CTF入门学习3->Web通信基础 | URL & HTTP
01 Web通信
这个部分重点介绍浏览器与Web服务器的详细通信过程。
01-00 URL协议
只要上网访问服务器,就离不开URL。
URL是什么?
URL就是我们在浏览器里输入的站点链接。又叫做“统一资源定位符”(Uniform Resource Locator)。
URL支持很多协议,比如HTTP、FTP等等。
PS:HTTP和URL有何区别?
答:(来源(https://www.jianshu.com/p/4fb712c05b63)
HTTP:(Hypertext transfer protocol)超文本传输协议,是用于从万维网(WWW:World Wide Web)服务器传输超文本到本地浏览器的传送协议。
URL:(Uniform Resource Locator)统一资源定位符,对可以从互联网上得到的资源的位置和访问方法的一种简洁的表示,是互联网上标准资源的地址。
URL的作用就是定位服务器的资源。
那如何才能定位到网站(服务器)的资源呢?
我们来设想一下:我们在网上购买的东西是如何寄到我们手上的呢?
我们提供了我们的收货地址。
在Web的世界中,URL就充当了收货地址的角色。
浏览器通过URL,可以定位到服务器的资源,然后将服务器的资源展示给我们。
这个“收货地址”有一定的格式:
schema://host[:port#]/path/.../[?query-string] [#anchor]
schema:底层协议如http、https、ftp等;
host:服务器的域名或者IP地址;
:port# : 服务器端口,HTTP默认端口是80(可以省略),其他端口需要指明;
/path: 访问资源的路径;
?query-string: 发送给服务器的数据;
#anchor: 锚;通常表示在页面的特定位置。
URL实例
例如这个URL:http://dun.163.com/sj/test/test.jsp?name=sviergn&x=true#stuff
逐一解析:
schema:http协议;
dun.163.com;没有指明端口,默认80
/path:/sj/test/test.jsp,访问资源的路径;
?query-string:?name=sviergn&x=true;
anchor:
这一部分需要常忆常用。
01-01 HTTP协议
HTTP就是Web通信时使用的协议,也是Web建立的基础;是网络上应用最广的一种协议。
什么是HTTP?
HTTP又称超文本传输协议;英文名:Hyper Text Transfer Protocol;
为了了解这一协议的过程,我们拿快递小哥的工作打比方:
-
-
如果要让快递小哥送进小区里面,我们就需要告诉物业准许他进入,相当于给他颁了个通行证;
-
HTTP协议类似。
-
-
快递小哥通过货车送货:浏览器通过Get方式发送请求。
-
HTTP中的Host就相当于“收件人地址”;
-
User-Agent就相当于快递小哥所处的公司;
-
HTTP包含的Cookie就相当于能够进入我们小区的凭证。
-
可以看到HTTP协议的请求和响应包含了一些特殊的属性,包含方式、User-Agent、Host、返回的状态码等等;
上面这些都属于HTTP的报文。
什么是HTTP的报文?
分为三部分:起始行、头、身体
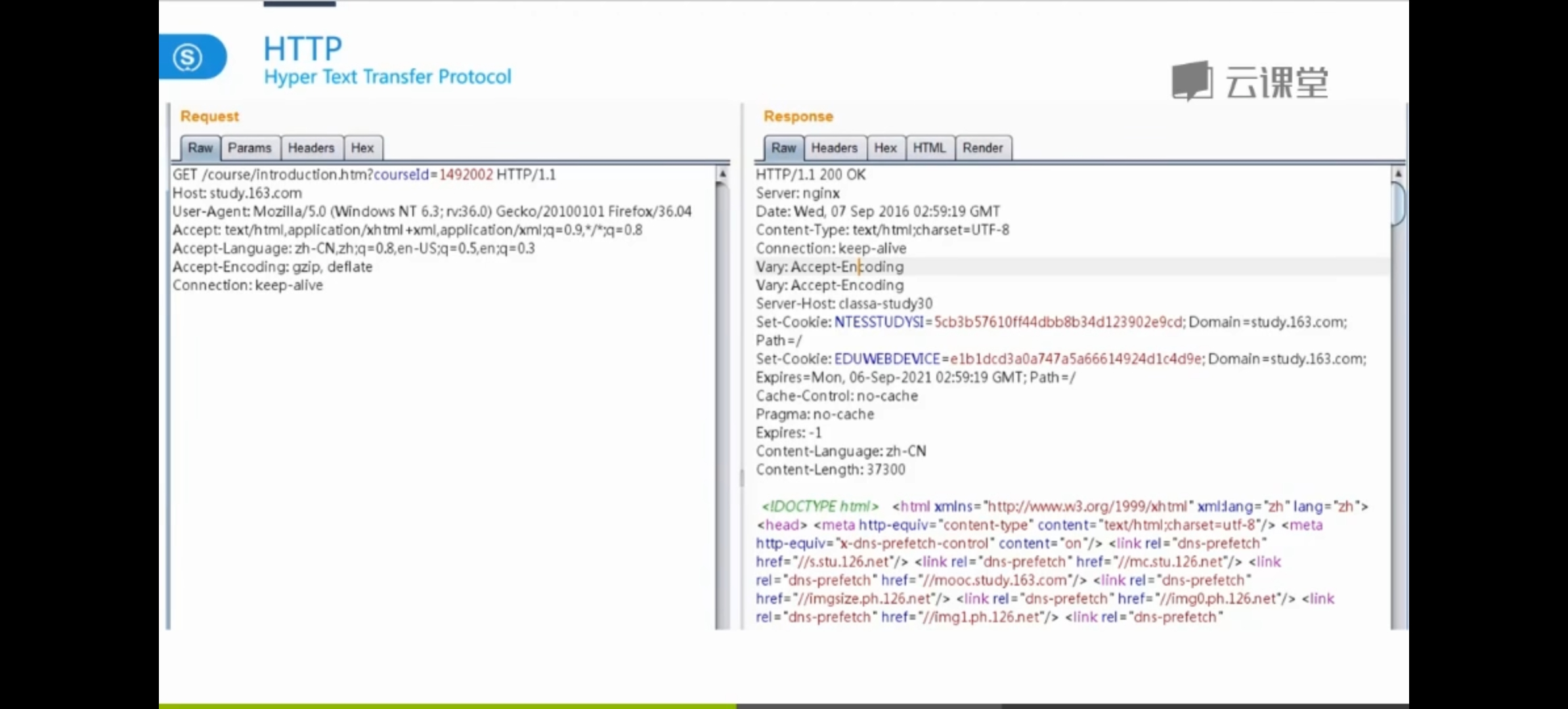
左边,是浏览器发送的HTTP请求报文,右边是服务器返回的HTTP请求报文;
-
左侧
-
第一行:请求行Request Line
-
之后:是我们的头部Headers;
-
下面:应该是我们的数据体,但由于是GET请求,没有数据体
-
注意头部和数据体之间是有一个空行的。
-
-
右侧
-
第一行:状态行;
-
比如:HTTP/1.1 200 OK
-
-
头部
-
主体:也就是响应的正文
-
注意响应的头部和主题之间也是有一行空行的。
-
HTTP请求示例
比如一个发帖的HTTP请求
当我们进行发帖的时候,我们的请求报文和响应报文如下:
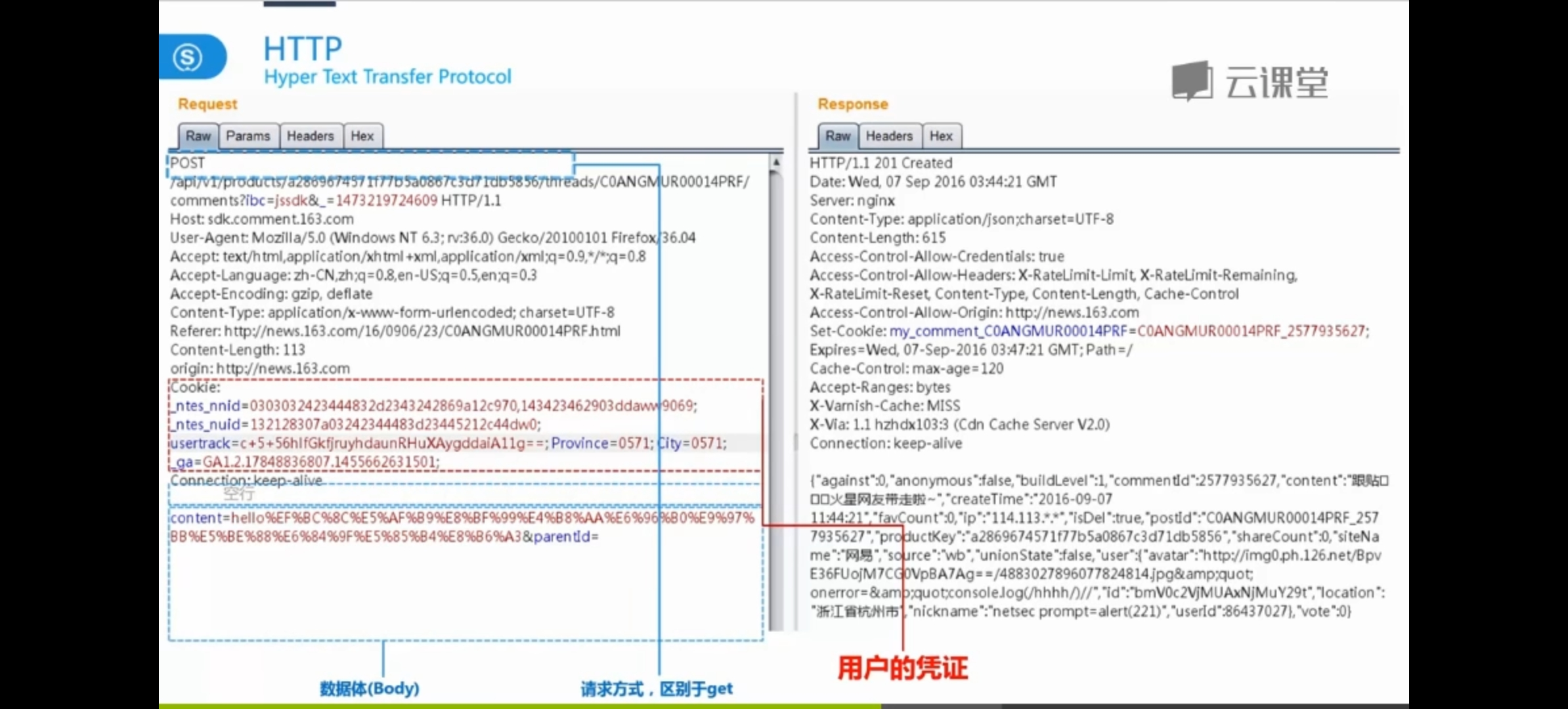
-
请求
-
第一行:请求行
-
这里是POST
-
-
Headers
-
相较于上面,多了一个Cookie字段,就是前面提到的用户凭证,相当于告诉服务器,是我发的这个帖子。
-
黑客就比较喜欢获取这个Cookie凭证,如果获取,就拥有了“我”的凭证,可以以“我”的身份发帖。
-
后面会接触一些这方面的安全漏洞。
-
-
也有了数据体
-
就是要发布的帖子的相关内容
-
-
HTTP请求的其他方法
-
HEAD
-
与GET请求类似,不同是只返回HTTP的头部信息,没有数据体,也就没有页面内容。
-
-
PUT
-
上传指定的URL描述
-
-
DELETE
-
删除指定资源
-
-
OPTIONS
-
返回服务器支持的HTTP方法
-
01-02 HTTP头的Referer
这是除了HTTP请求方式和Cookie的概念外,另一个重要概念。
Referer就是告诉服务器,我们从什么地方来(即告诉物业我们是哪个快递公司的);
举例:
我们通过https://m.study.163.com/直接跳转到页面。和从bing主页搜索云课堂再进入,开发者工具中显示的HTTP请求是不同的,后者会多一个Referer头,表示是从bing的这个链接来的。
如图;图一是直接跳转;图二是搜索跳转;
直接跳转Rerfer

搜索跳转的Rerfer与之不同。
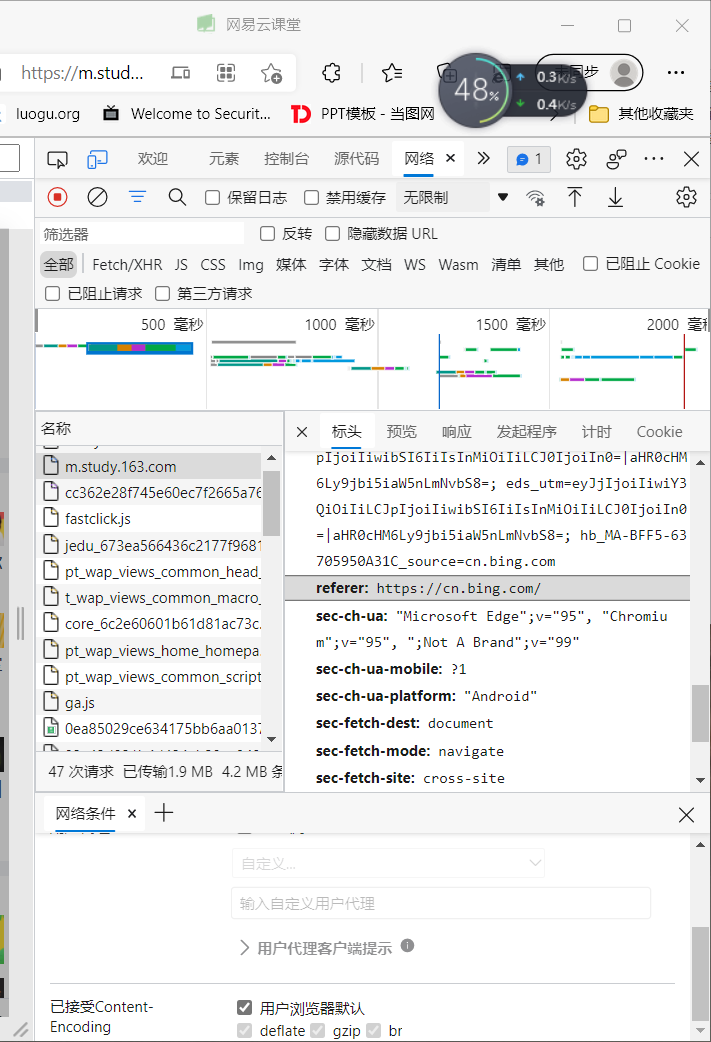
所以由于Referer可以告诉服务器该次请求的来源,所以很多Web服务器会通过Referer来进行统计(比如CNZZ、百度统计)
从安全的角度来讲,Referer还可以用来判断来源是否合法。
(比如:
-
防止盗链
-
比如一些网站不想被盗用内容或恶意引用,就会通过Referer限制来者
-
-
防止CSRF漏洞
-
(暂不了解
-
01-03 HTTP状态码
302 --跳转
比如:在响应报文的状态行(第一行)
HTTP/1.1 302 Moved Temporarily在跳转同时,还会在响应报文的Headers部分有一个Location字段,是跳转到的URL地址,也就是这个响应报文告诉我们,我们需要跳转到Location中的URL地址。
除了这两处,还会有Set-Cookie字段,作用是Web服务器向我们的浏览器颁发凭证,比如我们通过用户名密码登录成功后,Web服务器通常就会给我们颁发一个凭证。
类似的是301。
除此之外,还包括10x,20x,30x,40x,50x;每个状态码都代表不同的意思。
| 分类 | 分类描述 |
|---|---|
| 10x | 信息,服务器收到请求,需要请求者继续执行操作 |
| 20x | 成功,操作被成功接收并处理 |
| 30x | 重定向,需要进一步的操作以完成请求 |
| 40x | 客户端错误,请求包含语法错误或无法完成请求 |
| 50x | 服务器错误,服务器在处理请求的过程中发生了错误 |
具体的状态码可以到后面再学习,或用到查看。
01-04 实例演示
我们打开Edge浏览器,输入https://www.cnblogs.com/Roboduster
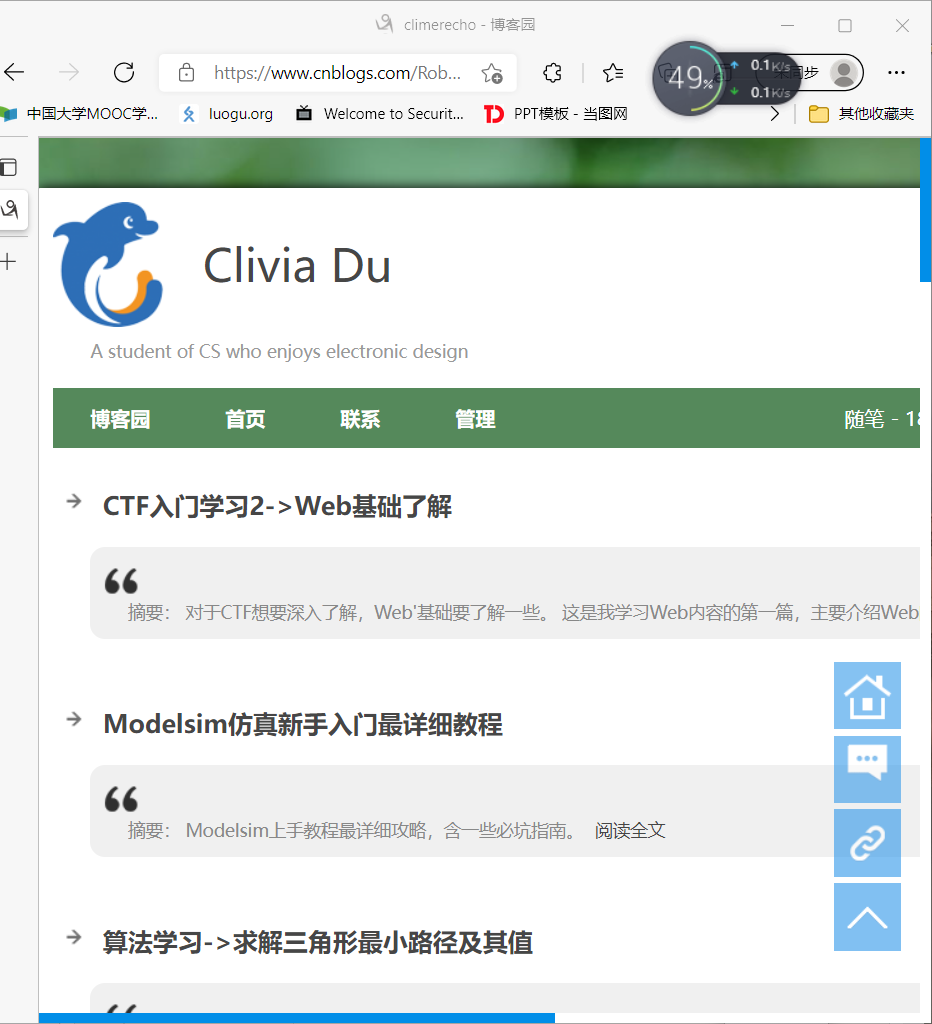
我们用F12打开开发者工具,进入“网络”,刷新一下,查看“文档”,选中head头,可以看到有请求头、响应头,点击就可以看源码,有一些是上面讲过的,还有些字段是不熟悉的。这些字段可以自行查阅。
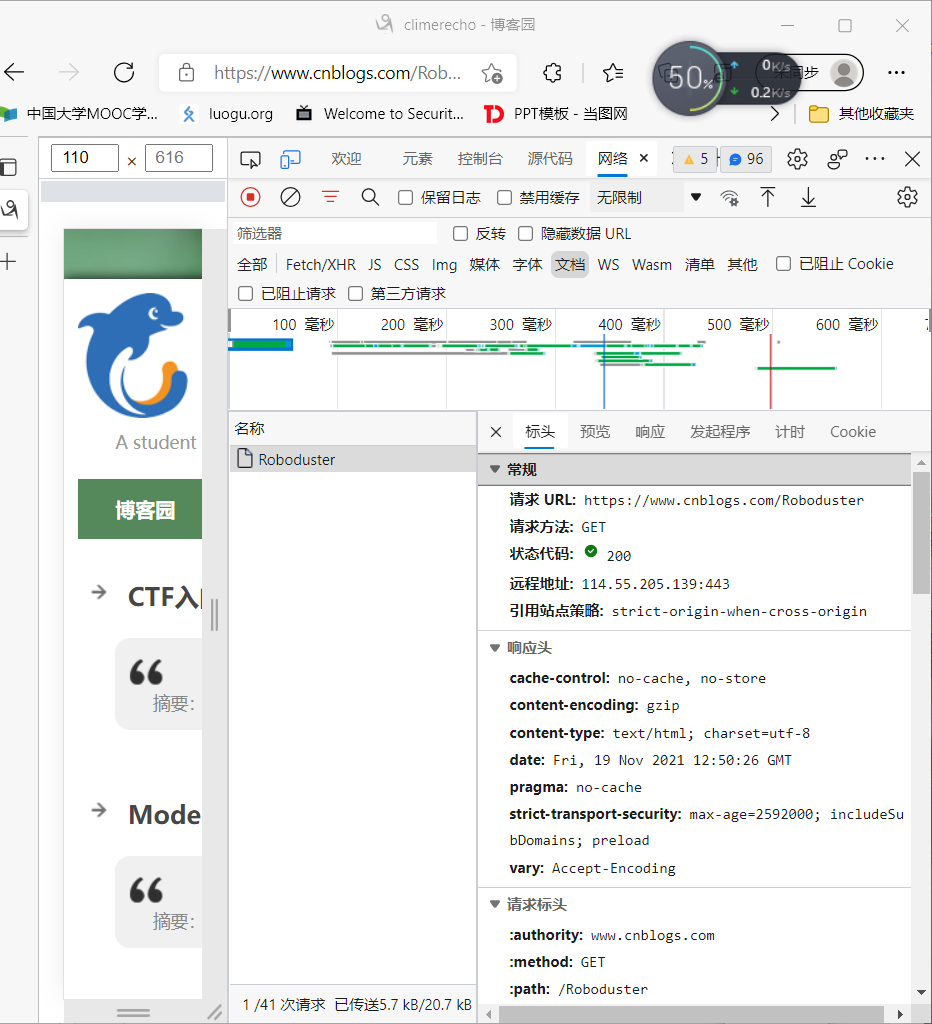
除了HEADER外,我们可以看一看响应的具体内容,在左侧的“响应”中;Cookie中有请求的Cookie等等。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号