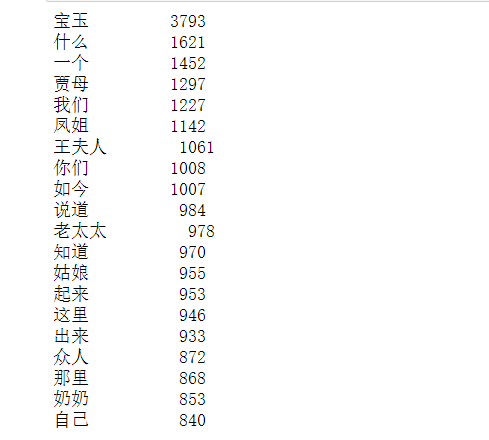
jieba 分词 红楼梦相关的分词,出现次数最高的20个
import jieba text=open('D:/红楼梦/红楼梦.txt',"r",encoding='utf-8').read() words=jieba.lcut(text) counts={} for word in words: if len(word)==1: #排除带个字符的分词效果 continue else: counts[word]=counts.get(word,0)+1 items=list(counts.items()) items.sort(key=lambda x:x[1],reverse=True) for i in range(20): word,count=items[i] print("{0:<10}{1:>5}".format(word,count))

 浙公网安备 33010602011771号
浙公网安备 33010602011771号