PySpark分布式项目运行流程
1. PySpark 是 Spark 为 Python 开发者提供的 API。
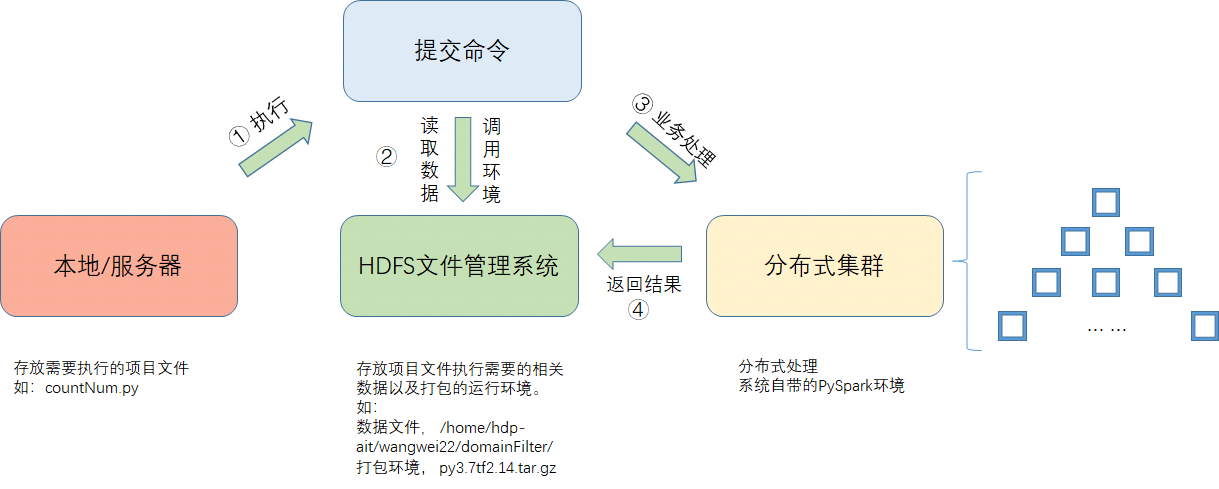
2. 基于PySpark的分布式项目主要由三部分组成,如图1所示,我们在开发自己的分布式程序时,只需要关注两部分,1是开发自己项目的PySpark代码,2是将该代码运行需要的环境进行打包。
下面的countNum.py即一个简单的分布式程序。
# countNum.py from pyspark import SparkConf,SparkContext if __name__=="__main__": ### 1.配置spark连接 ### # 参数设置 conf = SparkConf().setAppName("count_nums") # 实例化一个Spark集群的连接 sc = SparkContext(conf=conf) ### 2.业务处理 ### # 读取数据 edges = sc.textFile("/home/hdp-ait/wangwei22/edge/subdomain/part-00000-80565034-e42a-47c4-9767-49e1fd44b525-c000.json.gz") nodes = sc.textFile("/home/hdp-ait/wangwei22/tag/domain/part-00000-a3e54434-0e76-4a8e-ad71-cb59b12d5e8f-c000.json.gz") # 统计数据量 edges_Num = edges.count() nodes_Num = nodes.count() # 输出统计结果 print("Number of edges:", edges_Num) print("Number of nodes:", nodes_Num) # 输出数据样例 print("Number of nodes:", edges.take(10)) print("Number of nodes:", nodes.take(10))
3. 运行环境打包及上传
# 压缩环境
tar -zcvf py3.7_ne1.0.tar.gz py3.7# 上传至HDFShdfs dfs -copyFromLocal py3.7_ne1.0.tar.gz /home/hdp-ait/wangwei22/4. 项目提交
通过在自己运行程序代码(如countNum.py)所在位置提交命令的方式。
spark -submit
--master yarn --keytab /home/wangwei22/.wangwei22.keytab--principal wangwei22 --queue root.hdp_ait # 这里提交模式只能是 cluster, client模式会报错。--deploy-mode cluster# 分布式平台的执行机器最大只能支持14G,再大会报错--driver-memory 14G# 并发数的设置越多,推理速度越快--num-executors 200# 分布式平台的执行机器最大只能支持14G,再大会报错--executor-memory 14G# 核数设为1, 并发执行器利用率高,推理速度快--executor-cores 1# 环境压缩包的位置--archives hdfs:/home/hdp-ait/wangwei22/py3.7_ne1.0.tar.gz#py3.7 # pyspark的python驱动环境即我们上传的python环境--conf spark.pyspark.driver.python=./py3.7/py3.7/bin/python3--conf spark.pyspark.python=./py3.7/py3.7/bin/python3countNum.py5.常用HDFS操作命令

 浙公网安备 33010602011771号
浙公网安备 33010602011771号