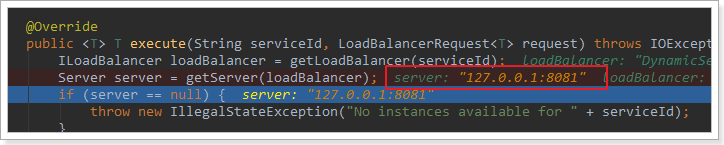
我们继续跟入:
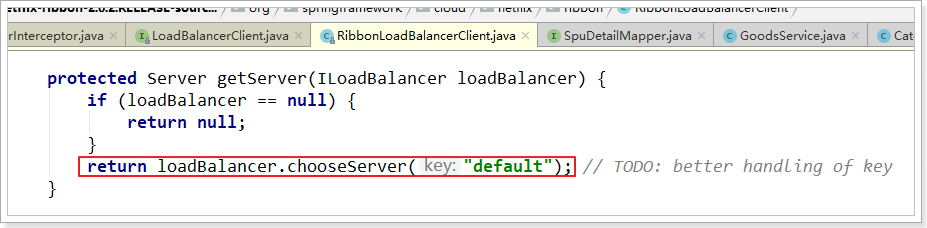
继续跟踪源码chooseServer方法,发现这么一段代码:
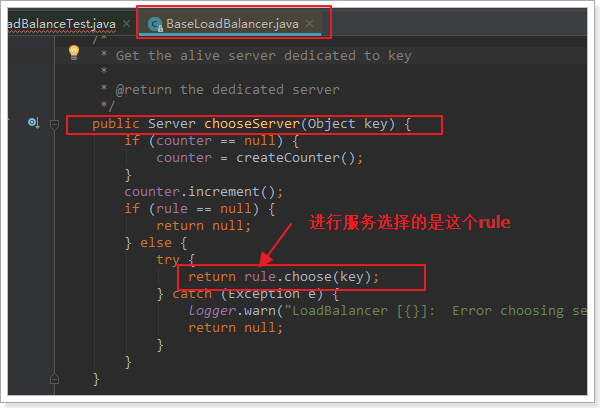
我们看看这个rule是谁:
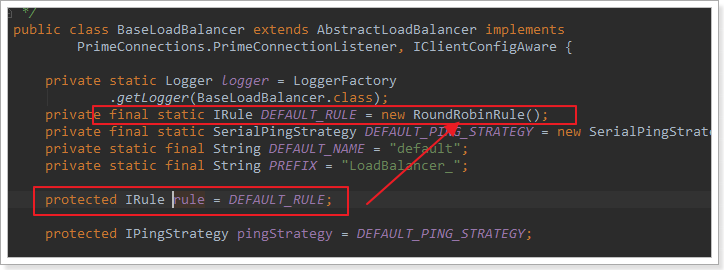
这里的rule默认值是一个RoundRobinRule,看类的介绍:
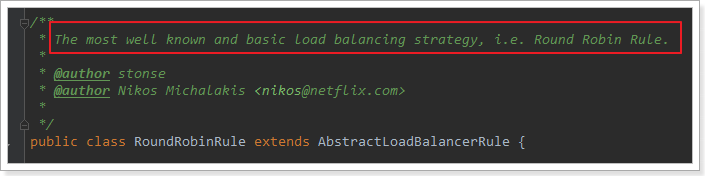
这不就是轮询的意思嘛。
到这里,整个负载均衡的流程我们就清楚了。
4)总结
SpringCloudRibbon的底层采用了一个拦截器,拦截了RestTemplate发出的请求,对地址做了修改。用一幅图来总结一下:
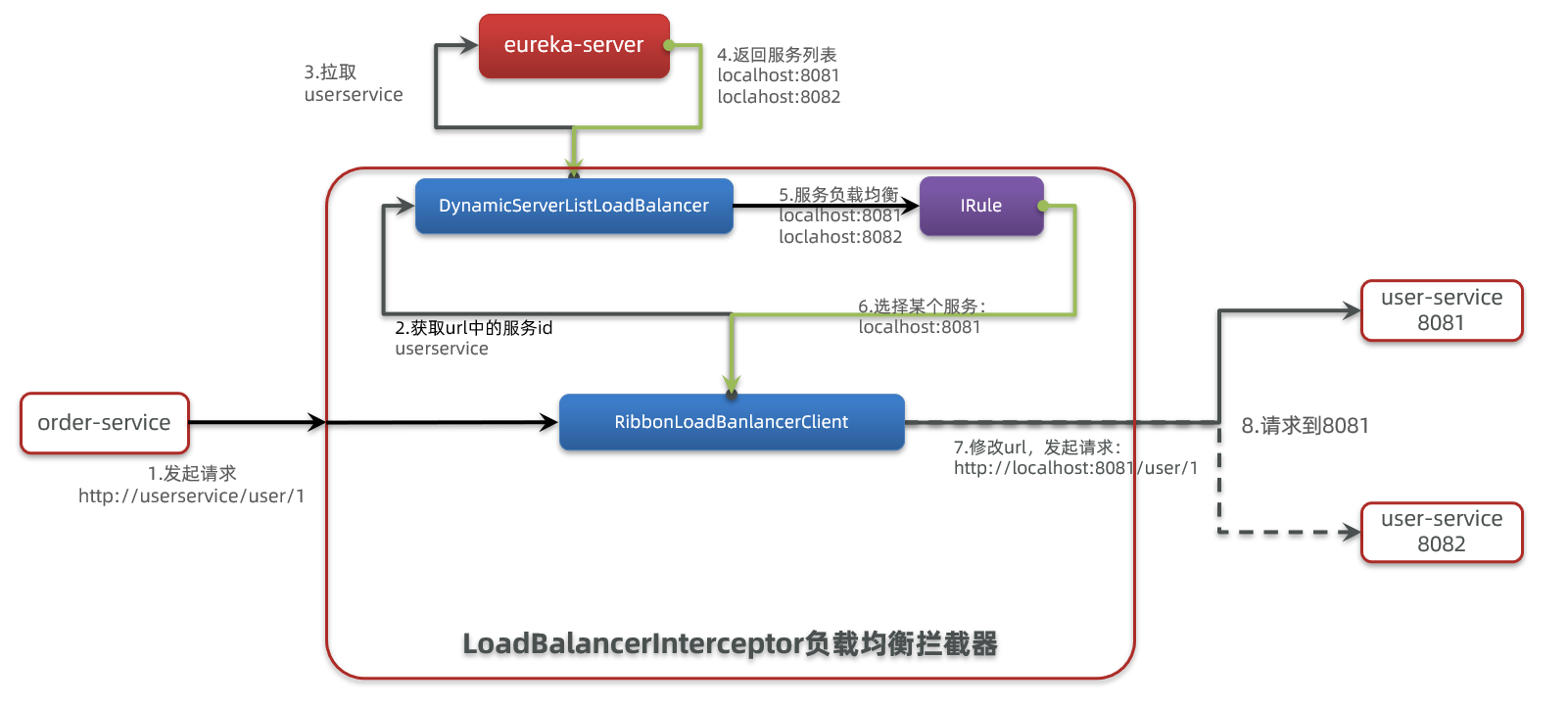
基本流程如下:
拦截我们的RestTemplate请求http://userservice/user/1
RibbonLoadBalancerClient会从请求url中获取服务名称,也就是user-service
DynamicServerListLoadBalancer根据user-service到eureka拉取服务列表
eureka返回列表,localhost:8081、localhost:8082
IRule利用内置负载均衡规则,从列表中选择一个,例如localhost:8081
RibbonLoadBalancerClient修改请求地址,用localhost:8081替代userservice,得到http://localhost:8081/user/1,发起真实请求
4.3.负载均衡策略
4.3.1.负载均衡策略
负载均衡的规则都定义在IRule接口中,而IRule有很多不同的实现类,每一个子接口都是一种规则:
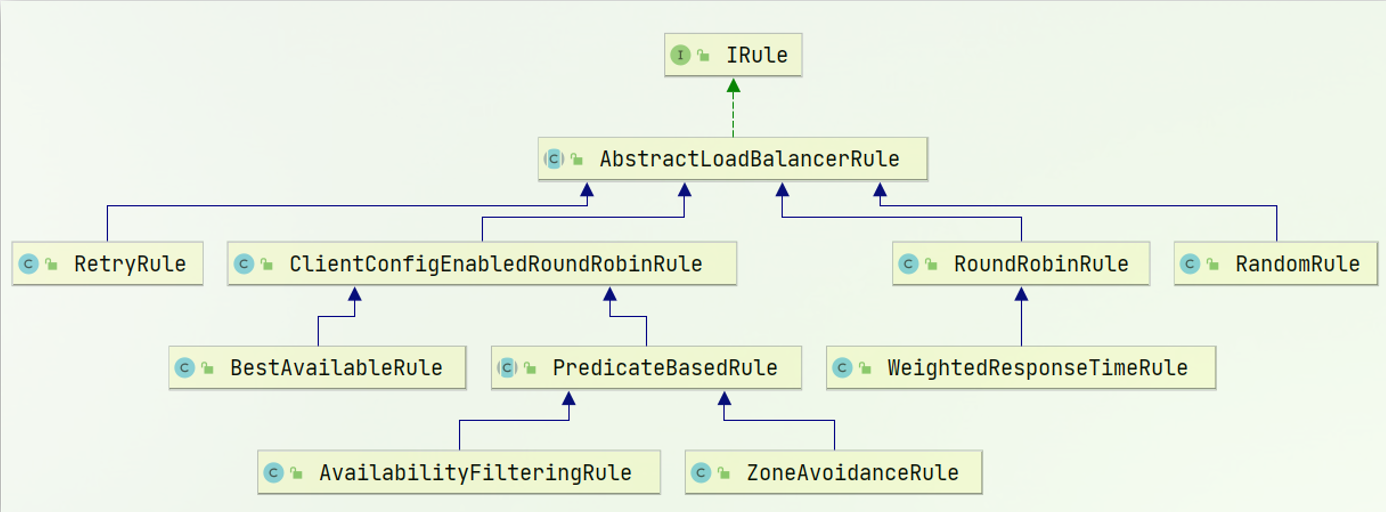
不同规则的含义如下:
内置负载均衡规则类 | 规则描述 |
RoundRobinRule | 简单轮询服务列表来选择服务器。它是Ribbon默认的负载均衡规则。 |
AvailabilityFilteringRule | 对以下两种服务器进行忽略: (1)在默认情况下,这台服务器如果3次连接失败,这台服务器就会被设置为“短路”状态。短路状态将持续30秒,如果再次连接失败,短路的持续时间就会几何级地增加。 (2)并发数过高的服务器。如果一个服务器的并发连接数过高,配置了AvailabilityFilteringRule规则的客户端也会将其忽略。并发连接数的上限,可以由客户端的 . .ActiveConnectionsLimit属性进行配置。 |
WeightedResponseTimeRule | 为每一个服务器赋予一个权重值。服务器响应时间越长,这个服务器的权重就越小。这个规则会随机选择服务器,这个权重值会影响服务器的选择。 |
ZoneAvoidanceRule | 以区域可用的服务器为基础进行服务器的选择。使用Zone对服务器进行分类,这个Zone可以理解为一个机房、一个机架等。而后再对Zone内的多个服务做轮询。 |
BestAvailableRule | 忽略那些短路的服务器,并选择并发数较低的服务器。 |
RandomRule | 随机选择一个可用的服务器。 |
RetryRule | 重试机制的选择逻辑 |
默认的实现就是ZoneAvoidanceRule,是一种轮询方案
4.3.2.自定义负载均衡策略
通过定义IRule实现可以修改负载均衡规则,有两种方式:
代码方式:在order-service中的OrderApplication类中,定义一个新的IRule:
@Bean
public IRule randomRule(){
return new RandomRule();
}配置文件方式:在order-service的application.yml文件中,添加新的配置也可以修改规则:
userservice: # 给某个微服务配置负载均衡规则,这里是userservice服务
ribbon: #代表给ribbon 配置负载均衡规则
NFLoadBalancerRuleClassName: com.netflix.loadbalancer.RandomRule # 负载均衡规则 注意,一般用默认的负载均衡规则,不做修改。
4.4.饥饿加载
Ribbon默认是采用懒加载,即第一次访问时才会去创建LoadBalanceClient,请求时间会很长。
而饥饿加载则会在项目启动时创建,降低第一次访问的耗时,通过下面配置开启饥饿加载:
ribbon:
eager-load:
enabled: true #开启饥饿加载
clients: #指定对userservice服务饥饿加载
- userservice 
5.Nacos注册中心
国内一般都推崇阿里巴巴,比如注册中心,SpringCloudAlibaba也推出了一个名为Nacos的注册中心。
5.1.认识和安装Nacos
Nacos是阿里巴巴的产品,现在是SpringCloud中的一个组件。相比Eureka功能更加丰富,在国内受欢迎程度较高。

安装方式可以参考课前资料《Nacos安装指南.md》
1.4.启动
启动非常简单,进入bin目录,结构如下:
然后执行命令即可:
windows命令:
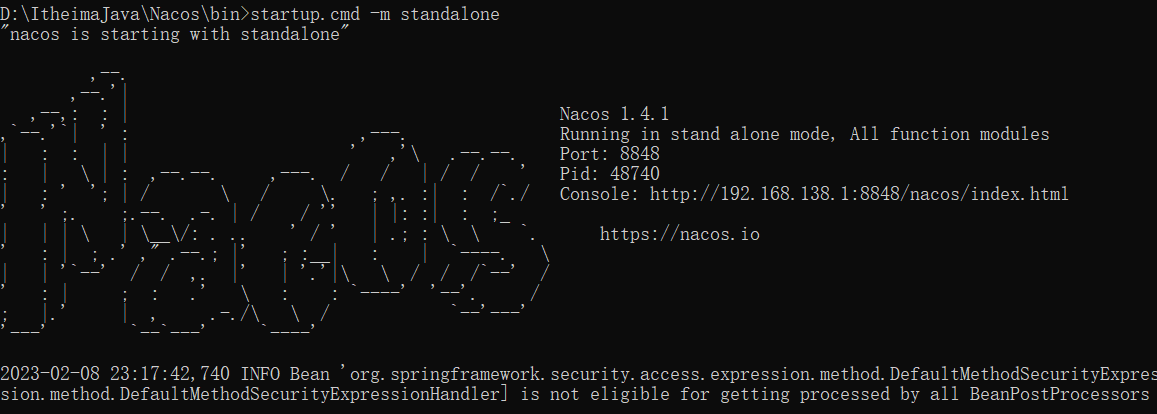
startup.cmd -m standalone
执行后的效果如图:
1.5.访问
在浏览器输入地址:http://127.0.0.1:8848/nacos即可:
点击console链接默认账号密码为:nacos
5.2.服务注册到nacos
Nacos是SpringCloudAlibaba的组件,而SpringCloudAlibaba也遵循SpringCloud中定义的服务注册、服务发现规范。因此使用Nacos和使用Eureka对于微服务来说,并没有太大区别。
主要差异在于:
依赖不同
服务地址不同
1)引入依赖
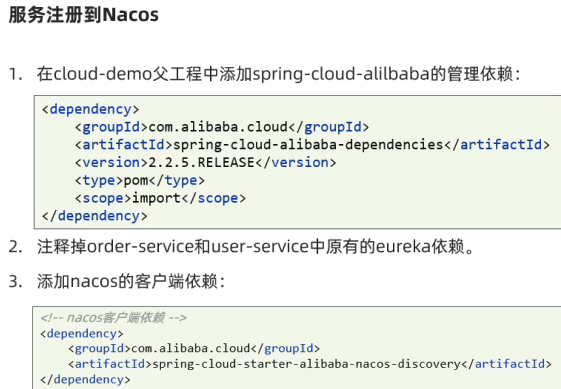
在cloud-demo父工程的pom文件中的<dependencyManagement>中引入SpringCloudAlibaba的依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-alibaba-dependencies</artifactId>
<version>2.2.6.RELEASE</version>
<type>pom</type>
<scope>import</scope>
</dependency>然后在user-service和order-service中的pom文件中引入nacos-discovery依赖:
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>注意:不要忘了注释掉eureka的依赖。
2)配置nacos地址
在user-service和order-service的application.yml中添加nacos地址:
spring:
cloud:
nacos:
server-addr: localhost:8848 #nacos服务地址注意:不要忘了注释掉eureka的地址
3)重启
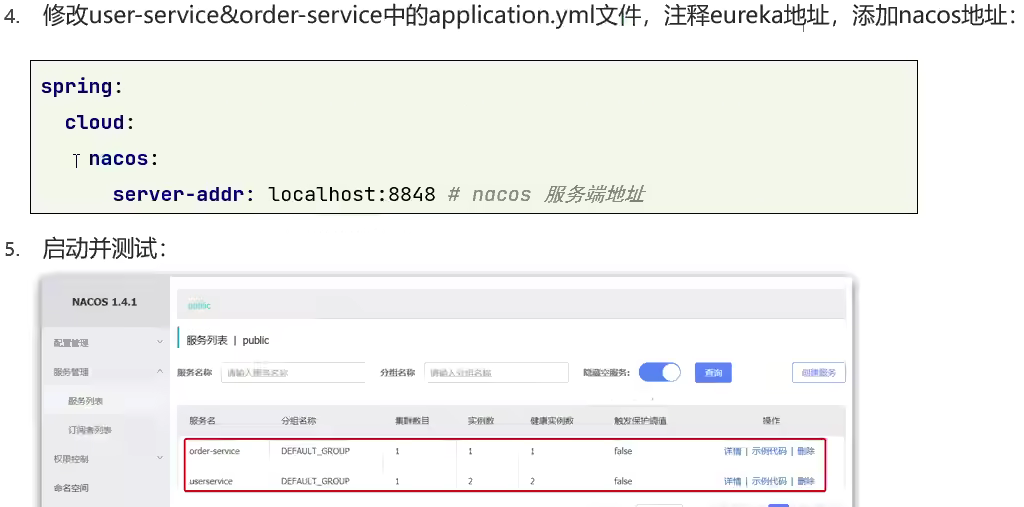
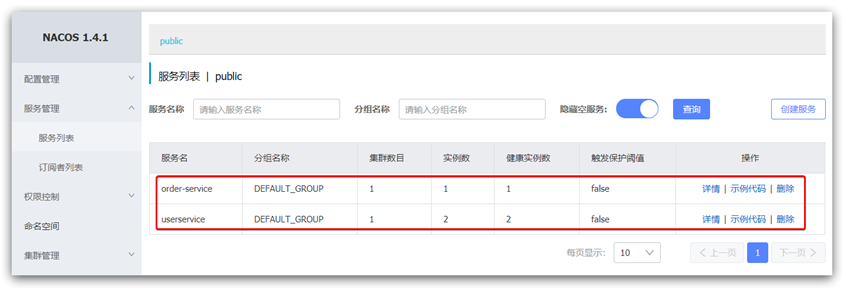
重启微服务后,登录nacos管理页面,可以看到微服务信息:
5.3.服务分级存储模型
一个服务可以有多个实例,例如我们的user-service,可以有:
127.0.0.1:8081
127.0.0.1:8082
127.0.0.1:8083
假如这些实例分布于全国各地的不同机房,例如:
127.0.0.1:8081,在上海机房
127.0.0.1:8082,在上海机房
127.0.0.1:8083,在杭州机房
Nacos就将同一机房内的实例 划分为一个集群。
也就是说,user-service是服务,一个服务可以包含多个集群,如杭州、上海,每个集群下可以有多个实例,形成分级模型,如图:

微服务互相访问时,应该尽可能访问同集群实例,因为本地访问速度更快。当本集群内不可用时,才访问其它集群。例如:
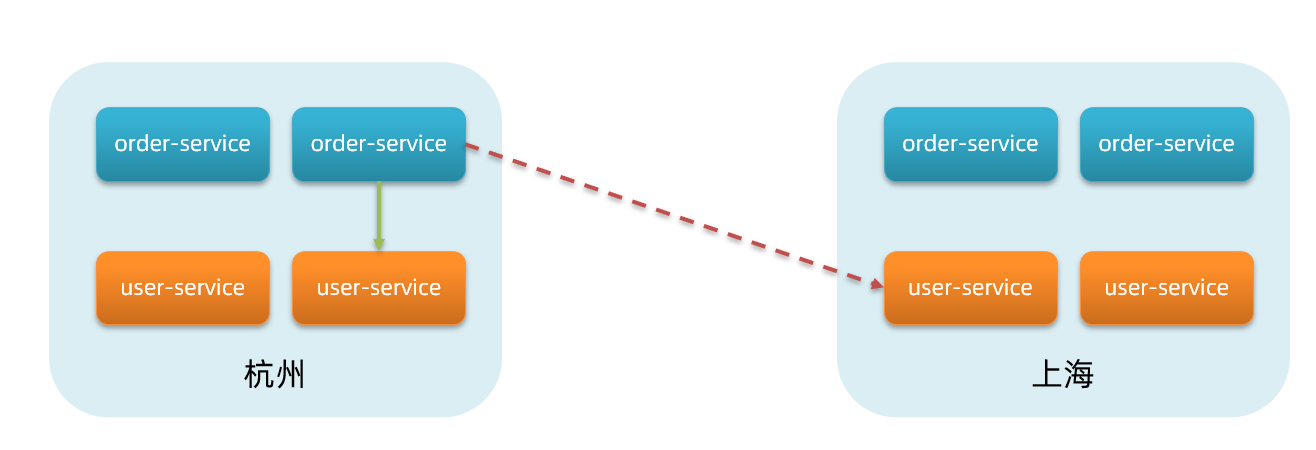
杭州机房内的order-service应该优先访问同机房的user-service。
5.3.1.给user-service配置集群
修改user-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848 #nacos 服务端地址
discovery:
cluster-name: HZ # 配置集群名称,也就是机房位置,例如:HZ:杭州重启两个user-service实例后,我们可以在nacos控制台看到下面结果:
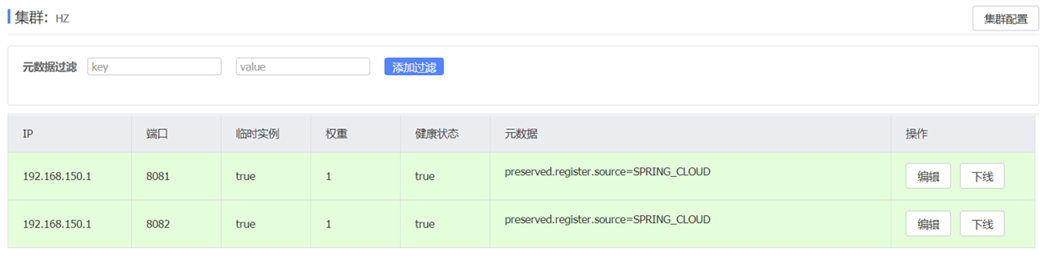

我们再次复制一个user-service启动配置,添加属性:
-Dserver.port=8083 -Dspring.cloud.nacos.discovery.cluster-name=SH配置如图所示:
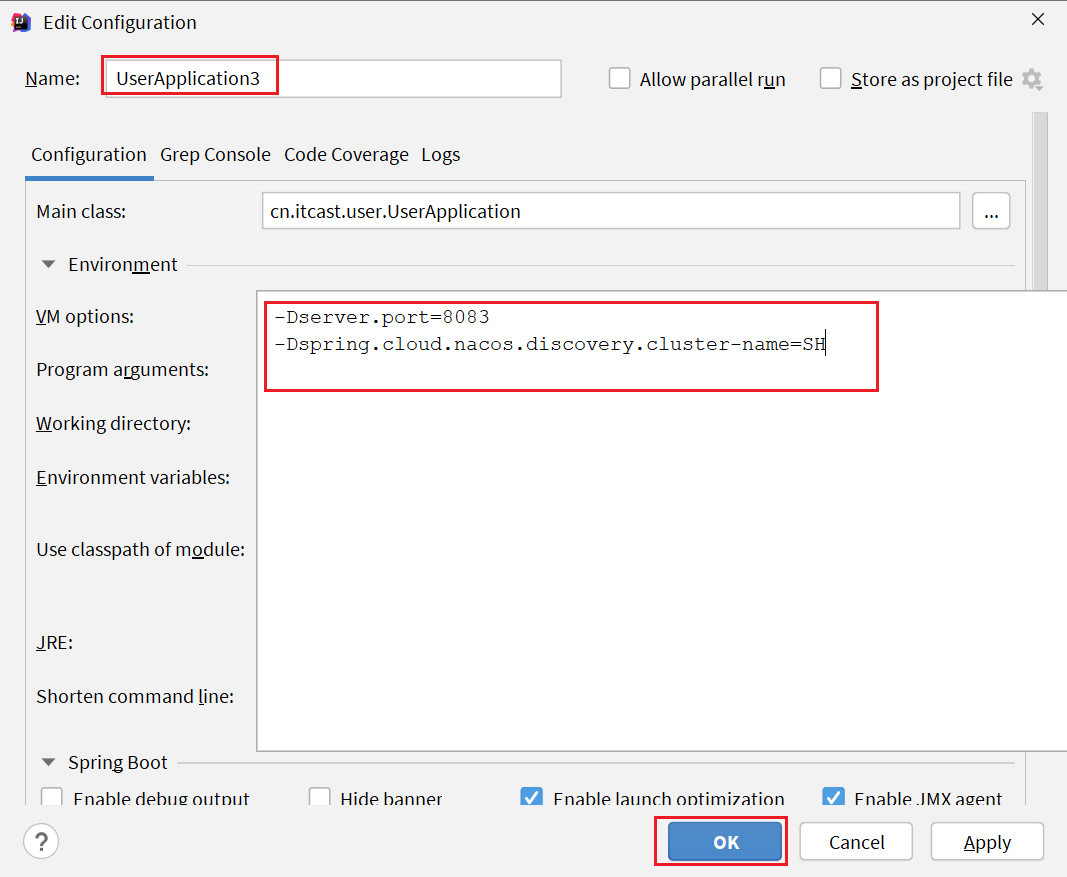
启动UserApplication3后再次查看nacos控制台:
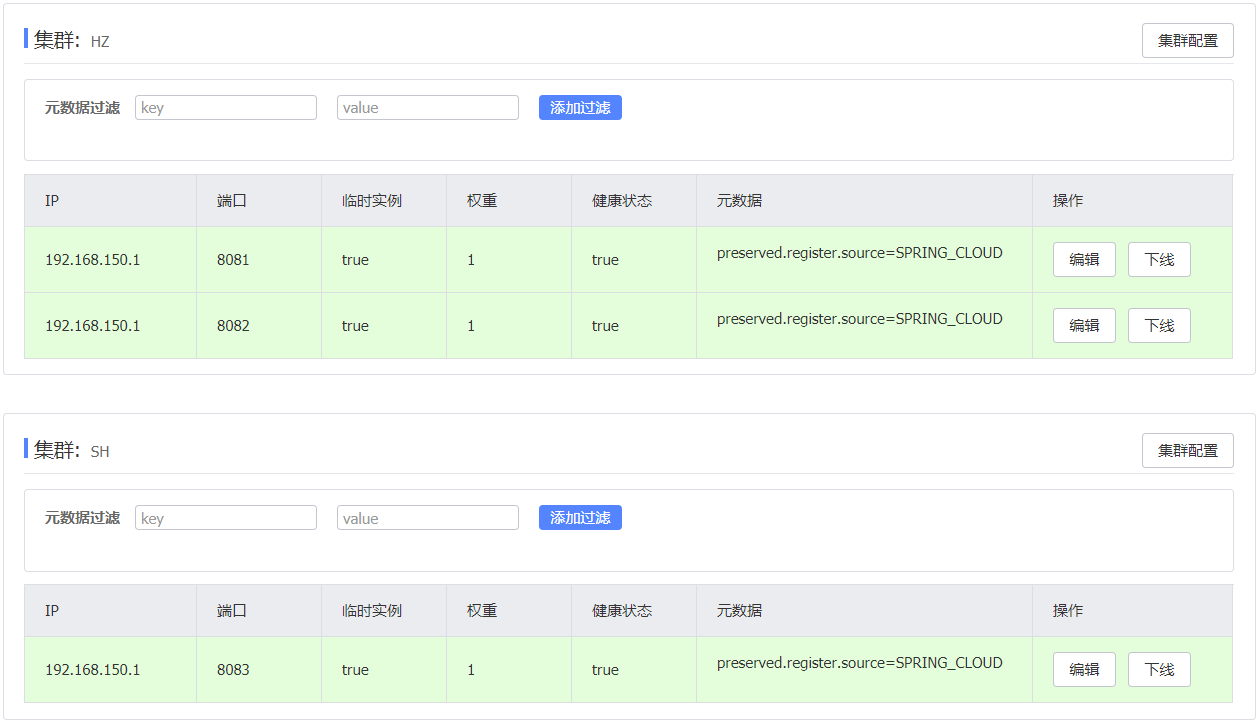
5.3.2.同集群优先的负载均衡
默认的ZoneAvoidanceRule并不能实现根据同集群优先来实现负载均衡。
因此Nacos中提供了一个NacosRule的实现,可以优先从同集群中挑选实例。
1)给order-service配置集群信息
修改order-service的application.yml文件,添加集群配置:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ # 集群名称2)修改负载均衡规则
修改order-service的application.yml文件,修改负载均衡规则:
userservice:
ribbon:
NFLoadBalancerRuleClassName: com.alibaba.cloud.nacos.ribbon.NacosRule # 负载均衡规则 
5.4.权重配置
实际部署中会出现这样的场景:
服务器设备性能有差异,部分实例所在机器性能较好,另一些较差,我们希望性能好的机器承担更多的用户请求。
但默认情况下NacosRule是同集群内随机挑选,不会考虑机器的性能问题。
因此,Nacos提供了权重配置来控制访问频率,权重越大则访问频率越高。
在nacos控制台,找到user-service的实例列表,点击编辑,即可修改权重:
在弹出的编辑窗口,修改权重:
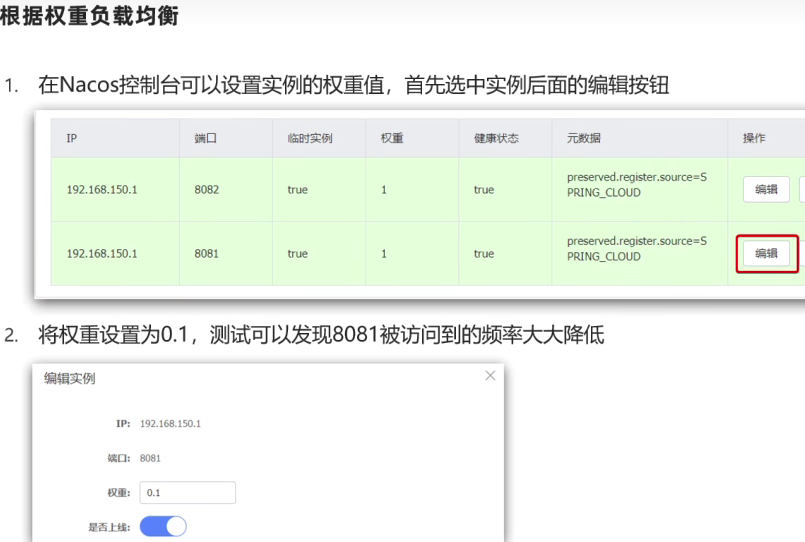
注意:如果权重修改为0,则该实例永远不会被访问
版本升级迭代的时候就可以让一个服务器权重=0;
等没有用户访问了,在这上面升级,然后重启,调整权重
5.5.环境隔离
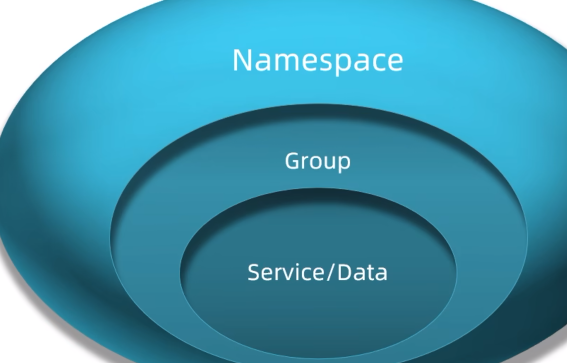
Nacos提供了namespace来实现环境(开发、测试...环境)隔离功能。
nacos中可以有多个namespace
namespace下可以有group(业务相关度比较高的放在一个Group)、service等
不同namespace之间相互隔离,例如不同namespace的服务互相不可见
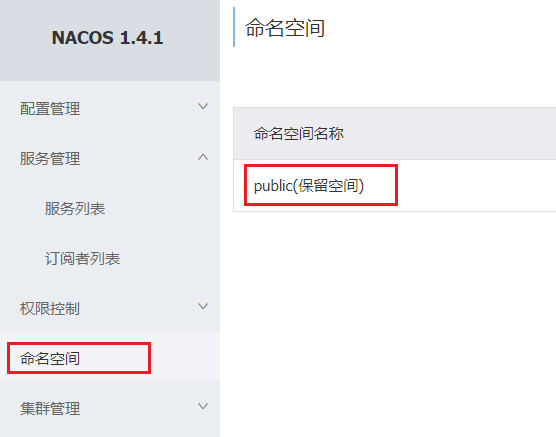
5.5.1.创建namespace
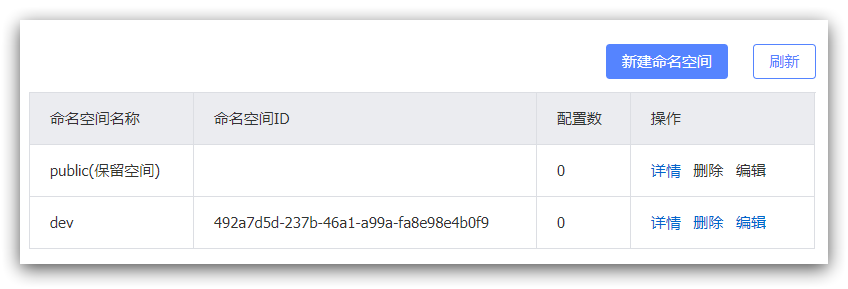
默认情况下,所有service、data、group都在同一个namespace,名为public:
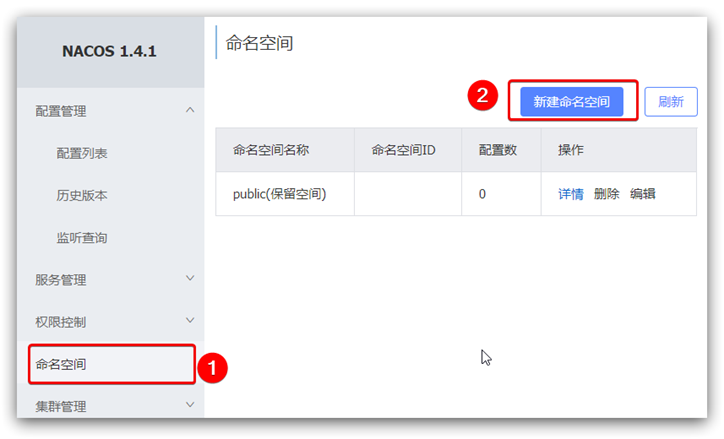
我们可以点击页面新增按钮,添加一个namespace:
然后,填写表单:
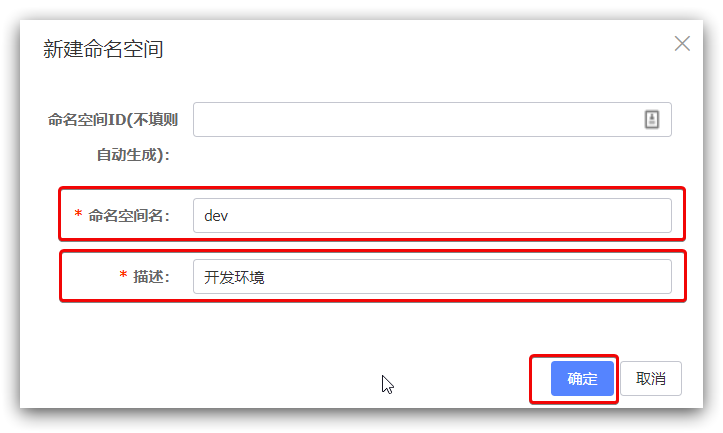
就能在页面看到一个新的namespace:
5.5.2.给微服务配置namespace
给微服务配置namespace只能通过修改配置来实现。
例如,修改order-service的application.yml文件:
spring:
cloud:
nacos:
server-addr: localhost:8848
discovery:
cluster-name: HZ
namespace: 492a7d5d-237b-46a1-a99a-fa8e98e4b0f9 # 命名空间,填ID重启order-service后,访问控制台,可以看到下面的结果:
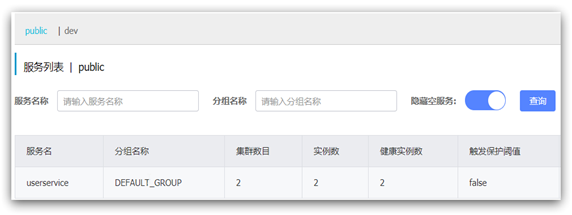
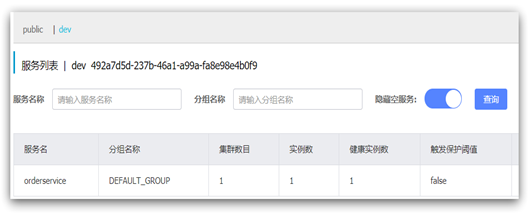
此时访问order-service,因为namespace不同,会导致找不到userservice,控制台会报错:

5.6.Nacos与Eureka的区别
Nacos的服务实例分为两种l类型:
临时实例:如果实例宕机超过一定时间,会从服务列表剔除,默认的类型。
非临时实例:如果实例宕机,不会从服务列表剔除,也可以叫永久实例。
配置一个服务实例为永久实例:
spring:
cloud:
nacos:
discovery:
ephemeral: false # 设置为非临时实例Nacos和Eureka整体结构类似,服务注册、服务拉取、心跳等待,但是也存在一些差异:
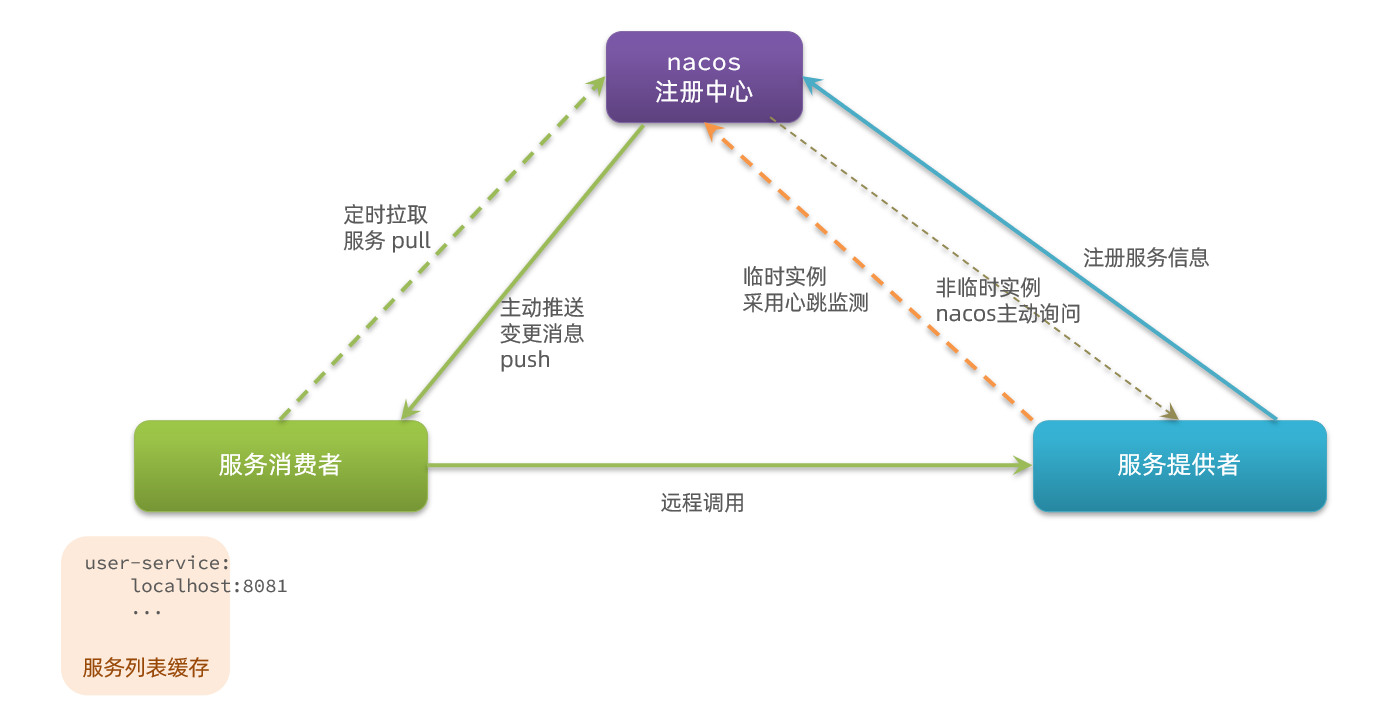
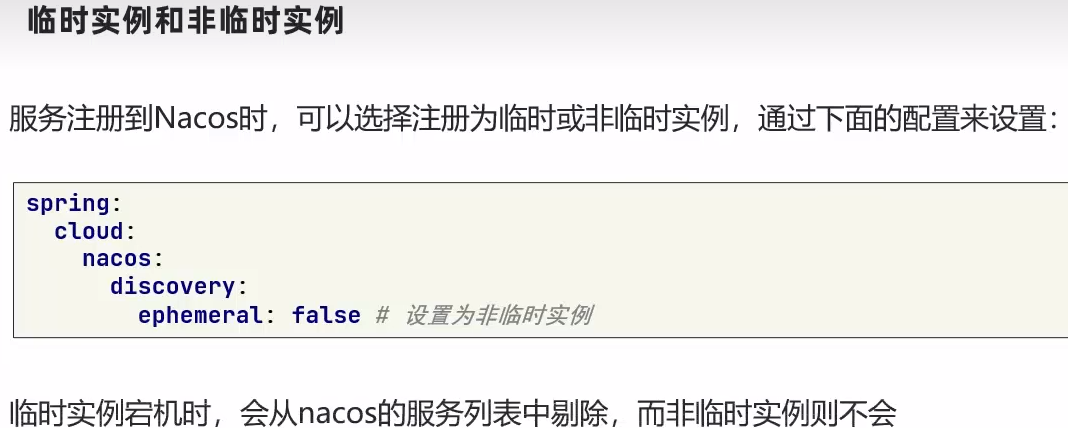
Nacos与eureka的共同点
都支持服务注册和服务拉取Pull
都支持服务提供者心跳方式做健康检测
Nacos与Eureka的区别
Nacos支持服务端主动检测提供者状态:
临时实例采用心跳模式,非临时实例采用主动检测(对服务器压力大)模式
临时实例心跳不正常会被剔除,非临时实例则不会被剔除
Nacos支持服务列表变更的消息推送Push模式,服务列表更新更及时
Eureka只支持定时拉取服务列表;
Nacos集群默认采用AP方式,当集群中存在非临时实例时,采用CP模式;Eureka采用AP方式
Markdown+Typora 解决CSDN导入md文件失败
我是真服了 我以为picgo下载插件必须用github;我不会用啊! 发现直接点击就能安装
PicGo本地导入插件
好不容易上传图床到gitee成功了,竟然显示由于网络问题或文件损坏 图片导入失败!!!毁灭吧!
SpringCloud实用篇02
0.学习目标
1.Nacos配置管理
Nacos除了可以做注册中心,同样可以做配置管理来使用。
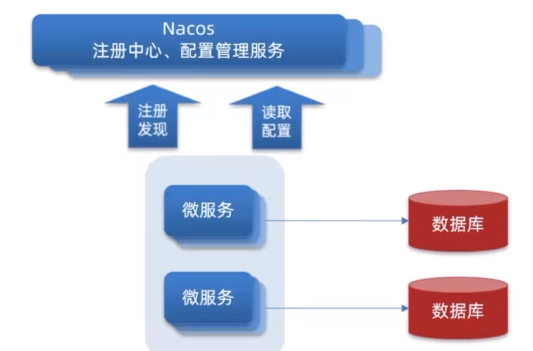
1.1.统一配置管理
当微服务部署的实例越来越多,达到数十、数百时,逐个修改微服务配置就会让人抓狂,而且很容易出错。我们需要一种统一配置管理方案,可以集中管理所有实例的配置。
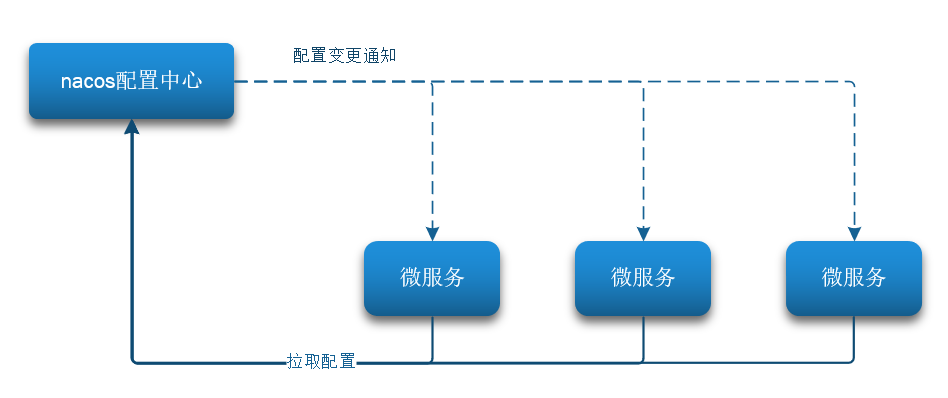
Nacos一方面可以将配置集中管理,另一方可以在配置变更时,及时通知微服务,实现配置的热更新。
1.1.1.在nacos中添加配置文件
如何在nacos中管理配置呢?
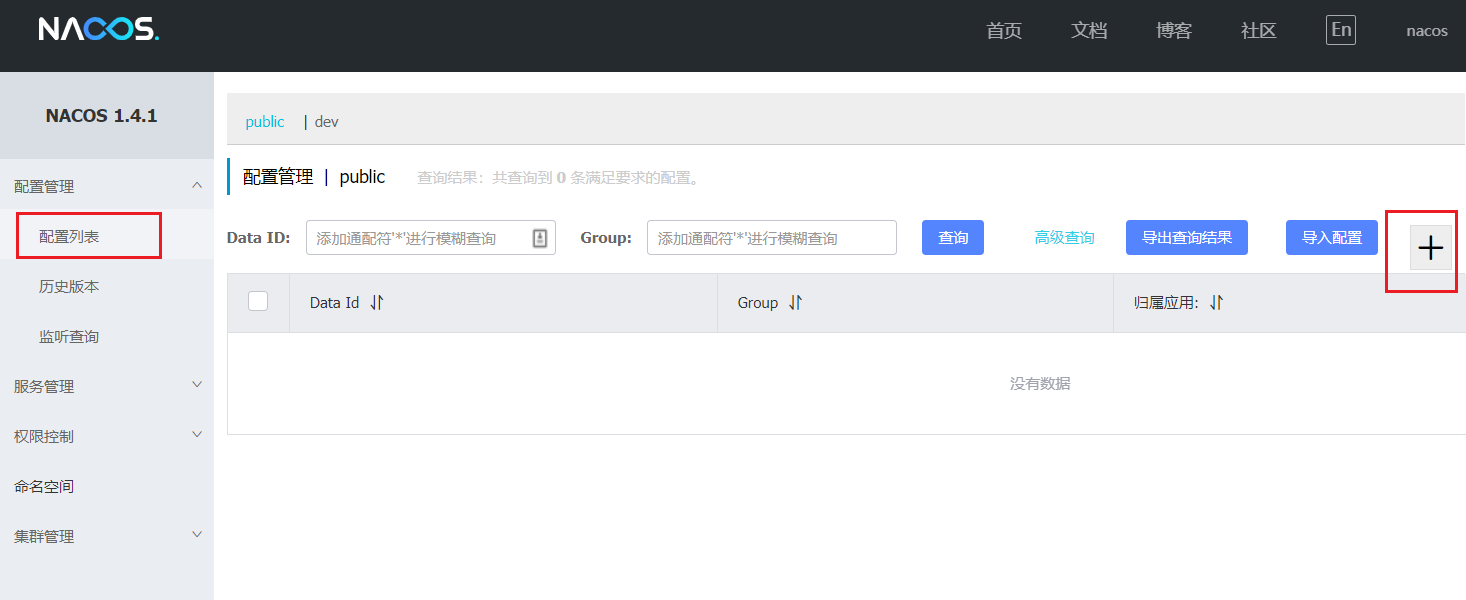
然后在弹出的表单中,填写配置信息:

注意:项目的核心配置, 需要热更新的配置才有放到nacos管理的必要。基本不会变更的一些配置还是保存在微服务本地比较好。
1.1.2.从微服务拉取配置
微服务要拉取nacos中管理的配置,并且与本地的application.yml配置合并,才能完成项目启动。
但如果尚未读取application.yml,又如何得知nacos地址呢?
因此spring引入了一种新的配置文件:bootstrap.yaml文件,会在application.yml之前被读取,流程如下:
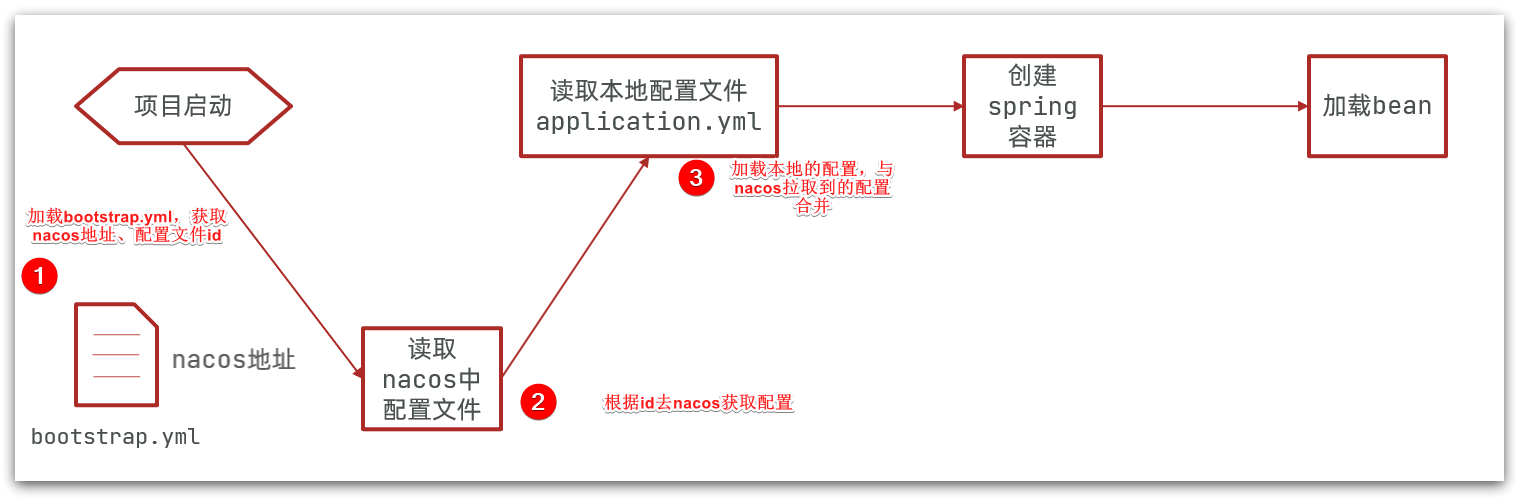
1)引入nacos-config依赖
首先,在user-service服务中,引入nacos-config的客户端依赖:
<!--nacos配置管理依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-config</artifactId>
</dependency>2)添加bootstrap.yaml
在user-service中添加一个bootstrap.yaml文件,引导文件,优先级高于application.yml内容如下:
spring:
application:
name: userservice # 服务名称
profiles:
active: dev #开发环境,这里是dev
cloud:
nacos:
server-addr: localhost:8848 # Nacos地址
config:
file-extension: yaml # 文件后缀名这里会根据spring.cloud.nacos.server-addr获取nacos地址,再根据
${spring.application.name}-${spring.profiles.active}.${spring.cloud.nacos.config.file-extension}作为文件id,来读取配置。
本例中,就是去读取userservice-dev.yaml:

3)读取nacos配置
在user-service中的UserController中添加业务逻辑,读取pattern.dateformat配置:
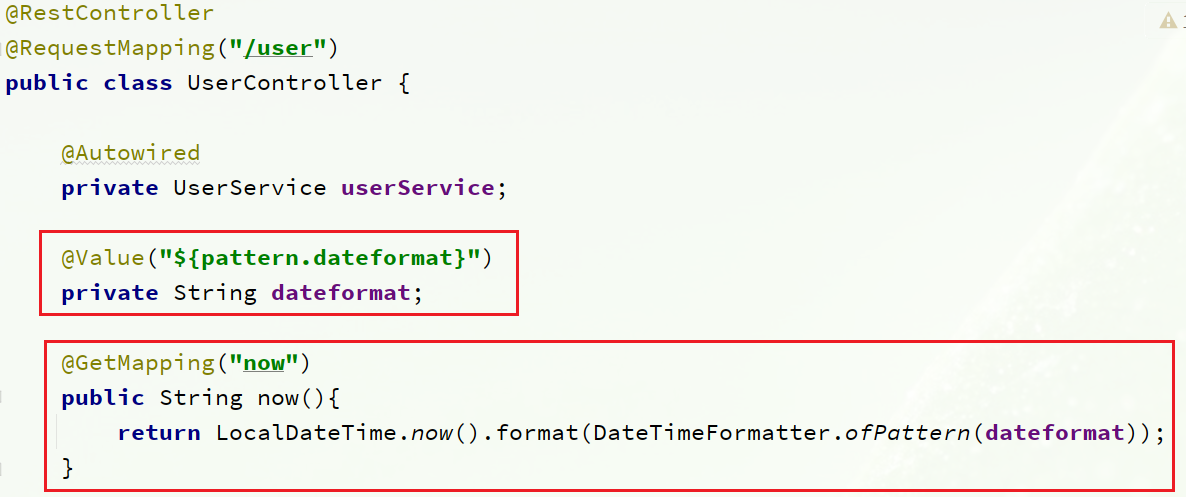
完整代码:
package cn.itcast.user.web;
import ...;
import java.time.format.DateTimeFormatter;
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Value("${pattern.dateformat}")
private String dateformat;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(dateformat));
}
// ...略
}在页面访问,可以看到效果:


1.2.配置热更新
我们最终的目的,是修改nacos中的配置后,微服务中无需重启即可让配置生效,也就是配置热更新。
要实现配置热更新,可以使用两种方式:
1.2.1.方式一
在@Value注入的变量所在类上添加注解@RefreshScope:

1.2.2.方式二
使用@ConfigurationProperties注解代替@Value注解。
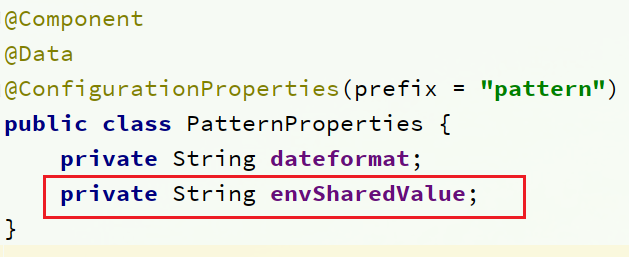
在user-service服务中,添加一个类,读取patterrn.dateformat属性:

package cn.itcast.user.config;
import lombok.Data;
@Component //注册成spring的Bean
@Data //提供getset方法
@ConfigurationProperties(prefix = "pattern")
public class PatternProperties {
private String dateformat;
}在UserController中使用这个类代替@Value:
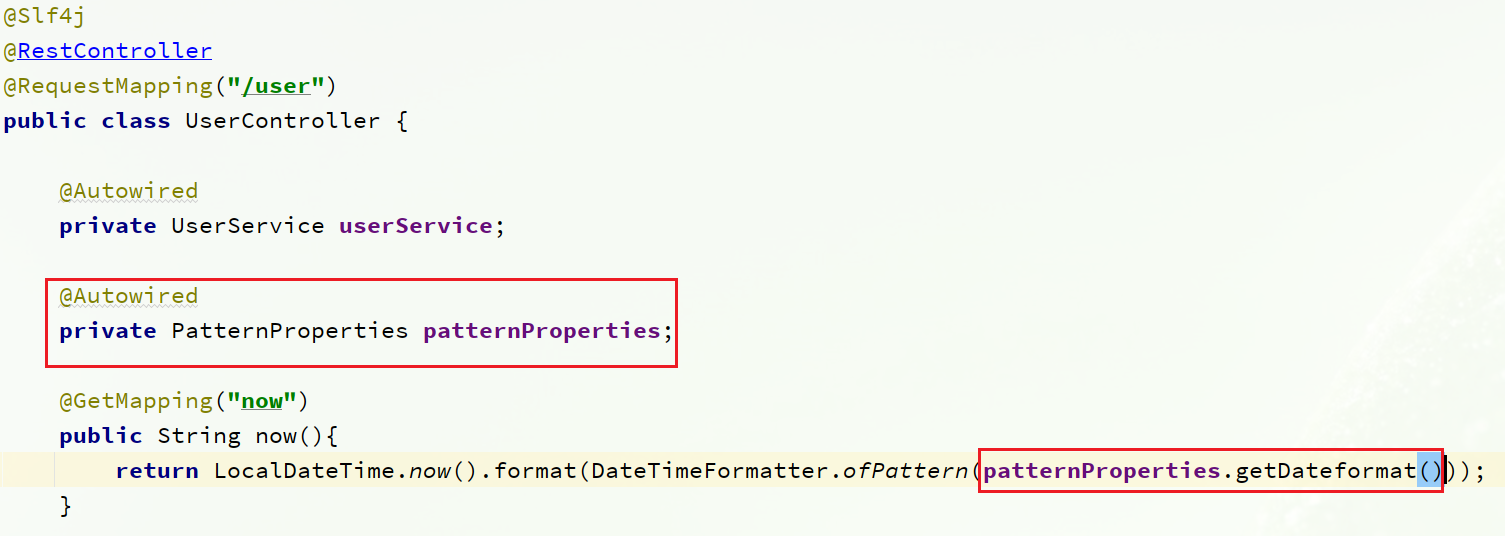
完整代码:
package cn.itcast.user.web;
import java.time.LocalDateTime;
import java.time.format.DateTimeFormatter;
@Slf4j
@RestController
@RequestMapping("/user")
public class UserController {
@Autowired
private UserService userService;
@Autowired
private PatternProperties patternProperties;
@GetMapping("now")
public String now(){
return LocalDateTime.now().format(DateTimeFormatter.ofPattern(patternProperties.getDateformat()));
}
// 略
}
1.3.配置共享
其实微服务启动时,会去nacos读取多个配置文件,例如:
[spring.application.name]-[spring.profiles.active].yaml,例如:userservice-dev.yaml
[spring.application.name].yaml,例如:userservice.yaml
而[spring.application.name].yaml不包含环境,因此可以被多个环境共享。
下面我们通过案例来测试配置共享
1)添加一个环境共享配置
我们在nacos中添加一个userservice.yaml文件:
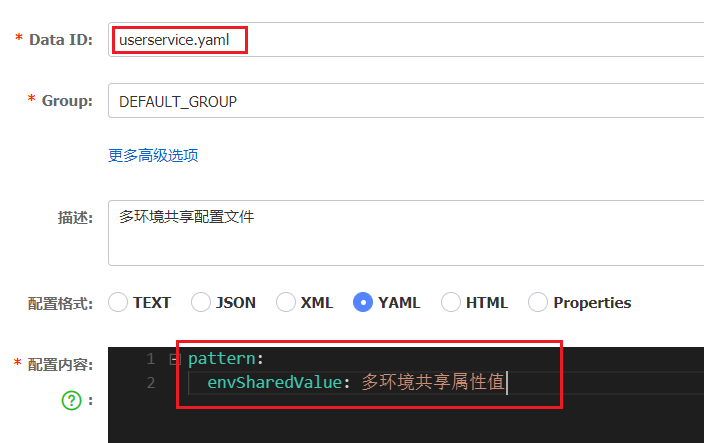
2)在user-service中读取共享配置
在user-service服务中,修改PatternProperties类,读取新添加的属性:
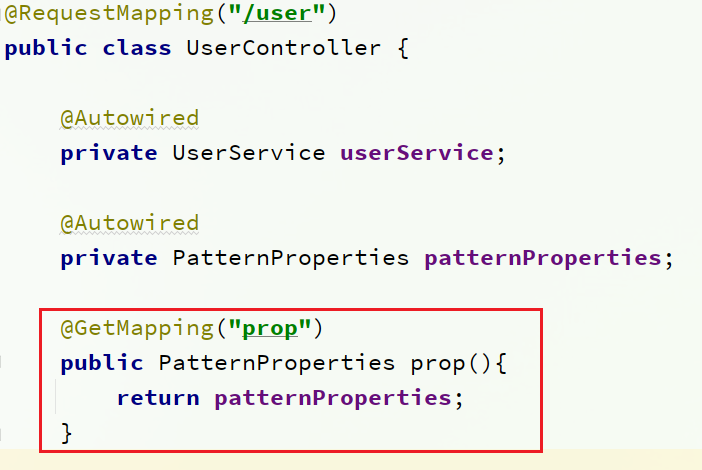
在user-service服务中,修改UserController,添加一个方法:
3)运行两个UserApplication,使用不同的profile
修改UserApplication2这个启动项,改变其profile值:
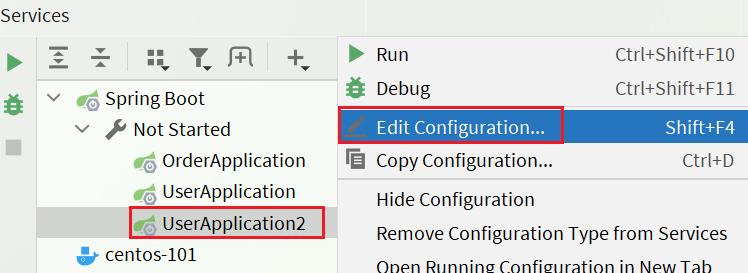
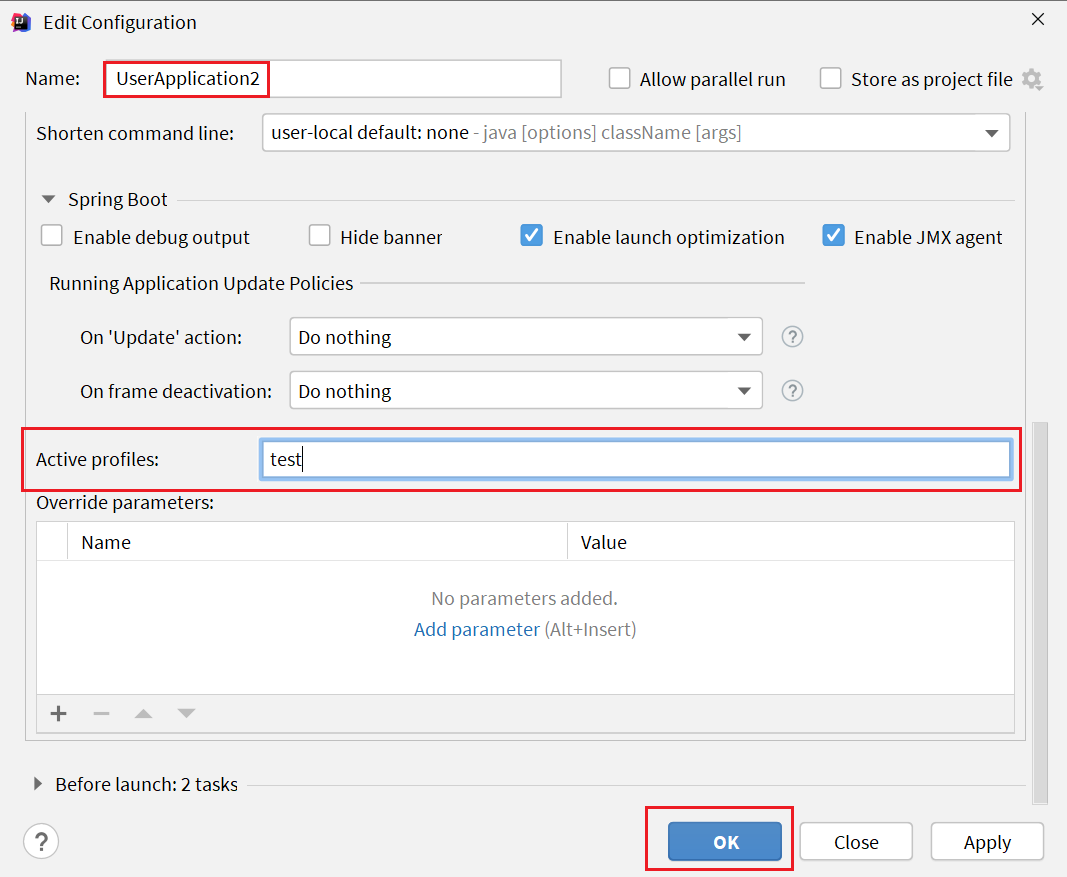
这样,UserApplication(8081)使用的profile是dev,UserApplication2(8082)使用的profile是test。
启动UserApplication和UserApplication2
访问http://localhost:8081/user/prop,结果:
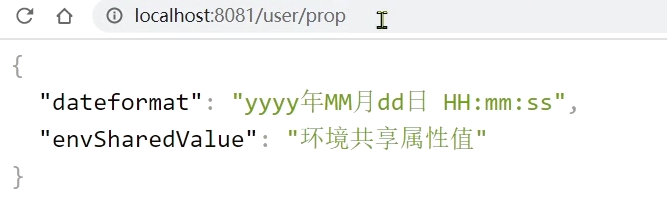
访问http://localhost:8082/user/prop,结果:

可以看出来,不管是dev,还是test环境,都读取到了envSharedValue这个属性的值。
配置共享的优先级

当nacos、服务本地同时出现相同属性时,优先级有高低之分:

1.4.搭建Nacos集群
Nacos生产环境下一定要部署为集群状态,部署方式参考课前资料中的文档:
没看这个P29 感觉企业篇再看吧
2.Feign远程调用
先来看我们以前利用RestTemplate发起远程调用的代码:

存在下面的问题:
•代码可读性差,编程体验不统一
•参数复杂URL难以维护
Feign是一个声明式的http客户端,官方地址:https://github.com/OpenFeign/feign
其作用就是帮助我们优雅的实现http请求的发送,解决上面提到的问题。
2.1.Feign替代RestTemplate
Fegin的使用步骤如下:
1)引入依赖
我们在order-service服务的pom文件中引入feign的依赖:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>2)添加注解
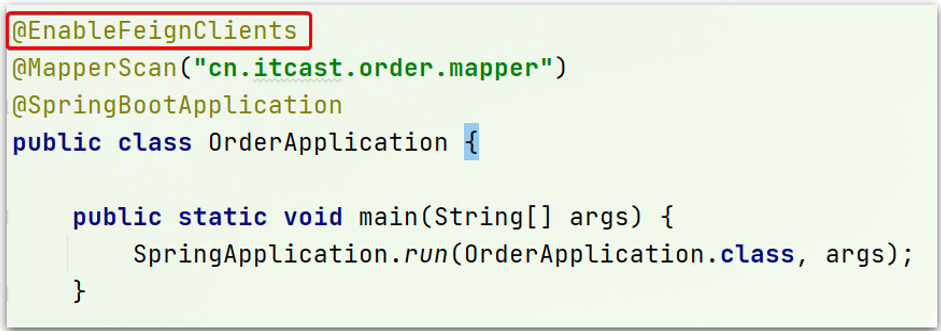
在order-service的启动类添加注解开启Feign的功能:
3)编写Feign的客户端
在order-service中新建一个接口,内容如下:
import org.springframework.web.bind.annotation.PathVariable;
@FeignClient("userservice") //指定服务名称
public interface UserClient {
@GetMapping("/user/{id}") //路径占位符
User findById(@PathVariable("id") Long id);
}这个客户端主要是基于SpringMVC的注解来声明远程调用的信息,比如:
服务名称:userservice
请求方式:GET
请求路径:/user/{id}
请求参数:Long id
返回值类型:User
这样,Feign就可以帮助我们发送http请求,无需自己使用RestTemplate来发送了。
4)测试
修改order-service中的OrderService类中的queryOrderById方法,使用Feign客户端代替RestTemplate:


是不是看起来优雅多了。
5)总结
使用Feign的步骤:
① 引入依赖
② 添加@EnableFeignClients注解
③ 编写FeignClient接口
④ 使用FeignClient中定义的方法代替RestTemplate
2.2.自定义配置
Feign可以支持很多的自定义配置,如下表所示:
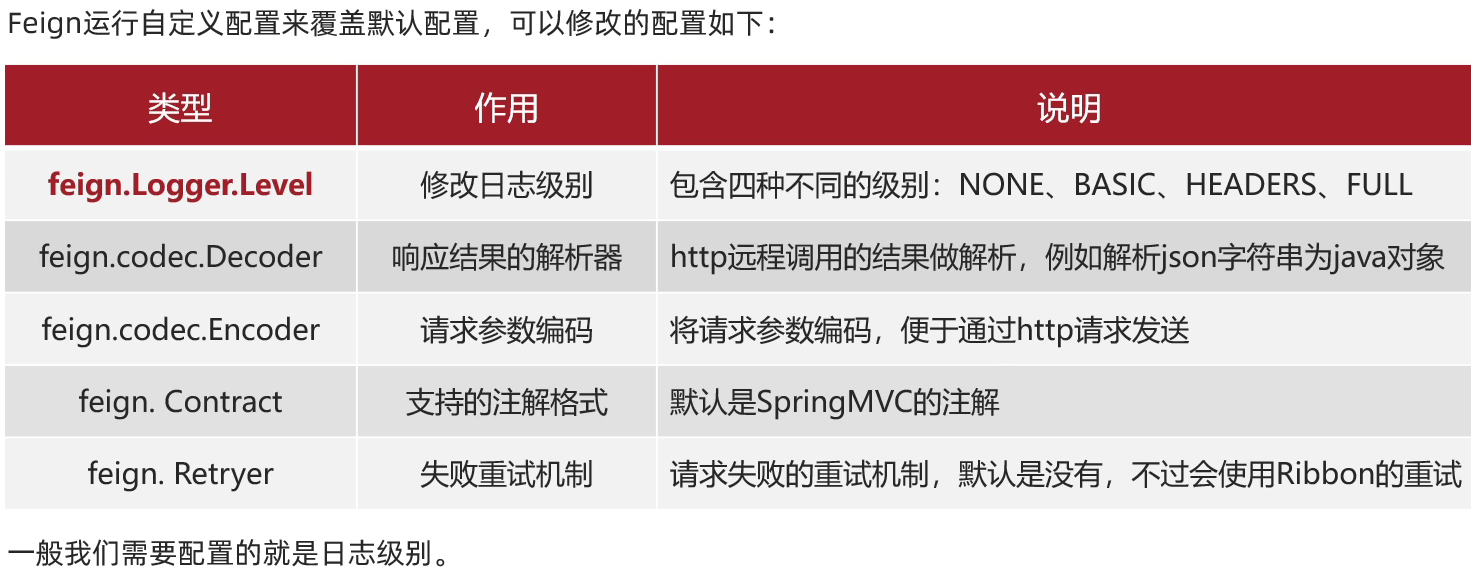
NONE 没有任何日志(默认)、
BASIC 发起HTTP请求时,记录请求的发送/结束时间等基本信息、
HEADERS 基本信息以外还有请求头和响应头信息、
FULL:HEADERS+请求体和响应体(最完整)
Contract: 配置 Feign支持哪种注解;
一般情况,默认值就能满足我们,如果要自定义时,只需要创建自定义的@Bean覆盖默认Bean即可。
下面以日志为例来演示如何自定义配置。
2.2.1.配置文件方式
基于配置文件修改feign的日志级别可以针对单个服务:
feign:
client:
config:
userservice: # 针对某个微服务的配置
loggerLevel: FULL # 日志级别 也可以针对所有服务(default):
feign:
client:
config:
default: # 这里用default就是全局配置,如果是写服务名称,则是针对某个微服务的配置
loggerLevel: FULL # 日志级别 而日志的级别分为四种:
NONE:不记录任何日志信息,这是默认值。
BASIC:仅记录请求的方法,URL以及响应状态码和执行时间
HEADERS:在BASIC的基础上,额外记录了请求和响应的头信息
FULL:记录所有请求和响应的明细,包括头信息、请求体、元数据。
一般情况用BASIC或者NONE,调试错误用FULL;
2.2.2.Java代码方式
也可以基于Java代码来修改日志级别,先声明一个类,然后声明一个Logger.Level的对象:
public class DefaultFeignConfiguration {
@Bean
public Logger.Level feignLogLevel(){
return Logger.Level.BASIC; // 日志级别为BASIC
}
}如果要全局生效,将其放到启动类的@EnableFeignClients这个注解中:
@EnableFeignClients(defaultConfiguration = DefaultFeignConfiguration .class) 如果是局部生效,则把它放到对应的@FeignClient这个注解中:
@FeignClient(value = "userservice", configuration = DefaultFeignConfiguration .class) 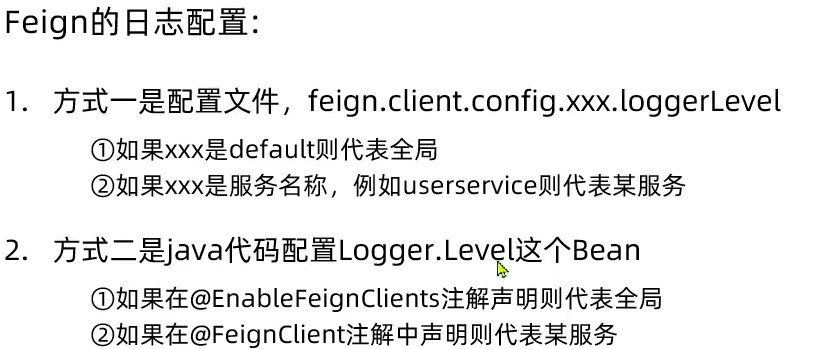
2.3.Feign使用优化
Feign底层发起http请求,依赖于其它的框架。其底层客户端实现包括:
•URLConnection:默认实现,不支持连接池
•Apache HttpClient :支持连接池
•OKHttp:支持连接池
因此提高Feign的性能主要手段就是使用连接池代替默认的URLConnection。

这里我们用Apache的HttpClient来演示。
1)引入依赖
在order-service的pom文件中引入Apache的HttpClient依赖:
<!--httpClient的依赖 -->
<dependency>
<groupId>io.github.openfeign</groupId>
<artifactId>feign-httpclient</artifactId>
</dependency>2)配置连接池
在order-service的application.yml中添加配置:
feign:
client:
config:
default: # default全局的配置
loggerLevel: BASIC # 日志级别,BASIC就是基本的请求和响应信息
httpclient:
enabled: true # 开启feign对HttpClient的支持,声明feign底层用httpclient替代
max-connections: 200 # 最大的连接数
max-connections-per-route: 50 # 每个路径的最大连接数接下来,在FeignClientFactoryBean中的loadBalance方法中打断点:
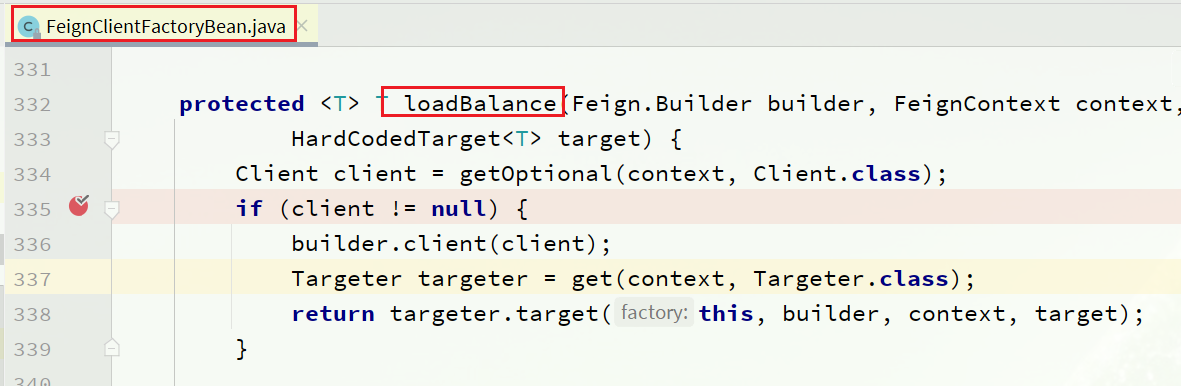
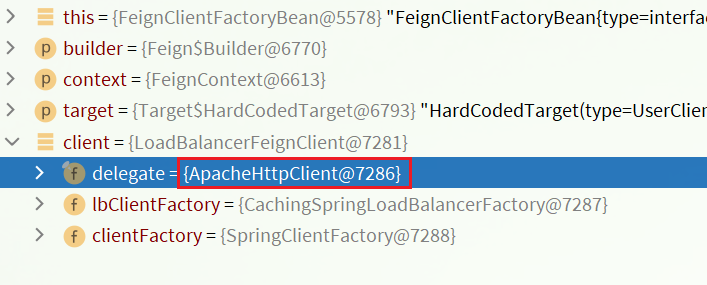
Debug方式启动order-service服务,可以看到这里的client,底层就是Apache HttpClient:

2.4.最佳实践
所谓最佳实践,就是使用过程中总结的经验,最好的一种使用方式。
自习观察可以发现,Feign的客户端与服务提供者的controller代码非常相似:
feign客户端:
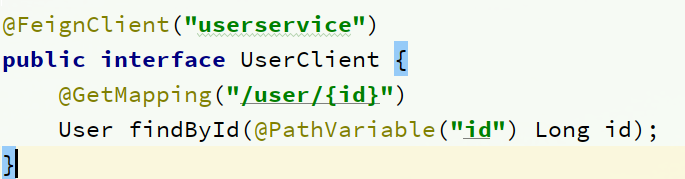
UserController:
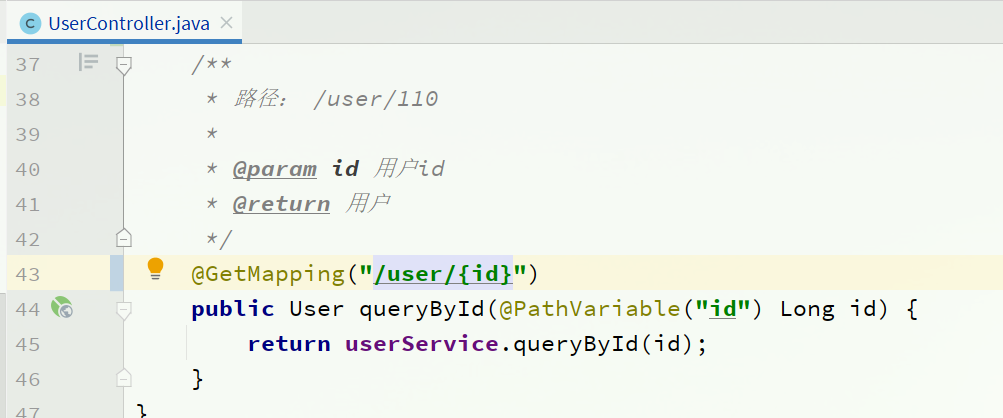
有没有一种办法简化这种重复的代码编写呢?
2.4.1.继承方式
一样的代码可以通过继承来共享:
1)定义一个API接口,利用定义方法,并基于SpringMVC注解做声明。
2)Feign客户端和Controller都集成改接口

优点:
简单
实现了代码共享
缺点:
服务提供方、服务消费方紧耦合
参数列表中的注解映射(@PathVar...)并不会继承,因此Controller中必须再次声明方法、参数列表、注解
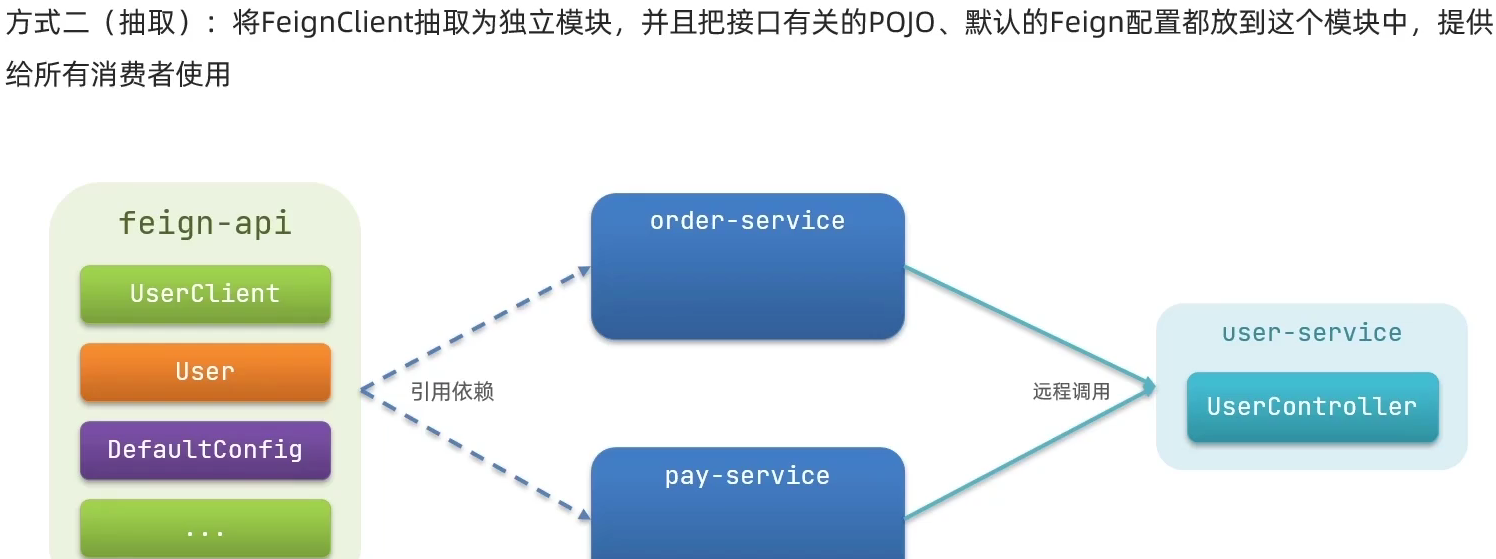
2.4.2.抽取方式
将Feign的Client抽取为独立模块,并且把接口有关的POJO、默认的Feign配置都放到这个模块中,提供给所有消费者使用。
例如,将UserClient、User、Feign的默认配置都抽取到一个feign-api包中,所有微服务引用该依赖包,即可直接使用。

2.4.3.实现基于抽取的最佳实践

1)抽取
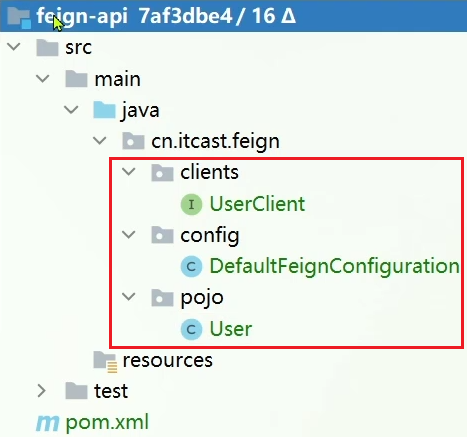
首先创建一个module,命名为feign-api:
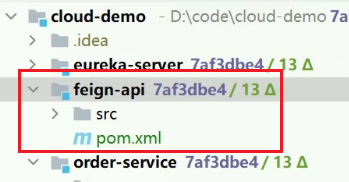
项目结构:
在feign-api中然后引入feign的starter依赖
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-openfeign</artifactId>
</dependency>然后,order-service中编写的UserClient、User、DefaultFeignConfiguration都复制到feign-api项目中
2)在order-service中使用feign-api
首先,删除order-service中的UserClient、User、DefaultFeignConfiguration等类或接口。
在order-service的pom文件中中引入feign-api的依赖:
<dependency>
<groupId>cn.itcast.demo</groupId>
<artifactId>feign-api</artifactId>
<version>1.0</version>
</dependency>修改order-service中的所有与上述三个组件有关的导包部分,改成导入feign-api中的包
3)重启测试
重启后,发现服务报错了:

这是因为UserClient现在在cn.itcast.feign.clients包下,
而order-service的@EnableFeignClients注解是在cn.itcast.order包下,不在同一个包,无法扫描到UserClient。
4)解决扫描包问题

3.Gateway服务网关
Spring Cloud Gateway 是 Spring Cloud 的一个全新项目,该项目是基于 Spring 5.0,Spring Boot 2.0 和 Project Reactor 等响应式编程和事件流技术开发的网关,它旨在为微服务架构提供一种简单有效的统一的 API 路由管理方式。
3.1.为什么需要网关
Gateway网关是我们服务的守门神,所有微服务的统一入口。
网关的核心功能特性:
请求路由
权限控制
限流
架构图:
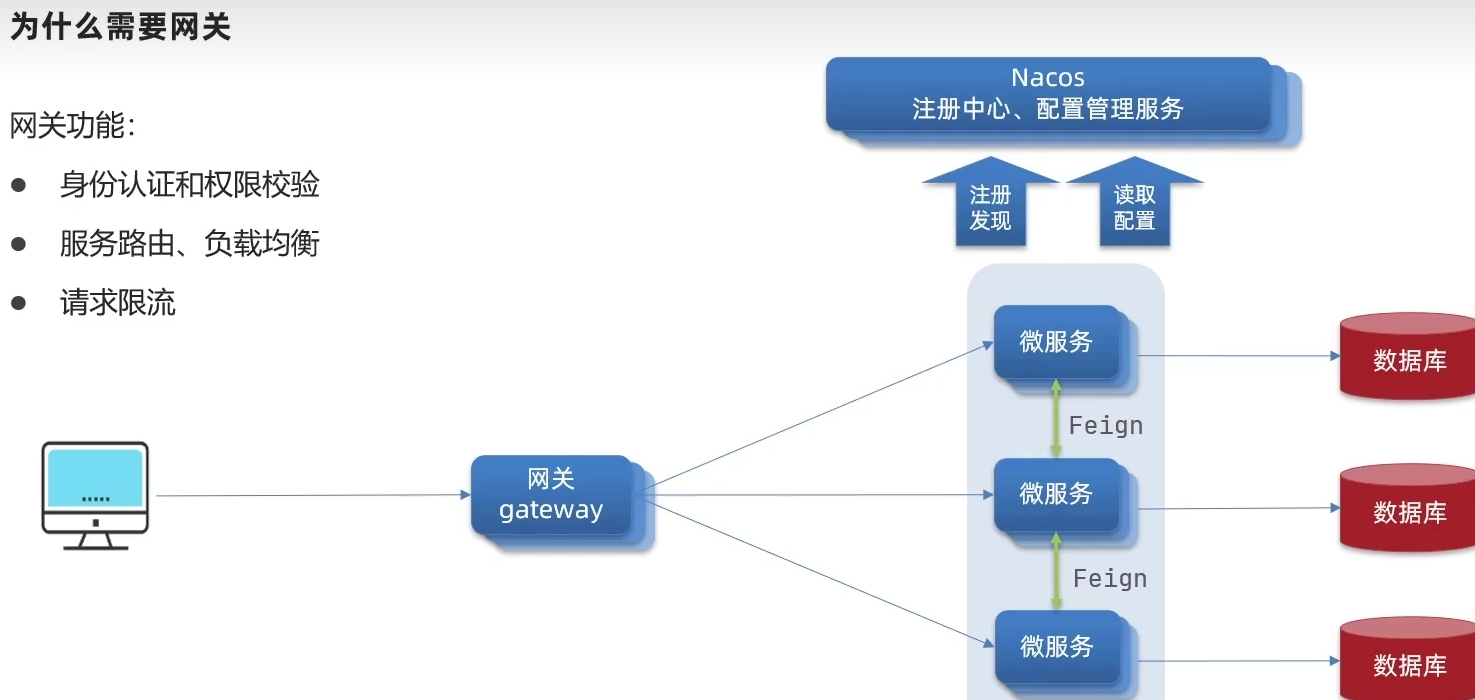
权限控制:网关作为微服务入口,需要校验用户是是否有请求资格,如果没有则进行拦截。
路由和负载均衡:一切请求都必须先经过gateway,但网关不处理业务,而是根据某种规则,把请求转发到某个微服务,这个过程叫做路由。当然路由的目标服务有多个时,还需要做负载均衡。
限流:当请求流量过高时,在网关中按照下流的微服务能够接受的速度来放行请求,避免服务压力过大。
在SpringCloud中网关的实现包括两种:
gateway
zuul
Zuul是基于Servlet的实现,属于阻塞式编程。而SpringCloudGateway则是基于Spring5中提供的WebFlux,属于响应式编程的实现,具备更好的性能。
3.2.gateway快速入门
下面,我们就演示下网关的基本路由功能。基本步骤如下:
创建SpringBoot工程gateway,引入网关依赖
编写启动类
编写基础配置和路由规则
启动网关服务进行测试
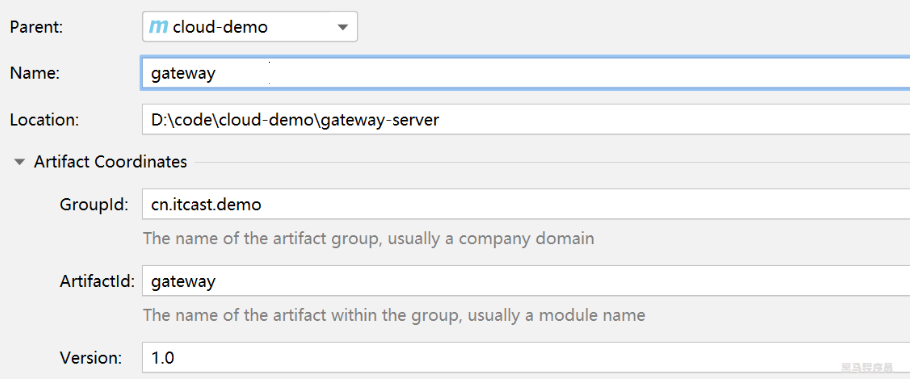
1)创建gateway服务,引入依赖
创建服务:
引入依赖:
<!--网关-->
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-gateway</artifactId>
</dependency>
<!--nacos服务发现依赖-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId>
</dependency>2)编写启动类
package cn.itcast.gateway;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class GatewayApplication {
public static void main(String[] args) {
SpringApplication.run(GatewayApplication.class, args);
}
}3)编写基础配置和路由规则
创建application.yml文件,内容如下:
server:
port: 10010 # 网关端口
spring:
application:
name: gateway # 服务名称
cloud:
nacos:
server-addr: localhost:8848 # nacos地址
gateway:
routes: # 网关路由配置
- id: user-service # 路由id,自定义,只要唯一即可
# uri: http://127.0.0.1:8081
# 上面这个 路由的目标地址 http就是固定地址 向具体ip和端口路由 一般不这样
uri: lb://userservice # 路由的目标地址 lb就是负载均衡(loadBalance),后面跟服务名称
predicates: # 路由断言,也就是判断请求是否符合路由规则的条件
- Path=/user/** # 这个是按照路径匹配,只要以/user/开头就符合要求我们将符合Path 规则的一切请求,都代理到 uri参数指定的地址。
本例中,我们将 /user/**开头的请求,代理到lb://userservice,lb是负载均衡,根据服务名拉取服务列表,实现负载均衡。
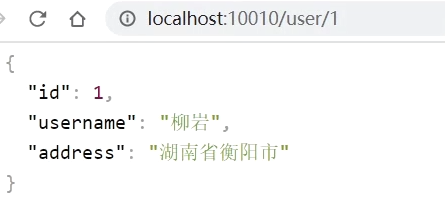
4)重启测试
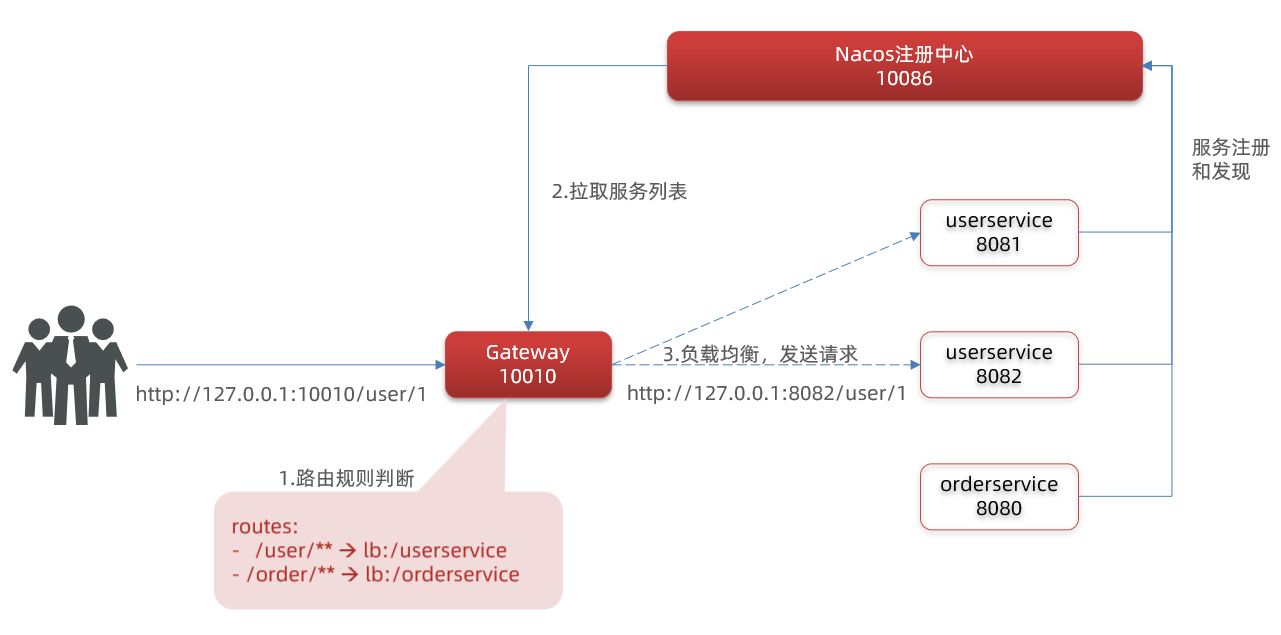
重启网关,访问http://localhost:10010/user/1时,符合/user/**规则,请求转发到uri:http://userservice/user/1,得到了结果:
5)网关路由的流程图
整个访问的流程如下:
总结:


接下来,就重点来学习路由断言和路由过滤器的详细知识
3.3.断言工厂

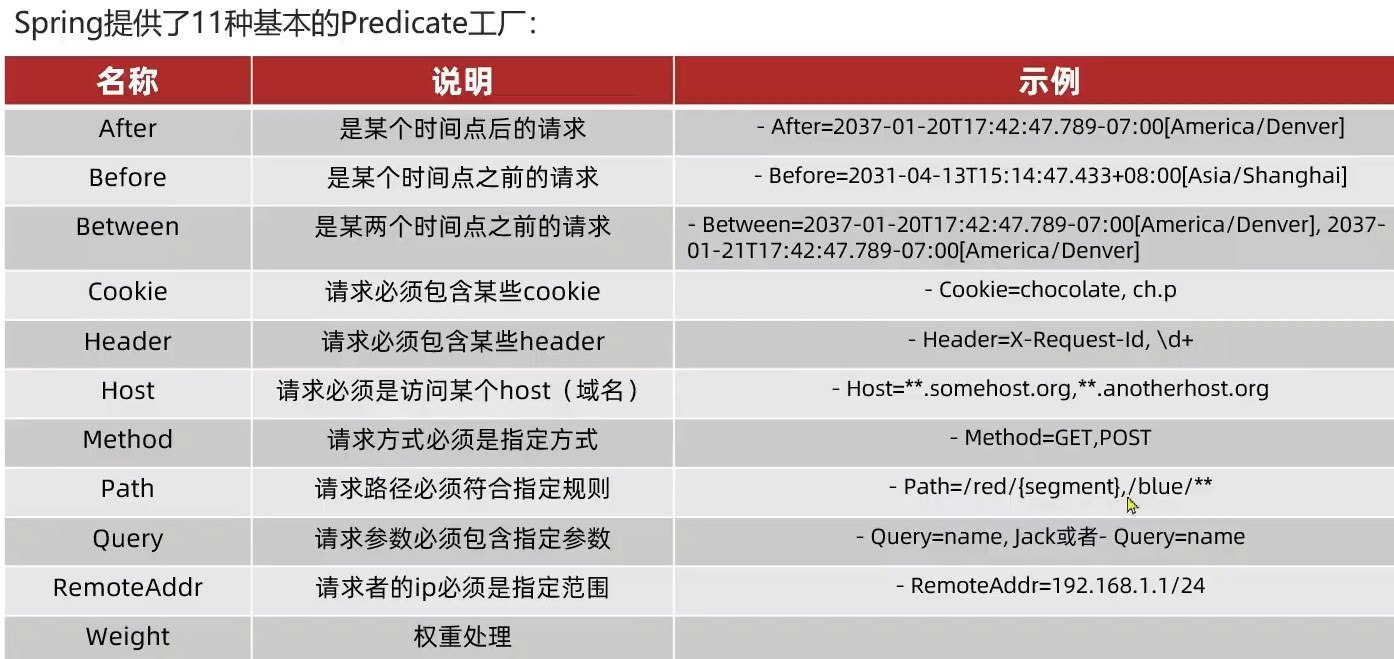
我们只需要掌握Path这种路由工程就可以了。

3.4.过滤器工厂
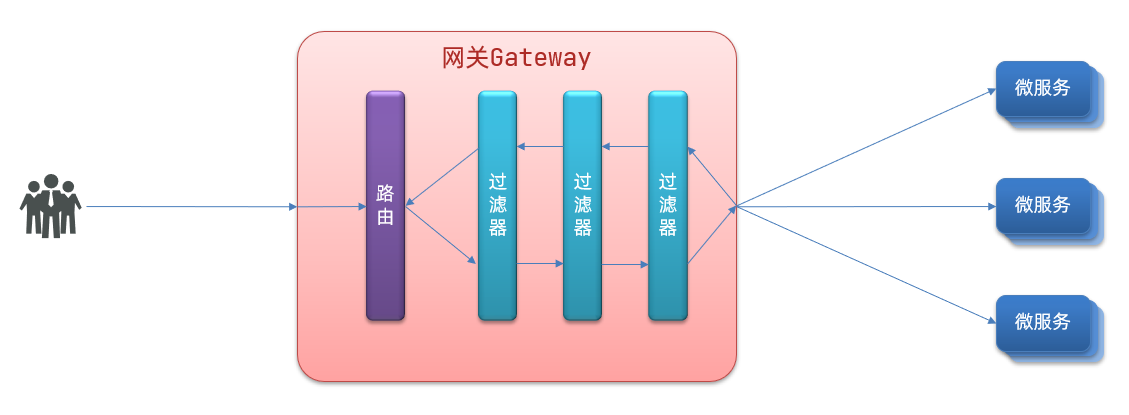
GatewayFilter是网关中提供的一种过滤器,可以对进入网关的请求和微服务返回的响应做处理:
3.4.1.路由过滤器的种类

3.4.2.请求头过滤器
下面我们以AddRequestHeader 为例来讲解。
需求: 给所有进入userservice的请求添加一个请求头:Truth=itcast is freaking awesome!
只需要修改gateway服务的application.yml文件,添加路由过滤即可:
spring:
cloud:
gateway:
routes: #网关路由配置
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
filters: # 过滤器
- AddRequestHeader=Truth, Itcast is freaking awesome! # 添加请求头
# - 请求头名字 = key, value当前过滤器写在userservice路由下,因此仅仅对访问userservice的请求有效。
3.4.3.默认过滤器
如果要对所有的路由都生效,则可以将过滤器工厂写到default下。格式如下:
spring:
cloud:
gateway:
routes:
- id: user-service
uri: lb://userservice
predicates:
- Path=/user/**
default-filters: # 默认过滤项
- AddRequestHeader=Truth, Itcast is freaking awesome! 3.4.4.总结

3.5.全局过滤器
上一节学习的过滤器,网关提供了31种,但每一种过滤器的作用都是固定的。如果我们希望拦截请求,做自己的业务逻辑则没办法实现。
3.5.1.全局过滤器作用
全局过滤器的作用也是处理一切进入网关的请求和微服务响应,与GatewayFilter的作用一样。区别在于GatewayFilter通过配置定义,处理逻辑是固定的;而GlobalFilter的逻辑需要自己写代码实现。
定义方式是实现GlobalFilter接口。
public interface GlobalFilter {
/**
* 处理当前请求,有必要的话通过{@link GatewayFilterChain}将请求交给下一个过滤器处理
*
* @param exchange 请求上下文(从请求进入网关到结束),里面可以获取Request、Response等信息
* @param chain 用来把请求委托给下一个过滤器
* @return {@code Mono<Void>} 返回标示当前过滤器业务结束
*/
Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain);
}在filter中编写自定义逻辑,可以实现下列功能:
登录状态判断
权限校验
请求限流等
3.5.2.自定义全局过滤器
需求:定义全局过滤器,拦截请求,判断请求的参数是否满足下面条件:
参数中是否有authorization,
authorization参数值是否为admin
如果同时满足则放行,否则拦截
实现:
在gateway中定义一个过滤器:
import reactor.core.publisher.Mono;
@Order(-1)//顺序注解(过滤器的顺序) 数字越小 优先级越高
@Component//注入到Spring做bean
public class AuthorizeFilter implements GlobalFilter {
@Override
public Mono<Void> filter(ServerWebExchange exchange, GatewayFilterChain chain) {
// 1.获取请求参数
MultiValueMap<String, String> params = exchange.getRequest().getQueryParams();
// 2.从params获取第一个匹配authorization参数
String auth = params.getFirst("authorization");
// 3.校验
if ("admin".equals(auth)) {
// 放行
return chain.filter(exchange);
}
// 4.拦截
// 4.1.禁止访问,设置状态码
exchange.getResponse().setStatusCode(HttpStatus.FORBIDDEN);
// 4.2.结束处理
return exchange.getResponse().setComplete();
}
}
3.5.3.过滤器执行顺序
请求进入网关会碰到三类过滤器:当前路由的过滤器、DefaultFilter、GlobalFilter
请求路由后,会将当前路由过滤器和DefaultFilter、GlobalFilter,合并到一个过滤器链(集合)中,排序后依次执行每个过滤器:


3.6.跨域问题
3.6.1.什么是跨域问题

解决方案:
CORS,这个以前应该学习过,这里不再赘述了。不知道的小伙伴可以查看跨域资源共享 CORS 详解

3.6.2.模拟跨域问题
找到课前资料的页面文件:

放入tomcat或者nginx这样的web服务器中,启动并访问。
可以在浏览器控制台看到下面的错误:

从localhost:8090访问localhost:10010,端口不同,显然是跨域的请求。
3.6.3.解决跨域问题
在gateway服务的application.yml文件中,添加下面的配置:
spring:
cloud:
gateway:
# 。。。
globalcors: # 全局的跨域处理
add-to-simple-url-handler-mapping: true # 解决options请求被拦截问题
corsConfigurations:
'[/**]':
allowedOrigins: # 允许哪些网站的跨域请求
- "http://localhost:8090"
allowedMethods: # 允许的跨域ajax的请求方式
- "GET"
- "POST"
- "DELETE"
- "PUT"
- "OPTIONS"
allowedHeaders: "*" # 允许在请求中携带的头信息
allowCredentials: true # 是否允许携带cookie
maxAge: 360000 # 这次跨域检测的有效期本文来自博客园,作者:软工菜鸡,转载请注明原文链接:https://www.cnblogs.com/SElearner/p/17676680.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号