1.Hadoop_Spak 虚拟机配置
利用Hadoop Spark 对大数据进行分析,需要Linux平台和集群系统。
这里通过虚拟机对其进行模拟,实际操作相似。
一.虚拟机、镜像下载
这里选用Virtual Box 5.2.22 和 Ubuntu 14.04.5 版本
下载地址:
Virtual Box 首页:https://www.virtualbox.org
Virtual Box 5.2.22:https://download.virtualbox.org/virtualbox/5.2.22/VirtualBox-5.2.22-126460-Win.exe
Ubuntu 首页:www.ubuntu.com
Ubuntu 14.04.5:http://releases.ubuntu.com/14.04.5/ubuntu-14.04.5-desktop-amd64.iso
二.软件安装和虚拟机配置
软件安装:修改路径,其他默认即可
配置虚拟机:
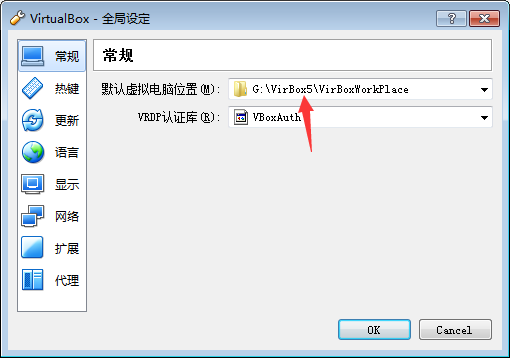
1.管理--全局设定--默认虚拟机电脑位子 (可以修改虚拟机存放位子)
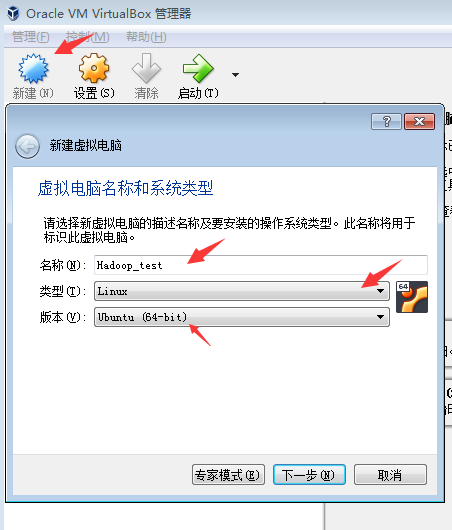
2.新建虚拟机,设置虚拟机名字和系统
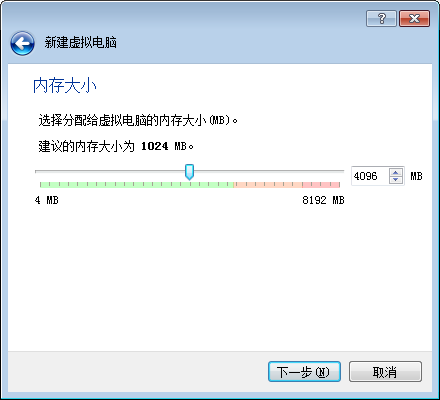
3.设置内存大小(可暂时设置大一点,因此前阶段只需要一台,从而提高速度)
这里设置为4G(电脑内存为8G)
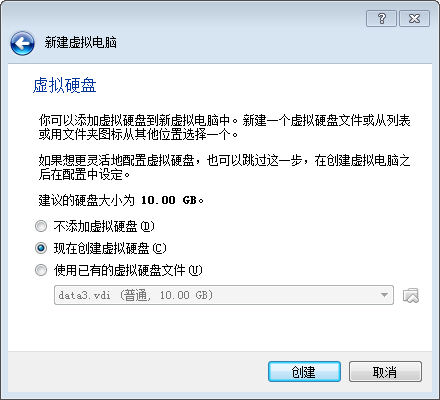
4.设置硬盘空(建议20G)
5.选择默认VDI
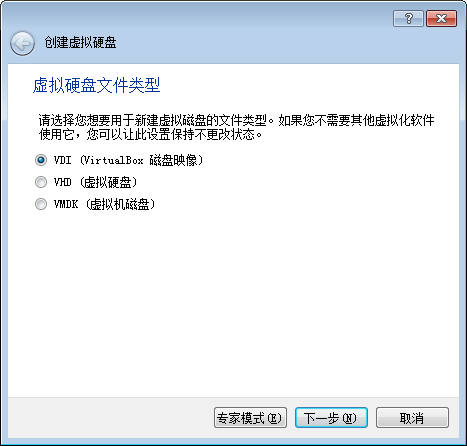
6.选择动态分配,随着使用,占用空间变多
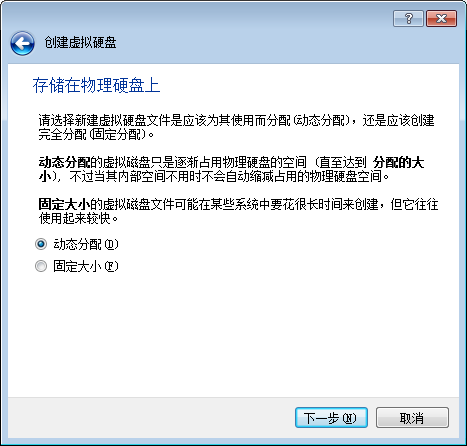
7.保存文件名称和硬盘(建议20G)
三.Ubuntu 系统安装
1.为虚拟机选择虚拟光驱和镜像
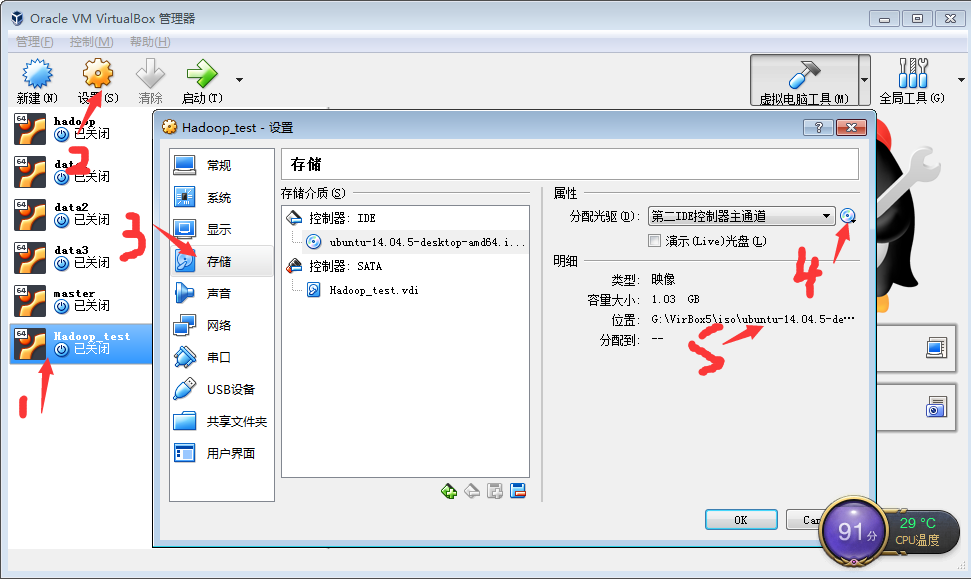
2.选中虚拟机,单机启动

3.启动后,可在左边选择安装环境的语言,然后单机Install Ubuntu
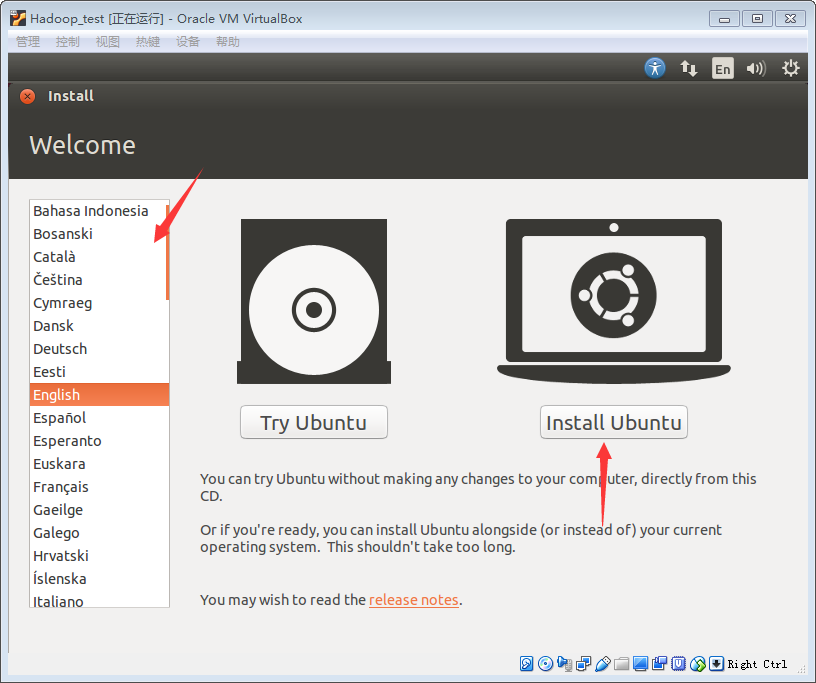
4.可以不选择更新和下载单方插件,直接单机continue即可
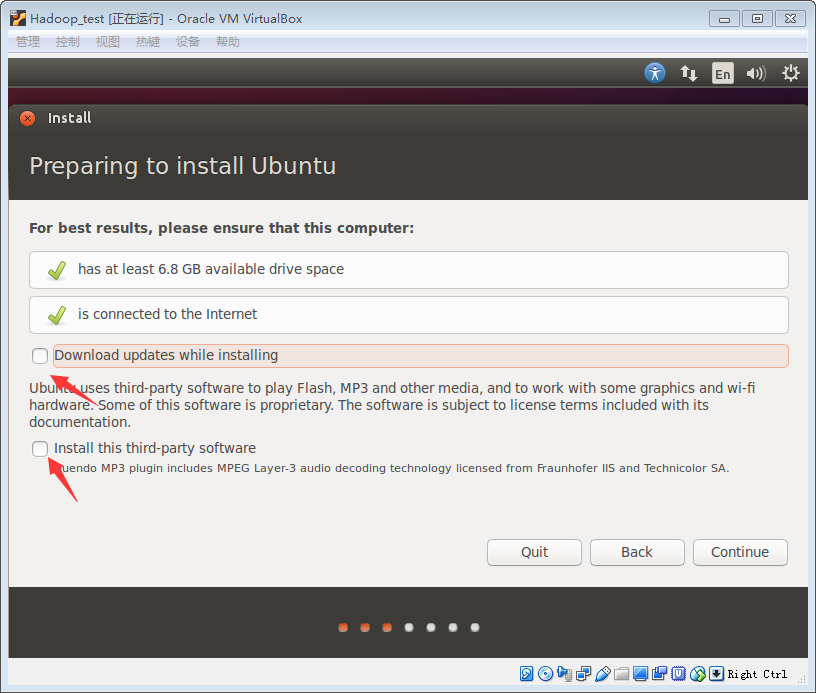
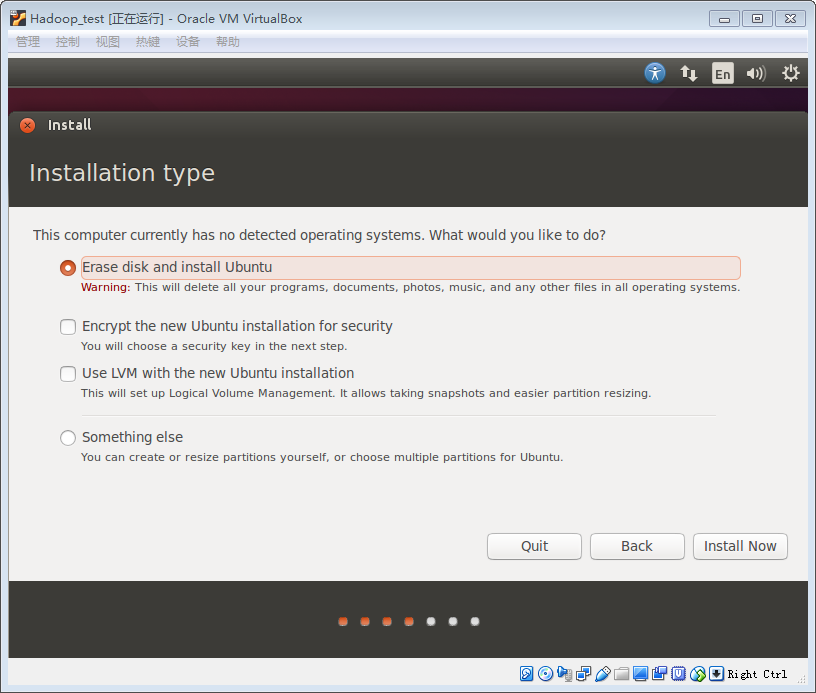
5.这里选择第一个,清空之前的data(如果是新建立的虚拟机则以前的data本身就是空),然后单机install Now
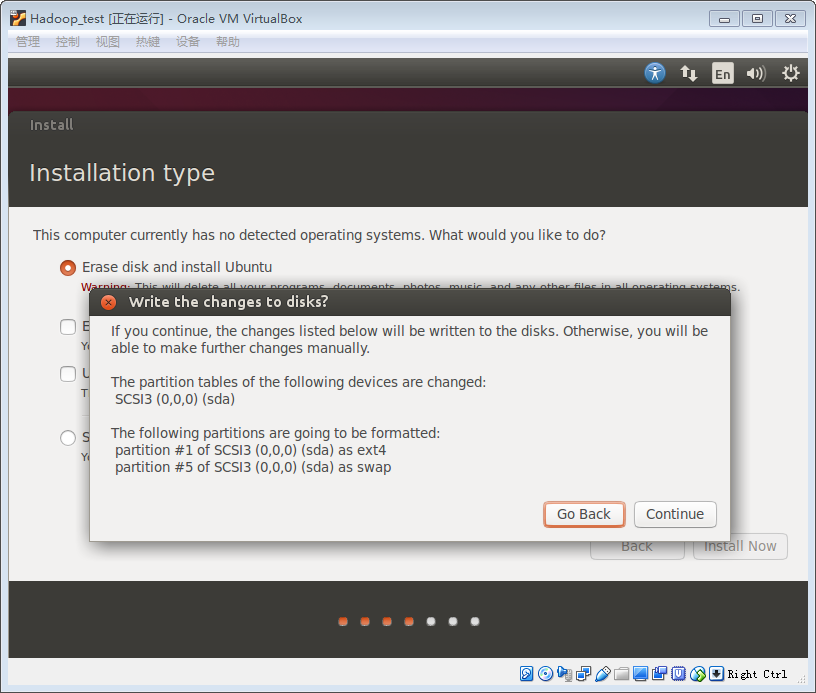
6.再次确认是否写入硬盘,单击continue
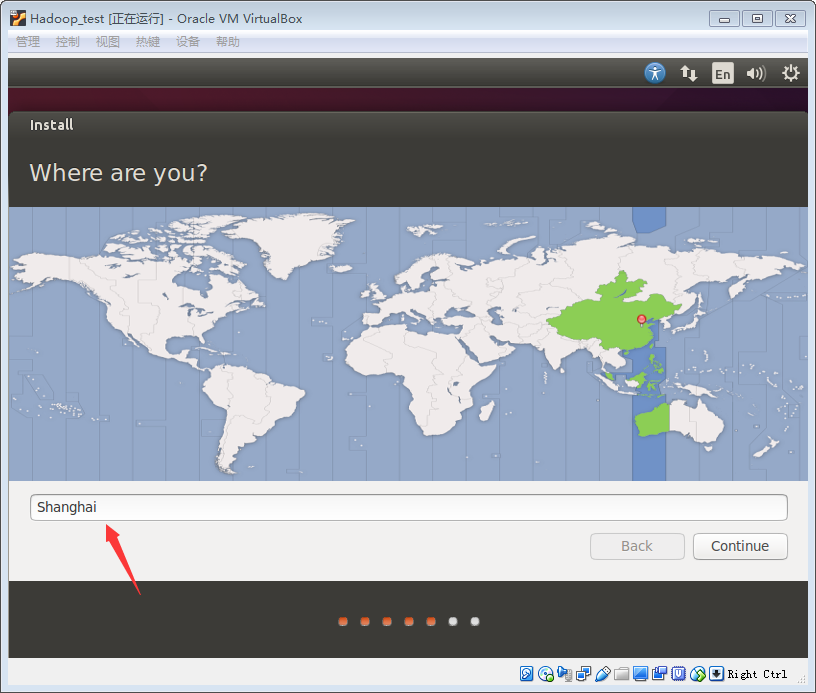
7.选择所在地区
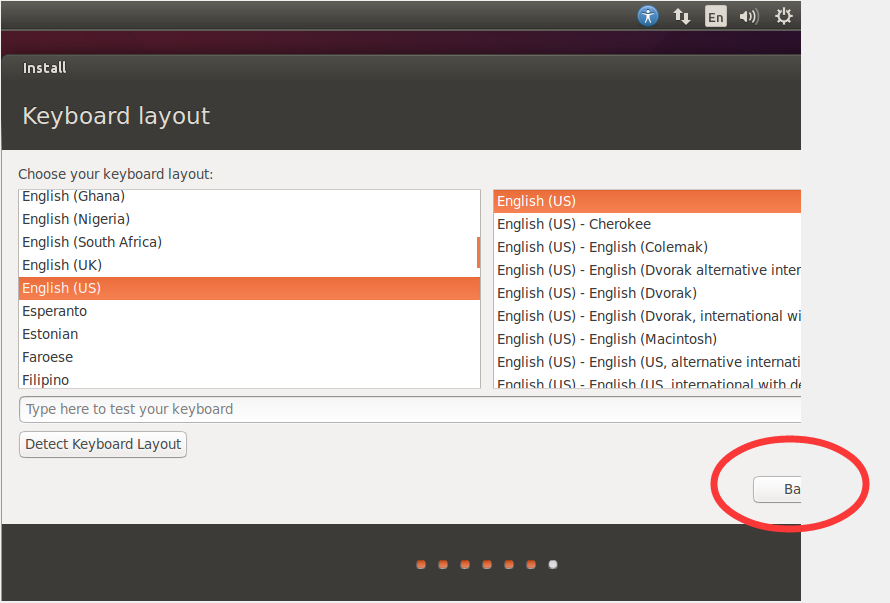
8.这里需要选择键盘布局和键盘语言(这里选择默认,底部有中文)
注意:这里红圈出现显示的一个bug,只显示了Back 的一部分,可以选完之后直接Enter 进入下一步
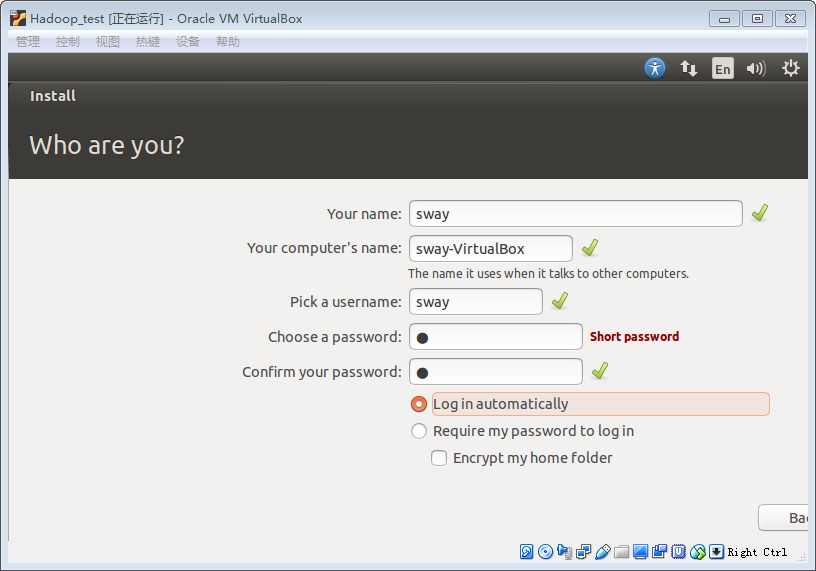
9.设置机器名字和和用户名密码
这里勾选自动登录(依据需求来选择)
PS.这里回车好像不奏效了,可以先在Back上按下鼠标然后脱开,然后按下Tab 再回车 开始安装
(在安装时好像是不可以调整分辨率)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号