ANTLR实现的SQL解析器 - OQL
OQL
使用ANTLR写了个SQL解析器,这样ORM的基本功能就比较完整了。几天的时间比较仓促,所以对于最终目标,还只能算是个雏形。
总体状况
使用SQL解析器的主要优点:
1. 基于解析之后的语法树提供用户操作接口,灵活性非常好,因为达到了对SQL每一部分的完整控制。
2. 对数据库的适应性。
首先可以采用标准SQL,以及部分封装好的特性(例如分页)、函数(例如主要数据库都支持的函数,但语法有一定差异的),使用一个适配器Dialect基于语法树进行翻译。这样能满足绝大部分用途。
如果确实需要使用某数据库的特性,可能只需要修改语法描述文件就能实现,或者对语法树等作少量修改进行配合。
3. 跟LINQ的比较。
a. LINQ具备编译期检查,与VS整合的优点。
b. 根据粗略的了解,感觉LINQ语法树操作起来比较繁琐。
c. 自己完全把握住了整个解析过程,不会受LINQ语法和语法树的限制。
d. 不了解LINQ语法树的开放性,即结构的稳定、兼容性。例如以后添加新的特性,是否会影响到语法树的结构?
类似LINQ to Hinbernate一样,只将LINQ当作查询的输入,而使用自己的ORM实现持久化,中间的可控能力会比较强。虽然LINQ与OQL在功能上重合,只是各有优缺点而已,并且可以采用不错的结合点。
目前的主要缺点:
1. 基于SQL Server的语法。
2. AST语法树看起来以及实现上不大流畅,表达式类体系结构理的不大清楚。
3. 数据库Dialect的机制不好。
以后的目标:
1. 多数据库支持。
不管是纯粹ORM操作,还是OQL或者SQL,都能由数据库dialect自动翻译。
2. 语法: 基于标准DML语法,添加必要的特性。
a. 分页,预计使用select distinct? range(start, end) column1, column2..这样的方式,由数据库dialect向各特定数据库SQL语法进行翻译。SQL Server 2000这种不完整支持的,由dialect辅助完成。
b. 标准函数,常用的SQL 92标准函数应当都能向各个数据库进行翻译,还可以提取一些其它函数,主流数据库都支持且能够进行翻译的。
3. 标准化Query Hints。
目的是在OQL中提供一个性能调优的机会,针对主要Query Hints进行提取,由dialect翻译成各数据库特定语法。
4. Object Query / 标准SQL Query功能。
a. 不象Hibernate要求纯粹的对象模型,OQL使用DomainClass1 inner join DomainClass2 on ...这样的方式。缺点是对象模型的内部结构被暴露,但更具灵活性。以后考虑对对象模型的自动支持,也就是可以使用各种混合方式进行开发。还允许DomainClass和Database Table混合写在OQL中,用于满足类似many-to-many的关联表不会建立DomainClass,又不想用对象属性建立双向映射关系的情况。
b. 程序先给出查询语句,OQL解析出语法树,基于语法树再动态修改,例如根据界面的选择添加查询条件、排序方式、需要的字段等。进一步,一些非必要的关联关系能够在运行时自动、动态确定。
c. 基于语法树进行修改的灵活性,应当能够提供比较灵活的AOP功能,例如AOP方式的数据权限控制。
下一步代办事项:
1. 项目中将用户接口和必要的功能特性进行完善。
2. 语法树结构的完善,表达式类体系的完善,数据库Dialect、O-R Mapping等与OQL结合的机制以及职责的梳理完善。
3. 标准化,主流数据库Dialect。
4. 语法优化(重点是解析性能)。
目前语法大致描述:
Statement: SelectStatement | UnionStatement | InsertStatement | UpdateStatement | DeleteStatement;
SelectStatement: SelectClause FromClause? WhereClause? (GroupByClause Having?)? OrderByClause?;
SelectClause: Columns+;
Column: '*'? | Identifier '.*'
| Expressions Alias?
//MathOperator为数学运算符,例如+, -, *, /, %
Expressions: Expression (MathOperator Expression)*;
//Identifier为字段/属性名,Constant为常量,包括系统变量例如@@identity之类以及字符串等
//Case .. When 语句当作Function处理
Expression: Identifier | Constant | UserVariable | Function | SelectStatement | UnionStatement;
//Where子句采用较标准的运算语法树形式,类EBNF描述
WhereClause: Condition;
Condition: SubCondition ((AND ^ | OR ^) SubCondition)*
SubCondition: '(' Condition ')' | Predicate;
Predicate: Expressions (
ComparisonOperator Expressions //ComparisonOperator为>, <=, !>, Like等比较运算符
| IS NOT? NULL
| IN '(' Expressions (',' Expressions)* ')'
| BETWEEN Expressions AND Expressions
| IN '(' (SelectStatement | UnionStatement) ')'
) |
EXISTS '(' (SelectStatement | UnionStatement) ')';
整体:
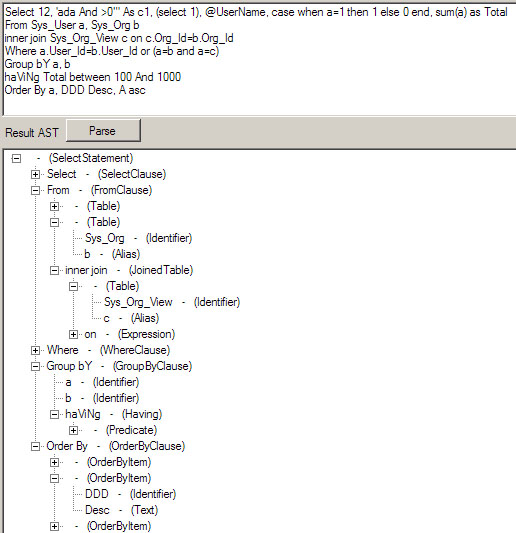
Select子句: Where子句:


解析性能测试:
下面这个SQL应该能够代表绝大部分普通查询情况,循环解析1000次,所用时间在480-600ms之间。其中{0}, {1}是在循环中替换为当前计数,使每次解析的SQL不一样。这样普通情况下,把解析后的语法树进行缓存已经没有太多必要。
使用ANTLR写了个SQL解析器,这样ORM的基本功能就比较完整了。几天的时间比较仓促,所以对于最终目标,还只能算是个雏形。
总体状况
使用SQL解析器的主要优点:
1. 基于解析之后的语法树提供用户操作接口,灵活性非常好,因为达到了对SQL每一部分的完整控制。
2. 对数据库的适应性。
首先可以采用标准SQL,以及部分封装好的特性(例如分页)、函数(例如主要数据库都支持的函数,但语法有一定差异的),使用一个适配器Dialect基于语法树进行翻译。这样能满足绝大部分用途。
如果确实需要使用某数据库的特性,可能只需要修改语法描述文件就能实现,或者对语法树等作少量修改进行配合。
3. 跟LINQ的比较。
a. LINQ具备编译期检查,与VS整合的优点。
b. 根据粗略的了解,感觉LINQ语法树操作起来比较繁琐。
c. 自己完全把握住了整个解析过程,不会受LINQ语法和语法树的限制。
d. 不了解LINQ语法树的开放性,即结构的稳定、兼容性。例如以后添加新的特性,是否会影响到语法树的结构?
类似LINQ to Hinbernate一样,只将LINQ当作查询的输入,而使用自己的ORM实现持久化,中间的可控能力会比较强。虽然LINQ与OQL在功能上重合,只是各有优缺点而已,并且可以采用不错的结合点。
目前的主要缺点:
1. 基于SQL Server的语法。
2. AST语法树看起来以及实现上不大流畅,表达式类体系结构理的不大清楚。
3. 数据库Dialect的机制不好。
以后的目标:
1. 多数据库支持。
不管是纯粹ORM操作,还是OQL或者SQL,都能由数据库dialect自动翻译。
2. 语法: 基于标准DML语法,添加必要的特性。
a. 分页,预计使用select distinct? range(start, end) column1, column2..这样的方式,由数据库dialect向各特定数据库SQL语法进行翻译。SQL Server 2000这种不完整支持的,由dialect辅助完成。
b. 标准函数,常用的SQL 92标准函数应当都能向各个数据库进行翻译,还可以提取一些其它函数,主流数据库都支持且能够进行翻译的。
3. 标准化Query Hints。
目的是在OQL中提供一个性能调优的机会,针对主要Query Hints进行提取,由dialect翻译成各数据库特定语法。
4. Object Query / 标准SQL Query功能。
a. 不象Hibernate要求纯粹的对象模型,OQL使用DomainClass1 inner join DomainClass2 on ...这样的方式。缺点是对象模型的内部结构被暴露,但更具灵活性。以后考虑对对象模型的自动支持,也就是可以使用各种混合方式进行开发。还允许DomainClass和Database Table混合写在OQL中,用于满足类似many-to-many的关联表不会建立DomainClass,又不想用对象属性建立双向映射关系的情况。
b. 程序先给出查询语句,OQL解析出语法树,基于语法树再动态修改,例如根据界面的选择添加查询条件、排序方式、需要的字段等。进一步,一些非必要的关联关系能够在运行时自动、动态确定。
c. 基于语法树进行修改的灵活性,应当能够提供比较灵活的AOP功能,例如AOP方式的数据权限控制。
下一步代办事项:
1. 项目中将用户接口和必要的功能特性进行完善。
2. 语法树结构的完善,表达式类体系的完善,数据库Dialect、O-R Mapping等与OQL结合的机制以及职责的梳理完善。
3. 标准化,主流数据库Dialect。
4. 语法优化(重点是解析性能)。
目前语法大致描述:
Statement: SelectStatement | UnionStatement | InsertStatement | UpdateStatement | DeleteStatement;
SelectStatement: SelectClause FromClause? WhereClause? (GroupByClause Having?)? OrderByClause?;
SelectClause: Columns+;
Column: '*'? | Identifier '.*'
| Expressions Alias?
//MathOperator为数学运算符,例如+, -, *, /, %
Expressions: Expression (MathOperator Expression)*;
//Identifier为字段/属性名,Constant为常量,包括系统变量例如@@identity之类以及字符串等
//Case .. When 语句当作Function处理
Expression: Identifier | Constant | UserVariable | Function | SelectStatement | UnionStatement;
//Where子句采用较标准的运算语法树形式,类EBNF描述
WhereClause: Condition;
Condition: SubCondition ((AND ^ | OR ^) SubCondition)*
SubCondition: '(' Condition ')' | Predicate;
Predicate: Expressions (
ComparisonOperator Expressions //ComparisonOperator为>, <=, !>, Like等比较运算符
| IS NOT? NULL
| IN '(' Expressions (',' Expressions)* ')'
| BETWEEN Expressions AND Expressions
| IN '(' (SelectStatement | UnionStatement) ')'
) |
EXISTS '(' (SelectStatement | UnionStatement) ')';
整体:
Select子句: Where子句:
解析性能测试:
下面这个SQL应该能够代表绝大部分普通查询情况,循环解析1000次,所用时间在480-600ms之间。其中{0}, {1}是在循环中替换为当前计数,使每次解析的SQL不一样。这样普通情况下,把解析后的语法树进行缓存已经没有太多必要。
Select 12, 'ada {0} And >0""' As c1, (select 1), @UserName, case when a=1 then 1 else 0 end, sum(a) as Total
From Sys_User a, Sys_Org b
inner join Sys_Org_View c on c.Org_Id=b.Org_Id and (ccc={1})
Where cast(a.User_Id as varchar)=b.User_Id or (a=b and Total between 100 And 1000)
Group bY a, b
haViNg Total between 100 And 1000
Order By a, DDD Desc, A asc
From Sys_User a, Sys_Org b
inner join Sys_Org_View c on c.Org_Id=b.Org_Id and (ccc={1})
Where cast(a.User_Id as varchar)=b.User_Id or (a=b and Total between 100 And 1000)
Group bY a, b
haViNg Total between 100 And 1000
Order By a, DDD Desc, A asc


 浙公网安备 33010602011771号
浙公网安备 33010602011771号