


代码随想录算法训练营|Day 16
Day 16
第六章 二叉树 part04
找树左下角的值
本题递归偏难,反而迭代简单属于模板题, 两种方法掌握一下
题目链接/文章讲解/视频讲解:https://programmercarl.com/0513.找树左下角的值.html
本题使用前序/中序/后序都可以
前序:中左右
中序:左中右
后序:左右中
本题没有中节点的处理逻辑,只需先遍历左
强调左在右的前面
优先遍历左节点,只要得到了深度最大的节点,得到的就是最后一行最靠左的节点
最靠左侧的节点不一定就是左孩子
深度最大的节点里的值放进result
depth->遍历当前的深度
maxDepth->记录所有遍历深度中的最大深度
终止条件:遍历到叶子结点
递归法 明确回溯
class Solution:
def findBottomLeftValue(self, root: TreeNode) -> int:
self.max_depth = float('-inf')
self.result = None
self.traversal(root, 0)
return self.result
def traversal(self, node, depth):
if not node.left and not node.right:
if depth > self.max_depth:
self.max_depth = depth
self.result = node.val
return
if node.left:
depth += 1
self.traversal(node.left, depth)
depth -= 1
if node.right:
depth += 1
self.traversal(node.right, depth)
depth -= 1
-
这是不是前序遍历 (pre‑order traversal)?
严格来说,这段代码并不是在每个节点(包括内部节点)都做“访问”(visit)操作,所以不能算是完整的 pre‑order(“先访问 node,再递归 left,再递归 right”)。- 你在
traversal里 只在叶子节点(leaf) 时做处理(也就是比较深度并可能更新result), - 在内部节点只是负责“决定往左还是往右走”,而没有把它当作一个“访问点”来处理。
因此它更准确地说是一种 深度优先搜索 (Depth‑First Search, DFS),且你写的是“先左后右”的遍历顺序(left‑first),但处理(processing)仅限叶子节点。
- 你在
-
为什么这样能拿到“树的左下角”那个节点?
-
你维护了一个全局的
max_depth和对应的result, -
每次到达一个叶子节点,就用当前
depth和max_depth比较:if depth > self.max_depth: self.max_depth = depth self.result = node.val -
关键是你是 先递归遍历左子树 (left subtree),再遍历右子树 (right subtree)。
-
因此,当你第一次“达到”某个新的更大深度时,一定是该深度 最左边 的叶子节点,你就把它的值记录下来了。
-
整棵树遍历完成后,
self.result保存的正是 最大深度(bottom)里最先被发现的节点,也就是最左边(leftmost)的叶子节点值。
-
下面用一个示例来说明,假设我们有如下这棵二叉树(root 深度记为 0):
1
/ \
2 3
/ / \
4 5 6
/ \
7 8
- 叶子节点 (leaf nodes):4(深度 2)、7(深度 3)、8(深度 3)、6(深度 2)。
- 最底层 deepest level 是深度 3,位于节点 7 和 8 所在的那一层。
- 这层最左的叶子节点就是 7。
下面看我们的遍历(DFS,先左再右)以及 max_depth/result 如何变化:
| 访问节点 | 深度 depth | 是否叶子 | 更新前 max_depth |
更新后 max_depth |
更新后 result |
|---|---|---|---|---|---|
| 1 | 0 | 否 | –∞ | –∞ | – |
| 2 | 1 | 否 | –∞ | –∞ | – |
| 4 | 2 | 是 | –∞ | 2 | 4 |
| (返回到 2,再返回到 1) | – | – | 2 | 2 | 4 |
| 3 | 1 | 否 | 2 | 2 | 4 |
| 5 | 2 | 否 | 2 | 2 | 4 |
| 7 | 3 | 是 | 2 | 3 | 7 |
| 8 | 3 | 是 | 3 | 3 (不变) | 7 (不变) |
| 6 | 2 | 是 | 3 | 3 | 7 |
- 初次遇到叶子 4(depth=2),
max_depth从 –∞ 更新到 2,result=4。 - 接着在右子树先遇到叶子 7(depth=3),
3>2,于是更新为max_depth=3, result=7。 - 后续遇到叶子 8 和 6 时,它们的深度都不大于当前
max_depth(3),因此不再更新。
最终 result=7,即最底层(bottom)最左边(leftmost)的叶子节点值。
这样就验证了:
- 虽然这段代码不是严格意义上对所有节点都做“访问”的前序遍历(pre‑order),但它是“先左后右”的 DFS,
- 借助“只在叶子节点处理 + 先遍历左子树”的策略,保证了第一次到达最深层时,拿到的就是那一层最左边的节点值。
递归法 精简版
不需要depth++后再depth--,而是直接把depth+1传递给函数
这样做,没有改变depth本身的值,因此不需要depth--来恢复深度再traverse右边
class Solution:
def findBottomLeftValue(self, root: TreeNode) -> int:
self.max_depth = float('-inf')
self.result = None
self.traversal(root, 0)
return self.result
def traversal(self, node, depth):
if not node.left and not node.right:
if depth > self.max_depth:
self.max_depth = depth
self.result = node.val
return
if node.left:
self.traversal(node.left, depth+1)
if node.right:
self.traversal(node.right, depth+1)
迭代法 层序遍历
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
from collections import deque
class Solution:
def findBottomLeftValue(self, root):
if root is None:
return 0
queue = deque()
queue.append(root)
result = 0
while queue:
size = len(queue)
for i in range(size):
node = queue.popleft()
if i == 0:
result = node.val
if node.left:
queue.append(node.left)
if node.right:
queue.append(node.right)
return result
路径总和
本题 又一次涉及到回溯的过程,而且回溯的过程隐藏的还挺深,建议先看视频来理解
优先掌握递归法
本题同样不涉及中节点的处理逻辑,因此前/中/后序均可
112. 路径总和

用累加然后判断是否等于目标和比较麻烦
可以初始化计数器count为目标和,然后每次减去路径节点上的数值
如果最后count==0,同时到了叶子结点的话,说明找到了目标和
如果遍历到了叶子结点,count不为0,就是没找到
递归法
class Solution:
def traversal(self, cur: TreeNode, count: int) -> bool:
if not cur.left and not cur.right and count == 0: # 遇到叶子节点,并且计数为0
return True
if not cur.left and not cur.right: # 遇到叶子节点直接返回
return False
if cur.left: # 左
count -= cur.left.val
if self.traversal(cur.left, count): # 递归,处理节点
return True
count += cur.left.val # 回溯,撤销处理结果
if cur.right: # 右
count -= cur.right.val
if self.traversal(cur.right, count): # 递归,处理节点
return True
count += cur.right.val # 回溯,撤销处理结果
return False
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if root is None:
return False
return self.traversal(root, targetSum - root.val)
递归法 精简
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
if not root.left and not root.right and targetSum == root.val:
return True
return self.hasPathSum(root.left, targetSum - root.val) or self.hasPathSum(root.right, targetSum - root.val)
迭代法
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
# 此时栈里要放的是pair<节点指针,路径数值>
st = [(root, root.val)]
while st:
node, path_sum = st.pop()
# 如果该节点是叶子节点了,同时该节点的路径数值等于sum,那么就返回true
if not node.left and not node.right and path_sum == targetSum:
return True
# 右节点,压进去一个节点的时候,将该节点的路径数值也记录下来
if node.right:
st.append((node.right, path_sum + node.right.val))
# 左节点,压进去一个节点的时候,将该节点的路径数值也记录下来
if node.left:
st.append((node.left, path_sum + node.left.val))
return False
这段代码用的是迭代版的深度优先搜索(DFS),用一个显式的栈来模拟递归遍历,同时在栈里把“走到当前节点时的路径和”也一起记录下来。
下面分几步来说明它的工作流程:
-
初始化栈
st = [(root, root.val)]栈里每一项都是一个
(节点引用, 从根节点累加到这个节点的路径和)。一开始只有根节点和它自己的值。 -
循环遍历,直到栈空或找到答案
while st: node, path_sum = st.pop() …每次从栈顶 pop 出当前要“访问”的节点和对应的
path_sum。 -
遇到叶子节点就判断
if not node.left and not node.right and path_sum == targetSum: return Truenot node.left and not node.right确认当前节点是叶子path_sum == targetSum则说明从根到这个叶子的那条路径和恰好等于题目给的targetSum,直接返回True。
-
如果不是满足条件的叶子,就把子节点和更新后的路径和压栈
if node.right: st.append((node.right, path_sum + node.right.val)) if node.left: st.append((node.left, path_sum + node.left.val))- 先把右子节点压栈,再把左子节点压栈,因为栈是后进先出 (LIFO),这样下次 pop 时就会先遍历“左子树”,保证与递归
dfs(node.left)…dfs(node.right)的顺序一致。
- 先把右子节点压栈,再把左子节点压栈,因为栈是后进先出 (LIFO),这样下次 pop 时就会先遍历“左子树”,保证与递归
-
遍历结束还没返回,就说明不存在这样的路径
return False
为什么这种方法能工作?
- 显式栈模拟递归:递归版 DFS 每到一个节点都会把「剩下要处理的分支」压到调用栈里;这种写法把调用栈变成了一个手动维护的
st列表。 - 路径和累加:在遍历过程中,一旦你从父节点“走”到子节点,就把子节点的值加到前面的
path_sum里,这样到达任何节点时,path_sum都恰好等于「从根节点到它的这条路径的累加和」。 - 叶子判断+早停:只在叶子节点才做等于判断,并且一旦满足就马上
return True,避免继续无意义的遍历。
复杂度
- 时间复杂度:每个节点最多入栈和出栈各一次,都是 O(1) 操作,合计 O(N),N 是节点总数。
- 空间复杂度:栈最坏情况下要同时保存一整条从根到最深(或最宽)的一条路径/所有兄弟节点,最坏是 O(N)。
错误解法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
#要注意剪枝
#前序 中左右
if not root:
return False
if self.traversal(root, root.val, targetSum):
return True
return False
def traversal(self,node, cur_sum,targetSum):
if cur_sum > targetSum:
return False
if node.left or node.right:
if cur_sum == targetSum:
return False
if node.left:
if self.traversal(node.left, cur_sum+node.left.val,targetSum):
return True
if node.right:
if self.traversal(node.right, cur_sum+node.right.val,targetSum):
return True
return False
if not node.left and not node.right:
if cur_sum == targetSum:
return True
return False
错误原因
去掉有风险的剪枝
你在开头写了:
if cur_sum > targetSum:
return False
但题目并不保证所有节点值都是非负的——遇到负数你就会 误剪枝。除非你能确认树中 所有 val ≥ 0,否则应该去掉这条剪枝。
事实上,测试用例中有的节点值为0
一个更清晰的递归版本
下面是一个简洁又可靠的写法,和你的思路几乎一样,但把叶子判断放前面,并去掉了那个有风险的剪枝:
class Solution:
def hasPathSum(self, root: Optional[TreeNode], targetSum: int) -> bool:
if not root:
return False
return self.dfs(root, root.val, targetSum)
def dfs(self, node: TreeNode, cur_sum: int, target: int) -> bool:
# 1) 先判断叶子
if not node.left and not node.right:
return cur_sum == target
# 2) 递归左、右子树
if node.left:
if self.dfs(node.left, cur_sum + node.left.val, target):
return True
if node.right:
if self.dfs(node.right, cur_sum + node.right.val, target):
return True
return False
这样:
- 先检测
not node.left and not node.right,一遇到叶子节点就直接比较并返回结果; - 不会误剪枝,也不用在中间节点再去判断
cur_sum == target; - 逻辑直观:叶子判断在前,递归在后。
只要把你的叶子判断改成 and not node.right,或者全面重写成上面的样子,就能通过所有测试用例了。
113. 路径总和ii
题目链接/文章讲解/视频讲解:https://programmercarl.com/0112.路径总和.html
我的解法
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
if not root:
return []
res = []
def find_path(node,path,targetSum, res):
if not node.left and not node.right and sum(path) == targetSum:
res.append(path)
return
if node.left:
find_path(node.left, path+[node.left.val],targetSum,res)
if node.right:
find_path(node.right, path+[node.right.val],targetSum,res)
find_path(root, [root.val], targetSum, res)
return res
递归法 体现回溯
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def __init__(self):
self.result = []
self.path = []
def traversal(self, cur, count):
if not cur.left and not cur.right and count == 0: # 遇到了叶子节点且找到了和为sum的路径
self.result.append(self.path[:])
return
if not cur.left and not cur.right: # 遇到叶子节点而没有找到合适的边,直接返回
return
if cur.left: # 左 (空节点不遍历)
self.path.append(cur.left.val)
count -= cur.left.val
self.traversal(cur.left, count) # 递归
count += cur.left.val # 回溯
self.path.pop() # 回溯
if cur.right: # 右 (空节点不遍历)
self.path.append(cur.right.val)
count -= cur.right.val
self.traversal(cur.right, count) # 递归
count += cur.right.val # 回溯
self.path.pop() # 回溯
return
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
self.result.clear()
self.path.clear()
if not root:
return self.result
self.path.append(root.val) # 把根节点放进路径
self.traversal(root, targetSum - root.val)
return self.result
这段代码用的是深度优先搜索 + 回溯(DFS+backtracking)的思路,来枚举所有从根到叶子的路径,并找出那些路径和恰好等于 targetSum 的路径。下面分步来讲它是怎么做的:
1. 全局状态
self.result:用来收集所有满足条件的路径,最终返回self.path:当前递归过程中,从根节点到“正在访问节点”这条路径上,节点值的列表
def __init__(self):
self.result = []
self.path = []
调用 pathSum(root, targetSum) 时,会先清空这两个列表,然后把根节点值压入 self.path,再启动递归:
self.result.clear()
self.path.clear()
if not root:
return self.result
self.path.append(root.val)
self.traversal(root, targetSum - root.val)
return self.result
这里把 count = targetSum - root.val 看作“从下一个子节点开始,还需要凑齐多少和”。
2. 递归函数 traversal(cur, count)
def traversal(self, cur, count):
# —— 1)到达叶子并且 count==0,就把当前 path 拷贝进 result
if not cur.left and not cur.right and count == 0:
self.result.append(self.path[:])
return
# —— 2)到达叶子但 count!=0,直接剪掉,返回
if not cur.left and not cur.right:
return
# —— 3)如果有左子节点,就“走”向左
if cur.left:
self.path.append(cur.left.val) # 加入左孩子到路径
count -= cur.left.val # 剩余的目标和减少
self.traversal(cur.left, count) # 递归
count += cur.left.val # 回溯:把 count 恢复
self.path.pop() # 回溯:把路径末尾弹出
# —— 4)同理,遍历右子节点
if cur.right:
self.path.append(cur.right.val)
count -= cur.right.val
self.traversal(cur.right, count)
count += cur.right.val
self.path.pop()
return
核心要点
-
叶子节点检测
if not cur.left and not cur.right判断当前节点是不是叶子- 如果是叶子,再看
count==0(说明从根到它的这条路的和正好等于targetSum),就把self.path的一个拷贝加入self.result
-
回溯机制
-
每次“走”向一个子节点之前:
- 把子节点的值
append到self.path - 把
count减去这个子节点的值
- 把子节点的值
-
递归返回后,要把这两步的操作逆向执行,即
pop()掉self.path末尾,并把count加回来 -
这样能够保证,把每一条路径都“干净”地探索一遍,互不干扰
-
-
剪枝
- 当到叶子但
count!=0时,直接return,不往下走(事实上叶子没孩子,但这写法在叶子上做了两次判断,第二个判断就是无条件退出)
- 当到叶子但
3. 举个小例子
假设树如下,targetSum = 22:
5
/ \
4 8
/ / \
11 13 4
/ \ \
7 2 1
- 开始时:
path = [5],count = 22−5=17 - 向左走:
path = [5,4],count = 17−4=13 - 再向左:
path = [5,4,11],count = 13−11=2 - 向左叶子 7:
path=[5,4,11,7],count=2−7=−5→ 叶子且count!=0→ 返回,不存结果,回溯 - 同理访问 2:
path=[5,4,11,2],count=2−2=0→ 叶子且count==0→ 把[5,4,11,2]加入result - 再遍历右子树……最终会找到
[5,8,4,5](若存在)等路径
4. 复杂度
- 时间:每个节点最多访问一次,且每条成功路径要做一次
path[:]拷贝。最坏情况所有节点都被访问,O(N);如果所有路径都符合,还要额外拷贝,最坏 O(N·L),L 是平均路径长度。 - 空间:递归栈 +
self.path最多保存一条从根到叶子的路径,都是 O(H),H 是树的高度(最坏 O(N))。
总结:
- 这是经典的「先序 DFS + 回溯」解法,
- 用
self.path记录当前节点的路径, - 用
count跟踪还需凑齐的和, - 走到叶子时检查是否达标,
- 回溯时要恢复状态,保证其它分支遍历时路径和
count正确。这样就能枚举出所有满足path sum == targetSum的根—叶子路径了。
问题
如果说走完左子节点,需要回溯是因为还要走右子节点,那为什么右子节点也需要回溯呢?
不论是左子树还是右子树,每次把子节点的值加到 self.path 和 count 里,走完那条分支以后,都必须把它们“弹”回去,才能恢复到「走这条分支之前」的状态,这样回到父节点的时候,self.path 和 count 才不会带着刚才走过的那一部分信息去影响后续的遍历。
举个对比更清晰:
# 假设 cur 有两个孩子:left 和 right
# 先走左
self.path.append(cur.left.val)
count -= cur.left.val
self.traversal(cur.left, count)
# 【回溯】——弹出 left 的那一步
count += cur.left.val
self.path.pop()
# 然后走右
self.path.append(cur.right.val)
count -= cur.right.val
self.traversal(cur.right, count)
# 【回溯】——弹出 right 的那一步
count += cur.right.val
self.path.pop()
如果你 不在右子树遍历后也做回溯,那么当这一层的递归函数结束、要返回到更高一层时,self.path 里依然会留着右孩子的值,导致:
- 路径不干净:父节点或祖先节点再看
self.path时,会多了本不该有的节点。 - 后续遍历错乱:祖先节点的其它分支(或者结束时收集的路径)就全乱了。
即使你在右子树走完之后,不再继续“同级别”的兄弟遍历,也必须把这次「压入/弹出」的过程完整做一次,才能保持全局状态一致。
递归法 精简回溯
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
result = []
self.traversal(root, targetSum, [], result)
return result
def traversal(self,node, count, path, result):
if not node:
return
path.append(node.val)
count -= node.val
if not node.left and not node.right and count == 0:
result.append(list(path))
self.traversal(node.left, count, path, result)
self.traversal(node.right, count, path, result)
path.pop()
迭代法
# Definition for a binary tree node.
# class TreeNode:
# def __init__(self, val=0, left=None, right=None):
# self.val = val
# self.left = left
# self.right = right
class Solution:
def pathSum(self, root: Optional[TreeNode], targetSum: int) -> List[List[int]]:
if not root:
return []
stack = [(root, [root.val])]
res = []
while stack:
node, path = stack.pop()
if not node.left and not node.right and sum(path) == targetSum:
res.append(path)
if node.right:
stack.append((node.right, path + [node.right.val]))
if node.left:
stack.append((node.left, path + [node.left.val]))
return res
从中序与后序遍历序列构造二叉树
本题算是比较难的二叉树题目了,大家先看视频来理解。
题目链接/文章讲解/视频讲解:https://programmercarl.com/0106.从中序与后序遍历序列构造二叉树.html

中序:左中右 ->能确定最左和最右节点
后序:左右中 ->最后一个元素一定是中间节点

切中序数组,是为了得到:左中序 右中序
拿中序数组的左区间的大小,可以去切后序数组的左区间,那么右区间就也得到了
切后序数组,得到:左后序,右后序
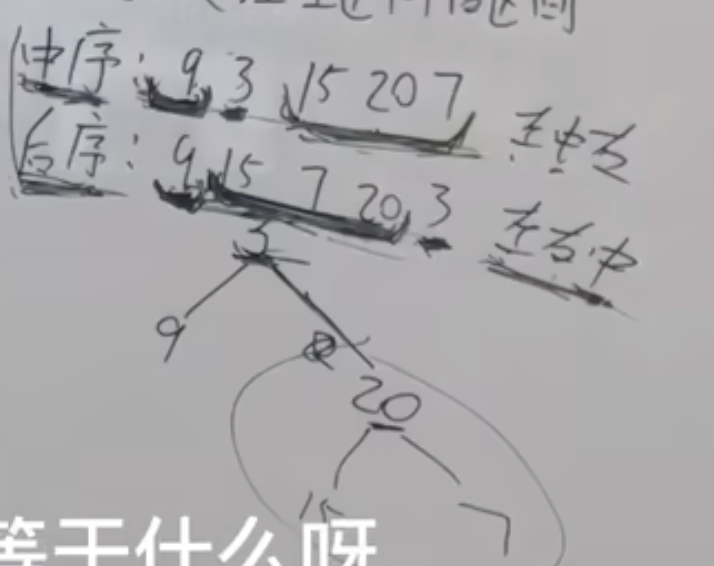
一定先切中序再切后序。后序的左右挨在一起,没办法切开
106.从中序与后序遍历序列构造二叉树
class Solution:
def buildTree(self, inorder: List[int], postorder: List[int]) -> TreeNode:
# 第一步: 特殊情况讨论: 树为空. (递归终止条件)
if not postorder:
return None
# 第二步: 后序遍历的最后一个就是当前的中间节点.
root_val = postorder[-1]
root = TreeNode(root_val)
# 第三步: 找切割点.
separator_idx = inorder.index(root_val)
# 第四步: 切割inorder数组. 得到inorder数组的左,右半边.
inorder_left = inorder[:separator_idx]
inorder_right = inorder[separator_idx + 1:]
# 第五步: 切割postorder数组. 得到postorder数组的左,右半边.
# ⭐️ 重点1: 中序数组大小一定跟后序数组大小是相同的.
postorder_left = postorder[:len(inorder_left)]
postorder_right = postorder[len(inorder_left): len(postorder) - 1]
# 第六步: 递归
root.left = self.buildTree(inorder_left, postorder_left)
root.right = self.buildTree(inorder_right, postorder_right)
# 第七步: 返回答案
return root
105.从前序与中序遍历序列构造二叉树
class Solution:
def buildTree(self, preorder: List[int], inorder: List[int]) -> Optional[TreeNode]:
#inorder:左中右
#preorder:中左右
if not preorder:
return None
root_val = preorder[0]
root = TreeNode(root_val)
separator_idx = inorder.index(root_val)
inorder_left = inorder[:separator_idx]
inorder_right = inorder[separator_idx+1:]
preorder_left = preorder[1:len(inorder_left)+1]
preorder_right = preorder[len(inorder_left)+1:]
root.left = self.buildTree(preorder_left,inorder_left)
root.right = self.buildTree(preorder_right,inorder_right)
return root
中序和后序 或 中序和前序都可以确定一个唯一的二叉树
但前序和后序不行
前序和后序中,左右都是挨在一起的,分割点没有告诉我们。而中序从中间把左右区间隔开了
我们才能知道左右区间分别是什么

形如上图的二叉树,前后序一样

 浙公网安备 33010602011771号
浙公网安备 33010602011771号