
监督学习——线性回归
1 线性回归简介
1.1 回归与分类的区别
若预测的值是离散值,如年龄,此类任务位“分类”。
若预测的值是连续值,如房价,此类任务为“回归”。
1.2 回归的目标
学习一个从输入X到输出Y的映射f,并根据该模型,对新的测试数据x进行预测,简单来说,就是找到一个输入与输出之间的映射,用于与新的输入。
1.3 线性回归模型
映射f是一个线性函数,即:f(x,w)=wTx + b
w为各个特征的权重,b为偏置项。
2 线性回归模型的目标函数
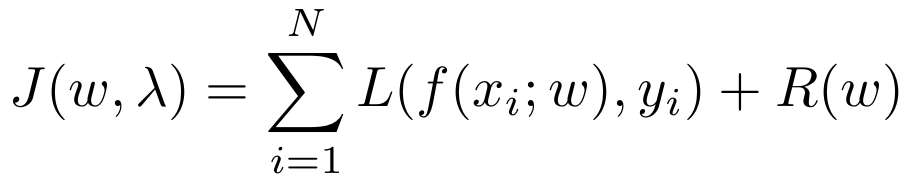
其中L为损失函数,R为正则函数。不带正则函数的目标函数为最小二乘线性回归模型。
2.1 损失函数
2.1.1 L2损失
预测残差
![]() ,其中
,其中![]() 为预测值,y为真实值,r表示预测值和真实值之间的差异。
为预测值,y为真实值,r表示预测值和真实值之间的差异。
L2损失
![]()
L2损失也就是预测残差的平方。
训练样本上的损失之和为残差平方和
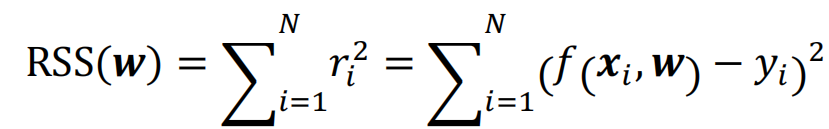
如果残差值与预测值有关,说明模型不准确。
缺点
对离群点敏感,如果某个离群点原理大部分数据,根据理想模型的预测残差![]() 将会非常大
将会非常大
2.1.2 L1损失
L1损失
![]()
优点
对离群点不敏感
缺点
绝对值函数在原点不连续,优化求解麻烦
2.1.3 Huber损失
Huber损失
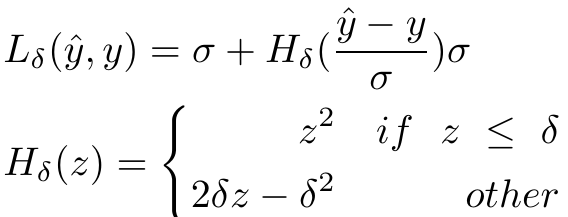
优点
综合了L2损失和L1损失。
当残差的绝对值小的时候,Huber损失函数为L2损失,当残差的绝对值大的时候,取L1损失。Huber损失既处处连续,优化又方便,对离群点又不敏感。
参数
Scikit-learn中建议δ=1.35。
2.2 正则函数
2.2.1 L2正则
L2正则项为范数的平方。
![]()
带有L2正则的线性回归模型称为岭回归模型:
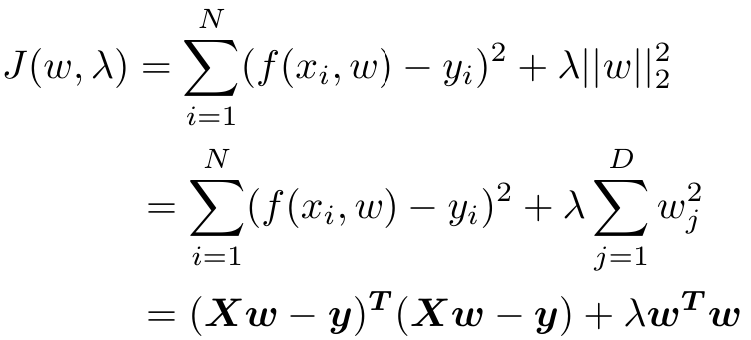
其中D为特征的维数,λ为正则参数,控制正则惩罚的强度。
岭回归模型等价于最大后验估计,其中![]() 。τ2越小,先验越强,τ2越大,先验越弱,数据更重要。
。τ2越小,先验越强,τ2越大,先验越弱,数据更重要。
2.2.2 L1正则
L1正则为带参数的L1范数:
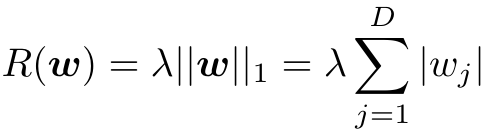
带有L1正则的线性回归模型称为Lasso,目标函数为:
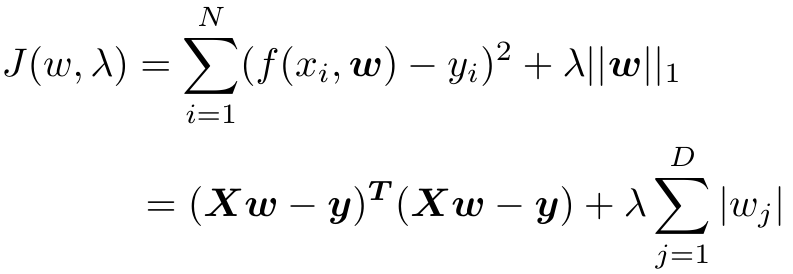
Lasso回归模型等价于贝叶斯最大后验估计,其中![]() 。λ越大,正则惩罚项比重大。,λ越小,正则惩罚项比重小。
。λ越大,正则惩罚项比重大。,λ越小,正则惩罚项比重小。
2.2.2 L1正则+L2正则:弹性网络
正则项同时包含L1正则和L2正则:
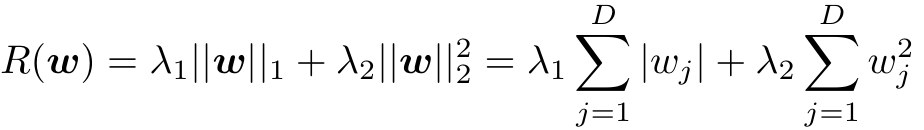
带有L2正则和L1正则的线性回归模型称为弹性网络,目标函数为:
![]()
3 线性回归模型优化求解
3.1 任务定义
模型的目标函数确定后,接下来就是要找到最佳的模型参数。在线性回归中,模型参数包括线性回归系数w和正则参数λ。
3.2 最佳模型参数
最佳的模型参数就是使得目标函数取极小值的参数。因为目标函数包含损失函数和正则项,损失越小,目标函数也就越小,模型就越优秀。
![]()
3.3 解析求解法
3.3.1 最小二乘线性回归解析求解
最小二乘法的目标函数:![]()
补充(向量求导公式):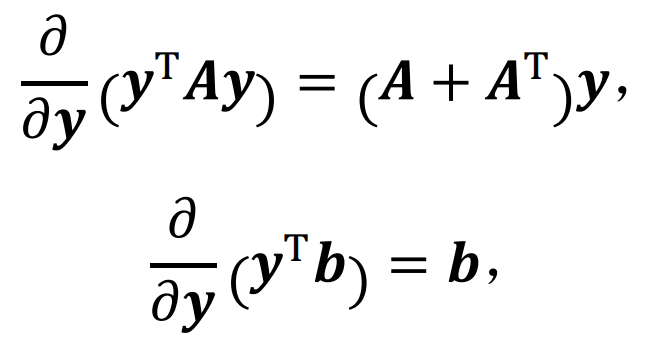
首先将J(w)展开:
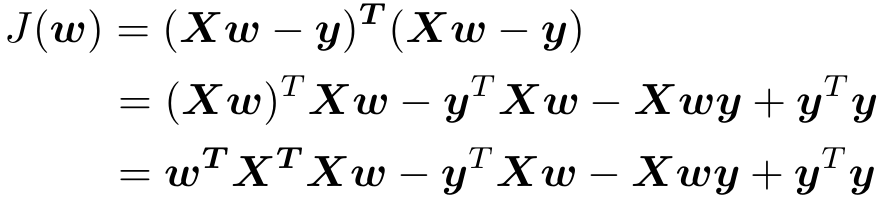
利用此公式对目标函数求导(因为每一项都是实数,所以转置等于本身):
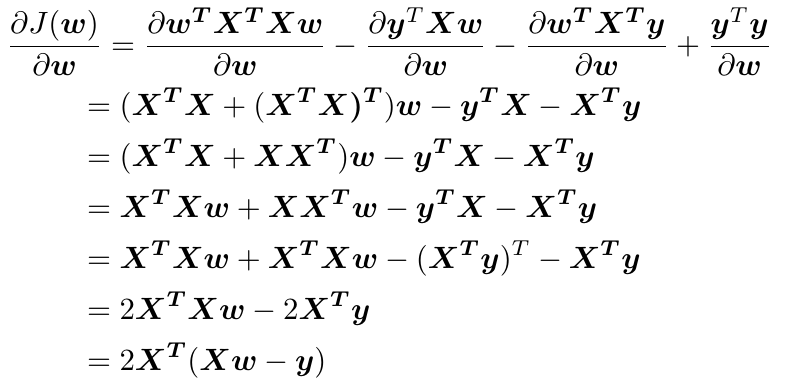
令![]() ,得到:
,得到:![]() ,当X满秩时,XTX可逆,此时两边同时乘以
,当X满秩时,XTX可逆,此时两边同时乘以![]() ,得到:
,得到:
![]()
最小二乘线性回归的正规方程组求解算法:
输入:训练数据{xi,yi}Ni=1,以xi为行向量组成输入矩阵X,N个样本yi构成输出向量y。
输出:特征权重向量w。
计算过程:
-
-
-
-
- 计算X的转置矩阵XT和A=XTX;
- 计算A的逆矩阵A-1。
- 计算w=A-1XT。
-
-
-
最小二乘线性回归的奇异值分解求解算法(更加稳定):
奇异值:设A为m*n阶矩阵,q=min(m,n),A*A的q个非负特征值的算术平方根叫作A的奇异值。
输入:训练数据{xi,yi}Ni=1,以xi为行向量组成输入矩阵X,N个样本yi构成输出向量y。
输出:特征权重向量w。
计算过程:
-
-
-
-
- 计算X的SVD分解:X=UDVT;
- 计算y'=UTy;
- 计算wj'=yj'/σj,σj为D的第j个对角线元素;
- 计算w=Vw';
-
-
-
3.3.2 岭回归解析求解
岭回归目标函数:
![]()
对目标函数求导:
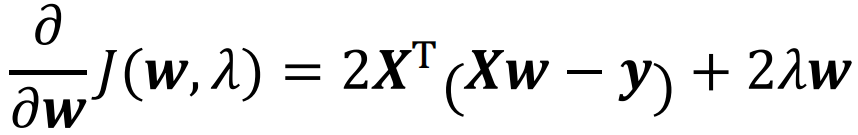
令 ![]() ,得到:
,得到:
![]()
类似于最小二乘线性回归的解析解求解,岭回归计算时也可以采用SVD。
岭回归的解与最小二乘线性回归的解之间的关系为:
![]()
3.4 梯度下降法
梯度下降法通常用于求解无约束的优化问题。
最小二乘线性回归,岭回归都可以采用梯度下降法求解。
Lasso由于目标函数中有L1正则函数不可导,不可用梯度下降法(要作用坐标轴下降法)。
3.4.1 梯度下降法过程
1.初始化:θ(0)。
2.计算函数J(θ)在当前位置θ(t)处的梯度g(t),若g(t)处于设定的最终收敛范围,则返回此时的θ(t)为最佳参数。(判断当前梯度是否可以结束)
3.根据学习率η,更新位置:θ(t+1)=θ(t)-ηg(t)。
4.t=t+1,转到第2步.
简而言之,不断地用学习率η和梯度g(t)更新参数,更新一次判断当前梯度是否可以结束。
3.4.2 梯度以及更新公式
最小二乘线性回归的梯度为:
![]()
最小二乘线性回归的梯度下降更新公式为:
![]()
岭回归的梯度为:
![]()
岭回归的梯度下降更新公式为:
![]()
学习率η越大,收敛速度越快,但是精度可能不够。学习率小,收敛速度慢。但是学习率过大,可能会跨越最佳值,使得目标函数反而增大,称为过冲现象。
3.4.3 梯度下降类别
批处理梯度下降
在计算梯度时,用到了所有样本。
优点:更加精确。
缺点:非常耗时。
随机梯度下降
计算梯度时,只用一个样本
优点:速度快。
缺点:可能不精确
小批量梯度下降
介于批处理梯度下降和随机梯度下降之间的算法,每次看一小批样本,每批样本的数量称为批容量(Batch Size)。
Scikit-Learn建议样本数目超过10000采用随机梯度下降或小批量梯度下降。
3.5 坐标轴下降法
Lasso虽然不能使用梯度下降法求解,但是可以使用坐标轴下降法求解。
3.5.1 坐标轴下降法大致思想
有一个函数f(x,y)=5x2-6xy+5y,利用坐标轴下降法求解极值。
设初始x=-0.5,y=-1.0,此时函数的值f=3.25。
首先固定x,将f看成关于y的一元二次方程,对y进行求导,求解y的极值。
利用y的极值,固定y,将f看成x的一元二次方程,对x进行求导,求x的极值。
如此迭代下去直到收敛。
3.5.2 Lasso梯度分析
已知Lasso的目标函数为:
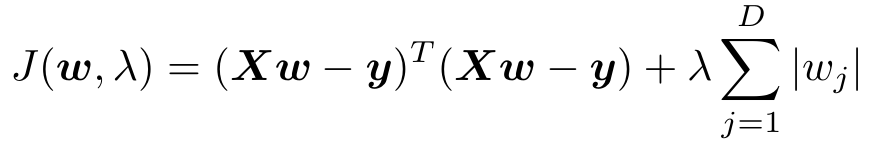
由坐标轴下降法可知,使用坐标轴下降法时,要求各个维度的梯度。
但是Lasso中,含有绝对值项,必须按照分段函数求导。
首先处理Lasso中的可微项
对Lasso中可微项进行求导:
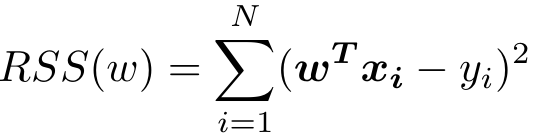
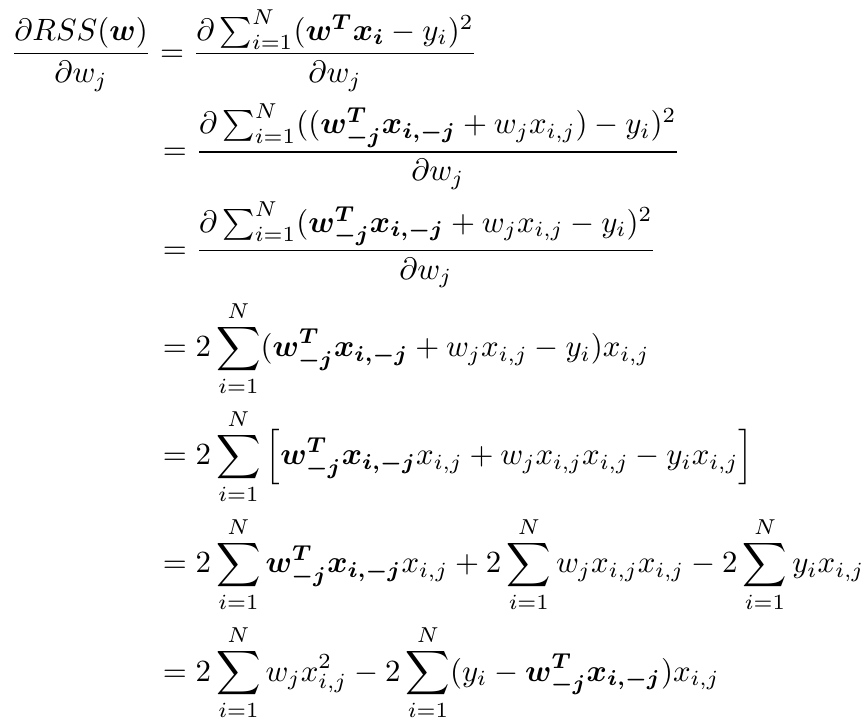
其中w-j表示向量w中除了第j维的其他D-1个元素,xi,-j表示向量xi中除了第j维的其他D-1个元素,xi,j表示向量xi中第j维元素。式子中将第j维元素单独提出来求导。
令:
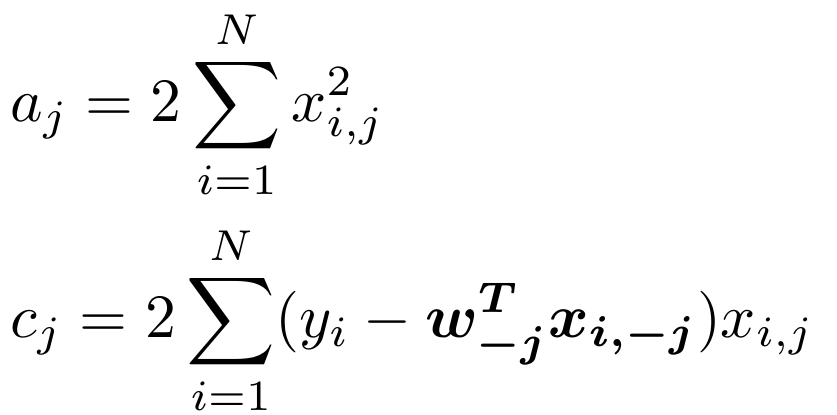
此时可微项的导数为:
![]()
接下来处理不可微的正则项|wj|的次梯度:
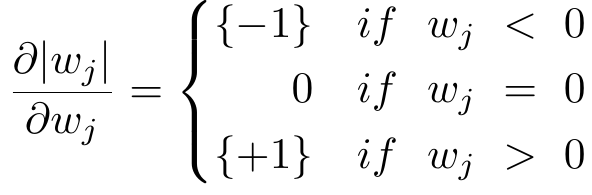
综合两项的导数Lasso目标函数的次梯度为:
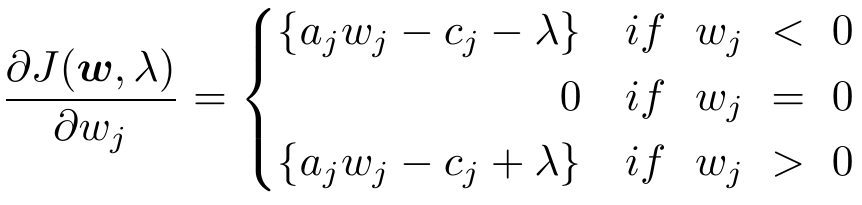
令![]() 为0,得到极值:
为0,得到极值:
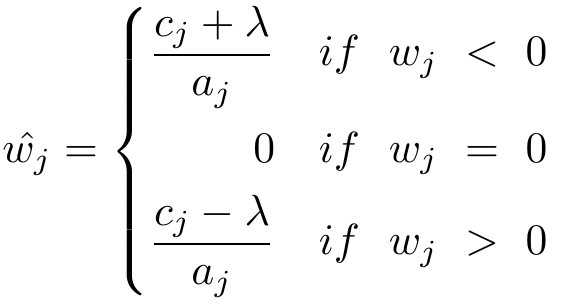
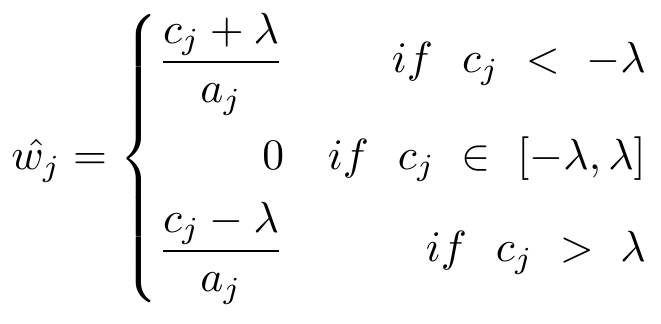
3.5.2 坐标轴下降法求解Lasso算法流程
在可微项目中,aj之和输入样本x有关,可以预先计算。
1.预先计算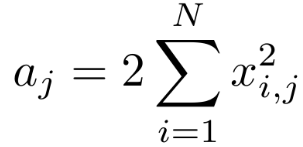 ;
;
2.初始化参数w(初始值为0或者随机)
3.迭代计算直到收敛:(选择变化幅度最大的维度或者轮流更新wj)
计算cj:
![]()
再计算wj:
4 模型评估
4.1 均方误差MSE
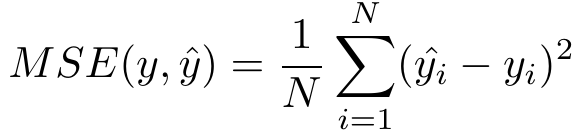
MSE越小越好,但是对离群点敏感。
4.2 均方根误差RMSE
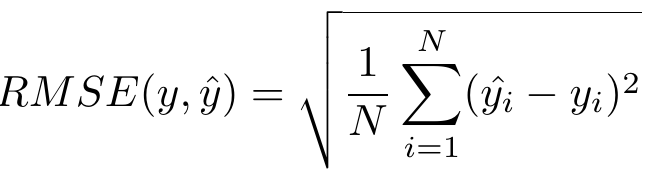
4.3 平方绝对误差MAE
![]()
MAE值越小越好。
4.4 绝对误差的中值MedianAE
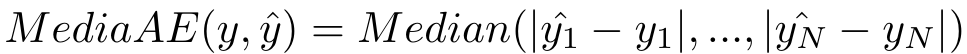
Median表示取中值,对离群点不敏感。
4.5 均方对数误差MSLE
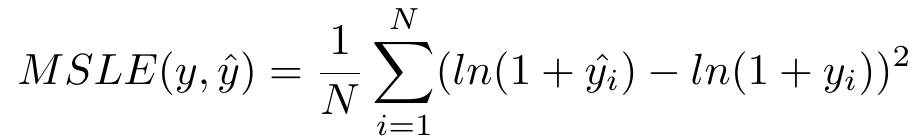
MSLE可以降低标签特别大的异常值的影响。
4.6 均方根对数误差RMSLE
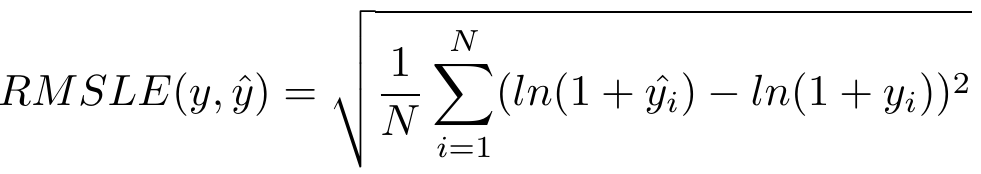
4.7 可解释方差分数EVS
![]()
分数最大值为1,越接近1越好。
4.8 R方分数R2 socre
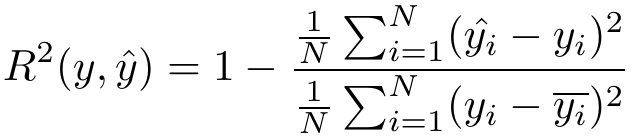
R方分数的最佳值为1,如果结果为0,说明模型跟随机猜测差不多,如果为负数,说明模型还不如随机猜测。
本文来自博客园,作者:Laplace蒜子,转载请注明原文链接:https://www.cnblogs.com/RedNoseBo/p/17132414.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号