动手学深度学习 | 批量归一化 | 26
批量归一化

现在卷积神经网基本都是要使用到BN层的。BN层的思想不新,但是这个特定的层确实是最近几年才出来的,而且大家会发现效果很好。而且当大家要把网络做深的时候,这就是一个不可避免的层了。

梯度在上面的层会大,越往下面梯度会越来越小。
这就导致了一个很大的问题,就是上面的层梯度较大,那么权重更新比较快,也就是收敛的快;但是下面的层因为梯度小,所以参数更新的慢,收敛的慢。但是因为底部的层是抽取比较底层的特征,所以每次底层的参数一更新,高层的参数又需要重新训练(底层的信息一变,那么上面就白学了)。
批量归一化:我们能不能在学习底部的时候避免变化顶部层?
我们讲数值稳定性的时候,为什么参数会变?是因为不同层之间的方差和均值的整个分布会变化。
那么简单的办法是说,假设把分布给固定住,就不管那一层,输出也好,梯度也好,假设都符合某个分布,那么相对来说就会比较稳定。
BN的想法就是希望让层和层之间的分布保持一致。
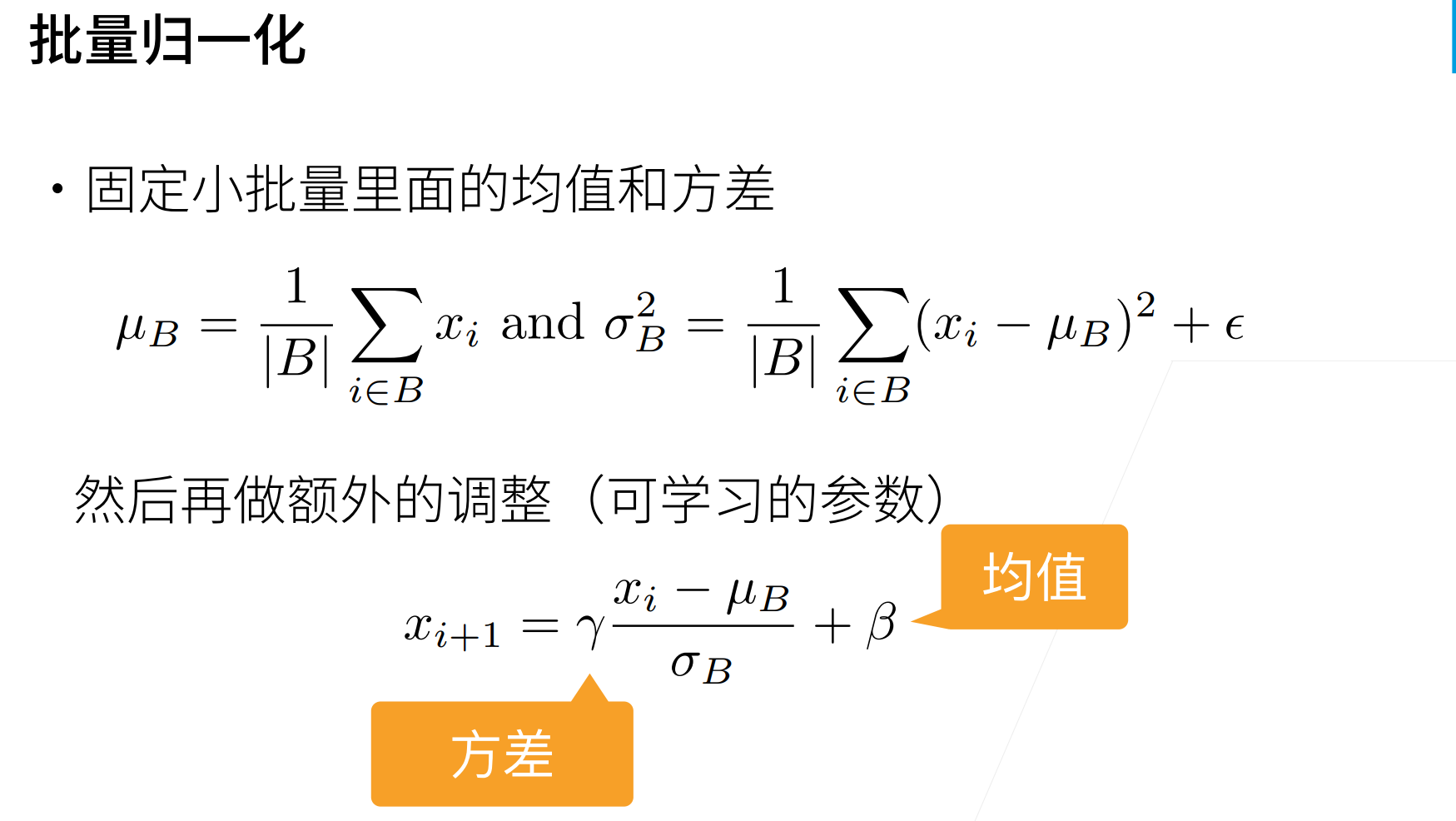
批量的均值: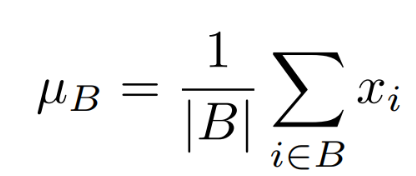
批量的方差: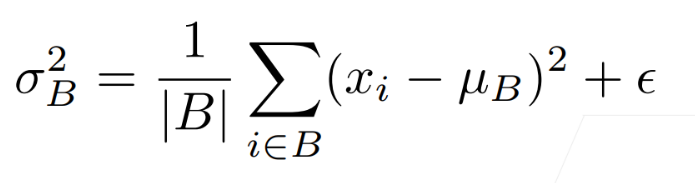
这里最后加一个很小的值就是为避免其方差为0。

\(x_{i+1}\)也就是下一层的输出,保持在和\(x_i\)在同一个分布,其中还有两个可以学习的参数\(\gamma,\beta\),为什么要有这两个参数呢?因为如果均值为0,方差为1的效果不好的话,那么可以再将这个均值和方差进行调整。




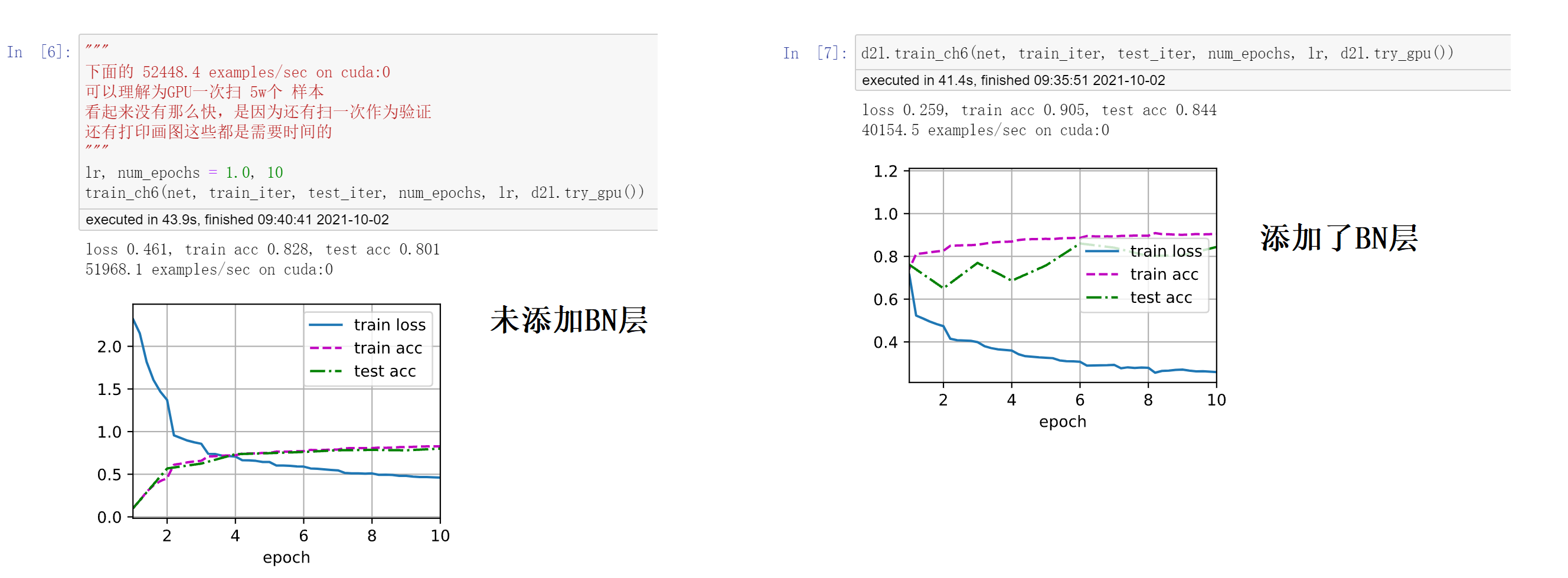
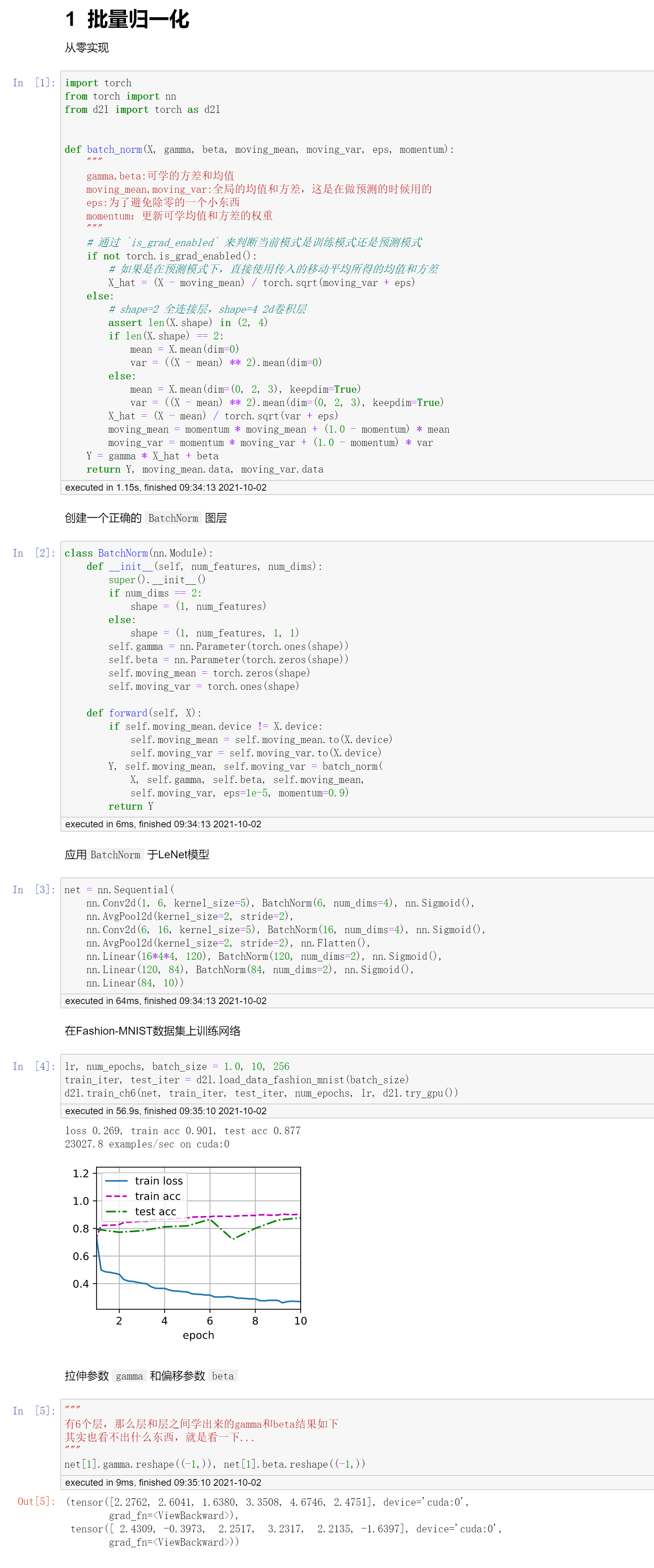
可以看看下面添加了BN层和未添加BN层的效果,前者的震动幅度较大,后者一开始损失什么的基本就可以认为在“同一分布”。后者收敛的速度更快,或者换句话说,未添加BN层可能过多几个epoch(比如20个)也可以达到添加BN层少几个epoch(比如10个)的效果。
代码
首先是简洁实现

然后再是具体的实现代码
QA
- 在将xavier的时候,也讲过类似normalization的东西,和BN什么区别?
本质上没有区别,是一个思想。就是模型的参数稳定了,收敛就不会慢。
xavier初始化是说在初始的时候,选取和合适的初始化参数能够使得模型稳定,但是不能保证之后。BN层则是在训练的时候,在每一层都进行一次“归一化”。
- BN是不是和权重衰退的作用类似?
权重衰退可以认为是每次更新权重的时候都除了一个小值(就是不要让权重的变化范围太大)
但是BN却不会太多的影响前一层的权重。
- BN能用在MLP中吗?
可以的,但是如果网络不深的话其实作用不大。
一般都是网络较深的时候才会出现上层更新快,下层更新慢的问题。
也就是BN层一般用于深层网络,浅层的MLP加上BN效果不会见得很棒。
- 为什么使用了BN收敛时间会变短?
因为BN可以让梯度正大(就不会到底层的时候变的很小),那么就可以适当增大学习率,加速收敛。
- 训练时候如何对epoch,batch_size,lr的数值进行设置?
epoch数总是可以选择大一点是没有关系的,就是浪费点资源。
batch_size你要选到合适,不能选择太大,也不能选择太小,一般batch_size就调整到一个GPU效率比较高的情况。
lr是在batch_size后面在进行调整的。
- batch_size是把显存占满好?还是利用率gpu-tuil 100%就可以了?还是需要同时达到100%?
利用率不要到100%,到90%就可以了。
或者这么讲,你去增加batch_size,去看看GPU每秒中能处理的样本数,如果batch_size到一定程度没有增加每秒处理样本数的话,batch_size就可以停止了。
下图是LeNet训练fashion-mnist时候batch_size和每秒处理样本数的差别,可以看到,其实1024的时候是并行度最好的,因为再往上加到2048,其实并行效果并没用说成倍的增加。(而且batch_size也不是越大越好,小一点的batch_size可以增加模型的泛化能力,相当于就是加入了噪音)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号