

Tensorflow2疑难问题---2、tensorflow2.3的GPU版本安装
Tensorflow2疑难问题---2、tensorflow2.3的GPU版本安装
一、总结
一句话总结:
安装tensorflow的gpu的版本的时候,要特别注意CUDA、cuDNN、tensorflow版本的一致性,在tensorflow官网可以查看对应版本关系
二、tensorflow2.3的GPU版本安装
博客对应课程的视频位置:
2、tensorflow2.3的GPU版本安装(一)-范仁义-读书编程笔记
https://www.fanrenyi.com/video/37/336
2、tensorflow2.3的GPU版本安装(二)-范仁义-读书编程笔记
https://www.fanrenyi.com/video/37/337
一、准备资料
需要显卡,还需要安装CUDA和cuDNN
1、显卡
比如我这台机器,显卡就是 NVIDIA GTX 1060,显存6GB
2、CUDA(Compute Unified Device Architecture):统一计算架构
是显卡厂商NVIDIA推出的运算平台。
CUDA是一种由NVIDIA推出的通用并行计算架构,该架构使GPU能够解决复杂的计算问题。
3、CUDNN:NVIDIA cuDNN是用于深度神经网络的GPU加速库。
The NVIDIA CUDA® Deep Neural Network library (cuDNN) is a GPU-accelerated library of primitives for deep neural networks.
4、CUDA和CUDNN的关系
CUDA看作是一个工作台,上面配有很多工具,如锤子、螺丝刀等。
cuDNN是基于CUDA的深度学习GPU加速库,有了它才能在GPU上完成深度学习的计算。二、安装CUDA和cuDNN
特别注意:
当配置CUDA、cuDNN、tensorflow时,要确保这三者之间的版本对应一致
在tensorflow官网可以查看这些软件版本对应信息
2、安装cuDNN
cuDNN各个版本的下载网址:
https://developer.nvidia.com/rdp/cudnn-archive#a-collapse51b
这个下载要注册,太太太麻烦,
所以我们可以直接复制链接地址,迅雷下载即可,不要点进去,点进去要注册麻烦
3、配置系统变量
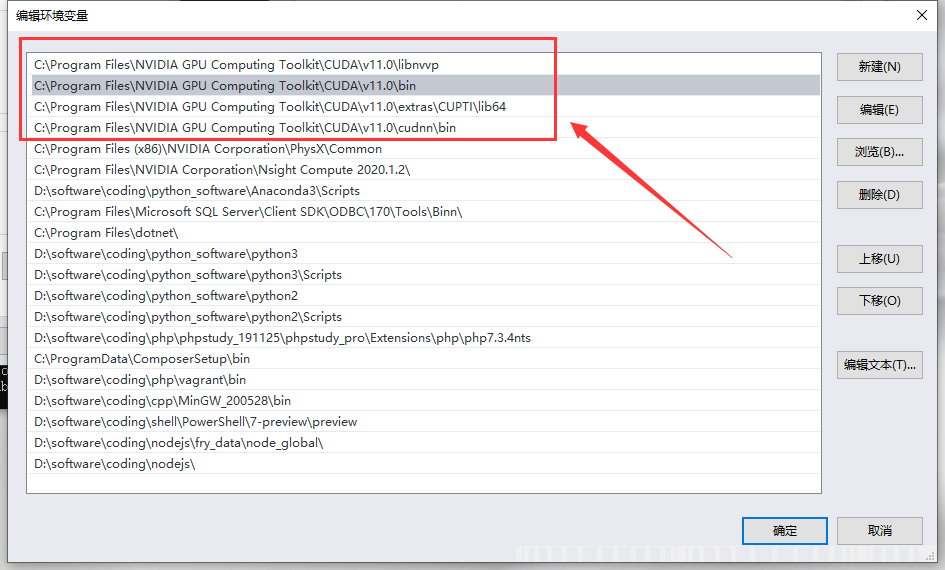
4、验证是否安装成功

配置完成后,我们可以验证是否配置成功,主要使用CUDA内置的deviceQuery.exe 和 bandwithTest.exe:
首先win+R启动cmd,cd到安装目录下的 ...\extras\demo_suite,然后分别执行bandwidthTest.exe和deviceQuery.exe,
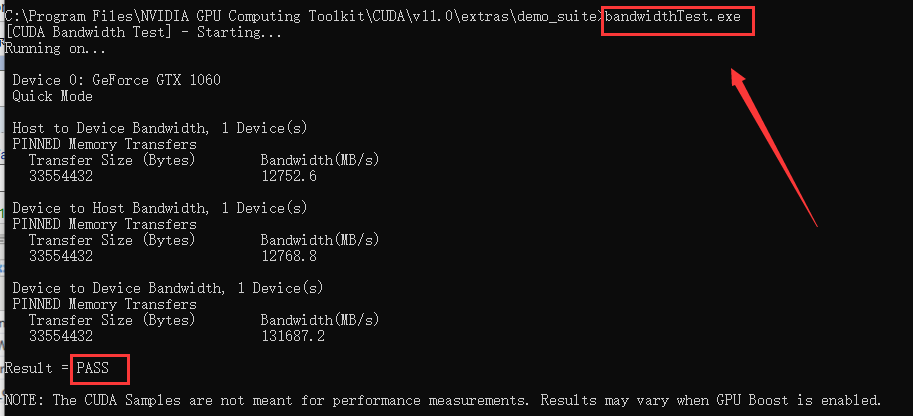

如果以上两步都返回了Result=PASS,那么就算成功啦。
三、安装tensorflow
如果安装了tensorflow-cpu版本,可以先把cpu版本先卸了
pip uninstall tensorflow-cpu
然后再安装gpu版本
pip install tensorflow-gpu四、验证tensorflow是否成功用gpu加速
In [2]:
import tensorflow as tf
print("GPU:",tf.test.is_gpu_available())
In [3]:
tf.config.list_physical_devices('GPU')
Out[3]:
五、卷积神经网络中GUP和CPU性能对比
In [5]:
import os
os.environ['TF_CPP_MIN_LOG_LEVEL']='2'
import tensorflow as tf
from tensorflow.keras import layers, optimizers, datasets, Sequential
# 按需分配GPU
# from tensorflow.compat.v1 import ConfigProto
# from tensorflow.compat.v1 import InteractiveSession
# config = ConfigProto()
# config.gpu_options.allow_growth = True
# session = InteractiveSession(config=config)
tf.random.set_seed(2345)
# 卷积层
conv_layers = [ # 5 units of conv + max pooling
# 5个单元
# unit 1
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(64, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 2
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(128, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(pool_size=[2, 2], strides=2, padding='same'),
# unit 3
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.Conv2D(256, kernel_size=[3, 3], padding="same", activation=tf.nn.relu),
layers.MaxPool2D(