

Python_selenium之获取页面上的全部邮箱
一、思路拆分
- 获取网页(这里以百度的“联系我们”为例),网址http://home.baidu.com/contact.html
- 获取页面的全部内容(driver.page_source)
- 运用正则表达式,导入re模块找到邮箱的字段
- 循环打印出邮箱(去重)
二、测试脚本
1. 源代码如下:
#coding:utf-8
from selenium import webdriver
import re#导入re模块
driver=webdriver.Firefox()
driver.maximize_window()
driver.implicitly_wait(8)
driver.get("http://home.baidu.com/contact.html")
doc=driver.page_source#获取网页所有的内容
emails=re.findall(r'[\w]+@[\w\.-]+',doc)#邮箱的正则表达式
for email in list(set(emails)):#去掉重复的邮箱
print email
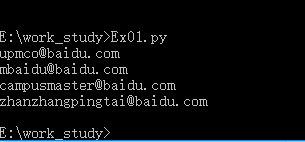
2. 测试结果如下图1所示

 浙公网安备 33010602011771号
浙公网安备 33010602011771号