
20182109 实验四《Python程序设计》实验报告
20182109 2019-2020-2 《Python程序设计》实验四报告
课程:《Python程序设计》
班级: 1821
姓名: 卢钟添
学号:20182109
实验教师:王志强
实验日期:2020年5月26日
必修/选修: 公选课
1. 实验内容
- Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
2. 实验过程及结果
最后一次的综合性实践,我选择将requests库,正则表达式,列表的应用,pyecharts库等结合在一起,实现一个可以从购物网站上爬取商品价格并比价的小程序。
1. 挑选购物网站
众所周知,各大网站都有针对爬虫的反爬虫协议,可以通过在网址后加上robots.txt来查看该网站是否是反爬虫的。下图显示了iTunes官网的反爬虫协议。
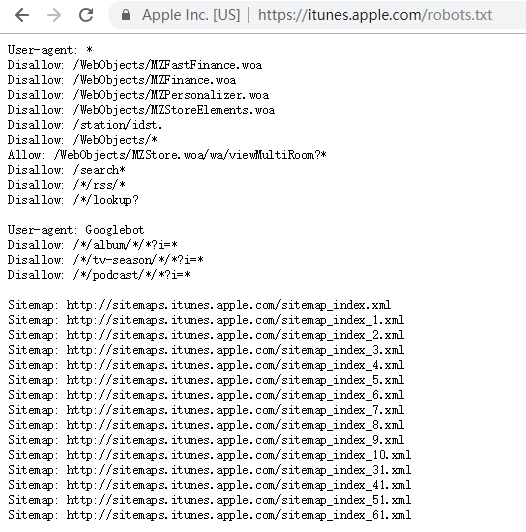
通过查看,我们可以发现,其实各大购物网站上均有诸如此类的反爬虫协议,但是这并不代表着我们不能编写爬虫去爬取网站上商品的信息。事实上,这一类协议是在警告我们,请不要无止境的访问该网址,对服务器造成不必要的麻烦,但如果我们是以一个正常人的频率去访问的话,那完全是允许的。
纵观各大购物网站之后,我选择淘宝作为爬取的对象。因为通过查看网页源码,我发现,淘宝中商品的名称和价格排列较为整齐,故更容易用正则表达式提取出来。至于如何提取,我会在报告的后文中具体分析。
2. 分析淘宝的商品搜索页网址
从下图可以看到,淘宝的商品搜索页网址构成接近于https://s.taobao.com/search?q= + 我们要搜索的商品名

为了使该爬虫更人性化,可以从用户输入处得到要搜索的商品名,并通过字符串链接的功能得到url。
3. 获得淘宝商品搜索页面的html
若某网站没有反爬虫协议,那么在已知url的情况下,我们可以通过requests库自带的get()函数很轻松地得到html文本。但是淘宝网是带有反爬虫协议的网站,所以我们需要在get()函数中添加一个headers变量,这样,淘宝网会将我们的爬虫认作是一个正常访问网页的人类,便可正确的将商品信息展示给该爬虫。
headers变量的获取
以Edge为例,我们用其打开一个网页,在键盘上按下F12后,选择“网络”选项。再刷新该页面,便可以在“请求标头”下得到headers。复制后将其赋值给代码中的一个字符串,作为get()函数的第二个参数,这样就能成功得到html文本文件,用于下面的爬取页面。

4.爬取页面
这一部分是整个代码的核心,即要将商品的名称和价格爬取出来。如图,在淘宝搜索页单击右键->查看网页源代码,可以查看我们得到的html文本,
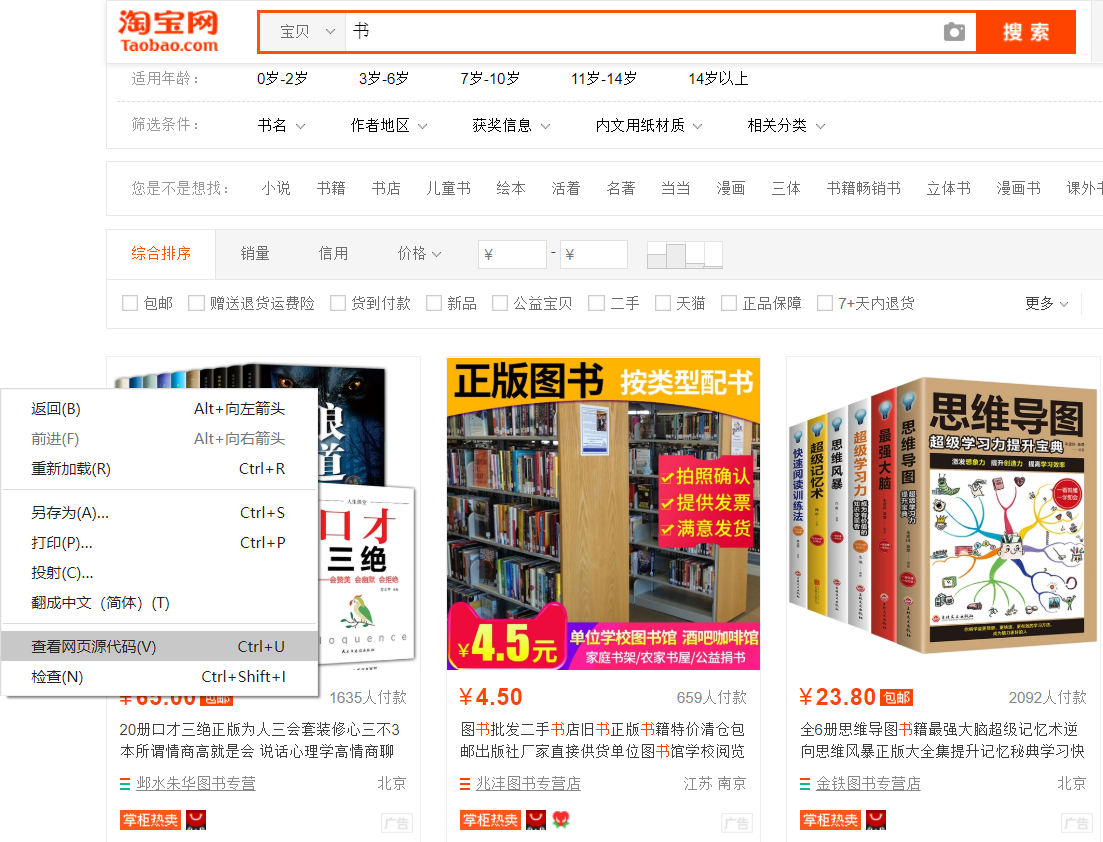
在进入网页源代码页后,为了查看html文本是如何描述商品名称和价格,我们可以复制商品页上第一件商品的名称,并将其作为关键字在源代码页搜索。可以发现商品的名称是存放在raw_title变量中,而价格是存放在view_price变量中。如此一分析,有利于我们编写正则表达式对商品名称和价格进行提取。

利用正则表达式,我们可以写出如下的语句,得到plt和tlt这两个存放所有商品价格和名称的列表
plt = re.findall(r'\"view_price\"\:\"[\d\.]*\"', html)
tlt = re.findall(r'\"raw_title\"\:\".*?\"', html)
接着进入一个循环,通过split分割函数,把同一商品的名称和价格分离出来,将其组合成一个列表的形式,存入代表爬取结果的大列表中。循环的次数代表最后显示的商品数量,可由用户决定。
5. 显示商品清单
先通过正则表达式tplt = "{:4}\t{:8}\t{:16}"来建立一个特定的输出格式,以确保商品清单在输出时不会参差不齐。
接着便可按照上述格式,遍历爬取得到的大列表来输出商品序号、商品价格、商品名称。
6. 输出可视化图表
为实现本程序比价的功能,我还添加了输出可视化图表这一功能。在主函数完成显示输出商品清单后,显示提示信息“是否需要生成可视化图表”。当用户输入yes后,可在D盘根目录下生成一份可视化图表,打开后显示的是各商品以价格为数据的柱状图,更有利于用户直观的进行比价。
同爬取页面这一部分类似,也是从html文本文件中通过正则表达式提取得到商品的名称和价格信息,再将其添加进相应的列表中。只不过,由于可视化图表的大小限制,某一横坐标的信息在过长时会影响其他横坐标的显示,所以在将商品名称添加进列表时可以将其统一为某一长度。
通过从pyecharts中导入Bar库,调用其中的函数,即可生成一份可视化图表,其中部分函数的用法如下。
bar = Bar() # 生成一个柱状图
bar.add_xaxis(tlist) # 横坐标上的每一个点是tlist中的数据,注意tlist应为列表
bar.add_yaxis(goods, plist) # 横坐标上每一个点的y值是plist里对应位置的数据,注意plist也应为列表,goods代表该数据的图例名称
bar.render("D:\***.html") # 在D盘根目录下生成可视化图表文件
7.码云链接
https://gitee.com/python_programming/Python_2020_lzt/blob/master/compare_price.py
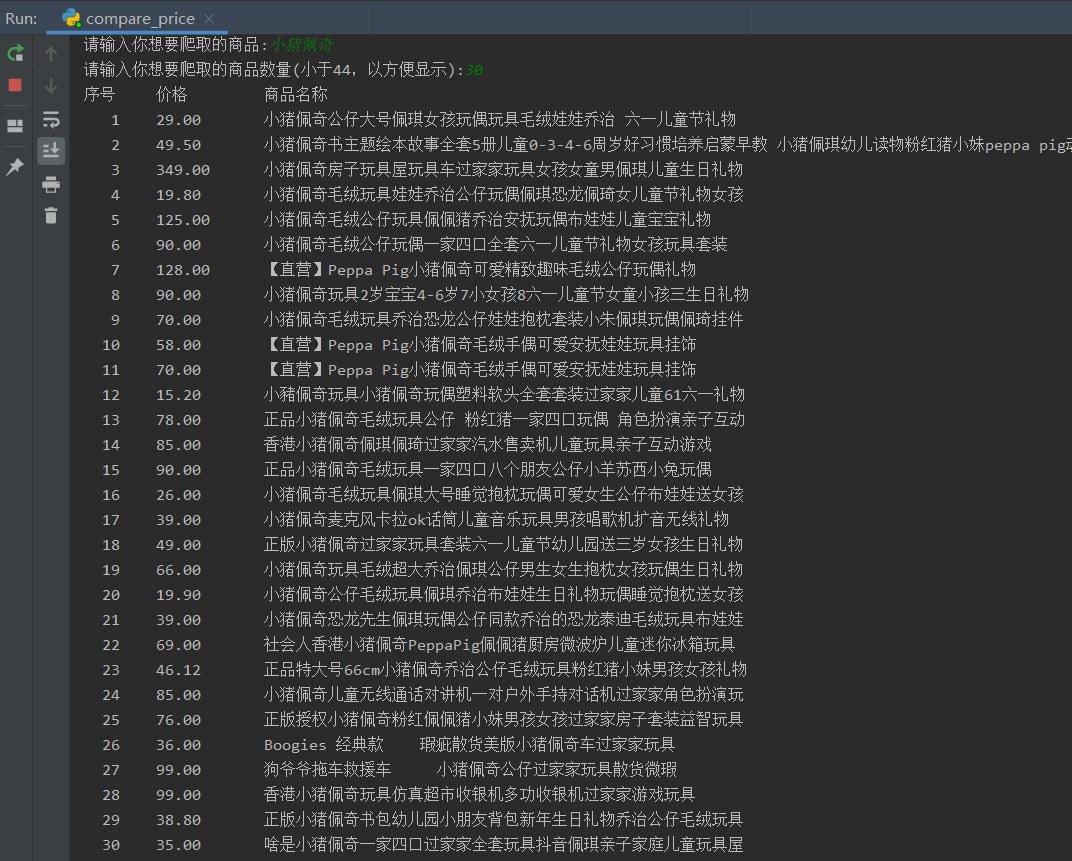
8. 运行结果
下面是在程序中显示的爬取到的商品列表
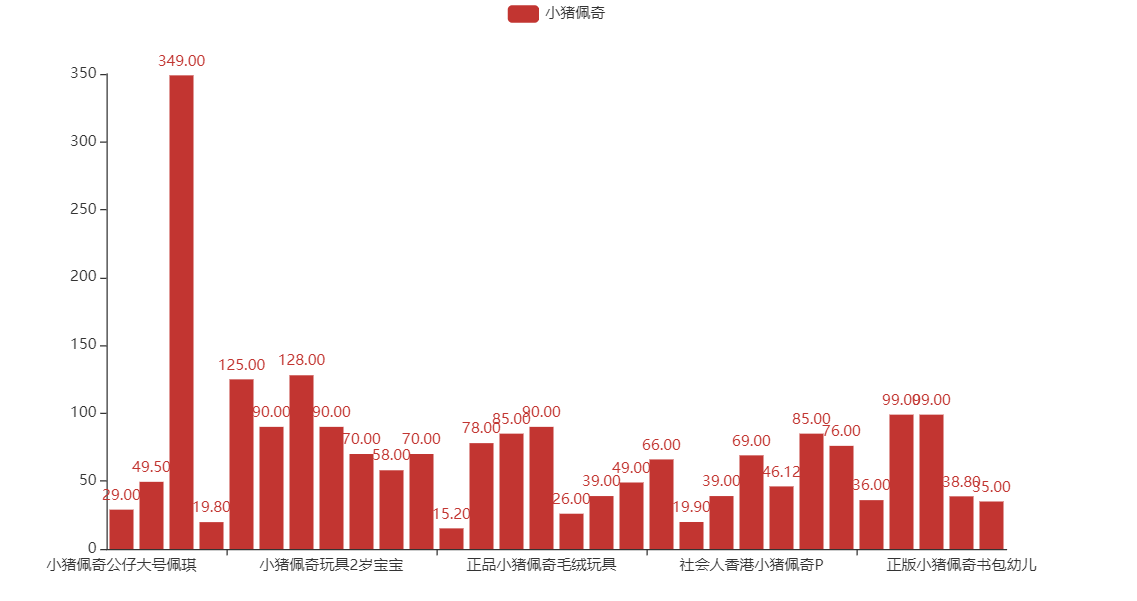
下面这张柱状图可以方便用户进行比价
3. 实验过程中遇到的问题和解决过程
- 问题1:无法调用pyecharts库中的函数来形成可视化图表
- 问题1解决方案:查询发现自己先前使用的时老版本的pyecharts函数,通过查阅pyecharts作者的网站并理解新版本的函数方法后便可成功创建可视化图表了。
- 问题2:使用requests库时,无法从购物网站上爬取到信息。
- 问题2解决方案:请教老师之后得知,现在的购物网站大多有反爬虫协议,所以应该在调用requests函数时加上headers,以标明这是以个人身份访问该网站的。
- 问题3:可视化图表里的商品名称显示不完全
- 问题3解决方案:限定加入商品名称列表的数据长度,即可适当优化显示问题
4. 课程感想与体会
总结一下这学期学到的知识,包括但不限于流程控制语句,Python独有的序列这种变量,字符串与正则表达式,面向对象语言所特有的类和对象,对文件的操作,Socket套接字编程,爬虫。站在自己的角度,这一学期的学习,让我对Python这一门语言从有兴趣到感兴趣。当然我也知道,自己所掌握的些许知识点只能算是皮毛,互联网时代已然来临,更多的要靠我们自己去探索,去发现。就像Python这一门语言一样,身为新时代的人类,要学着适应新环境、新变化,要在奔涌的洪流中进化自己,要试着在某个领域中独当一面。
从每节课后拖着不完成任务,到课后抢着完成作业,王老师的教学方式起到很大的督促作用。所以说,在课堂上,学生学到的不仅仅是那呆板的教科书式的知识,还有老师教导我们对待事情的态度。不单单局限于课堂上,等我们踏上社会,走入工作岗位时也是一样,有工作时就应当准时,细心,认真地完成。因为,没有谁会喜欢那个拖拖拉拉,吊儿郎当的人。
犹记得第一节课时,王老师让我们写下对这学期Python课的展望,我言之凿凿,情之笃定地写下了“虽然这学期课挺多的,但还是希望能抽出时间来学习Python”。时间如白马过隙,转眼间,伴随我大半学期的Python课程也迎来了最后一次实验。回首这一学期的学习,虽然仍有松懈、迷茫的时候,每次在听到王老师志气满满地给我们授课时,我总能燃起最初的那一份热情。所以,我也希望今后自己失去动力时,都要想起大二下在家上网课期间的那份坚持。
5. 意见和建议
疫情期间,网课成了学生党们热议的话题。在我看来,与线下课程不同的是,网络课让我们体会到其实网络上也有丰富、优质的资源。在课下,学生完全可以提前预习下一节课甚至下多节课的知识点,而老师在课上充当的可以只是一名答疑者,即学生有不懂的问题,再去请教老师。综上所述,我非常幸运,体验到了王老师在这学期课程上所做出的创新,也很惊喜的发现,在这样的新模式下,我能够培养自己的能力,从而学到更多的知识。最后,提一点小小的建议,希望老师在每节课后抛出的加分小彩蛋能再多延长些时间,因为有时会碰到其他课程作业的ddl,我没法按时“体验”这些有趣的小彩蛋,就很可惜QAQ。
参考资料
- 《python编程 从入门到实践》

 浙公网安备 33010602011771号
浙公网安备 33010602011771号