
查找表结构
查找表介绍
在日常生活中,几乎每天都要进行一些查找的工作,在电话簿中查阅某个人的电话号码;在电脑的文件夹中查找某个具体的文件等等。本节主要介绍用于查找操作的数据结构——查找表。
查找表是由同一类型的数据元素构成的集合。例如电话号码簿和字典都可以看作是一张查找表。
一般对于查找表有以下几种操作:
- 在查找表中查找某个具体的数据元素;
- 在查找表中插入数据元素;
- 从查找表中删除数据元素;
静态查找表和动态查找表
在查找表中只做查找操作,而不改动表中数据元素,称此类查找表为静态查找表;反之,在查找表中做查找操作的同时进行插入数据或者删除数据的操作,称此类表为动态查找表。
关键字
在查找表查找某个特定元素时,前提是需要知道这个元素的一些属性。例如,每个人上学的时候都会有自己唯一的学号,因为你的姓名、年龄都有可能和其他人是重复的,唯独学号不会重复。而学生具有的这些属性(学号、姓名、年龄等)都可以称为关键字。
关键字又细分为主关键字和次关键字。若某个关键字可以唯一地识别一个数据元素时,称这个关键字为主关键字,例如学生的学号就具有唯一性;反之,像学生姓名、年龄这类的关键字,由于不具有唯一性,称为次关键字。
如何进行查找?
不同的查找表,其使用的查找方法是不同的。例如每个人都有属于自己的朋友圈,都有自己的电话簿,电话簿中数据的排序方式是多种多样的,有的是按照姓名的首字母进行排序,这种情况在查找时,就可以根据被查找元素的首字母进行顺序查找;有的是按照类别(亲朋好友)进行排序。在查找时,就需要根据被查找元素本身的类别关键字进行排序。
具体的查找方法需要根据实际应用中具体情况而定。
顺序查找算法(C++)
静态查找表既可以使用顺序表表示,也可以使用链表结构表示。虽然一个是数组、一个链表,但两者在做查找操作时,基本上大同小异。
顺序查找的实现
静态查找表用顺序存储结构表示时,顺序查找的查找过程为:从表中的最后一个数据元素开始,逐个同记录的关键字做比较,如果匹配成功,则查找成功;反之,如果直到表中第一个关键字查找完也没有成功匹配,则查找失败。
#include<bits/stdc++.h>
using namespace std;
typedef struct {
int key;//查找表中数据的值
//按需求添加其他属性
}ElemType;
typedef struct {
ElemType *elem;//存放查找表中数据元素的数组
int length;//记录查找表中的数据总数量
}SSTable;
//创建查找表
void Creat(SSTable **st,int length) {
(*st) =(SSTable*) new SSTable;
(*st)->length = length;
(*st)->elem = (ElemType *) new ElemType[length + 1];
//根据查找表中数据元素的总长度,在存储时,从数组下标为 1 的空间开始存储数据
cout << "输入表中元素:\n";
for (int i = 1; i <= length; ++i) {
cin >> ((*st)->elem[i].key);
}
}
//查找表查找的功能函数,其中key为关键字
int Search_seq(SSTable *st, int key) {
st->elem[0].key = key;//将关键字作为一个数据元素存放在查找表的第一个位置,监视哨作用
int i = st->length;
//从查找表的最后一个元素依次遍历,直到下标为0
while (st->elem[i].key != key)
i--;
//如果 i=0,说明查找失败;反之,返回的是含有关键字key的数据元素在查找表中的位置
return i;
}
int main() {
SSTable *st;
Creat(&st, 6);
getchar();
printf("请输入查找数据的关键字:\n");
int key;
cin >> key;
int location = Search_seq(st, key);
if (location == 0) {
printf("查找失败\n");
}
else {
printf("数据在查找表中的位置为:%d", location);
}
return 0;
}
输入表中的数据元素:
1 2 3 4 5 6
请输入查找数据的关键字:
2
数据在查找表中的位置为:2
使用监视哨对普通的顺序表的遍历算法做了改进,在数据量大的情况下,能够有效提高算法的运行效率。
二分查找(折半查找)算法
折半查找,也称二分查找,在某些情况下相比于顺序查找,使用折半查找算法的效率更高。但是该算法的使用的前提是静态查找表中的数据必须是有序的。
例如,在{5,21,13,19,37,75,56,64,88 ,80,92}这个查找表使用折半查找算法查找数据之前,需要首先对该表中的数据按照所查的关键字进行排序:{5,13,19,21,37,56,64,75,80,88,92}。
在折半查找之前对查找表按照所查的关键字进行排序的意思是:若查找表中存储的数据元素含有多个关键字时,使用哪种关键字做折半查找,就需要提前以该关键字对所有数据进行排序。
#include<bits/stdc++.h>
using namespace std;
#define MAX_INT 20
//int a[MAX_INT];//存储元素
int n;//数组大小
int BinarySearch(int a[], int value) {
int left = 0;
int right = n - 1;
while (left <= right) {
//最好改用位运算符而不是 /2
//https://www.cnblogs.com/Kanna/p/12371164.html (位运算详解)
if (value > a[(left + right) / 2])
left = (right + left) / 2;
else if (value < a[(left + right) / 2])
right = (right + left) / 2;
else
{
return (left + right) / 2;
}
}
return -1;
}
int main() {
int a[] = { 1,2,3,4,5 };//sorted arrays
n = 5;
int ans = BinarySearch(a, 3);
if (ans == -1)cout << " Not find " << endl;
else cout << ans + 1 << endl;
return 0;
}
注意:在做查找的过程中,如果 left 和 right 的中间位置在计算时位于两个关键字中间,即求得 mid 的位置不是整数,需要统一做取整操作。
通过比较折半查找的平均查找长度,同前面介绍的顺序查找相对比,明显折半查找的效率要高。但是折半查找算法只适用于有序表,同时仅限于查找表用顺序存储结构表示。
当查找表使用链式存储结构表示时,折半查找算法无法有效地进行比较操作(排序和查找操作的实现都异常繁琐)。
分块查找(索引顺序查找)算法
分块查找,也叫索引顺序查找,算法实现除了需要查找表本身之外,还需要根据查找表建立一个索引表。例如图 1,给定一个查找表,其对应的索引表如图所示:
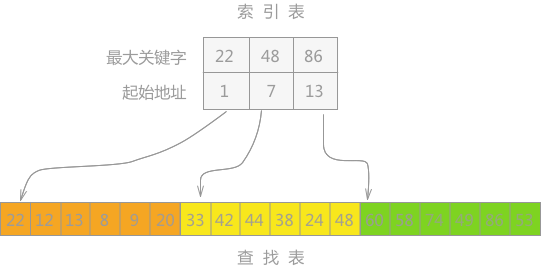
图中,查找表中共 18 个查找关键字,将其平均分为 3 个子表,对每个子表建立一个索引,索引中包含中两部分内容:该子表部分中最大的关键字以及第一个关键字在总表中的位置,即该子表的起始位置。
建立的索引表要求按照关键字进行升序排序,查找表要么整体有序,要么分块有序。
分块有序指的是第二个子表中所有关键字都要大于第一个子表中的最大关键字,第三个子表的所有关键字都要大于第二个子表中的最大关键字,依次类推。
块(子表)中各关键字的具体顺序,根据各自可能会被查找到的概率而定。如果各关键字被查找到的概率是相等的,那么可以随机存放;否则可按照被查找概率进行降序排序,以提高算法运行效率。
分块查找的具体实现
所有前期准备工作完成后,开始在此基础上进行分块查找。分块查找的过程分为两步进行:
- 确定要查找的关键字可能存在的具体块(子表);
- 在具体的块中进行顺序查找。
以图中的查找表为例,假设要查找关键字 38 的具体位置。首先将 38 依次和索引表中各最大关键字进行比较,因为 22 < 38 < 48,所以可以确定 38 如果存在,肯定在第二个子表中。
由于索引表中显示第二子表的起始位置在查找表的第 7 的位置上,所以从该位置开始进行顺序查找,一直查找到该子表最后一个关键字(一般将查找表进行等分,具体子表个数根据实际情况而定)。结果在第 10 的位置上确定该关键字即为所找。
Tip:在第一步确定块(子表)时,由于索引表中按照关键字有序,所有可以采用折半查找算法。而在第二步中,由于各子表中关键字没有严格要求有序,所以只能采用顺序查找的方式。
具体实现代码:
#include<bits/stdc++.h>
using namespace std;
struct index { //定义块的结构
int key;
int start;
} newIndex[3]; //定义结构体数组
int search(int key, int a[]);
int cmp(const void *a, const void* b) {
return (*(struct index*)a).key > (*(struct index*)b).key ? 1 : -1;
}
int main() {
int i, j = -1, k, key;
int a[] = { 33,42,44,38,24,48, 22,12,13,8,9,20, 60,58,74,49,86,53 };
//确认模块的起始值和最大值
for (i = 0; i < 3; i++) {
newIndex[i].start = j + 1; //确定每个块范围的起始值
j += 6;
for (int k = newIndex[i].start; k <= j; k++) {
if (newIndex[i].key < a[k]) {
newIndex[i].key = a[k];
}
}
}
//对结构体按照 key 值进行排序
qsort(newIndex, 3, sizeof(newIndex[0]), cmp);
//输入要查询的数,并调用函数进行查找
printf("请输入您想要查找的数:\n");
scanf("%d", &key);
k = search(key, a);
//输出查找的结果
if (k > 0) {
printf("查找成功!您要找的数在数组中的位置是:%d\n", k + 1);
}
else {
printf("查找失败!您要找的数不在数组中。\n");
}
return 0;
}
int search(int key, int a[]) {
int i, startValue;
i = 0;
while (i<3 && key>newIndex[i].key) { //确定在哪个块中,遍历每个块,确定key在哪个块中
i++;
}
if (i >= 3) { //大于分得的块数,则返回0
return -1;
}
startValue = newIndex[i].start; //startValue等于块范围的起始值
while (startValue <= startValue + 5 && a[startValue] != key)
{
startValue++;
}
if (startValue > startValue + 5) { //如果大于块范围的结束值,则说明没有要查找的数
return -1;
}
return startValue;
}
请输入您想要查找的数:
22
查找成功!您要找的数在数组中的位置是:7
分块查找的性能分析
分块查找算法的运行效率受两部分影响:
查找块的操作和块内查找的操作。查找块的操作可以采用顺序查找,也可以采用折半查找(更优);块内查找的操作采用顺序查找的方式。相比于折半查找,分块查找时间效率上更低一些;相比于顺序查找,由于在子表中进行,比较的子表个数会不同程度的减少,所有分块查找算法会更优。
总体来说,分块查找算法的效率介于顺序查找和折半查找之间。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号