数据分析项目之:金融反欺诈(信用卡盗刷)
项目名称:金融反欺诈(信用卡盗刷)
项目概述:本项目通过利用信用卡的历史交易数据进行机器学习,构建信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
项目背景:数据包含了由欧洲持卡人于2013年9月使用信用卡进行交易的数据。此数据集显示两天内发生的交易,其中284807笔交易中有492笔被盗刷。
数据集非常不均衡,积极的类(被盗刷)占所有交易的0.172%。
它只包含作为PCA转换结果的数字输入变量,不幸的是,由于保密问题,我们无法提供有关数据的原始功能和更多背景信息。特征V1,
V2,...V28是使用PCA获得的主要组件,没有用PCA转换的特征是“时间”和“金额”。特征“时间”包含数据集中每个事务和第一个事务
之间经过的秒数。特征“金额”是交易金额,此特征可用于实例依赖的成本认知学习。特征“类”是响应变量(目标值),如果发生被盗刷,
则取值1,否则为0。
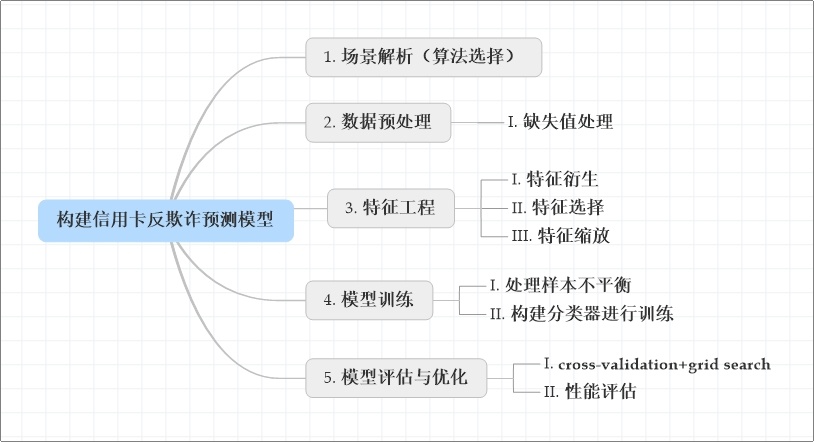
建模思路:
数据链接:链接:https://pan.baidu.com/s/1iDUderFhwM8YMJSgp2DrVg 密码:cglg
场景解析(算法选择)

0. 导包
1 import numpy as np 2 import pandas as pd 3 import matplotlib.pyplot as plt 4 import seaborn as sns 5 sns.set_style('whitegrid') 6 %matplotlib inline 7 8 import missingno as miss 9 from sklearn.linear_model import LogisticRegression 10 from sklearn.ensemble import GradientBoostingClassifier # 梯度提升树(用于特征重要性排序) 11 from sklearn.preprocessing import StandardScaler # 数据标准化 12 from imblearn.over_sampling import SMOTE # 过采样(解决样本不均衡问题) 13 from sklearn.metrics import roc_curve,auc # ROC-AUC曲线 14 from sklearn.metrics import confusion_matrix # 混淆矩阵 15 from sklearn.metrics import recall_score 16 from sklearn.metrics import accuracy_score 17 from sklearn.model_selection import GridSearchCV # 模型优化 18 from sklearn.model_selection import train_test_split 19 import itertools 20 21 import warnings 22 warnings.filterwarnings('ignore') 23 24 from pylab import mpl # 用于显示中文 25 mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体 26 mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
1. 数据载入
1 data = pd.read_csv('./creditcard.csv') 2 3 data1 = data.copy()
2. 查看数据概况
1 display(data1.shape,data1.tail(),data1.info(),data1.describe())
1 miss.matrix(data1) # 查看数据缺失情况

可以看到数据很干净,很完整。
总结如下:
1. 数据为格式化数据,无需做特征抽象;
2. 没有空值和异常值;
3. Time 和 Amount 两个特征需要做特征缩放。
4. 特征工程
4.1目标变量可视化
1 # 目标变量可视化 2 fig,ax=plt.subplots(1,2,figsize=(12,8)) 3 sns.set(style='darkgrid') 4 5 sns.countplot(x='Class',data=data1,ax=ax[0]) 6 ax[0].set_title("目标变量中每类的频数分布直方图") 7 # autopct='%1.2f%%' --- 长度为1,保留百分号前面的2个小数点 8 data1['Class'].value_counts().plot(kind='pie',ax=ax[1],fontsize=23,autopct='%1.2f%%') 9 ax[1].set_title("目标变量中的每类频率分布饼图")
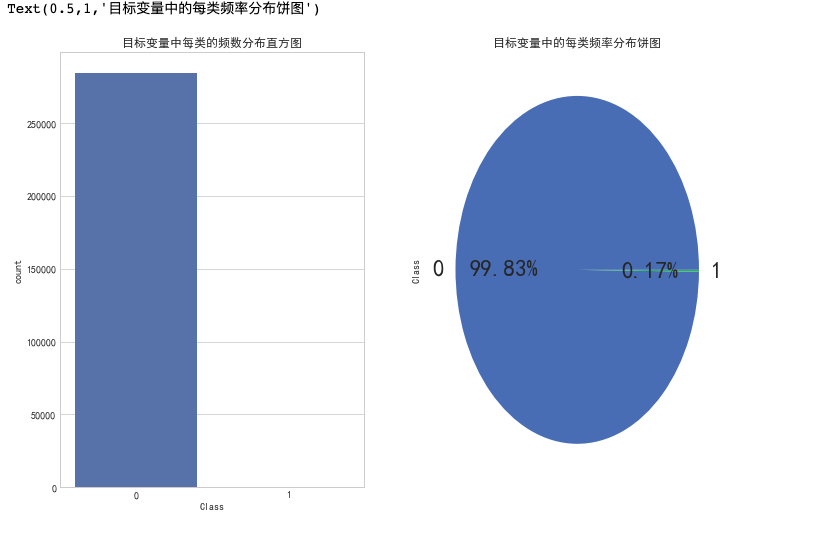
data1['Class'].value_counts() ''' 0 284315 1 492 Name: Class, dtype: int64 '''
通过上面的图和数据可知,存在492例盗刷,占总样本的0.17%,由此可知,这是一个明显的数据类别不平衡问题,稍后采用过采样(增加数据) 的方法
对这种问题进行处理。
4.2 特征转换(特征缩放)
1 # Time 和 Amount两个特征做特征缩放 2 std = StandardScaler() 3 4 # Amount 标准化 5 data1['Amount'] = std.fit_transform(data1[['Amount']]) 6 7 # Time 将单位变为小时 8 data1['Time'] = data1['Time'].map(lambda x : x//3600) 9 # Time 标准化 10 data1['Time'] = std.fit_transform(data1[['Time']]) 11 12 data1.tail()

4.3 特征选择
1 # 筛选条件 2 cond_0 = data1['Class'] == 0 3 cond_1 = data1['Class'] == 1 4 5 # 根据条件绘制各特征的直方图(可以观察类别区分是否明显,重合度较大的特征可以选择删除) 6 plt.figure(figsize=(9,28*6)) 7 8 for i in range(1,29): 9 ax = plt.subplot(28,1,i) 10 11 data['V%d'%i][cond_0].plot(kind='hist',bins=500,density=True,ax=ax) 12 data['V%d'%i][cond_1].plot(kind='hist',bins=50,density=True,ax=ax) 13 14 ax.set_title('V%d'%i)

上图是不同特征在信用卡正常和信用卡被盗刷的不同分布情况,我们选择在不同信用卡状态下的分布有明显区别的特征,重合度较高的特征选择剔除。
1 # 观察上图发现特征V5,V6,V13,V15,V19,V20,V22,V23,V24,V25,V26,V27,V28类别重合度较高,剔除这几个特征 2 droplabels = ['V5','V6','V13','V15','V19','V20','V22','V23','V24','V25','V26','V27','V28'] 3 4 data1.drop(droplabels,axis=1,inplace=True)
4.4 对特征重要性进行排序,进一步减少特征(这里用的是梯度提升树作为基模型)
1 gdbt = GradientBoostingClassifier() 2 3 # 数据 4 X = data1.iloc[:,:-1] 5 # 目标值 6 y = data1['Class'] 7 8 # 训练 9 gdbt.fit(X,y) 10 11 12 argsort = gdbt.feature_importances_.argsort()[::-1] 13 argsort
# 绘图查看特征重要性排名 plt.figure(figsize=(9,6)) plt.bar(np.arange(17),gdbt.feature_importances_[argsort]) _ = plt.xticks(np.arange(17),X.columns[argsort])
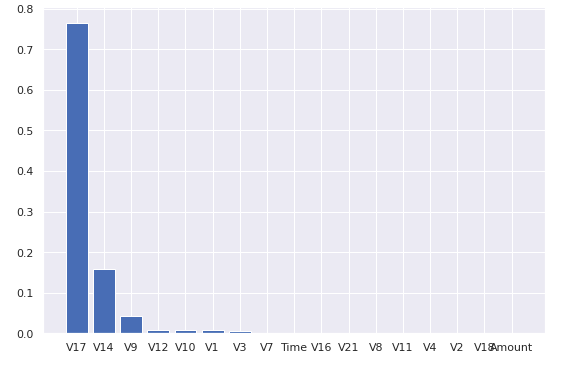
计算特征两两之间的相关性
1 # Compute pairwise correlation of columns 计算特征两两之间的相关性 2 corr = data1.corr().loc[['Class']] # loc[['Class']] --- 将 series 转换为 dataframe 3 corr

结合上图以及特征之间的相关性,剔除 Time,V8,V21,Amount几个特征
1 droplabels = ['Time','V8','V21','Amount'] 2 3 data1.drop(droplabels,axis=1,inplace=True) 4 5 data1.tail()

5. 模型训练
处理样本不均衡问题:
目标变量“Class”正常和被盗刷两种类别的数量差别较大,会对模型学习造成困扰。举例来说,假如有100个样本,其中只有1个是被盗刷样本,
其余99个全为正常样本,那么模型只要制定一个简单的方法,即判断所有样本均为正常样本,就能轻松达到99%的准确率。而这个分类器的
决策对我们的风险控制毫无意义。因此,在将数据带入模型训练之前,我们必须先解决样本不均衡的问题。现对该业务场景总结如下:
1. 过采样(Oversampling):增加正样本使得正负样本数量接近,然后再进行学习;
2. 欠采样(Undersampling):去除一些负样本使得正负样本数量接近,然后再进行学习。
本次采用过采样,具体操作:使用SMOTE(Synthetic Minority Oversampling Technique)。5.1 解决样本不均衡问题(SMOTE过采样)
1 smote = SMOTE() 2 3 X_smote,y_smote = smote.fit_resample(X,y) 4 5 display(X.shape,X_smote.shape) 6 7 ''' 8 (284807, 17) 9 (568630, 17) 10 '''
1 (y_smote == 0).sum() 2 3 ''' 4 284315 5 ''' 6 7 (y_smote == 1).sum() 8 9 ''' 10 284315 11 '''
1 fig,ax=plt.subplots(1,2,figsize=(12,8)) 2 sns.set(style="darkgrid") 3 4 data1["Class"].value_counts().plot(kind="pie",ax=ax[0],fontsize=23,autopct='%1.2f%%') 5 ax[0].set_title("SMOTE采样之前的频率分布饼图") 6 pd.Series(y_smote).value_counts().plot(kind="pie",ax=ax[1],fontsize=23,autopct='%1.2f%%')#长度为1,保留百分号前面的2个小数点 7 ax[1].set_title("SMOTE采样之后的频率分布饼图") 8 ax[1].set_ylabel("Class") 9 plt.savefig("./smote.jpg")
5.2 自定义可视化函数
1 # for 循环 2 import itertools 3 # 画图方法 4 # 绘制真实值和预测值对比情况 5 def plot_confusion_matrix(cm, classes, 6 title='Confusion matrix', 7 cmap=plt.cm.Blues): 8 """ 9 This function prints and plots the confusion matrix. 10 """ 11 plt.imshow(cm, interpolation='nearest', cmap=cmap) 12 plt.title(title) 13 # plt.colorbar(shrink = 0.5) 14 tick_marks = np.arange(len(classes)) 15 plt.xticks(tick_marks, classes, rotation=0) 16 plt.yticks(tick_marks, classes) 17 18 threshold = cm.max() / 2. 19 for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])): 20 plt.text(j, i, cm[i, j], 21 horizontalalignment="center", 22 color="white" if cm[i, j] > threshold else "black")#若对应格子上面的数量不超过阈值则,上面的字体为白色,为了方便查看 23 24 plt.tight_layout() 25 plt.ylabel('True label') 26 plt.xlabel('Predicted label')
5.3 建模训练预测
1 X_train,X_test,y_train,y_test = train_test_split(X_smote,y_smote,test_size=0.2) # 数据分割 2 3 lg = LogisticRegression() # 建模(逻辑回归) 4 5 lg.fit(X_train,y_train) # 训练 6 7 lg.score(X_test,y_test) # 预测
0.9412535392082725
lg.predict_proba(X_test) # 二分类则得到[(px1,px2)] 分别表示预测为0的概率和预测为1的概率

1 y_ = lg.predict(X_test) 2 y_ 3 4 5 array([1, 0, 0, ..., 0, 1, 0])
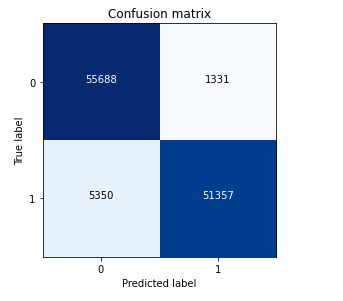
求得查全率 Recall rate
1 # 混淆矩阵,使用自定义绘图函数绘图 2 cm = confusion_matrix(y_test,y_) # 生成混淆矩阵 3 np.set_printoptions(precision=2)#精确到两位小数点 4 5 # 绘图 6 class_names = [0,1] 7 plt.figure(figsize=(6,4)) 8 plt.subplot(1,1,1) 9 plot_confusion_matrix(cm,classes=class_names, 10 title='logit_Confusion matrix,recall is {:.4f}'.format(cm[1,1]/cm[1].sum())) 11 12 plt.savefig('./逻辑回归.jpg',dpi=600)
6. 模型优化与评估
6.1.1 利用GridSearchCV进行交叉验证和模型参数自动调优
1 lg = LogisticRegression() 2 3 clf = GridSearchCV(lg,param_grid={'C':[0.1,0.2,0.4,0.6,1.0,10,100]}) 4 5 clf.fit(X_train,y_train) 6 7 display(clf.best_score_,clf.best_params_) 8 9 10 ''' 11 0.9401236290922194 12 {'C': 100} 13 '''
1 prob_ = clf.predict_proba(X_test)[:,-1]
6.1.2 结果可视化,对比逻辑回归和GridSearchCV结果
1 # GridSearchCV 2 y_clf = clf.predict(X_test) 3 cm_clf = confusion_matrix(y_test,y_clf) 4 plot_confusion_matrix(cm_clf,classes=[0,1])
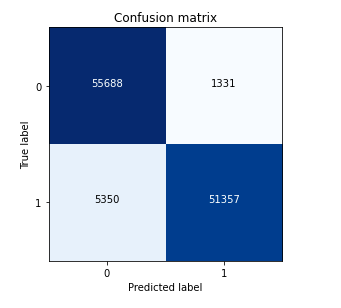
1 # 逻辑回归 2 cm = confusion_matrix(y_test,y_) 3 plot_confusion_matrix(cm,classes=[0,1])

6.2 模型评估
解决不同的问题,通常需要不同的指标来度量模型的性能。例如我们希望用算法来预测癌症是否是恶性的,假设100个病人中有5个病人的癌症是恶性, 对于医生来说,尽可能提高模型的查全率(recall)比提高查准率(precision)更为重要,因为站在病人的角度,发生漏发现癌症为恶性比发生误 判为癌症是恶性更为严重。
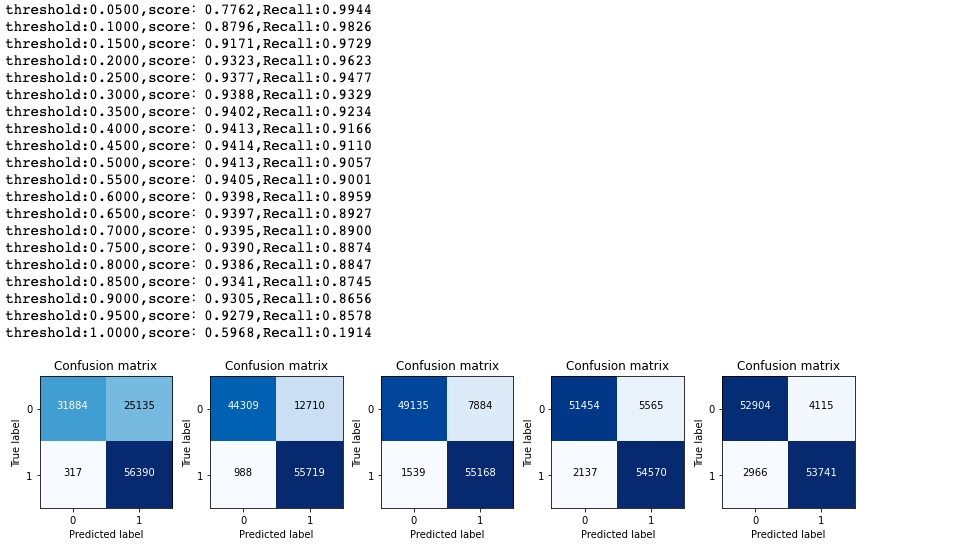
考虑设置阈值,来调整预测被盗刷的概率,依次来调整模型的查全率(Recall)
1 # 设置阈值 2 threshold = np.arange(0.05,1.05,0.05) 3 threshold 4 5 6 ''' 7 array([0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 , 0.55, 8 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ]) 9 '''
1 plt.figure(figsize=(12,20)) 2 3 recall = [] 4 5 accuracy = [] 6 7 for i,t in enumerate(threshold): 8 9 y_ = (prob_ >= t).astype(np.int8) 10 11 # y_test 12 cm = confusion_matrix(y_test,y_) 13 print('threshold:%0.4f,score:%0.4f,Recall:%0.4f'%(t,(cm[0,0] + cm[1,1])/cm.sum(),cm[1,1]/cm[1].sum())) 14 15 recall.append(cm[1,1]/cm[1].sum()) 16 accuracy.append((cm[0,0] + cm[1,1])/cm.sum()) 17 plt.subplot(5,5,i+1) 18 plot_confusion_matrix(cm,classes=[0,1])


7. 趋势图
1 plt.plot(threshold,recall,color = 'green') 2 3 plt.plot(threshold,accuracy,color = 'red') 4 5 plt.legend()
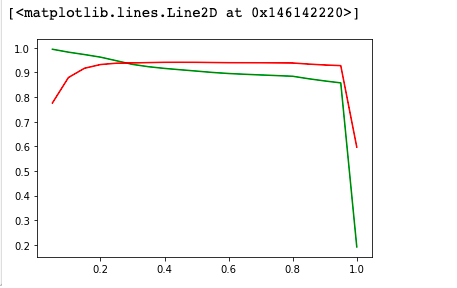
由上图所见,随着阈值逐渐变大,Recall rate逐渐变小,AUC值先增后减
8. 找出模型最优的阈值
precision和recall是一组矛盾的变量。从上面混淆矩阵和PRC曲线可以看到,阈值越小,recall值越大,模型能找出信用卡被盗刷的数量也就更多,但换来的代价是误判的数量也较大。随着阈值的提高,recall值逐渐降低,precision值也逐渐提高,误判的数量也随之减少。通过调整模型阈值,控制模型反信用卡欺诈的力度,若想找出更多的信用卡被盗刷就设置较小的阈值,反之,则设置较大的阈值。
实际业务中,阈值的选择取决于公司业务边际利润和边际成本的比较;当模型阈值设置较小的值,确实能找出更多的信用卡被盗刷的持卡人,但随着误判数量增加,不仅加大了贷后团队的工作量,也会降低正常情况误判为信用卡被盗刷客户的消费体验,从而导致客户满意度下降,如果某个模型阈值能让业务的边际利润和边际成本达到平衡时,则该模型的阈值为最优值。当然也有例外的情况,发生金融危机,往往伴随着贷款违约或信用卡被盗刷的几率会增大,而金融机构会更愿意设置小阈值,不惜一切代价守住风险的底线。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号