

Review: MySQL 01(SQL入门、约束、事务、多表、子查询、数据库设计、索引、存储过程、触发器)
MySQL
一、MySQL基础和SQL入门
1. MySQL使用相关
- 启动与关闭
- Windows计算机管理-服务中启动和关闭
- 使用CMD命令启动和关闭
- 命令行登录
- 本机MySQL服务器登录
- 加IP地址登录(可登录远程数据库)
- 目录结构
- MySQL安装目录下各种文件夹意义
- MySQL配置文件与数据库与数据表所在目录
2. DDL:使用SQL操作数据库和数据表
-
定义DATABASE
-
创建数据库
CREATE DATABASE db1_1 CHARACTER SET utf8;一般创建数据库时指定字符集,不指定数据库字符集默认是latin1
-
查看/选择数据库(切换数据库、查看正在使用的数据库、查看所有数据库、查看一个数据库的定义信息)
查看一个数据库的定义信息
SHOW CREATE DATABASE db1_1;可以查看到数据库创建时指定的字符集信息
-
修改数据库
修改数据库字符集
ALTER DATABASE 数据库名 CHARACTER SET 字符集; -
删除数据库
永久删除某个数据库
DROP DATABASE db1_1;
-
-
定义DATABASE中的TABLE
-
创建表
CREATE TABLE XXX(字段名 类型);使用LIKE可以快速创建一个表结构相同的表
-- 创建一个表结构与 test1 相同的 test2表 CREATE TABLE test2 LIKE test1; -
查看表
- 查看当前数据库中所有表
SHOW TABLES; - 查看指定表的表结构
DESC XXX;
- 查看当前数据库中所有表
-
删除表
DROP TABLE XXX;直接删除后再删除一次会报错,一般删除表使用DROP TABLE IF EXISTS XXX,表不存在就不删除
-
修改表
-
可以修改表名
-
可以修改表的字符集
-
可以向表中新加一列(新建字段)
alter table 表名 add 字段名称 字段类型; -
可以修改表中列的数据类型或长度(如VARCHAR类型数据的长度)
alter table 表名 modify 字段名称 字段类型;可以为主键添加自动增长关键字
alter table (表名) modify id int auto_increment; -
可以修改表中列的名称
alter table 表名 change 旧列名 新列名 类型(长度); -
可以删除列
alter table 表名 drop 列名;
-
-
3. DML:使用SQL操作数据表中的数据
-
插入数据
insert into 表名 (字段名1,字段名2...) values(字段值1,字段值2...);-- 一次性插入多行数据 insert into 表名 (列名1,列名2...列名n) values (值1, 值2...值n), (值1, 值2...值n), (值1, 值2...值n), ... (值1, 值2...值n); -
修改数据
update 表名 set 列名 = 值 [where 条件表达式:字段名 = 值 ]不加WHERE条件是修改全部,一般慎用
-
删除数据
-
delete from 表名 [where 字段名 = 值]不加WHERE条件删除全部数据,加WHERE条件后删除指定字段值的数据
-
TRUNCATE TABLE xxx删除指定表的所有数据
删除过程:先删除整张表, 然后再重新创建一张一模一样的表. 效率高
-
4. DQL:使用SQL查询数据表中的数据
-
使用SELECT的简单查询
基本格式
SELECT XXX FROM XXX;-
SELECT后FROM前的内容为查询的列,可以指定一个列名或多个列名(字段名),若只是指定为
*代表查询按照原表所有列进行。SELECT最后查询的结果会显示指定的列。
列名后可以使用AS关键字+'别名',使得查询结果的表中指定列名更改为指定的别名显示,不会更改表中原来的信息。
SELECT支持运算查询:指定列后面加上数字,使得查询结果中的这一列值都加上数字值。运算查询不会改变原表的数据,只是改变了查询结果。
-
FROM后为要查询的表名,可以指定一个表名或多个表名。简单查询中一般指定一个表名。
-
将SELECT改为SELECT DISTINCT使用,可以去除查询结果列中重复行的信息。
-
-
SELECT加上WHERE的条件查询
基本格式
SELECT XXX FROM XXX WHERE 条件表达式;-
条件查询的过程:先取出表中的每条数据,满足条件的数据就返回,不满足的就过滤掉 。
-
条件表表达式主要由比较运算符和逻辑运算符组成。
常用的比较运算符:
- 运算符
xxx = xxx:单等号判断两个列(字段)中值相等的所有行。 - 运算符
xxx LIKE 'xxx':进行模糊查询,查询条件中常用通配符_和%。用来判断指定列xxx(字段)中与查询条件匹配的所有行。 - 运算符
xxx IN(xxx):IN中的每个数据都会作为一次条件,只要满足条件就会显示。IN中放入一个集合,可以是多个具体数值或一列的表。 - 运算符
xxx IS NULL:查询xxx某一列(字段)值为NULL的所有行。判断NULL不能用符号只能用IS或IS NOT。
- 运算符
-
-
SELECT中的排序查询
通过ORDER BY子句,将查询出的结果进行排序(排序只是显示效果,不会影响真实数据)
基本格式
SELECT 字段名 FROM 表名 [WHERE 字段 = 值] ORDER BY 字段名 [ASC / DESC]- 单列排序:只按照某一个字段进行排序
- 组合排序:同时对多个字段进行排序,如果第一个字段相同 就按照第二个字段进行排序,以此类推
-
SELECT中聚合函数
使用聚合函数查询是纵向查询,它是对某一列的值进行计算,然后返回一个单一的值(另外聚合函数会忽略null空值)
基本格式
SELECT 聚合函数(字段名) FROM 表名;聚合函数中字段名表示指定某一列,也可以使用
*或1表示指定表中所有列,如使用COUNT(*)就会按所有列中最长的一列进行计算 -
SELECT中分组查询
分组查询指的是使用GROUP BY语句,对查询的信息进行分组,相同数据作为一组
一般配合分组字段和聚合函数来使用,单独查询某个字段或
*没有意义基本格式
SELECT 分组字段/聚合函数 FROM 表名 GROUP BY 分组字段 [HAVING 条件];分组操作中的having子语句,是用于在分组后对数据进行过滤的,作用类似于where条件
区别:
having后面可以用聚合函数,where后面不能使用聚合函数
having是分组后进行过滤,where是分组前进行过滤
-
SELECT中分页查询
LIMIT是MySQL中的方言
基本格式
SELECT 字段1,字段2... FROM 表名 LIMIT offset , length;
5. SQL格式标准Formatting Standard
-
数据库对象的命名
- 表或字段名避免使用复数单词
- 表或字段名超过一个单词使用下划线分割,如
employee_city - 尽量不要使用SQL关键字命名,若使用了关键字就要使用
` `包围,如`table_name` - 避免表或字段名过长,不要使用特殊字符,一般只用字母、数字和下划线来命名
- 仅在必要的名字中使用下划线,命名不要以下划线起始
- 避免将同一名称同时给出表和字段
- 主键字段避免直接命名
id,最好是结合表名和id,如id_employee
-
对齐
关键字每次在新的一行左侧,剩下的代码在右侧
SELECT p.PersonId, p.FirstName, p.LastName, c.Name FROM Person AS p JOIN City AS c ON p.CityId = c.CityId; -
缩进
- 运算符前后需要加空格缩进
-
注释
-
推荐使用多行注释
/* */,写这种注释新占一行,写在代码上方同代码一样的缩进SELECT p.PersonId, p.FirstName, p.LastName, /* Name column is the name of the city: */ p.Name, FROM Person AS p WHERE p.Name = 'New York'; -
单行注释
SELECT -- we have to delete this column p.PersonId, p.FirstName, p.LastName, p.Name FROM Person AS p;
-
-
SELECT查询
-
如果SELECT后有很多分开的字段,每个字段分开放一行,每一行字段需要缩进,
,写在每一行后SELECT p.PersonId, p.FirstName, p.LastName, c.Name FROM Person AS p; -
关键字FROM, WHERE, ORDER BY, GROUP BY, HAVING新写一行不用缩进
-
SELECT中有多个条件,需要使用
AND或OR带缩进新写一行在WHERE之内SELECT p.PersonId, p.FirstName, p.LastName, p.Name FROM Person AS p WHERE p.Name = 'New York' OR p.Name = 'Chicago'; -
SELECT中带JOIN、INNER JOIN、LEFT JOIN,都需要新写一行,ON需要新写一行带缩进在JOIN之内
SELECT p.PersonId, p.FirstName, p.LastName, c.Name FROM Person AS p JOIN City AS c ON p.CityId = c.CityId;
-
-
INSERT INTO中的缩进
单行插入,VALUES后行插入作为新的一行并带缩进
INSERT INTO Car(id_car, name, year) VALUES (1, 'Audi', 2010) ;多行插入,每行插入作为新的一行并带缩进
INSERT INTO Car(id_car, name, year) VALUES (1, 'Audi', 2010) , (2, 'Skoda', 2015) ; -
UPDATE中SET和WHERE新写一行不加缩进
UPDATE Car SET year = 2012 WHERE Name = 'Audi'; -
DELETE中WHERE新写一行不加缩进
DELETE FROM Car WHERE Name = 'Audi';
二、MySQL约束和事务
1. 约束
-
约束的作用:违反约束的不正确数据,将无法插入到表中
-
主键约束PRIMARY KEY
-
特点:不可重复、非空
-
创建主键有三种方式
-
删除主键约束的方式
-
含有主键约束的表结构查看
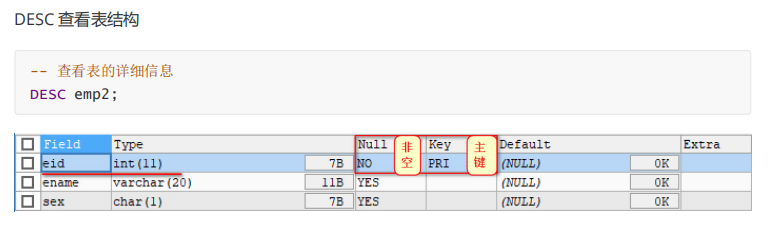
-
主键自增关键字AUTO_INCREMENT
- 添加条件:添加的字段类型必须是整数类型
- 创建主键自增的表时,可以自定义自增起始值
- DELETE FROM和TRUNCATE TABLE对自增长的影响不同
-
-
非空约束NOT NULL
- 特点:指定表中某一字段列非空
-
唯一约束UNIQUE
- 特点:表中的某一列的值不能重复(对null不做唯一的判断)
- 加了唯一约束的字段值可以为空
- 一个表中只能有一个主键约束,但可以有多个唯一约束
-
外键约束FOREIGN KEY
- 常用于多表中
-
默认值约束DEFAULT xxx
- 特点:用来指定某列的默认值
- 使用INSERT INTO添加数据时,可以将该字段值用DEFAULT代替表示使用了默认值,也可以不使用默认值直接添加
2. 事务
- 事务的概念
- MySQL中的事务操作
- 手动提交事务
- 自动提交事务
- 事务四大特性ACID
- 事务的四种隔离级别
- 事务的隔离性问题
- 脏读
- 不可重复读
- 幻读
三、MySQL多表、子查询和数据库设计
1. 多表
-
单表的缺点
- 缺点:冗余, 同一个字段中出现大量的重复数据
- 解决方法:设计为两张表
-
多表的外键约束
-
外键:在从表中与主表的主键对应的那个字段
-
外键的好处:使用外键约束可以让两张表之间产生一个对应关系,从而保证主从表的引用的完整性
-
外键的添加
外键添加注意事项:
- 从表的外键类型必须与主表的主键类型一致,否则创建失败
- 添加数据时应该先添加主表中的数据
- 删除数据时应该先删除从表中的数据
添加时可以省略外键约束的名称,系统会自动生成一个
- 新建表时添加
- 在已有的表添加外键
-
删除外键
-
级联删除
- 级联删除:在删除主表数据的同时,也删除掉从表的数据
- 级联删除的实现:需要在从表中添加级联删除关键字ON DELETE CASCADE
-
-
多表的常见关系
在SQLyog中使用架构设计器Schema Designer方便查看多表之间的关系
-
一对多关系
- 举例:部门和员工、客户和订单、分类和商品
- 建表原则:将多的一方视为从表,建立外键指向一的一方(主表)的主键
-
多对多关系
-
举例:老师和学生、学生和课程、用户和角色
-
建表原则:需要创建第三张表,中间表中至少两个字段,这两个字段分别作为外键指向各自一方的 主键
-
-
一对一关系
- 举例:实际开发中不多见,一般创建成一张表
- 建表原则:将从表中的外键设置为唯一约束指向主表的主键
-
-
多表查询
多表查询也属于DQL: 只是查询多张表,获取到需要的数据
使用
SELECT * FROM 表1,表2;直接进行多表查询的问题:交叉连接查询,因为会产生笛卡尔积,所以基本不会使用
-
内连接查询
内连接一般默认是从多的一方去找到一的一方的数据,这样的匹配是必然有对应关系的(所有从表外键值都能找到主表的主键值),这个过程相当于两张表取交集
内连接的特点:通过指定的条件去匹配两张表中的数据, 匹配上就显示,匹配不上就不显示
比如通过:从表的外键 = 主表的主键 方式去匹配
-
隐式内连接
特点:FROM子句后直接写多个表名,使用WHERE指定连接体条件
SELECT 字段名 FROM 左表, 右表 WHERE 连接条件;几个表名过长的可以起别名,方便在连接条件和字段名中使用
WHERE条件一般写连接条件从表的外键 = 主表的主键 方式去匹配和其他过滤条件使用逻辑运算符连接
-
显式内连接
特点:INNER JOIN ... ON
SELECT 字段名 FROM 左表 [INNER] JOIN 右表 ON 条件 -- inner 可以省略ON中条件一般写连接条件从表的外键 = 主表的主键 方式去匹配,在ON子句写完后面还可以添加WHERE过滤条件
-
-
外连接查询
外连接一般默认是从一的一方去找到多的一方的数据,这样的匹配是不一定有对应关系的(主表的主键值不一定有对应的从表的外键值),这个过程的结果相当于一的一方全部内容和两表的交集
-
左外连接:使用 LEFT OUTER JOIN , OUTER 可以省略
特点:以左表为基准, 匹配右边表中的数据,如果匹配的上,就展示匹配到的数据;如果匹配不到, 左表中的数据正常展示, 右边的展示为null
SELECT 字段名 FROM 左表 LEFT [OUTER] JOIN 右表 ON 条件ON连接条件同显式内连接
一般使用一的一方作为左表去匹配右表多的一方,匹配上的一的一方中的字段值会多增加几行,
匹配不上的字段只有一行,这一行中属于多的一方的字段值全为null
-
右外连接: 使用 RIGHT OUTER JOIN , OUTER 可以省略
特点:以右表为基准,匹配左边表中的数据,如果能匹配到,展示匹配到的数据;如果匹配不到,右表中的数据正常展示, 左边展示为null
SELECT 字段名 FROM 左表 RIGHT [OUTER ]JOIN 右表 ON 条件ON连接条件同显式内连接
一般使用一的一方作为右表去匹配左表多的一方,匹配上的一的一方中的字段值会多增加几行,
匹配不上的字段只有一行,这一行中属于多的一方的字段值全为null
-
-
2. 子查询SubQuery
-
子查询概念:一条select 查询语句的结果, 作为另一条 select 语句的一部分
子查询必须放在小括号中
-
WHERE型子查询:子查询的结果作为父查询比较条件
这种1*1的查询结果,可以直接当作数值变量来使用
-
FROM型子查询:子查询的结果作为一张表,提供给父层查询使用
当子查询作为一张表时,需要起别名,才能访问表中的字段
-
EXIST型子查询:子查询的结果是单列多行,类似一个数组, 父层查询使用 IN 函数 ,包含子查询的结果
常用于WHERE条件过滤;从一张表中过滤出的字段值用于另一张表中的查询条件
3. 数据库设计
-
数据库三范式
- 第一范式是最基本的范式。数据库表里面字段都是单一属性的,不可再分, 如果数据表中每个字段都是不可再分的最小数据单元,则满足第一范式
- 第二范式:在第一范式的基础上更进一步,目标是确保表中的每列都和主键相关,也就是一张表只能描述一件事
- 第三范式:消除传递依赖,也就是表的信息,如果能够被推导出来,就不应该单独的设计一个字段来存放
-
数据库反三范式
-
反范式化指的是通过增加冗余或重复的数据来提高数据库的读性能(以空间换时间)
举例:当需要查询“订单表”所有数据并且只需要“用户表”的name字段时, 没有冗余字段 就需要去join连接用户表,假设表中数据量非常的大, 那么会这次连接查询就会非常大的消耗系统的性能。这时候冗余的字段就可以派上用场了, 有冗余字段我们查一张表就可以了
-
-
关系型数据库设计
- 尽量遵循范式理论的规约,尽可能少的冗余字段
- 合理的加入冗余字段这个润滑剂,减少join,让数据库执行性能更高更快
四、MySQL索引、存储过程和触发器
1. 索引
-
概念:在数据库表中,对字段建立索引可以大大提高查询速度。通过善用这些索引,可以令MySQL的查询和运行更加高效
-
主键索引PRIMARY KEY
- 特点:主键是一种唯一性索引,每个表只能有一个主键,用于标识数据表中的某一条记录
- 添加主键索引方法同添加主键约束
-
唯一索引UNIQUE
-
特点:索引列的所有值都只能出现一次,必须唯一
-
在许多场合,人们创建唯一索引的目的往往不是为了提高访问速度,而只是为了避免数据出现重复
唯一索引保证了数据的唯一性,索引的效率也提升了
-
添加唯一约束方法:
- 创建表时直接添加唯一索引
- 修改表结构方式添加索引
- 使用CREATE UNIQUE INDEX语句进行创建,在已有的表上创建索引
-
-
普通索引INDEX
- 特点:普通索引(由关键字KEY或INDEX定义的索引)的唯一任务是加快对数据的访问速度。因此,应该只为那些最经常出现在查询条件(WHERE column=)或排序条件(ORDERBY column)中的数据列创建索引
- 添加普通索引的方法:
- 修改表结构方式添加索引
- 使用CREATE INDEX语句创建,在已有的表上创建索引
- 删除普通索引
- 作用:由于索引会占用一定的磁盘空间,因此,为了避免影响数据库的性能,应该及时删除不再使用的索引
- 修改表结构方式删除索引
-
索引使用场景和优缺点
-
使用场景:添加索引首先应考虑在 where 及 order by 涉及的列上建立索引
注意: 一般我们都是在创建表的时候 就确定需要添加索引的字段
-
优点:可以显著的减少查询中分组和排序的时间,大大的提高查询速度
-
缺点:创建索引和维护索引需要时间,而且数据量越大时间越长
-
2. 视图
-
视图概念:视图建立在已有表的基础上, 视图赖以建立的这些表称为基表;向视图提供数据内容的语句为 SELECT 语句,
可以将视图理解为存储起来的 SELECT 语句
-
主要作用:
-
权限控制时可以使用
-
简化复杂的多表查询:
视图本身就是一条查询SQL,可以将一次复杂的查询构建成一张视图, 用户只要查询视图就可以获取想要得到的信息,不需要再编写复杂的SQL
-
-
创建和使用视图
-
创建视图
create view 视图名 [column_list] as select语句; -
查询视图(可以看作是一张只读的表)
SELECT * FROM 视图名;
-
-
视图与表的区别
- 视图是建立在表的基础上,表存储数据库中的数据,而视图只是做一个数据的展示
- 通过视图不能改变表中数据
- 删除视图,表不受影响,而删除表,视图不再起作用
3. 存储过程
-
存储过程概念:
存储过程(Stored Procedure)是一种在数据库中存储复杂程序,以便外部程序调用的一种数据库对象。存储过程是为了完成特定功能的SQL语句集,经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行
-
存储过程主要优缺点:
- 优点:存储过程一旦调试完成后,就可以稳定运行,(前提是,业务需求要相对稳定,没有变化)
- 缺点:尽量在简单的逻辑中使用,存储过程移植十分困难,数据库集群环境,保证各个库之间存储过程变更一致也十分困难
-
存储过程创建和使用的3种方法:
-
创建存储过程和调用存储过程
DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 过程名称() -- 声明存储过程 BEGIN -- 开始编写存储过程 -- 要执行的操作 END $$ -- 存储过程结束call 存储过程名; -
向存储过程中传入字段参数,在执行的操作中可以调用这个字段参数
DELIMITER $$ -- 声明语句结束符,可以自定义 一般使用$$ CREATE PROCEDURE 过程名称(IN 参数名 参数类型) -- 声明存储过程 BEGIN -- 开始编写存储过程 -- 要执行的操作 END $$ -- 存储过程结束-- 调用存储过程中传入参数 call 存储过程名(参数类型的参数值); -
向存储过程中传入带OUT关键字的变量,定义执行的操作当存储过程结束时可以获取这个变量得到的结果,
调用存储过程可以获得返回值
-
4. 触发器
-
触发器概念
当我们执行一条SQL语句时,这条SQL语句的执行会自动触发执行其他的SQL语句
-
触发器实例
在下订单的时候,对应的商品的库存量要相应的减少,卖出商品之后减少库存量
5. 数据控制语言DCL
-
DCL的作用:
MySQL默认使用的都是 root 用户,超级管理员,拥有全部的权限;
可以通过DCL语言来定义一些权限较小的用户, 分配不同的权限来管理和维护数据库
-
创建用户
使用CREATE USER创建用户并定义用户名和密码以及指定在仅在本机登录或支持任意IP登录
-
用户授权
创建好的用户,需要进行授权,使用GRANT根据用户名和指定主机名进行授权
-
查看权限
使用SHOW GRANTS FOR根据用户名和指定主机名进行查看权限
-
删除用户
使用DROP USER根据用户名和指定主机名进行删除用户
-
查询用户
USE mysql; -- 选择mysql这个自带数据库 SELECT * FROM USER; -- 直接从USER中查询所有用户
6. 数据库的备份
- 使用SQLyog进行数据备份和还原
- 使用命令行对MySQL中数据进行备份和还原

 浙公网安备 33010602011771号
浙公网安备 33010602011771号