动手学深度学习 | 权重衰退 | 10
权重衰退
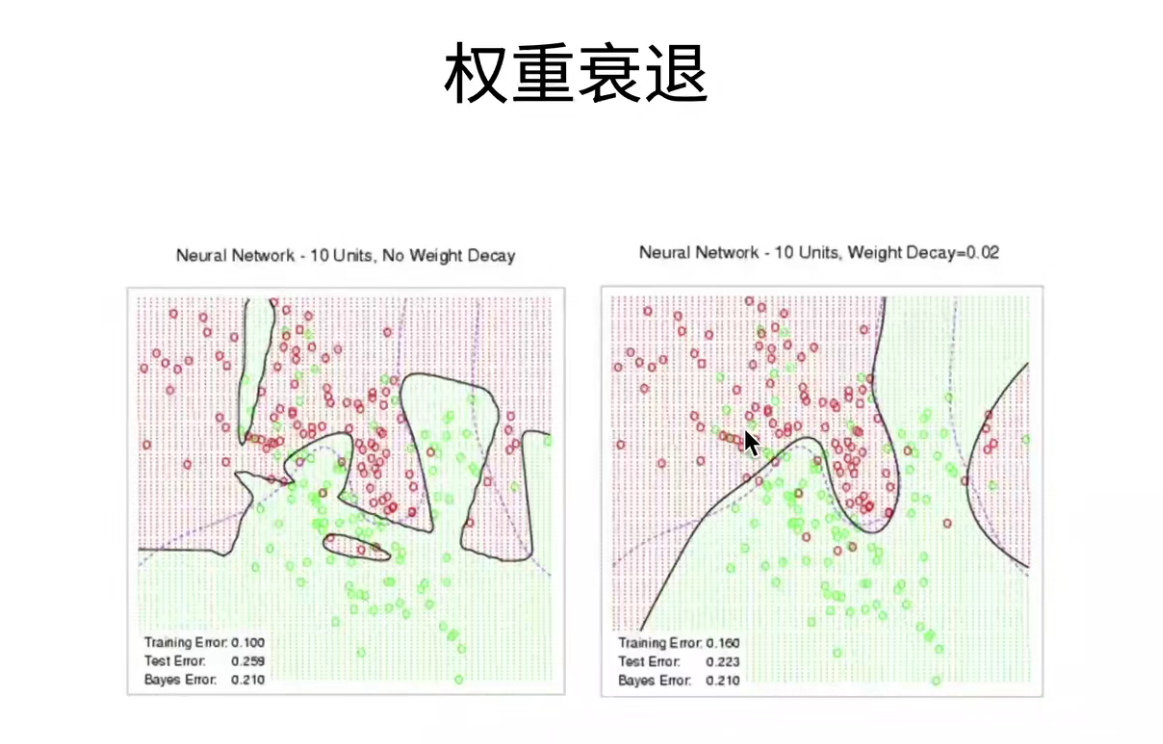

如何控制模型的容量呢?
- 模型参数个数
- 参数的取值范围
权重衰退就是控制参数的取值范围来控制模型容量的。
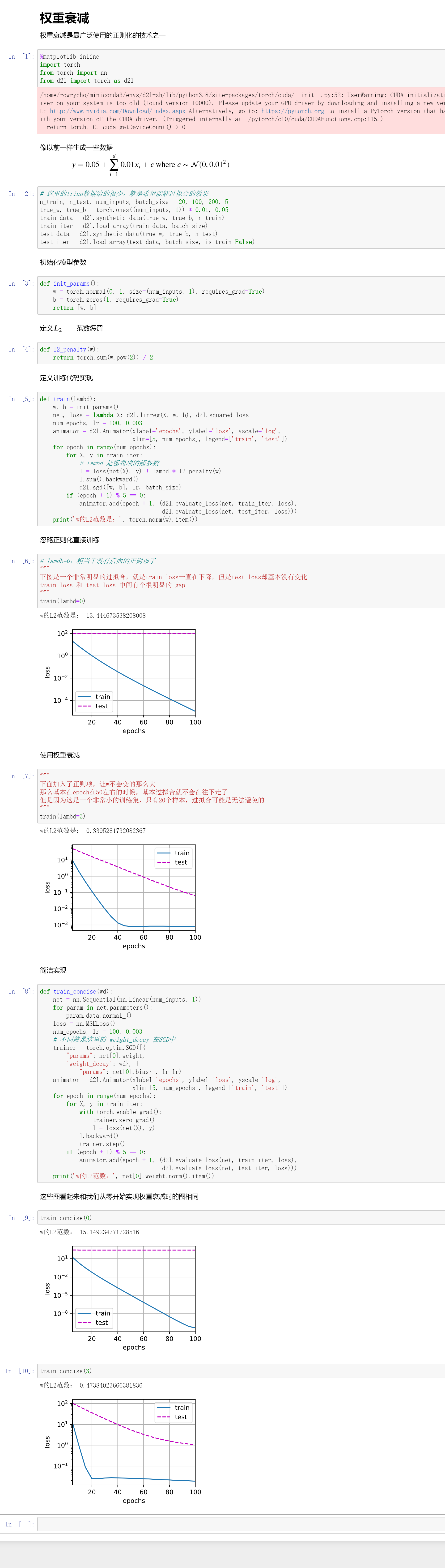
上面的\(||w||^2 \leq \theta\) ,则表示为每一个\(w\)都是要小于\(\sqrt{\theta}\)。其实也就是强行设置参数的取值的上限。
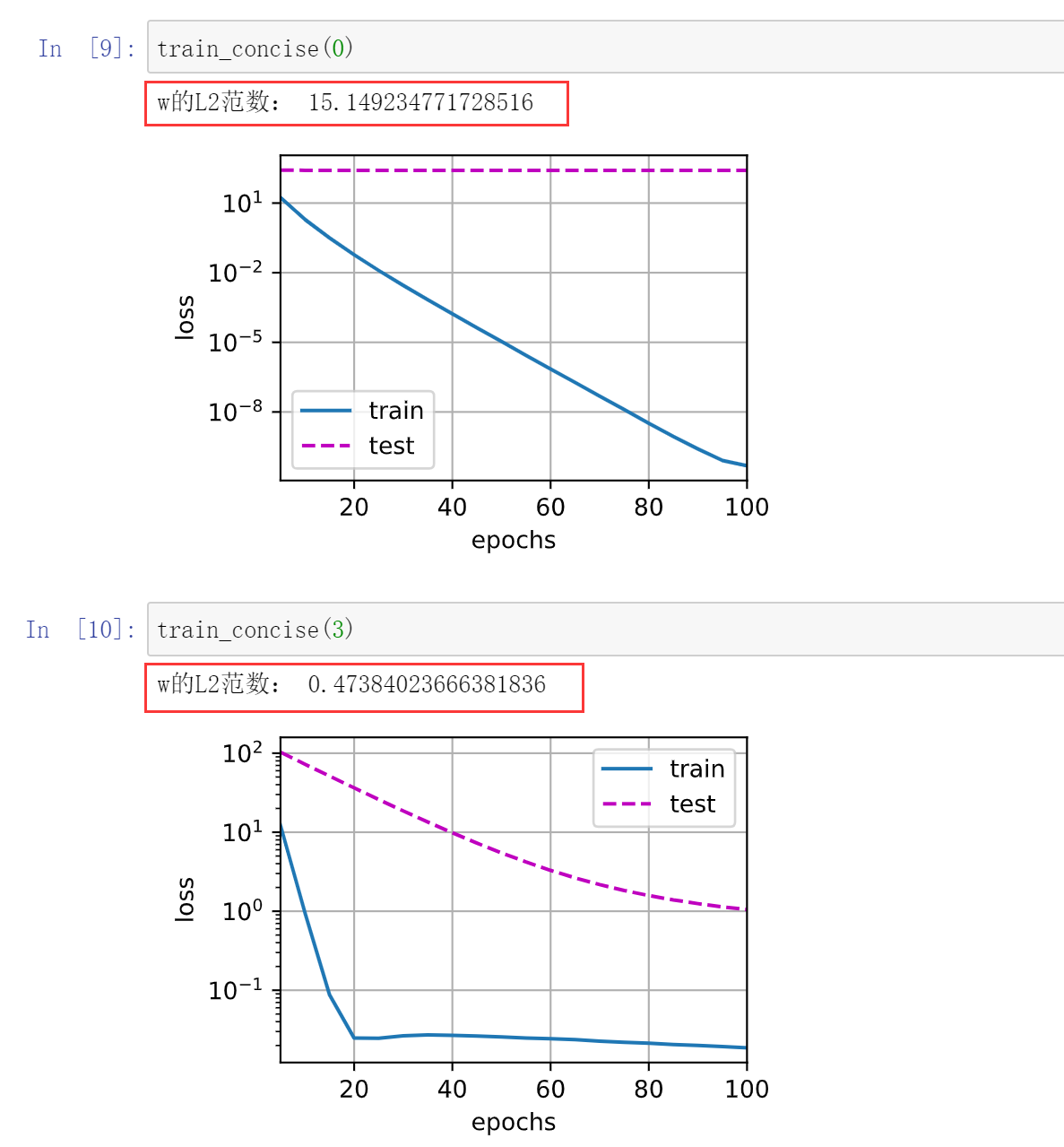
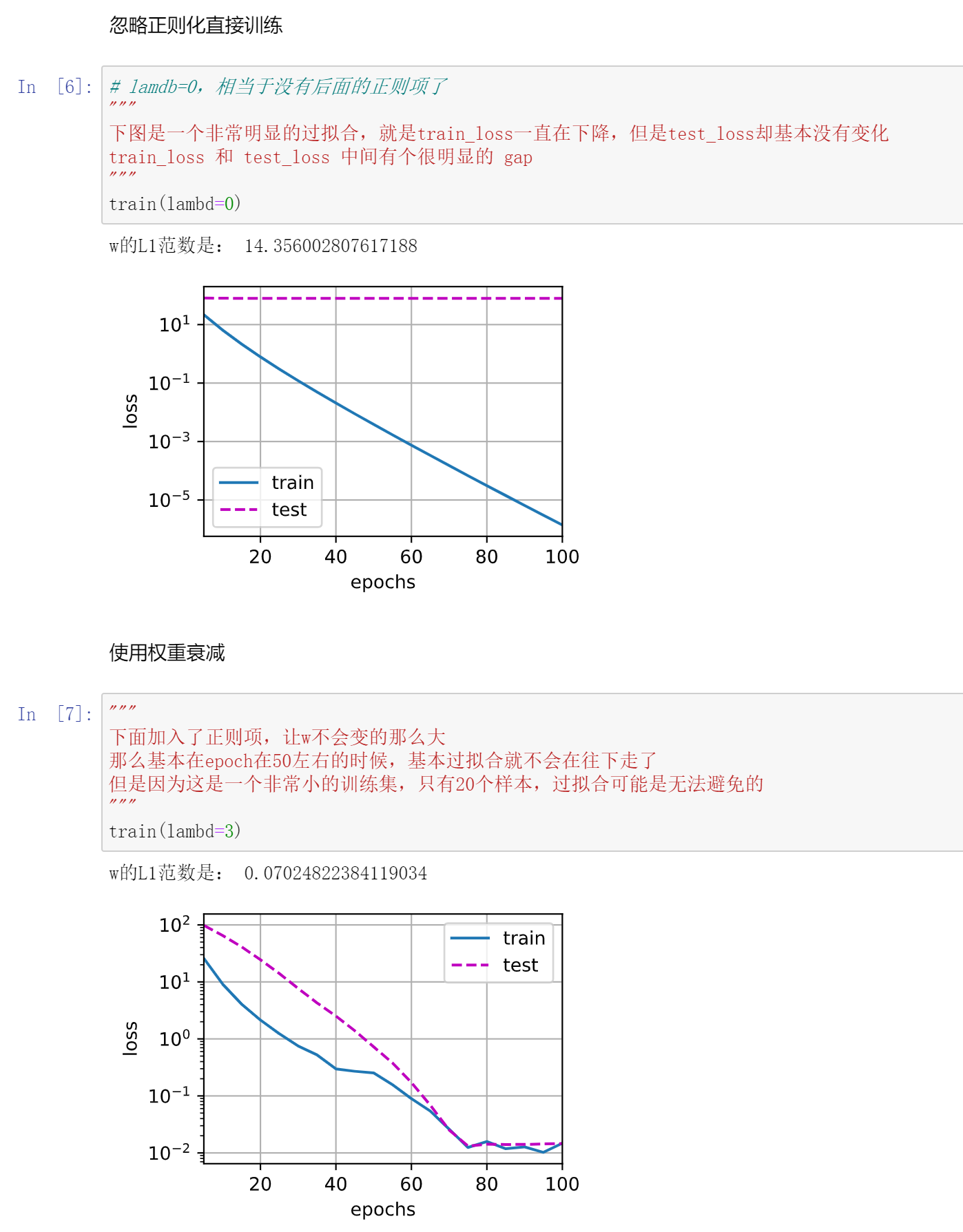
加了这个罚之后,w确实会变小很多。

我们一般不会用上面的优化方式,而是用这个。
对于每个\(\theta\),都可以找到一个\(\lambda\),是的loss变成 \(min\quad l(w,b)+\frac{\lambda}{2}||w||^2\)

原来绿色圈的最低点就是最优化的点,但是现在加入了一个惩罚项(就是为了限制参数的取值范围),那么loss的最优点位置就会发生变化了。橙色的最低点是惩罚项的最优点,但是\(min\quad l(w,b)+\frac{\lambda}{2}||w||^2\),也就是其中一个变大,另外一个就会变小,所以会找到一个平衡点。
加入惩罚项后,确实是会对最优点产生影响的。

这里是引入了\(\lambda\),而这个\(\lambda\)也是需要训练的,是个二次函数。
经过上面的数学推到,最终可以得到\(w_{t+1}=(1-\eta)w_t-\eta\frac{\partial l(w_t,b_t)}{\partial w_t}\),而且通常这个\(\eta\lambda\)是小于1的,也就是在正常计算梯度下降的时候,就先把\(w_t\)给缩小了,然后在沿着梯度的方向在走一点点。
为什么叫做权重衰退?因为\(\lambda\)的引入,使得我们在更新前,我们把当前的权重做了一次放小,这就被认为是一次衰退。

代码实现
QA
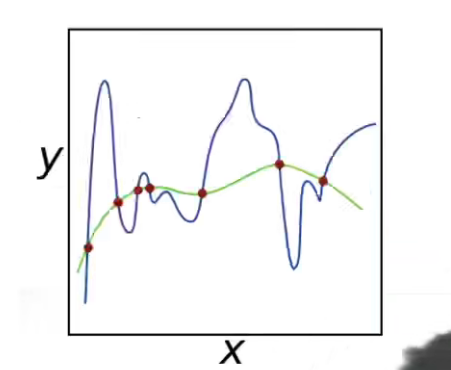
- 为什么参数不过大,模型复杂度就低呢?
其实不是参数不过大,模型的复杂度就低。
如下图,我们是限制参数只能在一个小范围内取值,这就意味着参数不可能像蓝线那样去拟合(这种大开大方需要很大的一个参数取值范围),但是我们强制规定了参数只能在一个比较小的取值范围取值,那么就会是的拟合的曲线比较平缓,如绿线。
拟合一条比较平缓的曲线,换句话说就是让模型不要那么复杂,也就是防止了过拟合。
- 如果是用L1范数的话,如何更新权重?
其实是一样的更新方式,只不过把L2变成了L1,编码并没有什么变化。
可以看到,如果是使用了L1范数来作为罚的话,其实会更加的强硬。
- 实践中权重衰退的值一般设置为多少好呢?之前在跑代码的时候总感觉权重衰退的效果并不好。
一般权重衰退的值都是设置为e-2,e-3,e-4。
其实权重衰退效果有一点点,但是你不要太指望。后面会介绍更多的手段来进行模型复杂度的控制,权重衰退它确实就那么一点点效果。如果你的模型真的很复杂,权重衰退并不会给你带来很好的效果。
像对于MLP来说,可能后面讲的dropout层效果会更好一点。
- 为什么要把w往小拉,如果最优解的w就是比较大的数,那权重衰退是不是会有反作用?
实际是不可能到达最优解的,因为存在噪音。有罚的存在就是为了让w不要太受到噪音的干扰。
w_true=0.01,如果正则项的话,w会训练的很大...
在看加入正则项的,基本训练出来的w都是在e-2的这个范围

 浙公网安备 33010602011771号
浙公网安备 33010602011771号