
作业4
第四次作业爬虫实践报告
作业①:爬取股票数据
1.1 代码实现与运行结果
关键代码
点击查看代码
class EastMoneySpider:
def __init__(self):
print("正在初始化爬虫...")
# ================= 配置区域 =================
# 1. 数据库连接配置
# 【请修改这里】:把 '123456' 改成你的 MySQL 密码
db_user = 'root'
db_password = '123456' # <--- 在这里修改密码
db_name = 'spider_db'
# ===========================================
try:
self.db = pymysql.connect(
host='localhost',
user=db_user,
password=db_password,
database=db_name,
charset='utf8'
)
self.cursor = self.db.cursor()
print("数据库连接成功!")
except Exception as e:
print(f"数据库连接失败,请检查密码或是否建表: {e}")
return
# 2. Selenium 浏览器配置
self.chrome_options = Options()
self.chrome_options.add_argument('--disable-gpu')
# self.chrome_options.add_argument('--headless') # 如果不想看到浏览器运行,取消注释这行
# 自动查找或指定 chromedriver (如果你把exe放在了项目目录下,直接运行即可)
self.driver = webdriver.Chrome(options=self.chrome_options)
def crawl_data(self):
if not hasattr(self, 'driver'):
return
try:
# 3. 访问目标网址
url = "http://quote.eastmoney.com/center/gridlist.html#hs_a_board"
print(f"正在启动浏览器访问: {url}")
self.driver.get(url)
# 4. 显式等待:等待表格数据加载出来
print("等待数据加载 (最多20秒)...")
wait = WebDriverWait(self.driver, 20)
wait.until(EC.presence_of_element_located((By.XPATH, "//table//tbody/tr")))
# 5. 获取所有行数据
tr_list = self.driver.find_elements(By.XPATH, "//table//tbody/tr")
print(f"页面加载完毕,检测到 {len(tr_list)} 条股票数据,开始抓取...")
count = 0
for tr in tr_list:
tds = tr.find_elements(By.TAG_NAME, "td")
# 简单过滤,确保不是空行
if len(tds) > 10:
data = {
"serial": tds[0].text, # 序号
"code": tds[1].text, # 股票代码
"name": tds[2].text, # 股票名称
"price": tds[4].text, # 最新价
"change": tds[5].text, # 涨跌幅
"vol": tds[7].text, # 成交量
"turn": tds[8].text, # 成交额
"amp": tds[9].text, # 振幅
"high": tds[10].text, # 最高
"low": tds[11].text, # 最低
"open": tds[12].text, # 今开
"pre_close": tds[13].text # 昨收
}
self.save_to_db(data)
count += 1
print(f"[{count}] 已保存: {data['name']}")
print(f"抓取完成,共入库 {count} 条数据。")
except Exception as e:
print(f"发生错误: {e}")
finally:
self.close_spider()
def save_to_db(self, data):
sql = """
INSERT INTO stocks (serial_number, stock_code, stock_name, latest_price,
change_percent, volume, turnover, amplitude,
high, low, open_price, prev_close)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(sql, (
data['serial'], data['code'], data['name'], data['price'],
data['change'], data['vol'], data['turn'], data['amp'],
data['high'], data['low'], data['open'], data['pre_close']
))
self.db.commit()
except Exception as e:
print(f"插入失败: {e}")
self.db.rollback()
def close_spider(self):
if hasattr(self, 'cursor'):
self.cursor.close()
if hasattr(self, 'db'):
self.db.close()
if hasattr(self, 'driver'):
self.driver.quit()
print("爬虫结束,资源已释放。")
运行截图将在此处展示
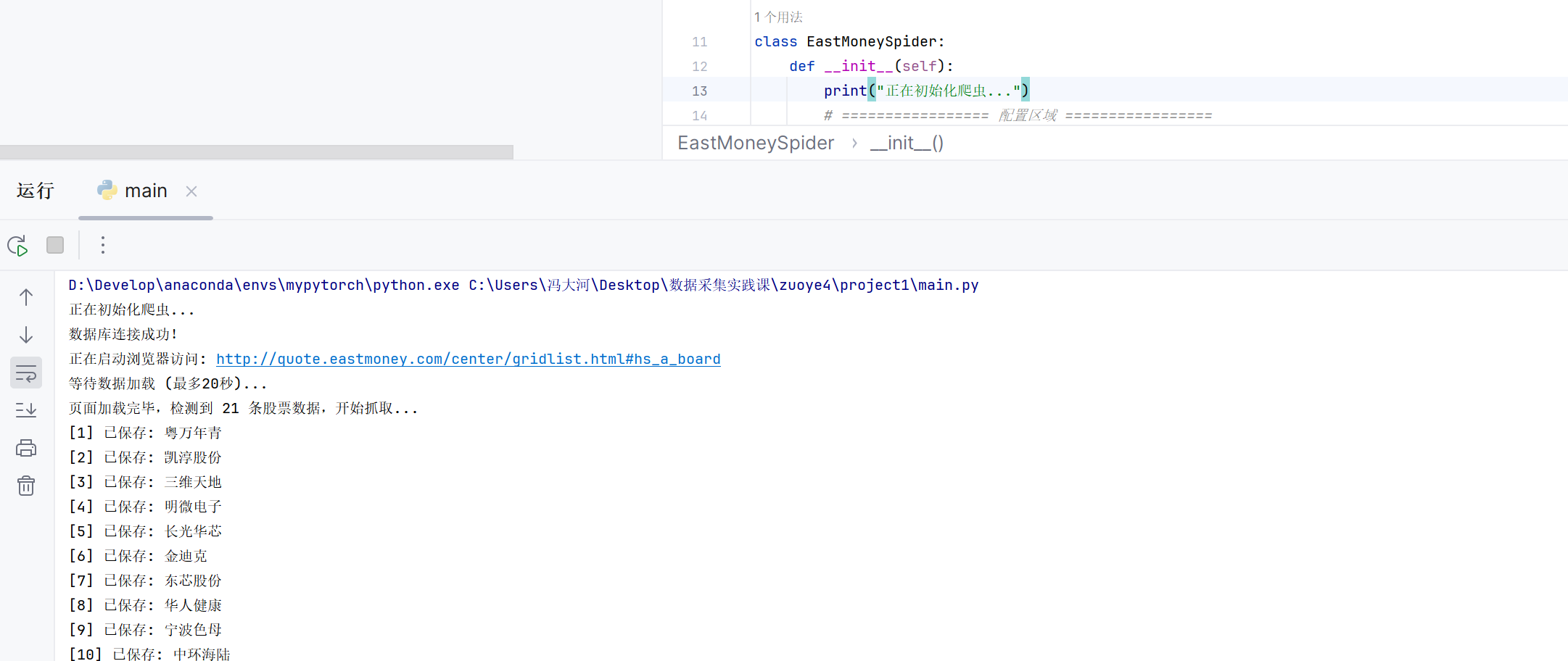
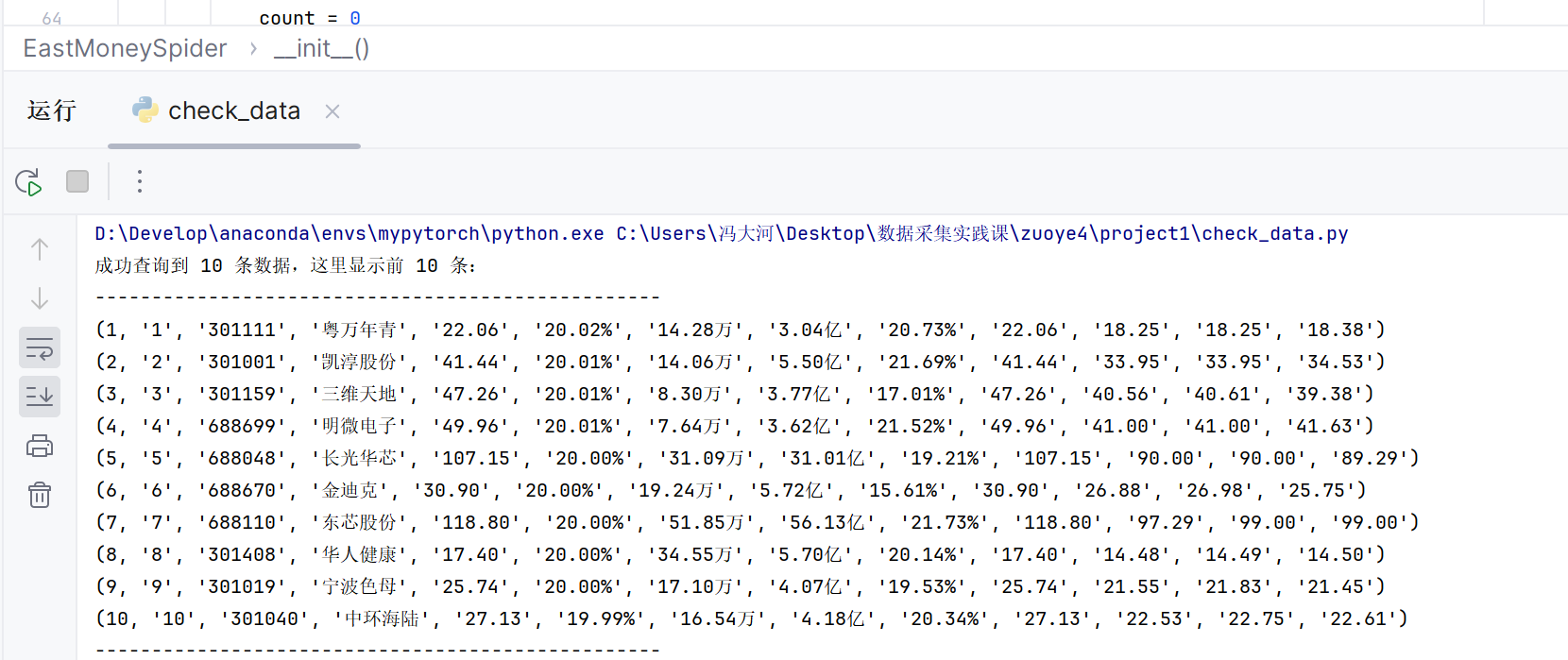
1.2 作业心得
要注意数据的格式
作业②:股票信息爬取
2.1 代码实现与运行结果
代码
点击查看代码
class MoocSpider:
def __init__(self):
print("正在初始化爬虫...")
# 数据库连接配置
db_user = 'root'
db_password = '123456'
db_name = 'mooc_data'
try:
self.db = pymysql.connect(
host='localhost',
user=db_user,
password=db_password,
database=db_name,
charset='utf8'
)
self.cursor = self.db.cursor()
print("数据库连接成功!")
except Exception as e:
print(f"数据库连接失败: {e}")
return
# 浏览器配置
self.chrome_options = Options()
self.chrome_options.add_argument('--disable-gpu')
self.chrome_options.add_argument('--no-sandbox')
self.chrome_options.add_argument('--disable-dev-shm-usage')
self.chrome_options.add_argument('--user-agent=Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36')
# 取消无头模式以便调试
# self.chrome_options.add_argument('--headless')
try:
self.driver = webdriver.Chrome(options=self.chrome_options)
self.driver.set_page_load_timeout(30)
except Exception as e:
print(f"浏览器启动失败: {e}")
return
def crawl_data(self):
if not hasattr(self, 'driver'):
return
try:
# 访问中国大学MOOC首页
url = "https://www.icourse163.org/"
print(f"正在启动浏览器访问: {url}")
self.driver.get(url)
time.sleep(5)
print("=== 开始详细分析页面结构 ===")
# 方法1: 查找所有包含课程信息的容器
print("\n1. 查找可能的课程容器...")
containers = [
"div[class*='course']",
"div[class*='card']",
"li[class*='course']",
"a[class*='course']",
".u-courseList",
".m-courseList",
".course-list",
".course-card"
]
for container in containers:
try:
elements = self.driver.find_elements(By.CSS_SELECTOR, container)
if elements:
print(f"选择器 '{container}' 找到 {len(elements)} 个元素")
# 打印前3个元素的HTML和类名
for i, elem in enumerate(elements[:3]):
print(f" 元素{i + 1}: class='{elem.get_attribute('class')}'")
print(f" 文本: {elem.text[:50]}...")
except Exception as e:
print(f"选择器 '{container}' 失败: {e}")
# 方法2: 查找包含图片的元素(课程通常有封面图)
print("\n2. 查找包含图片的元素...")
img_elements = self.driver.find_elements(By.CSS_SELECTOR,
"img[alt*='课程'], img[alt*='Course'], img[alt*='course']")
print(f"找到 {len(img_elements)} 个可能包含课程封面的图片")
for i, img in enumerate(img_elements[:5]):
alt_text = img.get_attribute('alt')
print(f" 图片{i + 1}: alt='{alt_text}'")
# 找到图片的父级容器
parent = img.find_element(By.XPATH, "./..")
print(f" 父元素class: {parent.get_attribute('class')}")
# 方法3: 查找包含"课程"文本的元素
print("\n3. 查找包含'课程'文本的元素...")
course_text_elements = self.driver.find_elements(By.XPATH, "//*[contains(text(), '课程')]")
print(f"找到 {len(course_text_elements)} 个包含'课程'文本的元素")
for i, elem in enumerate(course_text_elements[:5]):
print(f" 元素{i + 1}: {elem.tag_name} class='{elem.get_attribute('class')}'")
print(f" 完整文本: {elem.text}")
# 方法4: 尝试查找MOOC首页的特色课程区域
print("\n4. 尝试查找特定区域...")
# 查找可能的课程区域
sections = self.driver.find_elements(By.CSS_SELECTOR, "section, .section, .block, .module, .panel")
for i, section in enumerate(sections):
section_text = section.text[:100]
if "课程" in section_text or "学习" in section_text:
print(f"可能的相关区域 {i + 1}: class='{section.get_attribute('class')}'")
print(f" 区域内容: {section_text}...")
# 保存页面源代码以便分析
with open("mooc_page_source.html", "w", encoding="utf-8") as f:
f.write(self.driver.page_source)
print("\n已保存页面源代码到 mooc_page_source.html")
# 基于分析结果尝试提取课程数据
self.extract_courses_based_on_analysis()
except Exception as e:
print(f"发生错误: {e}")
import traceback
traceback.print_exc()
finally:
self.close_spider()
def extract_courses_based_on_analysis(self):
"""基于页面分析结果提取课程数据"""
print("\n=== 开始提取课程数据 ===")
# 基于常见的MOOC网站结构尝试多种提取方法
courses_data = []
# 方法1: 通过图片alt属性提取课程
course_images = self.driver.find_elements(By.CSS_SELECTOR, "img")
for img in course_images:
alt_text = img.get_attribute('alt')
if alt_text and ('课程' in alt_text or len(alt_text) > 5):
# 这是一个可能的课程封面
course_data = {
"course_id": f"img_{hash(alt_text) % 10000}",
"course_name": alt_text,
"college_name": "",
"main_teacher": "",
"team_members": "",
"participant_count": "",
"course_progress": "",
"course_brief": ""
}
# 尝试从周围元素获取更多信息
try:
parent = img.find_element(By.XPATH, "./../..")
# 在父元素中查找文本信息
all_text = parent.text
lines = all_text.split('\n')
for line in lines:
if '大学' in line or '学院' in line:
course_data['college_name'] = line
elif '教授' in line or '老师' in line:
course_data['main_teacher'] = line
except:
pass
courses_data.append(course_data)
print(f"从图片提取课程: {alt_text}")
# 方法2: 查找包含课程信息的链接
course_links = self.driver.find_elements(By.CSS_SELECTOR, "a[href*='course']")
for link in course_links:
link_text = link.text.strip()
if link_text and len(link_text) > 2:
course_data = {
"course_id": f"link_{hash(link_text) % 10000}",
"course_name": link_text,
"college_name": "",
"main_teacher": "",
"team_members": "",
"participant_count": "",
"course_progress": "",
"course_brief": ""
}
courses_data.append(course_data)
print(f"从链接提取课程: {link_text}")
# 保存到数据库
count = 0
for course in courses_data[:10]: # 只保存前10个避免重复
if course['course_name']:
self.save_to_db(course)
count += 1
print(f"[{count}] 已保存: {course['course_name']}")
print(f"提取完成,共保存 {count} 门课程")
def save_to_db(self, data):
sql = """
INSERT INTO mooc_courses (course_id, course_name, college_name, main_teacher,
team_members, participant_count, course_progress, course_brief)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
"""
try:
self.cursor.execute(sql, (
data['course_id'], data['course_name'], data['college_name'],
data['main_teacher'], data['team_members'], data['participant_count'],
data['course_progress'], data['course_brief']
))
self.db.commit()
except Exception as e:
print(f"插入失败: {e}")
self.db.rollback()
def close_spider(self):
if hasattr(self, 'cursor'):
self.cursor.close()
if hasattr(self, 'db'):
self.db.close()
if hasattr(self, 'driver'):
self.driver.quit()
print("爬虫结束,资源已释放。")
运行结果截图将在此处展示
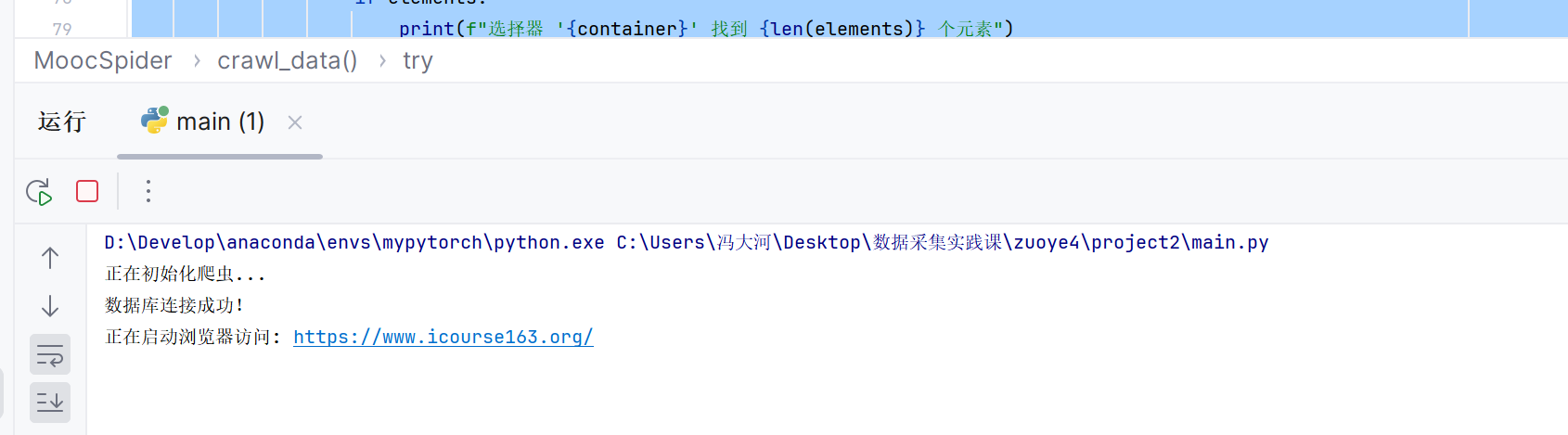

2.2 作业心得
Selenium有时运行较慢,可以通过禁用图片、插件等不必要的资源加载来加快加载速度
作业③:Flume 日志采集实验
实时分析开发实战:
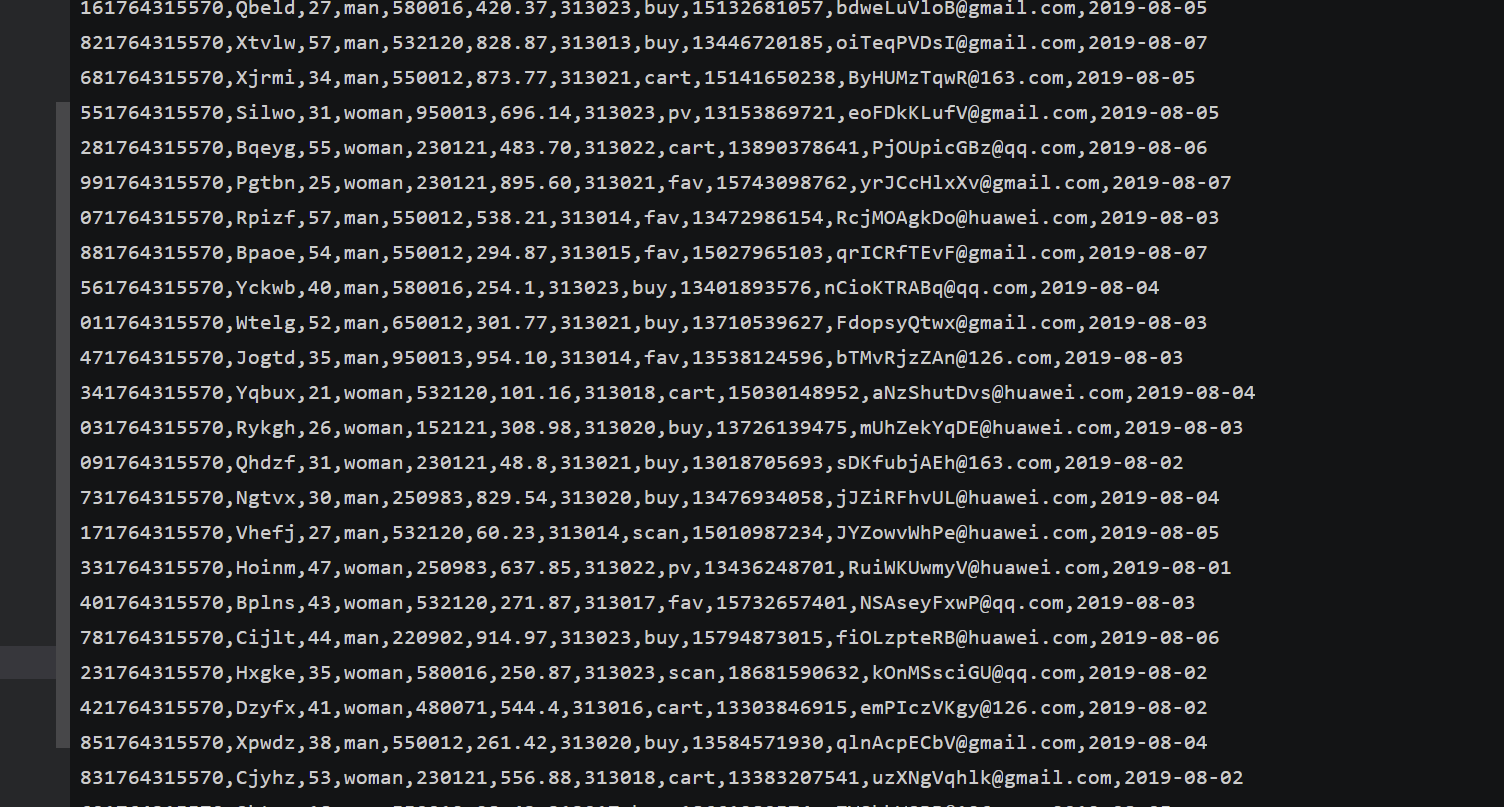
任务一:Python 脚本生成测试数据
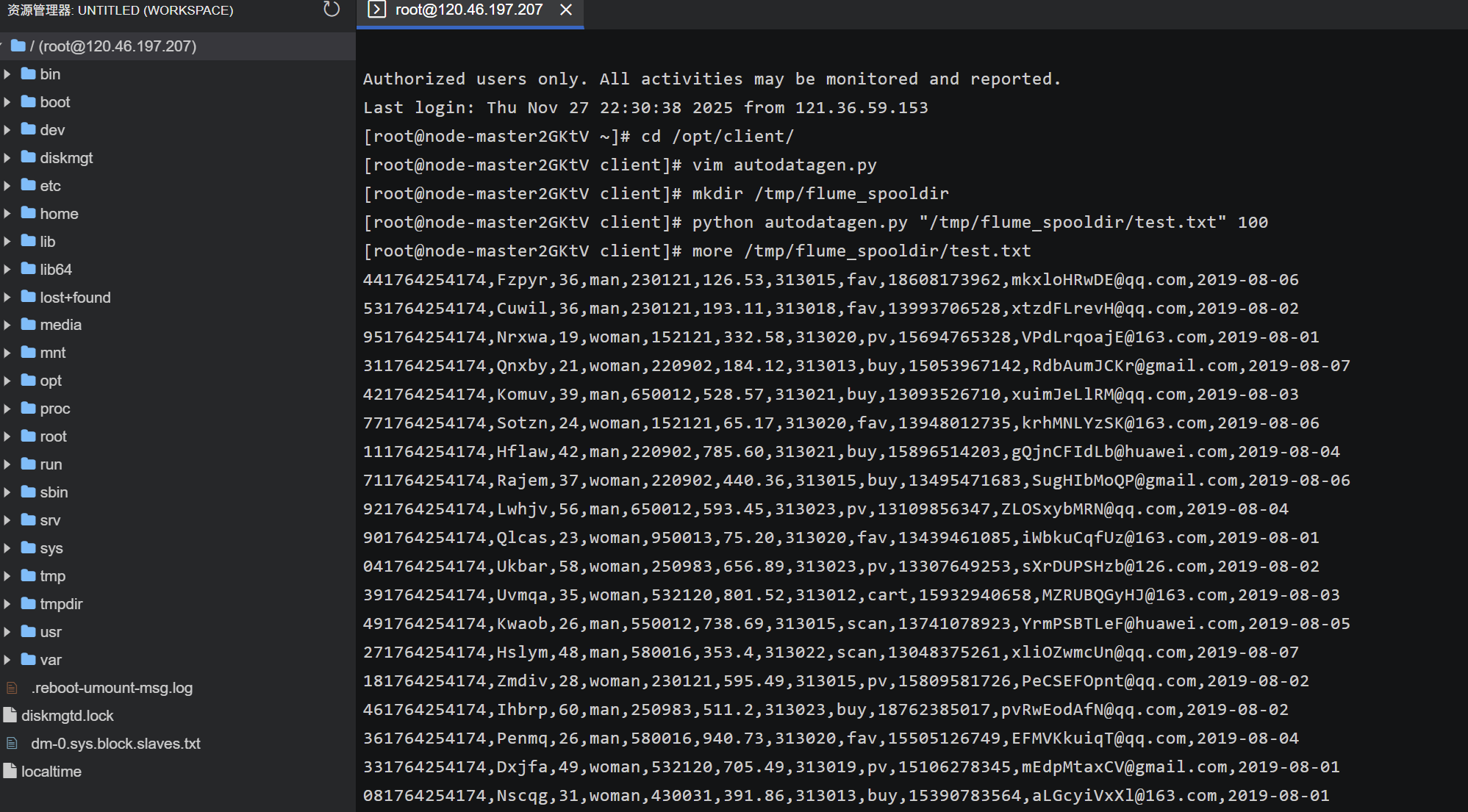
任务二:配置 Kafka


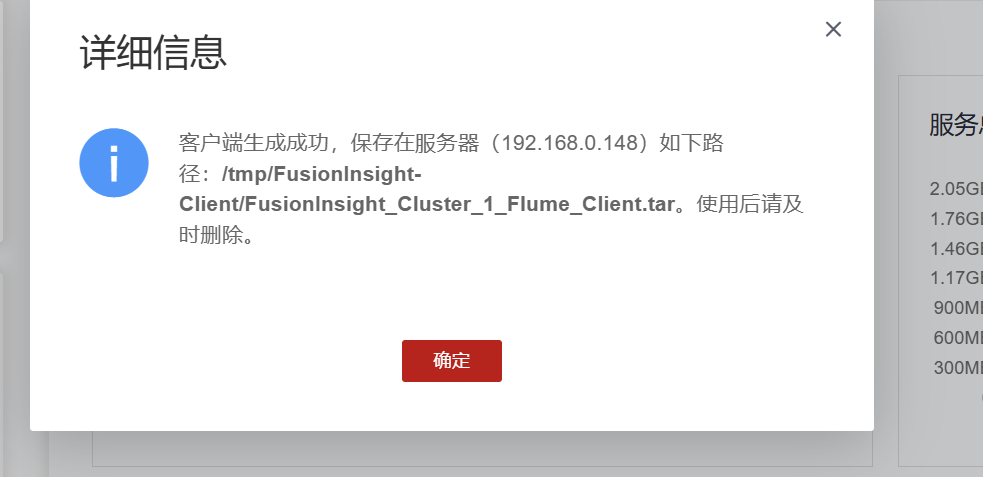
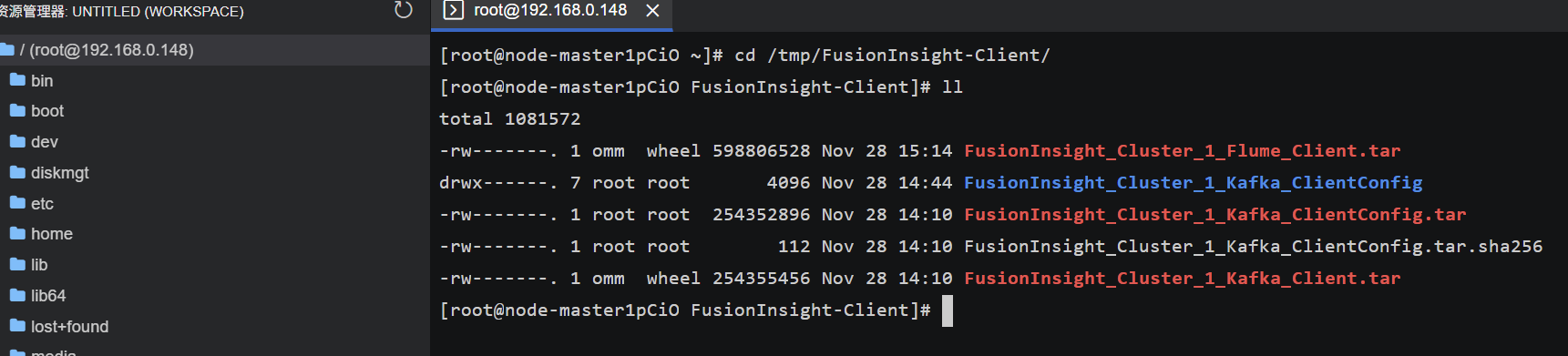
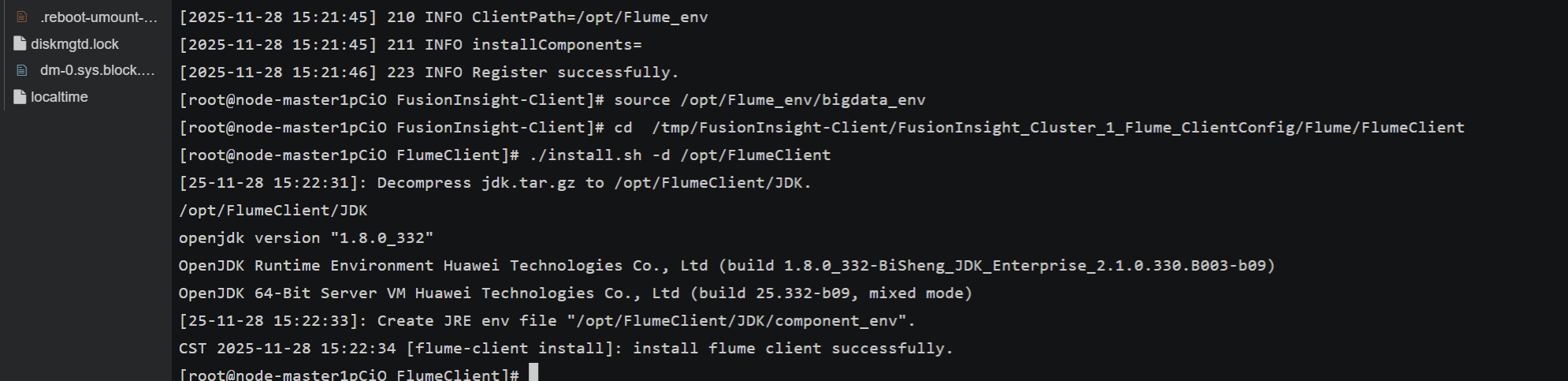
任务三: 安装 Flume 客户端

任务四:配置 Flume 采集数据
3.2 作业心得
配置 Kafka的步骤5在kafka中创建topic要注意kafka的连接和网络的稳定,不然会因为超时而错误


 浙公网安备 33010602011771号
浙公网安备 33010602011771号