MySQL 进阶篇1.0 索引 SQL优化 视图 锁
01-课程介绍

02-存储引擎-MySQL体系结构


03存储引擎-简介
查询建表语句 --默认存储引擎:InnoDB
show create table account;
查询当前数据库支持的存储引擎
show engines;


04存储引擎-InnoDB介绍


开关为"ON": 表示每个innodb引擎的表都有一个idb表共享文件

05存储引擎-MyISAM和Memory



面试常考(InnoDB与MyISAM区别)
06存储引擎的选择(一般就是InnoDB,其他两个在其他SQL中都有优化版)


08MySQL安装(linux)&遇到的问题

输入password的时候 不显示输入 我还以为没输入进去真贱啊


没开Linux防火墙3306的端口 不能远程链接
linux怎么允许3306端口通过防火墙,Centos7允许3306端口通过防火墙_倪振源的博客-CSDN博客
cnm,nmsl,教的什么j8玩意,链接虚拟机地址都不让我们查一下? 老子查了两个点才查出来!!!!
【MySQL】DataGrip连接linux中的MySQL_猫打球商店的博客-CSDN博客_datagrip 连接linux服务器
mariadb-libs 被 mysql-community-libs-compat-8.0.26-1.el7.x86_64 取代_别晃我的可乐的博客-CSDN博客_mariadb-libs
Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (111)
直接停止再重启mysql服务
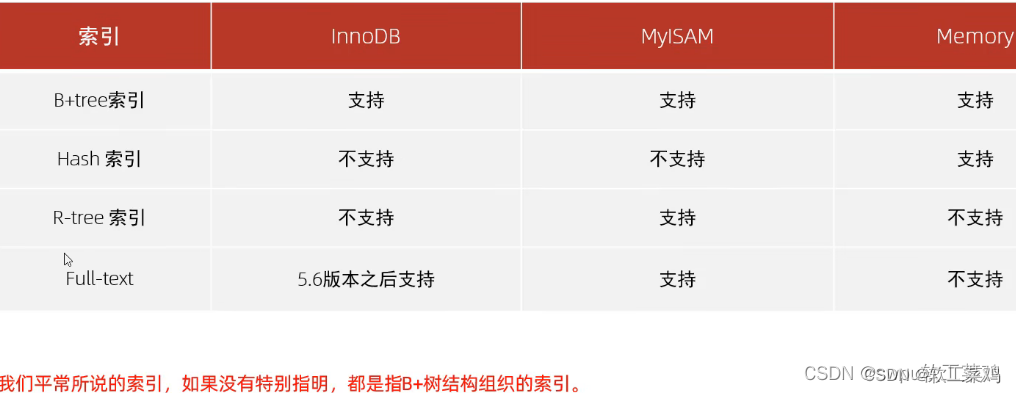
09索引-概述



10索引-结构-介绍

11索引-结构-Btree

红黑树和二叉树都存在问题:大数据量情况,层级较深,检索速度慢;

最大度数:n 每个节点最多存储n-1个key,n个指针;分裂的时候中间向上左右

继续插入元素,


数据结构可视化网站 ↑
12索引-结构-B+tree


非叶子节点的数据作为索引

13索引-结构-hash
先计算每一行的hash值,然后计算name的hash值映射到蓝色hash槽位里面,然后存储(name,name对应的行的hash值)到hash表;

14索引-结构-思考题(why InnoDB引擎用 B+tree?)
B-树就是B树;

B+树的双向链表便于范围搜索和排序;不用hash因为只支持对等比较,不能范围且无序
15索引-分类聚集索引&二级索引
可以这样理解,可以通过聚簇索引(一般都是主键索引)直接查到数据,如果通过二级索引,则需要通过二级索引定位数据对应的主键索引(聚簇索引),再通过主键索引(聚簇索引)找到数据,因为聚簇索引的叶子节点有数据
聚集索引之所以必须有是因为他是用来存储数据的,而二级索引更多的使用来更快更高效的查询数据



*16索引-思考题

n=key数量;8=主键占用的字节数;n+1 指针;6指针字节;一页16kb;
而每一个页有16k,一行数据假设为1k,就是每页可以存储16行。切记,只有叶子节点才是存放数据,非叶子节点是存储的索引
两千多万数据也才3层;
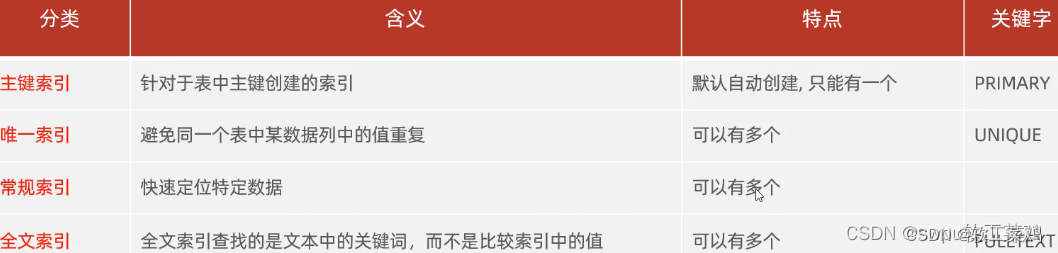
17索引-语法


1. create index idx_user_name on tb_user(name);
2. create index idx_user_name on tb_user(name);
3. create index idx_user_pro_age_sta on tb_user(profession,age,status);
4. create index idx_user_email on tb_user(email);
18索引-性能分析-查看执行频次
Com七个_; _代表字符占位符
因为7个下划线正好和_select,_update,_insert和_delete的拼写长度一样
代表当前数据库增删改查的次数

19索引-性能分析-慢查询日志



20索引-性能分析-show profiles





21索引-性能分析-explain 执行计划


连接类型type
NULL:查询不妨问任何表时出现NULL, 如:select 'A',业务系统的sql一般不可能优化到NULL; system:访问系统表 const:根据主键/唯一索引访问; ref:使用非唯一索引查询
eq_ref 在主键索引或者唯一性索引用于做被驱动表的连接字段时就会出现
index:使用了索引,但会扫描遍历整个索引树 all:全表扫描


22索引-使用规则-验证索引效率




23索引-使用规则-最左前缀法则


24索引-使用规则-索引失效情况一



25索引-使用规则-索引失效情况二

先看or后面的,后面没有那都没有,后面有在看前面的;必须两个都有才用索引;
道理很简单,你要在一堆东西中找两个东西,一个能够立即找到,但是另外一个必须在所有东西中找;

26索引-使用规则-SQL提示
(use只是一种建议 mysql是否接受不一定要看效率) use/ignore/force 建议/不用/强制使用

27索引-使用规则-覆盖索引&回表查询



面试题:最佳方案:针对username-password建立联合索引 因为联合索引是二级索引,B+树叶子下面挂的是ID(主键),所以执行select不需要回表查询 性能最好
28索引-使用规则-前缀索引




29使用规则-单列&联合索引


创建索引(phone,name) 先 按phone排列 后按name;
要满足最左前缀法则;所以要考虑参数顺序 单列索引容易回表查询,性能降低
30索引-设计原则

31索引-小结
32SQL优化-插入数据


33SQL优化-主键优化(每页包含2~n)


编辑
编辑


编辑
编辑
编辑


编辑


编辑
34SQL优化-order by优化

编辑


编辑


编辑
35SQL优化-group by优化


编辑
36SQL优化-limit优化

编辑
37SQL优化-count优化(由存储引擎决定)
编辑

编辑
编辑
38SQL优化-update优化(避免行锁升级为表锁)


编辑
39SQL优化-小结


编辑
40视图-介绍及基本语法

编辑


编辑
41视图-检查选项(cascaded) (译为:级联的)


编辑with cascaded check option;
视图 会在操作的时候检查是否满足where条件
并递归继续检查上面(依赖)的v2带cascaded的where 直到每个底层带cascaded的 都满足 才执行SQL;
42.进阶-视图-检查选项(local)


编辑
区别在于:local 当前v3没有检查选项 就不用管其它带(local的)依赖视图;
但是cascaded 就算v3没有也要管v2,v1(带cascaded检查选项的).
43.进阶-视图-更新及作用

编辑

编辑
44.进阶-视图-案例


编辑
本文来自博客园,作者:软工菜鸡,转载请注明原文链接:https://www.cnblogs.com/SElearner/p/17676661.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号