

python爬虫-bs4解析
bs4解析概述
bs4解析技术是python独有的一种数据解析方式
bs4实现数据解析原理:
- 实例化一个BeautifulSoup对象,并将页面源码加载到该数据中
- 加载本地的html
# 本地加载
fp1 = open("../data2/test.html", 'r', encoding="utf-8")
soup1 = BeautifulSoup(fp1, 'lxml')
- 加载互联网上的html
fp2 = response.text
soup2 = BeautifulSoup(fp1, 'lxml')
- 通过BeautifulSoup对象中的属性和方法来进行标签定位和数据提取
环境的准备
pip install bs4
# 这是一个xml解析器
pip install lxml
爬取红楼梦小说的所有章节标题和内容
"""
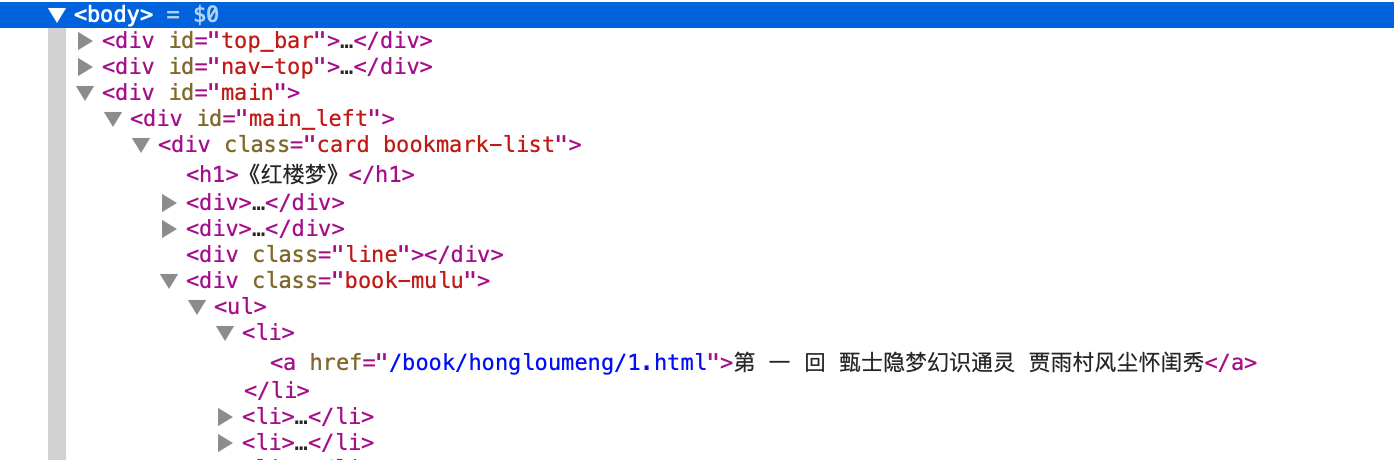
案例:爬取红楼梦全部标题和内容
url = "https://www.shicimingju.com/book/hongloumeng.html"
- 每一个章节标题都是一个a标签
- 章节的内容在href中
- a标签的层级是 div class="book-mulu" -> ul -> li -> a
"""
import requests
from bs4 import BeautifulSoup
if __name__ == '__main__':
# UA伪装
headers = {
"User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 (KHTML, like Gecko) "
"Version/14.1 Safari/605.1.15 "
}
# 文件存储位置
fp = open("../data2/honglou.text", 'w', encoding='utf-8')
# 对页面进行捕获
url = "https://www.shicimingju.com/book/hongloumeng.html"
page = requests.get(url=url, headers=headers)
page.encoding='utf-8'
# 解析出章节标题和内容的url
# 1,加载页面到靓汤对象中
soup = BeautifulSoup(page.text, 'lxml')
# 2,解析章节标题和详情页的url
li_list = soup.select('.book-mulu > ul > li')
for li in li_list:
title = li.a.string
detail_url = "https://www.shicimingju.com" + li.a['href']
# 对详情页发起请求,解析出章节内容
detail_page = requests.get(url=detail_url, headers=headers)
detail_page.encoding='utf-8'
detail_soup = BeautifulSoup(detail_page.text, 'lxml')
div_tag = detail_soup.find("div", class_="card bookmark-list")
content = div_tag.text
# 持久化存储
fp.write(title + ':\n' + content + '\n')
print(title + "爬取成功!")
fp.close()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号