个人项目
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023 |
|---|---|
| GitHub链接 | https://github.com/Rainnnu/Rainnnu.git |
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/gdgy/SoftwareEngineeringClassof2023/homework/13324 |
| 这个作业的目标 | 按照软件工程的相关流程完成一个可以进行论文查重的个人项目 |
1.PSP
| Personal Software Process Stages | 预估耗时(分钟 | 实际耗时(分钟 |
|---|---|---|
| 计划 | 30 | 30 |
| 估计这个任务需要多少时间 | 3days | 3days |
| 开发 | 60 | 80 |
| 需求分析 (包括学习新技术) | 20 | 20 |
| 生成设计文档 | 30 | 30 |
| 设计复审 | 30 | 40 |
| 代码规范 (为目前的开发制定合适的规范) | 10 | 5 |
| 具体设计 | 20 | 20 |
| 具体编码 | 30 | 20 |
| 代码复审 | 20 | 15 |
| 测试(自我测试,修改代码,提交修改 | 30 | 30 |
| 报告 | 40 | 60 |
| 测试报告 | 30 | 30 |
| 计算工作量 | 20 | 20 |
| 事后总结, 并提出过程改进计划 | 30 | 30 |
| 合计 | 3days | 3days |
流程图
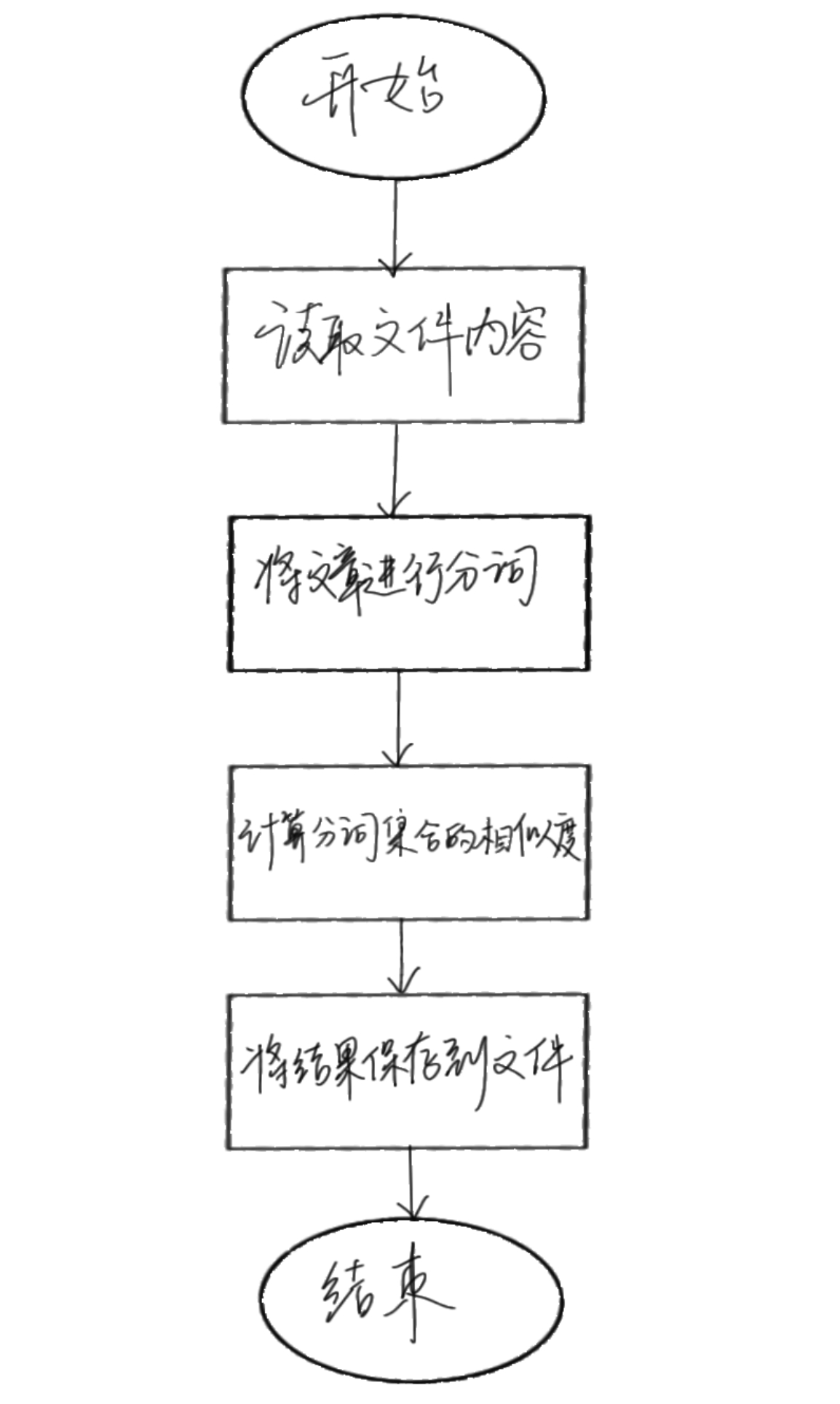
2.计算模块接口的设计与实现过程
将实现代码分为三个函数模块进行组织,分别是
- 文本预处理:before_calculate(text)
使用正则表达式去除标点符号和特殊字符。
使用jieba进行中文分词。
去除空白字符和空格。 - 相似度计算:similarity_calculate(orig_words,plag_words)
将原文和抄袭版的词汇分别转换为集合。
使用集合的交集和并集计算相似度。 - 主函数:main(orig_path, plag_path, output_path)
读取文件并将相似度结果(浮点型,精确到小数点后两位)写入指定的输出文件。
为什么选用jieba?
在论文查重代码中选择使用 jieba 进行中文分词,主要是因为分词是中文文本处理的基础步骤。中文文本没有像英文那样的单词分隔符(如空格),因此需要通过分词将连续的汉字序列切分成有意义的词语。在论文查重任务中,使用 jieba 进行分词可以显著提高相似度计算的准确性和效率。它不仅能够将文本分解为有意义的词语,还能减少噪声,支持更复杂的相似度计算方法。
3.计算模块接口部分的性能改进
接口无异常。但最初在进行文本预处理时,采用的方式是使用正则表达式re.sub去除标点符号和特殊字符,使用split()方法将文本分割成单词列表。该算法基于单词匹配,对于简单替换(如“星期天”替换为“周天”)可能无法完全准确检测。在用测试文件进行计算后,发现查重精度不高。后替换成精度更高的jieba。
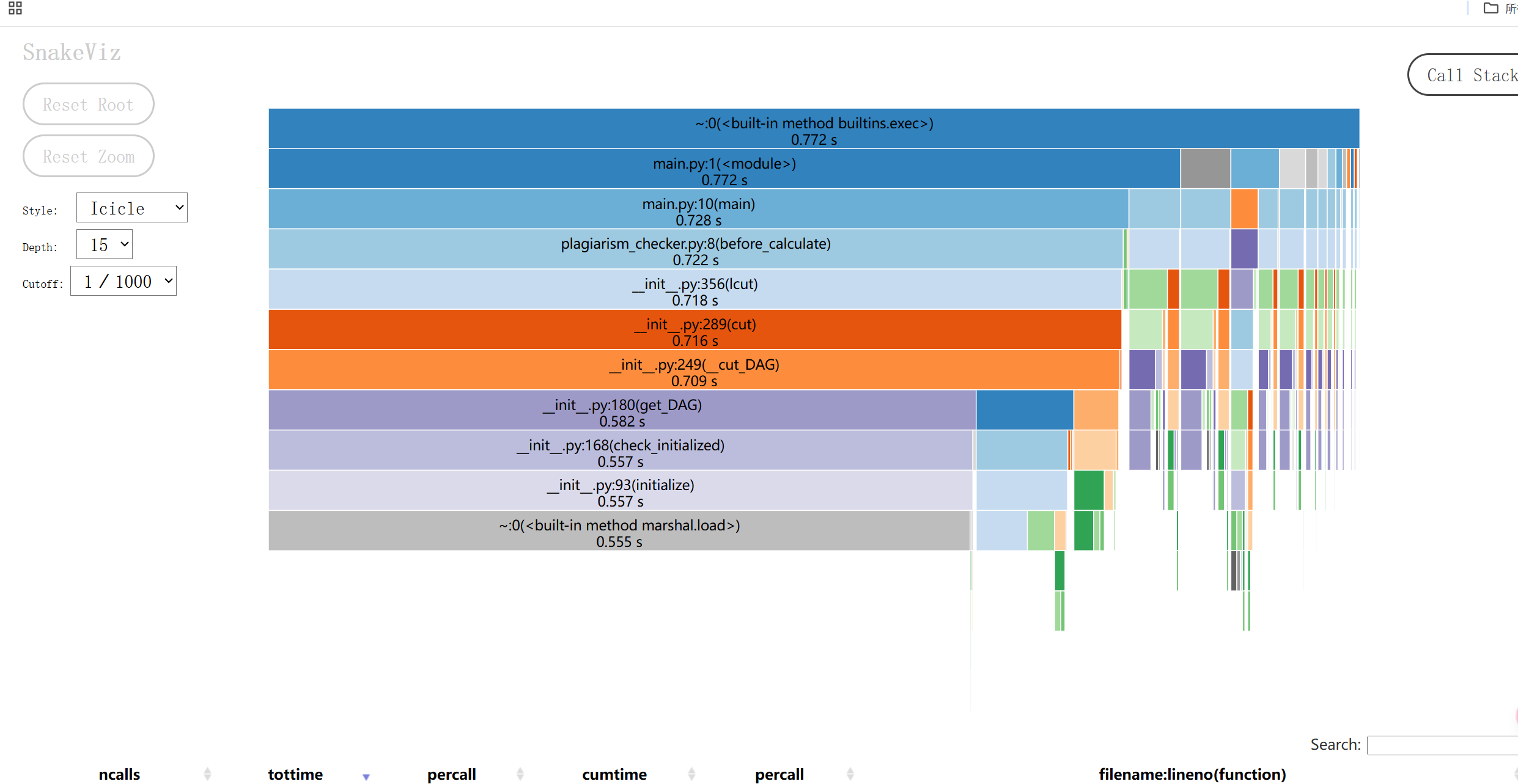
4.计算模块部分单元测试展示
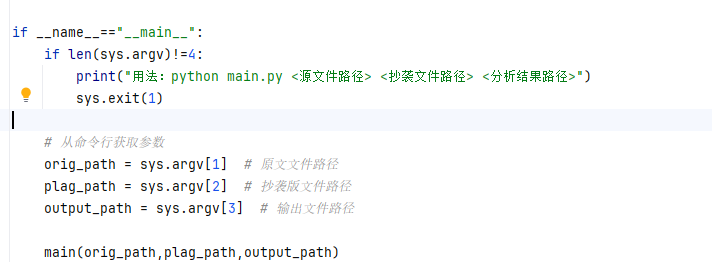
5.计算模块部分异常处理说明

 浙公网安备 33010602011771号
浙公网安备 33010602011771号