
操作系统-线程
线程:CPU使用的基本单元,由线程ID、程序计数器、寄存器集合和栈组成。
单线程进程和多线程进程的差别:
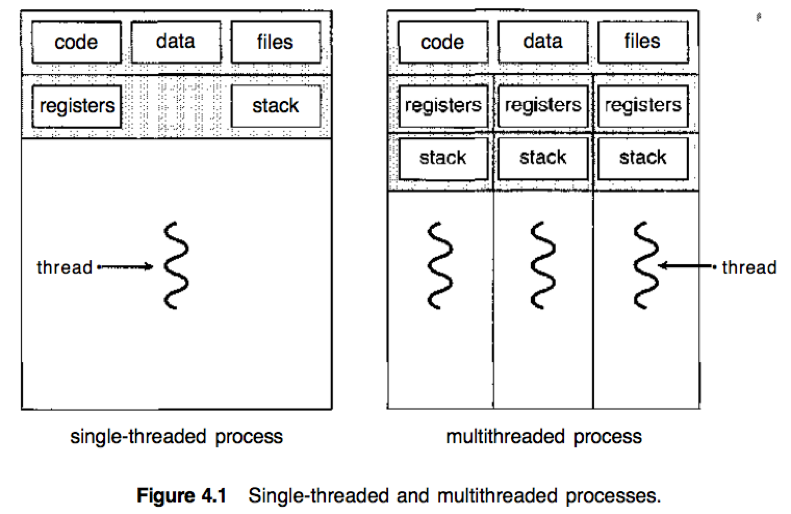
传统重量级(heavyweight)进程只有单个控制线程;
多线程进程中,线程与属于同一进程的其他线程共享代码段、数据段和其他操作系统资源。
多线程编程的优点:
1. 对用户响应度高:即使部分阻塞或操作冗长,仍能继续执行,增加对用户的响应程度;
2. 进程内资源共享:多个不同的活动线程能够共享所属进程的内存和资源。
3. 经济:创建和切换线程比进程需要更少的内存和资源分配。
4. 利用多处理器体系结构:充分使用多处理器体系结构,每个进程能并行运行在不同处理器上。(单线程进程只能运行在一个CPU上,不论有多少CPU。)
多线程模型
两种提供线程支持的方法:用户线程或内核线程。
用户线程:受内核支持,无须内核管理。用户线程对程序员可见,不需要内核干预,创建和管理相比内核线程更快。
内核线程:由操作系统直接支持和管理。
用户线程和内核线程的三种常用关系模型:多对一、一对一、多对多。
1. 多对一模型:多个用户线程映射到一个内核线程。
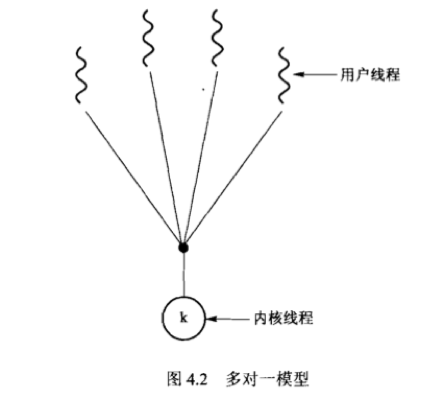
任一时刻只有一个线程能访问内核,多个线程不能并行运行在多处理器上。
优点:由线程库在用户空间进行线程管理,效率较高;
缺点:如果一个线程执行阻塞系统调用,整个进程阻塞。
e.g. Green thread(Solaris线程库)、GNU Portable Threads.
2. 一对一模型:每个用户线程各映射到一个相应的内核线程。
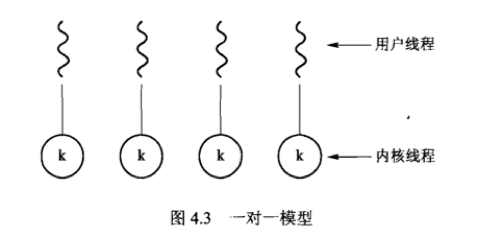
允许多个线程并行运行在多处理器系统上。【并发性较高】
优点:一个线程执行阻塞系统调用,另一个线程能够继续执行。
缺点:往往需要限制系统所支持的线程数量。因为创建一个用户进程就需要创建一个相应的内核线程,该开销会影响性能。
e.g. Linux、Windows95/98/NT/2000/XP/Solaris9
3. 多对多模型:多路复用多个用户线程到同样数量(或更少)的内核线程上。

内核线程数量与特定应用程序或机器有关。
开发人员可创建任意多的用户线程,并且内核线程能在多处理器系统上并发执行。一个线程执行阻塞系统调用时,内核能调度另一个线程来执行。
二级模型:多对多模型的变种,允许将一个用户线程绑定到某个内核线程上。
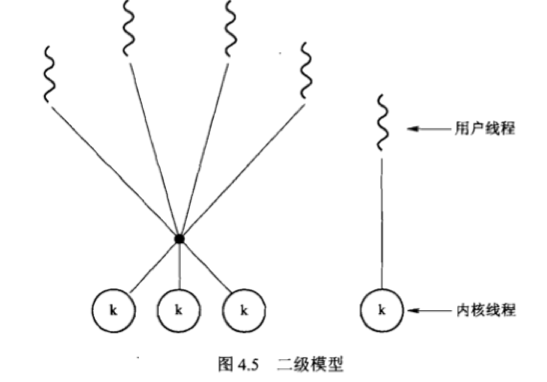
e.g. IRIX/HP-UX/Tru64 Unix/Solaris9之前的版本。
线程库
线程库(thread library):为应用程序员提供了创建和管理线程的API。
线程库的两种主要实现方法:
1. 没有内核支持的库,代码和数据结构都在用户空间,只导致用户空间中本地函数调用(而不是系统调用)。
2. 由操作系统直接支持的内核级库,代码和数据结构都在内核空间,通常导致系统调用。
通常有三种主要的线程库:
1) POSIX Pthread:POSIX标准的扩展,可提供用户级或内核级的库。是线程行为的规范,而不是实现。
e.g. Solaris/Linux/Mac OS X/Tru64 Unix等。
2)Win32:适用于Windows操作系统的内核级的库。
3)Java线程:允许线程在Java程序中直接创建和管理。
由于大多数JVM实例运行在宿主操作系统之上,Java线程API通常采用宿主系统上的线程库实现。
线程是Java程序执行的基本模型,所有Java程序至少由一个控制线程组成。
Java程序中有两种创建线程的技术:1. 创建一个从Thread类派生的新的类,并重载run()函数;2.定义一个实现Runnable接口的类。(更常用)
e.g. 创建线程
传递Runnable对象作为参数来创建Thread类对象实例-> Thread类对象调用start()函数来创建新线程
start()函数需要完成:1. 在JVM中分配内存并初始化新线程。2. 调用run()函数(i.e. Runnable实现类中定义)。
多线程问题
系统调用fork()和exec()
fork() – 有的Unix系统有两种形式的fork(),与应用程序有关。
1) 复制所有线程:如果调用fork()后立即调用exec(),操作系统只需复制调用fork()的线程。
2) 只复制调用fork()的线程:如果调用fork()后不调用exec(),复制所有线程;
exec() – 如果一个线程调用exec(),exec()参数指定的程序会替换整个进程(包括所有线程)。
线程取消
线程取消(thread cancellation):在线程完成之前终止线程的任务,要取消的线程称为目标线程。
线程取消的两种情况:
1) 异步取消(asynchronous cancellation):由一个线程立即终止目标线程。
对于异步取消,因为如果在已经给目标线程分配资源或目标线程正在更新与其他线程共享的数据的情况下,操作系统从回收系统资源时不能将所有资源全部回收。
2) 延迟取消(deferred cancellation):目标线程周期性地检查其是否应该终止,允许目标线程以有序方式终止自己。
对于延迟取消,只有在目标线程检查了flag,确定其是否应该取消后才会执行取消。
取消点(cancellation point):Pthread中,指延迟取消时目标线程检查其是否应该取消的安全点。
信号处理
信号:在UNIX中用来通知某个特定事件的发生,模式为1) 由特定事件发生所产生;2)产生信号要发送到进程;3) 一旦发送,信号必须加以处理。
信号可分为同步和异步:
同步信号:被发送到产生信号的同一进程。E.g. 非法访问内存、被0所除。
异步信号:由运行进程之外的事件产生,通常被发送到另一进程。E.g. 使用特殊键、定时器到期。
信号由两种可能的处理程序中的一种处理:
1) 默认信号处理程序(default signal handler):每个信号都有一个,在内核中运行。
2) 用户定义的信号处理程序:可对默认动作进行改写。
对于多线程程序,信号可能被发送到(依赖于信号类型):
1) 信号所应用的线程;(同步信号)
2) 进程内的每个线程;
3) 进程内的某些固定线程;
4) 规定一个特定线程以接收进程的所有信号。
异步信号的情况比较复杂。
线程池
多线程服务器的潜在问题:1) 处理请求前创建线程需要时间,线程完成工作后要被丢弃;2) 如果允许所有并发请求都用新线程处理,则无法限制系统中并发执行的线程数量,大量消耗系统资源。
解决方法:线程池
线程池(thread pool):在进程开始时创建一定数量的线程,放入池中等待工作。服务器收到请求时,如有可用线程则唤醒池中的一个线程,并传递要处理的请求。线程完成服务后返回池中再等待工作。如果池中没有可用线程,则服务器一直等待直到有可用线程为止。
线程池的优点:
1) 用现有线程处理请求比等待创建新线程快;
2) 限制在任何时候可用线程的数量,对不能支持大量并发线程的系统非常重要。
线程特定数据
线程特定数据(thread-specific data):(虽然同属一个进程的线程共享数据)有些情况下每个线程可能需要自己拥有的关于某些数据的副本。
调度程序激活
轻量级进程(Lightweight process, LWP):实现多对多模型或二级模型的系统在用户线程和内核线程之间通常设置一种中间数据结构,通常为LWP。
对于用户线程库,LWP表现为一种应用程序可以调度用户线程来运行的虚拟处理器。每个LWP与内核线程相连,该内核线程被操作系统调度到物理处理器上运行。如果物理处理器上运行的内核线程阻塞,则与其相连的LWP也阻塞,关系链顶端与LWP相连的用户线程也阻塞。
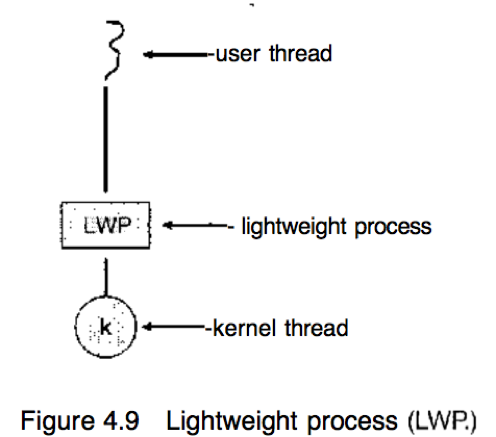
不同应用程序需要的LWP数量可能不同——如果是运行在单处理器机器上的CPU-bound应用,一次只能运行一个线程,则一个LWP就足够;如果是I/O请求密集的应用程序,可能需要多个LWP,通常有几个并发阻塞系统调用就需要几个LWP,若不够则必须等待LWP从内核返回。
upcall:内核通知应用程序与其有关的特定事件的过程;
upcall handler:upcall处理句柄,在虚拟处理器(LWP)上运行。
调度器激活(scheduler activation):一种解决用户线程与内核间通信的方法。
工作方式——内核提供一组LWP给应用程序,应用程序可调度用户线程到一个可用的LWP上。
当一个应用线程将要阻塞时,事件引发内核发送upcall到应用程序,通知应用程序线程阻塞并标识特殊线程 ->
内核分配一个新的LWP给应用程序 ->
应用程序在该新LWP上运行upcall handler:1) 保存该阻塞线程的状态 2)放弃阻塞线程运行的原虚拟处理器 ->
upcall handler调度另一个适合在新LWP上运行的线程 ->
当原先阻塞的线程准备好执行时,内核发送另一个upcall到线程库,通知线程库原先阻塞的线程已经能够运行了(内核可能分配一个新的LWP,或抢占一个用户线程并在其LWP用于运行处理该事件的upcall handler)->
应用程序将已处于未堵塞状态的线程标记为“能够运行”,调度一条合适的线程到可用LWP上运行。
操作系统实例-如何实现线程
Windows XP
应用程序以独立进程方式运行,每个进程可包括一个或多个线程。
使用一对一映射,也提供对fiber库的支持(多对多模型)。
同属一个进程的每个线程都能访问进程的地址空间。
一个线程包括:
1) 线程ID:用于唯一标识线程
2) 寄存器集合:用于表示处理器状态
3) 用户栈:供线程在用户模式下运行时使用
4) 内核堆栈:供线程在内核模式下运行时使用
5) 私有存储区域:供各种运行时库和动态链接库(DLL)使用
线程的上下文:寄存器集合、栈和私有存储区域。
线程的主要数据结构包括:
1) ETHREAD:执行线程块,包括指向线程所属进程的指针、线程开始控制的子程序的地址、指向KTHREAD的指针。
2) KTHREAD:内核线程块,包括线程的调度和同步信息、指向内核栈的指针、指向TEB的指针
3) TEB:用户空间的数据结构,供线程在用户模式下运行时访问,包含许多其他域、用户模式栈、用于线程特定数据的数组。
ETHREAD、KTHREAD完全处于内核空间,只有内核可以访问它们。
Windows XP线程结构:

Linux
不区分进程和线程,通常称之为任务(task)。
系统调用fork()提供传统进程复制功能,系统调用clone()提供创建线程功能。
调用clone()时传递一组标志,决定父任务与子任务之间发生多少共享。E.g.

如果调用clone()时没有设置标志,则不会发生共享,类似于系统调用fork()提供的功能。
Task_struct:Linux系统中每个任务都有一个唯一的内核数据结构struct task_struct,它并不保存任务本身的数据,而是指向其他存储这些数据的数据结构(e.g. 打开文件列表、信号处理信息、虚拟内存等)的指针;
调用fork()时,所创建的新任务具有父进程所有数据的副本;调用clone时,所创建新任务根据所传递标志集指向父任务的数据结构。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号