

2.Hadoop演进与Hadoop生态
1.了解对比Hadoop不同版本的特性,可以用图表的形式呈现。
Apache Hadoop:Apache Hadoop是一款支持数据密集型分布式应用并以Apache 2.0许可协议发布的开源软件框架。它支持在商品硬件构建的大型集群上运行的应用程序。Hadoop是根据Google公司发表的MapReduce和Google档案系统的论文自行制作而成。称为社区版Hadoop。
第三方发行版Hadoop:Hadoop遵从Apache开源协议,用户可以免费地任意使用和修改Hadoop,也正因此,市面上出现了很多Hadoop版本。其中有很多厂家在Apache Hadoop的基础上开发自己的Hadoop产品,比如Cloudera的CDH,Hortonworks的HDP,大快的DKhadoop产品等。
Apache社区版本
优点:
- 完全开源免费。
- 社区活跃
- 文档、资料详实
缺点:
- 复杂的版本管理。版本管理比较混乱的,各种版本层出不穷,让很多使用者不知所措。
- 复杂的集群部署、安装、配置。通常按照集群需要编写大量的配置文件,分发到每一台节点上,容易出错,效率低下。
- 复杂的集群运维。对集群的监控,运维,需要安装第三方的其他软件,如ganglia,nagois等,运维难度较大。
- 复杂的生态环境。在Hadoop生态圈中,组件的选择、使用,比如Hive,Mahout,Sqoop,Flume,Spark,Oozie等等,需要大量考虑兼容性的问题,版本是否兼容,组件是否有冲突,编译是否能通过等。经常会浪费大量的时间去编译组件,解决版本冲突问题。
第三方发行版本(如CDH,HDP,MapR等)
优点:
- 基于Apache协议,100%开源。
- 版本管理清晰。比如Cloudera,CDH1,CDH2,CDH3,CDH4等,后面加上补丁版本,如CDH4.1.0 patch level 923.142,表示在原生态Apache Hadoop 0.20.2基础上添加了1065个patch。
- 比Apache Hadoop在兼容性、安全性、稳定性上有增强。第三方发行版通常都经过了大量的测试验证,有众多部署实例,大量的运行到各种生产环境。
- 版本更新快。通常情况,比如CDH每个季度会有一个update,每一年会有一个release。
- 基于稳定版本Apache Hadoop,并应用了最新Bug修复或Feature的patch
- 提供了部署、安装、配置工具,大大提高了集群部署的效率,可以在几个小时内部署好集群。
- 运维简单。提供了管理、监控、诊断、配置修改的工具,管理配置方便,定位问题快速、准确,使运维工作简单,有效。
缺点:
- 涉及到厂商锁定的问题。(可以通过技术解决)
对比版选择:DKhadoop发行版、cloudera发行版、hortonworks发行版。
1、DKhadoop发行版:有效的集成了整个HADOOP生态系统的全部组件,并深度优化,重新编译为一个完整的更高性能的大数据通用计算平台,实现了各部件的有机协调。因此DKH相比开源的大数据平台,在计算性能上有了高达5倍(最大)的性能提升。DKhadoop将复杂的大数据集群配置简化至三种节点(主节点、管理节点、计算节点),极大的简化了集群的管理运维,增强了集群的高可用性、高可维护性、高稳定性。
2、Cloudera发行版:CDH是Cloudera的hadoop发行版,完全开源,比Apache hadoop在兼容性,安全性,稳定性上有增强。
3、Hortonworks发行版:Hortonworks 的主打产品是Hortonworks Data Platform (HDP),也同样是100%开源的产品,其版本特点:HDP包括稳定版本的Apache Hadoop的所有关键组件;安装方便,HDP包括一个现代化的,直观的用户界面的安装和配置工具。
2.Hadoop生态的组成、每个组件的作用、组件之间的相互关系,以图例加文字描述呈现。
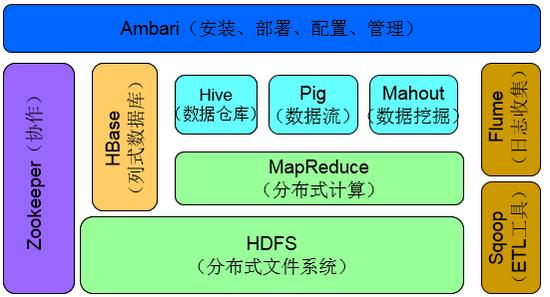
Hadoop生态系统组件主要包括:MapReduce、HDFS、HBase、Hive、Pig、Zookeeper、Mahout
MapReduce(分布式计算)
主要由Google Reduce而来,它简化了大型数据的处理,是一个并行的,分布式处理的编程模型。
hadoop2.0它是基于YARN框架构建的。YARN的全称是Yet-Another-Resource-Negotiator。Yarn可以运用在S3|Spark等上。
HDFS(分布式文件系统)
它是由Google File System而来,全称是Hadoop Distributed File System,是Hadoop的分布式文件系统,有许多机器组成的,可以存储大型数据文件。
它是由NameNode和DataNode组成,NameNode可以配置成HA(高可用),避免单点故障。一般用Zookeeper来处理。两个NameNode是同步的。
Hive(数据仓库)
它是Hadoop的数据仓库(DW),它可以用类似SQL的语言HSQL来操作数据,很是方便,主要用来联机分析处理OLAP(On-Line Analytical Processing),进行数据汇总|查询|分析。
HBase(列式数据库)
它是由Google BigTable而来。是Hadoop的数据库。HBase底层还是利用的Hadoop的HDFS作为文件存储系统,可以利用Hadoop的MR来处理HBase的数据,它也通常用Zookeeper来做协同服务。
Zookeeper(协作)
它是一个针对大型分布式系统的可靠协调系统,在Hadoop|HBase|Strom等都有用到,它的目的就是封装好复杂易出错的关键服务,提供给用户一个简单|可靠|高效|稳定的系统。提供配置维护|分布式同步|名字服务等功能,Zookeeper主要是通过lead选举来维护HA或同步操作等
Pig(数据流)
它提供一个引擎在Hadoop并行执行数据流。它包含了一般的数据操作如join|sort|filter等,它也是使用MR来处理数据。
Mahout(数据挖掘)
它是机器学习库。提供一些可扩展的机器学习领域经典算法的实现,目的是帮助开发人员更加方便快捷地创建智能应用程序。Mahout包含许多实现,包括聚类、分类、推荐算法等。
3.官网学习Hadoop的安装与使用,用文档的方式列出步骤与注意事项。
http://www.apache.org/
→Projects
→Projects List
一、基础环境
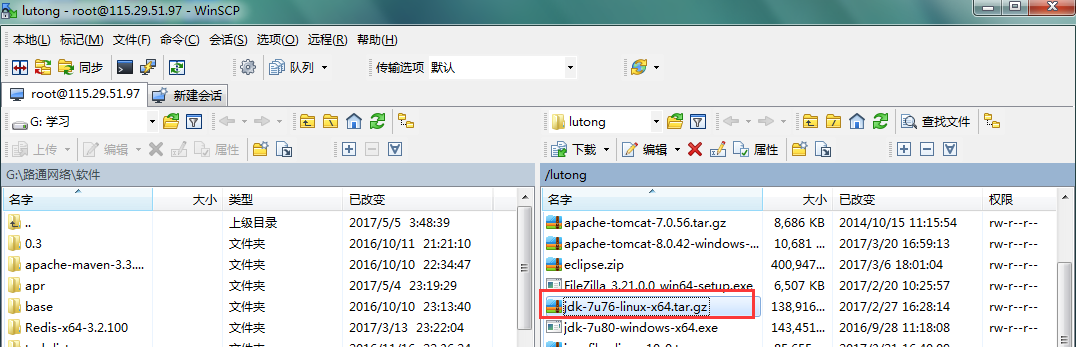
1.1 安装说明


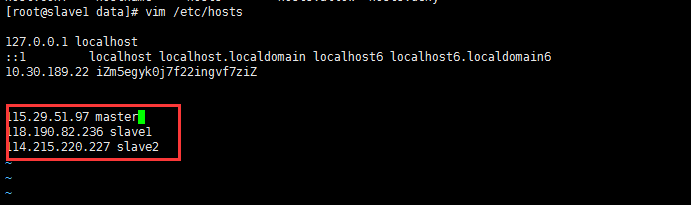
二、Host配置
三、Hadoop的安装与配置
3.1 创建文件目录
3.2 下载
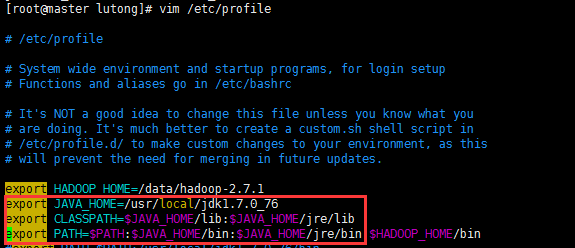
3.3 配置环境变量
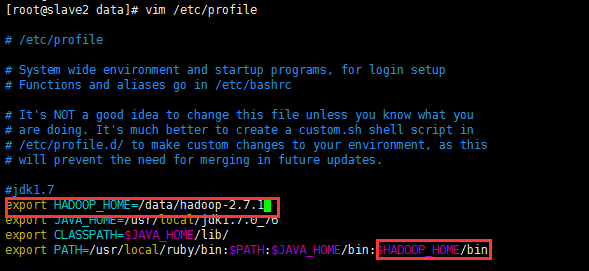
3.4 Hadoop的配置

1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed under the Apache License, Version 2.0 (the "License"); 5 you may not use this file except in compliance with the License. 6 You may obtain a copy of the License at 7 8 http://www.apache.org/licenses/LICENSE-2.0 9 Unless required by applicable law or agreed to in writing, software 10 distributed under the License is distributed on an "AS IS" BASIS, 11 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 See the License for the specific language governing permissions and 13 limitations under the License. See accompanying LICENSE file. 14 --> 15 16 <!-- Put site-specific property overrides in this file. --> 17 <configuration> 18 <property> 19 <name>hadoop.tmp.dir</name> 20 <value>file:/data/hdfs/tmp</value> 21 <description>A base for other temporary directories.</description> 22 </property> 23 <property> 24 <name>io.file.buffer.size</name> 25 <value>131072</value> 26 </property> 27 <property> 28 <name>fs.default.name</name> 29 <value>hdfs://master:9000</value> 30 </property> 31 <property> 32 <name>hadoop.proxyuser.root.hosts</name> 33 <value>*</value> 34 </property> 35 <property> 36 <name>hadoop.proxyuser.root.groups</name> 37 <value>*</value> 38 </property> 39 </configuration>
1 <?xml version="1.0" encoding="UTF-8"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed under the Apache License, Version 2.0 (the "License"); 5 you may not use this file except in compliance with the License. 6 You may obtain a copy of the License at 7 8 http://www.apache.org/licenses/LICENSE-2.0 9 10 Unless required by applicable law or agreed to in writing, software 11 distributed under the License is distributed on an "AS IS" BASIS, 12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 See the License for the specific language governing permissions and 14 limitations under the License. See accompanying LICENSE file. 15 --> 16 17 <!-- Put site-specific property overrides in this file. --> 18 19 <configuration> 20 <property> 21 <name>dfs.replication</name> 22 <value>2</value> 23 </property> 24 <property> 25 <name>dfs.namenode.name.dir</name> 26 <value>file:/data/hdfs/name</value> 27 <final>true</final> 28 </property> 29 <property> 30 <name>dfs.datanode.data.dir</name> 31 <value>file:/data/hdfs/data</value> 32 <final>true</final> 33 </property> 34 <property> 35 <name>dfs.namenode.secondary.http-address</name> 36 <value>master:9001</value> 37 </property> 38 <property> 39 <name>dfs.webhdfs.enabled</name> 40 <value>true</value> 41 </property> 42 <property> 43 <name>dfs.permissions</name> 44 <value>false</value> 45 </property> 46 </configuration>
注意:dfs.namenode.name.dir和dfs.datanode.data.dir的value填写对应前面创建的目录
复制template,生成xml,命令如下:
cp mapred-site.xml.template mapred-site.xml
1 <?xml version="1.0"?> 2 <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> 3 <!-- 4 Licensed under the Apache License, Version 2.0 (the "License"); 5 you may not use this file except in compliance with the License. 6 You may obtain a copy of the License at 7 8 http://www.apache.org/licenses/LICENSE-2.0 9 10 Unless required by applicable law or agreed to in writing, software 11 distributed under the License is distributed on an "AS IS" BASIS, 12 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 13 See the License for the specific language governing permissions and 14 limitations under the License. See accompanying LICENSE file. 15 --> 16 17 <!-- Put site-specific property overrides in this file. --> 18 19 <configuration> 20 21 <property> 22 <name>mapreduce.framework.name</name> 23 <value>yarn</value> 24 </property> 25 26 </configuration>
1 <?xml version="1.0"?> 2 <!-- 3 Licensed under the Apache License, Version 2.0 (the "License"); 4 you may not use this file except in compliance with the License. 5 You may obtain a copy of the License at 6 7 http://www.apache.org/licenses/LICENSE-2.0 8 9 Unless required by applicable law or agreed to in writing, software 10 distributed under the License is distributed on an "AS IS" BASIS, 11 WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. 12 See the License for the specific language governing permissions and 13 limitations under the License. See accompanying LICENSE file. 14 --> 15 <configuration> 16 17 <!-- Site specific YARN configuration properties --> 18 <property> 19 <name>yarn.resourcemanager.address</name> 20 <value>master:18040</value> 21 </property> 22 <property> 23 <name>yarn.resourcemanager.scheduler.address</name> 24 <value>master:18030</value> 25 </property> 26 <property> 27 <name>yarn.resourcemanager.webapp.address</name> 28 <value>master:18088</value> 29 </property> 30 <property> 31 <name>yarn.resourcemanager.resource-tracker.address</name> 32 <value>master:18025</value> 33 </property> 34 <property> 35 <name>yarn.resourcemanager.admin.address</name> 36 <value>master:18141</value> 37 </property> 38 <property> 39 <name>yarn.nodemanager.aux-services</name> 40 <value>mapreduce.shuffle</value> 41 </property> 42 <property> 43 <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> 44 <value>org.apache.hadoop.mapred.ShuffleHandler</value> 45 </property> 46 </configuration>

最后,将整个hadoop-2.7.1文件夹及其子文件夹使用scp复制到slave1和slave2的相同目录中:
scp -r /data/hadoop-2.7.1 root@slave1:/data
四、运行Hadoop
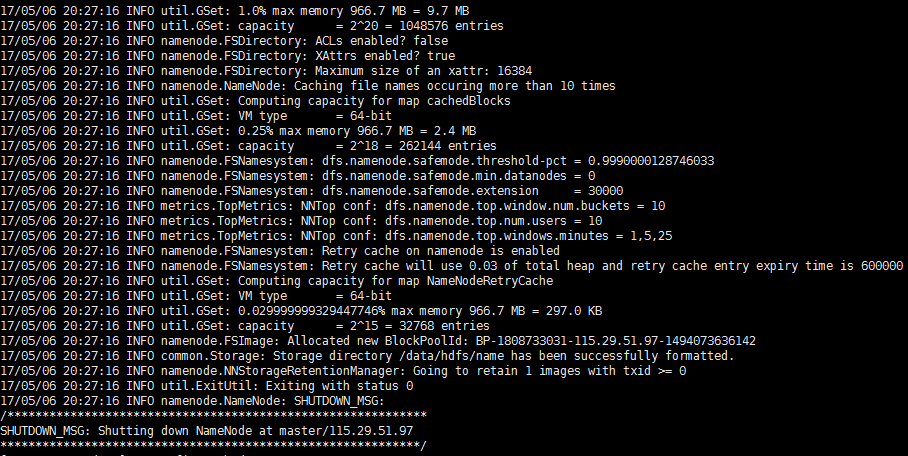
4.1 格式化NameNode
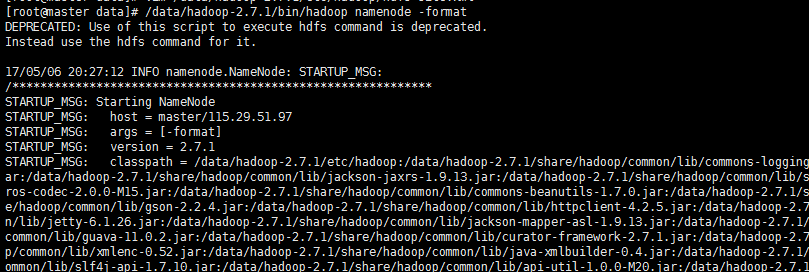
最后的执行结果如下图:
4.2 启动NameNode


在Master上执行jps命令,得到如下结果:

4.3 启动DataNode

master

slave1

slave2

4.4 运行YARN
说明ResourceManager运行正常。

4.5 查看集群是否启动成功:
jps
Master显示:
SecondaryNameNode
ResourceManager
NameNode
Slave显示:
NodeManager
DataNode
五、测试hadoop
5.1 测试HDFS
最后测试下亲手搭建的Hadoop集群是否执行正常,测试的命令如下图所示:

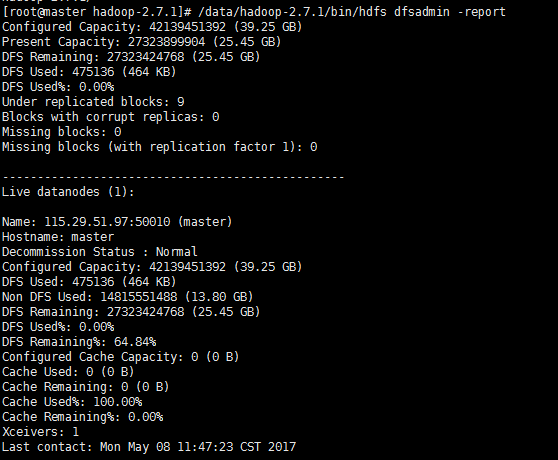
5.2 查看集群状态
/data/hadoop-2.7.1/bin/hdfs dfsadmin -report
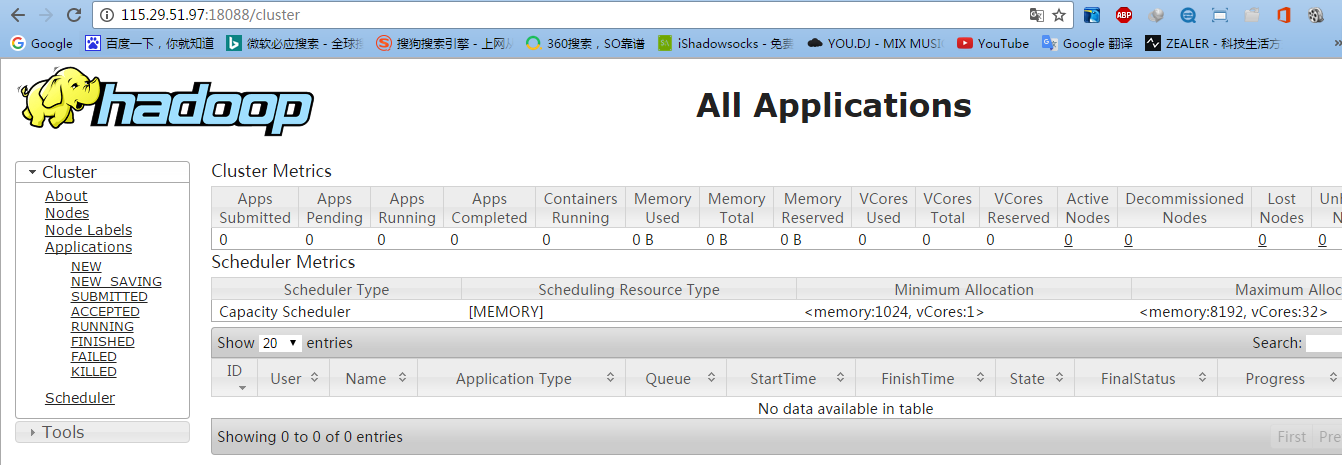
5.3 测试YARN
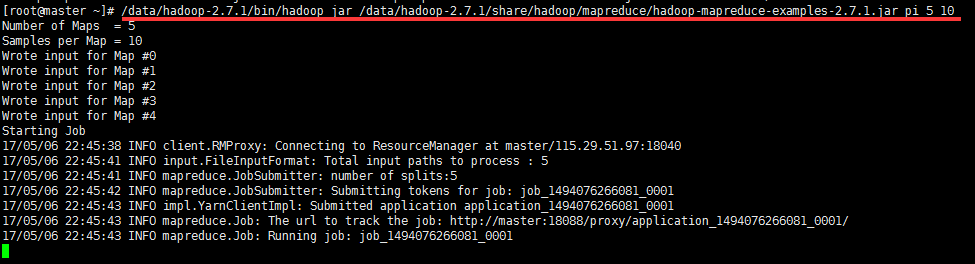
5.4 测试mapreduce
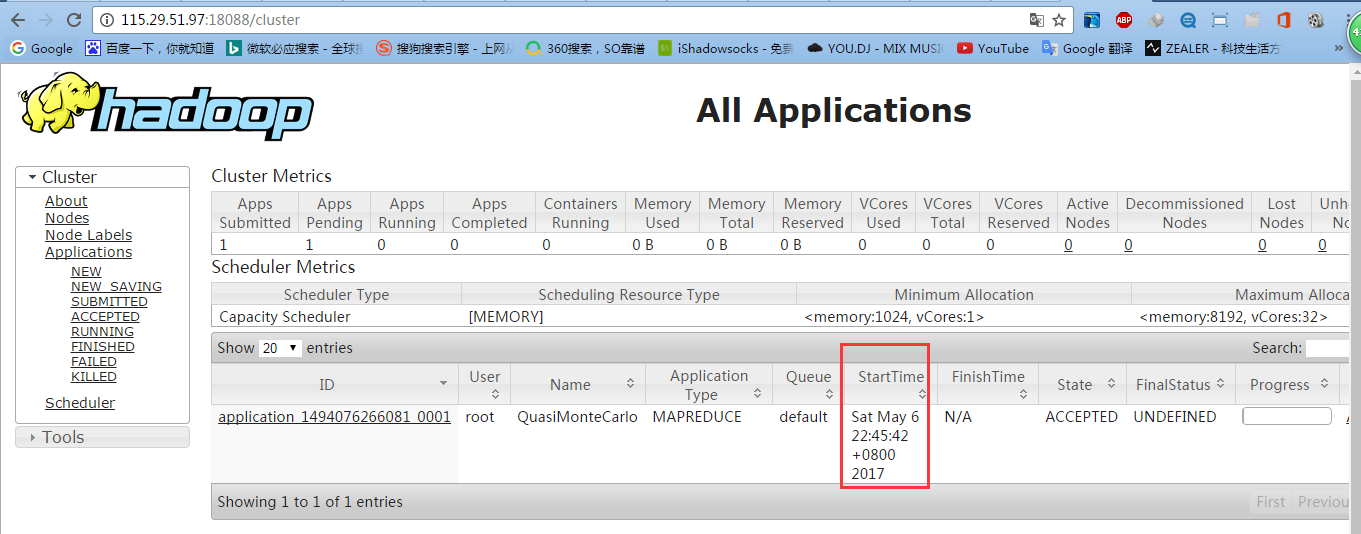
5.5 测试查看HDFS:
http://115.29.51.97:50070/dfshealth.html#tab-overview
六、配置运行Hadoop中遇见的问题
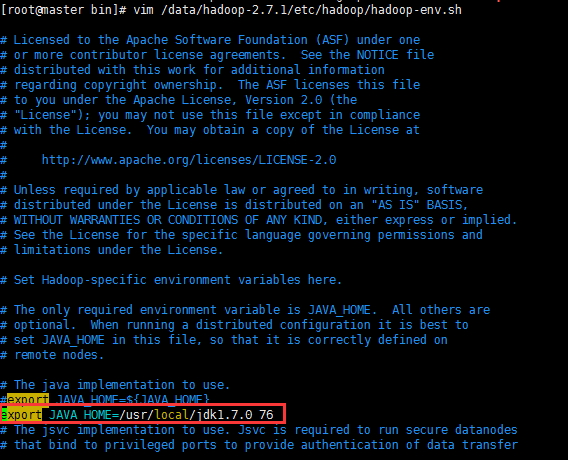
JAVA_HOME未设置

则需要/data/hadoop-2.7.1/etc/hadoop/hadoop-env.sh,添加JAVA_HOME路径
4.评估华为hadoop发行版本的特点与可用性。
一.特点
华为FusionInsight HD发行版紧随开源社区的最新技术,快速集成最新组件,并在可靠性、安全性、管理性等方面做企业级的增强,持续改进,持续保持技术领先。
FusionInsight HD的企业级增强主要表现在以下几个方面。
安全
- 架构安全
FusionInsight HD基于开源组件实现功能增强,保持100%的开放性,不使用私有架构和组件。
- 认证安全
- 基于用户和角色的认证统一体系,遵从帐户/角色RBAC(Role-Based Access Control)模型,实现通过角色进行权限管理,对用户进行批量授权管理。
- 支持安全协议Kerberos,FusionInsight HD使用LDAP作为帐户管理系统,并通过Kerberos对帐户信息进行安全认证。
- 提供单点登录,统一了Manager系统用户和组件用户的管理及认证。
- 对登录FusionInsight Manager的用户进行审计。
- 文件系统层加密
Hive、HBase可以对表、字段加密,集群内部用户信息禁止明文存储。
- 加密灵活:加密算法插件化,可进行扩充,亦可自行开发。非敏感数据可不加密,不影响性能(加密约有5%性能开销)。
- 业务透明:上层业务只需指定敏感数据(Hive表级、HBase列族级加密),加解密过程业务完全不感知。
可靠
- 所有管理节点组件均实现HA(High Availability)
业界第一个实现所有组件HA的产品,确保数据的可靠性、一致性。NameNode、Hive Server、HMaster、Resources Manager等管理节点均实现HA。
- 集群异地灾备
业界第一个支持超过1000公里异地容灾的大数据平台,为日志详单类存储提供了迄今为止可靠性最佳实践。
- 数据备份恢复
表级别全量备份、增量备份,数据恢复(对本地存储的业务数据进行完整性校验,在发现数据遭破坏或丢失时进行自恢复)。
易用
- 统一运维管理
Manager作为FusionInsight HD的运维管理系统,提供界面化的统一安装、告警、监控和集群管理。
- 易集成
提供北向接口,实现与企业现有网管系统集成;当前支持Syslog接口,接口消息可通过配置适配现有系统;整个集群采用统一的集中管理,未来北向接口可根据需求灵活扩展。
- 易开发
提供自动化的二次开发助手和开发样例,帮助软件开发人员快速上手。
二.可用性
金融领域
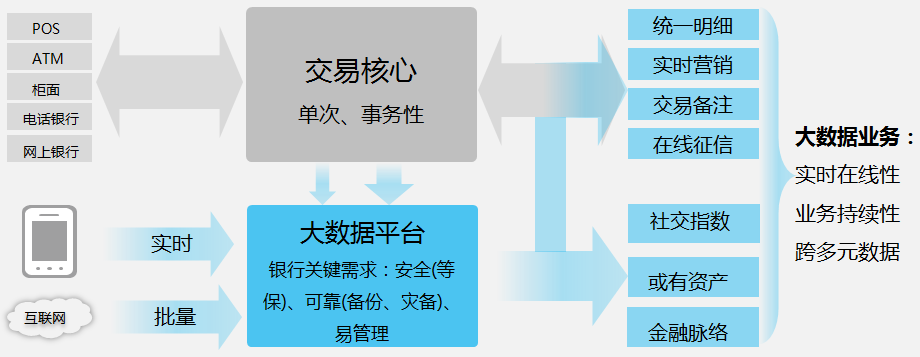
场景特点
面对互联网金融的竞争压力,金融企业急需重构以大数据分析挖掘为基础的决策和服务体系,提升自身竞争力和客户满意度。在大数据时代,银行将从以交易为中心转向以数据为中心,以应对更多维、更大量、更实时的数据和互联网业务的挑战。
华为FusionInsight HD可以从不同方面解决金融企业的问题,提升其竞争力。例如:
- 历史交易明细实时查询业务
实时查询用户的历史交易明细,能够将查询范围从1年提升到7年以上;能够实现百TB级历史数据表的毫秒级查询。
- 实时征信业务
用户信用卡征信时间由3天左右减少到10分钟以内。
- 小微贷业务预测
TOP 1000小微贷倾向用户预测准确率比传统模式提高40倍以上。
- 精准营销
- 极大缩短分布式网银日志的收集周期,基于网银日志的用户行为统计与分析,提供精确营销,极大提升了网银用户体验效果。
- 只需不到原来20%的推荐短信,就可基本覆盖原来全部的有效购买用户,实现精准营销。
运营商领域

场景特点
随着大数据时代的到来,运营商面临如下挑战。
- 需要处理的数据数量、种类呈现爆炸式增长,尤其对于非结构化数据的处理,现有架构的分析速度十分缓慢。
- 现有应用系统以烟囱式建设,导致数据重复存储,跨系统数据共享难度大,业务决策分析缓慢。
华为FusionInsight HD产品可以从不同方面解决运营商问题,提升其竞争力。例如:
- 构建统一的大数据详单集中平台和经营详单数据分析平台,从架构上根本解决运营商问题。
- 历史话单查询,客户可实时查询的历史话单由3个月提升到6个月至24个月。
- 经营详单数据并发分析,由原来的5天减少到1天。
- 构建统一的PB级大数据平台,统一存储业务数据。利用大数据平台分布式计算能力,并发处理各种分析任务,快速获取业务决策结果。
- 缩短新业务推出周期,由原来的1.5个月减少到1周。
- 存量用户挽留,VIP用户离网率大幅降低。
- 在保障数据安全性和隐私性前提下,提供数据共享访问和开放接口,让大数据对外提供共享服务,支撑业务创新与商业成功。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号