
1 Introduction
人类的视觉系统是快速准确的。
目前的检测系统通过反复利用分类器来实现检测。例如DPM(可变形零件模型)使用滑动窗口法。
更近期的方法如R-CNN,先采用selective search算法提取约2000个建议框,然后在这些框上运行分类器。分类后进行修改边界框,消除重复检测,并根据场景中的其他对象重新设置框等。这些复杂的流水线速度慢且难以优化,因为每个部分都要单独进行训练。
YOLO的想法是将图像重新设计为单一回归问题,直接从图像像素得到边框坐标和分类概率。使用此系统,只需在图像上看一次就可预测对象的类型和位置。
YOLO非常简单,利用单个卷积网络可以同时预测这些盒子的多个边界框和类概率。 YOLO训练全图像并直接优化检测性能。 这种统一的模型与传统的物体检测方法相比有许多优点。
YOLO的优点
首先,YOLO速度非常快。 由于我们将检测视为回归问题,因此我们不需要复杂的流水线。 我们只是在测试的时候在一幅新图像上运行我们的神经网络来预测检测结果。 我们的基础网络运行速度为每秒45帧,Titan X GPU上没有批处理,而快速版本运行速度超过150 fps。 这意味着我们可以在不到25毫秒的延迟时间内实时处理流媒体视频。 此外,YOLO实现了其他实时系统平均精度的两倍以上。
其次,在进行预测时,YOLO在预测时会整体地考虑整个图像。 与基于滑动窗口和Region proposal的技术不同,YOLO在训练和测试时间期间看到整个图像,因此它隐式地编码关于类的上下文信息以及它们的外观。 快速R-CNN,一种顶级的检测方法,由于无法看到较大的上下文,因此在图像中出现对象的背景错误。 与Fast R-CNN相比,YOLO的背景错误数量少了一半。
第三,YOLO学习物体的一般化表示。 在对自然图像进行训练并对艺术作品进行测试时,YOLO大幅优于DPM和R-CNN等顶级检测方法。 由于YOLO具有高度概括性,因此在应用于新域或意外输入时不太可能发生故障。
YOLO的准确度仍然落后于最先进的检测系统。 虽然它可以快速识别图像中的物体,但它在精确定位某些物体,尤其是小物体小还稍有不足。 我们在实验中进一步检查了这些折衷。 我们所有的培训和测试代码都是开源的。
2 Unified Detection
YOLO将对象检测的单独组件集成到单个神经网络中。 我们的网络使用整个图像的特征来预测每个边界框。 它还可以同时预测图像中所有类的所有边界框。 这意味着我们的网络同时推测整个图像和图像中的所有对象。 YOLO设计可实现端到端训练和实时速度,同时保持较高的平均精度。
系统将输入图像划分为S×S网格。 如果对象的中心落入网格单元格中,则该网格单元格负责检测该对象。
每个网格单元预测B个边界框和置信度。 这些置信度反映了该模型如何确定方框是否包含一个对象,以及方框内的物体就是其预测的物体的准确度。 形式上,我们将置信度定义为\[\Pr (Object)*IOU_{pred}^{truth}\]
如果该单元格中不存在对象,则置信度分数应为零。 否则,我们希望置信度得分等于预测框与真实框之间的IOU(intersection over union,可理解为两方框的交集比上并集) 。
每个边界框由5个预测组成:x,y,w,h和置信度。(x,y)坐标表示相对于网格单元边界的框的中心。宽度和高度是相对于整个图像的。最后,置信度预测代表预测框与真实框之间的IOU值。
每个网格单元还预测C个条件类别概率 \[\Pr (clas{s_i}|object)\],这些概率是以该风格包含该对象求得的概率。对于每个网格单元,我们只预测一组类别概率,而不管方框的数目。
测试时将条件概率和单个方框的置信度相乘,\[\Pr (Clas{s_i}|Object)*Pr(Object)*IOU_{pred}^{truth} = {\rm{Pr(Clas}}{{\rm{s}}_i})*IOU_{pred}^{truth}\]
这给出了每个方框特定类的置信度分数,这些分数衡量了该类物体出现在此方框中的可能性以及预测框对该物体的合适程度。
2.1 Network Design
通过卷积神经网络实现,在PASCAL VOC 检测数据集上评估。
神经网络的初始卷积层从图像中提取特征,完全连接层预测输出概率和坐标。
此网络架构受到用于图像分类的GoogLeNet模型的启发。网络有24个卷积层,其次是2个完全连接层。与GoogLeNet使用的初始模块不同,我们简单地使用1×1的缩减层,然后是3×3的卷积层,这与Linet相似。 完整的网络如下图所示。
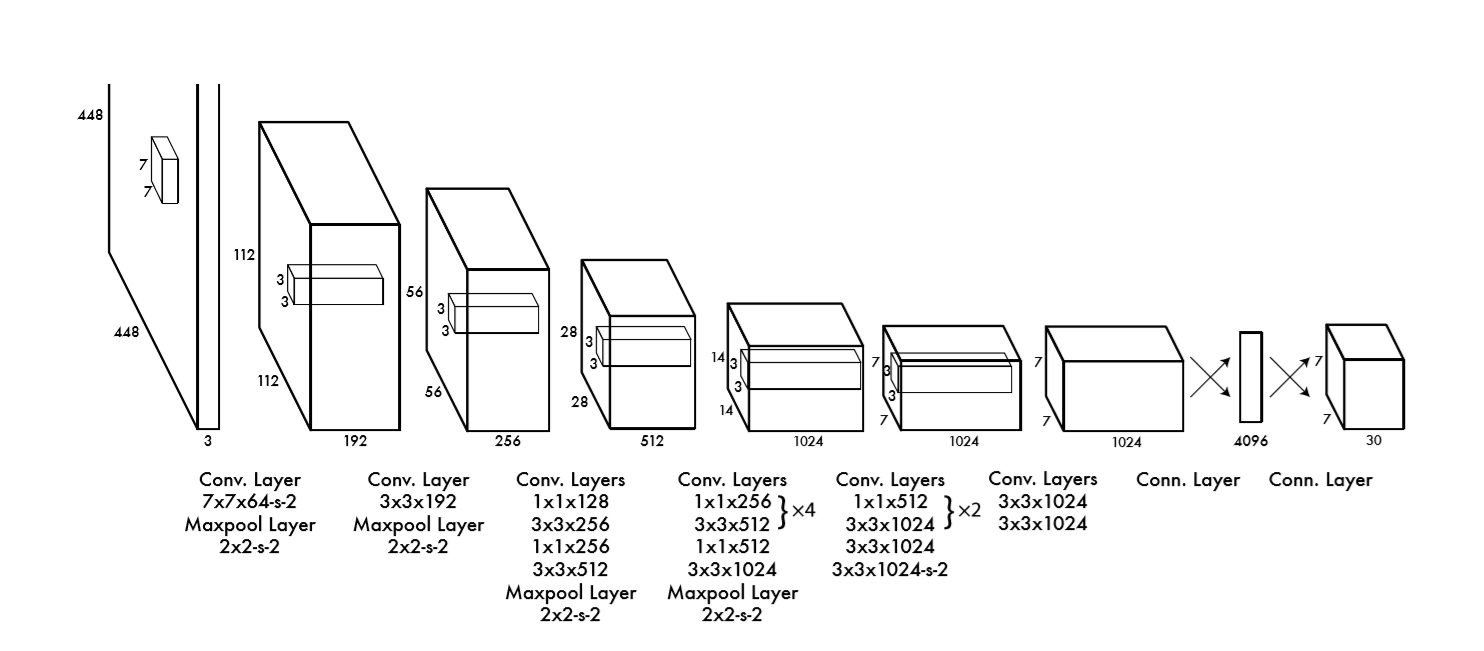
此外还做出训练了快速版本的YOLO以达到快速对象检测。快速YOLO使用较少卷积层的神经网络,并且在层中使用了更少的滤波器。除了网络规模外,YOLO和快速YOLO的训练和测试参数都相同。网络的最终输出是一个7 × 7 × 30的预测张量。
2.2 Training
用ImageNet上1000类 competition 数据集训练卷积层。使用了20个卷积层1个average-pooling layer 和一个完全连接层。训练了大约一周时间,在ImageNet 2012 的交叉检测集上实现了single crop top-5 accuracy 88%,与GoogleNet 的模型相当。
然后,我们将模型转换为执行检测。 Ren等人 表明,将卷积层和连接层添加到预训练网络可以提高性能。按照他们的例子,我们添加四个卷积层和两个完全连接的层,并且随机初始化权重。 检测通常需要细粒度的视觉信息,因此我们将网络的输入分辨率从224×224提高到448×448。
最终层使用线性激励函数,其他所有层使用以下leaky rectified linear activation:
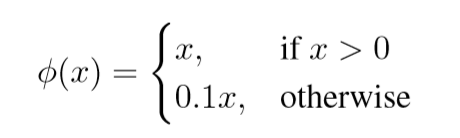
优化模型输出中的平方各误差。使用平方和误差是因为它易于优化,但它并不完全符合我们最大化平均精度的目标。它将局部化误差与分类误差同等加权,这可能并不理想。而且,在每个图像中,许多网格单元不包含任何对象。 这将这些单元格的置信度分数接近于零,使包含对象的单元格梯度很大。这可能导致模型不稳定,从而导致训练很快发散。为了弥补这一点,增加边界框坐标预测的损失,并减少不包含对象的框的置信度预测损失。 我们使用两个参数λcoord和λnoobj来完成这个。 我们设定λcoord= 5和λnoobj= .5。
平方各误差同样对大方框和小方框的误差进行加权。Our error metric should reflect that small deviations in large boxes matter less than in small boxes. 为一定程度解决此问题,我们预测方框宽度和高度的平方根而不直接预测宽度和高度。
YOLO预测每个网格单元的多个边界框。 在训练时,我们希望一个边界框预测器只负责一个对象。 我们根据哪个预测框和真实框具有最高的IOU从而指定此预测框用于检测当前对象。这使不同的边界框变得专一化。 每个预测框可以更好地预测某些尺寸,宽高比或对象类别,从而改善整体性能。
训练中优化以下多部分损失函数:
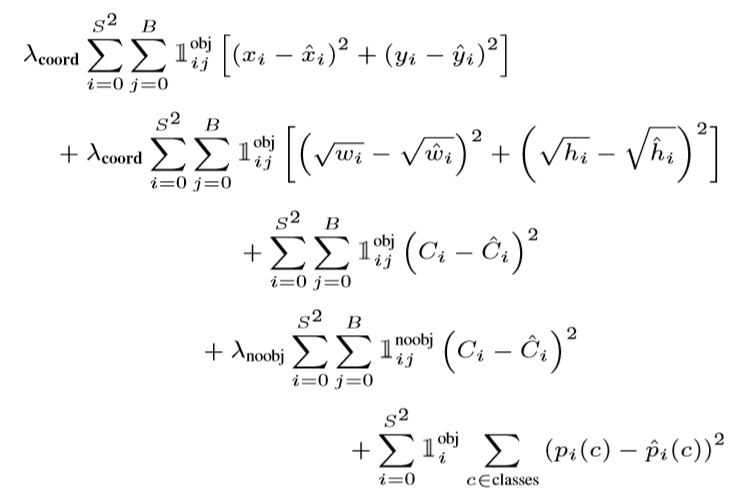
其中\[1_i^{obj}\]代表对象出现在单元格i中,\[1_{ij}^{obj}\]代表第j个边界框负责预测此对象。
注意如果一个对象存在于网格单元中,损失函数仅penalize分类误差。同样的如果此预测框确实是responsible for真实框,损失函数也仅penalize边界框坐标误差。
在PASCAL VOC 2007&2012的训练集和交叉验证集上进行了135次迭代训练。在2012数据集测试时,还包含了用于训练的VOC 2007测试集。训练过程中 batch size 为64,momentun 为0.9, decay 为0.0005。
我们的学习速率变化如下:对于第一个时期,我们慢慢将学习率从0.001提高到0.01。 如果我们从高学习率开始,我们的模型通常会由于不稳定的梯度而发散。 我们继续以0.01的学习速率进行75次的训练,然后以0.001的成绩完成30次,最后以0.0001的成绩完成30次。
为避免过拟合,使用dropout and extenxive data augmentation. 在第一个连接层后,速率为.5的dropout layer 避免了层间的co-adaptation.数据增强,我们引入了对原图尺寸高达20%的random scaling and translations.我们还在HSV色彩空间中随机调整图像的曝光和饱和度达1.5倍。
2.3 Inference
与训练时一样,预测测试图像的检测只需要一次神经网络评估。 在PASCAL VOC上,神经网络预测每个图像的98个边界框和每个框的类概率。 YOLO在测试时间速度非常快,因为它只需要一个神经网络评估,而不像基于分类器的方法。
网格设计强化了边界框预测中的空间差异性。 通常很清楚一个对象落在哪个网格单元,神经网络仅为每个对象预测一个边界框。 但是,一些大的物体或物体附近多个细胞的边界可以很好地被多个细胞定位。 非最大抑制可以用来确定这些多重检测。 对于R-CNN或DPM而言,对性能不是至关重要的,非最大抑制在mAP中增加了23%。
2.4 Limitations of YOLO
3 Comparison to Other Detection Systems
目标检测是计算机视觉中的一个核心问题。检测流水线先从训练样本中提取出一些 robust 的特征,例如Haar特征(反映图像灰度变化,分为边缘特征、线性特征、中心特征和对角线特征),SIFT ( Scale Invariant Feature Transform ),HOG(Histogram of Oriented Gradient ),Conventional Features。然后用分类器或者定位器识别特征空间中的对象,这些分类器或者定位器要么以滑动窗口的方式滑过整个图像,要么检测原图像的某些子区域。以下是将YOLO和一些top detection frameworks进行对比,并列出了重要的相同点和不同点。
Deformable parts models(DPM)
DPM使用滑动窗口的方式来进行目标检测,DPM使用disjoint pipeline来提取静态特征、对区域进行分类、并预测边界框的位。YOLO使用单一的CNN代替了这些分离的部分。这个网络同时执行特征提取,边界框预测,非极大值抑制,以及contextual reasoning。网络不是提取静态特征,而是一边训练一边优化检测性能,这种统一的结构使得YOLO比DPM更快更准。
R-CNN
R-CNN及其变体使用region proposal而不是sliding window来寻找图像中的目标。Selective Search生成可能的边界框,用一个CNN来提取特征,用SVM来计算边界框的scores,用一个线性模型来调整边界框和一个非极大值抑制算法来消除重复检测。这个复杂的流水线每一个阶段都需要独立地进行精确地调整,导致整个系统很慢,测试时每幅图像需要40秒以上。
YOLO和R-CNN有一些相似之处。每个风格单元提出可能的边界框并使用卷积特征对这些边界框进行评分。不同的是,YOLO系统对网格单元的proposals空间上加以限制,这减少了对同一对象的重复检测。每幅图像YOLO只会propose 98个边界框,而Selective Search每幅图像会生成2000个边界框。最后,我们的系统将这些单独的组件组合成一个单一共同优化的模型。
Other Fast Detectors
Fast and Faster R-CNN通过共享计算并使用神经网络propose边界框来代替Selective Search的方式来加速R-CNN。虽然这些使R-CNN的速度和准确率有所提高,但仍然不能达到实时检测的效果。
许多研究致力于加速DPM pipeline。他们回事HOG计算,使用级联,并用GPU来进行运算,但DPM的实时检测只能达到30Hz。
YOLO并不是优化detection pipeline的每个单独部分,而是完全抛开了pipeline,设计速度很快。
单一类的检测器如人脸或者人可以很好的优化因为只需要处理很少的变化,而YOLO可以同时学习检测很多种物体。
Deep MultiBox
与R-CNN不同,Szegedy等人使用Selective Search而是训练了一个卷积神经网络来预测可能的区域。MultiBox通过把置信度预测替换为单一类预测也能实现单一目标检测。然而,MultiBox无法实现通用对象检测,而且它只是一个更大的detection pipeline中的一部分,还需要进一步的图像分类模块。YOLO和MultiBox都使用了CNN来预测图像中的边界框,但YOLO是一个完整的检测系统。
OverFeat
Sermanet等人训练了一个CNN来实现定位并将该定位器用于目标检测。OverFeat有效地实现了滑动窗口检测但它只是一个disjoint system。OverFeat优化的是定位器而不是检测性能。例如DPM,定位器只能在进行预测的时候看到局部的信息。OverFeat无法对全局信息进行推理,因此需要重要的后续处理才能产生检测结果。
MultiGrasp
YOLO的设计类似于Redmon等人在grasp detection方面的工作。用网格单元来预测边界框就是基于MuntiGrasp system for regression to grasps。然而grasp detection是一项比目标检测简单得多的工作。MultiGrasp只需对一幅图片预测一个包含目标的graspable region。它不需要估计目标的尺寸、位置、边界框或者预测其类型,只需要找到一个region suitable for grasping。YOLO预测一幅图中多个目标多种类型的边界框和分类的概率。
4 Experiments
首先将YOLO和其他实时检测系统在数据集PASCAL VOC 2007上比较。为了了解YOLO和R-CNN及其变体之间的区别,我们计算了错误率,这是R-CNN表现最好方面之一。基于这些不同的错误率,我们发现YOLO可以用来重新定位Fast R-CNN检测并减少背景误报引起的错误,使其性能有重大提升。我们还测试了在VOC 2012上的结果并将mAP与当前最先进的方法进行比较。最终我们发现比其他检测系统在两个artwork datasets上具有更好的泛化性。
4.1 Comparison to Other Real-Time Systems
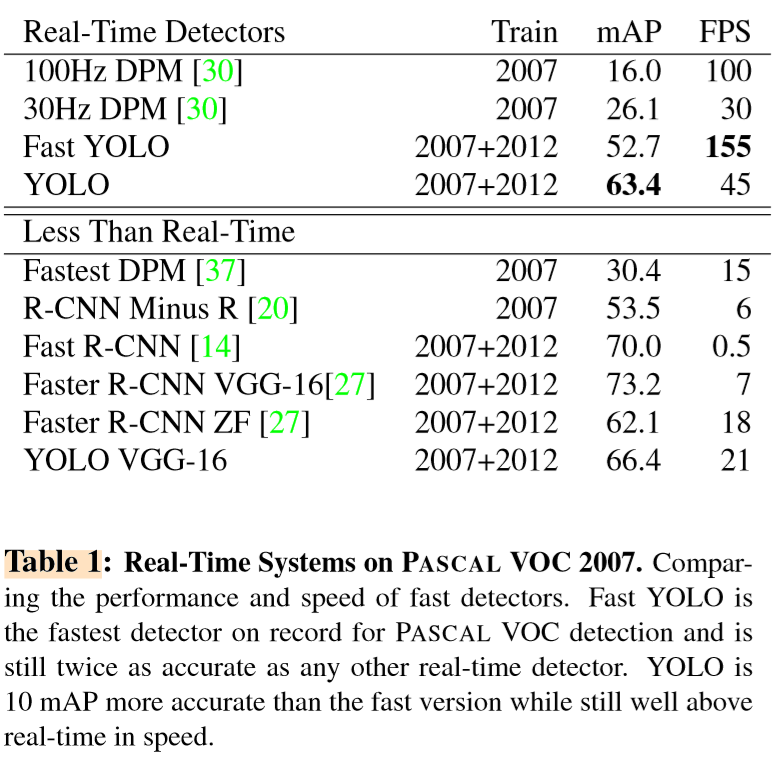
目标检测方面的许多研究工作都集中在加速标准的detection pipeline。然而,只有Sadeghi等人做出一个可以实时检测的检测系统(30fps或更好)。我们将YOLO和他们30Hz或100Hz的DPM的GPU实现进行了比较。虽然其它的努力还没有达到实时检测系统的里程碑,我们还比较了它们的相对mAP和检测速度来测试它们在目标检测系统中所能达到的准确率和性能折衷。
Fast YOLO是PASCA上L最快的目标检测方法,据我们所知,它是现存最快的目标检测系统。它的mAP为57.2%,比之前实时检测系统的准确率高出一倍以上。YOLO在mAP达到63.4%的状态下还能保持实时检测。
我们还用VGG-16来训练YOLO。这个模型更加准确但却要慢很多。将它与其他依赖于VGG-16的检测系统进行比较是有意义的,但由于它比实时检测系统慢,所以本文重点描述我们更快的模型。
Fastest DPM在没有损失多少mAP的前提下有效加速了DPM,但它的实时性能降低到了原来的一半。而且与NN相比,DPM检测的准确性也相对较低。
R-CNN minus R用静态边界框proposals替代了Selective Search。尽管它比R-CNN快很多,但它仍然缺乏实时性,而且因为没有好的proposals而导致准确性严重下降。
Fast R-CNN对R-CNN的分类阶段进行加速,但它仍然依赖于Selective Search,这使其每幅图像大约需要2秒来生成边界框。因此它的mAP很高但只有0.5fps,远不能达到实时效果。
最近的Faster R-CNN用一个神经网络代替Selective Search来生成一边界框,与Szegedy等人的工作有些类似。在我们的测试中,他们最准确的模型达到了7fps,而规模更小准确率更低的模型可以到18fps。VGG-16版本的Faster R-CNN比YOLO的mAP高10%但速度只有YOLO的六分之一。Zeiler Fergus Faster R-CNN只比YOLO慢2.5倍,但准确率却低。
4.2 VOC 2007 Error Analysis
为进一步比较YOLO和其他先进的检测器,我们将详细分析VOC 2007上的测试结果。我们将YOLO和Fast R-CNN进行比较,因为Fast R-CNN是PASCAL上性能表现最好的检测器而且它的检测结果是公开的。
我们使用Hoiem等人的方法和工具。对每个类别测试时,我们考察该类的前N个预测,每个预测根据误差类型来分类:
Correct:correct class and IOU > 0.5
Localization:correct class,0.1 < IOU < 0.5
Simliar:class is similar,IOU > 0.1
Other:class is wrong,IOU > 0.1
Background:IOU < 0.1 for any object
Figure 4 显示了所有20个类别的平均错误类型的细分。
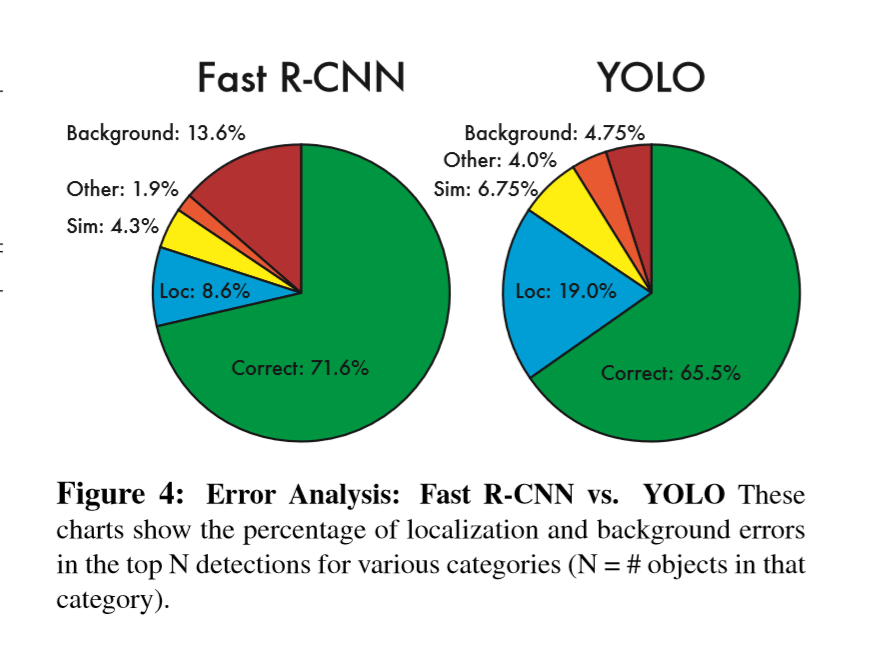
YOLO致力于对目标的准确定位。localization error比YOLO的其它误差总和所占比例还大。Fast R-CNN中localization error占比例更少,更多的是background error。它的最高检测结果中有13.6%是false positive,不包含任何目标。Fast R-CNN预测背景检测的可能性比YOLO高出3倍。
4.3 Combining Fast R-CNN and YOLO
YOLO比Fast R-CNN产生更少的背景误报。用YOLO来消除Fast R-CNN中的背景检测我们使性能显著提升。对于R-CNN预测的每一个边界框,我们都检查YOLO是否给出一个相似的边界框的预测。如果是,我们就根据YOLO预测的概率和两个边界框的重叠情况对R-CNN给出的概率作一定的提升。
最好的Fast R-CNN模型在VOC 2007测试集上mAP达到了71.8%,当把它与YOLO联合起来时,其mAP达到了75.0%。我们还尝试将最好地Fast R-CNN和其它版本的Fast R-CNN结合起来,这些模型的mAP的增长在0.3%到0.6%之间,详见Table 2。
从YOLO中得到的提升并不仅仅是模型联合的副产物,因为将不同版本的R-CNN结合起来并没有什么好处。相反,正是因为YOLO在测试时会有误差,它才能有效地提升Fast R-CNN的性能。
不幸的是,这个模型联合并不能得益于YOLO的速度,因为我们单独运行每个模型再把结果联合起来。但由于YOLO很快,与原来的Fast R-CNN相比它并不会增加很多计算量。
4.4 VOC 2012 Results
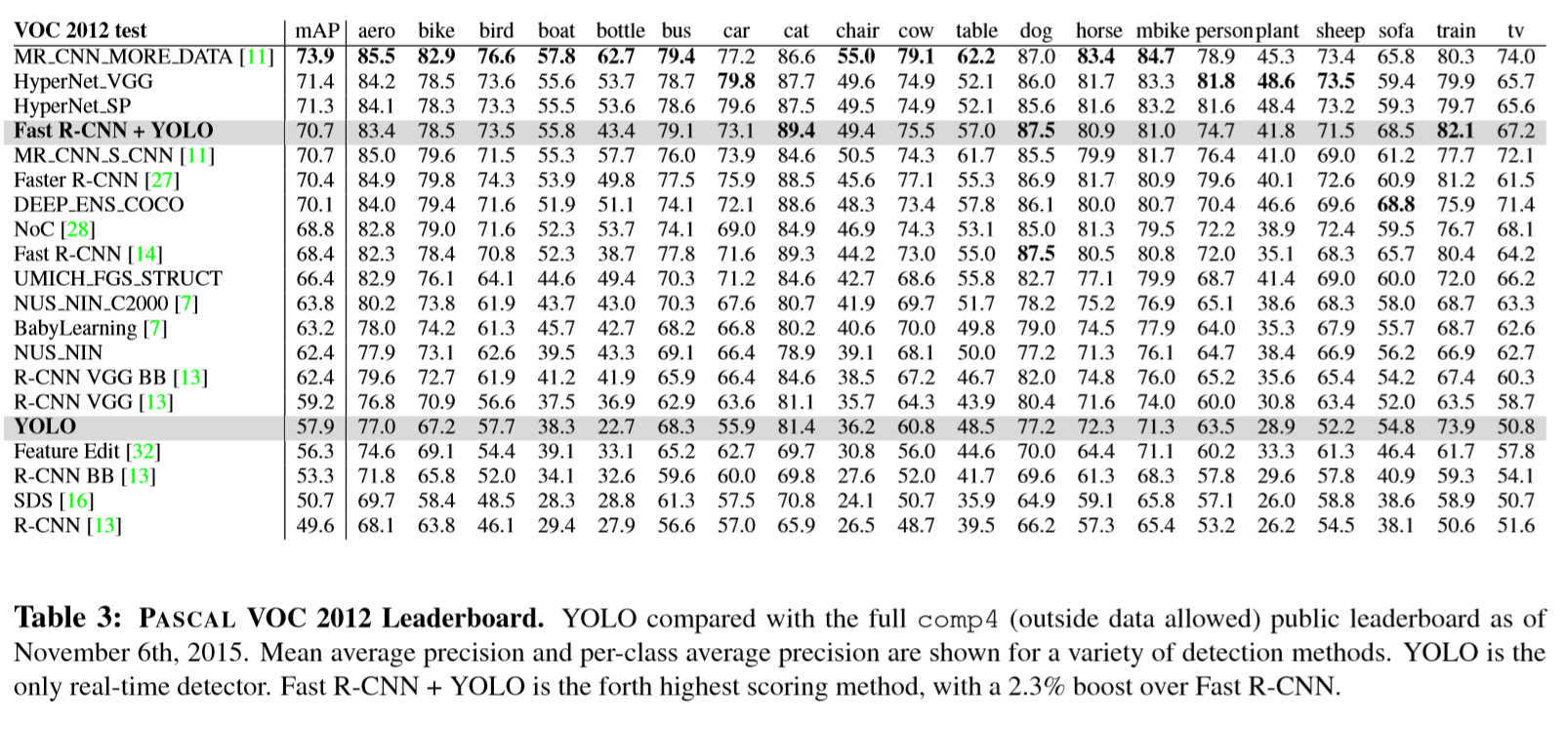
在VOC 2012测试集上,YOLO的mAP为57.9%。这比现有的技术水平低,接近于使用VGG-16的原始R-CNN。与之相比,YOLO在检测小的目标时性能较低。在bottle,sheep,tv/monitor等类别上,YOLO的评分比 R-CNN 或 Feature Edit 低 8%~10%。然而在其它类别如cat,train上YOLO达到了很高的性能。
我们联合的Fast R-CNN+YOLO模型检测性能最高的方式之一。Fast R-CNN通过和YOLO结合,mAP提高了2.3%,在排行榜上提升了5位。
4.5 Generalizability: Person Detection in Artwork
用于目标检测的学术数据集从同一分布中获取训练集和测试集。在实际应用中,很难预测用例和测试集有什么不同。我们将YOLO和其它检测系统在Picasso Dateset和People-Art Dataset上的表现进行了比较,这两个数据集用于艺术品上的人物检测。
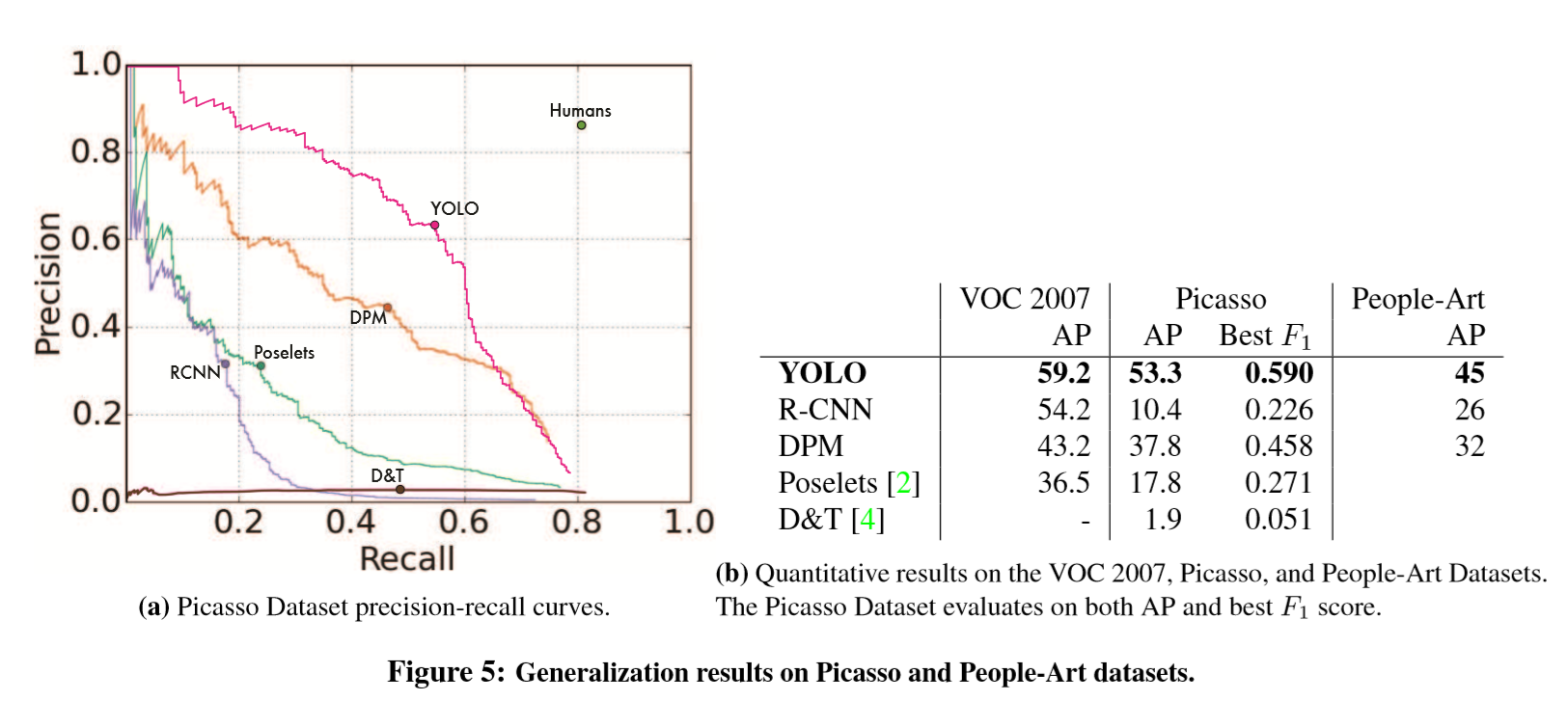
Figure 5 显示了YOLO和其它检测方式的性能比较。作为参考,我们给出了所有仅在VOC 2007训练的检测系统在检测VOC 2007中的人物时的AP。检测Picasso的模型是用VOC 2012训练的而检测People-Art的模型是用VOC 2010训练的。
R-CNN在VOC 2007上有很高的AP。而当R-CNN应用到艺术作品上时,AP有相当大的下降。R-CNN使用Selective Search来进行bounding boxes proposals,它的参数适合自然图片。因此R-CNN中的分类器只看到了很小的部分,而且需要好的proposals。
DPM应用到艺术作品上时,保持了其原来的AP。之前的工作认为DPM性能很好,因为它具有强大的物体形状和布局的空间模型。尽管DPM的AP不像R-CNN一样下降很多,但它的AP值原本就比较低。
YOLO在VOC 2007上的性能表现很好,而且当应用到艺术作品上时比其它模型下降的都少。与DPM一样,YOLO模拟对象的大小和形状,以及对象之间的关系和对象通常出现的位置之间的关系。艺术品和自然图像在像素级别上有很大不同,但它们在物体的大小和形状方面相似,因此YOLO仍然可以预测好的边界框和检测结果。
5 Real-Time Detection In The Wild
YOLO是一个快速,精确的物体检测器,非常适合计算机视觉应用。我们将YOLO连接到网络摄像头并验证它是否保持实时性能,测试包含了包括从相机提取图像并显示检测结果的时间。这样得到的系统是交互式的,虽然YOLO是单独处理图片的,但当它连接到网络摄像机时它就像一个追踪系统一样,当目标四处移动或形状发生变化时也能实时检测目标。
6 Conclusion
我们介绍YOLO,一个统一的物体检测模型。 此模型构造简单,可以直接在完整的图像上训练。 与基于分类器的方法不同,YOLO是通过与检测性能直接对应的损失函数进行培训的,并且整个模型是共同培训的。
快速YOLO是文献中最快的通用对象检测器,YOLO推动实时目标检测的最新技术。 YOLO还很好地推广到新领域,使其成为依赖快速,强大物体检测的应用的理想选择。
