
机器学习 | 机器学习简介
前言:本系列博客参考于 《机器学习算法导论》和《Python机器学习》
如有侵权,敬请谅解。博客内尽量用总结性的语言重述书中内容,避免侵权。
数据转化成知识
我们正处于现代化技术飞速发展的时代,同时还拥有大量的结构化和非结构化的数据资源。机器学习只是人工智能的一个分支,最近火热的人工智能概念已经深入人心,那么要进入人工智能这个行业,机器学习必须先行。
机器学习的目的是通过对自学习算法的开发,从数据中获取知识,进而对未来进行预测。机器学习不仅在计算机科学研究领域显现出日益重要的地位,而且在日常生活中也逐渐发挥了越来越大的作用。机器学习技术的存在,使得人们可以享受强大的垃圾邮件过滤带来的便利;拥有方便的文字和语音识别软件;能够使用强大的网络搜索引擎;同时在围棋领域中完胜世界一流人类职业选手;而且在不久的将来我们将会拥有安全高效的无人驾驶汽车。
百度,阿里,腾讯每天PB级别的数据产出,部署在阿里云服务器上成百上千的爬虫服务在 \(7\times24\) 不停歇的爬去网络数据,如果能够充分发觉数据的价值并利用他们,将会对我们的生活有很大的改善。
介绍
机器学习的三种分类:监督学习(supervised learning)、无监督学习(unsupervised learning)、强化学习(reinforcement learning)
监督学习
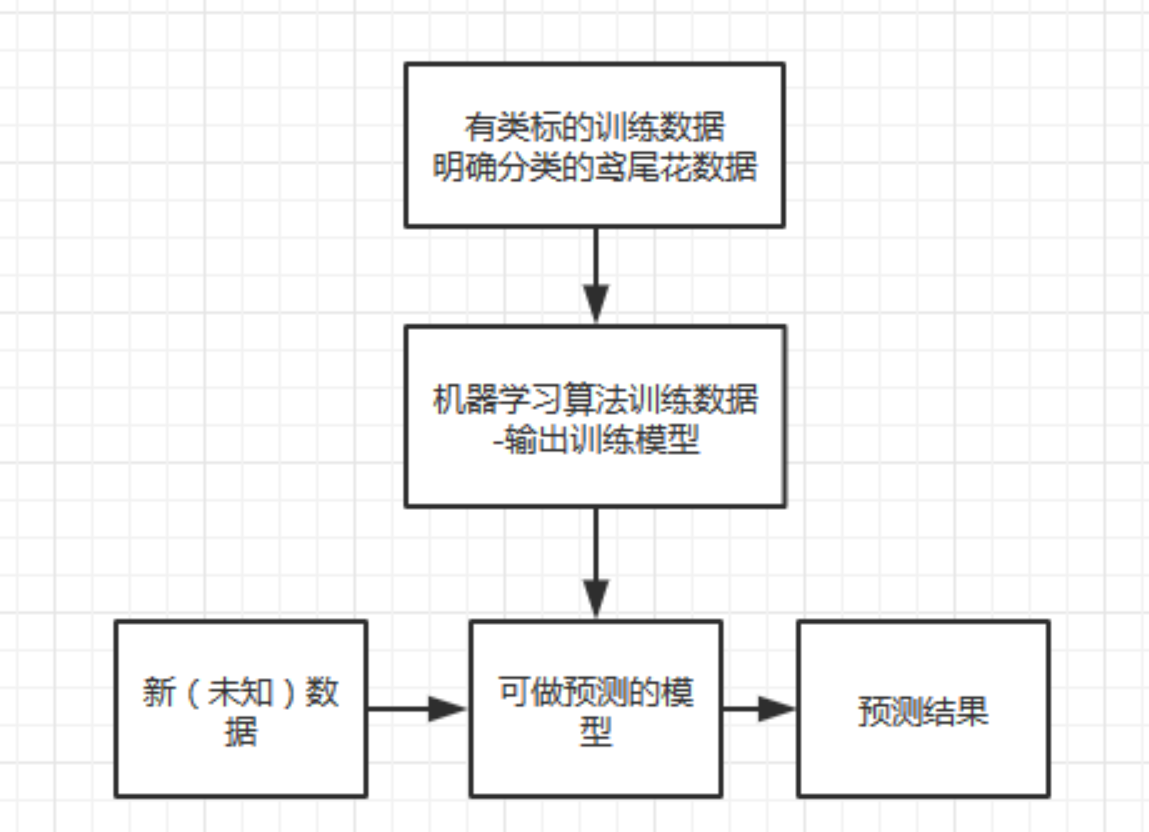
监督学习的目的是使用有类标的训练数据结构模型,我们可以使用经训练得到的模型对未来数据进行预测。
“监督”:训练数据集中的每个样本均有一个已知的输出项(类标-label)例如:以鸢尾花分类为例,数据集提供了150个包涵花萼长度,花萼宽带,花瓣长度,花瓣宽度等四个特征的3类鸢尾花。
以已知的前100条数据为训练样本,这100条数据已经被明确分类为哪种花,根据训练模型将其进行正确的分类。监督学习包涵分类(classification)与回归(regression)
-
利用分类对类标进行预测
分类是对过往类标已知示例的观察与学习,实现对新样本类标的预测。 这些类标是离散的、无序的值。
-
使用回归预测连续输出值
回归问题输出项是连续值,针对连续输出量进行预测,也就是所谓的回归分析
在回归分析中,数据中会给出大量的自变量和相应的连续因变量,通过尝试寻找这两种变量之间的关系,就能够预测输出变量 -
通过强化学习解决交互式问题
强化学习的目标是构建一个系统,在与环境交互过程中提高系统的性能,
环境的当前状态信息中通常包含一个反馈信号,我们可以将强化学习视为与监督学习相关的一个领域。
然而,在强化学习中,我个反馈值不是一个确定的类标或者连续类型的值,而是一个通过反馈函数产生的对当前系统行为的评价。
通过与环境的交互,系统可以通过强化学习来得到一些列行为,通过探索性的试错或者借助精心设计的激励系统使得正向反馈最大化。一个常用的强化学习例子就是象棋对弈的游戏。系统根据棋盘上的当前局态决定落子位置,而游戏结束时胜负的判定可以作为激励信号。
无监督学习
在监督学习中,训练模型之前,我们事先可以获知各训练样本对应的目标值。
在强化学习中,可以由Agent定义反馈函数对特定行为进行判定。
然而,在无监督学习中,我们将处理无类标数据或者是总体分布趋势不明朗的数据。
通过无监督学习,我们可以在没有已知输出变量和反馈函数指导情况下提取有效信息来探索数据的整体结构。
-
通过聚类发现数据的子群
聚类是一种探索性数据分析技术。在没有任何相关先验信息的情况下,它可以帮助我们将数据划分为有意义的小的组别(即簇)
聚类是获取数据的结构信息,以及到处数据间有价值的关系的一种很好的技术 -
数据压缩中的降维
数据降维是无监督学习的另一个子领域。通常,我们面对的是高维的数据,
这就对有限的数据存储空间以及机器学习算法性能提出了挑战。无监督降维是数据特征预处理时常用的技术,用于清楚数据中的噪声
它能够在最大程度保留相关信息的情况下将数据压缩到一个维度较小的子空间,但同时也可能会降低某些算法的准确性方面的性能。
降维技术有时在数据可视化方面也是非常有用的。
机器学习流程
-
数据预处理
为了尽可能发挥机器学习算法的性能,往往对原始数据的格式等有一些特定的要求,但原始数据很少能达到此标准。
因此,数据预处理是机器学习应用过程中必不可少的重要步骤之一。 -
选择预测模型类型并进行训练
-
模型验证与使用未知数据进行预测
在使用训练数据集构建出一个模型之后,可以采用测试数据集对模型进行测试,预测改模型在位置数据
为什么使用Python实现机器学习算法
Python是数据科学领域最流行的编程语言之一,因此拥有大量由众多社区开发的附加扩展库。
对于计算密集型任务,尽管解释型语言(如Python)在性能方面不如低级别语言,但使用相对低级别语言(如Fortran,C等)
开发的扩展库(如 Numpy,Scipy 等)实现了多维数组高速向量化的运算。
处理机器学习程序开发任务,我们主要使用最流行的开源学习库 scikit-learn 来完成。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号