kali工具
kali工具
john解密工具
john解密
用法:
john [OPTIONS] [PASSWORD-FILES]
john [选项] [密码文件]
选项:
--single[=SECTION] ]“单裂”模式
--wordlist[=FILE] --stdin 单词表模式,从FILE或stdin读取单词
--pipe 像--stdin一样,但批量读取,并允许规则
--loopback[=FILE] 像 --wordlistg一样, 但是从.pot文件中获取单词
--dupe-suppression 压制wordlist中的所有模糊(并强制预加载)
--prince[=FILE] PRINCE模式,从FILE中读取单词
--encoding=NAME 输入编码(例如,UTF-8,ISO-8859-1)。 也可以看看doc / ENCODING和--list = hidden-options。
--rules[=SECTION] 为单词表模式启用单词修改规则
--incremental[=MODE] “增量”模式[使用部分模式]
--mask=MASK 掩码模式使用MASK
--markov[=OPTIONS] “马尔可夫”模式(参见doc / MARKOV)
--external=MODE 外部模式或字过滤器
--stdout[=LENGTH] 只是输出候选人密码[在LENGTH切]
--restore[=NAME] 恢复被中断的会话[名为NAME]
--session=NAME 给一个新的会话NAME
--status[=NAME] 打印会话的状态[名称]
--make-charset=FILE 制作一个字符集文件。 它将被覆盖
--show[=LEFT] 显示破解的密码[如果=左,然后uncracked]
--test[=TIME] 运行测试和每个TIME秒的基准
--users=[-]LOGIN|UID[,..] [不]只加载这个(这些)用户
--groups=[-]GID[,..] 只加载这个(这些)组的用户
--shells=[-]SHELL[,..] 用[out]这个(这些)shell来加载用户
--salts=[-]COUNT[:MAX] 用[out] COUNT [到MAX]散列加载盐
--save-memory=LEVEL 启用内存保存,级别1..3
--node=MIN[-MAX]/TOTAL 此节点的数量范围不在总计数中
--fork=N 叉N过程
--pot=NAME 锅文件使用
--list=WHAT 列表功能,请参阅--list = help或doc / OPTIONS
--format=NAME 强制使用NAME类型的散列。 支持的格式可以用--list=formats和--list=subformats来看
实例:
通过cp /etc/shadow a1.txt
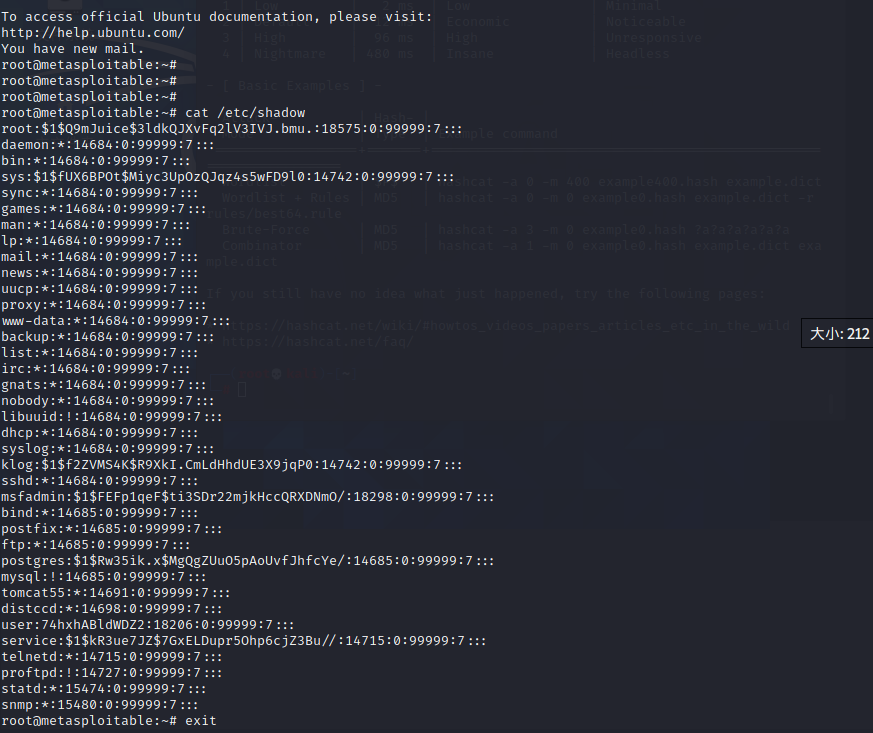
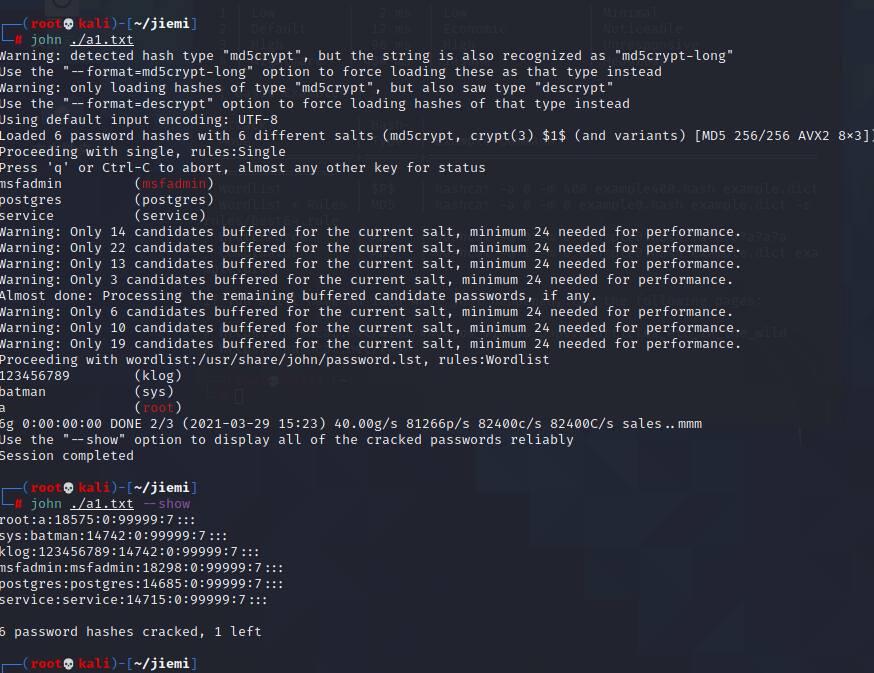
然后使用john a1.txt进行解密
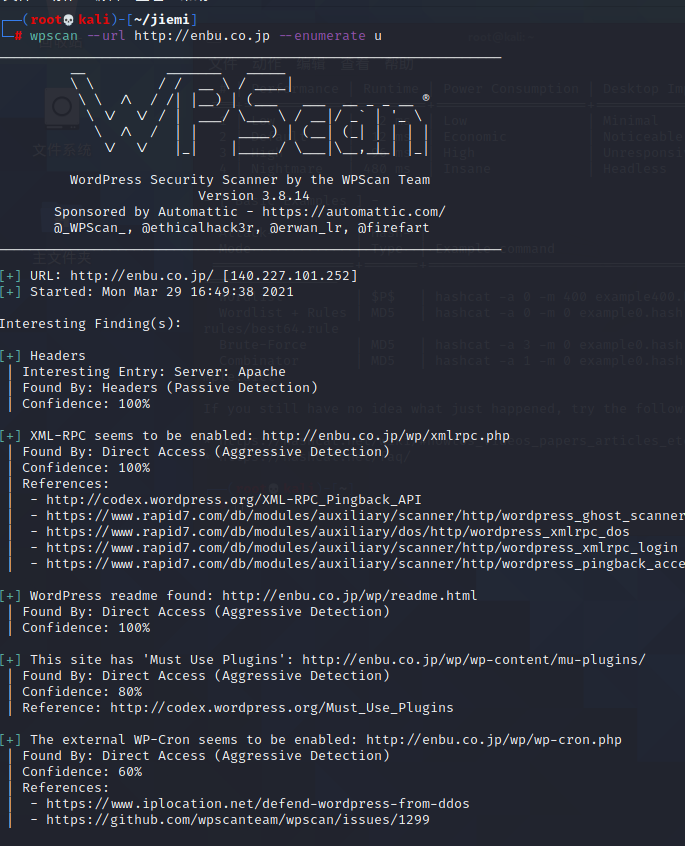
wpscan WordPress博客模板
选项:
--update 更新到最新版本
--url | -u <target url> 要扫描的`WordPress`站点.
--force | -f 不检查网站运行的是不是`WordPress`
--enumerate | -e [option(s)] 枚举
u 枚举用户名,默认从1-10
u[10-20] 枚举用户名,配置从10-20
p 枚举插件
vp 只枚举有漏洞的插件
ap 枚举所有插件,时间较长
tt 列举缩略图相关的文件
t 枚举主题信息
vt 只枚举存在漏洞的主题
at 枚举所有主题,时间较长
可以指定多个扫描选项,例:"-e tt,p"
如果没有指定选项,默认选项为:"vt,tt,u,vp"
--exclude-content-based "<regexp or string>"
当使用枚举选项时,可以使用该参数做一些过滤,基于正则或者字符串,可以不写正则分隔符,但要用单引号或双引号包裹
--config-file | -c <config file使用指定的配置文件
--user-agent | -a <User-Agent指定User-Agent
--cookie <String指定cookie
--random-agent | -r 使用随机User-Agent
--follow-redirection 如果目标包含一个重定向,则直接跟随跳转
--batch 无需用户交互,都使用默认行为
--no-color 不要采用彩色输出
--wp-content-dir <wp content dirWPScan会去发现wp-content目录,用户可手动指定
--wp-plugins-dir <wp plugins dir指定wp插件目录,默认是wp-content/plugins
--proxy <[protocol://]host:port设置一个代理,可以使用HTTP、SOCKS4、SOCKS4A、SOCKS5,如果未设置默认是HTTP协议
--proxy-auth <username:password设置代理登陆信息
--basic-auth <username:password设置基础认证信息
--wordlist | -w <wordlist指定密码字典
--username | -U <username指定爆破的用户名
--usernames <path-to-file指定爆破用户名字典
--threads | -t <number of threads指定多线程
--cache-ttl <cache-ttl设置 cache TTL
--request-timeout <request-timeout请求超时时间
--connect-timeout <connect-timeout连接超时时间
--max-threads <max-threads最大线程数
--throttle <milliseconds当线程数设置为1时,设置两个请求之间的间隔
--help | -h 输出帮助信息
--verbose | -v 输出Verbose
--version 输出当前版本
实例:
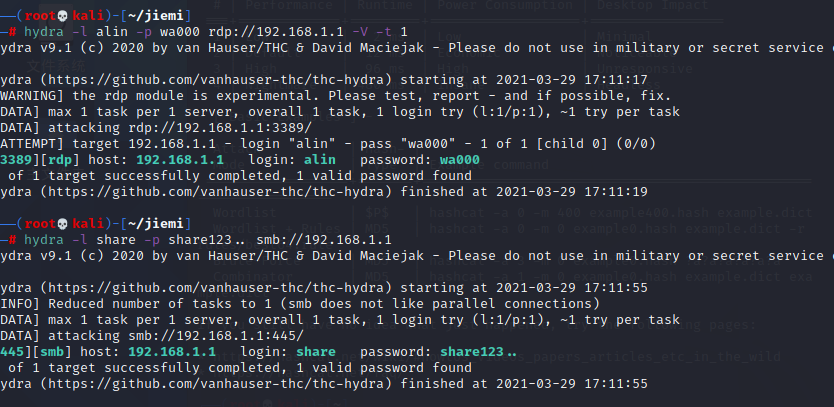
hydra 爆破
参数:
-R 继续从上一次进度接着破解。
-S 采用SSL链接。
-s PORT 可通过这个参数指定非默认端口。
-l LOGIN 指定破解的用户,对特定用户破解。
-L FILE 指定用户名字典。
-p PASS 小写,指定密码破解,少用,一般是采用密码字典。
-P FILE 大写,指定密码字典。
-e ns 可选选项,n:空密码试探,s:使用指定用户和密码试探。
-C FILE 使用冒号分割格式,例如“登录名:密码”来代替-L/-P参数。
-M FILE 指定目标列表文件一行一条。
-o FILE 指定结果输出文件。
-f 在使用-M参数以后,找到第一对登录名或者密码的时候中止破解。
-t TASKS 同时运行的线程数,默认为16。
-w TIME 设置最大超时的时间,单位秒,默认是30s。
-v / -V 显示详细过程。
示例:
使用示例:
Examples:
hydra -l user -P passlist.txt ftp://192.168.0.1
hydra -L userlist.txt -p defaultpw imap://192.168.0.1/PLAIN
hydra -C defaults.txt -6 pop3s://[2001:db8::1]:143/TLS:DIGEST-MD5
hydra -l admin -p password ftp://[192.168.0.0/24]/
hydra -L logins.txt -P pws.txt -M targets.txt ssh
-l 后面跟着 具体的用户名
-p 后面跟着 具体的密码
-L 后面跟着 用户字典
-P 后面跟着 密码字典
实例:
skipfish web扫描
用法:
skipfish [options ...] -W wordlist -o output_dir start_url [start_url2 ...]
skipfish [选项 ...] -W 词表 -o 输出目录 开始url [开始url2 ...]
选项:
验证和访问选项:
-A user:pass - 使用指定的HTTP身份验证凭据
-F host = IP - 假装'host'解析为'IP'
-C name = val - 将自定义Cookie附加到所有请求
-H name = val - 将自定义HTTP标头附加到所有请求
-b(i | f | p) - 使用与MSIE / Firefox / iPhone一致的标题
-N - 不接受任何新的cookies
--auth-form url - 表单认证URL
--auth-user user - 表单认证用户
--auth-pass pass - 通行证验证密码
--auth-verify-url - 会话检测的URL
抓取范围选项:
-d max_depth - 最大爬网树深度(16)
-c max_child - 每个节点索引的最大子对象(512)
-x max_desc - 每个分支索引的最大后代(8192)
-r r_limit - 发送请求的最大总数(100000000)
-p crawl% - 节点和链接爬网概率(100%)
-q hex - 用给定种子重复概率扫描
-I string - 仅跟踪匹配'string'的URL
-X string - 排除匹配'string'的URL
-K string - 不要将名为'string'的模糊参数
-D domain - 抓取跨站点链接到另一个域
-B domain - 信任,但不要爬网,另一个域
-Z -不要下降到5xx位置
-O - 不提交任何表格
-P - 不解析HTML等,以找到新的链接
报告选项:
-o dir - 将输出写入指定的目录(必需)
-M - 关于混合内容/非SSL密码的日志警告
-E - 记录所有HTTP / 1.0 / HTTP / 1.1缓存意图不匹配
-U - 记录所有外部URL和电子邮件
-Q - 完全抑制报表中的重复节点
-u - 安静,禁用实时进度统计
-v - 启用运行时记录(到stderr)
词典管理选项:
-W wordlist - 使用指定的read-write wordlist(必填)
-S wordlist - 加载一个补充的只读单词列表
-L - 不要自动学习网站的新关键字
-Y - 不要在目录中强制扩展
-R age - 清除字词超过“年龄”扫描
-T name = val - 添加新的表单自动填充规则
-G max_guess - 要保留的关键字猜测的最大数量(256)
-z sigfile - 从此文件加载签名
性能设置:
-g max_conn - 最大同时TCP连接,全局(40)
-m host_conn - 最大同时连接,每个目标IP(10)
-f max_fail - 连续HTTP错误的最大数量(100)
-t req_tmout - 总请求响应超时(20秒)
-w rw_tmout - 个别网络I / O超时(10秒)
-i idle_tmout - 空闲HTTP连接超时(10秒)
-s s_limit - 响应大小限制(400000 B)
-e - 不要保留二进制报告
其他设置:
-l max_req - 每秒最大请求数(0.000000)
-k duration - 给定持续时间后停止扫描h:m:s
--config file - 加载指定的配置文件
实例:
skipfish -o test http://192.168.1.5
uniscan web扫描
参数:
-h 帮助
-u <url>示例:https://www.example.com/
-f <file>url列表
-b 后台
-q 启用目录检查
-w 启用文件检查
-e 启用robots.txt以及sitemap.xml检查
-d 启用动态检查
-s 启用静态检查
-r 启用应力检查
-i <dork>必应搜索
-o <dork>谷歌搜索
-g Web指纹
-j 服务器指纹
示例:
usage:
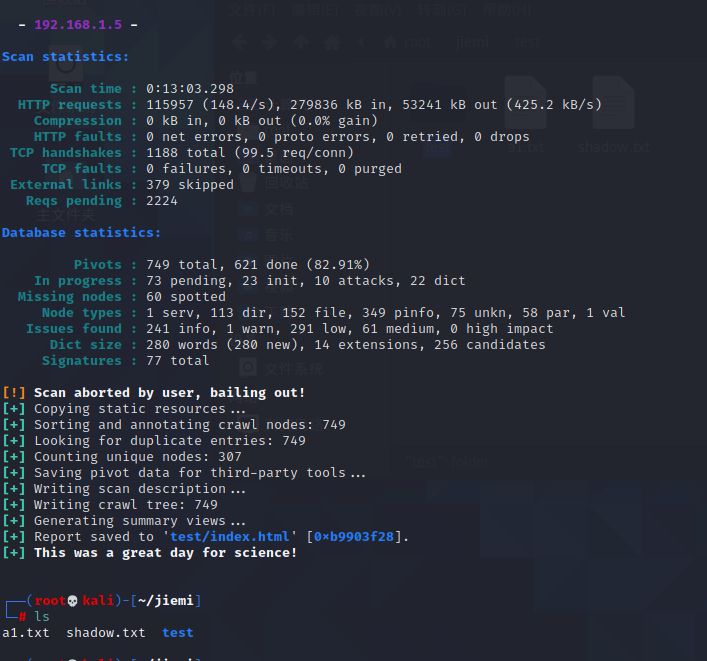
[1] uniscan -u Example Domain -qweds
[2] uniscan -f sites.txt -bqweds
[3] uniscan -i uniscan
[4] uniscan -i "ip:http://xxx.xxx.xxx.xxx"
[5] uniscan -o "inurl:test"
[6] uniscan -u Example Domain -r
实例:
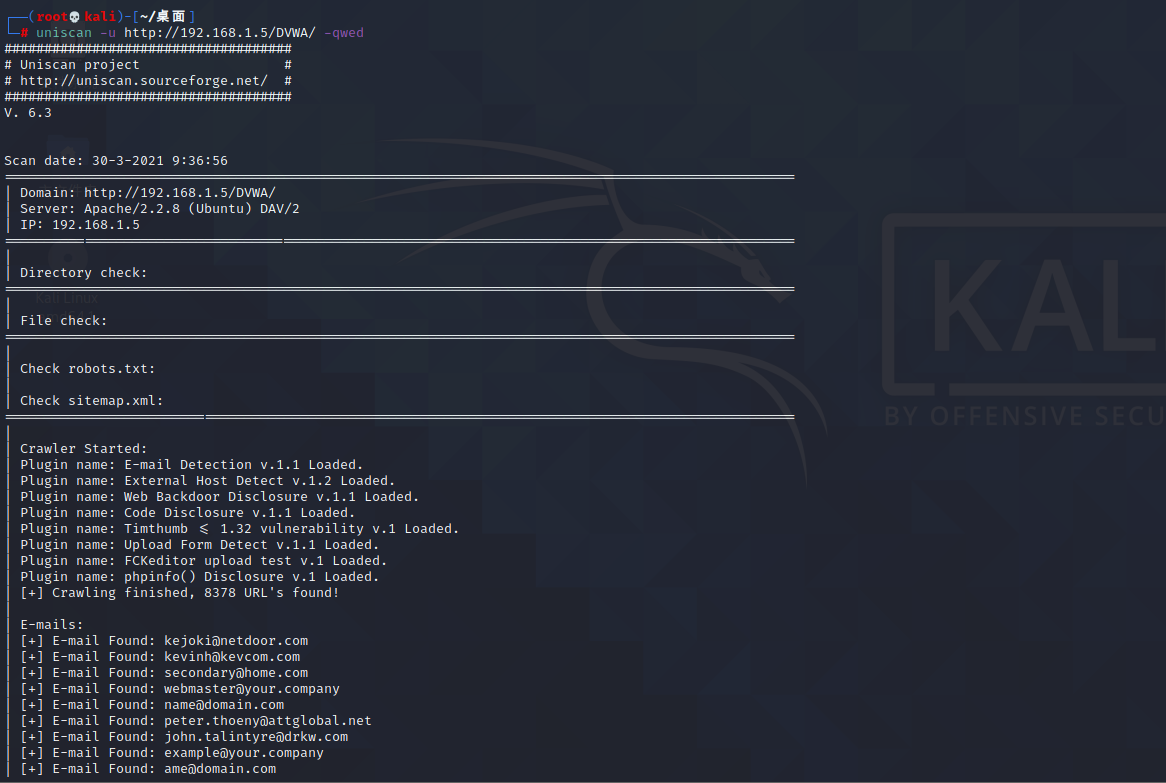
扫描结果:

wapiti web扫描
参数:
-x <URL>:从扫描中排除特定的 URL,对于登出和密码修改 URL 很实用。
-o <output>:设置输出文件及其格式,如:result.html
-f <type_file>:设置输出文件格式,如:html,json等
-m <module_options>:设置模块进行攻击
-i <file>:从 XML 文件中恢复之前保存的扫描。文件名称是可选的,因为如果忽略的话 Wapiti 从scan文件夹中读取文件。
-a <login%password>:为 HTTP 登录使用特定的证书。
--auth-method <method>:为-a选项定义授权方式,可以为basic,digest,kerberos 或 ntlm。
-s <URL>:定义要扫描的 URL。
-p <proxy_url>:使用 HTTP 或 HTTPS 代理。
模块:
backup
blindsql (default)
buster
crlf
delay
exec (default)
file (default)
htaccess
methods
nikto
permanentxss (default)
redirect (default)
shellshock
sql (default)
ssrf (default)
xss (default)
xxe
实例:
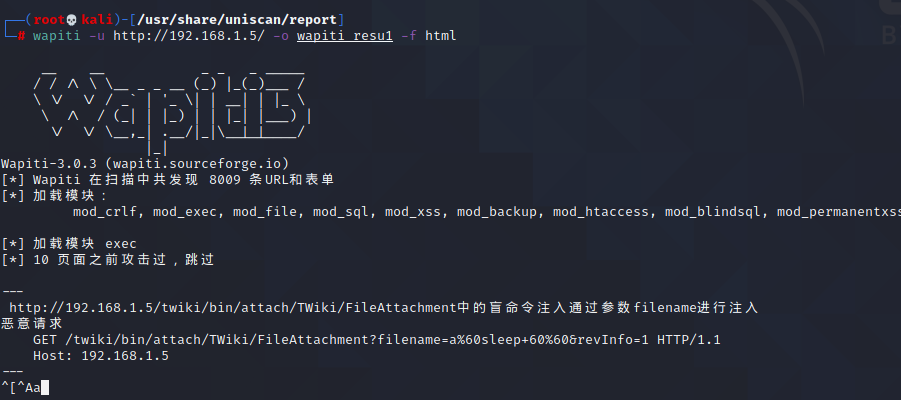
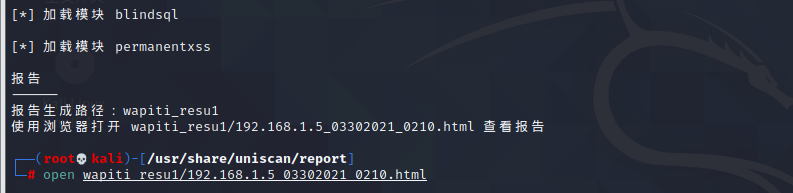
wapiti -u http://192.168.1.5/ -o wapiti_resu1 -f html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号