

数据库基础和原理
数据库基础和原理
关系型数据库是如何工作的
Architecture of a Database System
How does a relational database work
关系型数据库设计理论
重要术语
-
属性(attribute):列
-
元组(tuple):行
-
表(table):由多个属性,以及众多元组所表示的各个实例组成。
-
依赖(relation):列属性间存在的某种联系。
-
模式(schema):这里我们指逻辑结构,描述数据的全局性。
-
域(domain):数据类型,如string、integer等,上图中每一个属性都有它的数据类型(即域)。
-
键(key):由关系的一个或多个属性组成,任意两个键相同的元组,所有属性都相同。需要保证表示键的属性最少。一个关系可以存在好几种键,工程中一般从这些候选键中选出一个作为主键(primary key)。
-
候选键(candidate key):由关系的一个或多个属性组成,候选键都具备键的特征,都有资格成为主键。
-
超键(super key):包含键的属性集合,无需保证属性集的最小化。每个键也是超键。可以认为是键的超集。
-
外键(foreign key):如果某一个关系A中的一个(组)属性是另一个关系B的键,则该(组)属性在A中称为外键。
-
主属性(prime attribute):所有候选键所包含的属性都是主属性。
-
投影(projection):选取特定的列,如将关系学生信息投影为学号、姓名即得到上表中仅包含学号、姓名的列
-
选择(selection):按照一定条件选取特定元组,如选择上表中分数>80的元组。
-
笛卡儿积(交叉连接Cross join):第一个关系每一行分别与第二个关系的每一行组合。
-
自然连接(natural join):第一个关系中每一行与第二个关系的每一行进行匹配,如果得到有交叉部分则合并,若无交叉部分则舍弃。
-
连接(theta join):即加上约束条件的笛卡儿积,先得到笛卡儿积,然后根据约束条件删除不满足的元组。
-
外连接(outer join):执行自然连接后,将舍弃的部分也加入,并且匹配失败处的属性用NULL代替。
-
除法运算(division):关系R除以关系S的结果为T,则T包含所有在R但不在S中的属性,且T的元组与S的元组的所有组合在R中。
函数依赖
定义:设有一关系模式R(A1,A2,…,An),X和Y均为(A1,A2,…,An)的子集,对于R的值r来说,当其中任意两个元组u,v中对应于X的那些属性分量的值均时,则有u,v中对应于Y的那些属性分量的值也相等,称X函数决定Y,或Y依赖于X,记为X->Y [1] 。
例:有关系,学生(学号S#,姓名SN,系名SD),子集X(学号S#),子集Y(系名SD)。
每个学生有唯一的一个学号,学生中可以有重名的姓名,每个学生只能属于一个系,每个系有唯一的系代号。有此,可以找出学生关系模式中存在下列函数依赖:
S#->SN;S#->SD
例:有关系,学校简况(学号S#,系名SD,系主任MN,课程CN,成绩G)。可写出函数依赖:
S#->SD;SD->MN;S#,CN->G
根据函数依赖的不同性质,函数依赖可分为完全函数依赖、部分函数依赖和传递函数依赖。
完全函数依赖
定义:在R(U)中,如果X->Y,对于X的任意一个真子集X’,都有X’不能决定Y,则称Y对X完全函数依赖,记为XY 。
例:(S#,CN)->G
部分函数依赖
定义:在R(U)中,如果X-> Y,但Y不完全函数依赖于X,则称Y对X部分函数依赖。
传递函数依赖
定义:在R(U)中,当且仅当X-> Y,Y->Z时,称Z对X传递函数依赖。
例:描述学生(S#)、班级(SB)、辅导员(TN)的关系U(S#,SB,TN)。一个班有若干学生,一个学生只属于一个班,一个班只有一个辅导员,但一个辅导员负责几个班。根据现实世界可得到一组函数依赖:
F={S#->SB,SB->TN}
学生学号决定了所在班级,所在班级决定了辅导员,所以辅导员TN传递函数依赖于学生学号S#。
数据依赖还包括多值依赖和连接依赖两种形式。
范式
第一范式:属性不可再分
第二范式:每个非主属性完全依赖于键码
第三范式:非主属性不传递依赖于键码
关系型数据库设计流程
需求分析:分析用户的需求,包括数据、功能和性能需求;
概念结构设计:主要采用E-R模型进行设计,包括画E-R图;
逻辑结构设计:通过将E-R图转换成表,实现从E-R模型到关系模型的转换;
数据库物理设计:主要是为所设计的数据库选择合适的存储结构和存取路径;
数据库的实施:包括编程、测试和试运行;
数据库运行与维护:系统的运行与数据库的日常维护
数据库系统核心知识要点
事务
事务指的是满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
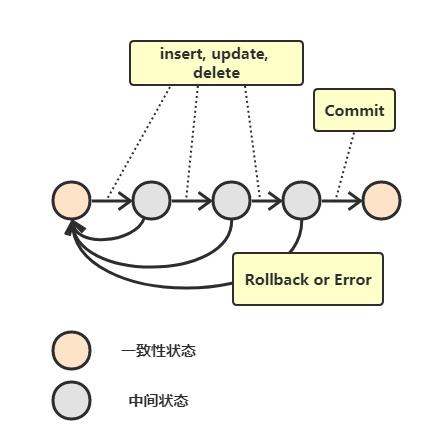
ACID
原子性(Atomicity) —— 事务被视为不可分割的最小单元,事务的所有操作要么全部提交成功,要么全部失败回滚。
一致性(Consistency) —— 数据库在事务执行前后都保持一致性状态。在一致性状态下,所有事务对一个数据的读取结果都是相同的。
隔离性(Isolation) —— 一个事务所做的修改在最终提交以前,对其它事务是不可见的。
持久性(Durability) —— 一旦事务提交,则其所做的修改将会永远保存到数据库中。即使系统发生崩溃,事务执行的结果也不能丢失。
并发一致性问题
丢失修改:多个事务对同一数据修改,后者的修改覆盖了前者的修改。
读脏数据:一事务修改了数据但最后回滚了,另一个在此期间读取了数据,此数据为脏数据。
不可重复读:事务对一数据进行读取,若之后另一事务对该数据进行了修改,则前一事务再次读取该数据,结果和之前会不同。
幻影读:事务读取某一范围的数据,另一个事务对这个范围的数据信息增删的操作导致前一事务再一次读取的结果和之前不一致。
产生并发不一致性问题主要原因是破坏了事务的隔离性,解决方法是通过并发控制来保证隔离性。并发控制可以通过封锁来实现,但是封锁操作需要用户自己控制,相当复杂。数据库管理系统提供了事务的隔离级别,让用户以一种更轻松的方式处理并发一致性问题。
锁机制
MySQL 中提供了两种封锁粒度: 行级锁以及表级锁。
应该尽量只锁定需要修改的那部分数据,而不是所有的资源。锁定的数据量越少,发生锁争用的可能就越小,系统的并发程度就越高。
下面是一些锁的类型:
- 读写锁
其中包括 排它锁(Exclusive) 和 共享锁(Shared) ,又或者称X锁和S锁、或写锁和读锁
若事务对一个数据对象加了X锁,则该事务可以对这个数据对象进行更新、读取操作,在这个加锁期间其他事务不能再对该数据对象加任何锁。
若事务对一个数据对象加了S锁,则该事务可以对这个数据对象进行读取操作,但不能进行更新操作,这个加锁期间其他事务能够对该数据对象添加S锁,但是不能添加X锁。
- 意向锁
使用 意向锁(Intention Locks) 可以更容易地支持多粒度封锁。
意向锁在原来的 X/S 锁之上引入了 IX/IS 表锁,用来表示一个事务想要在表中的某个数据行上加 X 锁或 S 锁。有以下两个规定:
- 一个事务在获得某个数据行对象的 S 锁之前,必须先获得表的 IS 锁或者更强的锁;
- 一个事务在获得某个数据行对象的 X 锁之前,必须先获得表的 IX 锁。
封锁协议
- 一级封锁协议
事务 T 要修改数据 A 时必须加 X 锁,直到 T 结束才释放锁。(解决丢失修改问题)
- 二级封锁协议
在一级的基础上,要求读取数据 A 时必须加 S 锁,读取完马上释放 S 锁。(解决读脏数据问题)
- 三级封锁协议
在二级的基础上,要求读取数据 A 时必须加 S 锁,直到事务结束了才能释放 S 锁。(解决不可重复读问题)
- 两段锁协议
加锁和解锁分为两个阶段进行。
可串行化调度是指,通过并发控制,使得并发执行的事务结果与某个串行执行的事务结果相同。事务遵循两段锁协议是保证可串行化调度的充分条件。
隔离级别
- 未提交读(READ UNCOMMITTED)
事务中的修改,即使没有提交,对其它事务也是可见的。
- 提交读(READ COMMITTED)
一个事务只能读取已经提交的事务所做的修改
- 可重复读(REPEATABLE READ)
保证在同一个事务中多次读取同样数据的结果是一样的。
- 可串行化(SERIALIZABLE)
强制事务串行执行。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号