感知机
(本章主要参考李航老师的《统计学习方法》和周志华老师的《机器学习》以及各个博客园+CSDN的博客。通过自己的阅读,提炼出书中的知识点以及些许自己部分的理解(可能不到位),巩固所学知识。如有不当,恳请指出,多多包涵!)
2.感知机
1.感知机是二分类的线性分类模型
2.感知机将输入的实例划分为正负两类,属于判别模型
3.感知机于1957年由Rosenblatt提出
2.1感知机模型
感知机定义:假设输出空间是X,输出空间是Y={-1,+1}。输入x属于X,表示实例的特征向量,输出y属于Y,表示实例的类别,由输入空间到输出空间的如下函数:
f(x)=sign(w*x+b)
称为感知机。w叫做权值,b叫做偏置,sign是符号函数。

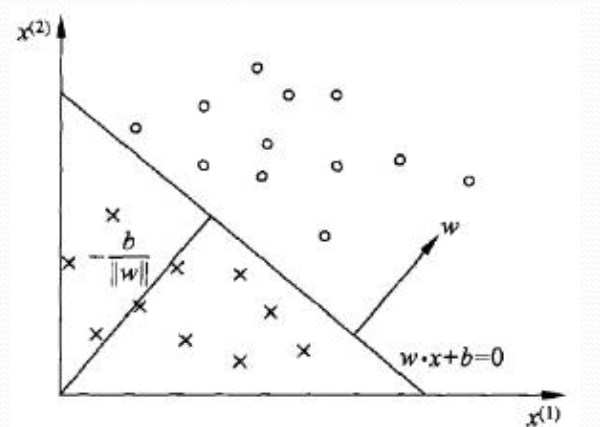
感知机由如下几何解释:
线性方程: w*x+b=0 对应于特征空间中的一个超平面S,其中w是超平面的法向量,b是超平面的截距。
这个超平面将特征口昂加分为两部分,位于两部分的点分别被分为正类和负类。
2.2感知机学习策略
假设训练数据集是线性可分的,感知机学习的目标是求得一个能够将训练数据集的正实例点和负实例点完全正确分开的超平面。为了找出这样的超平面,定义损失函数,确定参数w,b使得损失函数极小化。
损失函数一个自然的选择是误分类的总数,但该函数并不是w,b的连续可导函数,不易优化。故另一个选择是误分类点到超平面S的总距离。
输入空间Rn中任何一点x0到超平面S的距离为:

∥w∥是w的L2范数。
对于误分类的数据(xi,yi)
-yi(w*xi+b)>0
成立(添加yi 的原因是去掉绝对值)。
故,所有误分类点到超平面S的总距离为(M为误分类点的集合):

不考虑分母∥w∥(因为分母对优化目标无影响。权值w是一个向量,而∥w∥是大小不会影响向量的方向。确定一个超平面是通过法向量w和截距b,故∥w∥对优化无影响。),故得损失函数:
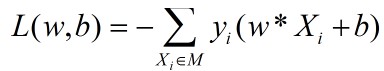
2.3感知机学习算法
2.3.1感知机学习算法的原始形式
感知机算法是误分类点驱动的,具体采用随机梯度下降法.
首先选取w0,b0,然后沿梯度方向不断迭代w和b的值,直到达到损失函数局部极小值。
假设误分类点集合M是固定的,那么损失函数L(w,b)的梯度由:
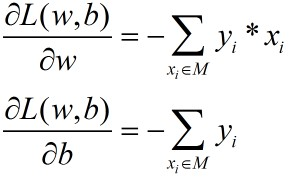 (梯度即是对变量求导)
(梯度即是对变量求导)
接着随机选取一个误分类点(xi,yi),即该点满足yi*(w*xi+b)≤,对w和b进行更新:
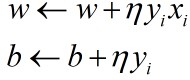
(其中η(0<η≤1)称为学习率(learning rate),可以通过学习率控制迭代速度。若是η太大可能无法收敛,η太小速度太慢。选取一个合适的η值对学习算法有较大的帮助。)
继续重复选择误分类点对w,b迭代更新。
直到无误分类点或w、b的值不再变化。此时损失函数达到极小值。
2.3.2感知机学习算法的收敛性
定理:对于线性可分的数据集,感知机学习算法的原始形式收敛。即经过有限次迭代可以得到一个将数据集完全正确划分的超平面。
迭代次数k≤(R/η)2,其中R为max{||xi||},η为min{yi*(w*xi+b)}(其中w、b满足的超平面能正确分离数据集)
2.3.3感知机学习算法的对偶形式
posted on 2018-09-07 21:25 小青青learner 阅读(192) 评论(0) 收藏 举报


 浙公网安备 33010602011771号
浙公网安备 33010602011771号