操作系统学习笔记12 | 从生磁盘到文件
 下面就是磁盘管理的第3层抽象,从磁盘到文件,上一讲最后留下的盘块号并不符合我们日常使用计算机的习惯,而文件才是我们使用计算机更为常用的方式。这一部分就来细说第3层抽象:生磁盘到文件。这部分将解释如何从文件得到盘块号。
下面就是磁盘管理的第3层抽象,从磁盘到文件,上一讲最后留下的盘块号并不符合我们日常使用计算机的习惯,而文件才是我们使用计算机更为常用的方式。这一部分就来细说第3层抽象:生磁盘到文件。这部分将解释如何从文件得到盘块号。
下面就是磁盘管理的第3层抽象,从磁盘到文件,上一讲最后留下的盘块号并不符合我们日常使用计算机的习惯,而文件才是我们使用计算机更为常用的方式。这一部分就来细说第3层抽象:生磁盘到文件。这部分将解释如何从文件得到盘块号。
参考资料:
-
课程:哈工大操作系统(本部分对应 L29 && L30)
磁盘管理共4层抽象,本部分为第3层,前两层在 笔记11
-
课本:《操作系统原理、实现与实践》-李治军、刘宏伟
1. 第3层抽象描述:为什么引入文件?
引入文件抽象的磁盘也称,File-cooked disk,这正与上一讲中的生磁盘 Raw disk 相对,也是比较有意思的一件事情。
前两层抽象的建立已经让人叹为观止,但是对于普通用户而言,并不了解盘块号这样的专业名词,所以引入更高一层的抽象:文件,这样普通用户操纵磁盘信息时更为方便和舒适。
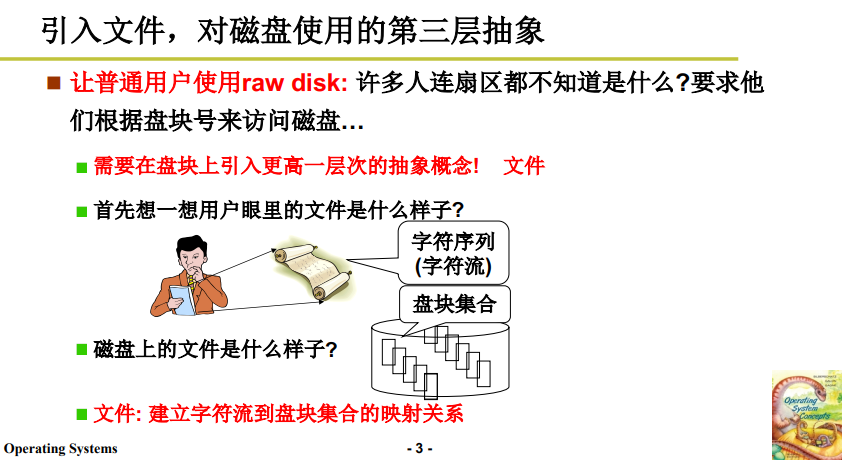
用户眼中的文件是什么样子的?
- 在用户眼中,文件本质是字符流;但这显然是一个抽象的概念;
- 在计算机/操作系统眼中,文件作为数据只能存放在磁盘上。而磁盘是由盘块组成的(操作系统视角),如下图所示;
我们要做的事情就是 建立字符流到盘块的映射关系。而文件抽象的初心是建立文件与盘块号的联系,这意味着这层抽象中操作系统将从文件字符流中推算盘块号。
下面举例说明一下上面提到的映射关系的作用:
-
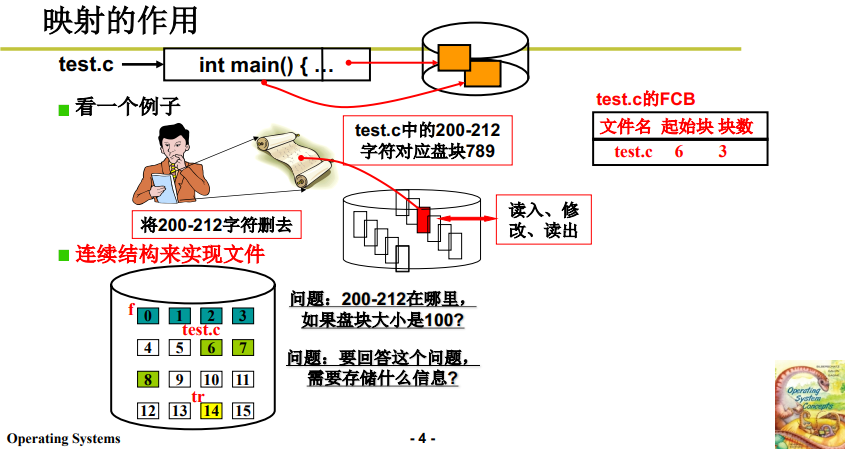
对于一个 test.c 文件,我们想要删掉其中的 200 ~ 212 行(这也是日常调试过程经常发生的事情)。
这一段在用户眼中就是连续的字符流,而在OS眼中就对应磁盘的盘块。
-
因此,从 操作系统/磁盘管理 的角度来讲,删除,首先需要读出这一段代码,然后在内存中修改后再写入磁盘。
- 找到这段字符对应的盘块 (比如789);
- 按照上篇笔记的读写方式,通过电梯队列将盘块内容读入内存缓冲区;
- 用户进行删除。
- 再通过电梯队列将这段数据写回到磁盘上,再读取该位置磁盘数据时,就不会显示这一段代码了。
这里留一个坑:删除了200~212行,对应磁盘盘块就出现了空白,这段空白怎么处理?
- 空白是文件系统处理的,文件系统会对其进行缩进和调整,然后体现在内存缓冲区中,文件关闭的时候会从缓冲区写入磁盘。
- 文件系统下一篇笔记会讲。
- 这个映射关系是由操作系统来维护的,对于上层用户不可见,用户层面的是文件字符流操作,而操作系统负责将字符流操作请求解析为盘块号,接着以前2层封装再向下执行。
- 这里已经很接近我们日常使用计算机的真相了。
2. 映射表:文件存储结构
上文提到,操作系统负责根据映射关系解析文件字符流,这种映射需要一个映射表。映射表需要根据文件在磁盘中的存储结构来建立,下面介绍几种基本的文件存储结构及其映射表建立,我们也可以自行设计其他文件存储结构及映射:
2.1 顺序存储结构
文件使用顺序结构储存在磁盘上,文件字符流被按照顺序存放在连续的盘块里。
比如 1~100 字符放在6号盘块,101~200 字符就放在7号盘块,以此类推。
顺序结构的映射建立如下,如下图下半部分所示:
-
已知字符数与盘块的存储关系;
如例子中的100个字符1个盘块,这是操作系统内部的参数。
-
根据字符序号计算盘块序号;
比如访问第202字符,202/100 = 2,可知该字符被存放在该文件对应的第2个盘块里(从0开始)。
-
文件的 FCB (File Control Block 文件控制块)存储该文件的起始块号,结合盘块序号就能知道对应的字符在那个盘块;
起始块号为6,6+2=8,符合事实。
映射建立后,读写磁盘所需的盘块号就被映射表封装成了文件字符流的修改。联系上一讲的上层接口 盘块号,继续向下就实现了磁盘的访问。
顺序存储结构也有不妥之处:
- 用顺序存储的结构适合文件的直接读写,不适合文件的动态增长,就像C语言数组,不方便插入元素。
- 当插入内容时,需要整体拷贝挪到另一片空闲空间,涉及整个文件的读出和写入,这开销很大。
所以每种存储结构的特点不同,我们需要根据文件的特性,来选择/设计存储结构。
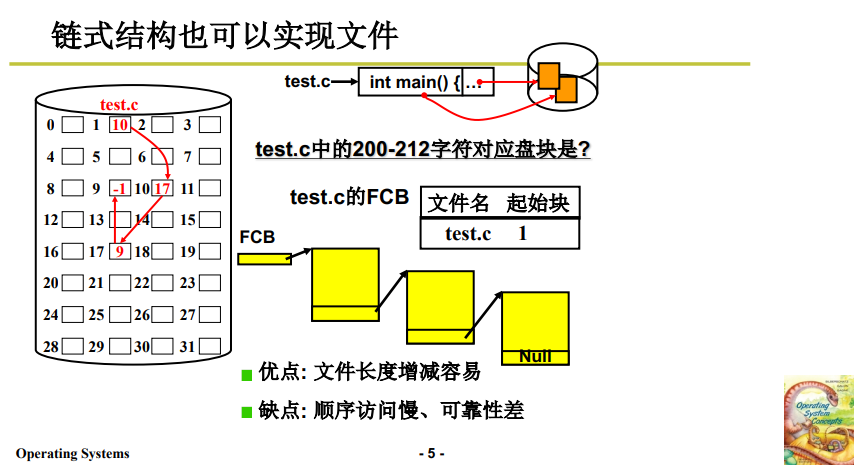
2.2 链式存储结构
文件使用链式结构储存在磁盘上,当前盘块中存放下一块盘块的位置指针,实际上就是链表在磁盘中的表现形式。如下图所示:
文件控制块 FCB 中需要存放的主要映射信息:第一个磁盘块的盘块号。
- 利用这个信息可以找到文件的第一个磁盘块;
- 每个磁盘块中存放下一个盘块号的指针,据此找到第二个磁盘块……
- 这种链式存储结构就很适合文件动态增长,插入只需要申请空闲盘块写入后插入链表即可。
- 同时,链式存储结构的读写就会变得复杂,需要顺序遍历才能找到,不能像顺序存储结构那样直接读写;并且,其中一个盘块信息丢失,就可能导致整个文件不可用。
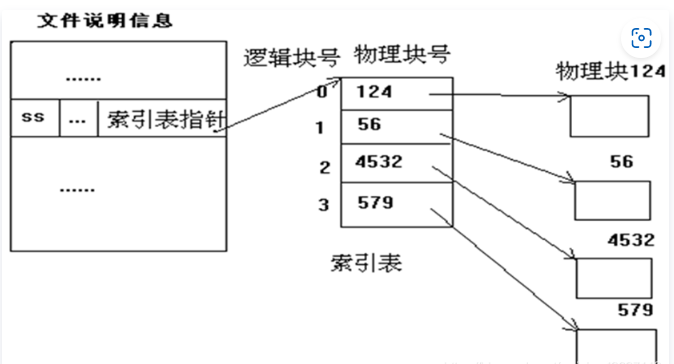
2.3 索引存储结构
联想前面键盘和显示器中 Linux 0.11 文件的读取方式,使用了一个 inode 的结构来存储文件信息并据此进行读取,这显然是一种索引结构。
文件使用索引结构储存在磁盘上时,文件信息可以存放在不连续的磁盘盘块上,FCB 存储索引表,索引表存储盘块号,如下图所示(位置是19):
-
将文件字符流分割成多个逻辑块,在磁盘上申请一些空闲物理盘块(无需连续),将这些逻辑块的内容存放进去;
-
用另外的磁盘块(可能不止1个)建立索引表,按序存放各个逻辑块对应的盘块号;
就像内存管理的页表一样。
-
当访问202号字符时(还是继续上文例子):
- 首先我们计算出,这是该文件第2个盘块(从0计数)上的内容;
- 根据文件的FCB中的索引表位置,查找索引表,对应盘块号是1;
- 读入盘块1,就完成了202号字符的读入。

- 索引存储结构结合了顺式存储和链式存储两者的优点,支持动态增长、插入删除;既能够顺序读写,也能够随机读写。能够充分利用磁盘空间。
- 索引存储结构的缺点就是引入了 索引表,建表和查表会带来额外的开销。但是这一问题可以通过存储技术发展来得到解决。
2.4 多级索引结构
由于上述优点和可解决的缺点,实际操作系统 如 Linux 和 Unix,使用的文件存储都是 基于 索引存储 的 多级索引结构。如下图所示:
-
如果是小型文件,inode 直接作为索引对应盘块,此时类似于上文索引存储;
-
如果是中等文件,建立一阶间接索引,inode 放置索引表的位置;
-
如果是大型文件,则建立多阶间接索引,此时可以表示非常大的文件;
inode 的理解:
- 文件数据存储在盘块里,还需要空间存储文件本身的信息,比如创建者、创建日期、大小、位置等;
- 这种储存文件元信息的区域就叫做inode,中文译名为"索引节点"。是一个映射表。
- 参考资料:理解inode - 阮一峰的网络日志,博主我关注了很久,这篇博文写得也很好。同时,这篇博客讲解了更深入的 inode 软链接、硬链接等内容。
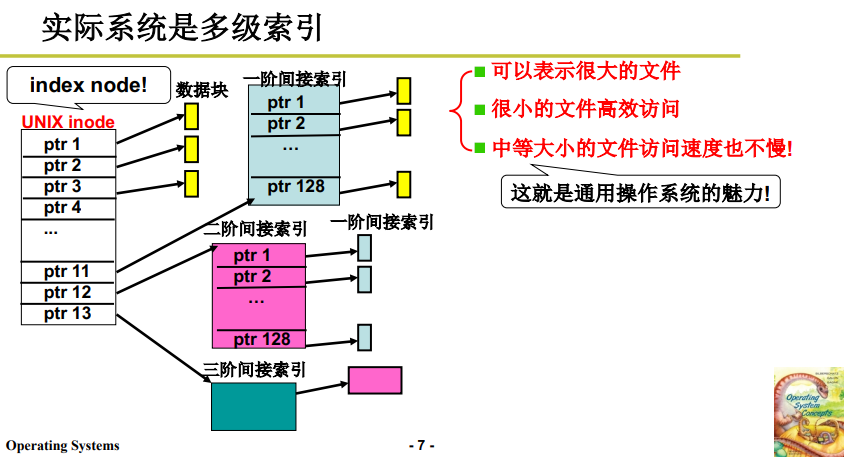
可见,如上图这样的索引架构:可以表示很大的文件,很小的文件高效访问,中等大小的文件访问速度也不慢。是一种比较优秀的综合方案。
3. 代码实现:文件使用磁盘
这部分介绍文件层抽象使用磁盘的最核心代码。
其实这部分也可以联系 之前学习笔记10-键盘和鼠标 的内容一起理解,在驱动外设时已经使用了文件抽象,因此其中的过程跟这里很相似。
3.1 sys_write
用户对文件的写操作,在系统接口层面具体行动是调用write(),内核层功能代码sys_write()如下所示:
// 在fs/read_write.c中
int sys_write(int fd, const char* buf, int count)
{
struct file *file = current->filp[fd];
struct m_inode *inode = file->inode;
if(S_ISREG(inode->i_mode)){
// file 包含了前面缺少的字符流信息
return file_write(inode, file, buf, count);
}
}
-
可见,sys_write 的参数: fd 为 文件描述符, buf 为 内存缓冲区, count 为 写入内存的字符个数;盘块号此时就被封装了。
文件描述符见下文参考资料部分我的总结描述,简言之就是使用 fd 找到对应文件。这部分在学习笔记10-显示器与键盘中的2.3.1与2.3.2 、2.3.3 我也仔细分析过。
这里老师可能是因为讲过,所以讲的很简略。
-
file=current->filp[fd];如果对多进程图像还有点印象,current 就是当前进程的PCB,这里的意思就是 PCB 中的一个数组 flip 的 fd 号位置处 存储了一个文件。flip 数组的来源:是从子进程根据父进程创建时就拷贝过来的 (sys_fork),最原始的父进程从操作系统进程拷贝。通过 sys_open 建立从文件inode 到进程PCB的链;
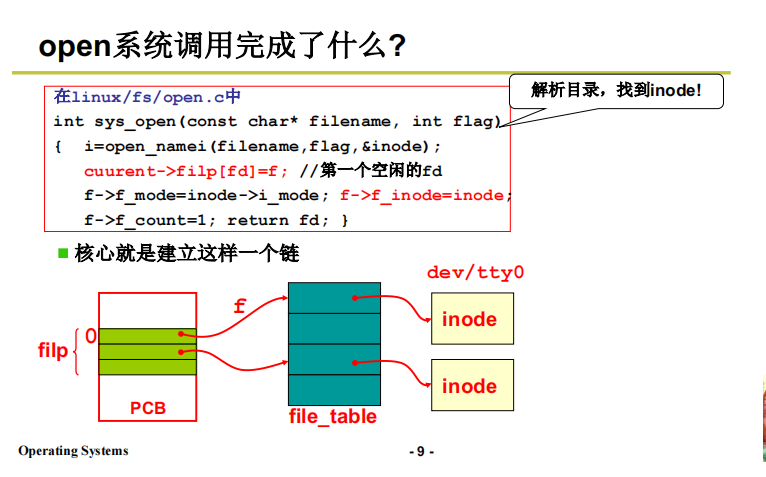
上图摘自我的笔记10,这个链本部分的配图也有。
-
struct m_inode *inode = file->inode;获得 inode(文件本身的信息); -
接下来根据 字符流file 和 inode 换算 盘块号,调用 file_wirte;
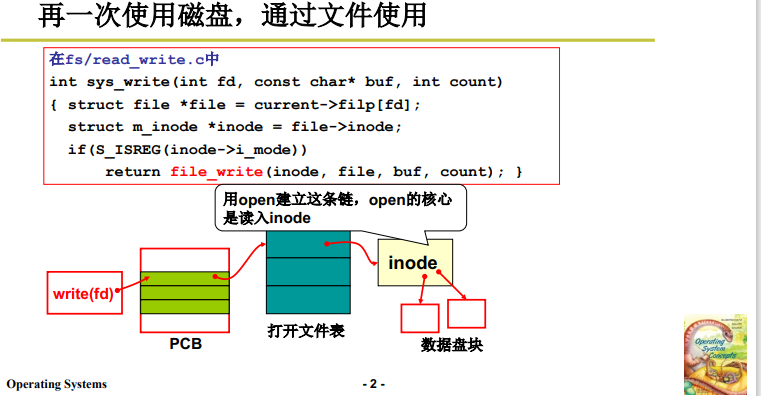
3.2 file_write
这部分代码实现 人访问文件的图像 向 生磁盘读写数据的图像的转换;也就是这里的代码实现本文第1部分思路的实现。
如下图,我们要修改200~212字符,下面的参数意义就是:
-
file_write(inode,file,buf,count); -
inode 表示文件索引块(索引结构), file 是 200,buf 是 内存缓冲区位置,count 是 12;
-
根据这些信息,就可以找到相关盘块,放入电梯队列,进行访问。
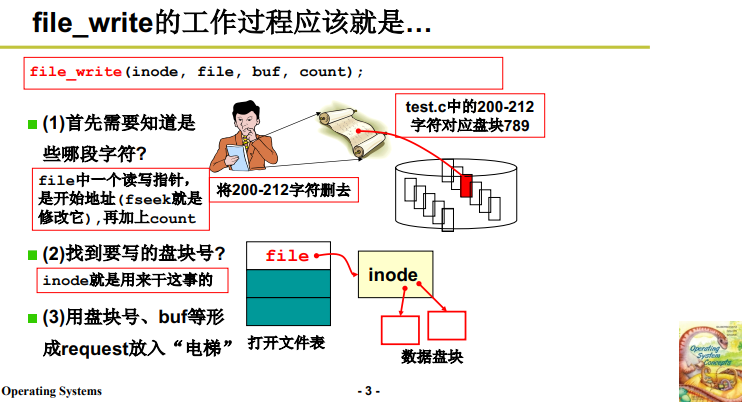
file_write 的 工作过程:
-
首先要根据 file 找到 200 ,这个目标字符流的开始位置。
- fseek 调整 file 中的读写指针(文件的当前读写位置);
这个读写指针是字符流形式的一个具体表现,刚打开时读写指针,随着读写,读写指针后移,也就形成了字符流的图像。
- 并根据 count 找到 文件读写 对应的字符流;
-
接着 根据对应的字符流 计算找到盘块号;
根据字符流上的读写位置 算出逻辑块号(也就是相对位置) ,由 inode 找到物理盘块号(也对于基址);具体调用了 create_block 来计算,见 3.3 部分。
-
接下来的故事其实就很顺利了,与上一篇笔记接到一起:
- 接上第2层抽象,用盘块号、buf等形成的 进程请求 request 放入电梯队列。
- 再接上第1层抽象,磁盘中断时从电梯队列中取出请求,解算出CHS,通过 outb 指令,发到磁盘控制器,控制对应的磁盘地址进行读写。
而 file_write 就是上面几步的顶层代码,每一步调用函数来完成:
-
第一大部分:得到目标字符流位置;
- 通过对目标读写位置pos 进行处理,找到文件的读写位置;
- 记录在 f_pos 中;
-
第二大部分:根据字符流计算盘块号;(核心)
-
create_block,核心代码,计算盘块号 / 扇区号(左移);
-
bread,展开就是 make_request,向磁盘发出请求,放入电梯队列后阻塞;
make_request,见第2层抽象解释。
-
-
第三大部分:写 完成,对 pos 做相应处理;
- 这里的例子是磁盘写,所以写操作完成后,应当增加pos,相当于向后移动,形成字符流。
-
具体见代码注释:
int file_write(struct m_inode *inode, struct file *filp, char *buf, int count)
{
// pos 代表当前位置
off_t pos;
//1.得到字符流的读写位置,也就是200
if(filp->f_flags&O_APPEND){
//如果是追加,pos从文末开始,i_size就是文件大小。
pos=inode->i_size;
}
else{
//如果不是,就从上一次读写的位置继续。
pos=filp->f_pos;
}
.....
//2. 下面是核心代码,根据读写位置找到盘块号。
while(i<count)
{
//算出对应的块
block=create_block(inode, pos/BLOCK_SIZE);//起始位置和偏移量
//发送请求,放入电梯队列,bread展开就是 make_request。
bh=bread(inode->i_dev, block);//放入电梯队列后阻塞
//3.修改pos
//写入数据后,修改 pos
int c=pos%BLOCK_SIZE; char *p=c+bh->b_data;
// pos指向文件的读写位置(字符流的末尾位置)
bh->b_dirt=1; c=BLOCK_SIZE-c; pos+=c;
...
//一块一块地拷贝用户字符, 并且释放写出
while(c-->0) *(p++)=get_fs_byte(buf++);
brelse(bh);
}
filp->f_pos=pos;
}

3.3 create_block
计算盘块号,这是第3层文件抽象的核心工作。
- 调用 create_block 的这段代码:
while(i<count){
//create=1的_bmap,没有映射时创建映射
block=create_block(inode, pos/BLOCK_SIZE);
bh=bread(inode->i_dev, block);
...
-
create_block 调用了 _bmap,旨在建立 2.4 部分的多级索引结构/映射表。
强调:block 是逻辑块,课程此处不够清晰。block - 7是因为第7块存储在一重间接的指向的第0个索引表,以此类推
-
当 block < 7 ,对应小文件部分,0-6块: 直接数据块;
此时新申请数据块时,就在 inode 中新批一块来存放序号。
-
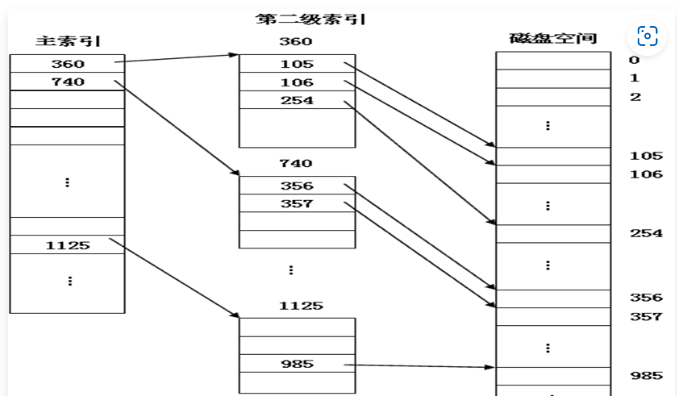
当 7 <= block < 512,建立一阶间接索引,注意这里的数据大小换算关系;
- 索引表中一个盘块号的存储需要 2 个字节,2 个字节 16 位;
- 索引表本身存储需要 1 个盘块。
- 1 个盘块 = 2 个扇区 = 1 K = 1024 Byte
- ∴ 一个索引表盘块可以放 1024 /2 = 512 个盘块号
- 当 盘块 block < 512 时,一阶索引完全就够用了。
此时再申请新的数据块时,逻辑块号需要放到一阶索引表的下一位(顺序);
我在学习这部分时感觉不是很直观,下图表述一间接索引的情况较好:
-
很显然,当 block >=512,索引表也需要建立二级索引表,因此引入多阶间接索引。
-
int _bmap(m_inode *inode, int block, int create)
{
if(block<7){
if(create&&!inode->i_zone[block]){
// 新申请一个数据块,返回它的块号放在i_zone[block]中
//这样0~6的inode就是直接索引数据
inode->i_zone[block]=new_block(inode->i_dev);
inode->i_ctime=CURRENT_TIME;
inode->i_dirt=1;
}
// 0~6 部分建表完成。
return inode->i_zone[block];
}
//
block-=7;
if(block<512){ //一个盘块号2个字节
bh=bread(inode->i_dev,inode->i_zone[7]);
return (bh->b_data)[block];
}
...
到这里从文件到盘块的映射表建立完成,接下来就会回到 file_write 中继续 bread 向磁盘发出请求,接入前2层抽象。

3.4 inode抽象意义的理解
-
上面3.3 中 inode 可以作为映射表,从文件对应盘块号;
-
inode 还可以视为 文件的抽象存在:
-
如果是普通文件,需要根据 inode 里面的映射表来建立磁盘号到字符流直接的映射;
struct d_inode{ unsigned short i_mode;... unsigned short i_zone[9]; }//(0-6):直接数据块,(7):一重间接索引,(8):二重间接索引 -
如果是特殊文件如设备文件,不需要inode去完成映射,inode存放主设备号、从设备号:
// 读入内存后的inode,并不是设备文件和普通文件的该结构体不同 struct m_inode{ //前几项和d_inode一样! //文件的类型和属性 //i_mode 存放 设备文件和普通文件的标志位。 unsigned short i_mode; ... //指向文件内容数据块 unsigned short i_zone[9]; //多个进程共享的打开这个inode,有的进程等待… struct task_struct *i_wait; unsigned short i_count; unsigned char i_lock; unsigned char i_dirt; ... }
-
-
下面就可以根据 inode 区分文件的属性和类型:
int sys_open(const char* filename, int flag) { if(S_ISCHR(inode->i_mode)) //字符设备,设备文件 { // 由于是设备文件,zone数组不再用于映射表,用于设备号存储 if(MAJOR(inode->i_zone[0])==4) current->tty=MINOR(inode->i_zone[0]); } ... } // emm 此处解释一下上面代码的 MAJOR 和 MINOR // MAJOR 取高字节 #define MAJOR(a)(((unsigned)(a))>>8)) // MINOR 取低字节 #define MINOR(a)((a)&0xff)

理解到这里,整个文件视图就可以建立了。
3.x 参考资料
本部分用于记录一些需要拓展而不想占用正文篇幅的资料。
-
fd,File Descriptor,文件描述符:
-
这一点在学习笔记10 的 sys_open 处有所提及。
-
简称 fd,是系统调用接口 open 的返回值,当应用程序请求内核 打开/新建 一个文件时,就会调用 open 执行 sys_open;
-
fd 本质上就是一个非负整数,读写文件也是需要使用这个文件描述符来指定待读写的文件的。
-
4. 简单总结
4.1 文件视图/整体流程
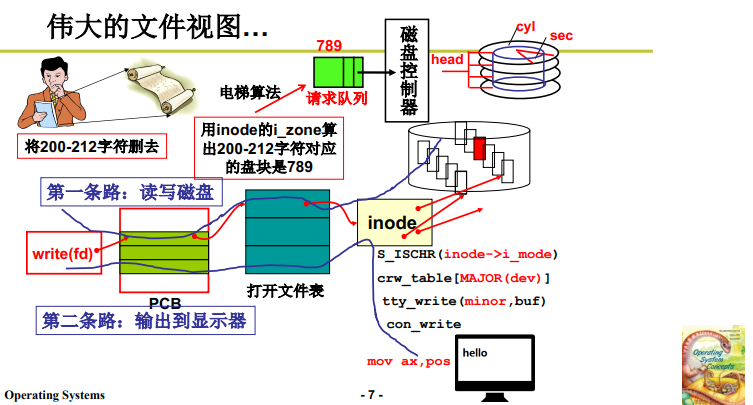
首先,用户要操作文件,分为两条路:
-
第一条:读写普通磁盘数据文件。
根据 系统接口层的 fd 找到文件表,再读取对应的 inode,据此接入3层抽象,顺利读取磁盘;
如果C语言基础不好,对于用户在应用层的文件操作不熟练,我再提一下:
-
fd = open("test.c"); read(fd,...);可见,整体流程是:路径名或文件名->inode (fd)->盘块号->放入电梯队列,取出时解算CHS->out发到磁盘控制器驱动电磁效应读写数据。
-
第3层抽象解释的是 read 这一句,即已知 fd 如何找到文件位置;拿到对应的 inode 接入已经掌握的抽象层进行读取。
-
目前缺乏的就是 从文件名test.c 到 fd 和 inode 的联系,这是第4层抽象。
注意:如何找到下图文件表?如何打开文件(open那一句代码)?
- 这就是下一篇笔记会讲到的第4层抽象。
- 到文件表是进程PCB与 文件表 的链接,打开文件是建立文件名与 inode 的来链接;
-
-
第二条:读写设备文件
这里前面学习笔记10也详细介绍过了,inode不再用于映射,而是用于操作函数的选择,根据不同的函数最后向设备控制器发送对应指令。
4.2 实验8介绍
实验 8 要实现一个 proc 文件,实现的效果是:输入 cat /proc/psinfo,打出如下图所示的进程情况:
Linux0.11中 这些进程信息存放在 PCB 中,也就是说,并不在磁盘上,而 cat 命令要打开一个文件。所以要从PCB中取出相关信息 先放到内存中再读写放到磁盘文件中(见下图 cat 的一些程序,作用是持续打印,知道文件中没有信息)。
要实现这样的效果,还是沿着 4.1 中的思路,不过要将 该文件的 i_mode 设置为 proc 设备(S_ISPROC(inode -> i_mode); 接下来调用 proc_read() 从 PCB 中的 task_struct 中取出数据拷贝给 buffer 内存缓冲区。
执行读内存的相关操作,就实现了要求的效果。
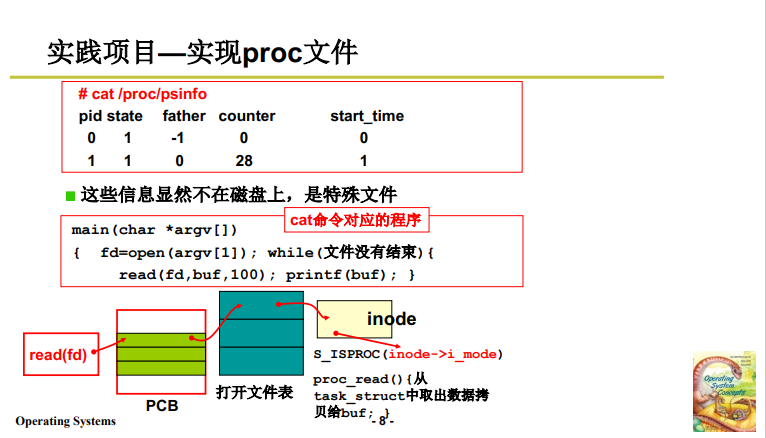
具体实现代码框架如下图所示:
- 初始化时 mknod 创建设备,设备设计为 S_IFPROC 设备。
- sys_read 中对文件类型 即 i_mode 进行判断,如果是,那就 proc_read.
- 从 PCB 中取出相关信息放到内存上,传到用户态内存;
- 修改 pos 指针,将这些信息不断传递,形成字符流。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号