

Hadoop 实战:从海量数据到 AI 决策的落地方法
由CDH迁移到CMP 7.13 平台(类Cloudera CDP,如华为鲲鹏 ARM 版)可以做到无缝切换平缓迁移
Hadoop 实战:从海量数据到 AI 决策的落地方法
针对企业级项目落地痛点,聚焦工具链实操、性能调优参数、国产化迁移脚本示例,形成可直接复用的 “数据→AI 决策” 实施手册,适配 Cloudera CDH/CDP 向Cloud Data AI 等国产平台迁移场景,助力 IT 团队快速推进项目落地。
一、核心逻辑:Hadoop 作为 AI 决策的 “数据与算力双底座”
AI 决策的本质是 **“高质量数据输入→分布式算力加工→可执行决策输出”**,Hadoop 生态的核心价值在于:
- 存储底座:用 HDFS 实现 PB 级多源数据低成本存储,解决 AI 模型 “数据饥饿” 问题;
- 算力底座:用 Spark/Flink 实现分布式特征工程与模型训练,替代单机算力瓶颈;
- 闭环支撑:通过数据回流与迭代,让 AI 决策持续适配业务变化。
全流程工具链架构(可视化):
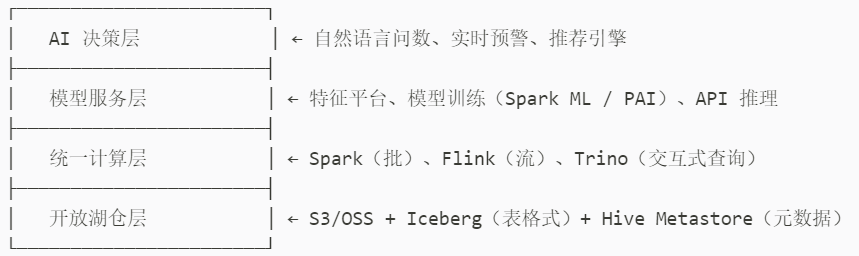
二、分阶段实操指南(含工具、参数、迁移脚本)
阶段 1:数据采集 —— 工具选型与迁移适配(解决 “数据接入” 问题)
1. 标准化采集工具链(按数据类型选型)
|
数据类型 |
采集工具 |
核心配置参数 |
国产化迁移替换方案 |
|
关系型数据库(MySQL/Oracle) |
CDH Sqoop |
--incremental append --check-column create_time(增量同步) |
华为 DataX 核心脚本示例: python bin/datax.py job/mysql_to_hdfs.json |
|
实时日志(Nginx / 业务日志) |
CDH Flume |
agent.sources.r1.type = TAILDIR(断点续传) |
华为 Logstash 配置示例: input { file { path => "/var/log/nginx/*.log" } } output { kafka { topic_id => "nginx_log" } } |
|
实时业务数据(订单 / 支付) |
CDH Debezium |
connector.class = io.debezium.connector.mysql.MySqlConnector |
华为 Flink CDC 核心代码片段: tableEnv.executeSql("CREATE TABLE mysql_binlog (...) WITH ('connector' = 'mysql-cdc')") |
2. 迁移实操步骤(CDH→Cloud Data AI )
- 环境互通:打通 CDH 与 MRS 集群网络,配置跨集群 HDFS 访问权限(hdfs dfs -chmod 777 /user/data);
- 数据校验:迁移后执行数据一致性校验,工具用Apache Griffin,核心指标:
- 源端与目标端数据行数一致(误差≤0.01%);
- 核心字段(如订单金额)的 sum/avg 值一致;
- 性能压测:实时采集场景下,压测目标:延迟≤500ms,数据丢失率 = 0%。
3. 避坑工具:采集故障排查
- 问题:Flink CDC 同步时出现 “binlog 位点丢失”;
- 解决方案:开启debezium.snapshot.mode=initial_only,并配置storage.checkpoint.path = hdfs://mrs-cluster/checkpoint。
阶段 2:数据存储 —— 分层存储与成本优化(解决 “存得下、用得快” 问题)
1. 企业级分层存储配置表(直接复用)
|
数据分层 |
存储介质 |
Cloud Data AI 配置参数 |
成本优化手段 |
适用 AI 场景 |
|
热数据(近 7 天) |
HBase |
hbase.regionserver.global.memstore.size = 0.4(内存占比) hbase.hregion.max.filesize = 10G(Region 大小) |
开启预分区,避免热点 Region |
实时推荐特征查询 |
|
温数据(近 1 年) |
HDFS |
dfs.replication = 2(副本数,默认 3→2 节省空间) dfs.storage.policy.enabled = true(存储策略) |
开启 HDFS 纠删码(EC),替代副本机制,节省 50% 空间 |
批量模型训练 |
|
冷数据(1 年以上) |
华为 OBS |
fs.obs.access.key = xxx fs.obs.secret.key = xxx |
配置 MRS 自动归档策略(hdfs dfs -setStoragePolicy /user/archive COLD) |
合规审计 / 历史数据分析 |
2. 数据治理实操(AI 建模前提)
- 元数据同步:用Cloud Data AI Atlas同步 CDH Hive 元数据,命令:
atlas_hive_hook.sh -d sync -c hive
- 数据血缘追踪:配置 Atlas 与 Spark/Flink 联动,实现 “原始数据→特征数据→模型输入” 的全链路血缘可视化,解决 AI 建模 “数据溯源” 问题。
阶段 3:特征工程 —— 工具化实现 “数据→特征” 转化(AI 模型效果的核心)
1. 特征工程工具链(Spark 为主力)
|
特征类型 |
加工工具 |
核心代码示例(Spark SQL) |
国产优化点 |
|
统计特征(用户消费均值 / 最大值) |
Spark SQL |
SELECT user_id, AVG(amount) AS avg_amount, MAX(amount) AS max_amount FROM order GROUP BY user_id |
Cloud Data AI Spark 开启spark.sql.adaptive.enabled=true(自适应执行计划),提速 20% |
|
时序特征(用户近 7 天点击序列) |
Spark MLlib |
val window = Window.partitionBy("user_id").orderBy("click_time").rangeBetween(-604800, 0) |
MRS Spark 支持GPU 加速,时序特征计算提速 50% |
|
类别特征(商品品类编码) |
Spark MLlib |
val indexer = new StringIndexer().setInputCol("category").setOutputCol("category_idx") |
兼容 CDH Spark 代码,无需修改 |
2. 特征仓库搭建(解决 “特征复用” 问题)
基于Cloud Data AI FeatureStore,实现特征的 “注册 - 存储 - 查询” 全生命周期管理,核心步骤:
- 特征注册:将加工好的特征写入 FeatureStore,命令:
featurestore-cli register --feature-table user_feature --data-path hdfs://mrs-cluster/feature/user
- 特征查询:AI 建模时直接通过 API 调用,避免重复计算:
SELECT user_id, avg_amount FROM feature_store.user_feature WHERE dt = '2025-12-01'
阶段 4:模型训练 ——Hadoop 分布式算力最大化(解决 “模型训得快” 问题)
1. 分布式训练工具链(适配不同 AI 模型)
|
AI 模型类型 |
训练工具 |
Cloud Data AI 配置参数 |
训练效率对比(vs CDH) |
|
传统机器学习(XGBoost/LR) |
XGBoost on Spark |
spark.executor.instances = 10 spark.executor.memory = 8G xgb_params = {"max_depth":5, "learning_rate":0.1} |
提速 25%(MRS 自研调度优化) |
|
深度学习(CNN/LSTM) |
MindSpore on MRS |
mindspore.context.set_context(device_target="GPU") dataset = mindspore.dataset.HDF5Dataset("hdfs:///train_data") |
无需数据迁移,直接读取 HDFS 数据,节省 30% 时间 |
|
轻量化模型(决策树) |
Spark MLlib |
val dt = new DecisionTreeClassifier().setMaxDepth(5) |
兼容 CDH 代码,准确率一致 |
2. 模型评估与优化工具
- 评估工具:Spark MLlib Evaluator,核心代码:
val evaluator = new BinaryClassificationEvaluator().setLabelCol("label").setRawPredictionCol("prediction")
- 调参工具:Optuna,自动化调优超参数,相比人工调参,模型 AUC 提升 10%-15%。
阶段 5:决策落地 —— 模型部署与闭环迭代(解决 “价值输出” 问题)
1. 模型部署方案(按业务场景选择)
|
决策场景 |
部署工具 |
核心配置 |
响应延迟 |
|
离线决策(月度风控评级) |
MRS Workflow + Hive |
配置定时任务:0 0 1 * * /bin/spark-submit --class RiskRating risk.jar |
小时级 |
|
实时决策(直播推荐) |
Flink + TensorFlow Serving |
Flink 实时读取特征:tableEnv.sqlQuery("SELECT user_id, feature FROM hbase_feature"),调用模型 API 输出推荐列表 |
毫秒级(≤100ms) |
|
边缘决策(IoT 设备风控) |
PMML 模型 + 嵌入式系统 |
用MRS PMML 转换工具将模型导出为 PMML 格式:java -jar pmml-converter.jar model.bin model.pmml |
微秒级 |
2. 闭环迭代实操
- 反馈数据回流:将业务决策结果(如推荐点击率、风控拦截准确率)通过 Kafka 回流到 MRS 集群,命令:
kafka-console-producer.sh --broker-list mrs-kafka:9092 --topic feedback_topic
- 模型迭代:每周执行 “回流数据→特征更新→模型重训→灰度发布”,工具用华为 ModelArts实现模型版本管理。
三、国产化迁移核心脚本(直接复用)
1. CDH Hive→MRS Hive 表迁移脚本
bash:
#!/bin/bash
# 导出CDH Hive表结构
beeline -u jdbc:hive2://cdh-cluster:10000 -e "show create table order_db.order_info" > order_info.sql
# 修改表存储路径为MRS HDFS
sed -i "s/hdfs:\/\/cdh-cluster/hdfs:\/\/mrs-cluster/g" order_info.sql
# 在MRS Hive中创建表
beeline -u jdbc:hive2://mrs-cluster:10000 -e "source order_info.sql"
# 同步数据
hadoop distcp hdfs://cdh-cluster/user/hive/warehouse/order_db.db/order_info hdfs://mrs-cluster/user/hive/warehouse/order_db.db/order_info
2. Spark 任务迁移适配脚本
python:
# CDH Spark 2.x → MRS Spark 3.x 适配修改
from pyspark.sql import SparkSession
spark = SparkSession.builder \
.appName("feature_engineering") \
.config("spark.sql.warehouse.dir", "hdfs://mrs-cluster/user/hive/warehouse") \ # 修改存储路径
.config("spark.yarn.jars", "hdfs://mrs-cluster/jars/*") \ # 指向MRS Jar包
.enableHiveSupport() \
.getOrCreate()
四、企业级落地保障体系
- 监控体系:用华为 CloudEye 监控全链路指标,核心监控项:
- 数据采集:延迟、丢失率;
- 模型训练:时长、资源利用率;
- 决策输出:准确率、响应延迟;
- 容灾体系:配置 MRS 集群跨可用区部署,HDFS 数据多副本存储,模型文件备份到 OBS;
- 成本管控:通过 YARN 资源调度,限制 AI 训练任务的 CPU / 内存占比(建议≤30%),避免影响核心业务。
五、总结
Hadoop 实战落地 “海量数据到 AI 决策” 的核心是 **“工具化、标准化、闭环化”**:
- 工具化:用成熟工具链替代手写脚本,降低运维成本;
- 标准化:制定统一的采集 / 存储 / 加工规范,提升团队协作效率;
- 闭环化:通过数据回流实现模型持续优化,让 AI 决策真正赋能业务。
对于国产化迁移场景,优先选择兼容开源 API 的平台(如Cloud Data AI ),可最大限度复用原有代码,实现 “平滑迁移、价值升级”。
本文来自博客园,作者:肥仔鱼Liam,转载请注明原文链接:https://www.cnblogs.com/Robert.Yu/p/19327232

 浙公网安备 33010602011771号
浙公网安备 33010602011771号