2023 暑假 清北学堂 笔记
未完结, 有较多漏洞, 勿喷
Day 1
拓扑排序
每次删去一个没有入度的点加到拓扑序中
板子
vector <int> res;
void topsort ()
{
queue<int> q;
for (int i = 1; i <= n; i++)
{
if (ind[i] == 0) q.push (i);
}
while (not q.empty())
{
int now = q.front();
res.push_back (t);
for (int i = last[now]; i; i = pre[i])
{
int t = to[i];
ind[t] --;
if (ind[t] == 0)
{
q.push (t);
}
}
}
}
扩展
求最长路
$ dis[u] = max (dis[u], dis[t] + w[i]) $
void solve ()
{
topsort ();
for (auto now : res)
{
for (int i = last[now]; i; i = pre[i])
{
int t = to[i];
dis[now] = max (dis[now], dis[t] + w[i]);
}
}
}
欧拉路
无向图
无向图欧拉回路: 所有点度数都为奇数
无向图欧拉路(非回路): 恰好有两个点度数为奇数
有向图
有向图欧拉回路: 所有点入度与出度相等
有向图欧拉路(非回路): 恰好有一个点入度比出度多1
找欧拉路
神奇的\(hierholzer\)算法
每次删去一条边后dfs, 然后dfs
struct Edge{
int u, v, w;
};
Edge es[maxn];
vector<int> g[N]; // g[i] 是edge编号
int euler_path[maxn];
int euler_cnt[maxn];
int cur[maxn];
bool vis[maxn];
void dfs (int u, int eid)
{
for (auto enow : g[u])
{
if (not vis[enow])
{
vis[enow] = true;
vis[enow ^ 1] = true;
euler(edge[enow].u, enow);
}
euler_path[++euler_cnt] = eid;
}
}
例题 Krolestwo
Subtask1 不考虑偶数
核心思想: 构建新超级点
然后找欧拉回路
再把欧拉回路切开匹配
Subtask2 (Solution)
核心思想: 打包
构造dfs树!
dfs树中间不会有跨子树的边
构造完dfs树不在树上的边就只有在子树上从下往上的边
把当前节点u每个子节点v向下还没有匹配的边和v到u的边打包成一条
打包以后再随便找路径即可(因为把他还原到原图中一定是一个长度为偶数的路径)
单元最短路
算法直接快速略过
好吧为了水笔记长度我还是把板子写了一遍
下面的板子是dijkstra
struct Node{
int t;
int dis;
friend bool operator < (Node a, Node b)
{
return a.dis > b.dis; // priority_queue 运算符变方向
}
};
int to[maxn], pre[maxn], last[maxn];
int w[maxn];
int cnt;
inline void addEdge (int u, int v, int ww)
{
cnt ++;
to[cnt] = v;
w[cnt] = ww;
pre[cnt] = last[u];
last[u] = cnt;
}
int dis[maxn];
bool vis[maxn];
void dij (int s)
{
priority_queue<Node> q;
memset (vis, 0, sizeof (vis));
memset (dis, 0x3f, sizeof (dis));
dis[s] = 0;
q.push(Node{s, dis[s]});
while (not q.empty())
{
int now = q.top().t; q.pop();
if (vis[now]) continue;
vis[now] = true;
for (int i = last[now]; i; i = pre[i])
{
int t = to[i];
if (dis[t] > dis[now] + w[i])
{
dis[t] = dis[now] + w[i];
q.push({t, dis[t]});
}
}
}
}
"直接"上例题
例1: Tales of seafaring
先证明如果存在长度为d的路径则一定存在长度为d+2的路径
因此只需要维护任意两点的奇偶最短路即可
怎么维护呢?
可以建一个分层图, 分奇偶交叉联边
这里详细解释一下:
其实奇数等于偶数加1, 因此转移的时候, 奇数由偶数转移过来, 偶数由奇数转移过来, 因此要交叉连边
然后再跑最短路
发现用dij复杂度带log
居然会T
然后又发现边权都是1
所以直接bfs
例2: 路障
次短路
dij时先求出\(d[i]\), 再考虑求一个\(f[i]\)表示次短路
与\(d[i]\)不同的是, \(f[i]\)初始值为\(min(d[j] + e)\)
然后再在更新\(d[i]\)的过程中更新\(f[i]\)
非严格次短路?
美妙的A*
可惜我不会
有时间再补
例3 Lamp
把对角线补全
原来的边边权为0
补全的边边权为1
跑最短路就行
然后又知道边权只有01
就可以用不带log的0-1 bfs解决
例4 飞行路线
分层图板子
小优化:
可以不用建新图, 直接用原图并在dij时写\(dis[i][k]\)表示第k层
并且转移的时候加上
if (know < k and dis[t][know + 1] > dis[now][know]) { // 可以转到下一层 dis[t][know + 1] = dis[now][know]; q.push(/*Node*/) }
例5 最快路线
仍然分层图
拆成V层, 第i层表示速度为i
小优化:
新建超级点, 可以将入边 * 出边 降为 入边 + 出边
例6 安排值班
每个奶牛的工作时间的左右端点都可以看作两个结点
然后发现每个奶牛的结束时间都可以向他之前的所有开始时间节点点连边
然后发现这样就变乘一个能跑最短路的图了
然后跑最短路
然后发现T了
所以考虑优化
总结刚才的做法, 核心思想是时间回溯
所以, 我们可以考虑构建一条长为MAXT的时间轴, 时间轴上每个点都向前连边, 每个结束节点向时间轴连边, 时间轴的对应时间向对应起点连边, 增加的辅助边边权都为1
然后跑最短路
然后发现又T了
然后发现可以使用0-1 bfs 去掉一个log
然后完结撒花
例7 TYVJ 1467
传送门 ? 不存在的
但是看到图上有奇偶, 直接一个分层图秒了
打了一个分层图
然后发现求的不是到Candy家最近的朋友而是Candy家能到的最近的朋友
因为这题的奇偶性, 不一定可以满足a可以到b则b一定能到a
所以建反图
然后完结撒花
例8 莫莫的等式
本例题 目前有待完善
居然是同余最短路!!!
(模意义下的最短路)
核心在于 按同余类建点, 按同余类之间的转移建边
同余类之间如何转移呢? 如果其他数能凑出当前同余类中的某一个数, 那么一定也可以凑出当前同余类的所有数(通过不断加当前的这个数), 所以我们要统计每个同余类中能被凑出的最小的数
所以对于当前同余类中的每个点都对其他同余类连一个边, 然后跑最短路
例9 The Captain
摆烂
构图? 见 安排值班
线段树构图
用线段树维护原图节点
然后就支持\(logn\)批量区间加边
(与线段树区间加减同理)
多源最短路
floyd
略
但是为了复习 水笔记长度, 我还是写了个模板
int dis[maxn][maxn];
inline void floyd ()
{
for (int k = 1; k <= n; k++)
{
for (int i = 1; i <= n; i++)
{
for (int j = 1; j <= n; j++)
{
dis[i][j] = min (dis[i][j], dis[i][k] + dis[k][j]);
}
}
}
}
例1 Cow Relay
矩阵快速幂
例2 负环
倍增思想
先不断倍增出\(f_{2 ^ k}\)
即从当前点走\(<= 2 ^ k\)步后回到当前节点的最短路的长度
然后\(O(\log n)\)找出2个小于零的最小\(f_{2 ^ k}\) (因为\(f_{2 ^ k}\)一共只有\(\log n\)个)
然后以两个\(k\)为端点, 在内部二分查找
例3 灾后重建
\(floyd\) 可以 \(O(n ^ 2)\) (不枚举k)更新dis数组
又因为这题询问比较毒瘤
所以离线后按时间排序, 每次排序完就可以\(O(n ^ 2)\)更新
生成树
例1 Kuglarz
震惊! 这是个生成树题?!!
发现如果用左闭右开的区间来表示原题中的区间
[a, x) 和 [x, b + 1) 正好可以凑出[a, b], 如果能凑出[1, n], 就能推出所有的点的奇偶性
这很像图中的边!
更进一步地,
我们的题意 (凑出[1 ~ n]) 这就可以转化为图上的连通性问题, 然后要求最小的询问次数, 即最小的连边次数, 就发现是最小生成树
例2 Tree
好题
每个白色边增加一个附加权重c, c越大, 最小生成树中白色边越少
而且, 还单调!
于是二分权重, 每次数一下白边的个数
核心思想 增加权重然后二分权重
本题思想也可以用在 飞行路线中, 并且可以处理k较大的情况
具体做法是先求一个s ~ t边数最短路
如果 <= k 则证明可以完全白嫖
如果 > k 则可以贪心的想到一定要用k次
然后就可以给每次白嫖增加一个权重, 二分这个权重使得白嫖次数正好等于k, 此时最短路径长即为
分数规划
最优比例生成树
求一收入benefit和花费cost总和比值最小的生成树
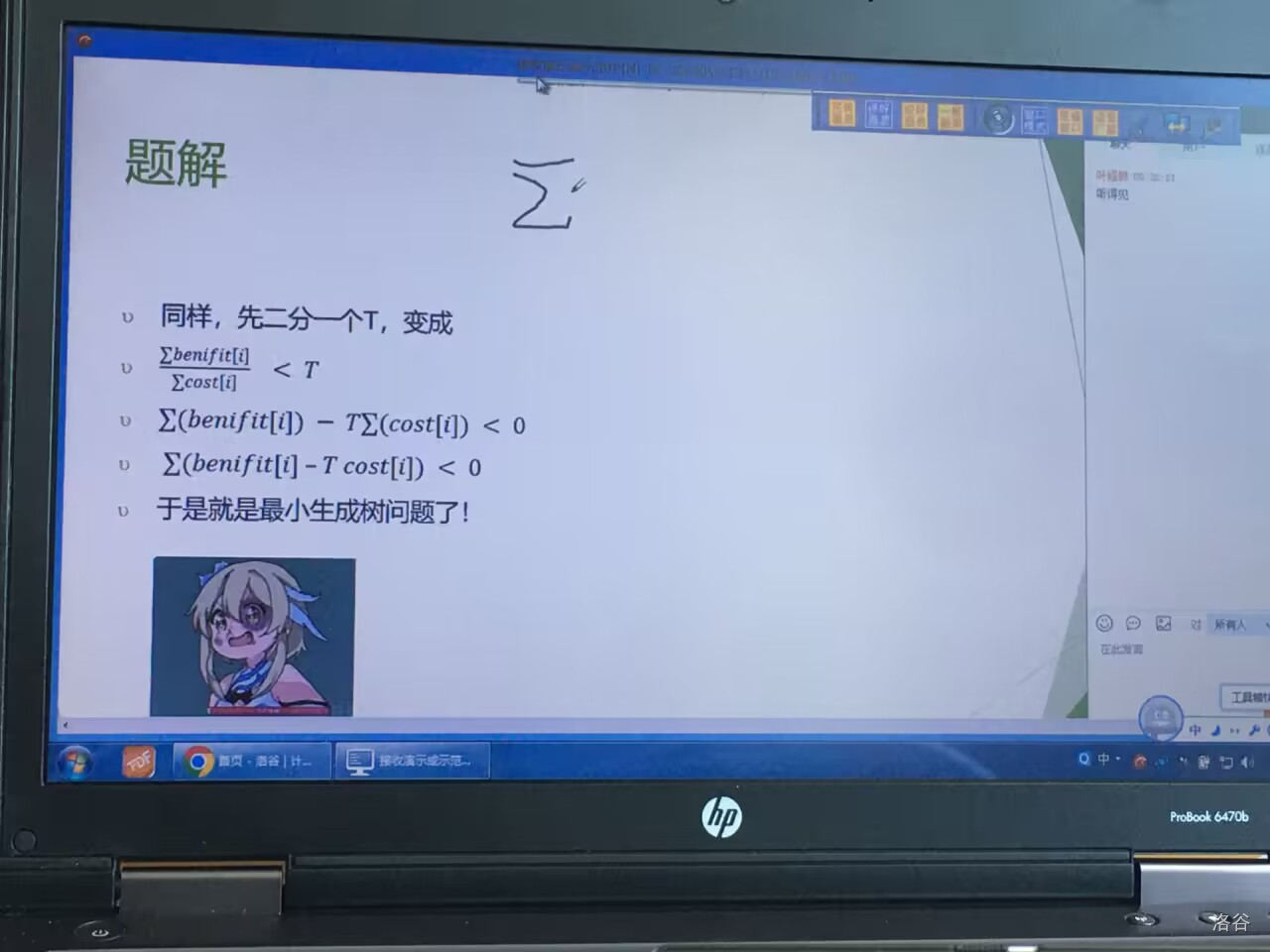
所以二分
真妙!
例 Talent Show
看到要求一个什么比值最小, 考虑分数规划
发现光用分数规划不是很行
需要保证总重量 \(\geq W\)
所以考虑背包
以 \(t[i] + T \times w\) 作为价值, \(w\) 作为重量, 然后把dp过程中产生的\(>W\)的结果都放到\(dp[W]\)上, 这样就可以保证, 每次最后的结果\(dp[W]\)是\(\geq W\)的
Day 2
树的直径
求法: 两次dfs
树的重心
定义: 到所有点带权距离之和最小的点
等价于从当前点断开最大子树最小
性质1: 一个点以所有子节点为根的的子树大小都 <= n / 2, 当前点为重心
性质2: 两棵树连起来, 新的重心在原有两棵树的重心的路径上
例1 Centrolds
2遍dfs
-
统计siz, 统计一个节点能删去的向上和向下的不超过n / 2的子树
-
每个点最大的儿子尝试剪掉最大的<=n/2的孙子并且使最大的儿子<=n/2, 如果可以则证明这个点k
例2 挑战NP-Hard
搞一棵原图的dfs树
dfs树上只有没有横插边
如果dfs树的深度>k, 显然存在长为k的简单路径
否则的话就把每个点的颜色设为深度即可 (深度<k 因此颜色数也一定<k)
LCA
求法
欧拉序求lca
先生成欧拉序p[]
则a, b的lca是a, b之间欧拉序的最小值所在的点
倍增
略
树剖
略
例1 货车运输
可以用kruskal搞出一个最大生成树, 这样就能把不需要的小边去掉
然后可以直接在树剖维护路径信息或倍增维护路径信息
更好的做法其实是kruskal重构树
kruskal 重构树
怎么搞kruskal重构树呢?
我们发现, 在做kruskal时会先进行排序, 那么最小生成树加入边的边权一定是从小到大的
那么如果我们知道了两点之间最后加的边, 就求出了两点之间路径的最大值
那么考虑把每个边断开, 对加入的每条边都新建一个节点, 点权等于边权, 刚才的问题就转化为了两个点之间最后加的点的点权
所以考虑把边权转为点权后, 每次并查集合并把新建的点作为根, 维护连通性
然后直接在并查集建的树(kruskal重构树)上求lca, lca的点权就是我们要两点间路径最大的
例2 运输计划
核心思想: 二分答案+树上差分
在计算机科学中, 判定往往比求解更加容易
这题我们发现直接做不好做, 但是我们知道这题求解的答案: 时间\(t\) 具有单调性
而且要使最大的\(t\)最小
所以, 这题的第一个重要思想: 二分 就呼之欲出了
那么现在开始考虑怎么样来写二分
其实二分的核心就是一个check()
所以我们假设当前check的时间是\(t\)
也就是看一下能不能在时间\(t\)以内完成所有计划, 也即在最大的耗时要小于等于\(t\)
那么我们可以先把所有耗时\(>t\)的计划找出来
然后考虑找一条公共边把边权改为0, 并且保证改为0以后能够使最大的耗时减小到t以下
为什么是公共边呢? 因为如果改的不是公共边, 只把某个计划的边改了并且使这个计划耗时减小到t以下, 其他任务的变没有被改, 因此必然仍\(>t\)
所以, 必须找公共边
那么现在开始考虑怎么样找这些计划(树上的链)的公共边
我们发现如果一个边是公共边, 这个边一定被所有耗时\(>t\)的计划经过 这不废话吗
所以统计有多少个计划耗时\(>t\), 每个边被多少个计划经过
很显然, 这是 树上差分 !
那么, 树上差分是什么呢?
树上差分
这里考虑的是每条边被经过的次数
但是考虑边不是很好考虑
因此尝试把边的差分数组转化到点上
所以用\(c[u]\)表示节点\(u\)到它的父节点这条边的差分数组
假设有一个计划是\(a\) → \(b\)
我们把它分成两块考虑: \(a\) → \(lca(a, b)\) 和 \(b\) → \(lca(a, b)\) 然后后在每一段所在的链上做和普通序列中一样的差分
因此每次处理任务时:
inline void addPlan (int a, int b)
{
c[lca(a, b)] -= 2;
c[a] ++;
c[b] ++;
}
因为\(lca(a, b)\) 在处理a时减了一遍, 在处理b时又减了一遍,所以对应的差分数组必须减小2
然后每次\(O(n)\) dfs 一次, 把差分数组做前缀和, 就可以得到每条边被经过的次数
得到经过次数, 判断一下是否满足\(maxL - w \leq t\)
注: maxL 是耗时最长的计划的时间长度, w是当前判断的这条边的边权, t是前面说的二分check的时间
然后二分, 完结撒花!
次小生成树
先求出最小生成树
接下来枚举所有不在生成树上的边, 求出它会使比安全和减少多少
需要倍增优化
基环树
每个点正好有一条出边, 称为基环内向树
每个点正好有一条入边, 称为基环外向树
基环树直径
首先考虑基环树的直径要么是环上的子树的直径, 要么是两个点向下的路径加上一段换上路径
前者很好求
后者我们先预处理出来一个\(f_u\)表示环上以u为根
然后再给环做一个前缀和,
棋盘上的守卫
如果把行列看成点, 把棋子看成出边, 做最小生成基环树即可
天天爱跑步
首先把路径拆成向上和向下的
设当前选手为i, 设当前观察员为j
向下:
创造虚拟起点 \(R_i\) , 终点 \(T_i\)
每个人拆成2部分, 从根节点到 \(lca\) , 权值为 \(-1\) ; 从 \(lca\) 到 \(T_i\) , 权值为 \(-1\) ,
到\(lca\)的权值为负数是因为我们把原来在\(lca\)另一侧的起点\(S_i\),
改为了在根节点上方的虚拟起点\(R_i\) (这个节点在根节点上面, 深度本应该是负的, 但这里为了方便计算仍然设成正的),
我们为了纠正点到根节点到\(lca\)的距离, 就必须把根节点到\(lca\)的权值都设为\(-1\)
然后从 \(lca\) 到 \(T_i\) 与原来一样, 本身就应该是 \(+1\)
然后考虑观察员j看到i的前提是:
即
又发现\(dep[j] - w[j]\)对于当前点是固定的, \(dep[R_i]\) 也是固定的, 因此可以维护一个数组, 然后再用dep[j]查询
可以注意到, 向下的路径可以不用考虑是否在子树中
因为相当于都从当前点的 \(R_i\) 往下跑, 从上往下跑都可以到达每个节点, 不需要区分子树
向上:
仍然像上面一样先拆点
但这里跟上面新建 \(R_i\) 有一点小差别, 这里需要搞一个开始跑的时间
然后用dfn序统计子树内的问题
推荐题目
-
BZOJ 3743 Kamp
-
BZOJ 1060 时态同步
强连通分量
tarjan
目前我看到过的最优雅的写法:
int low[maxn], dfn[maxn], dpos;
stack<int> stk;
bool ins[maxn];
int scc[maxn], scc_cnt;
void tarjan (int now)
{
low[now] = dfn[now] = ++dpos;
stk.push(now);
ins[now] = true;
for (int i = last[now]; i; i = pre[i])
{
int t = to[i];
if (not dfn[t])
{
tarjan (t);
low[now] = min (low[now], low[t]);
}
else if (ins[t])
{
low[now] = min (low[now], dfn[t]);
}
}
if (low[now] == dfn[now])
{
scc_cnt++;
do{
scc[now] = scc_cnt;
now = stk.top(); stk.pop(); ins[now] = false;
} while (low[now] != dfn[now]);
}
}
例1 联通数
强连通分量内的点两两可以互相到达
这样后进行缩点, 然后进行缩点, 变成DAG
然后拓扑排序, 递推求解
例2 间谍网络
仍然缩点
2-SAT 问题
定义: 有一些布尔变量之间的关系式, 求这组布尔变量的一个解
如何做呢?
在图上, 对每个变量真假各建一个点, 如果a能推出b, 则在a, b之间连边
发现连出来的边有一定的对称性
然后缩点后拓扑排序, 按拓扑序推导
发现推导的时候应该倒序推, 又因为tarjan用到了栈, 相当于一个反拓扑排序, 即scc 越大, 拓扑序越小, 所以当\(scc[x] < scc[!x]\)时x取true, \(scc[x] > scc[!x]\)时x取false
感性理解:
在一个图中, 拓扑序越大的点越接近终点, 因此选拓扑排序大的点不容易产生矛盾
如下图, \(x1\)选true只能往下走一个点, \(x1\)选false, 则有可能到达\(x1\)选true的哪个点
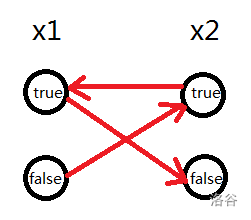
连边时注意推出的顺序: 一条从A的角度考虑, 一条从B的角度考虑
2-SAT 求为真尽可能多的的解是NPC问题
Day 3
最大流
板子
感性定义: 有向图中有一些水管, 每个管子有最大水流限制, 求从s到t的最大水流是多少
Ford-Fulkerson
核心思想是反悔
反悔的边是原图中边的反向边
如果我们给一个边增加了一点流量, 我们就给反向边也增加这样的流量, 所以反向边一开始是0(每个边对应的正向边还没有权值)
这样从当前节点走到另一个节点, 还可以通过反向边回来, 而且正好抵消(反向边流量等于正向边流量)
EK
但是呢, 发现这个算法跟流量有关
所以, 考虑优化
发现dfs在图中搜索是很乱的
所以, 用bfs, 找最短路增广
然后就变成\(O(VE^2)\)了
Dinic
然后发现 EK 连板子都跑不过
所以, 找到一个更好的算法\(Dinic\)
bfs先分层, 然后再用dfs进行多路增广最短路径
为什么要先分层呢? 因为我们dfs多路增广是非常容易互相干扰的, 因此我们分层, 使我们在多路增广的时候尽可能地减少互相干扰
然后还有个当前弧优化
就是指的在同一层bfs分层的几次dfs中, 我们每次会把前面搜过的那几条边流量耗尽
因此前面几条边就不用再dfs, 所以每次dfs时让head等于i, 每次bfs之前把它再改回来
然后上代码 水笔记长度
struct Edge{
int u, v, pre;
int flow;
};
Edge es[maxn];
int last[maxn], cnt = 1;
inline void _addEdge (int u, int v, int cap)
{
cnt ++;
es[cnt].u = u;
es[cnt].v = v;
es[cnt].cap = cap;
es[cnt].pre = last[u];
last[u] = cnt;
}
inline void addEdge (int u, int v, int cap)
{
_addEdge (u, v, cap);
_addEdge (v, u, 0);
}
int S, T;
void bfs ()
{
memset (dep, 0x3f, sizeof (dep));
dis[s] = 0; queue<int> q; q.push(s);
while (not q.empty ())
{
int now = q.front(); q.pop();
for (int i = last[now]; i; i = es[i].pre)
{
int t = to[i];
if (dep[t] == 0x3f3f3f3f and es[i].flow != 0) // 没有被访问且还有剩流
{
dep[t] = dep[now] + 1;
q.push(t);
}
}
}
return dep[S] == 0x3f3f3f3f;
}
int cur[maxn]; // 替代last, 当前弧优化
int dfs (int now, int flow_now) // flow_now: 到达当前点的流量
{
if (flow_now == 0 or now == T) return flow_now; // 没有流量了 or 到了 都直接返回
int res = 0; // 当前点能增广到t的总流量
for (int &i = cur[now]; i; i = es[i].pre) // &i 当前弧优化
{
int t = to[i];
if (es[i].flow == 0 or dis[t] != dis[now] + 1) continue; // 没有流量了 or t的不是now的下一层
int flow_t = dfs (t, min(es[i].flow, flow_now)); // 当前流向t的流量由 流向当前点的流量 和 now到t的边的容量 决定
if (flow_t) // 能流到t
{
es[i].flow -= flow_t; // now与t的边的容量被消耗了flow_t
es[i ^ 1].flow += flow_t; // 相应的反悔边也要加上flow_t
res += flow_t;
flow_now -= flow_t;
if (flow_now == 0) return res; // 没有容量了直接返回
}
}
return res
}
int dinic ()
{
int res = 0;
while (bfs ())
{
memscpy(cur, last, sizeof (last));
res += dfs (s1, 0x3f3f3f3f); // 源点拥有无限的流量
}
}
注释都很详细的,可以帮助理解&复习
最大流等于最小割
例题
March of the Penguins
拆点技巧
把每个点拆成两个, 这两个点之间的边的容量为\(m_i\), 这样就可以限制企鹅跳的次数
然后原来两个点之间如果可达, 则连的边的容量都是inf
然后枚举每个点作为汇点, 如果能满流(能被所有点经过), 证明这个点可以作为答案
MPIGS - Sell Pigs
建图
关键在于建图, 有时间再详细补
然后跑最大流
完美的牛栏 The Perfect Stall
这其实是个二分图最大匹配
但也可以用网络流来做 高射炮打蚊子
于是我们可以搞两部分, 一部分是牛, 另一部分是牛栏
然后因为每个牛栏都只能给一个牛住
所以把超源连向牛的边和牛栏连向超汇的边的容量都设成1
然后完结撒花
Dining G
这题主要是有两个限制条件:
-
每个牛都只能享用1种食物和饮料
-
每种食物和饮料都只能被一头牛享用
第一个限制条件的解决方案是 拆点
我们把本来的一个牛拆成两个两个点, 这两个点之间边的容量是1, 就可以保证不可能有2个或以上的食物通过这头牛
第二个限制条件的解决方案是 把超源和超汇的边容量都设成1, 这样就可以保证每种食物和饮料只能找到一头牛
然后套上板子就完结撒花了
IM - Intergalactic Map
拆点限流, 可以保证不能重复经过
拆出来两点之间的容量是1, 显然不可能被多次经过(多次经过就超过边的容量了)
切糕
最小割最难的题 --wyl
摆烂, 准备听回放
上下界最大流
Zoj3229 Shoot the Bullet|东方文花帖
不会, 摆烂
喜报: 会了!
设下界限制为 \(L\) , 上界限制为 \(R\)
-
无源无汇可行流:
首先我们发现上界的限制就跟普通最大流的限制是一样的, 所以我们解决问题的重点在于解决下界的限制
那我们既然有下界的限制, 我们就可以先把这下界的限制 \(L\) (即一定要流的)给推走, 给这些边先填充 \(L\) 的流量
所以, 这些边的限制变为了\([0, R - L]\) (只有上界)
但很显然的是, 我们每条边直接给它强制填充流量, 肯定是不行的, 有的点肯定凭空流出了流量, 有的点流量流进去以后凭空消失了, 这打破了原来的流量平衡, 我们现在把每个点积蓄/欠缺的能量记作 \(W_i\)
\(W_i\) 到底应该怎么算
我认为最优雅的方法是先算出\(i\)的入边中的流\(in_i\) 和 \(i\)的出边的流\(out_i\)
然后\(W[i] = in_i - out_i\)
所以呢, 我们考虑找一种方案, 使 \(W_i\) 恰好被全部用完/补全
这就需要一个可以凭空多出来/吸收流量的点(因为在原本的图里面跑显然是不行的)
那什么样的点有这样的性质呢?
自然是源点和汇点, 但是目前我们没有源点和汇点, 所以我们新建一个超级源点\(S\)和超级汇点\(T\)
所以对于每个\(W_i > 0\)的点(入边的流量大于出边), 都被超级源点\(S\)向它连一条容量为\(\lvert W_i \rvert\)的边, 每个\(W_i < 0\)的点(), 都向超级汇点连一条容量为\(\lvert W_i \rvert\)的边, 这样正好就把流量平衡了
然后这样再跑最大流即可, \(S\)如果能满流则证明是可行的
-
有源有汇上下界可行流:
源汇之间添加限制为\(\infty\)的边(相当于没有限制), 然后源点和汇点就被去掉了, 就把它转化为了无源无汇上下界可行流
建超级源点和超级汇点然后连边然后跑最大流就行了
-
有源有汇上下界最大流
刚才的最大流并不是为了求出源点与汇点之间的最大流, 而是为了判断是否存在可行流而在超级源和超级汇之间做的
那么怎么求原图源汇之间的最大流呢
我们先来把上次跑可行流的最大流跑一遍, 记结果为\(flow_1\),这样就可以把超级源点和超级汇点中间的边跑满
但原图上有一些边可能可以被原来的源点汇点跑最大流时消耗流量(即原图上可能仍存在增广路)所以我们就考虑上对原来的源点与汇点上做一遍最大流, 记结果为\(flow_2\)
答案显然就是\(flow_1 + flow_2\)
需要注意的一点
在对原图的源点与汇点跑最大流时, 需要把源点与汇点之间的无限长的边去掉
否则有可能产生死循环
最长反链
最长反链=最小链覆盖
最小链覆盖: 最少需要几条路径使得DAG被完全覆盖
然后用floyd传递闭包, 求出任意两点是否可达
于是变成了最小路径覆盖(每个点都只属于一条路径中)
因为我们要最小化路径数, 所以我们要最大化路径上的边数
每个点入度都去匹配另一个点的出度, 这正好是一个网络流问题
最小割问题
例1 切糕
好难, 摆烂
其实就是根据各种高度建几条链,
然后再根据限制条件连边, 求最小割
详细解释还是看下面的例2投票吧
例2 投票
这其实是就是切糕 (怎么能切小朋友呢
然后我们考虑怎么样建图

最小割只能最小化一个值, 那么最大化收益怎么求呢?
可以最小化损失即可
例3 方格取数问题
我们还是照常用切糕大法开切
总结一下切糕大法:
先来考虑一个结点的几种状态, 考虑这几种状态之间的关系:
如上面一题有睡觉和不睡觉两种情况
愿意睡觉的小朋友(上面的)睡觉的代价为0(边权为0), 不睡觉代价为1(矛盾数会增加1);
不愿意睡觉的小朋友睡觉的代价为1, 不睡觉代价为0
然后再考虑不同小朋友之间的关系, 然后发现每个小朋友之间有矛盾, 就可以加边(容量为1)
但是呢, 我们发现有明显可以优化的地方
每次建的容量为0的边, 没有什么用, 因为它容量是0, 不可能有流可以从这里流过去
但是它在这里, 徒增我们的空间复杂度
所以我们直接不连这些容量为0的边
然后这题看起来像是切糕大法构图的板子, 我们把板子套上, 就非常愉快的WA了
寄
我们发现题中有个限制条件: 要求任意两个数在原图中没有公共边
这个东西不好搞
但是我们又很容易发现, 题中还有一个奇怪的条件没有被我们用: 这是一个棋盘, 是网格状的
所以我们发现我们其实是可以把这个棋盘染成每个格子都与4边的格子颜色不同
例如
黑 白 黑
白 黑 白
黑 白 黑
这样染
然后我们就发现, 想让它们不相邻, 只要在构图转移(从黑点到百点)的时候把它们之间的边的边权取成inf不就行了吗, 这样在取最小割的时候一定不会取
然后跑最小割, 所有点都取的结果 - 最小割 = 答案, 完结撒花
奇怪问题
例: 狼抓兔子
一样看这不是板子吗, 直接让求最小割
但是发现这是一道紫题看到数据范围是 \(n , m \leq 1000\)所以点数大概有快1e6, 边数大概有3e6
显然普通最大流, 跑不过去
当然HLPP, ISAP一类毒瘤的东西也不是不行
但是HLPP一类的东西码量太大, 所以我们暂时不考虑
那么发现这题的图它是非常特殊的
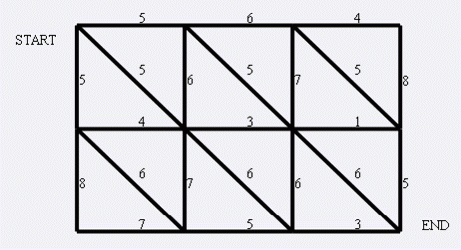
它是一种类似网格状的图
那么这种图有没有什么特殊性质呢
当然有
我们考虑什么是最小割
最小割实际就是用最小的代价把这个网格图的几条边切掉使它不连通
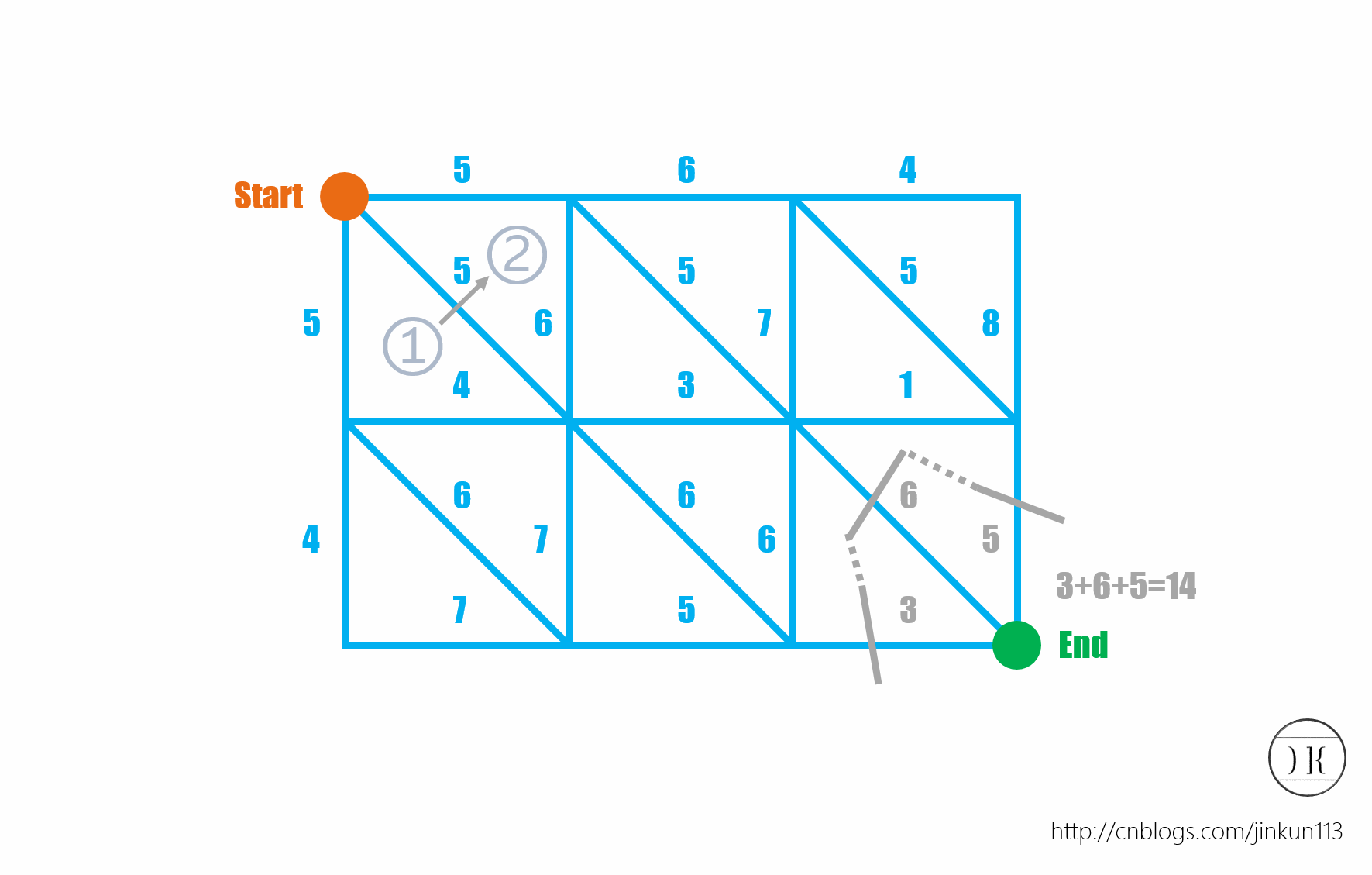
(感谢cnblogs jinkun113大佬的图片)
然后我们又会发现, 在这种图(平面图上), 我们画出的灰杠(被灰杠画掉的边是被割掉的边)居然可以连起来, 也就意味着如果把所有的灰杠画出来这是一条路径
所以我们不妨建一个新图, 对于每条原图上的的边都建一条斜杠, 边权与原边边权相等
那么我们要求的最小割不就是求个最短路吗, 然后一个dij就水过去了
感谢洛谷大佬d3ac在题解中的图
然后建好超级源和超级汇跑最短路即可
平面图中: 最大流 = 最小割 = 对偶图的最短路
Day4
数据结构
笛卡尔树
笛卡尔树就是是一种神奇的数据结构
每个点都有两个属性, 一个是 \(key\) , 另一个是 \(val\)
单看 \(key\) 笛卡尔树是一个二叉搜索树
单看 \(val\) 笛卡尔树是一个小根堆
所以treap(tree + heap)本质上也是笛卡尔树
那怎么建树呢?
首先 \(key\) 默认是编号, 否则就要把 \(key\) 排序
然后我们用栈维护树的右链
为什么是右链呢? 因为我们已经把 \(key\) 排序了, 每个新加入的点的 \(key\) 一定是最大的, 所以一定被插入在右链中
然后又因为要满足 \(val\) 是堆
所以我们要用单调栈维护右链, 找出右链中第一个 \(>val\) 的点(如果不存在这样的点, 就把插入的点设成根节点), 然后将这个点的有儿子设为当前插入的这个点
那如果这个点本来就有右子树呢? 我们就把右子树设成当前这个点的左子树(因为之前插入的点 \(val\) 都比当前这个节点的 \(val\) 小, \(key\) 都比当前节点的\(key\) 小, 所以设成左子树可以保持堆的性质)
搬运一张oi-wiki的图
那么笛卡尔树的应用呢? 反正不考
自然是有的: 笛卡尔树上两个点的lca对应的值, 是他们的RMQ 反正不考, 考了也能用别的数据结构代替
Hash
\(Hash\)本质就是使字符串一类本来不好比较的东西, 转化为可以比较的数进行比较
字符串Hash就是规定一个\(base\), 一个\(mod\), 把它转化为一个\(base\)进制的数,转化过程中模\(mod\)
但是这样容易被卡, 所以我们考虑双哈希
直接上代码
typedef unsigned long long ll;
struct Hash{
int h1, h2;
}h[maxn];
string str[maxn];
inline void getHash (int id, int now)
{
h[id].hash1 = 0; h[id].hash2 = 0;
for (int i = 0; i < str[id].size(); i++)
{
h[id].h1 = (h[id].h1 * base1 + str[i] - 'a') % mod1;
h[id].h2 = (h[id].h2 * base2 + str[i] - 'a') % mod2;
}
}
bool cmp (int a, int b)
{
if (h[a].h1 == h[b].h1 and h[a].h2 == h[b].h2) return true;
return false;
}
单次hash模数大概都是1e9级别的, 碰撞的概率只有 1 / 1e9
(彩票中奖概率都只有1 / 1e7)
但容易被卡
所以双哈希基本上没什么问题 (碰撞概率显然更小)
双哈希要是被卡了基本上可以去买彩票了
线段树
基础线段树先不搞了(
模板等有时间补一个
懒标记 Lazy Tag
就是在区间修改的时候如果已经递归到可以完全覆盖当前区间, 就给当前区间打上懒标记 Lazy Tag
只有在需要查询的时候才下传到具体的节点, 这就可以保证区间修改\(O(\log n)\)的复杂度
树状数组
核心就是一个\(lowbit\), 可以非常巧妙的建树
直接上代码
inline int lowbit (int x)
{
return x & (-x);
}
int t[maxn];
inline int add (int pos, int x)
{
for (int i = pos; i <= n; i+= lowbit(i)) res += t[i];
}
inline int sum (int pos)
{
int res = 0;
for (int i = pos; i; i -= lowbit(i)) res += t[i];
return res;
}
平衡树
什么样的树是平衡的?
很显然, 那种一条链一样的树是不平衡的
近似完全二叉树这样的树是平衡的
就是那种看起来不偏向一边的树
这种定义不怎么准确, 不喜勿喷 但平衡的树确实是这样的
Treap
建树
\(Treap\) 在说笛卡尔树的时候已经提到了, 就是 \(tree\) + \(heap\) , 也就是二叉搜索树+堆
但是笛卡尔树并不平衡
所以有可能单次复杂度被卡到 \(O(n)\)
这自然是不行的, 肯定会T
所以我们考虑构建一个平衡的树
这就需要我们把原来的树变成一颗平衡的树
所以我们需要的操作是旋转! 可以想象一下, 我们可以不断的旋转, 把一颗本来不是很平衡的树给搞成平衡的
当然, 这里的旋转不是是左右调换, 而是如下图所示 (换根)
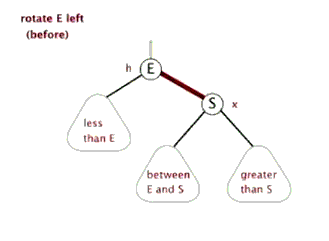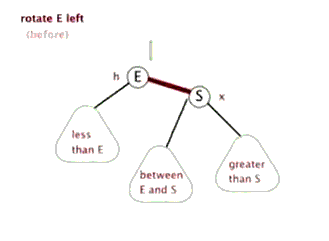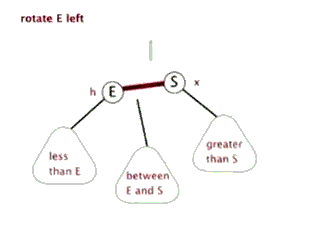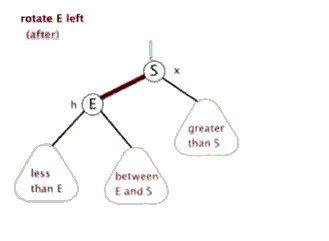
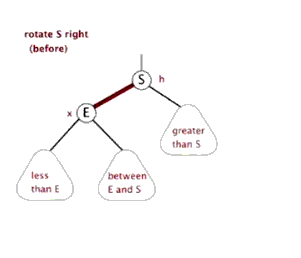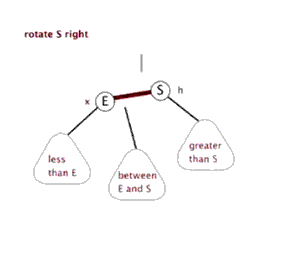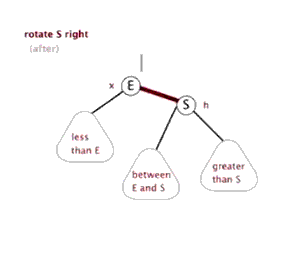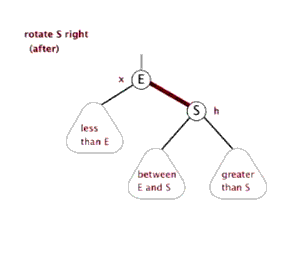
引用自这里, 感谢博主ljc20020730
那么 \(Treap\) 是如何旋转来保证复杂度的呢?
随机化!
没错, 随机化旋转是一个可以使 \(Treap\) 快速平衡的非常好的方法
就是建树时给每个点随机分配一个堆权值
然后通过旋转维护 \(Treap\) 的性质就行了
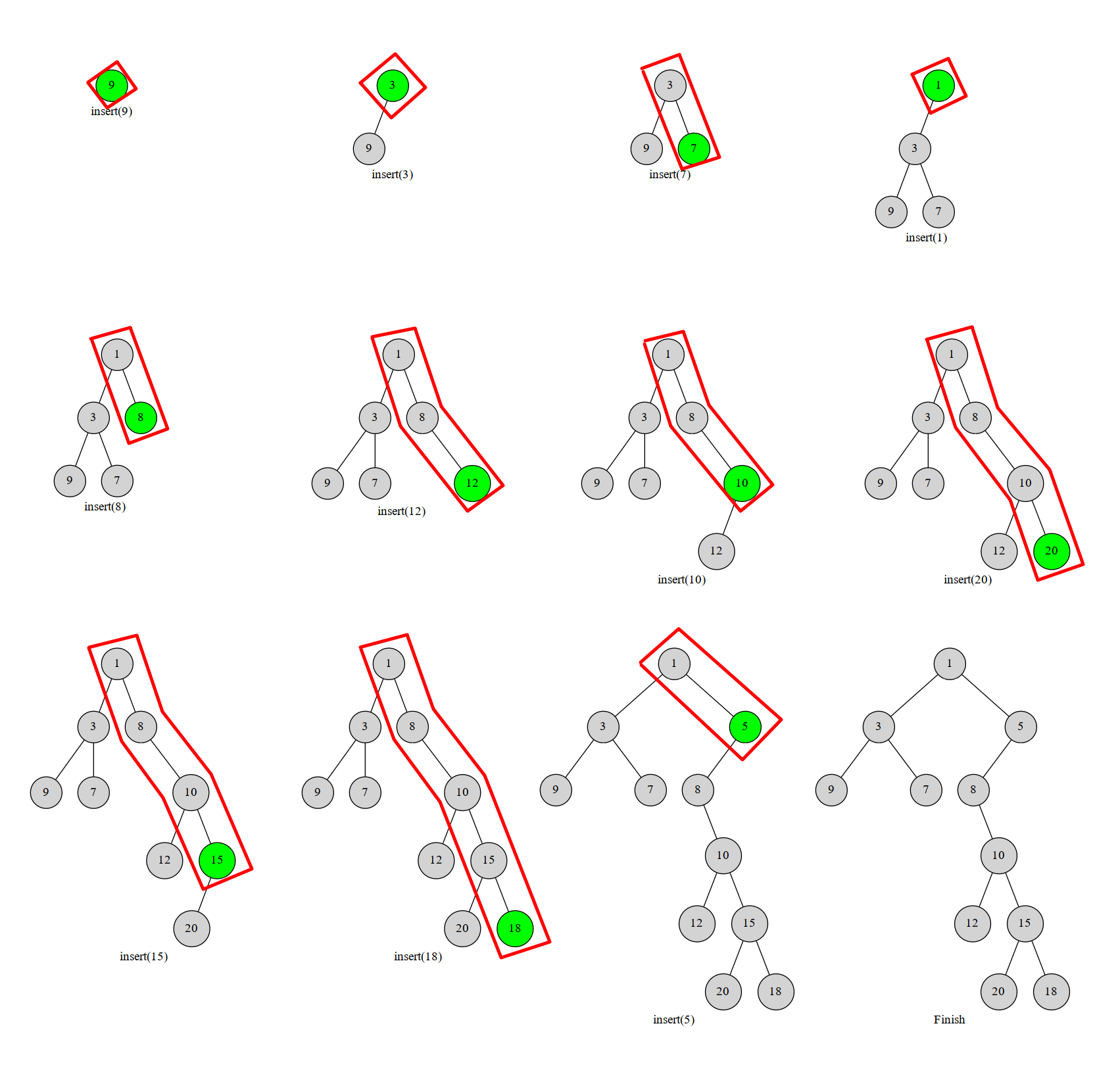
插入
总结起来就是一下几个步骤
- 分配一个随机的堆权值
- 把这个节点按照二叉搜索树的规则插入
- 然后在按二叉搜索树递归时旋转使得 \(Treap\) 满足堆的性质
然后为了优化, 我们把值相同的节点直接看作一个节点, 然后记录一下当前数值的出现次数即可
删除
朴素且不容易写错的方法是直接把这个点的所有属性都改成0, 然后不就相当于删除了当前这个点嘛, 然后常数爆炸, 可能T (但一般也不会T)
然后为了OI的严谨性, 正经的删除怎么做呢?
首先当前节点的出现次数-1
我们先判断当前这个点有没有儿子
-
如果没有儿子, 本身就是一个叶节点, 那直接删了也不会有什么事
-
如果有儿子, 但只有一个, 那也很简单, 让它的儿子替代它即可
-
如果有两个儿子怎么办呢? 那我们不停的旋转当前节点, 然后把当前节点变为一个叶节点, 直接删除即可
查询
自然是非常简单的
因为已经有了二叉搜索树的性质, 干什么都只需要 \(O(\log n)\) 从上到下统计即可
这样就可以查询 \(kth\) 和 \(rnk\) 了
分裂与合并
为什么要用 \(Treap\) ? 上面那些功能用线段树维护值域也大概可以实现
所以这就要体现 \(Treap\) 的独特性了, \(Treap\) 支持一些非常毒瘤的操作(比如分裂/合并)
分裂
我们可以想象有一把刀, 把原来的 \(Treap\) 从上往下切开 (下图红线)
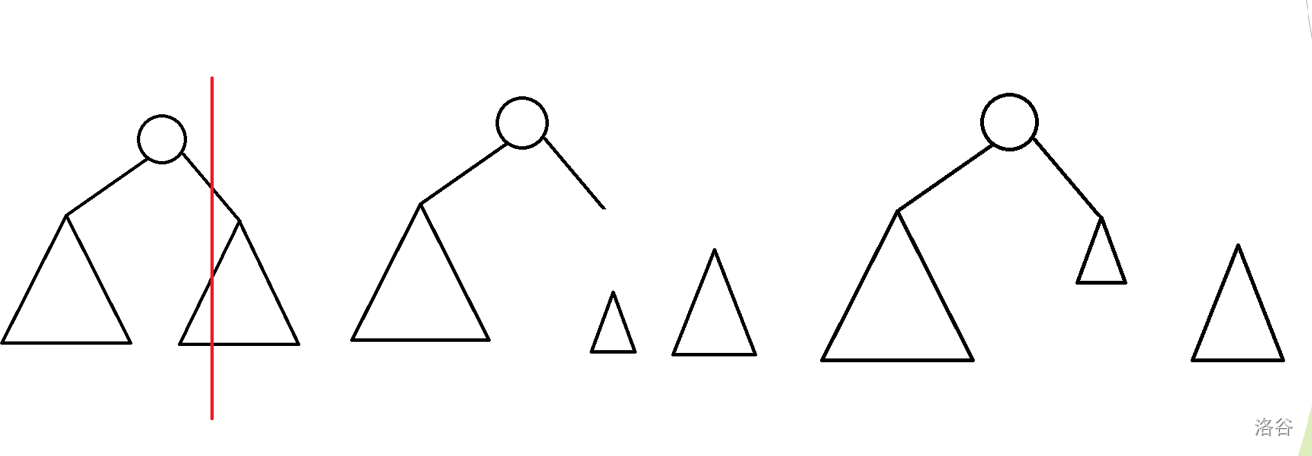
这样也许会切到一些子树, 但是这些子树应该属于前半部分(如上面第二个图中, 中间的那一小棵子树)
所以把这些应该属于前半部分的子树连在前半部分即可
合并
我们要合并的两个\(Treap\)肯定已经有序了
所以我们只需要考虑那个\(Treap\)的根节点可以作为合并以后的根
所以我们不断递归, 不停的看要合并的两棵 \(Treap\) 是在当前应该怎样合并, 然后合并即可
splay
介绍
我们发现在 \(Treap\) 上直接从上往下查询好像每次都是 \(O(\log n)\) , 并且几乎不能变小
所以, 我们 伟大的 \(Trajan\), 发明了一种神奇的毒瘤的数据结构 \(splay\) !
旋转
\(splay\) 的核心思想就是把要查询的点都通过各种各样的旋转, 旋转到 \(splay\) 的最顶上, 然后就可以直接查询了
为什么这样好呢?
因为我们如果反复查询相同的东西, 我们就只用每次取出 \(splay\) 的顶部就行了
其实, \(splay\) 本来的思想其实是把查询频率高的点放在深度浅的地方, 这样就能很容易 & 很快速的找到我们要查询的东西
然后 \(splay\) 与 \(Treap\) 不同的是 \(splay\) 是双旋 (单旋可能别卡成 \(O (n)\))
双旋, 主要分为以下两种情况
三点共线
什么是三点共线的情况呢?
像这样
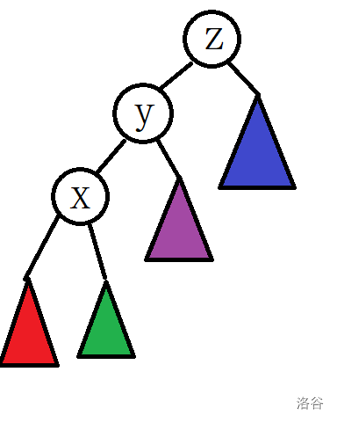
或这样
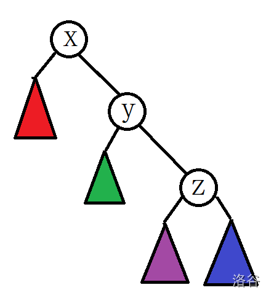
的就是三点共线
简单来说,
分块
分块就直接把区间分成多个块
查询的时候就看看区间都覆盖了那些完整的块, 把完整的块内直接统计成答案
然后剩下的散块暴力统计即可
通常情况下, 我们都是把块的大小设为 \(\sqrt{n}\)
这样保证期望复杂度大概是 \(O(n \times \sqrt{n})\)
其实对于特殊的题目, 我们还是可以优化的
比如说有的题目查询特别多, 我们可以把块的大小设小一点
有的题目插入特别多, 我们可以把块大小设大一点
总之可以根据题意
和大样例自己调整最佳的块的大小甚至为了应对卡分块的题目, 可以随机化块的大小
莫队
非常毒瘤
莫队最擅长的是统计区间内各种数的出现个数一类的东西
首先, 我们看
各种奇怪的区打标记技巧
区间加
区间加, 加法自然就跟线段树懒标记的加法标记是一样的
区间乘
区间乘, 又有区间加怎么办呢?
首先可定是要打两个标记
我们很容易发现, 加与乘之间的优先级是不同的 小学数学
所以, 先乘后加, 把树标记pushdown即可
区间最大子段和
我们发现维护最大子段和就一定需要
李超线段树
李超线段树主要功能是维护在平面直角坐标系上各种直线的问题
我们考虑怎么样合并这样的信息
首
各种例题
数据结构的解题方法
到底怎么维护?
怎么合并?
怎么push_down?
Day 5
其实是Day 5 下午, Day 5上午讲的还是数据结构
DP!
简单DP
DP的优化, 一般都可以总结为以下两方面的优化:
观察题目性质优化
毒瘤数据结构优化
先看道简单的例题
例1: LIS最长上升子序列
太简单了似乎没有题目链接
Subtask1
\(n \leq 10^3\)
那不一个 \(O(n ^ 2)\) 的DP暴力转移轻松水过去
转移方程就是
dp[i] = max {dp[j] + 1 | j < i && a[j] < a[i]}
但是如果一个 QBXT noip 重难点突破营的例题, 怎么能这么水呢
Subtask2
\(n \leq 10 ^ 5\)
这就需要优化了
那么怎么优化呢
一看这数据范围, 估计要把复杂度压到 \(O(n)\) 或者 \(O(n \log n)\)
线性复杂度的我不会, 所以 我们考虑 \(O(n \log n)\) 的解法
我们可以看到, 上面归纳的 \(DP\) 优化方法大概就有两种: 一种用数据结构, 一种观察性质
数据结构优化
一般来说, 观察性质挺难的, 需要思考
对于我这种懒得思考的蒟蒻自然是需要用毒瘤数据结构辅佐我
然我们考虑刚才转移方程的本质是什么
就是要找一数组值小于当前值的最大dp值
就是用汉语描述一下刚才的方程, 但是这样确实有帮助
然后我们发现要找数组值小于当前节点的值
一般怎么用数据结构维护大于小于一类的东西呢?
自然要使用值域数据结构
然后如果我们把值域下标对应的值设成dp
那我们就可以轻松找到数组值小于当前值的最大dp值
总而言之
我们用一个值域线段树/树状数组 (树状数组不能维护区间最值但其实可以维护前缀最值)来维护一个类似桶的东西, 以数组的值作为下标, 以dp的值作为桶中对应的值
比如说 \(a_1 = 2\) , \(dp_1 = 3\)
那我们就在值域线段树/树状数组上2的位置插入一个3
例2 LCIS 最长公共上升子序列
摆烂
例3 BZOJ 3782 上学路线
首先发现这数据非常不正常
按照每条路径第一个经过的障碍点来分类, 这样不会重
因为如果不满足条件, 就一定会经过一些障碍点
例4 项链
bzoj 4247
例5 乘积最大
记忆化搜索
例1 STANOVI
观察性质, 发现合法的切分方案必然有一条切割线贯穿当前矩阵
那么又因为要保证有窗户
所以分出以下几种情况
-
只有1面, 只能垂直与那仅有的1面切
-
有2面并且相邻, 可以竖着切, 也可以横着
但切完以后的两块一块是1, 一块是2
-
有2面但不相邻
-
有3面
然后不停递归求解即可
数位DP
挺简单的
主要是有以下几个注意的点
-
0可能本身可以作为一个答案, 记忆化的时候最好不用0作为未访问的标记
-
\(n = 0\) 可能是一种特殊的情况
-
不一定只有10进制可以做数位dp
概率DP
例1 OSU!
我们发现有一个重要的东西是题面里说:
相同的的 \(x\) 个 \(1\) 可以产生 \(x ^ 3\) 的贡献
然后我们考虑用
例2 概率充电器
树上DP
例1 树上最大独立集
首先我们发现这是个树上dp (废话, 这题本身就叫树上最大独立集)
例2 三色二叉树
这种在树上的染色问题, 似乎一般都是树上dp
例3 树上背包
很巧妙的一个方法是, 在dfs序上做背包
这样如果不选父亲, 跳过这段dfs序即可 (跳过这棵子树)
例4 树上染色
当前这条边的贡献与它的每棵子树中有多少黑色点有多少是没有关系的
因此可以处理出来它在子树内有一定黑点时的贡献
然后进行dp
状压DP
例1 Pakowaine
BZOJ3717
Description
\(n\) 个物品 \(m\) 个包, 物品有物品的体积, 背包有背包的容量, 现在求最小的背包使这些
Solution
例2 愤怒的小鸟
发现这题中的抛物线是 \(y = ax ^ 2 + bx\)
也就是说, 任意一个抛物线, 都只需要两个点(两头猪)就能确定
所以, 我们可以 \(O(n ^ 2)\) 枚举每个抛物线, 并且记录一下每条抛物线能打到的猪都是那些
然后我们考虑状压DP
先设计状态 \(dp[S]\) 表示消灭猪的集合为S时的最小抛物线数量
然后考虑转移
首先肯定可以暴力转移, \(O(n ^ 2)\) 枚举所有的抛物线, 然后再用这些抛物线更新所有的 \(dp[S]\)
显然, 有如下转移:
-
\(dp[0] = 0\) (这个是真的很显然)
-
\(dp[S | line[i][j]] = \min{dp[S] + 1}\) (增加一条经过 \(i\) 和 \(j\) 的抛物线, 然后转移到添加了这条线以后的dp, 同时dp值加1)
-
\(dp[S | 1 << (i - 1)] = \min{dp[S] + 1}\) (对于 \(i\) 这头猪, 单独开一条线, 不考虑这条线还能经过多少猪)
然后分析一下上面这种暴力转移到复杂度, 大概是 \(O(n ^ 2 * 2 ^ n)\) 这复杂度甚至还是是回文的
然后发现这样似乎可以过, 但又很可能不能过 (数据强一点就被卡掉了)
这显然是不是很好的
所以考虑优化?
我们发现, 我们最终是需要把每个猪都消灭掉的, 如果这一次不消灭这个猪, 之后一定有一次转移还是要把这头猪个消灭了, 而且它们的代价是一样的(都是增加1)
因此我们知道, 现在消灭这头猪和将来消灭这头猪是完全等价的
而且我们还能知道, 既然它们是完全等价的, 那为什么还要转移两次? 将来的那一次转移一定是多余的
所以我们直接在枚举当前猪的时候, 把让当前这头猪一定被消灭
而经过当前这头猪的抛物线只能有 \(n\) 条, 于是每次转移的时候都只会涉及到n条线
于是我们成功的把复杂度从 \(O(n ^ 2)\) 降到了 \(O(n)\)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号