计算机系统5-> 计组与体系结构2 | MIPS指令集(上)| 指令系统
 介绍指令集的指令格式、寻址方式、指令类型,介绍了一些著名的指令集。
介绍指令集的指令格式、寻址方式、指令类型,介绍了一些著名的指令集。
系列的上一篇计算机系统4-> 计组与体系结构1 | 基础概念与系统评估,学习了一些计算机的基础概念,将一些基本的计算机组成部分的功能和相互联系了解了一下,其中很重要的一个抽象思想就是软硬件的接口——指令集,这一篇就来具体地学习MIPS指令集。
参考资料:
- Computer Organization and Design the 5th Edition,即计算机组成与设计硬件软件接口第五版
- 课件,由于是英文且只是老师的思路,所以是辅助参考
- 《计算机组成原理》谭志虎,HUST(此书强推)
- 《计算机组成原理》MOOC HUST
没有学过计算机系统基础,也就没接触过×86指令集,当时上课听的挺难受的。下来又看了一遍书。我觉得课本写得不太好,得完全通读一遍,才知道它整体上要给我们传授什么概念和思想,知识之间是糅杂在一起的,更像是作者关于MIPS的漫谈(想到哪介绍到哪)。
00 一些前言
关于指令集这部分的内容,系列4中已经介绍了它在计算机系统层次中的位置以及功能作用,本文是对于指令集功能的具体实现的更深入的介绍。
这次学习的指令集就包含两个方面:
- 人编程书写的形式--汇编语句(助记符);
- 计算机识别的形式--机器指令(数字串);
本部分不按照课件整理,也不按照课本整理,我就以上面这两个方面以及上图中的三个过程,分四个部分,来进行梳理:
-
- 自顶向下讲解一下指令系统的组成和特性
-
- 单独整理MIPS的各种指令作用及其机器指令格式。
-
MIPS指令集(下):高级程序块在MIPS指令集架构中的翻译
- 高级语言的MIPS汇编表示是什么样子的。
-
MIPS指令集(续):完整C代码的各级表示(偏向实操) | 使用Mars
- 一次作业(已截止),进行深挖细想。
-
接下来从机器指令到数字逻辑,是处理器CPU部分要介绍的内容
因为计算机硬件技术的基本原理相似,而且能够提供的基本操作也不外乎几种,所以不同的指令集及其机器语言大多很相似。
但是对于设计人员来说,追求的就是一种性能最优、功耗成本最低的指令集 / 机器语言架构。MIPS就是一种性能比较好的指令集。
可能大家会有一个疑问,即指令集为什么还有性能、功耗、成本之说,它是怎么影响这些指标的呢?这部分内容会来解释这个问题。
0413 本以为拆分之后会短一点,其实内容还是很多。
01 指令系统概述
根据图灵机理论,我们得知,计算机的工作就是不断地以一种重复的流程执行不同的指令。指令到底是什么呢?
指令以前提到过,就是对于计算机的命令。狭义来讲,就是一串数字流,控制计算机来执行某种操作(比如加、减、移位等);广泛一点来讲,其实本质上是对于计算机的命令,出于计算机不同层次的指令可能会不同,比如微程序设计级用户一般会用微指令(微体系结构,处理器部分会讲解);一般机器级用户会使用机器指令;汇编语言级的用户会使用汇编指令;高级语言级用户会使用高级语言指令。

所谓指令集 / 指令系统,即计算机中底层设计承认的指令的集合,官方一些的话就是某种计算机体系结构中所有指令的集合。
指令集 / 指令系统是计算机的主要属性,位于硬件和软件的交界面上。也可以说指令系统是计算机硬/软件的界面。
02 指令格式
指令是怎样控制计算机底层的电路的呢?状态机还记得吧,我们将不同的状态编码为不同的数字串,通过逻辑电路识别不同的状态码来执行不同的工作,加法或是移位。所以设计指令首先要考虑的事情就是指令的格式;
即明确指令处理什么对象(操作数),对对象进行何种操作,通过何种方式获取操作数等等。
指令格式具体来讲就是二进制代码表示指令的结构形式,一般格式如下图所示。
| 操作码字段op | 地址码字段A |
|---|
- 操作码:表示这条指令用于进行何种操作 / 处理何种操作数(操作对象);
- 地址码:给出被操作对象 / 操作数的位置;
- 寻址方式:决定获取操作对象 / 操作数的方式;寻址方式可以在地址码中(如PDP-11、Inel×86),也可以放在操作码中(如MIPS、RISC-V);
02-1 指令字长度
一条指令中包含的二进制数的个数,也即指令字长,比如MIPS的指令字长为32。
MIPS32 和 MIPS64 的差别在于单个寄存器的位数以及CPU的字;
- 前者寄存器32位;
- 后者寄存器64位;
- CPU中都是32个寄存器;
- 指令长度都为32位。
按照指令字长是否固定,可分为定长和变长指令系统。
- 定长指令系统
- 长度固定,结构简单,有利于CPU取指、译码和指令的顺序寻址;方便硬件实现;
- 但指令平均长度较长,冗余状态较多,不易扩展;
- 精简指令系统 / RISC 多采用定长指令系统;
- 变长指令系统
- 长度可变,结构灵活,冗余状态较少,平均指令长度较短,可扩展性好;
- 指令变长会给取值、译码带来不便;取指过程可能涉及多次访存操作,下一条指令地址必须在指令译码后才能确定(也即没有顺序可言),增加了硬件实现难度;
- ×86使用的就是变长指令系统;
- 后续指令系统举例部分还会讨论 CISC 和 RISC;
无论变长还是定长,指令字长都需要是字节的整数倍,才能存储在存储器中。按照指令字长和机器字长的关系,可将指令分为半字长指令、单子长指令和多字长指令。
- 机器字长即byte / 字节,8位;
- 指令字长即word / 字,长度与指令集有关,MIPS为32位定长,变长指令需要是byte的整数倍;
- MIPS中一个字等于多少字节
此外关于 位、字节、字、字长:
- 位(bit)
“位”是计算机中的最小单位,它只表示一个二进制数 0 00 或 1 11。- 字节(Byte)
转化:1 Byte = 8 bit.
字节是计算机中数据处理的基本单位,用来单位存储和解释信息。一个字节固定由 8 个二进制位组成。- 字(word)
概念:计算机进行数据处理时,一次存取加工和传送的数据长度。
转化:1 字 = n Byte
一个字通常为字节的整数倍(即 8 的整数倍)。- 字长
一个字包含的位数,即 8n 位。
指令越长,占用内存 / 主存的空间就越大,访问所需时间越长:对于半字长指令,CPU访问主存一次可以读取两条,单字长一条,双字长则需要两个存储周期才能完成取指。
所以,长指令的取指速度慢,会影响指令执行速度,但多字长的指令能提供足够长的操作码字段和足够长的地址码字段,可以设计更多的指令、支持更多的指令格式、扩大寻址范围,功能上更加强大。
但为了提高速度,一般指令还是短一些好,即硬件设计原则一:越短越快。
02-2 指令地址码
地址码的意义有很多,可能是一个操作数,也可能是操作数的地址(包括操作数的内存地址、寄存器编号或者外部端口的地址),还可能是一个用于计算地址的偏移量(类似于数组),具体表示哪一种含义,要由寻址方式决定。
根据指令中含有的操作数地址的数量,可以将指令分为三地址指令、双地址指令、单地址指令和零地址指令。
-
三地址指令
C语言中我们经常见到形如
a=b+c;的式子。在底层指令中也相似,具有两个操作对象的运算叫做双目运算,包括两个源操作数和一个目的操作数,如果一条指令将三者的地址都给出,那么这种指令就是三地址指令。表达式为:
\[A_3 \leftarrow (A_1)OP(A_2) \]意思是,将A1中的内容和A2中的内容进行OP操作,将结果存入A3。
但是这种指令存在一种问题,设想如果我们的内存很大,三地址指令要对内存地址进行操作,那么用于表示内存地址的 Ai 的长度就会很大,总的指令长度也会变大。所以,3个地址码很少都用存储单元的地址码。常见的三地址指令(如MIPS的较大部分)的三个操作数均为寄存器。
-
双地址指令
双地址指令仍然是基于双目运算设计,只不过是将运算结果继续存入第一个操作数地址A1中。表达式为:
\[A_1\leftarrow (A_1) OP(A_2) \]意思是,A1为第一个源操作数,也是运算结果的目的地;A2是另一个源操作数。
不同双地址指令指向的数据存储位置可能不同,有以下三种可能:
- RR(Register - Register)型:源操作数和目的操作数均用寄存器存放;
- RS(Register - Storage)型:源操作数和目的操作数分别在寄存器和主存中存放;
- SS(Storage - Storage)型:两个操作数均在主存中存放。
由于寄存器就在CPU中,且存储器的访问速度和CPU的速度存在很大差距,所以存储器的访问速度慢于寄存器,所以速度上RR最快,SS最慢。
×86计算机主要采用RR和RS,MIPS等RISC计算机中主要使用RR型。
-
单地址指令
单地址指令主要有两类:
-
单目运算类指令
比如逻辑运算中的取反,表达式为:
\[A_1 \leftarrow OP(A_2) \] -
隐含操作数的双目运算类指令
为了缩短指令长度,设计者将双目运算符指令中的一个操作数规定隐含于CPU的某个寄存器(比如累加器AC)中,这样指令就可以只描述另一个操作数的地址,并将操作后的结果送到规定的寄存器,表达式为:
\[AC\leftarrow (AC)OP(A_1) \]如80×86系列CPU中的乘法 Mul BL指令,表示将AL中的数据与BL中的数据相乘,结果存放在AX寄存器。
-
-
零地址指令
这类指令中没有地址码,仅有操作码,主要有两类;
- 不需要操作数的指令:
- 比如为占位、延时而设置的空操作指令NOP、等待指令WAIT、停机指令HALT、程序返回指令RET等等;
- 操作数被隐藏于寄存器的 “单地址指令”
- 有一个操作数,但是被隐藏在寄存器,比如Intel8086压缩BCD编码的运算调整指令DAA;
- 不需要操作数的指令:
02-3 指令操作码
操作码字段表示具体进行何种操作,不同功能的指令其操作码的编码不同,如可用0001表示加法,0010表示减法。操作码的长度就是操作码字段所包含的位数。有定长操作码和变长操作码两种。
-
定长操作码
定长操作码不仅指操作码的长度固定,而且其在指令中的位置也是固定的。这种方式的指令功能译码简单,有利于硬件设计。
操作码的位数取决于计算机指令系统的规模,指令系统中包含的指令数越多,操作码的长度就越长;反之就越短。假设指令系统包含m条指令,则操作码的位数 n 应该满足
\[n \geq log_2m \] -
变长操作码
变长操作码中操作码的长度可变,而且操作码的位置也不固定,采用这种方式可以有效压缩指令操作码的平均长度,便于用较短的指令字长表示更多的操作类型,以寻址更大的存储空间。
早期计算机指令字长较短,所以多采用变长操作码来争取表达更多的指令。例如PDP-11、Intel 8086,而 MIPS和RISC-V的部分类型指令也采用了这种方式。
扩展操作码技术:
是实现变长操作码的一种技术,基本思想是操作码的长度随地址码数目减少而增加。
下面是一个较为简单的扩展操作码的16位系统,长度固定,不同操作数指令的操作码长度不同。
三地址指令(括号里表示二进制位数)
OP(4) A1(4) A2(4) A3(4) 双地址指令
OP(8) A1(4) A2(4) 单地址指令
OP(12) A1(4) 零地址指令
OP(16) 但这个技术中有两点需要注意:
- 不允许短码是长码的前缀,即短操作码不能与长操作码的前面部分的代码相同。(这样会无法分辨
- 各指令的操作码一定不能重复。
这就是说,前面的三地址指令的OP字段是不能把24种可能全部用完的,不然其余指令就没有余地设计了。以此类推。
通常情况下,对使用频率较高的指令分配较短的操作码,对使用频率较低的指令分配较长的操作码,从而尽可能减少指令译码和分析的时间。(加速大概率事件)
03 寻址方式
依据存储程序的概念,计算机在运行程序之前须要把指令和操作数(数据)加载 / 存放到主存的相应地址单元中,运行程序时,CPU不断从主存来取指令和数据。
主存基于地址来访问指令和数据(形如一个巨型数组),所以要想拿到指令和数据,需要得到它们在主存中的地址(也称有效地址EA)。
寻址方式就是寻找指令或者操作数有效地址的方式。寻址方式是整个指令系统中的重要部分,对于指令集的性能有很大影响。
03-1 指令寻址方式
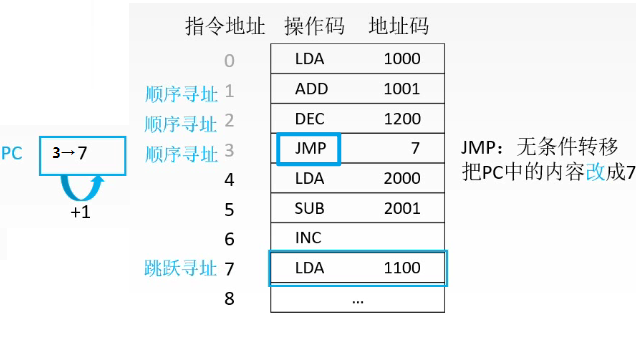
指令寻址方式有两种:顺序寻址方式和跳跃寻址方式。
03-1-1 顺序寻址方式
程序中的机器指令序列在主存中通常是按顺序存放的,大多数情况下,程序按照指令序列的顺序执行,因此在这种情况下,我们知道了当前指令的EA有效地址,再增加一个指令的长度(指令占用主存单元的数量 ,类比数组),就是下一条指令的位置了。这就是顺序寻址。
具体点说,如果某种指令系统的计算机用程序计数器PC(类似于指针)来保存指令地址(×86中为IP / EIP),每执行一条指令,用PC+1就能算出下一条指令地址。
特别说明,这个 “1” 就是指令长度,如果是32位的计算机中指令长度是32位(正好占用一个存储字),采用顺序寻址方式时下一条指令通过PC+4得到。(32bits = 4byte,字是寻址的基本单位)
03-1-2 跳跃寻址方式
当然,有时候程序并不是自上而依次运行的,如果出现分支和转移,就会改变程序运行顺序,这时候下一条指令就不一定是PC+1了,而需要通过指令本身以及其他的条件决定。比如无条件转移指令和条件转移指令均采用跳跃寻址方式。
03-1-3 图解程序计数器PC
程序计数器(pc)是这样子工作的,这里有一块存储器和一个程序计数器:
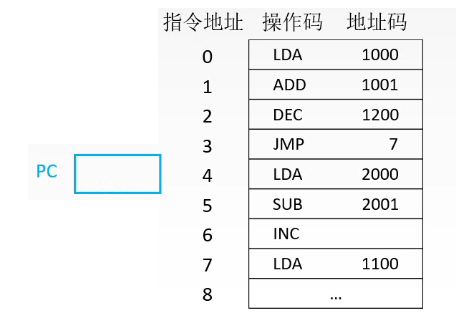
从0开始执行,我们就需要在pc中写入地址0。执行完零号指令后,由于这是普通的取数指令,因此程序计数器自动+1,于是cpu开始执行指令1。
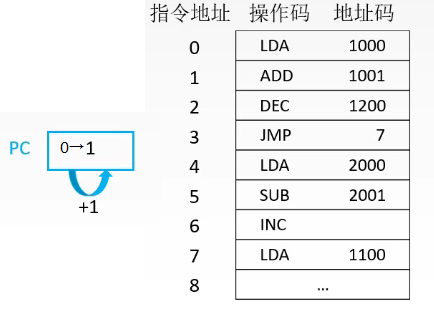
以此类推...碰到跳转指令,也就是指令3,读取指令3后,PC跳转到地址7,去执行7这个地方的指令。
03-2 操作数寻址方式
03-2-1 操作数寻址的情况及机制
操作数的来源有三种情况:参考博客1
- 立即数操作数,直接来自指令内部;
- 寄存器操作数,来自寄存器;
- 存储器操作数,来自存储器;
操作数的寻址方式也灵活复杂很多,有:立即寻址、隐含寻址、直接寻址、间接寻址、寄存器寻址、寄存器间接寻址、基址寻址、变址寻址、相对寻址、堆栈寻址。
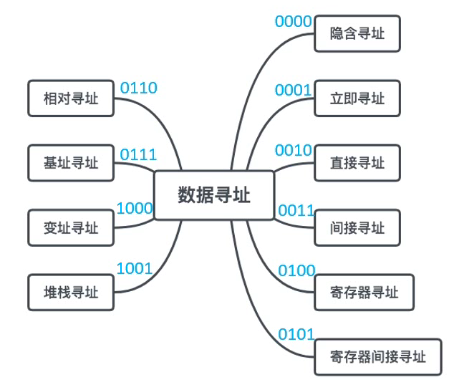
该如何实现操作数寻址呢?我们可以将地址码字段再分为寻址方式字段 I 和形式地址字段 D 两部分,比如说一个包含了寻址方式的单地址指令结构:
| 操作码OP | 寻址方式I | 形式地址D |
|---|
寻址过程就是将 I字段 和 D字段 的不同组合转换为有效地址;I字段表示寻址的方式,形式地址需要根据寻址方式I的不同进行转换。
03-2-2 立即寻址
即I字段编码为立即寻址,D字段形式地址就是操作数本身,也即操作数存在指令里,在我们的课本中被译为立即数,在取值时操作数随该指令一起被送到指令寄存器里,寻址时直接从指令中获取操作数。
这种方式取操作数很快,但是指令字长有限,所以形式地址D长度也有限,所以操作数能表示的范围有限,一般用于变量赋值。
×86中的立即寻址的指令为:
MOV EAX,200BH
意为给寄存器EAX赋初值200BH。
03-2-3 隐含寻址
隐含寻址不直接给出操作数的地址,而是在指令中隐含操作数的地址。
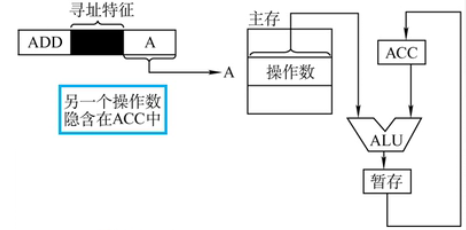
像上面这个图中,形式地址A取出了对应的一个操作数,而另一个操作数则隐含在了ACC中。
03-2-4 直接寻址
直接寻址方式中操作数存放在主存里,操作数地址由形式地址字段D给出,不需要其他计算来获得地址。
不足在于:寻址范围受限于形式地址字段D的长度;数据地址放在指令中,程序和数据在内存中的存放位置也受到限制。
比如×86的直接寻址方式:
MOV EAX,[200BH]
意为将主存中200BH位置的内容送进寄存器EAX里。
03-2-5 间接寻址
相对直接寻址而言,间接寻址D给出的不是操作数的有效地址,而是操作数的间接地址:操作数有效地址所存放的存储单元的地址(地址的地址,联系指针)。
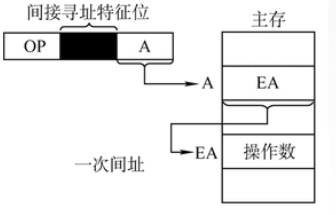
×86的间接寻址指令:
MOV EAX,@2008H
#@是间接寻址标志
意为去2008H这个地方找操作数的地址,在拿这个地址去找操作数。
假设计算机指令字长32位,形式地址字长16位,如果用直接寻址,则寻址空间是216=64K;而如果采用间接寻址,操作数地址放在主存中,寻址空间232=4GB。
可见,间接寻址扩大了寻址范围,可以用较短的形式地址访问较大的内存;相对于直接寻址更加灵活,操作数地址改变时不需改变指令中的形式地址字段,只需改变形式地址指向的主存单元内容即可。
但是,间接寻址访问了两次主存,降低了指令的执行速度,目前更常用的是寄存器间接寻址。
03-2-6 寄存器寻址
这种方式是最常用的寻址方式。和直接寻址原理相近,只是把访问主存改为访问寄存器。
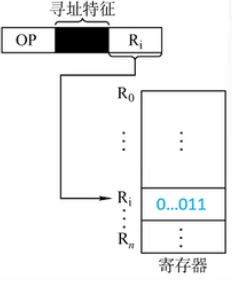
寄存器寻址不需要访问内存,指令执行速度快;所需的地址码较短,有利于缩短指令长度,节省存储空间。但是CPU中寄存器数量也较少,不能同时存储太多操作数。
×86中的寄存器寻址指令为:
MOV EAX,ECX
意为将寄存器ECX中的内容送入EAX中。
03-2-7 寄存器间接寻址
和访问主存的间接寻址原理相同,只不过是操作数的有效地址(主存地址)存放在寄存器中,而形式地址D表示的是存放操作数地址的寄存器的编号。
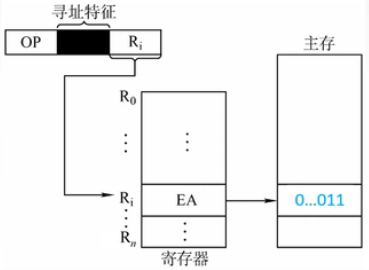
由于第一次访存是访问寄存器,相较于间接寻址速度要快一些。
×86的寄存器间接寻址指令:
MOV AL,[EBX]
意为按照寄存器EBX中的地址访问主存相应位置,取出该位置的内容(操作数地址),再去找到操作数,送入AL寄存器中。
下面介绍偏移寻址的三种方式。简单讲即通过加法计算出有效地址。在思想和形式上更类似于数组的基址偏移,各自的不同是 “数组的基址” 不同。相对于前几种比较复杂,对比思考起来也有难度。
03-2-8 基址寻址
基址寻址是用一个寄存器(BR / EBX / EBP,EBX操作数在数据段,EBP操作数在堆栈段)来放基地址(这个不变),指令中形式地址D存放地址的变化值(偏移量),所以EA = R[BR] + D;
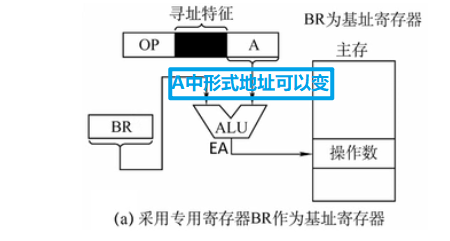
当然也可以不用BR寄存器,使用通用寄存器的话,需要在指令中留一段编码(R0)指向这个通用寄存器,如下图:
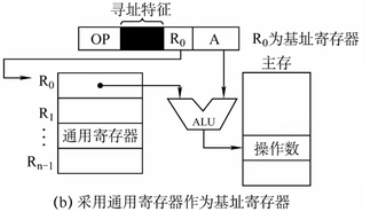
可见这种方式也使用了一点隐含寻址,基址寄存器没有在指令中显式指出。基址寻址的优点是扩大寻址范围,以前D表示地址,现在D表示偏移的多少,显然变得很大。
×86的基址寻址指令为:
MOV EAX,[EBX+SI]
但是在一个循环语句中,基址寻址有一定的局限性,
03-2-9 变址寻址
与基址寻址正好相反,变址寻址指定一个寄存器来存放地址的变化量,而形式字段D来作为基址(基准量),形式地址字段D中还会有一段来指示变址寄存器的编号。EA = R[X] + D。

所以变址寻址中,存放变化量的寄存器的内容可变,D字段不可变。变址寻址常用于有规律的操作:如对线性表之类的数组元素进行重复访问,只需将线性表的起始地址作为基址赋值给形式地址D,让变址寄存器的值按顺序遍历,就可以完成对线性表的遍历。
×86中变址寻址的指令为:
MOV EAX,32[ESI]
意为将变址寄存器ESI的值加上偏移量32作为地址访问主存,再送入EAX中。
03-2-10 相对寻址
把程序计数器PC中的内容加上指令中的形式地址D,产生操作数的有效地址。即 EA = PC + D。D相当于偏移量。
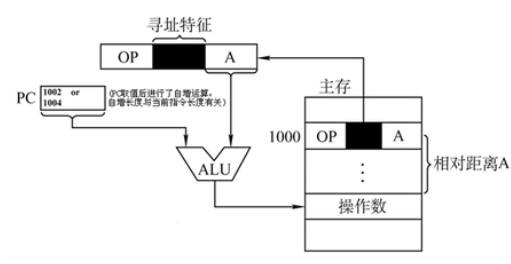
至于为什么是PC程序计数器呢?这跟基址寻址有什么区别呢?可以回忆一下03-2-8的基址寻址,在基址寻址中,我们只能得到操作数的地址,而不能得到操作数后就跳转到下一条指令,而使用相对寻址就可以在取指时通过PC的自增实现指令的顺序跳转。
03-2-11 偏移寻址三种方式的对比思考
这个回头再整理,肝不动了
03-2-12 堆栈寻址
堆栈寻址就是寻找放在堆栈中的操作数。具体根据堆栈的类型分为内存堆栈寻址和寄存器堆栈寻址。
-
内存堆栈寻址 / 软堆栈
为了保证对于空间的需求,计算机一般使用的是存储器堆栈,设置一个栈顶指针寄存器(SP)指向栈顶单元(存储栈顶单元的地址),以字节为单位进栈出栈,进栈出栈的操作由SP指针加减完成,其过程与数据结构中相同,只不过。
- 入栈:SP = SP - 1,M[SP] = R;
- 出栈:R = M[SP], SP = SP + 1;
如果出栈和入栈的数据单位不同,SP每次加减的量也不同,比如32位的数据入栈,就要 SP = SP - 4 ;图源博客:计算机组成原理学习笔记(六):指令系统

内存堆栈又可以分为两种,向上生长(向高地址方向 / 递增堆栈)和向下生长(向低地址方向生长 / 递减堆栈)。上面的例子都是基于向下生长。栈向什么方向增长取决于OS和CPU。具体在这不做深入。
-
寄存器堆栈寻址 / 硬堆栈
为了保证对于速度的需求,还有一些计算机设计了寄存器堆栈,寄存器不按地址访问,所以不设置栈顶指针,栈顶寄存器不能移动,移动的是数据。
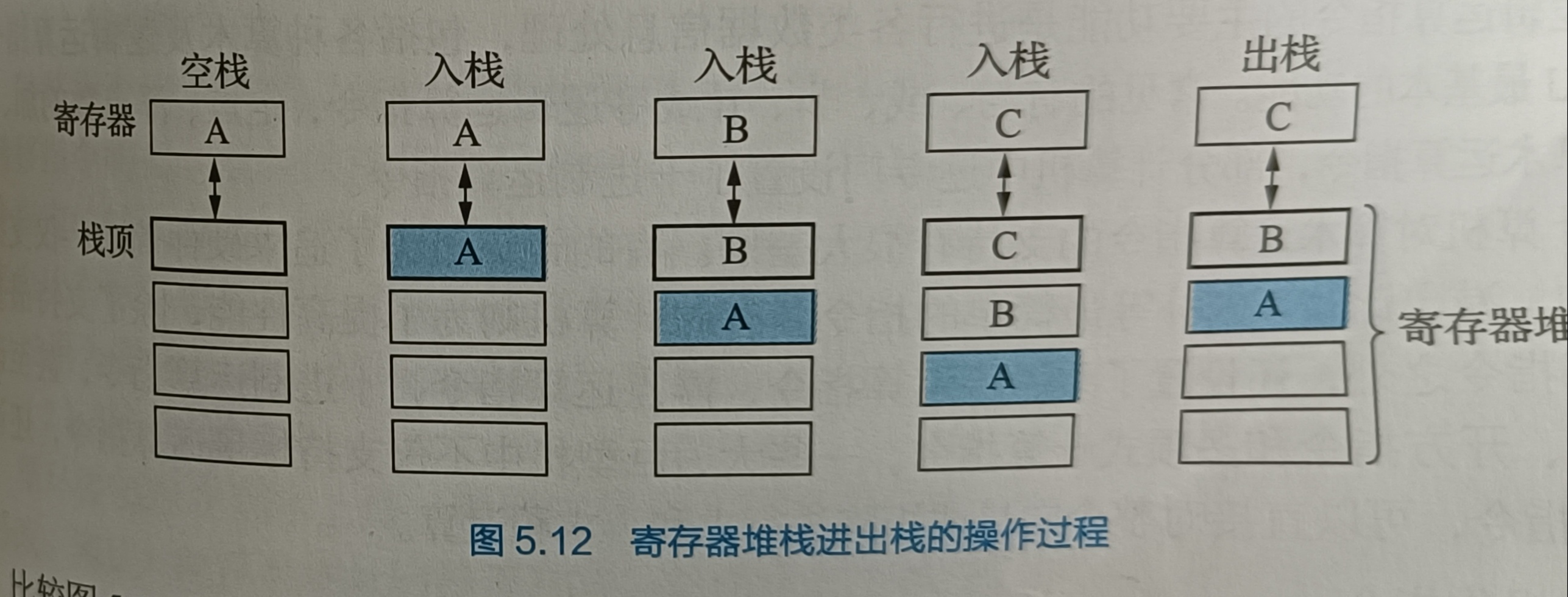
两种堆栈中,寄存器堆栈虽然很快,但成本较高,不适合做大容量的堆栈;内存堆栈虽然速度较慢,但是成本低。而从主存中划出一段区域来做软堆栈是最合算且最常用的方法。
寄存器堆栈必须使用专门的堆栈指令,内存堆栈不一定,可以有其他的替代方法。
在采用堆栈结构的计算机系统中,大部分指令表面上都表现为无操作数指令的形式,而在操作数地址中隐含了SP寄存器。通常情况下,在读 / 写堆栈中的一个单元的前后都伴有自动完成对SP内容的增量或减量操作。
03-2-13 其他寻址以及指令集具体实现
将前面的几种寻址方式排列组合,可以继续得到一些复合的寻址方式,主要用于复杂指令集中:
-
变址 + 间接寻址方式:
先进行变址寻址再进行间接寻址。即把变址寄存器X中的变化量与指令中的形式地址D(基址)相加,得到存储操作数地址的地址。
形式为: EA = (R[X] + D)
-
间接 + 变址寻址方式:
先间接再变址寻址。即根据形式地址D的内容得到存储偏移量的地址,找到这个地址后,再跟变址寄存器中的内容(基址)相加得到操作数的地址,再去拿操作数。
形式为: EA = R[X] + (D)
-
相对 + 间接寻址方式:
先相对再间接寻址。即先把PC中的基址与D中的偏移量相加,再间接寻址等等。
对于某种具体的指令集,可能只实现了以上的一部分,以及它们的一些组合。并且前面所有都是以单地址指令为例,如果是多地址指令,可能每个地址段都有不同的寻址方式。
04 指令类型
虽然不同的指令集设计思想、性能、结构不尽相同,但是都应当具备一些基本的指令类型:
04-1 算术 / 逻辑运算指令
主要作用是进行各类数据信息处理,这也是CPU最基本功能,常见的基本指令有:与、或、非、异或(逻辑运算),定点、浮点的加减乘除(算术运算),以及求补、比较等等。
为了追求硬件简单,计算机可能只支持上面中最基本的指令,甚至连乘除都不一定会有(因为乘除也是通过加法实现的);而如果旨在提高性能,就会有乘除、开方、多项式计算、浮点运算、十进制运算等。
04-2 移位操作指令
包括算术移位、逻辑移位和循环移位三个指令。算术移位和逻辑移位主要用于控制符号数和无符号数的移位;循环移位主要用于实现循环式控制、高低字节互换,以及多倍字长数据的算术移位和逻辑移位;根据是否带上进位位一起循环分为带进位循环和不带进位循环。
04-3 数据传输指令
主要用于数据传送操作,比如寄存器和寄存器之间、寄存器和存储器之间的数据传送。有的指令集设计了通用的MOV指令,而另一些只设计了Load和Store指令,仅用于访存。
04-4 堆栈操作指令
是特殊的数据传输指令,主要包括压栈和出栈两种。有些指令集不设置专门的压栈和出栈指令,而用访存指令和堆栈指针运算指令代替堆栈操作指令,而另一些指令集甚至设有多数据的压栈、出栈指令。
这类指令主要是用于程序调用函数的参数传递过程等。
04-5 字符串操作指令
用于在硬件层面直接支持处理非数值。主要包括字符传送、字符串比较、字符串查找、字符串抽取、字符串转换等指令。
04-6 程序控制指令
用于控制程序的执行顺序和运行方向。主要包括转移指令、循环控制指令、子程序调用返回指令。
- 转移指令
- 无条件跳转
- 条件跳转
- 条件符合,转移到指令指定的地址继续运行;
- 条件不符合,继续原顺序执行;
- 循环控制指令
- 是增强版的转移指令,兼具循环变量修改、条件判断、地址转移功能。
- 子程序调用与返回指令
- 子程序调用指令也称过程调用指令。
- 会给出子程序的入口和子程序返回主程序的地址(断点),当然,需要保存这个断点,比如压入堆栈。
- 用于调用公用的子程序,如MIPS的jal、×86的call指令。
- 子程序返回指令
- 从压入堆栈中取出断点地址送入程序计数器PC,返回断点处继续主程序。
- 与转移指令的区别在于:
- 转移指令在同一程序内,子程序调用指令实现不同程序之间的转移。
- 转移指令不需要返回原处,而子程序调用指令还需要保护断点地址来确保返回。
- 都是无条件的,条件转移需要条件。
- 子程序调用指令也称过程调用指令。
04-7 输入输出指令
用于实现主机和外部设备之间的信息传送,读取外部设备的工作状态、控制外部设备工作等;如果外部设备和主存采用统一编址模式,则不需要设置专门的I/O指令,直接用访存指令即可。
04-8 其他指令
其他指令包括停机、等待、空操作、特权等其他控制功能的指令。
特权指令主要用于资源分配管理,一般不直接给用户使用。
05 指令格式设计
现在我们已经了解了指令集的一些特征和运作机制,在开始介绍具体的指令集之前,如果要我们自己设计一种指令集,我们应当考虑哪些方面?
从宏观上讲,这个指令集要完备、要规整、要有效、要具备兼容和扩展性,最重要的是要有合理的指令格式,这决定了软硬件两方面后续工作是否因此变得简化和便捷。
指令一般由操作码和地址码组成,我们首先要确定指令编码格式,然后确定操作码和地址码各自的长度以及组合形式。最后是寻址方式。
-
指令编码格式设计
即决定指令集的指令采用定长、变长还是混合编码指令。定长和变长均在02指令格式部分有所介绍,混合编码指令格式是定长和变长两种指令结构的综合,提供若干长度固定的指令字,既能减少目标代码的长度,也能降低译码复杂度。
-
操作码设计
操作码的编码比较直观,只需要把指令情况全部编码即可,此外要考虑指令编码格式是变长还是定长,要保证两条指令之间在硬件电路译码时不能相互冲突。
-
地址码设计
地址码要为指令提供操作数,通常还需要考虑寻址方式,尽量利用有限的位宽提供更大的范围。
-
寻址方式设计
寻址方式前面提到过,可以放在操作码字段中编码,也可以在地址码中单独设置一段来指示寻址方式。
06 指令系统举例
这部分本想放在前面,但里面的一些术语需要了解了指令系统才能更好明白。
06-1 发展历程
- 1970年 DEC发布PDP-11指令集,1992年推出ALPHA(64位)
- 1978年 Intel发布了×86指令集,2001年推出IA64
- ×86依托Intel,控制了电脑产业链
- 1980年 IBM推出PowerPC
- 1981年 诞生MIPS指令集
- 很美很学术,但是生态系统分裂,没有形成合力
- 1985年 SUN推出SPARC
- 1991年 arm推出第一版arm
- 依靠IP授权,在手机领域应用广泛
- 2016年 RISC发布开源RISC-V,是MIPS的改进,两者差别不大
- 2020年 龙芯推出LoongArch
- 面对制裁下的“丢掉幻想”
06-2 指令集分类
就是著名的CISC和RISC。CISC是指 Complex Instruction Set Computer / 复杂指令集计算机;而RISC是指 Reduced Instruction Set Computer / 精简指令集计算机。它们分别采用了不同的设计理念。
06-2-1 复杂指令系统计算机 / CISC
基于大规模集成电路的不断发展,硬件成本不断降低,而上层软件成本不断提高(需求在变复杂),因此,计算机设计者在设计指令系统时,着重考虑为上层软件服务,增加了许多功能强大的复杂指令,以及更多的寻址方式,来满足上层软件不同的需求,具体表现为:
- 更支持高级语言
- 语义更加接近高级语言,
- 简化编译器工作
- 编译器将高级语言翻译为机器语言,当机器语言接近高级语言,编译器的工作会变简单。
- 支持操作系统的更多功能
- 复杂的指令更满足操作系统更复杂的功能,比如操作系统的多媒体、3D功能
- 支持实现更多的指令
- 指令虽然有定长和变长两种,但长度不可能是无限长的,要在有限长的空间中表达出更多的指令,只能压缩地址码长度,因此需要设计更多的寻址方式
- 满足指令集更新和软件兼容
- 同一系列的计算机,为了使软件兼容新旧计算机,指令系统只能扩充而不能删减已有指令,所以指令数量越来越多,而CISC更适合指令集的扩充;
CISC的特点有:
- 指令集复杂、庞大,指令数目繁多(上百条近千条);
- 指令不定长,格式多、寻址方式多;
- 访存指令没有限制;
- 各个指令使用频率相差会很大;
- 各个指令执行时间相差会很大;
- 微程序控制器被广泛使用;
06-2-2 精简指令集计算机 / RISC
RISC是在继承CISC的成功技术和克服一些缺点的基础上发展起来的。早期被提出是因为在研究中人们发现,复杂指令集虽然可以支持强大的功能,但是内部格式过于复杂,指令格式很不规范,并且,80%的程序只用到了20%的指令,而如果看过我的上一篇,加速大概率事件是一种硬件设计应当遵循的原则,所以我们可以只设计20%或多一点的指令,对这些指令的格式进行优化,使其格式规范、寻址方式简洁,再由多条简单指令凑出复杂指令的功能。
RISC的特点有:
- 优先选用使用频率最高的简单指令,以及一些有用而不负责的指令,避免直接使用复杂指令;
- 大多数指令在一个时钟周期中完成;
- 规定仅由 load & store 指令访问主存,其他指令只能基于寄存器操作数处理;
- 着重面向寄存器操作,因此CPU内部寄存器较多(32 / 64);
- 长度固定,寻址方式和指令格式简单,逻辑实现方便,使得控制器速度提高;
- 注重编译优化,力求有效支持高级语言;
06-2-3 两种指令集简单对比
CISC倾向于服务软件,对于指令集的设计优先支持软件,同时寄存器较少(早期,目前由于硬件设计技术的进步,寄存器也变多了),这照顾了硬件设计的难度(寄存器太多,线路过长,硬件成本会上升、信号传递时间也会上升)。其优化的思路是简化指令系统,通过额外的指令微程序控制器,来实现复杂指令逻辑的正常运作。
常见有Intel ×86,IA64;
RISC更兼顾软硬件需求,基本思想是选取使用频次高和有用的指令,设计简单规范的基本指令,再由基本指令组装成为复杂指令,实现复杂功能。其优化的思路是简化指令本身,使计算机的结构简单合理,降低单条指令的执行时间 / 执行周期数(可以达到一周期一条指令甚至多条指令运行),对于硬件来说,逻辑的简化也简化了硬件电路的设计,而增加了寄存器数量,会对硬件设计造成一定的压力。
常见有ARM、MIPS、RISC-V。
06-3 指令集优劣
评估一个指令集会从以下两个方面进行:
- 是否方便CPU的硬件实现;高性能、低功耗;
- 是否方便编译器、操作系统、虚拟机的实现和开发;
07 简单总结 | Review
这个部分比我想象的更长,介绍了一个指令集的特征以及工作模式,提了提设计一个指令集应该考虑什么问题,然后介绍了各种已成名的指令集。
- 指令格式,指令码和地址码。
- 寻址方式,各种寻址方式的实现机制。
- 指令种类,指令集需要一些基本的指令,也会有其他用于支持复杂功能的指令。
- 各种各样的指令集,CISC和RISC的对比。
感觉还是在填计基的坑。下一篇讲解MIPS的指令可能就会轻松一点。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号