数据分析项目之:用户消费行为分析
项目分享原因:在学习完Numpy,Pandas,matplotlib后,熟练运用它们的最好方法就是实践并总结。在下面的分享中,我会将每一步进行分析与代码展示,
希望能对大家有所帮助。
项目名称:CD用户消费行为分析
项目概述:本项目主要利用上面提到的三个工具进行数据的处理,来分析用户消费行为。数据来源与CDNow网站的用户购买明细。
数据链接:链接:https://pan.baidu.com/s/1Cs36oeH0xgblzULmgX75-g 密码:oeam
分析步骤:
第一部分:数据清洗
1. 数据类型的转换
2. 空值处理
3. 异常值处理
第二部分:按月数据分析
1. 每月的消费总金额
2. 每月的消费次数
3. 每月的产品购买量
4. 每月的消费人数
第三部分:用户个体消费数据分析
1. 用户消费金额和消费次数的描述统计
2. 用户消费金额和消费次数的散点图
3. 用户消费金额的分布图
4. 用户消费次数的分布图
5. 用户累计消费金额的占比
第四部分:用户消费行为分析
1. 用户第一次消费时间
2. 用户最后一次消费时间
3. 新老客户消费比
4. 用户分层
5. 用户购买周期
6. 用户生命周期
导包


1 import numpy as np 2 import pandas as pd 3 from pandas import Series,DataFrame 4 import matplotlib.pyplot as plt 5 %matplotlib inline 6 from datetime import datetime
数据载入
1 # 因为原始数据中不包含表头,在这里定义好赋值 2 columns = ['user_id','order_dt','order_products','order_amount'] 3 4 # 参数 sep='\s+',用于匹配任意空白符 5 data = pd.read_csv('./CDNOW_master.txt',names=columns,sep='\s+')
''' 字段含义: user_id:用户ID order_dt:购买日期 order_products:购买产品数 order_amount:购买金额 '''
'''
消费行业或者是电商行业一般是通过订单数、订单额、购买日期,用户ID这四个字段来分析的,基本上这四个字段就能缑进行很丰富的分析。
'''
查看数据概况
display(data.head(),data.info()) ''' 结果如下: <class 'pandas.core.frame.DataFrame'> RangeIndex: 69659 entries, 0 to 69658 Data columns (total 4 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 user_id 69659 non-null int64 1 order_dt 69659 non-null int64 2 order_products 69659 non-null int64 3 order_amount 69659 non-null float64 dtypes: float64(1), int64(3) memory usage: 2.1 MB user_id order_dt order_products order_amount 0 1 19970101 1 11.77 1 2 19970112 1 12.00 2 2 19970112 5 77.00 3 3 19970102 2 20.76 4 3 19970330 2 20.76 '''
分析:
1. 数据完整,没有空数据
2. order_dt是 int类型,需要将其转换为时间类型
3. 用户可能在同一天内重复购买(如:ID为2的顾客在1月12日这一天内购买了两次)
4. 因为后面要按月分析,所以需要添加一列 month
数据清洗
1 # order_dt 数据类型转换 2 3 df = data.copy() 4 # format='%Y%m%d' 这里要指明格式,否则可能出错 5 df['order_dt'] = pd.to_datetime(df['order_dt'],format='%Y%m%d') 6 7 # 增加一列 month 8 df['month'] = df['order_dt'].values.astype('datetime64[M]') 9 10 display(df.head(),df.info(),df.describe()) 11 12 ''' 13 结果如下: 14 <class 'pandas.core.frame.DataFrame'> 15 RangeIndex: 69659 entries, 0 to 69658 16 Data columns (total 5 columns): 17 # Column Non-Null Count Dtype 18 --- ------ -------------- ----- 19 0 user_id 69659 non-null int64 20 1 order_dt 69659 non-null datetime64[ns] 21 2 order_products 69659 non-null int64 22 3 order_amount 69659 non-null float64 23 4 month 69659 non-null datetime64[ns] 24 dtypes: datetime64[ns](2), float64(1), int64(2) 25 memory usage: 2.7 MB 26 user_id order_dt order_products order_amount month 27 0 1 1997-01-01 1 11.77 1997-01-01 28 1 2 1997-01-12 1 12.00 1997-01-01 29 2 2 1997-01-12 5 77.00 1997-01-01 30 3 3 1997-01-02 2 20.76 1997-01-01 31 4 3 1997-03-30 2 20.76 1997-03-01 32 user_id order_products order_amount 33 count 69659.000000 69659.000000 69659.000000 34 mean 11470.854592 2.410040 35.893648 35 std 6819.904848 2.333924 36.281942 36 min 1.000000 1.000000 0.000000 37 25% 5506.000000 1.000000 14.490000 38 50% 11410.000000 2.000000 25.980000 39 75% 17273.000000 3.000000 43.700000 40 max 23570.000000 99.000000 1286.010000 41 '''
分析:
describe()是描述统计:
1. 大部分的订单只消费了少量的商品(平均2.4),有一定的极值干扰
2. 用户的消费金额比较稳定,平均消费在35.8元,中位数在25.9元,有一定的极值干扰。
3. 用户平均每笔订单购买2.4个商品,标准差在2.3,稍具波动性。中位数2个商品,75分位数3个商品,
说明绝大部分订单的购买量都不多。最大值在99个,数字比较高。购买金额的情况差不多,大部分
订单集中在小额
4. 一般而言,消费类的数据分布都是长尾形。大部分用户都是小额,然而小部分用户贡献了收入的大头,
俗称二八。
第二部分:按月数据分析
分析方向:用户、订单、消费趋势
消费趋势的分析
1 # 查看一下df的列,方便操作 2 df.columns
1. 每月的消费总金额
# 根据 month分组统计购买金额总和 order_amt_mon = df.groupby('month')['order_amount'].sum() order_amt_mon.head() ''' 结果: month 1997-01-01 299060.17 1997-02-01 379590.03 1997-03-01 393155.27 1997-04-01 142824.49 1997-05-01 107933.30 Name: order_amount, dtype: float64 '''
# 绘图 order_amt_mon.plot(c='red')

分析:
可以看到,97年1,2,3月销量很高,每月平局约3.6万,后期销量趋于平稳,每月在1万左右波动
2. 每月的消费次数
df.groupby('month')['user_id'].count().plot(c='red')
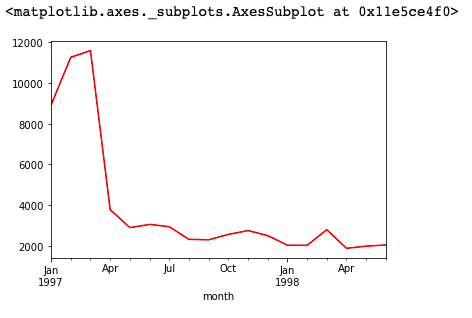
分析:前三个月平均消费订单在1万左右,后续月份趋于平稳,约在2500单每月
3. 每月的产品购买量
df.groupby('month')['order_products'].sum().plot(c='red',figsize=(9,6))

分析:前3个月产品购买数量平均在24000左右,后期下降趋于平稳,约6000每月。原因猜想:
1.用户层面,早期用户中有异常值;
2. 公司层面,在搞促销等。因为只有销售数据,所以暂时无法判断具体原因。
4. 每月的消费人数(去重)
# 去重的原因:一个人可能在一个月内多次消费 df.groupby('month')['user_id'].nunique().plot()
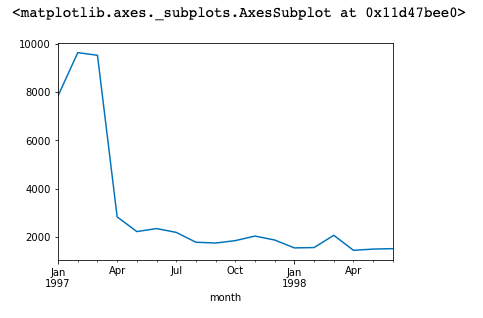
分析:每个月的消费人数小于每月的消费次数,但是区别不大。前3个月月均消费人数在9000左右,后续月均2000
不到,一样是前期消费人多,后期平稳的趋势。
5. 将上述趋势分析用透视表展示(pivot_table)
df.pivot_table(index='month', values=['user_id','order_amount','order_products'], aggfunc={'user_id':'count','order_amount':'sum','order_products':'sum'})
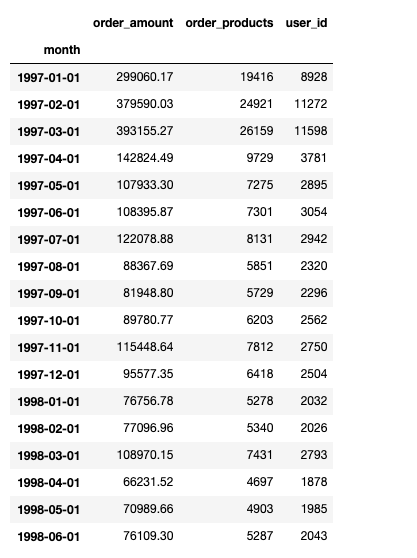
分析:(解决一个需求可能会有很多种方法,具体看哪个更方便,更简单)
数据透视表是更简单的方法,有了透视表,用里面的数据绘图也是狠方便的。
第三部分:用户个体消费数据分析
上面是通过维度月,来看总体趋势。下面对个体进行分析,看消费能力如何。 大致分为以下五个方向:
1. 用户消费金额和消费次数的描述统计;
2. 用户消费金额和消费次数的散点图;
3. 用户消费金额的分布图(二八法则);
4. 用户消费次数的分布图;
5. 用户累计消费金额的占比(百分之多少的用户占了百分之多少的消费额)
1. 用户消费金额和消费次数的描述统计
1 group_user = df.groupby('user_id') 2 3 group_user.sum().describe()
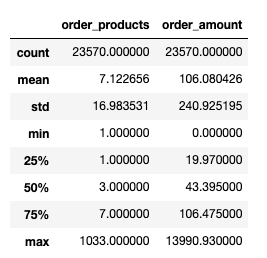
分析:
1. 从用户角度看,每位用户平均购买7件商品,最多的用户买了1033件。
2. 用户平均消费额(客单价)100元,标准差是240,结合分位数和最大值看,平均值和75分位接近。
结论:肯定存在小部分高额消费用户,小部分的用户占了消费的大头,符合二八法则。2.用户消费金额和消费次数的散点图
group_user.sum().query('order_amount < 4000').plot(kind='scatter',x='order_amount',y='order_products')
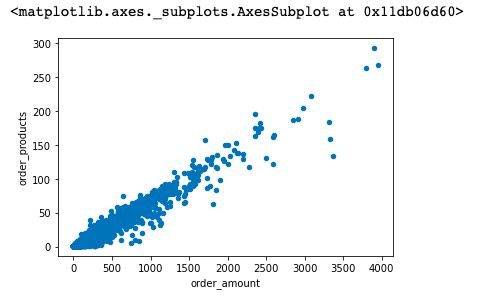
分析:
通过绘制用户的散点图,用户比较健康而且规律性很强。因为这是CD网站的销售数据,商品比较单一,金额和商品质量的关系 也呈线性,没几个离群点。
3. 用户消费金额的分布图(二八法则)
group_user.sum()['order_amount'].plot(kind='hist',bins=20)
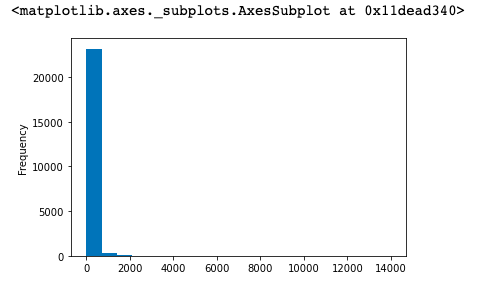
分析:
1. 从直方图可知,大部分用户的消费能力确实不高,绝大部分集中在很低的消费档次。高消费用户在图上几乎看不到。这也确实
符合消费行为的行业规律。
2. 虽然有极值干扰了我们的数据,但是大部分用户还是集中在比较低的消费档次。4. 用户消费次数的分布图(二八法则)
group_user.sum().query('order_products < 100')['order_products'].plot(kind='hist',bins=40)
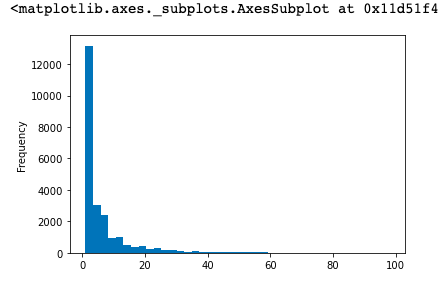
5. 用户累计消费金额的占比(百分之多少的用户占了百分之多少的消费额)
1 # cumsum() 滚动累加求和 2 user_cumsum = (group_user.sum().sort_values('order_amount').cumsum())/2500315.63 3 user_cumsum
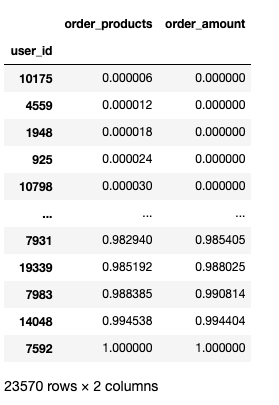
user_cumsum.reset_index().order_amount.plot()
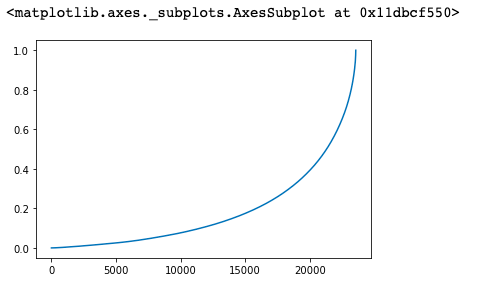
分析:
按用户消费金额进行升序排序,由图可知50%的用户仅贡献了15%的销售额。而排名前5000的用户就贡献了60%的消费额
也就是说,只要维护好这5000个客户,就可以完成业绩KPI的60%,如果能把5000个用户运营的更好就可以占比70%-80%甚至更高。
第四部分:用户消费行为分析
用户第一次消费(首购)
在很多行业中首购是一个很重要的维度,它和渠道信息息息相关,尤其针对客单价比较高客户留存率比较低的行业,
第一次客户从哪里来可以拓展出很多运营方式。用户最后一次消费
新老客户消费比
多少客户仅消费了一次
每月新客占比用户分层
RFM
新、老、活跃、流失用户购买周期(按订单)
用户消费周期描述
用户消费周期分布用户生命周期(按第一次&最后一次消费)
用户生命周期描述
用户生命周期分布
1.用户第一次消费(首购)
# 求月份的最小值,即用户消费行为中的第一次消费时间 group_user = df.groupby('user_id') group_user['month'].min().value_counts() # 通过统计结果发现:所有用户第一次消费都集中在前3个月 df['user_id'].unique().size---查看用户总数 ''' 结果: 1997-02-01 8476 1997-01-01 7846 1997-03-01 7248 Name: month, dtype: int64 '''
2. 用户最后一次消费
group_user['month'].max().value_counts() ''' 结果: 1997-02-01 4912 1997-03-01 4478 1997-01-01 4192 1998-06-01 1506 1998-05-01 1042 1998-03-01 993 1998-04-01 769 1997-04-01 677 1997-12-01 620 1997-11-01 609 1998-02-01 550 1998-01-01 514 1997-06-01 499 1997-07-01 493 1997-05-01 480 1997-10-01 455 1997-09-01 397 1997-08-01 384 Name: month, dtype: int64 '''
group_user['order_dt'].max().value_counts().plot()
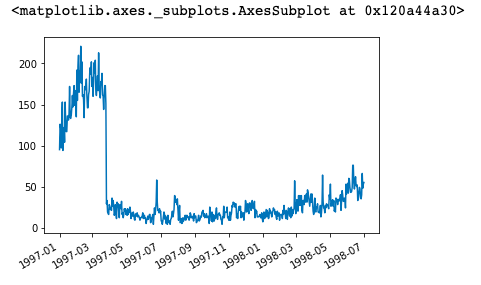
group_user['order_dt'].agg(['min','max'])
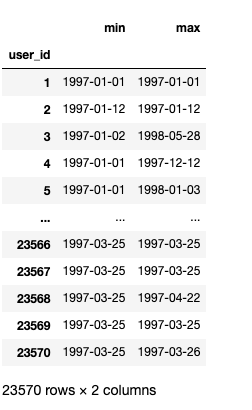
分析:
观察用户最后一次购买时间发现,用户最后一次消费比第一次消费分布广,大部分最后一次消费集中在前三个月,
说明很多客户购买一次后就不再购买。随着时间的增长,最后一次购买数也在递增,消费呈现流失上升的情况,用户忠诚度在慢慢下降。3. 新老客户的消费比
user_life = group_user['order_dt'].agg(['min','max']) user_life.head()
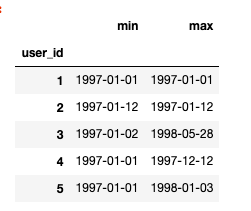
分析:user_id为1的用户第一次消费时间和最后一次消费时间相同,说明他只消费了一次
4. 用户的购买周期
(user_life['min'] == user_life['max']).value_counts() '''
结果:
True 12054 False 11516 dtype: int64 '''
分析:可以看到,有一半的用户只消费了一次
5. 用户分层(使用透视表)
1 rfm = df.pivot_table(index='user_id', 2 values=['order_products','order_amount','order_dt'], 3 aggfunc={'order_products':'sum','order_amount':'sum','order_dt':'max'}) 4 5 rfm.head() 6 7 # order_products--求消费产品总数、order_amount---求消费总金额、order_dt--求最近一次消费时间
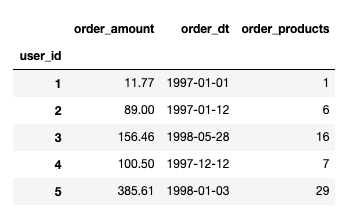
1 # rfm 距今天数 增加一列 2 3 #-(rfm.order_dt - rfm.order_dt.max())结果为时间类型,将时间格式转化为整数或者浮点数的形式, 4 # 可以除以单位‘D’,也可以用astype转化 5 rfm['R'] = -(rfm['order_dt'] - rfm['order_dt'].max()) / np.timedelta64(1,'D') 6 7 rfm.rename(columns ={'order_products':'F', 'order_amount':'M'},inplace = True ) 8 9 rfm.head()
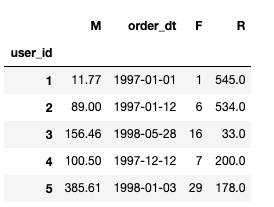
分析:
R表示客户最近一次交易的时间间隔,M表示客户在最近一段时间内交易的金额。F表示客户在最近一段时间内交易的次数。
F值越大,表示客户交易越频繁,反之则表示客户交易不够活跃。M表示客户在最近一段时间内交易的金额。
M值越大,表示客户价值越高,反之则表示客户价值越低。5. 用户分层二:RFM
1 def rfm_func(x): 2 level = x.apply(lambda x : '1' if x >= 0 else '0') 3 label = level.R + level.F + level.M 4 5 dict = { 6 '111':'重要价值客户', 7 '011':'重要保持客户', 8 '101':'重要挽留客户', 9 '001':'重要发展客户', 10 '110':'一般价值客户', 11 '010':'一般保持客户', 12 '100':'一般挽留客户', 13 '000':'一般发展客户' 14 } 15 16 result = dict[label] 17 return result 18 19 # 用户分层,这里使用平均数 20 rfm['label'] = rfm[['R','F','M']].apply(lambda x : x - x.mean()).apply(rfm_func,axis=1) 21 22 rfm.head()
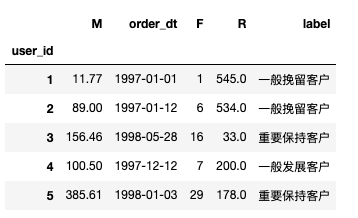
5. 用户分层三:求和
rfm.groupby('label').sum()

分析:M表示不同层次客户累计消费金额,重要保持客户最高
5. 用户分层四:计数
rfm.groupby('label').count()

分析:不同层次用户的消费人数,之前重要保持客户的累计消费金额最高,这里人数排第2,但与一般挽留用户人数差距比较大
5. 用户分层五:给不同层次客户用颜色区分设置
1 rfm.loc[rfm.label == '重要价值客户','color'] = 'g' 2 3 # ~:表示求非 4 rfm.loc[~(rfm.label == '重要价值客户'),'color'] = 'r' 5 6 rfm.plot('F','R',kind='scatter',c=rfm.color)
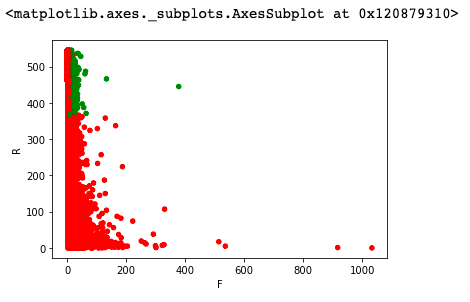
分析:
1. 从RFM分层可知,大部分用户为重要保持客户,但是这是由于极值的影响,所以RFM的划分应该尽量以业务为准。
尽量用小部分的用户覆盖大部分的额度,不能为了数据好看划分等级。
2. RFM是人工使用象限法把数据划分为几个立方体,立方体对应相应的标签,我们可以把标签运用到业务层面上。
比如重要保持客户贡献金额最多159203.62,我们如何与业务方配合把数据提高或者维护;而重要发展客户
和重要挽留客户他们有一段时间没消费了,我们如何把他们拉回来。5. 用户分层六:用户生命周期
1 pivoted_counts = df.pivot_table(index='user_id', 2 columns='month', 3 values='order_dt', 4 aggfunc='count', 5 fill_value=0) 6 pivoted_counts.head()
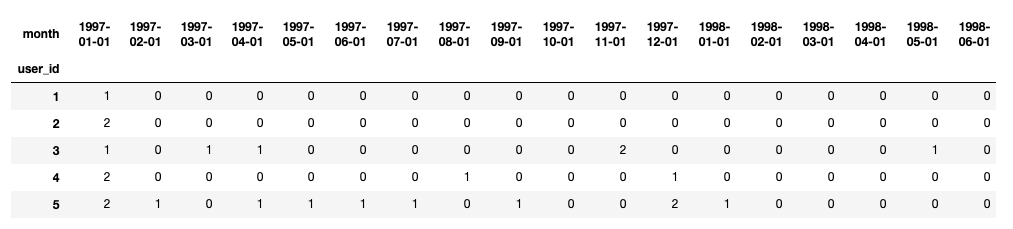
分析:
用户每个月的消费次数,对于生命周期的划分只需要知道用户本月是否消费,消费次数在这里并不重要,需要将模型进行简化注:使用数据透视表时,要明确获得什么结果。
# 简化 df_purchase = pivoted_counts.applymap(lambda x: 1 if x>0 else 0) df_purchase.tail()
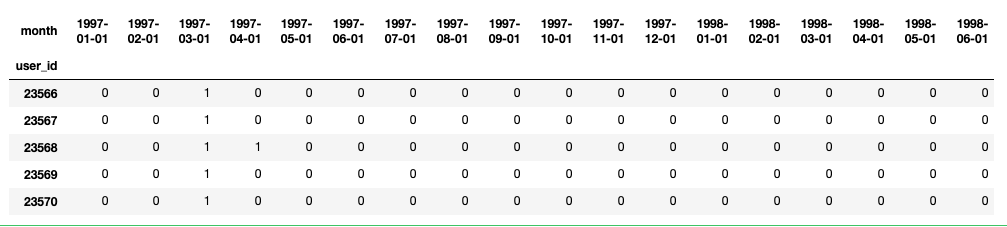
分析:对于尾部数据,user_id 2w+的数据是有一些问题的,因为从实际业务场景来说,一月二月他们都没有注册,三月份才是
第一次消费。这里需要进行判断将第一次消费作为生命周期的起始,不能从一月份开始就粗略的计算。
1 # 用户生命周期状态变化 2 3 def active_status(data): 4 5 ur = 'unreg' #未注册 6 ua = 'unactive' #不活跃 7 n = 'new' #新用户 8 a = 'active' #活跃 9 r = 'return' #回流用户:上个月不活跃,这个月活跃 10 status = [] 11 for i in range(18): 12 #若本月没有消费 13 if data[i] == 0: 14 if len(status) > 0: 15 if n not in status: 16 status.append(ur) 17 else: 18 status.append(ua) 19 else: 20 status.append(ur) 21 22 #若本月消费 23 else: 24 if len(status) == 0: 25 status.append(n) 26 else: 27 if n not in status: 28 status.append(n) 29 elif status[-1] == ua: 30 status.append(r) 31 else: 32 status.append(a) 33 # 不能直接返回 status,否则会失去表头 ---重点 34 return pd.Series(status, index = df_purchase.columns) 35 36 pivoted_status = df_purchase.apply(active_status,axis = 1) 37 38 pivoted_status.head()
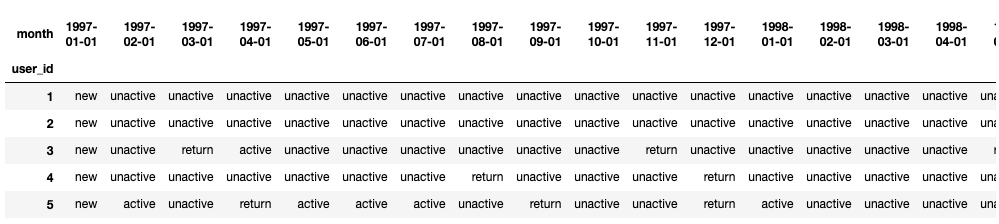
每月不同活跃用户的计数
purchase_status_ct = pivoted_status.replace('unreg',np.NaN).apply(lambda x: pd.value_counts(x)) purchase_status_ct

1 purchase_status_ct.fillna(0,inplace=True) 2 3 # 浮点数转换为整数 4 purchase_status_ct.astype(np.int) 5 6 # 绘面积图 (purchase_status_ct要求一下转置矩阵) 7 purchase_status_ct.T.plot(kind='area')
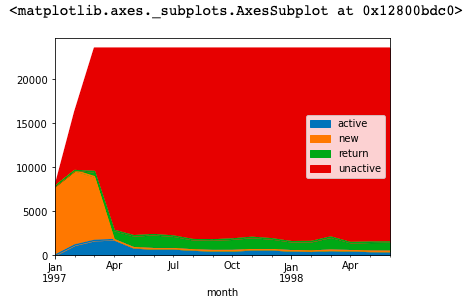
每月不同活跃用户占比
消费用户构成:活跃 + 新增 + 回流
purchase_status_ct.T.apply(lambda x: x/x.sum(),axis=1)

分析报告:
由上表可以看到每月用户的消费状态变化。
1. 活跃用户,持续消费用户对应的是---消费运营质量;
2. 回流用户(上月不消费本月消费)对应的是---唤回运营情况;
3. 不活跃的用户对应的是---用户流失情况。分析结果:流失用户增加,回流用户正在减少。
5. 用户分层七:用户购买周期(按订单)
# 将用户分组后,每个用户的订单购买时间进行错位相减 shift():下一行减上一行的值 order_diff = group_user.apply(lambda x:x.order_dt - x.order_dt.shift()) order_diff.head(10) ''' 结果: user_id 1 0 NaT 2 1 NaT 2 0 days 3 3 NaT 4 87 days 5 3 days 6 227 days 7 10 days 8 184 days 4 9 NaT Name: order_dt, dtype: timedelta64[ns] '''
分析:
1. 可以看到:user_id 1为空值,说明用户只购买过一个订单
2. user_id 2 的用户第一笔订单与第二笔订单在同一天购买用户消费周期分布
(order_diff / np.timedelta64(1,'D')).hist(bins = 20)

分析:
订单周期呈指数分布,用户的平均购买周期是68天,绝大部分用户的购买周期都低于100天。
用户生命周期(第一笔订单时间 & 最后一笔订单时间)
user_life = group_user['order_dt'].agg(['min','max']) user_life.head()

user_life['life_period'] = user_life['max'] - user_life['min'] user_life.head()
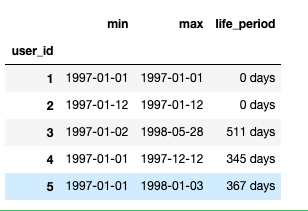
user_life['life_period'].describe() ''' 结果: count 23570 mean 134 days 20:55:36.987696 std 180 days 13:46:43.039788 min 0 days 00:00:00 25% 0 days 00:00:00 50% 0 days 00:00:00 75% 294 days 00:00:00 max 544 days 00:00:00 Name: life_period, dtype: object '''
分析:
可以看到,数据偏移较大,中位数是0天,意味着超过50%的用户生命周期是0天,即只购买了1次。(user_life['life_period'] / np.timedelta64(1,'D')).plot(kind='hist',bins=40)
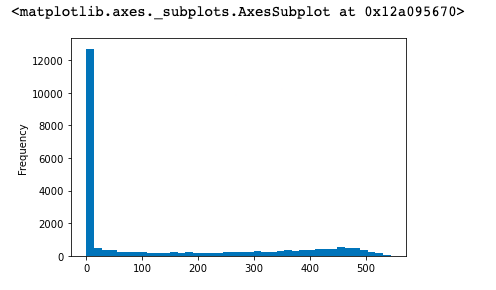
分析:
可以看出,用户生命周期受只购买一次的用户影响比较大(因此可以排除生命周期为0天的用户再观察)# 用户生命周期大于0天的分布图 cond = user_life['life_period'] / np.timedelta64(1,'D') cond[cond>0].hist(bins=40)
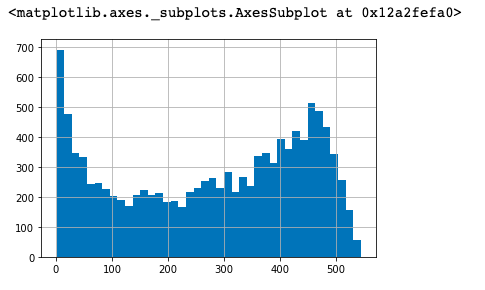
分析:
1. 有不少用户生命周期靠拢在0天,部分质量差的用户虽然消费了两次,但是仍然无法持续,
用户首次消费30天以内应该尽量引导;
2. 少部分用户集中在50-300天,属于普通型的生命周期;
3. 高质量用户的生命周期,集中在400天以后,这属于忠诚用户。6. 复购率和回购率的分析
复购率:自然月内,购买多次的用户占比
回购率:曾经购买过的用户在某一时期内的再次购买占比# applymap()针对DataFrame里的所有数据。使用lambda函数,因为设计了多个结果,所以要用两个if else purchase_r = pivoted_counts.applymap(lambda x: 1 if x>1 else np.NaN if x==0 else 0) purchase_r.head()

复购率
(purchase_r.sum()/purchase_r.count()).plot(figsize=(10,4))
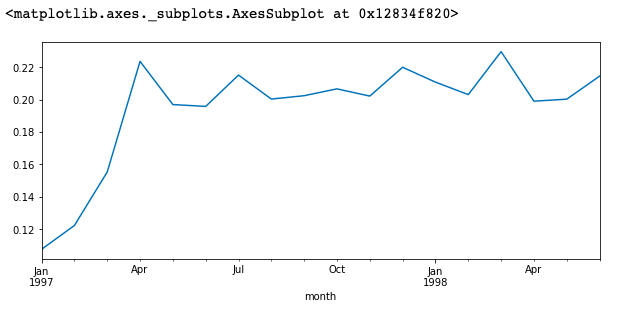
分析:
1. 用sum和count相除即可计算出复购率。这两个函数都会忽略掉NaN,而NaN是没有消费的用户,count不论是0或1都会统计,
所以是总的消费用户数。而sum求和计算了消费两次及以上的用户。这里比较巧妙的用了替代法计算复购率。sql中也可以用。
2. 图上可以看出复购率在早期,因为大量新用户加入的关系,新客的复购率并不高,譬如1月新客们的复购率只有6%左右。
而在后期,这时的用户都是大浪淘沙剩下的老客户,复购率比较稳定,在20%左右。单看新客和老客,复购率有三倍左右的差距。回购率:回购率是某一个时间窗口内消费的用户,在下个时间窗口仍旧消费的占比。
1 # 消费金额进行透视 2 3 pivoted_amount = df.pivot_table(index='user_id', 4 columns='month', 5 values='order_amount', 6 aggfunc='mean') 7 pivoted_amount.fillna(0,inplace=True) 8 columns_month = df['month'].sort_values().astype('str').unique() 9 pivoted_amount.columns = columns_month 10 11 # pivoted_amount.head() 12 pivoted_amount.head()

pivoted_purchase = pivoted_amount.applymap(lambda x : 1 if x>0 else 0) pivoted_purchase.head()
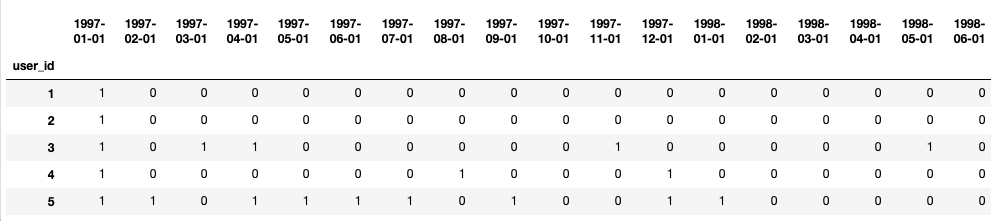
1 # 0代表当月消费过次月没有消费过,1代表当月消费过次月依然消费 2 3 def purchase_return(data): 4 status = [] 5 for i in range(17): 6 if data[i] == 1: 7 if data[i+1] ==1: 8 status.append(1) 9 if data[i+1] == 0: 10 status.append(0) 11 else: 12 status.append(np.NaN) 13 status.append(np.NaN) 14 return pd.Series(status, index = pivoted_purchase.columns) 15 16 pivoted_purchase_return = pivoted_purchase.apply(purchase_return,axis = 1) 17 18 pivoted_purchase_return.head()

# 回购率,计算方法和复购率类似,同样的逻辑 (pivoted_purchase_return.sum()/pivoted_purchase_return.count()).plot(figsize=(10,4))

分析:
1. 从上图看出,用户的回购率高于复购率,约在30%左右,和老客户差异不大。
2. 从回购率和复购率综合分析,新客的整体质量低于老客,老客的忠诚度(回购率)很好,消费频次稍次

 浙公网安备 33010602011771号
浙公网安备 33010602011771号