功能规格说明书
总体目标
本说明书意在说明表中所列问题,其范畴不会超出表中所给出的范畴。为了阅读的流畅性,我们将会在表中给出一个概括性的范畴描述,并在下文中作进一步解释。
| 问题 | 范畴 |
|---|---|
| 术语说明 | 本文的相关术语及说明 |
| 产品分析 | 产品的用户和应用场景 |
| 系统功能 | 产品实现的相关功能和依赖关系 |
| 边界条件 | 产品功能涉及的边界条件和触发时行为 |
| 产品目标 | 产品需要实现的目标 |
| 数据收集 | 产品需要收集的数据 |
术语说明
数据集:本文中特指机器学习数据集,定义为训练模型和进行预测所需的数据集合,在深度学习过程中,这些数据集被分为训练,验证和测试集,用于训练和测量模型的性能。
针对产品目标和数据收集,我们定义了一系列相关指标,会在相应的章节中给出相关定义和说明。
产品分析
典型用户
- 入门深度学习的高校学生
- 用户特征:刚刚接触深度学习,对数据集只有一个模糊的概念。
- 潜在总量:随着计算机专业和深度学习越来越热门,学习这方面的学生会越来越多,而大多数刚入门的学生,对数据集的理解存在较大障碍,需要一款数据集可视化软件来帮助理解。所以,这部分用户的潜在总量会很大。
- 市场比例:20%
- 使用环境:主要是学习场所,例如教室、宿舍、实验室。
- 动机:在入门深度学习时,往往需要对使用的数据集有直观的认识,而现有的数据集格式复杂,数据大多以数字、文本这样的形式体现,无法从现有格式中感性认识数据集,因此,需要将数据集中的信息直观表示出来。
- 困难:数据集格式多样,暂无统一软件以形象展示
- 偏好:这部分用户专业知识缺乏,无法对数据集进行专业的操作,因此需要软件便捷、易上手
- 愿意付出的代价:该类用户使用的功能比较基础,并且经济能力有限,为产品付出代价的意愿比较小。
- 模型设计与模型优化等相关从业者
- 用户特征:从事的工作与深度学习密切相关
- 潜在用户:对工作效率要求高的从业者
- 市场比例:35%
- 使用环境:主要是在工作中使用,例如办公室、家中
- 动机:方便筛选部分数据,查看其特征 在用测试集对模型的进行测试时,常常会遇到表现不好的测试数据,需要筛选这部分的数据
- 困难:数据集的筛选清洗需要自行编写,是重复劳动
- 偏好:特定数据集中进行大量筛选,可能是非公开的
- 愿意付出的代价:企业或部门会愿意为软件或功能付费,方式可能是买断或年付
- 深度学习相关研究者
- 用户特征:从事的研究与深度学习密切相关
- 潜在用户:对工作效率要求高的研究者
- 市场比例:35%
- 使用环境:主要是在实验室中使用
- 动机:除了筛选数据集的功能外,研究者通常还有发论文的需求,论文中需要将实验数据、结果等信息用直观的方式表示出来,所以研究者需要方便快速的将数据信息转化成可视化的信息在论文中使用。
- 困难:数据集的筛选和需要自行编写、数据集的可视化需要自行编写,重复劳动
- 偏好:支持多种数据集类型的多种可视化模式
- 愿意付出的代价:实验室或课题组会愿意为软件或功能付费,实验室可能是买断或年付,课题组可能视课题情况而定,可能方式是按月付。
- 用作教学的教师
- 用户特征:课堂内容涉及数据集相关内容,需要让学生更好的理解与掌握,同时需要方便课堂讲解
- 潜在用户:越来越多的高校开设人工智能专业与课程,数据集的处理是这些课程中很重要的内容,传统的数据集形式对学生的理解与老师的讲课效果来说都是不尽人意的。
- 市场比例:10%
- 使用环境:主要是在教学中,例如课堂、讲座
- 动机:在课堂上用传统的数据集形式讲解,课堂枯燥、学生理解困难,导致课堂效果差,需要以更直观的方式讲解数据集。
- 困难:教室中设备的局限性较大
- 偏好:软件具有丰富的展示形式,可以直观反映数据集的特征等信息。
- 愿意付出的代价:课程组会愿意为软件或功能付费,可能方式是买断或年付。
典型场景
入门深度学习的高校学生
- A同学,刚选了一门叫“计算机导论”的课程,就被要是要求实现xxx神经网络的训练,该同学不太理解数据集中的标注,于是打开了本软件,导入下发的标注好的数据集,本软件提供的可视化的标注信息能帮助他快速理解标注的意义,他同时可以和其他同学一起查看并共同讨论,使他更容易的理解课程内容。
模型设计与模型优化等相关从业者
- B工程师,盯着训好的目标网络,再看看效果不佳的测试集,无法找出其中的原因。使用本软件,可以查看数据集中的标注情况,让他对难以完成的调优工作有了一丝思路,同时还可以可视化的与同事讲解,交流可能的问题。使他更轻松的完成工作。
深度学习相关研究者
- C研究员,刚读完顶会的最新paper,准备复现一下实验,于是先下载了数据集,使用本软件查看数据集中的标注情况,同时保存了一些图片,为之后的组会presentation,论文中的插图做了不少准备。本软件使他更轻松的完成科研。
用作教学的教师
- D讲师,为了在课堂上展示数据集的标注工作,于是打开了本软件,向同学们展示标注好的可视化数据集。使用本软件,让同学们更容易的理解数据集的标注工作,拉近了师生距离,使用本软件,让老师们更轻松的完成了教学任务。
系统功能
系统功能及验收标准
| 模块 | 功能 | 验收标准 |
|---|---|---|
| 主页 | 提供引导、功能入口 | 1. 可以简要展示产品特点 2. 可以导航至数据集管理 3. 可以导航至反馈和设置页面 |
| 管理数据集 | 查看,管理数据集 | 1. 能展示用户已经添加的数据集 2. 能通过选中某个数据集进入数据集查看页面 3. 可以根据用户输入筛选出需要的数据集 4. 能添加、删除、从磁盘删除数据集 |
| 设置页面 | 控制个性化选项 | 1. 用户可以选择是否参加用户体验计划(收集用于改进产品质量和服务的数据) |
| 反馈界面 | 用户提供反馈 | 1. 用户可以向开发人员提交反馈 |
| 数据集内容查看 | 查看数据集具体内容 | 1. 可以展示选中数据集中的数据,通过分页等方式查看 2. 可以根据用户输入对标签进行单选、多选筛选,展示部分数据 3. 可以展示数据的附加信息 4. 可以导航至数据集格式示例 *在Alpha阶段,暂时只支持工作量最大受众也最多的图片方面的数据集 |
| 数据集格式解析 | 形象解析数据集格式 | 1. 可以以十六进制形式展示数据集真实数据,并且标明各部分意义 |
beta阶段预计功能及验收标准
| 模块 | 功能 | 验收标准 |
|---|---|---|
| 用户系统 | 实现用户系统和对应的权限管理 | 1. 用户可以注册、登录 2. 用户可以创建用户组 3. 用户可以在用户组内为其他用户设置相应的权限 |
| 数据集类型拓展 | 将数据集类型拓展到文本、音频等数据集上 | 1. 可以对文本数据集进行可视化展示 2. 可以对音频数据集进行可视化展示 |
| 本地部署端 | 使得用户可以在本地部署端进行数据集可视化的查看,上传 | 1. 提供可以安装的本地部署端 2. 用户可以上传自己的数据集并对其进行可视化 |
| 数据集及其条目筛选 | 使得用户可以通过标签、内容等方式对数据集和其中的条目进行筛选 | 1. 为数据集设置相应的标签,并提供根据标签筛选的功能 2. 可以根据数据集条目的内容进行筛选 3. 可以组合数据集条目的内容满足的条件,进行复杂地筛选 |
| 可视化页面提供数据和可视化的对应 | 使用户可以在可视化界面直观地看到数据和可视化图片的对应关系 | 1. 提供数据和可视化图片的对应关系 |
| 视觉效果优化 | 提供更好的首页展示效果 | 1. 提供一个有良好视觉效果的首页,对项目进行介绍 |
原型设计
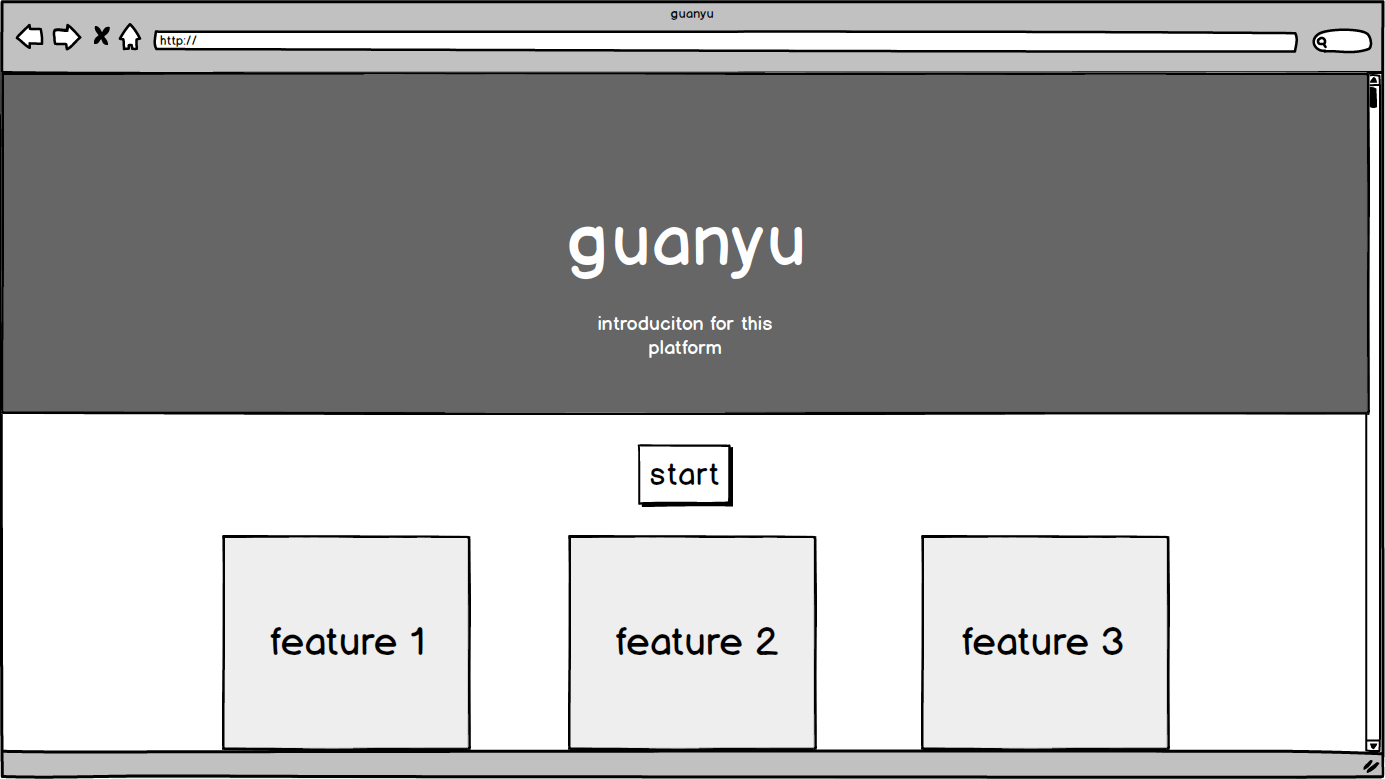

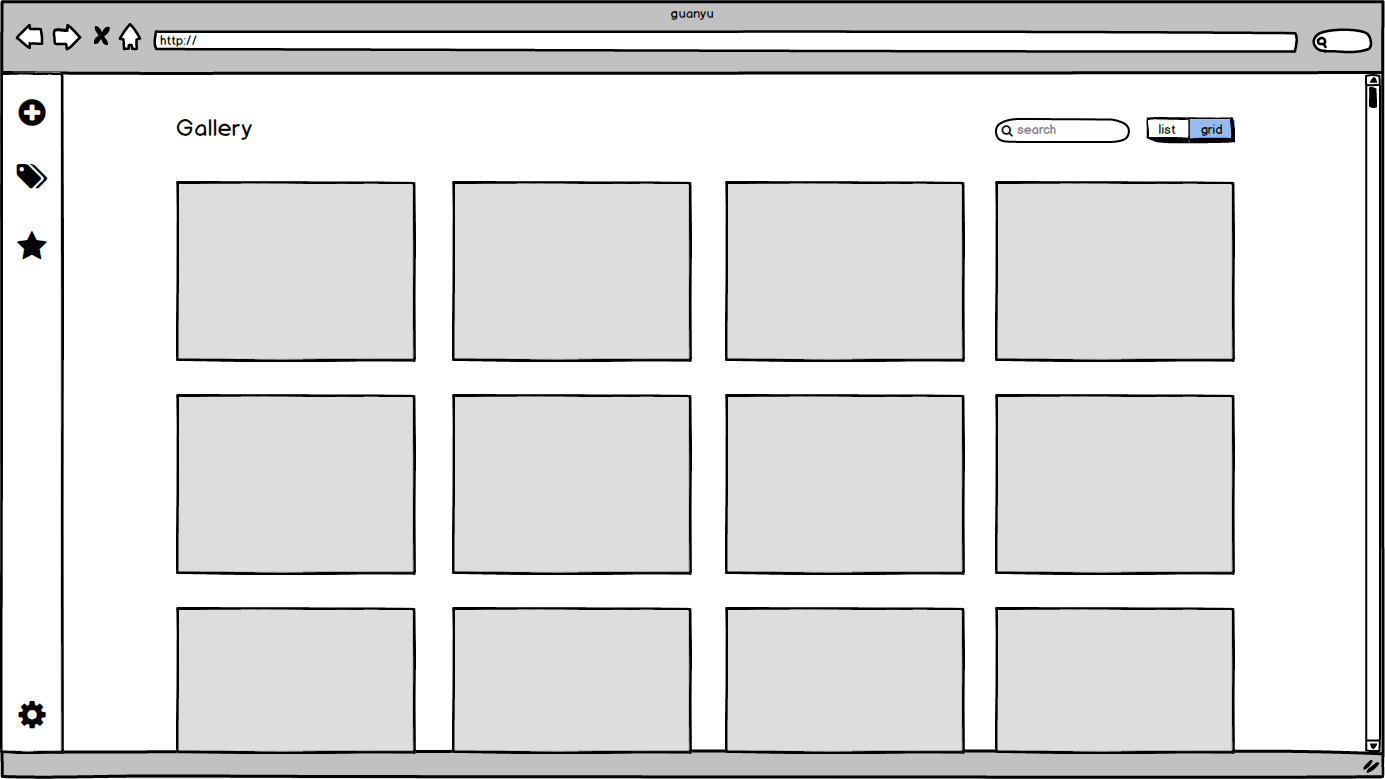
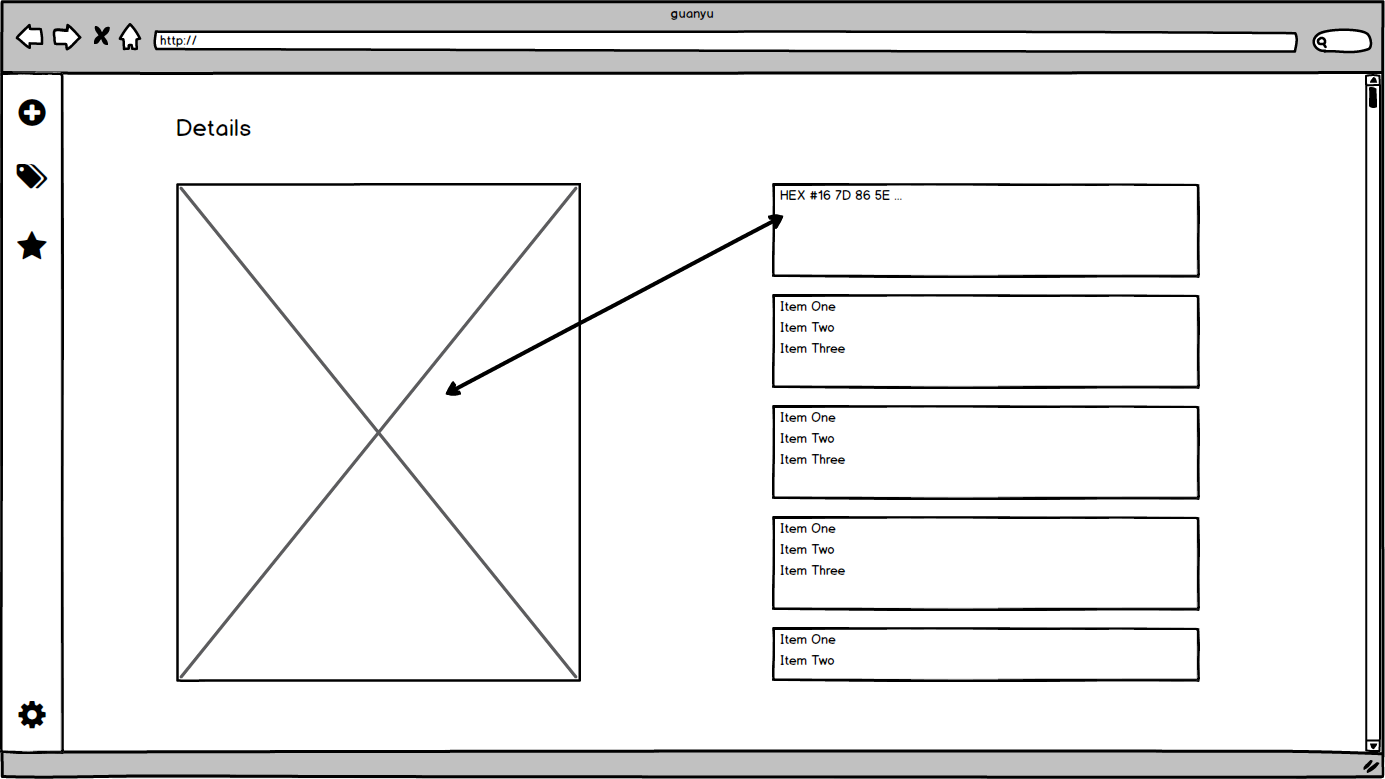
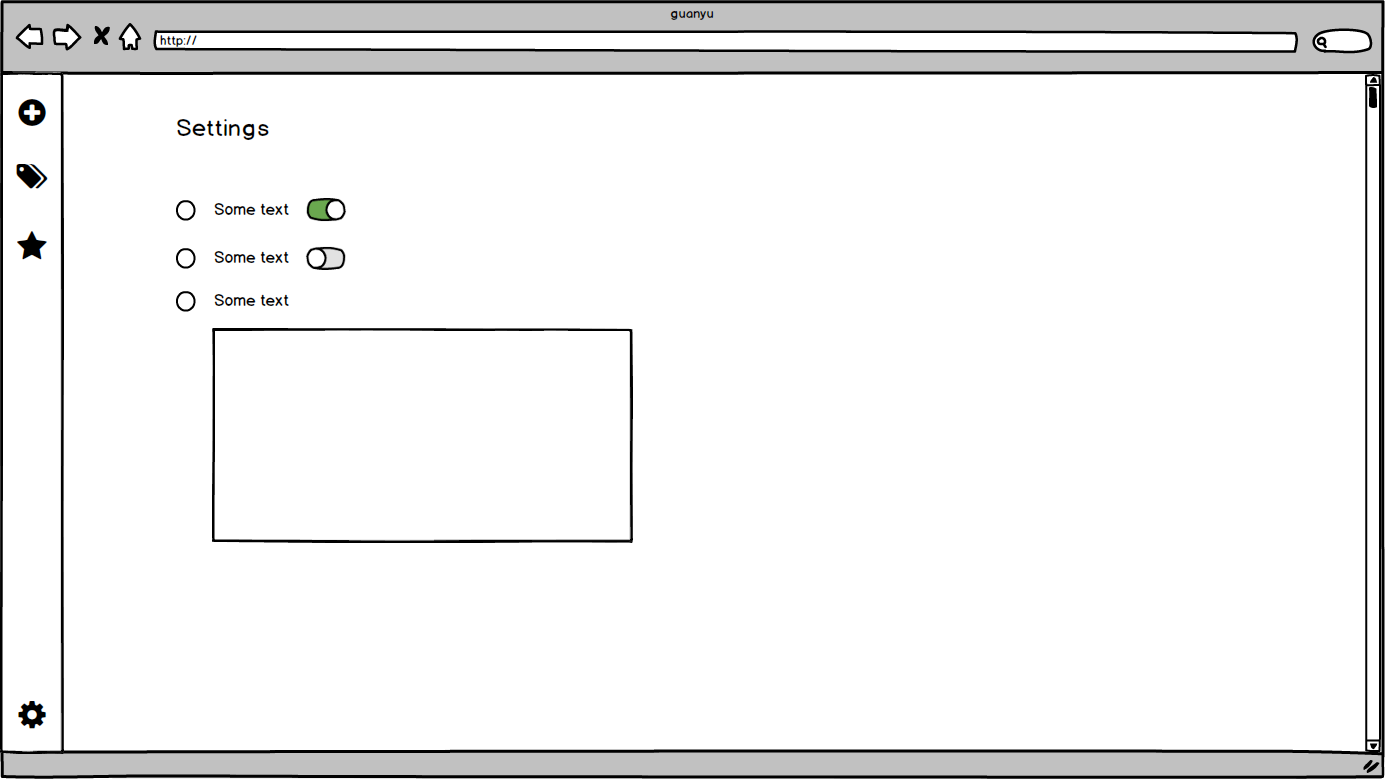
边界条件
- 网站访问量过大无法响应新的请求:给出相应提示,并引导用户尝试本地部署
- 不支持的数据集:给出相应提示,并引导用户到反馈页面
- 临时文件大小超限:提示用户清理磁盘
- 不支持的浏览器平台:提示浏览器不支持,并列出支持的常见浏览器
产品目标
1.产品应当可以实现哪些功能和效果?请精确详细地进行描述。
从用户角度分析,我们的产品将会提供以下功能:
- 管理数据集功能——用户可以自行添加我们所支持的种类的数据集,或者删除曾经上传过的但不再需要的数据集。
- 查看数据集功能——对于用户所上传的合法数据集,我们会对该数据集进行可视化处理并展示。
- 筛选数据集功能——我们会分析数据集的"格式配置文件",并得出一些可以用作筛选的字段,用户可以选择某一字段并输入相应的筛选范围,我们会先将结果筛选后再进行可视化处理与展示。
- 解析数据集功能——我们可以对所展示的可视化载体上标出该数据集格式文件每一字段所表示含义的位置,以辅助用户理解每一字段的含义
- 反馈功能——用户可以向我们进行反馈
2.需要积累多少真实用户?注意请不要使用fake data。
3.需要达成日活跃用户多少的目标?日活跃用户数量通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户)。
在学期截止前,我们将会以朋友圈、QQ空间、北航各院系校内内群、所属企业群等为渠道进行用户的推广与宣传,因此我们将我们所能推广到的人群进行类型划分,以进行产品积累用户估计与日活跃量分析。接下来将粗略的给出预计累计用户量以日活跃用户量估计。
累计用户估计方式:
- 我们将所能推广到的人群按照学习场所、工作场所等进行类型划分,并判断其所属的典型用户。统计指标包括
total_number(总人数)与relevance(相关性)。其中总人数为我们所能推广到的这一类人群的总人数,相关性指某一类人群与所属于的典型用户的归属程度,也就是这一类人群中属于该类典型用户的占比。将total_num与relevance做乘积运算可以得到在这类人群中的潜在典型用户有多少。 - 得到每一类典型用户的潜在数目后,我们会用以下指标:
advertised_percent——受宣发程度,也就是这一类人群中实际收到我们宣发消息的人数占比
willing_percent——使用意愿程度,表示这一类人群中收到我们选发消息后有意愿进行下载安装或者使用的人数占比
spread_percent——传播程度,表示该类人群使用过我们的产品后,愿意向周边人群进行介绍或推荐的人数占比
则我们actual_user(累计用户量估计)可以通过潜在用户数目与上述三个指标的乘积得到。
日活跃量估计方式:
-
由于日活跃量受累计用户量影响较大,因此我们上述累计用户作为基础进行分析。
对于每一类典型用户,我们会用以下指标进行评估:
stickness——用户粘性,表示该类典型用户一周内愿意使用该产品的天数占比。注:对于用户粘性指标,我们不考虑“新鲜感”这一参数对用户粘性的影响(一般来产品刚下载安装时,用户对产品具有新鲜感,短期内更乐意使用该产品),因此只是一个粗略估计。
累计用户估计量表格:
| kind | type | all_number (总人数) |
relevance (相关性) |
potential_typical_num (潜在典型用户数目) |
|---|---|---|---|---|
| 入门深度学习的高校学生 | 北航人工智能研究学院、北航计算机学院、北航软件工程学院等与深度学习相关性较大的学院 | 1500 | 6.7% | 100 |
| 北航其它与深度学习相关性较小的学院 | 7500 | 1% | 75 | |
| 通过宣发途径所能联系到的其它高校的学生 | 150 | 2% | 3 | |
| 模型设计与模型优化等相关从业者 | 商汤/字节跳动等企业中使用到人工智能技术的部门 | 100 | 80% | 80 |
| 深度学习相关研究者 | 北航人工智能研究方向研究生 | 87 | 100% | 87 |
| 北航智能机器人、智能控制方向研究生 | 300 | 20% | 60 | |
| 北航计算机应用方向,如计算机视觉、自然语言处理等研究生 | 100 | 25% | 25 | |
| 用作教学的教师 | 北航人工智能教学团队 | 30 | 80% | 24 |
故潜在典型用户估计量为:454(人)
接下来估计潜在典型用户到实际用户的转化结果:
| kind | effective_typical_num (典型用户数目) |
advertised_percent (受宣发比例) |
willing_percent (使用意愿占比) |
spread_percent (传播人数占比) |
acture_user_number (实际用户数目) |
|---|---|---|---|---|---|
| 入门深度学习的高校学生 | 178 | 10% | 20% | 20% | 4 |
| 模型设计与模型优化等相关从业者 | 80 | 20% | 3.3% | 50% | 0.5 |
| 深度学习相关研究者 | 172 | 10% | 25% | 33% | 5.5 |
| 用作教学的教师 | 30 | 20% | 50% | 50% | 4.5 |
故实际累计用户量估计为:15人(向上取整)
但由于开发团队自己的使用、课程组的体验以及开发团队对熟悉朋友的安利会增加用户量,故最终的实际累计用户量估计为28人。
日活跃量估计表格:
| kind | acture_user_number (实际用户数目) |
stickness | Daily_active |
|---|---|---|---|
| 入门深度学习的高校学生 | 4 | 14.3% | 0.5 |
| 模型设计与模型优化等相关从业者 | 0.5 | 7.1% | 0~1 |
| 深度学习相关研究者 | 5.5 | 5% | 0.25 |
| 用作教学的教师 | 4 | 28.6% | 1 |
故日活跃量人数估计为:1~2人
不过由于用户下载安装时间的不同(上文所述的新鲜感),某一时期内的日活量统计可能出现高于上述统计值的情况,再加上开发团队自己使用以及课程组的体验,日活跃量人数峰值估计可达8~10人,稳定时期日活跃量估计可达2~4人
4.需要在系统内部积累多少数据资源?例如题目、做题记录、讨论数据等。
我们会在系统内存储一些常见数据集资源文件,以向用户展示我们系统会怎样处理这些数据集,从而起到引导用户理解与使用的作用。
由于alpha阶段我们暂只打算支持常见图像数据集的可视化处理,因此在这一阶段我们会在内部存储经典的MNIST图像数据集等。而beta阶段我们可能会支持更多种类的数据集,如视频数据集、音频数据集,在这一阶段我们会在内部额外存储FSDD音频数据集与YouTube-BoundingBoxes视频数据集。
6.对于需要发布的包应用(例如pip包、gem包、maven包),需要打包成到什么样的程度?是否在一些官方平台(例如Github、Python的Pypi、Ruby的RubyGem)上正式部署发布?并达成下载安装量多少的目标?
为了尽量减少用户安装我们产品的工作量,我们会将我们产品打包到用户只需要点击exe文件,就能够使用我们产品的程度。并且我们会将打包后的产品部署在Github和Pypi两个官方平台上。结合前面的累计用户量分析,我们预计在学期截至时两个平台上共有25~30次的下载安装量。
数据收集
收集范围
| 网页端 | 本地部署端 | |
|---|---|---|
| 前置说明 | 暂不考虑用户权限情况: 默认情况用户拥有查看权限 |
可能引入用户体验改进计划: 以收集某些偏隐私的信息 |
| 可以收集 | 总访问量[√] | 总下载量[√] |
| 是否需要收集 以[√]/[x]表示 |
日访问量[√] | 各功能使用量[√] |
| 目标 以{}表示 |
各时段访问量[√] | |
| 在线时间[√] | ||
| 各数据集访问量[√] | ||
| 用户反馈[√] |
现实意义
网页端
总访问量(\(V_{total}\))量化表示了我们软件的总体推广程度;
日访问量(\(V_{daily}\))量化表示了我们软件的单日使用情况;
各时段访问量(\(V_{hourly}\))可以用于得到我们软件的日使用热度图,从而让我们对不同时间段的网站负载情况进行直观了解;
在线时间(\(t_{online}\))与日访问量结合,可以量化表示我们的日活跃用户数(\(U_{active}\)),定义如下:
各数据集访问量(\(V_{dataset}\))可以用于得到最近访问较多的数据集,方便用户进行了解;
用户反馈(Feedback)是直接让我们了解用户想法的途径。
本地部署端
总下载量(\(D_{total}\))量化表示了我们软件的总体推广程度;
用户加入用户体验改进计划后,我们会收集以下数据:
各功能使用量(\(UC_{function}\))可以用于得到我们软件的功能使用热度图,从而让我们对不同功能的使用情况进行直观了解,对使用频率较少的功能收集相关用户反馈后进行改进。
准备工作
网页端
分时段(每小时、每日、总)网站访问量:可直接在服务器端统计;
关于在线时间:可能会通过session和cookie的方式存取用户临时的使用情况,进而统计在线时间(相关技术论证有待进一步讨论);
各数据集访问量:可直接在服务器端统计;
用户反馈:我们会给用户提供反馈入口(邮件、GitLab issues 网址)。
本地部署端
总下载量:可直接通过pypi统计;
各功能使用量:可能会通过接入第三方接口的方式嵌入脚本,用户使用功能时进行统计,我们通过第三方接口获取这部分信息(相关技术论证有待进一步讨论)。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号