[T.12] 团队项目:Alpha 阶段项目展示
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 2025年春季软件工程(罗杰、任健) |
| 这个作业的要求在哪里 | [T.12] 团队项目:Alpha 阶段项目展示 |
| 我在这个课程的目标是 | 学习软件工程的基础知识,和团队成员们实践各种软件工程的方法与流程,开发一个让我们值得骄傲的项目 |
| 这个作业在哪个具体方面帮助我实现目标 | Alpha 阶段项目展示 |
团队成员与分工简介
- 范兴堃
- 参与任务:
- 选题(调研与可行性分析)
- 整体架构设计(协同完成)
- 工具调研:(协助执行)
- 流程构想(主责)
- 数据库设计(主责)
- 吴佳峻
- 参与任务:
- 选题及需求分析(独立)
- 整体架构(协同完成)
- 前端移动端适配(多端实现)
- MCP协议支持探索(独立)
- 工具调研:(主责执行)
- 流程构想(协同执行)
- 叶佩霖
- 参与任务:
- 选题(调研)
- 前端适配(响应式设计)
- 学习 React 和 Ragflow 前端架构(主要负责人)
- 搭建RAGnarok前端(主要负责人)
- 林宇浩
- 参与任务:
- 选题(调研)
- 前端适配(响应式开发)
- 文件切分(新增,独立负责)
- 后端组件对接(协作执行)
- 熊晓焜
- 参与任务:
- 选题(调研)
- 前端适配(移动端开发协同)
- embedding(优化和联调)
- 后端组件对接(协作执行)
- 钟芳梽
- 参与任务:
- 选题(调研)
- 向量库+Retrieve 模块(独立负责)
- Qdrant(框架搭建与功能完善)
- 后端组件对接(协作执行)
- 陈叙传
- 参与任务:
- 选题(调研)
- 用户提问 + LLM 模块(独立完成)
- 后端组件对接(协作执行)
- 优化 LLM 异步调用性能
项目管理
1. 任务管理工具
- 飞书多维表格:记录和跟踪所有任务的信息,包括任务标题、描述、执行人、开始与截止日期、预估工时、实际进展、依赖关系等。
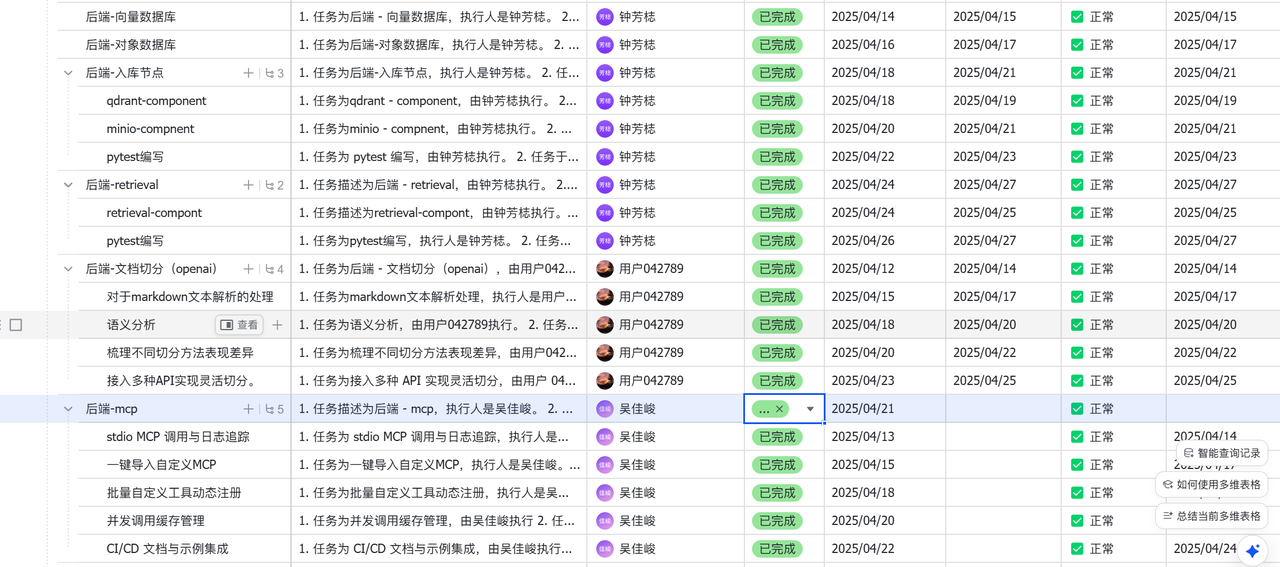
2. 任务分解方法
- WBS(工作分解结构)方法:项目目标首先被拆解为高层次的任务,再根据任务的重要性和复杂性进一步细化为具体的、独立的、短时的子任务。
- 任务粒度控制:通过拆解任务为短时、可执行的小任务,可以确保每个子任务能够在短时间内完成,降低任务的复杂度与不确定性。
3. 进度记录与跟踪
- 飞书多维表格进度更新:所有任务及子任务的进度信息都记录在飞书多维表格中,包括任务描述、负责人、实际完成情况、任务进展等。
- 定期进度更新:团队定期进行进度更新(如每日或每周),通过飞书进行共享,形成动态的任务进度图表。这有助于团队及时了解各自任务的完成情况,保持整体协调。
4. 动态调整机制
- 实时反馈与调整:项目经理(PM)根据团队成员的反馈、开发过程中的实际情况对任务的预估工时、依赖关系以及任务分配进行动态调整。
典型用户场景与软件满足方式
本项目RAGnarok面向B端企业用户和C端个人用户两大核心用户群体,针对其实际使用需求和目标,系统在功能、架构和使用体验等方面做了明确设计,以满足典型应用场景下的业务与个人智能问答需求。
一、B端企业用户典型场景
1. 应用背景
企业IT部门或业务团队希望构建专属的智能问答系统,用于客服支持、知识管理、内部知识库问答、员工培训等场景,需保障数据安全、知识隔离、系统集成能力。
2. 典型用户画像
- 企业IT经理、架构师、系统管理员
- 对接平台的第三方服务集成商
- 企业知识库维护人员
3. 典型用户场景
场景:某大型企业搭建内部智能问答助手,支持员工在内部系统中提问业务流程、制度政策、技术文档。
用户操作流程:
- 企业通过RAGnarok部署私有化实例,上传结构化/非结构化文档至私有知识库。
- 使用模块化Pipeline配置:文档检索 → 智能排序 → LLM问答生成。
- 系统通过MCP协议对接企业已有系统(如OA或CRM)以获取动态信息。
- IT管理员设定访问权限,多租户模式保障不同部门数据隔离。
4. 软件满足方式
| 功能模块 | 满足点说明 |
|---|---|
| 私有化部署 & 多租户架构 | 确保企业数据安全,支持不同部门独立使用与管理知识库 |
| MCP接口协议 | 统一数据上下文结构,简化与企业现有系统的集成工作 |
| 流水线(Pipeline)编排 | 企业可自定义问答流程,灵活适应业务场景变化 |
| 权限与审计管理 | 提供用户权限分级与操作日志,满足企业合规要求 |
| 运维监控 & 调试工具 | 保障系统稳定运行,支持快速故障定位与性能调优 |
5. 效果
- 快速构建面向员工或客户的问答系统,缩短部署周期
- 强化内部知识共享与工作效率
- 降低技术集成与维护成本,提高系统安全性和稳定性
二、C端普通用户典型场景
1. 应用背景
个人用户希望借助RAG技术便捷获取知识答案,例如进行日常知识查询、学习辅助、工作参考等,追求高效、准确、无需技术门槛的使用体验。
2. 典型用户画像
- 学生、自由职业者、知识工作者、AI兴趣爱好者
- 对LLM技术感兴趣但无开发能力的用户
3. 典型用户场景
场景:用户希望快速查询某个专业术语、撰写资料或整理文献摘要,通过RAGnarok平台完成这一过程。
用户操作流程:
- 用户注册并创建个人知识库,上传PDF、网页、笔记等内容。
- 在界面中输入问题,系统使用内置Pipeline完成检索增强问答。
- 系统提供回答结果,并列出参考文档与出处。
- 用户收藏、反馈或分享回答结果,形成个性化历史记录。
4. 软件满足方式
| 功能模块 | 满足点说明 |
|---|---|
| 开箱即用的可视化界面 | 无需编码,即可上传文档、提问并获取回答 |
| 智能问答 + 引用文档呈现 | 保证答案可追溯,提高信任度与实用性 |
| 个性化知识库 | 用户可构建属于自己的语义库,提升问答的相关性 |
| 查询历史与推荐机制 | 根据用户行为进行答案推荐与内容优化 |
| 简洁交互体验 | 面向C端设计的界面与流程,适配移动端与Web端 |
5. 效果
- 快速获得准确、上下文相关的答案,无需自行查阅文档
- 可持续构建个人知识体系,助力学习与工作
- 用户体验友好,无需任何技术背景即可使用
RAGnarok 的杀手级功能与差异化亮点
(对比 Dify / Haystack / RAGFlow 等主流竞品)
| 维度 | RAGnarok 核心能力 | 竞品现状 | 差异化价值 |
|---|---|---|---|
| 标准化对接(80%) | 原生支持 MCP 协议- “万能插头”式标准- 既可作为 MCP Client 调用外部工具,也能作为 MCP Server 把知识库能力共享给其它 Agent | • Dify / RAGFlow:仅自有 REST• Haystack:自行封装连接器 | 彻底消除“每接一个数据源就改一次代码”的痛点,形成可组合、可互联的 AI 生态 |
| RAG 逻辑细分(100%) | Pipeline 颗粒级可编排- 检索 → 过滤 → Rerank → LLM → 后处理… 块级拖拽- 串并行、条件分支、循环、断点调试 | • Dify:可视化流程但节点种类有限、不可并行• Haystack:需写 Python 脚本• RAGFlow:主流程固定 | 像“搭积木”一样自定义任意深度的 RAG & Agent;复杂业务链路不再受限 |
| 高级检索(0%) | - 混合搜(向量 + BM25)- 可插拔 Cross‑Encoder Rerank- 跨库调度与去重 | • Dify:主打跨库,单库精准度一般• Haystack:需自行配置 Rerank• RAGFlow:高精度但慢 | 在保留跨库广度的同时给出专业级精准度,满足金融 / 法律等高要求场景 |
| 知识库多租户 & 安全(50%) | - 公私库 + 租户隔离- 条目级权限 & 字段加密 | 多数竞品仅简单分库或需企业版 | 企业可放心私有化部署;同一实例服务多业务线 SaaS 化无障碍 |
| 实时可观测性(50%) | 全链路调试仪表盘- 中间结果逐步展示- WebSocket 秒级推送- 断点运行 / 参数热调 | 大多仅日志或简单 Console | 开发者 DX 大幅提升,定位“幻觉”、检索不准等问题只需几分钟 |
| 开发者友好(80%) | - Python SDK + 细粒度子模块- MIT / Apache‑2.0 友好开源- Docker 一键起 | • Dify:License 对商业有约束• Haystack:代码型,上手门槛高 | 既“开箱即用”,又能拆成库嵌入现有系统,商业化不背包袱 |
| 扩展方式(50%) | MCP + 自定义组件双轨- 插件即服务- 支持把本地脚本包装成 MCP 工具 | 竞品多依赖内建接口 | 未来新模型 / 新数据库不改核心,只加一个组件即可热插拔 |
一句话总结
RAGnarok 把 RAG 做成了“可编排的乐高套装”,再加上 MCP 这把“USB‑C 通用插头”,让开发者和企业第一次可以 无锁定、零胶水 地自由拼装高精度、可观测、可扩展的检索增强智能体——这是现有任何单一 RAG 框架都无法同时做到的。
项目发布时的团队努力
项目已完成alpha阶段任务
- 邀请b端用户进行试用,收集反馈
软件工程质量
一、团队代码的软件工程质量分析
- 架构设计清晰,模块划分合理
项目采用模块化流水线(Pipeline)架构,具备高度可组合性和扩展性,支持企业用户和个人用户的多样化需求。这种设计模式体现了良好的高内聚、低耦合理念,是现代软件工程的典范结构。
- 高度关注安全性与可维护性
引入私有化部署、多租户隔离、权限管理、审计机制等功能,体现了系统在安全合规性和运维可控性方面的严谨设计,符合企业级工程的质量标准。
- 支持自动化与标准化对接
通过 MCP 协议标准化数据上下文和系统接口,大大降低与外部系统的耦合度,提高了系统的可移植性和长期维护能力。
- 面向企业用户的专业化体验设计
系统界面与交互流程针对 B 端用户进行专业化设计,支持多租户管理、权限配置、模块化知识库配置与流程编排,满足企业在数据安全、系统集成和操作效率上的需求,体现出企业级人机工程与可用性设计水准。
二、可用的数据或指标证明工程质量
为了更客观地评估和证明团队的软件工程质量,可以从以下几个维度引入数据支撑:
- 模块测试
- 除了每一个组件都有自己的单元测试外还有流水线整体测试,保证单个组件正常运行的同时测试组件间的连通性;
- 目标覆盖率应不低于 80%,关键模块(如知识库上传、MCP接口)应达到 90%+;
- 架构一致性与接口规范性
使用Apifox 保障软件工程质量

- 接口规范一致 接口即文档,统一前后端理解,减少对接错误,变更自动同步。
- 自动化测试 支持接口测试用例与断言校验,发现边界问题,保障接口稳定性。
- 前后端高效协作 提供 Mock 数据,前后端可并行开发,减少等待时间。
- 质量可视化 自动生成测试报告,覆盖率可追踪,便于问题定位与风险评估。
- 集成 CI/CD 流程 支持自动化测试接入流水线,实现每次构建前接口校验,保障上线质量。
- 版本控制与协作度指标
- 使用 Git 仓库进行版本管理;
- 所有代码通过 Pull Request 审核机制,确保每次合并前经过同行评审,提升代码质量与一致性。
- 提交记录显示多人频繁贡献代码,PR(合并请求)流程规范,说明团队协作良好、分工明确。
- 使用 uv 使依赖完全一致
使用 uv 提高了依赖管理与协作开发的工程质量,主要体现在以下方面:
- 构建环境统一:通过
uv.lock,每个开发者、CI/CD 服务器都使用完全一致的依赖版本,避免版本不一致的问题。 - 依赖安装提速:大幅减少依赖安装时间,提高开发效率和构建速度。
- 自动创建虚拟环境:简化项目初始化步骤,降低新人上手门槛。
- 依赖安全与审计支持:便于后续接入安全扫描工具,确保依赖清洁可靠。
项目管理
团队成员的简介和个人博客地址
| 成员 | 介绍 | 个人博客地址 |
|---|---|---|
| 吴佳峻 | "你是项目的PM兼测试人员,负责捍卫cxc,fxk,lyh,xxk,ypl,zfz的头发" | https://www.cnblogs.com/wuyu666888 |
| 熊晓焜 | "你是一个后端开发工程师,喜欢古典乐和足球,希望写出有序且优雅的项目" | https://www.cnblogs.com/CrisXxk |
| 叶佩霖 | "你是一个前端开发工程师,想要捍卫银河中的美" | https://www.cnblogs.com/Idrila |
| 林宇浩 | "你是一个前端开发工程师,喜欢北冰洋,还是一名羽毛球爱好者" | https://www.cnblogs.com/7111-lyh |
| 范兴堃 | "你是项目的PM兼测试人员,热爱滑雪" | https://www.cnblogs.com/Poseidon-fan |
| 钟芳梽 | "你是一个后端开发工程师,永远对新的技术保持热忱,希望能在这次合作中学习到更多的新技能" | https://www.cnblogs.com/Wednesday-zfz |
| 陈叙传 | "你是一个后端开发工程师,热衷于一切释放生产力的新技术,喜欢构建自动化工作流,你期待在团队中与前端工程师、PM等其他团队成员合作,共同创造出有价值的项目" | https://www.cnblogs.com/cxccxc |
团队项目管理
项目在开发过程中结合多种工具,实现了任务规划清晰、进度追踪高效、接口规范一致、环境统一部署,全面保障工程质量。
- 任务规划与执行跟踪:飞书文档管理全流程
- 任务管理工具:使用 飞书多维表格 全程记录任务标题、执行人、起止时间、预估工时与依赖关系,确保信息完整透明;
- 任务拆解方法:应用 WBS 将项目目标层层分解为短周期、可执行的子任务;
- 进度跟踪机制:
- 所有进度实时更新至飞书表格;
- 定期共享(每两天一次),形成 任务动态进度图表;
- 项目经理根据实际情况进行工时与依赖动态调整。
- 版本控制与开发协作:GitHub 高效管理、同步团队代码仓库
- 接口一致性与测试保障:Apifox 提升前后端协同效率
- 依赖管理与构建统一:uv 实现环境一致性
分工协作
分工协作方式:
团队成员听从PM进行任务分配,同时也按专业技能和学习意愿分工。
经验与教训:
-
经验:
- 各自负责模块,协同接口联调,明确责任边界;
- 鼓励探索新技术并在组内分享(如 MCP 协议、Qdrant 向量库)。
-
教训:
- 前期接口定义不够明确,导致后端联调阶段耗时较长
- 对部分功能定义模糊,让人难以下手,进度推进缓慢
- 前端适配对多端兼容细节预估不足,影响初期演示进度
- 组件化不足时,成员之间代码协作摩擦较大
沟通和对接
沟通方式:
- 线上同步:
- 日常通过飞书会议 + 群聊 + 多维表格协同;
- 每两天举行例会(线上或线下),进行阶段回顾与下阶段规划。
- 异步沟通:
- 所有需求、任务进展、代码接口文档都统一记录在飞书文档与表格中;
- 代码通过 Git 分支管理进行协同开发。
留存记录:
- 飞书表格保留了完整的任务与进展信息;
- 代码开发阶段的接口文档、提交记录、版本更新均保留在 Git 仓库与飞书知识库中;
- 会议纪要与决策结论同步记录在飞书文档。
时间/质量/资源的平衡
- 前期任务粒度控制与优先级排序:使用 WBS 拆解任务,并按照关键路径优先调配资源,提升整体效率;
- 动态调整与容错机制:项目经理根据任务实际进展灵活调整优先级与人力配置,有效缓解关键路径上的卡点问题;
- 阶段性完成目标、边做边调:每完成一部分功能就尽快使用和测试,根据结果及时改进后续开发方向,避免方向偏离;
- 集中投入解决关键问题:在项目后期将精力集中到系统稳定性、功能完整性和团队协作效率上,确保最终项目整体表现良好。
这种方式有助于在人员精力有限的情况下,保证演示功能的基本可用与系统结构的合理性。
实际进展情况
我们采用飞书文档进行项目进度管理
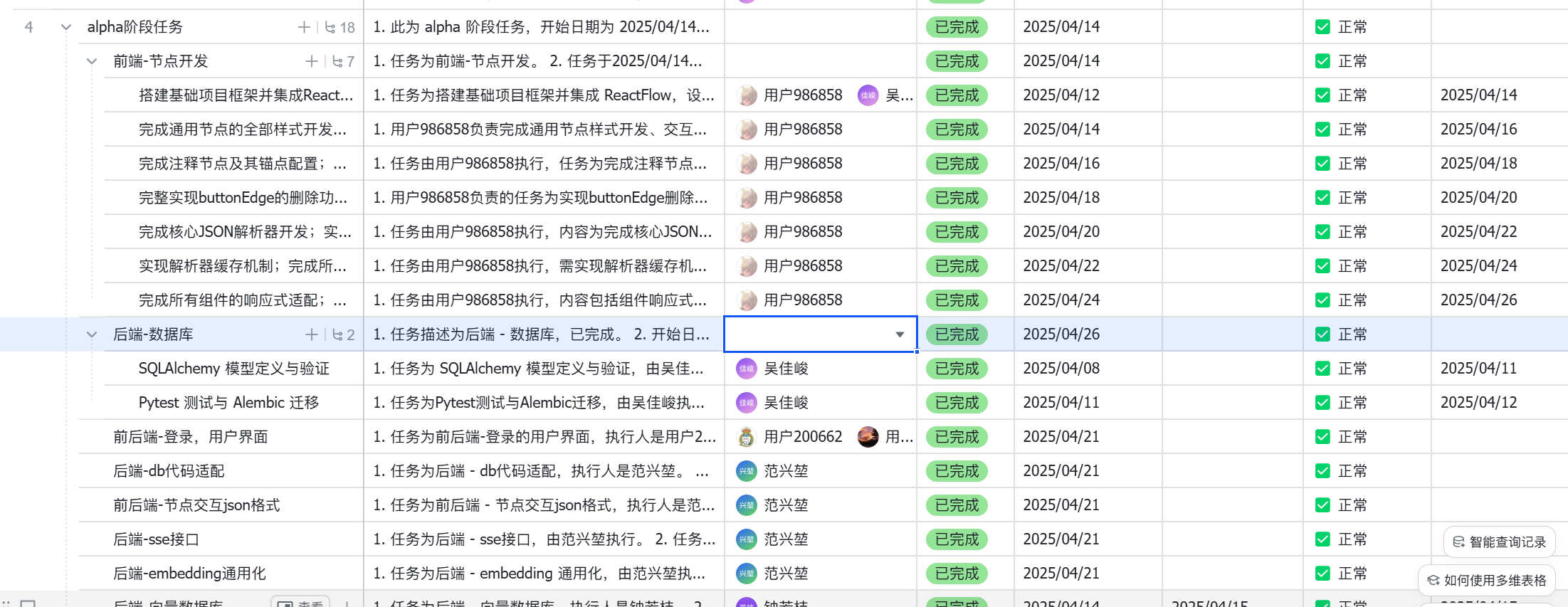


项目管理工具(燃尽图)如何反应真实状态
通过与“理想燃尽线”的对比,燃尽图能够清晰反映项目是否按计划推进:如果实际燃尽线大致贴合或低于理想线,说明项目进展顺利;如果持续高于理想线,说明进度落后,存在任务积压;而如果实际线长期没有变化,说明团队在某个阶段可能遇到阻塞,进展停滞。
燃尽图之所以能够真实反映项目状态,是因为它以每日任务完成数据为基础,不依赖主观判断,具有高度透明性和可追踪性。它不仅帮助团队及时发现偏差、调整节奏,还能在冲刺回顾时提供依据,用于复盘哪些阶段执行顺利、哪些地方存在瓶颈,从而不断优化开发流程。
项目进度管理工具(燃尽图)反映真实性分析:
-
真实性方面:
- 燃尽图反映了各成员提交的任务完成度,配合定期更新,能较真实地展示整体进度;
-
存在一定“美化”情况:
- 部分任务标为“完成”但仍有 bug 或未测试完全;
- 个别任务以“部分完成”状态上报,但在图表中仍计入“完成量”,可能掩盖问题。
团队角色与贡献
| 名字 | 角色 | 团队贡献分 | 具体的、可衡量的、可验证的贡献 |
|---|---|---|---|
| 范兴堃 | 架构与数据库设计 | 54 | 负责数据库结构设计,主导核心流程构想,参与架构方案制定与优化 |
| 吴佳峻 | PM & 技术骨干 & 工具集成 | 53.5 | 主导工具选型与集成,完成移动端适配,实现核心协议接入功能 |
| 叶佩霖 | 前端核心开发 | 53 | 搭建前端架构,完成主要页面设计与组件开发,实现响应式布局 |
| 林宇浩 | 文件处理与前端协作 | 47.1 | 开发文件切分模块,参与后端联调 |
| 熊晓焜 | embedding、前端支持与博客管理 | 47.4 | 开发embedding模块,参与前端开发、博客整理与发布 |
| 钟芳梽 | 检索模块开发 | 48 | 开发 Retrieve 模块、搭建 Qdrant 环境、参与后端联调 |
| 陈叙传 | 问答与模型调用 | 47 | 独立完成问答模块开发,优化大模型调用性能 |
用户场景
1. 项目开发前的目标,预期的典型用户场景,预期的功能描述
目标:
构建一个支持多租户、私有化部署、模块化Pipeline配置的RAG问答系统,服务B端企业用户与C端个人用户,满足其智能问答和知识管理需求。
预期典型用户场景:
- B端企业用户:如企业IT部门希望构建内部智能问答助手,应用于客服、知识库、员工培训等,注重数据安全、系统集成和多部门隔离。
- C端个人用户:如学生或自由职业者,用于查询术语、文献摘要、辅助写作等,追求使用便捷和高质量问答体验。
预期功能描述:
- 私有化部署、多租户支持
- 模块化问答流程配置(Pipeline)
- 知识上传、引用溯源
- MCP协议系统集成
- 用户权限管理、操作日志审计
- 可视化问答界面、个性化知识库
2. 项目发布的功能(拷贝发布文档),在哪里发布了软件
发布功能包含:
- 私有化部署 & 多租户架构
- MCP协议支持(系统对接)
- 模块化Pipeline问答配置
- 可视化问答界面(C端界面)
- 支持结构化/非结构化文档上传与引用
- 用户权限管理、日志审计
- 查询历史与个性化推荐机制
发布平台:
在 GitHub上作为开源项目。
3. 项目发布后是否满足了全部典型场景?剩下的为何没有满足?
是否满足全部典型场景:
- 大部分典型场景已满足:包括企业内部问答系统搭建、私有化部署、个性化知识查询等。
- 尚未满足的部分:
- 更复杂场景下的深度集成需求
- 移动端适配
- 高并发能力
原因推测:
- 开发周期和资源限制
- 用户场景过于复杂或需二次定制开发
- 某些功能优先级较低或仍在测试阶段
4. 项目发布后真正符合用户需求了吗?列出目标用户使用产品的过程和评价
是否符合用户需求:
- 大体上满足了用户需求,尤其是针对B端企业的系统集成、权限管理、私有化需求,以及C端用户的低门槛、高效率问答体验。
用户使用过程与评价:
-
B端用户使用流程:
- 企业部署系统 → 上传资料 → 配置Pipeline → 对接内部系统 → 设置权限
-
C端用户使用流程:
- 注册账号 → 上传笔记/PDF → 提问 → 获取答案和引用文献 → 收藏/反馈
用户日活
我们已经邀请了b端用户进行试用,现阶段用户的活跃量不是很多,收集到的反馈也比较有限。
特色功能
1. 杀手级功能
RAGnarok 的杀手级功能是:
- MCP协议支持 + 可编排 RAG Pipeline 的双组合:
- MCP协议支持让 RAGnarok 成为可以双向对接的“AI 万能插头”,既能调用外部智能体工具,也能将自身能力暴露给其它系统,突破了单一框架的封闭限制。
- 可编排的 RAG 流程设计支持颗粒级逻辑自由组合(检索→过滤→重排→LLM调用→后处理等),以图形化方式“搭积木”构建任意复杂任务流程。
与竞品相比,Dify 的流程节点种类有限、不能并行;Haystack 需代码脚本实现流程,RAGFlow 流程固定难拓展。RAGnarok 首次实现了零代码、块级组合的灵活性,同时还支持断点调试、参数热调等高级可观测性。
2. 竞品为何不具有这些功能
竞品缺失原因:
- 生态封闭或设计初衷不同:如 Dify 更聚焦 C 端轻量体验,不追求多智能体协作;Haystack 偏底层 NLP 工具包,缺乏“通用插件”理念;RAGFlow 固化流程,利于教学但缺乏生产级灵活性。
- 缺乏协议层标准(如 MCP)支持:竞品大多是“孤岛型”设计,无法与外部智能体生态打通。
我们的实现优势:
- 架构前瞻性:在系统设计初期就将“模块化、组合性、可扩展性”作为首要目标。
- 协议抽象层 MCP 的原生支持:团队在系统集成与智能体通信方面积累较多经验,能够实现 RAG 与智能体的无缝协同。
- 前后端协同能力强:支持 WebSocket 实时链路追踪、图形化拖拽界面、后端可热插拔调度器等技术难度较高的功能。
3. 团队成员对这些功能的自我评价
自我评价:
- 核心目标已实现。
- MCP 协议集成效果优于预期,插件注册和调用稳定性高,复用效率高。
- 拖拽式 RAG 设计在测试场景中实现了多流程并发与调试。
是否达标:
达到了预期目标
4. 用户对这些功能的评价如何?是否认为这些功能富有特色,为什么?
用户评价:
B端用户普遍认为 MCP 插件机制与图形化流程功能非常有用。特别是在多部门共享数据、分层权限配置与私有部署需求场景中更加灵活且安全。
用户为何觉得功能富有特色:
- 之前尝试过的工具无法兼容多个数据源或自定义工作流,而 RAGnarok 正好解决了这个痛点。
- MCP 协议的“即插即用”能力,帮助 IT 团队快速打通原有系统与新 AI 能力,无需改动业务系统。
- 图形化流程中每个步骤都能实时预览中间结果,对调试和教学极具帮助。
软件工程质量
1. 项目有完善的文档吗,是否有约定代码规范?
项目具备完善的文档体系和统一的代码规范
- 使用 Apifox 进行接口文档与测试管理,接口即文档,前后端协作高效。
- 每个模块和接口都有说明文档,遵循统一的设计规范和接口约定。
- 所有代码通过 Pull Request 审核机制,确保风格一致性与代码质量。
2. 项目是否有出现代码混乱、没有注释、没有详细文档的问题?明年继续开发会不会出现以上抱怨?
- 项目代码组织良好,模块划分清晰。
- 代码和接口的规范性能够在联调过程中确保。
- 每个模块有文档说明,新同学阅读文档和 PR 记录能快速理解项目结构和开发规范。
3. 如果一个新学生在一台新机器上想编译并运行你的项目,能顺利完成吗?有什么样的文档能指导他?
可以顺利完成,项目使用 uv 管理依赖,具备良好的可移植性:
- 项目配套提供
README和环境初始化脚本。 - 通过
uv自动创建虚拟环境,确保依赖版本一致、安装过程简洁。 - 有明确的启动说明文档,包括数据库初始化、接口服务运行、前端调试等流程。
4. 项目是否有单元测试?测试用例数目、代码覆盖率等?
有明确的单元测试与流水线测试机制:
- 每个组件都具备单元测试。
- 流水线中集成了整体测试。
- 关键模块和整体项目都能够充分覆盖。
**5. 项目是否采用了 CI/CD
- 集成自动化测试、接口校验与构建流程。
- 每次提交触发流水线进行接口测试与依赖校验。
- 通过测试报告和覆盖率工具确保上线版本质量。
6. 学到的经验和教训:Alpha 阶段学到了什么?对软件工程的经验教训?Beta 阶段有什么计划?
Alpha 阶段经验教训:
- 模块解耦性很关键:早期模块间耦合度高,后期通过流水线架构大幅降低依赖,提高可测试性。
- 接口标准化带来巨大收益:MCP 协议与 Apifox 使前后端协作更流畅。
- 可扩展性:如果没有事先进行规划未来扩展时会面临许多困难。过早的决定或不充分的规划可能导致需要重构系统。
Beta 阶段计划:
- 优化多租户资源隔离与权限控制模块。
- 前端的功能要继续完善。
- 增加使用文档与开发者指南,降低用户与开发者上手门槛。
- 实现完整的持续部署流程,支持线上预览与多环境切换。
- 需要改变项目的推广方式,找到更多的用户并且得到更多的反馈,尤其是C端。
项目一览


 浙公网安备 33010602011771号
浙公网安备 33010602011771号