

201116西瓜书机器学习系列---10、降维
201116西瓜书机器学习系列---10、降维
一、总结
一句话总结:
先讲一个【引子:k-nearst labor】,然后讲【降维方法】,有【线性和非线性两种】,然后是度量学习

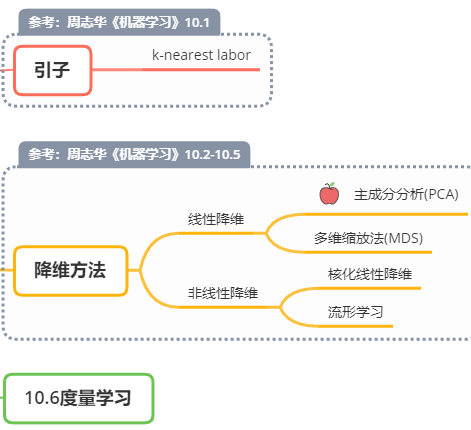
1、降维常见方法?
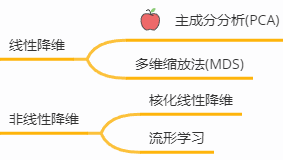
降维方法主要是【线性和非线性两种】,线性的里面有我们熟知的【主成分分析PCA】
2、K近邻学习?
K近邻学习的原理就是判断一个点的正负的时候,【找离他最近的点的正负】即可,【k=3就是最近的3个样本】

3、线性变换降维的原理?
比如从1000维降到100维,原理就是【乘一个W矩阵】,所以问题的核心就是【寻找合适的W】

4、主成分分析PCA原理?
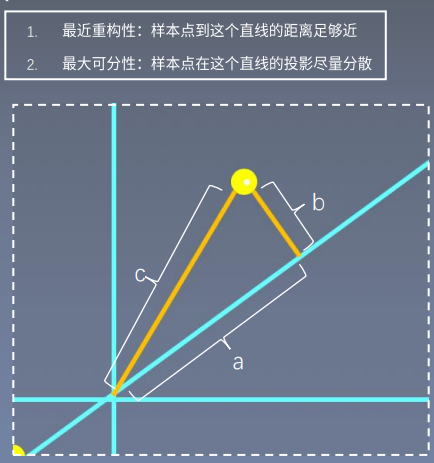
比如二维降到一维,我们需要【画一条直线尽可能保留原始信息】,这条直线需满足【最近重构性】和【最大可分性】
【最近重构性】:样本点【到这个直线的距离足够近】;【最大可分性】:样本点【在这个直线的投影尽量分散】

5、主成分分析PCA简单数学原理?
先简单abc【勾股定理】,想要【a^2足够大就是让b^2足够小】,使用【拉格朗日乘子法】,就是【求特征向量相加最大的值】


6、南瓜书PumpkinBook?
PumpkinBook【西瓜书里所有重点公式的推导和解析】:https://github.com/datawhalechina/pumpkin-book
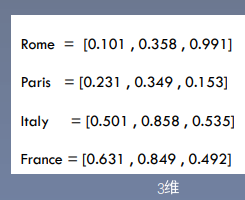
7、降维用到的不多,但是Embedding用到的真的多?
用一个【低维度稠密向量表示一个对象】,广泛应用于推荐、广告、搜索等领域【(万物皆embedding)】


8、机器学习和深度学习耗时太久的原因?
【没有系统的看书】,【找到的资料并不好】,所以【可以系统的看书,多看几本】
二、内容在总结中
博客对应课程的视频位置:


 浙公网安备 33010602011771号
浙公网安备 33010602011771号