数据分析项目之:链家二手房数据分析
项目分享目的:在学习完Numpy,Pandas,matplotlib后,熟练运用它们的最好方法就是实践并总结。在下面的分享中,我会将每一步进行分析与代码展示,
希望能对大家有所帮助。
项目名称:链家二手房数据分析
项目概述:本项目主要利用上面提到的三个工具进行数据的处理,从不同的维度对北京各区二手房市场情况进行可视化分析,为后续
数据挖掘建模预测房价打好基础。
数据链接:链接:https://pan.baidu.com/s/1v7MXARXxFdMmniyW7aNuAA 密码:kucd
分析步骤:工具库导入--->数据加载--->数据清洗--->数据可视化分析
导包
# 数据分析三剑客 import numpy as np import seaborn as sns import pandas as pd from pandas import Series,DataFrame import matplotlib.pyplot as plt sns.set_style({'font.sans-serif':['simhei','Arial']}) %matplotlib inline
# 设置忽略警告 import warnings warnings.filterwarnings('ignore')
# 设置全局字体 plt.rcParams['font.sans-serif'] = 'Songti SC' plt.rcParams['axes.unicode_minus'] = False
数据载入
lj_data = pd.read_csv('./lianjia.csv') display(lj_data.head(),lj_data.shape)
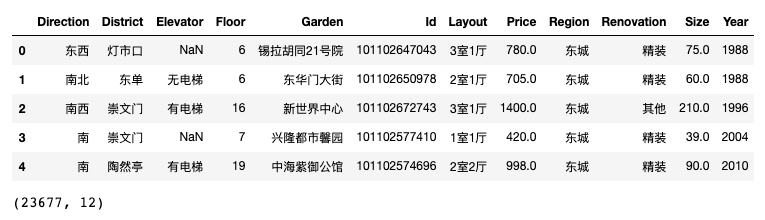
查看数据概况
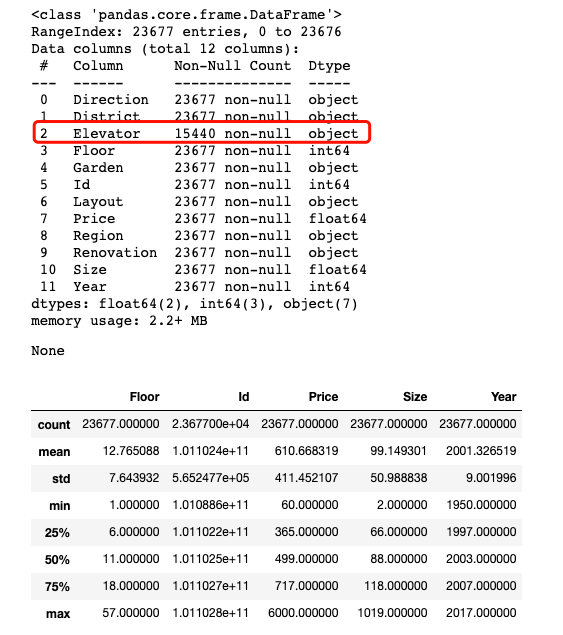
display(lj_data.info(),lj_data.describe()) ''' 通过观察: 1. Elevator列存在严重的数据缺失情况 2. Size列最小值为2平米,最大值为1019平米,跟据常识,初步判断为异常值 '''
添加新属性房屋均价(PerPrice),并且重新排列列位置
''' 观察发现: 1. ID属性对于本次分析没有什么意义,所以可以将其移除; 2. 由于房屋单价分析起来比较方便,简单使用总价/面积即可得到,所以增加一列PerPrice(只用于分析,不是预测特征); 3. 原数据属性的顺序比较杂乱,所以可以调整一下。 '''
# 添加 PerPrice(单位均价) 列 df = lj_data.copy() df['PerPrice'] = (lj_data['Price']/lj_data['Size']).round(2) # 重新摆放列位置 columns = ['Region','District','Garden','Layout','Floor','Year','Size','Elevator', 'Direction','Renovation','PerPrice','Price'] df = pd.DataFrame(df,columns = columns) # 重新查看数据集 df.head(3)

数据可视化分析
1. Region特征分析
对于区域特征,我们可以分析不同区域房价和数量的对比
# 对二手房区域分组,对比二手房数量和每平米房价 df_house_count = df.groupby('Region')['Price'].count().sort_values(ascending = False).to_frame().reset_index() df_house_mean = df.groupby('Region')['PerPrice'].mean().sort_values(ascending = False).to_frame().reset_index() # display(df_house_count.head(2),df_house_mean.head(2))
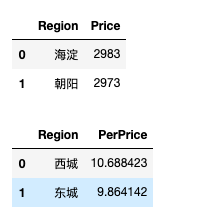
绘图
1 # 创建子视图对象 2 f,[ax1,ax2,ax3] = plt.subplots(3,1,figsize = (20,18)) 3 4 # 设置绘图参数 5 sns.barplot(x='Region',y='PerPrice',palette='Blues_d',data=df_house_mean,ax=ax1) 6 ax1.set_title('北京各区二手房单位平米价格对比',fontsize=15) 7 ax1.set_xlabel('区域') 8 ax1.set_ylabel('单位平米价格') 9 10 sns.barplot(x='Region',y='Price',palette='Greens_d',data=df_house_count,ax=ax2) 11 ax2.set_title('北京各区二手房数量对比',fontsize=15) 12 ax2.set_xlabel('区域') 13 ax2.set_ylabel('数量') 14 15 sns.boxplot(x='Region',y='Price',data=df,ax=ax3) 16 ax3.set_title('北京各区二手房房屋总价',fontsize=15) 17 ax3.set_xlabel('区域') 18 ax3.set_ylabel('房屋总价') 19 20 # 展示 21 plt.show()
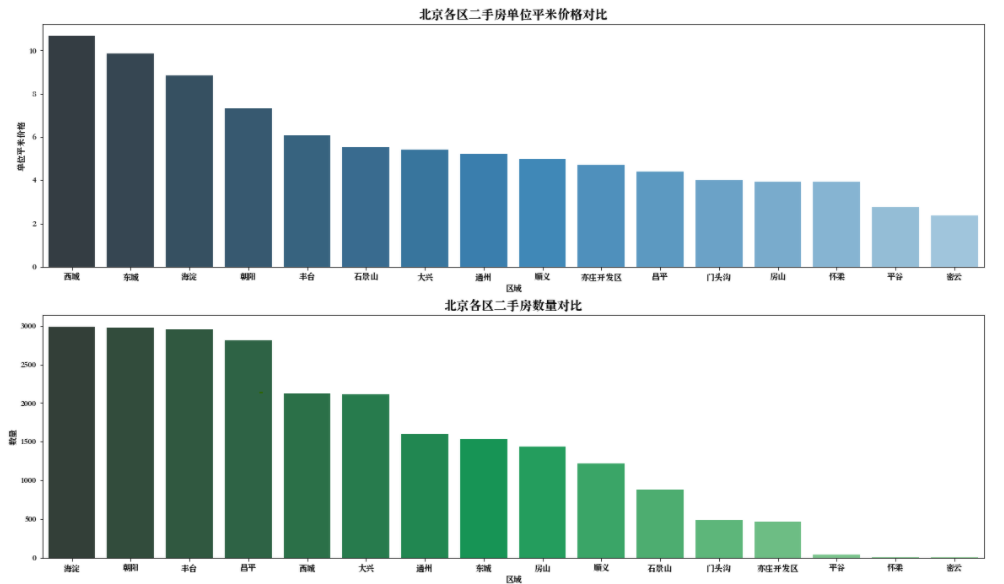

分析报告
可以观察到:
二手房均价:西城区房价最贵均价大约11万/平,因为西城在二环以里,且是热门学区房聚集地。
其次是东城约10万/平,海淀约8.5万/平,其他均低于8万/平。
二手房数量:从数量统计来看,可以看到目前二手房市场比较火热的区域。海淀和朝阳区二手房数量最多,
差不多都接近3000套。然后是丰台区,近几年正在改造建设,有赶超之势。
二手房总价:通过箱型图看到,各大区房屋总价中位数都在1000万以下,而且房屋总价离散值较高,
西城最高达到了6000万,说明房屋价格不是理想的正态分布。2. Size特征分析
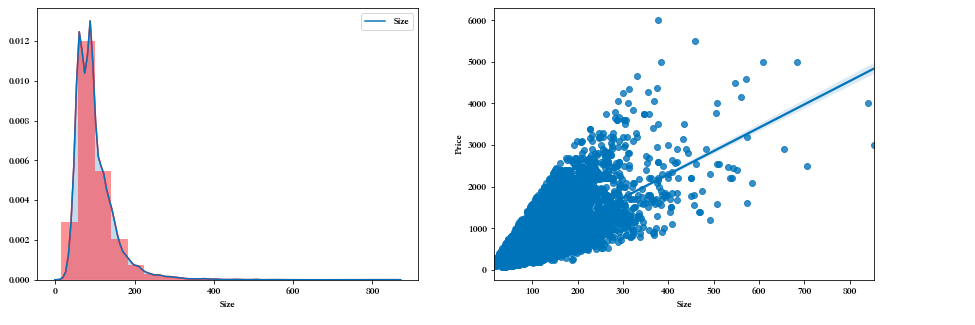
# 创建子视图 f,[ax1,ax2] = plt.subplots(1,2,figsize=(15,5)) # 房屋面积分布情况 sns.distplot(df['Size'],bins=20,ax=ax1,color='r') sns.kdeplot(df['Size'],shade=True,ax=ax1) # 房屋面积和出售价格的关系 sns.regplot(x='Size',y='Price',data=df,ax=ax2) # 展示 plt.show()
注:下面👇的图是后面删除数据后绘制出的结果,这里的代码绘制出的图不一样,请各位留意,无需疑惑,接着往下看即可
分析报告
Size分布:
通过 distplot 和 kdeplot 绘制柱状图观察 Size 特征的分布情况,属于长尾形的分布,
这说明有很多面积很大且超出正常范围的二手房。Size 和 Price 的关系:
通过 regplot 绘制了 Size 和 Price 之间的散点图,发现 Size 特征基本与 Price 呈线性关系,
符合基本常识,即面积越大,价格越高。但是有两组明显的异常点:
1. 面积不到10平米,但是价格超过1000万;
2. 一个点面积超过了1000平米,但是价格很低。
需要查看是什么情况。# 查看异常值 cond = df['Size'] < 10 df[cond]
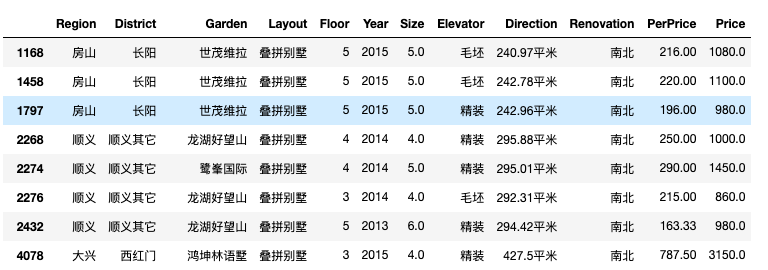

经查看并对比发现这组数据是别墅,出现异常的原因是由于别墅结构比较特殊(无朝向无电梯),字段定义与二手商品房不太一样, 导致爬虫爬取数据错位。
也因为别墅类型二手房不在我们的考虑范围之内,所以将这些数据移除再次观察 Size和 Price关系。
cond1 = df['Size'] > 1000 df[cond1]

经观察发现这个异常点不是普通的民用二手房,很可能是商用写字楼,所以才有 1房间0厅如此大超过1000平的面积,这里选择移除。
# 删除异常数据 df = df[(df['Layout'] != '叠拼别墅') & (df['Size'] < 1000)]
重新可视化后发现基本没有明显异常点了(重新可视化后的效果是最开始展示的图)
Layout特征分析
f,ax = plt.subplots(figsize=(20,20)) sns.countplot(y='Layout',data=df,ax=ax) ax.set_title('房屋户型',fontsize=15) ax.set_xlabel('数量') ax.set_ylabel('户型') plt.show()
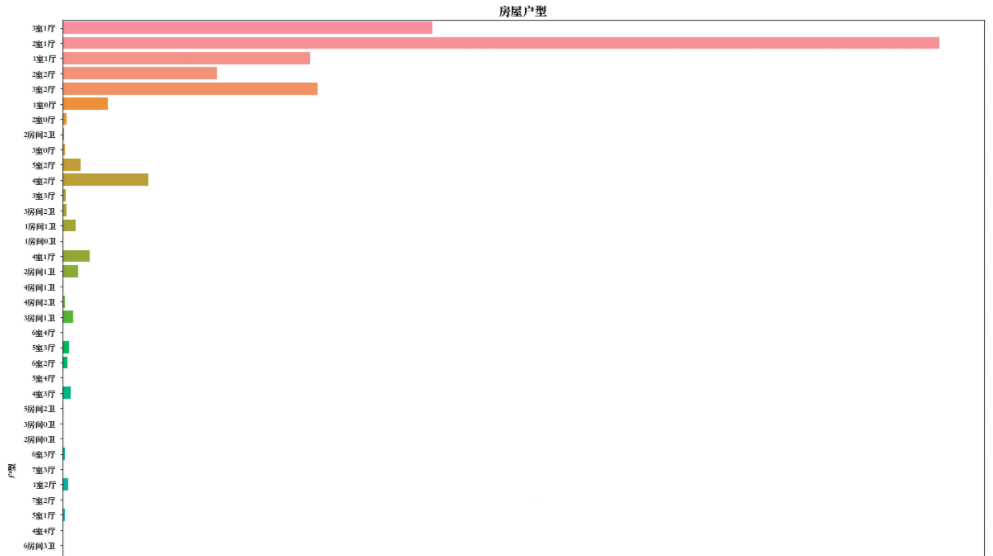
分析报告
通过观察才知道有各种厅室组合搭配,居然还有9室3厅,4室0厅的结构。其中2室1厅占绝大部分,其次室3室1厅,2室2厅,3室2厅。
但是经过仔细观察,特征分类下还有很多不规则的命名,如:2房间1卫,别墅等,没有统一的叫法。这样的特征是肯定不能作为机器学习
模型的数据输入的,需要使用特征工程进行相应的处理。
Renovation特征分析
df['Renovation'].value_counts() ''' 精装 11345 简装 8496 其他 3239 毛坯 576 Name: Renovation, dtype: int64 '''
f,[ax1,ax2,ax3] = plt.subplots(3,1,figsize=(20,20)) sns.countplot(df['Renovation'],ax=ax1) sns.barplot(x='Renovation',y='Price',data=df,ax=ax2) sns.boxplot(x='Renovation',y='Price',data=df,ax=ax3) plt.show()
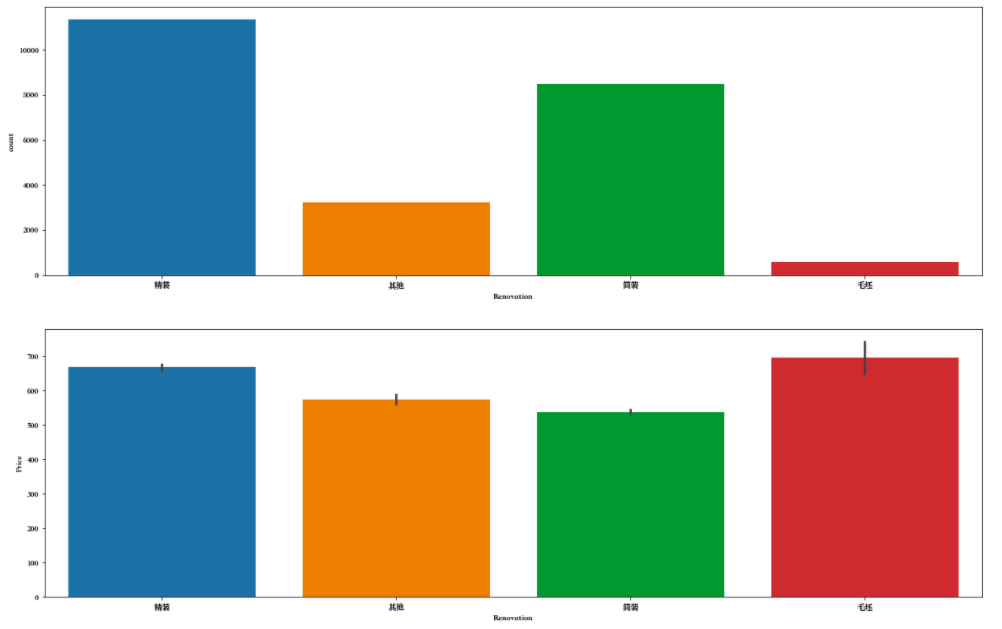
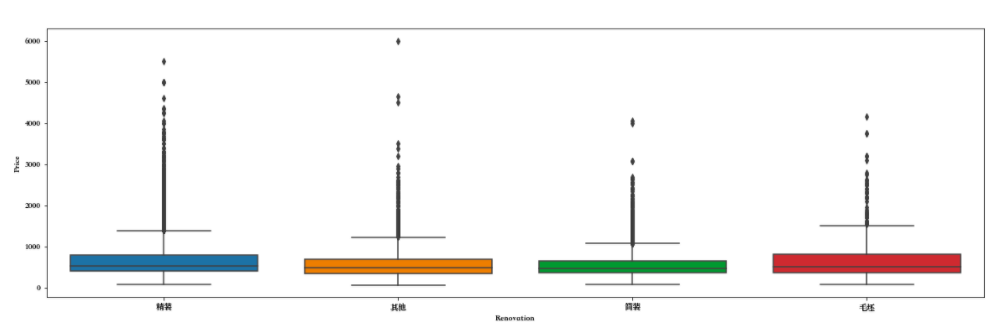
分析报告
观察到,精装修的二手房数量最多,简装其次,这也符合我们的常识。对于价格来说,毛坯型价格最高,精装其次。
Elevator特征分析
df.info() ''' <class 'pandas.core.frame.DataFrame'> Int64Index: 23656 entries, 0 to 23676 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 Region 23656 non-null object 1 District 23656 non-null object 2 Garden 23656 non-null object 3 Layout 23656 non-null object 4 Floor 23656 non-null int64 5 Year 23656 non-null int64 6 Size 23656 non-null float64 7 Elevator 15419 non-null object 8 Direction 23656 non-null object 9 Renovation 23656 non-null object 10 PerPrice 23656 non-null float64 11 Price 23656 non-null float64 dtypes: float64(3), int64(2), object(7) memory usage: 3.0+ MB '''
发现存在空值
处理办法:
1. 删除空值
2. 插值:平均值/中位数/线性插值/拉格朗日插值等插值思路:根据楼层 Floor判断有无电梯。6层以上都有电梯,6层及以下无电梯(其实也有缺陷,Floor表示的是 房屋所在楼层,并不代表楼的总层数)
cond = (df['Floor'] > 6) & (df['Elevator'].isnull()) cond1 = (df['Floor'] <= 6) & (df['Elevator'].isnull()) df['Elevator'][cond] = '有电梯' df['Elevator'][cond1] = '无电梯' df.info()
# 创建子视图 f,[ax1,ax2] = plt.subplots(1,2,figsize=(20,5)) sns.countplot(df['Elevator'],ax=ax1) ax1.set_title('有无电梯数量对比',fontsize=15) ax1.set_xlabel('是否有电梯') ax1.set_ylabel('数量') sns.barplot(x='Elevator',y='Price',data=df,ax=ax2) ax2.set_title('有无电梯房价对比',fontsize=15) ax2.set_xlabel('是否有电梯') ax2.set_ylabel('总价') plt.show()
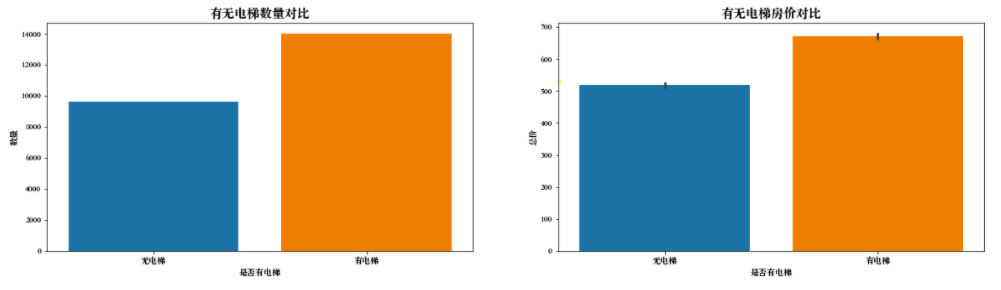
分析报告
根据结果观察到,有电梯的二手房数量居多一些,毕竟在北京,人口数量庞大,高层对于土地的利用率高,高层自然也会配置电梯。相应的,电梯二手房价格较高,
因为电梯前期安装费和后期维修费已经包含在内(这个价格比较只是一个平均的概念,比如无电梯的6层豪华小区当然价格更高)。
Year特征分析
grid = sns.FacetGrid(df,row='Elevator',col='Renovation',palette='seismic',size=4) grid.map(plt.scatter,'Year','Price') grid.add_legend()
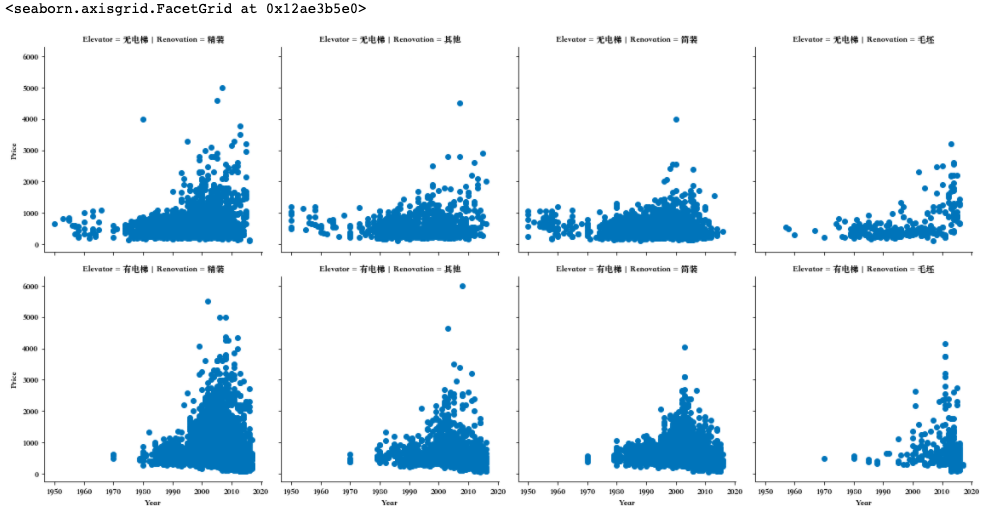
分析报告
在 Renovation和 Elevator的分类条件下,使用 FacetGrid 分析 Year特征,观察结果如下:
1. 整个二手房房价趋势随着时间增长而增长;
2. 2000年后建造的房屋二手房房价相较于2000年以前有很明显的价格上涨;
3. 1980年之前几乎不存在有电梯的二手房数据,说明1980年以前还没有大量安装电梯;
4. 1980年之前的无电梯二手房中,简装占大多数,精装反而很少。Floor特征分析
# 创建子视图 f,ax = plt.subplots(figsize=(20,5)) sns.countplot(df['Floor'],ax=ax) ax.set_title('房屋楼层',fontsize=15) ax.set_xlabel('楼层') ax.set_ylabel('数量') plt.show()
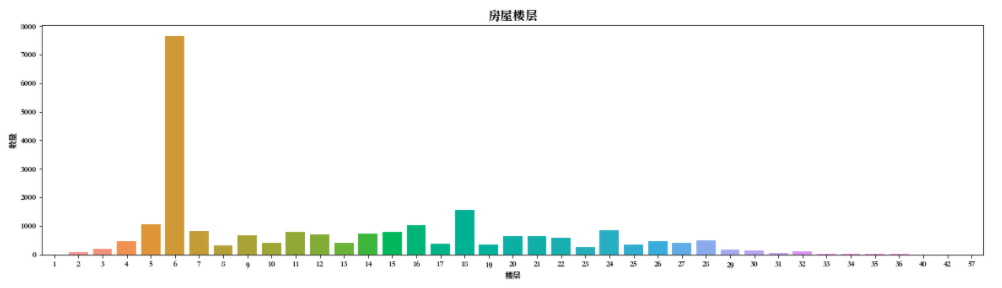
分析报告
可以看到,6层二手房数量最多,但单独的楼层特征没什么意义,因为每个小区的住房总楼层不一样,我们需要知道楼层的相对意义。 另外,楼层与文化也有很重要的联系。
比如中国常说七上八下,七层可能更受欢迎,房价也贵,而一般不会有4层或18层。当然正常 情况下中间楼层是比较受欢迎的,价格相对较高,底层和顶层受欢迎度较低,
价格也相对较低。所以楼层是一个非常复杂的特征,对房价影响也比较大。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号