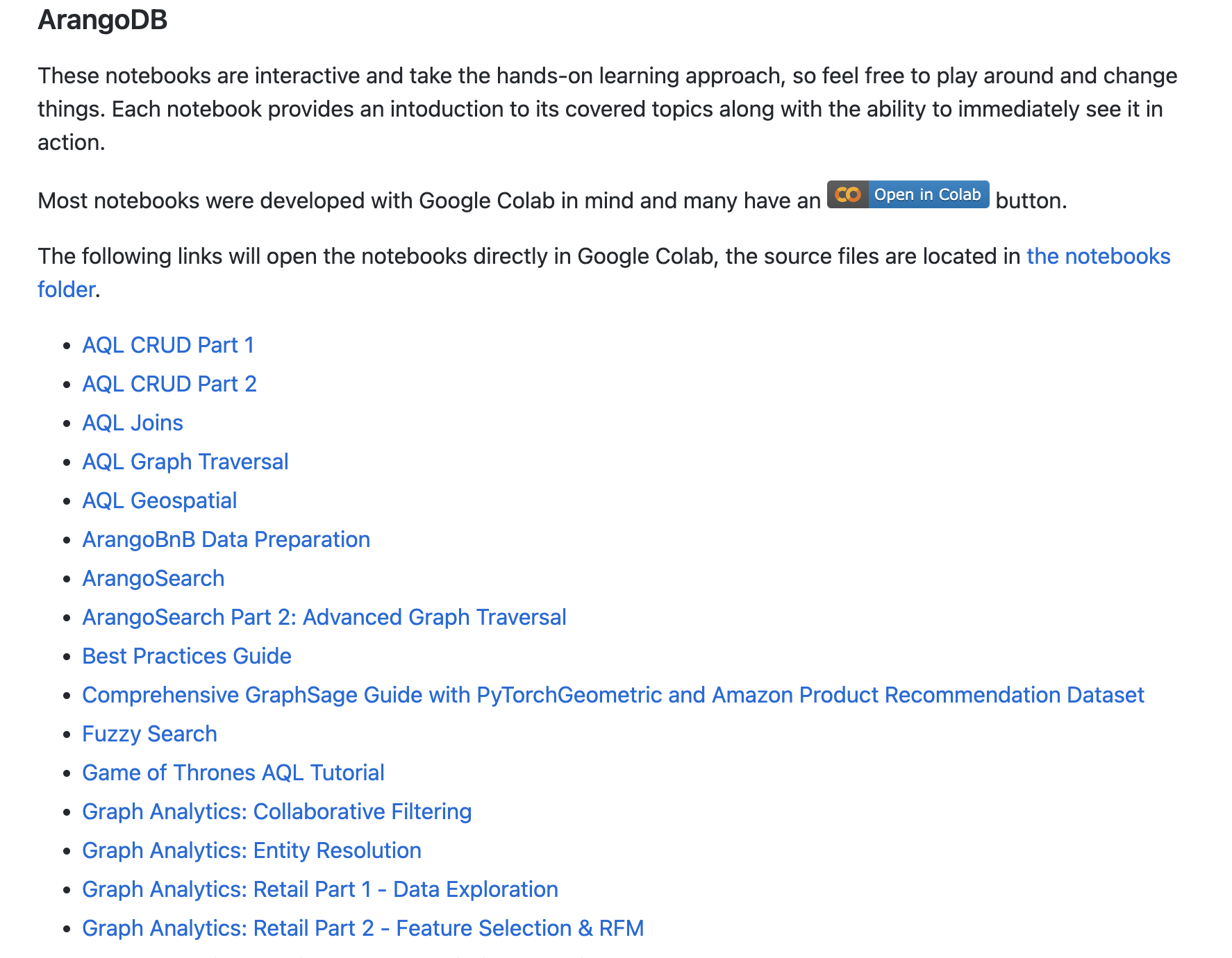
PyArango
- PyArango:【Github:pyArango】;【官网学习文档1:ArangoDB v3.9.1 Documentation】; 【官网学习文档2:Learn ArangoDB】; 【Videos】
包含基本使用,以及如何去连接各个collection。一个不错的文档:Graph Course for Freshers: The Shortest Path to first graph skills
油管:Graph:PyaragoDB ML; Web: Scalable Graph ML Everywhere;Github: ITSM_ArangoDB_Adapter
视频的ppt之前看到过,没找到,Github: Graph_Powered_ML_Workshop 中有个课件。
如果你对ArangoDB和图神经网络感兴趣,可以点击 Blog: 图神经网络
- 自学笔记:https://blog.csdn.net/qq_39377543/article/details/110137333
- 中文本基本教程:https://www.arangodb.com/tutorials/cn-tutorial-python/
- PyArango Document:https://pyarango.readthedocs.io/en/stable/
- ABD csdn:https://blog.csdn.net/kongxx/category_9687000.html
怎么创建基本的文件类型
一般需要包括:数据库,集合(collection),文件(document);一个数据库可以有多个collection,当然一个collection也可以有多个document。
下面是最基本的如何去创建:
Step0: 在Python终端连接Arango,
from pyArango.connection import Connection
conn = Connection(arangoURL=url, username=username password=password)
print('conn: %s' % conn)
/* 嵌入新的数据 */
INSERT { name: "Katie Foster", age: 27 } INTO users
INSERT { name: "James Hendrix", age: 69 } INTO users
- Step1: 需要创建数据库:
db = conn.createDatabase(name="test")
也可以打开现有的数据库:
db = conn["test"]
- Step2: 创建集合,集合可以收纳同种类型的
document
studentsCollection = db.createCollection(name="test")
- Step3: 创建document,对于那个document,存在
_id,_key,这些都是唯一的,可以用来查询。
doc1 = studentsCollection.createDocument()
doc1["name"] = "John Smith"
doc1.save() # 保存到终端数据库中,否则数据仅出存在python运行内存中
怎么将我们已有的数据导入到pyarngo数据库中?
具体要看我们的需求,最简单的是python中有处理的数据,下面是一个demo:
一个列表中存储着多个元组,一个元组有三个数据元素;
# link:https://www.cnblogs.com/minglex/p/9480516.html
students = [('Oscar', 'Wilde', 3.5), ('Thomas', 'Hobbes', 3.2),
('Mark', 'Twain', 3.0), ('Kate', 'Chopin', 3.8), ('Fyodor', 'Dostoevsky', 3.1),
('Jane', 'Austen',3.4), ('Mary', 'Wollstonecraft', 3.7), ('Percy', 'Shelley', 3.5),
('William', 'Faulkner', 3.8), ('Charlotte', 'Bronte', 3.0)]
for (first, last, gpa) in students:
doc = studentsCollection.createDocument()
doc['name'] = "%s %s" % (first, last)
doc['gpa'] = gpa
doc['year'] = 2017
doc._key = ''.join([first, last]).lower()
doc.save()
如果是外部的文件,怎么导入到数据库中?比如json文件。一般来说,pyarngo中的的document就是一个json格式的数据。
可以先python读取数据,在按照上面的格式将数据导入到数据库中。
如果我想要的是图结果的数据,改如何去构建这个数据库?
一般来说,图结构包括点和边,点可以有不同的类型,每种类型可以含有不同的信息,对于边来说,亦是如此。
这就需要构建多个collections , 每个collections 中的特征将会存在关联性,这将如何去构建?
如果构建成功,对于图数据类型,他的数据特点在哪里?
可以参考 【建立点、边表并进行简单的图查询】:
导入CSV文件
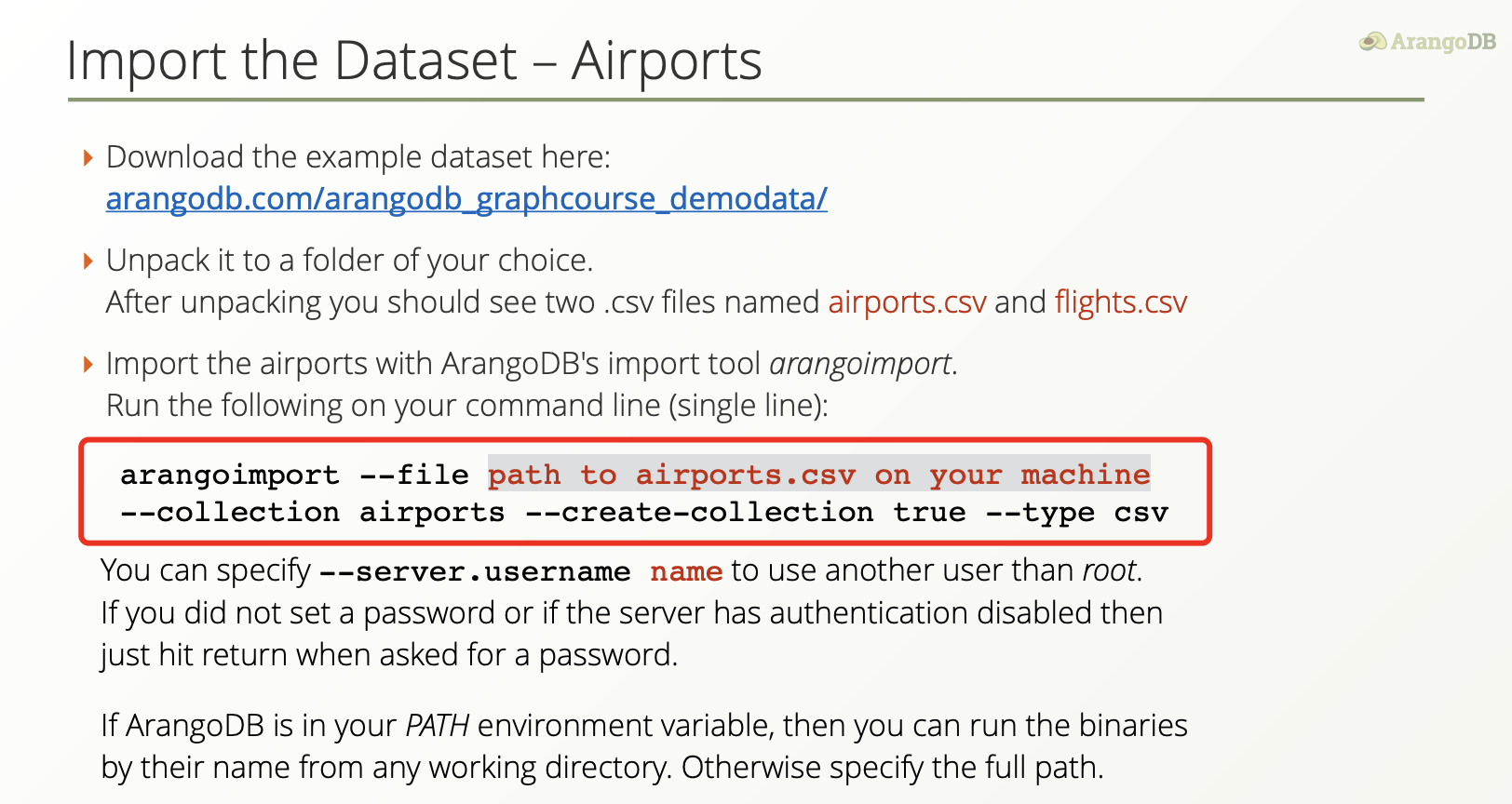
AQL query
【AQL 官方教程】;【模式匹配】
pyarango 可以运行 AQL quert的 命令,
aql = "FOR x IN Students RETURN x._key"
queryResult = db.AQLQuery(aql, rawResults=True, batchSize=100)
for key in queryResult:
print(key)
一些基础的query命令: 可以参考:官方:Querying the Database
/*
首先生成一个数据包含 name: "Katie Foster", age: 27
在connection 中手动生成一个
*/
RETURN DOCUMENT("users/9883")
/* 嵌入新的数据 */
INSERT { name: "Katie Foster", age: 27 } INTO users
INSERT { name: "James Hendrix", age: 69 } INTO users
/* 返回多个 */
RETURN DOCUMENT( ["users/9883", "users/31645", "users/31665"] )
/* 按年龄进行升序 */
FOR user IN users
SORT user.age
RETURN user
/* 按年龄进行降序 */
FOR user IN users
SORT user.age DESC
RETURN user
/* 筛选大于30 */
FOR user IN users
FILTER user.age > 30
SORT user.age
RETURN user
/* Update 仅仅更改特定的属性,如果使用REPLACE, 将会删除除 _id, _key 外的信息 */
UPDATE "31645" WITH { age: 40 } IN users
RETURN NEW
/* Filter 可以起到过滤的功能 */
FOR user IN users
FILTER user.age > 30
SORT user.age
RETURN user.name
/* 修改返回值的 indexs */
FOR user IN users
RETURN { userName: user.name, age: user.age }
/* concat 字符串 */
FOR user IN users RETURN CONCAT(user.name, "'s age is ", user.age)
/* 两个for 循环进行排列取不同元素 */
FOR user1 IN users
FOR user2 IN users
FILTER user1 != user2
RETURN [user1.name, user2.name]
/* 进行求和 */
FOR user1 IN users
FOR user2 IN users
FILTER user1 != user2
RETURN {
pair: [user1.name, user2.name],
sumOfAges: user1.age + user2.age
}
/* 筛选小于100,使用LET 进行赋值 */
FOR user1 IN users
FOR user2 IN users
FILTER user1 != user2
LET sumOfAges = user1.age + user2.age
FILTER sumOfAges < 100
RETURN {
pair: [user1.name, user2.name],
sumOfAges: sumOfAges
}
/* 进行删除 */
REMOVE "9883" IN users
Graph
高阶用法
如何封装成类,在Python中套用:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号