
Flash attention
Flash attention
#CSE234#
减少IO访存
将输入QKV分块,并保证每个块能够在SRAM (一级缓存)上完成注意力操作,并将结果更新回HBM,从而降低对高带宽内存(HBM)的读写操作。总之,FlashAttention从GPU的内存读写入手,减少了内存读写量,从而实现了2~4倍的速度提升
Key Insight(Green)
avoid reading and writing the attention matrix to and from HBM
- computing the softmax reduction without access to the whole input
- not storing the large intermediate attention matrix for the backward pass.
Analysis(Red)
-
标准sa怎么算
![Screenshot 2025-08-12 at 16.06.37]()
-
Attention计算主要属于Memory Bound操作

Key Design(Blue)
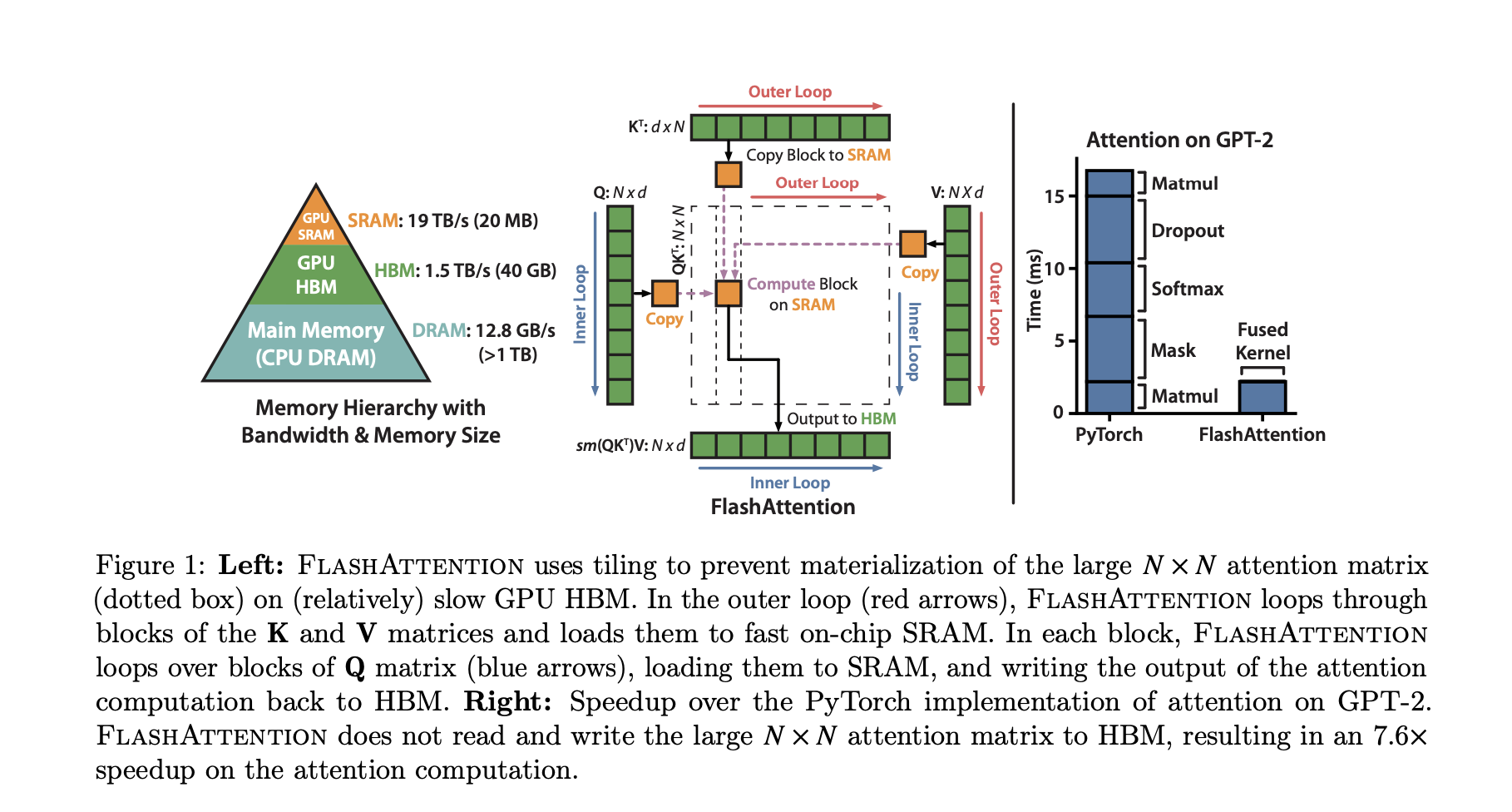
-
tillung:注意力计算-分块计算
避免将中间结果S存入HBM
-
Softmax归一化因子的存储-加速softmax(不希望存、取attn_matrix)
-
具体算法
Algorithm 1 returns O = softmax1QK>oV with O 1N2do FLOPs and requires O 1No additional memory beyond inputs and output. ![Screenshot 2025-08-12 at 16.07.45]()
An Efficient Attention Algorithm With Tiling and Recomputation
- Tiling
- Recomputation
- Implementation details: Kernel fusion
-
Softmax怎么算
- 实时维护每行的最大值和指数和(用于 softmax 归一化),避免存储完整分数矩阵
-
FlashAttn都是加速了什么
- 减少 HBM 读写:标准注意力需读写
O(N²) 的注意力矩阵,而 FlashAttention 通过分块将 HBM 读写量降至O(N²d/M)(M 为 SRAM 大小),避免 HBM 带宽瓶颈; - 核融合(Kernel Fusion) :将分数计算、softmax、加权求和等操作合并为单个 GPU 核函数,减少核启动开销;
- 反向传播优化:通过重计算局部分数替代存储完整注意力矩阵,节省内存并减少 HBM 访问。
- 减少 HBM 读写:标准注意力需读写
-
Backward怎么算的
- 不存储完整注意力矩阵,而是通过重计算局部分数(利用正向保存的中间变量)推导梯度,进一步减少 HBM 读写
-
IO Complexity of FlashAttention
-
Self-attn: $O(Nd + N^2)$ HBM
-
Flash-attn: $O(N2d2M^{-1})$ HBM
-
d 为 head dimension, M 为 SRAM的大小
一般 d (64-128) and M (around 100KB)
-

Experiment(Purple)
也就是三个contributions(原文Intro最后一段)
- Faster Model Training. FlashAttention trains Transformer models faster in wall-clock time. We train BERT-large (seq. length 512) 15% faster than the training speed record in MLPerf 1.1 [58], GPT2 (seq. length 1K) 3 faster than baseline implementations from HuggingFace [87] and Megatron-LM [77], and long-range arena (seq. length 1K-4K) 2.4 faster than baselines.
- Higher Quality Models. FlashAttention scales Transformers to longer sequences, which improves their quality and enables new capabilities. We observe a 0.7 improvement in perplexity on GPT-2 and 6.4 points of lift from modeling longer sequences on long-document classification [13]. FlashAttention enables the first Transformer that can achieve better-than-chance performance on the Path-X [80] challenge, solely from using a longer sequence length (16K). Block-sparse FlashAttention enables a Transformer to scale to even longer sequences (64K), resulting in the first model that can achieve better-than-chance performance on Path-256.
- Benchmarking Attention. FlashAttention is up to 3 faster than the standard attention implementation across common sequence lengths from 128 to 2K and scales up to 64K. Up to sequence length of 512, FlashAttention is both faster and more memory-efficient than any existing attention method, whereas for sequence length beyond 1K, some approximate attention methods (e.g., Linformer) start to become faster. On the other hand, block-sparse FlashAttention is faster than all existing approximate attention methods that we know of.
问题:能不能这么随便,contribution就放实验结果;这合理吗?合理(
Other
- 能不能用来加速Entropy计算,有没有attn_map的生成
- 多GPU下的TP,怎么用这个
- 代码实现 #TODO#
#10423#

 浙公网安备 33010602011771号
浙公网安备 33010602011771号