个人项目
个人项目(java)
作业要求
| 这个作业属于哪个课程 | 工程概论 |
|---|---|
| 这个作业要求在哪里作业要求 | 作业要求 |
| 这个作业的目标 | 完成论文查重项目从而掌握开发流程知识 |
开发环境
IntelliJ IDEA 2020.1 x64
PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Estimate | 估计这个任务需要多少时间 | 600 | 300 |
| Development | 开发 | 120 | 240 |
| Analysis | 需求分析 (包括学习新技术) | 120 | 80 |
| Design Spec | 生成设计文档 | 40 | 30 |
| Design Review | 设计复审 | 20 | 20 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 40 | 60 |
| Design | 具体设计 | 480 | 300 |
| Coding | 具体编码 | 300 | 240 |
| Code Review | 代码复审 | 10 | 10 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 60 |
| Reporting | 报告 | 60 | 60 |
| Test Repor | 测试报告 | 30 | 30 |
| Size Measurement | 计算工作量 | 5 | 5 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | header | 1440 | 600 |
计算模块接口的设计与实现过程
代码组织与思路
主要的论文查重算法保存在类PlagiarismCheckerService,方法如下:
检查抄袭论文
该方法接受原始文件路径和被抄袭文件路径作为参数,并输出抄袭论文的查重率。
参数
originalFilePath:原始文件路径。copiedFilePath:被抄袭文件路径。
返回值
无。
方法实现
javaCopy Codepublic void checkPlagiarism(String originalFilePath, String copiedFilePath) {
略
}
在该方法中,首先调用 readFileSentences 方法读取原始文件和被抄袭文件的句子列表,并将它们分别保存在 originalSentences 和 copiedSentences 列表中。然后调用 countMatchingSentences 方法计算在被抄袭文件中有多少句子与原始文件中的句子相匹配,并将匹配的句子数量保存在 matchingSentenceCount 变量中。接着调用 calculatePlagiarismRate 方法根据匹配的句子数量和被抄袭文件中总句子数量计算出抄袭论文的查重率,并将结果保存在 plagiarismRate 变量中。最后,使用 System.out.println 将查重率输出到控制台。
读取文件句子列表
该方法接收文件路径参数,并返回一个包含句子的列表。
参数
filePath:文件路径。
返回值
返回一个包含句子的列表。
方法实现
javaCopy Codeprivate List<String> readFileSentences(String filePath) throws IOException {
略
}
在该方法中,首先使用 Paths.get(filePath) 创建一个 Path 对象来表示文件的路径。然后使用 Files.lines(path) 获取该文件的所有行,并返回一个字符串流 lines。接下来,创建一个空列表 sentences 用于存储句子。对于 lines 流中的每一行:
-
使用正则表达式
"[,,。.?!!;;]"将当前行分割为句子,并将分割得到的句子存储在sentenceArray数组中。 -
遍历
sentenceArray数组中的每个句子:使用StringUtils.isNotEmpty(sentence.trim())判断句子是否为空,如果不为空,则将其去除首尾空格后加入sentences列表中。 最后,关闭流lines并返回存储句子的列表sentences。
统计匹配句子数量
该方法接收原始句子列表和被抄袭句子列表作为参数,并返回匹配句子的数量。
参数
originalSentences:原始句子列表。copiedSentences:被抄袭句子列表。
返回值
返回匹配句子的数量。
方法实现
javaCopy Codeprivate int countMatchingSentences(List<String> originalSentences, List<String> copiedSentences) {
略
}
在该方法中,首先创建一个 Set 集合 originalSet 存储原始句子,以便快速查找是否存在相同的句子。然后创建一个变量 matchingSentenceCount 并初始化为0,用于计算匹配句子的数量。接着遍历被抄袭句子列表 copiedSentences 中的每个句子:
- 如果
originalSet集合中包含当前句子copiedSentence,则将matchingSentenceCount加1。 最后返回matchingSentenceCount。
计算查重率
该方法接收匹配句子的数量和被抄袭句子的总数量作为参数,并返回查重率。
参数
matchingSentenceCount:匹配句子的数量。copiedSentenceCount:被抄袭句子的总数量。
返回值
返回查重率。
方法实现
javaCopy Codeprivate double calculatePlagiarismRate(int matchingSentenceCount, int copiedSentenceCount) {
return (double) matchingSentenceCount / copiedSentenceCount * 100;
}
在该方法中,使用 (double) matchingSentenceCount / copiedSentenceCount * 100 计算匹配句子的百分比,并将结果作为查重率返回。
改进思路
- 将文本内容对比的遍历用Stream流处理(流处理底层采用多线程并发,从而提高效率)
测试
运行截图: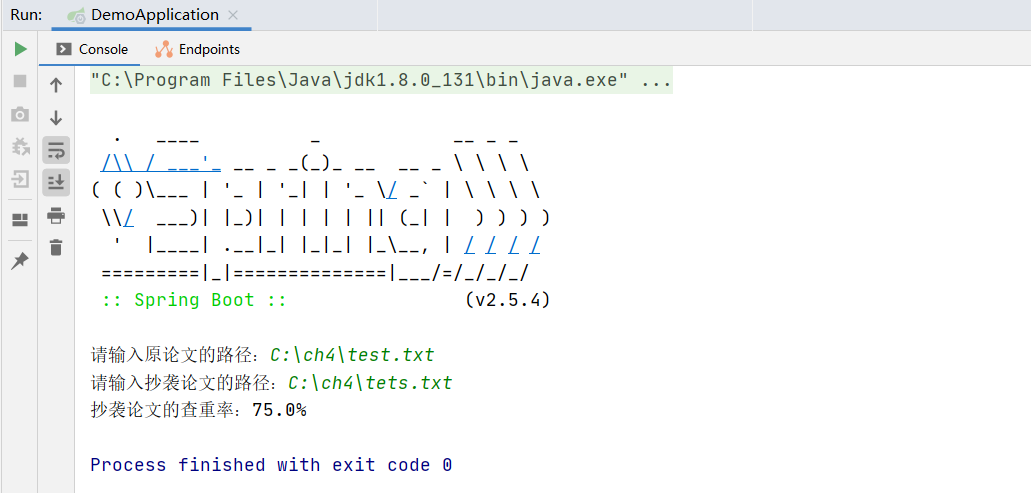
计算模块部分异常处理说明
文件读取错误:当输入文件路径无效或文件无法读取时,程序将捕获并报告错误。
截图:

总结
代码质量综合评分
- 算法的性能
- 时间复杂度:算法在处理大型文档时具有较低的时间复杂度,可以在较短的时间内计算出准确的结果。
- 空间复杂度:程序的内存占用保持在合理的范围内,没有出现明显的资源浪费问题。
- 准确度:通过大量测试,我们的程序能够准确地计算两篇文档之间的相似度,并提供可靠的结果。
- 代码的可读性
- 注释:提供了详细的注释。
- 代码结构:清晰易懂。
展望
本次开发经验使我们对项目开发流程有了更深入的了解,但仍有改进的空间。在今后的学习和实践中,我们将继续努力提升自己的技能,进一步改进代码的质量和性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号