
编译原理
编译原理

第一章 引论
1.编译程序:先编译后执行
2.解释程序:边解释边执行
3.编译程序的工作过程:词法分析、语法分析、语义分析与中间代码产生、优化、目标代码生成
4.描述词法规则的工具:正规式和有限自动机
5.描述语法规则的工具:上下文无关文法
6.编译程序的结构:词法分析器、语法分析器、语义分析与中间代码产生器、优化器、目标代码生成器、表格管理和出错处理
7.遍:对源程序或源程序的中间结果从头到尾扫描一次,并作有关的加工处理,生成新的中间结果或目标程序
8.编译前端主要由与 源语言 有关但与目标机无关的部分组成
9.编译后端包括与目标机有关的部分,不依赖源语言而依赖于中间语言
第二章 高级语言及其语法描述
| 规则 | 描述工具 |
|---|---|
| 词法规则 | 正规式和有限自动机 |
| 语法规则 | 上下文无关文法 |
| 语义规则 | 属性文法 |
1.单词符号是由词法规则所确定的,单词符号一般包括:各类型的常数、标识符、基本字、算符和界符等。
2.语法规则规定了如何从单词符号形成语法单位,一般程序语言的语法单位有:表达式、语句、分程序、函数、过程和程序等。
3.语义:单词符号和语法单位的意义。
4.字母表、符号和符号串。
设 \(\sum\) 是一个有穷字母表,它的每一个元素称为一个符号。
\(\sum\) 上的一个符号串是指由 \(\sum\) 中的符号所构成的一个有穷序列,不包含任何符号的序列称为空字,记为 \(\varepsilon\)。
用 \(\sum^*\) 表示 \(\sum\) 上的所有符号串的全体,空字 \(\varepsilon\) 也包括在其中。
\(\sum^*\) 的子集 \(U\) 和 \(V\) 的(连接)积定义为 \(UV = \{ \alpha\beta | \alpha \in U \& \beta \in V \}\)
记 \(U^0 = \{ \varepsilon \}\),$U^* = U^0 \cup U^1 \cup U^2 \cup \cdots $,称 \(U^*\) 是 \(U\) 的闭包;记 \(U^+ = UU^*\),称 \(U^+\) 是 \(U\) 的正则闭包
5.上下文无关文法包括四个组成部分:一组终结符号 \(V_T\),一组非终结符号 \(V_N\),一个开始符号 \(S\) 和
一组产生式。
上下文无关文法:它所定义的语法范畴(或语 法单位)是完全独立于这种范畴可能出现的环境的
语法规则: \(\rightarrow\) 表示由\(\cdots\)组成或定义为\(\cdots\) 。p27 ,一步只能推导一个
推导每前进一步总是引用一条产生式,符号 \(\Rightarrow\) 指仅推导一步,如 \(E \Rightarrow i\)
6.句型、句子和语言。p29
若 \(S \stackrel{*}{\Rightarrow} \alpha\),则称 \(\alpha\) 是一个句型,仅含终结符的句型是一个句子。
文法 \(G\) 所产生的句子的全体是一个语言,记作 \(L(G)\)
7.一棵语法树表示了一个句型种种可能的(但未必是所有的)不同推导过程,包括最左(最右)推导。
8.二义文法:一个文法存在某个句子对应两棵不同的语法树,即有两个不同的最左(最右)推导
2.3 程序语言的语法描述
-
非终结符(也称语法变量)用来代表语法范畴 p27
-
推导的概念 p29
-
最左推导和最右推导 p30
最左推导是指任务一步 \(\alpha \Rightarrow \beta\) 都是对 \(\alpha\) 中的最左非终结符进行替换的;最右推导同理

- 语法分析树:用一张图表示一个句型的推导,或简称为语法树
如果一个文法存在某个句子对应两棵不同的语法树,则称这个文法是二义的
第三章 词法分析
词法分析的任务:从左至右逐个字符地对源程序进行扫描,产生一个个单词符号,把作为字符串的源程序改造成为单词符号串的中间程序。
词法分析器(Lexical Analyzer) 又称扫描器 (Scanner):执行词法分析的程序
- 3.1 对于词法分析器的要求
功能:输入源程序, 输出单词符号(程序语言基本的语法符号)
单词符号的种类:关键字、标识符、常数、运算符、界符
输出的单词符号的表示形式:(单词种别,单词符号的属性值)
单词种别通常使用整数编码表示
把词法分析器作为一个独立的子程序,每当语法分析器需要一个单词符号的时候就调用这个子程序;每一次调用,词法分析器就从输入串中识别出一个单词符号,把它交给语法分析器
- 3.2 词法分析器的设计
使用状态转换图是设计词法分析程序的一种好途径
基本概念
1.词法分析器的功能是输入源程序,输出单词符号。
2.词法分析器输入的单词符号表示成二元式(单词种别,单词符号的属性值)
3.正规文法、正规式、确定有限自动机(DFA)和非确定有限自动机(NFA)在接收语言的能力上是等价的
正规式 -> NFA -> DFA \(\stackrel{化简}{\longrightarrow} \cdots\)
-
对任何FAM,都存在一个正规式r,使得 L(r)=L(M)。
-
对任何正规式r,都存在一个FAM,使得 L(M)=L(r)。
4.LEX:描述词法分析器的语言,由一组正规式以及与每个正规式相应的一个动作组成。
计算
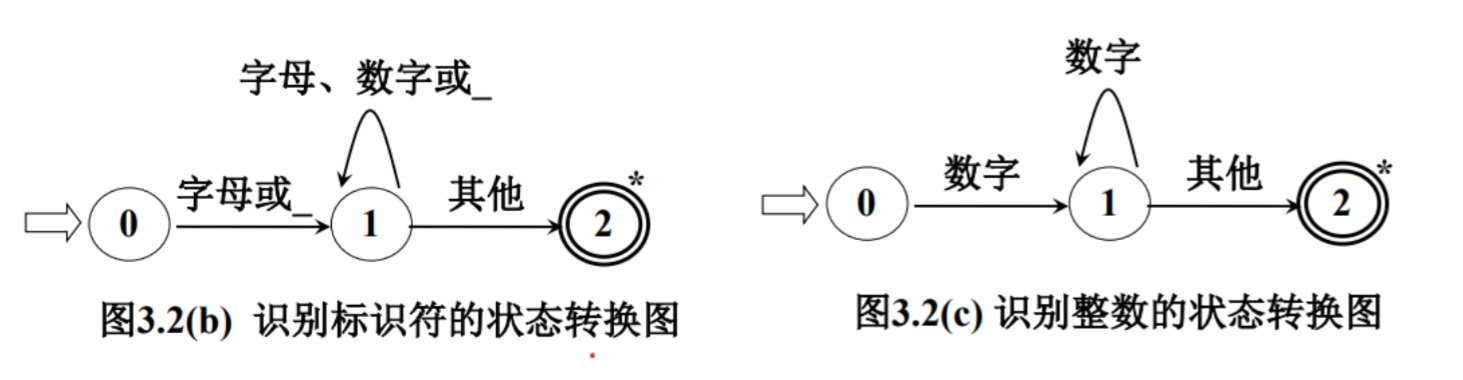
1.转换图:图 3.2(b) 、图 3.2(c)。
词法分析器的设计
2.正规式与正规集:例 3.1、例 3.2。
用正规式来描述正规集

3.从正规式构造有限自动机:例 3.5。 ppt 3 - 2 p45 / p53
正规式和有限自动机之间的相互转换,从有限自动机转化为正规式较为简单,详见书,这里摘记正规式转化为有限自动机
从小到大构造正规式

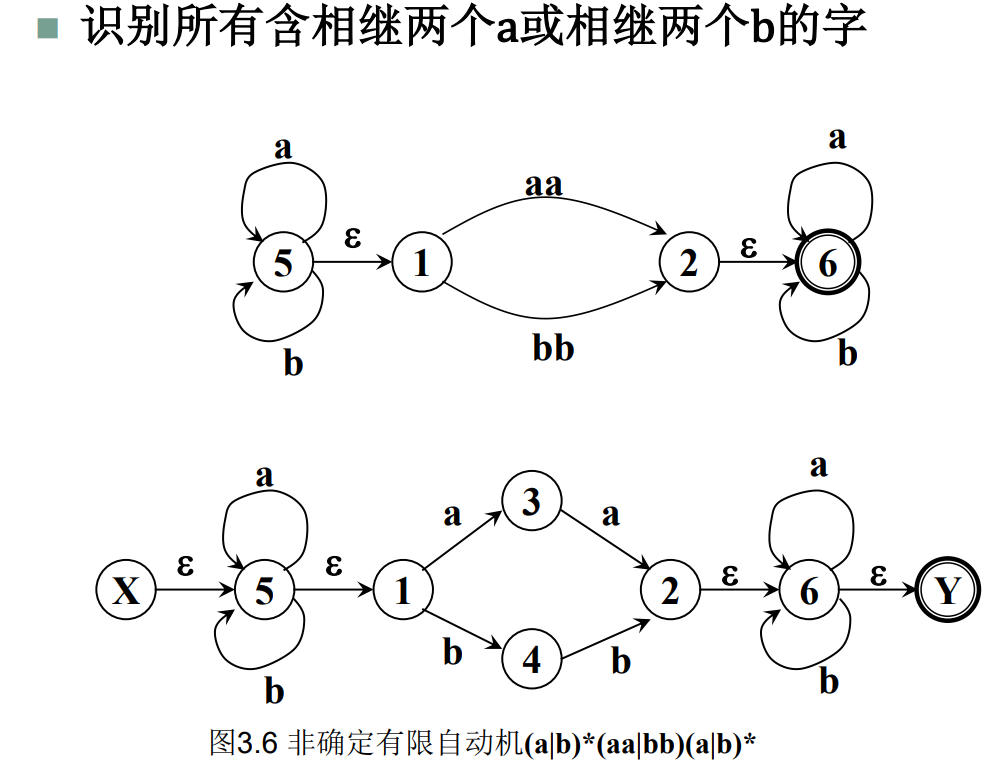
4.NFA 确定化:例 3.3。
对于每一个 NFA M,都存在一个 DFA M'',使得 L(M) = L(M'') p49 / ppt 3-2 p15~37
子集法把 NFA 确定为 DFA

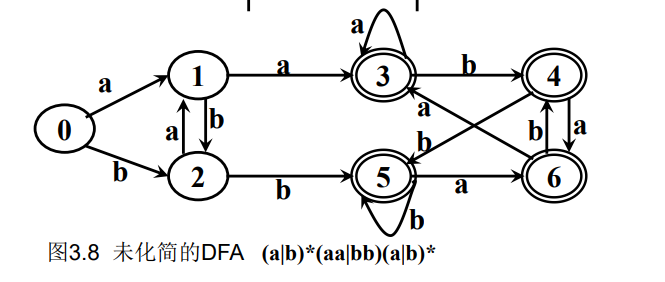
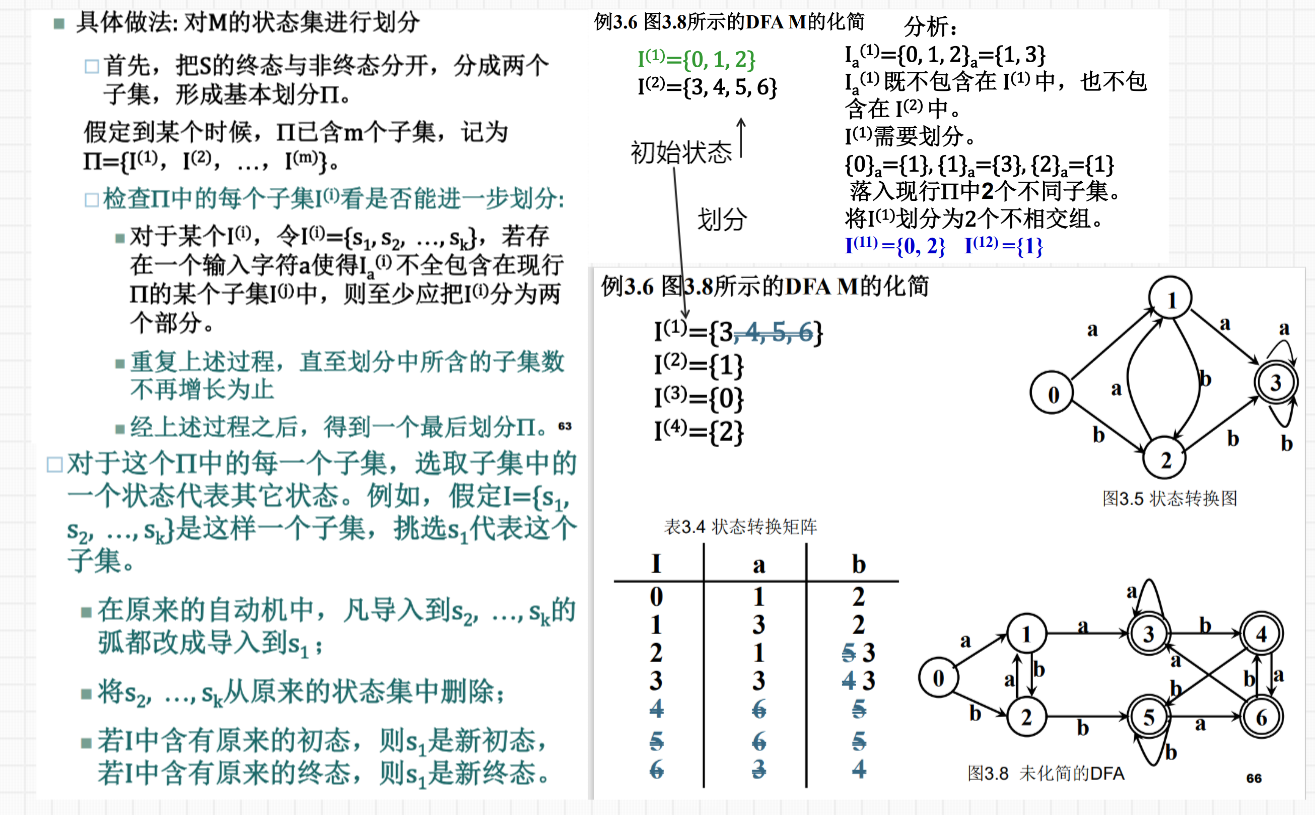
5.DFA 的化简:例 3.6 p57 / ppt 3-2 p52
DFA M的化简:寻找一个状态数比M少的DFA M’, 使得L(M)=L(M’)
两个状态等价: 假设 s 和 t 是 M 的两个不同状态,如果从状态 s 出发能读出某个字 w 而停止于终态,那么同样,从t出 发也能读出同样的字 w 而停于终态;反之亦然。
两个状态可区别: 如果 DFA M 的两个状态 s 和 t 不等价,则称这两个状态是可区别的。 例:终态与非终态是可区别的
利用分割法实现 DFA 的化简
第四章 语法分析-自上而下分析
- LL(1) 分析法
左递归的消除 和 提取左因子、回溯的消除 见书 p71

当一个文法满足 LL(1) 条件的时候,我们就可以为它构造一个不带回溯的自上而下分析程序,这个程序是由一组递归程序组成的,每个过程对于文法的一个非终结符。这样的一个程序称为递归下降分析器
实现 LL(1) 分析的另一种有效方法是使用一张分析表和一个栈进行联合控制,书上介绍了预测分析程序
基本概念
1.语法分析器的工作是按文法的产生式,识别输入符号串是否为一个句子,从概念上讲, 就是要建立一棵与输入串相匹配的语法分析树。
2.自上而下分析从文法的开始符号出发,向下推导,推出句子,即自上而下地为输入串建立一棵语法树,或者说,为输入串寻找一个最左推导。
计算
1.消除文法的左递归:例 4.2、例 4.3。 p69 / ppt 4-1 p11

**2.构造 FIRST 集和 FOLLOW 集:例 4.7。 p78 **
FIRST集定义 p71
构造FIRST集:

FOLLOW集定义 p73
构造FOLLOW集:

3.构造预测分析表:例 4.8。 p79

4.利用预测分析表进行预测分析:例 4.6 p76 / ppt 4-2 p11

第五章 语法分析-自下而上分析
-
在算符优先分析中,我们用“最左素短语”来刻画“可归约串”;在“规范归约”中,则用“句柄”来刻画“可归约串”
-
采用“移进-归约”思想进行自下而上分析
-
算符优先分析法不是一种规范归约法,其特别有利于表达式分析,宜于手工实现
-
LR 分析法:L 表示从左到右扫描输入串,R 表示构造一个最右推导的逆过程
LR分析程序对所有的LR语法分析器都是一样的, 不同的语法分析器LR分析表不同
-
LR分析器基本概念 p100
-
活前缀:规范句型的一个前缀,该前缀不含句柄之后的任何符号。可归前缀:归约动作前符号栈中的内容称为可归前缀 p104
-
LR(0)文法:一个文法G的拓广文法G'的活前缀识别自动机中的每个状态(项目集)不存在下述情况 - 既含移进项目又含归约项目 、 含有多个归约项目,即文法的活前缀识别自动机的每个状态(项目集)都不含冲突性的项目。
使用LR(0)表的分析器叫做一个LR(0)分析器

-
SLR(1)文法:按照下文给出的算法构造的含有 ACTION 和 GOTO 两部分的分析表,如果每个入口不含多重定义,则称它为文法 G 的一张 SLR 表,具有 SLR 表的文法 G 称为一个 SLR(1) 文法
使用SLR表的分析器叫做一个SLR分析器
每个SLR(1)文法都是无二义的,但也存在许多无二义文法不是SLR(1)的。
-
规范 LR 分析表

按下面描述的算法构造的分析表,若不存在多重定义的入口(即,动作冲突)的情形,则称它是文法G 的一张规范的LR(1)分析表。
使用这种分析表的分析器叫做一个规范的LR分析器。具有规范的LR(1)分析表的文法称为一个LR(1) 文法。LR(1)状态比SLR多
- LALR分析表
心:一个LR(1)项目可以看成两个部分组成,一部分 和LR(0)项目相同,这部分称它为心,另一部分为向 前搜索符。
同心集:对于两个LR(1)项目集,如果除去搜索符之 后,这两个集合是相同的,则称这两个集合是同心集
LALR分析表的构造见 p118 / ppt5-5 p16
基本概念
1.自下而上分析:从输入串开始,逐步归约,直至归约到文法的开始符号。
2.移进-归约法:用一个寄存符号的先进后出栈,把输入符号逐个移进栈里,当栈顶形成某个产生式的候选式时,把栈顶的这一部分归约为该产生式的左部符号。
3.短语、直接短语、句柄:一个句型的最左直接短语。
4.规范归约:最左归约
5.规范推导(最右推导)、规范句型(由规范推导所得的句型)
6.如果文法是无二义的,那么规范推导(最右推导)的逆过程必是规范归约(最左归约)。
7.语法分析对符号栈的使用有四类操作:移进、归约、接受和出错处理。
8.算符优先关系

9.算符文法与算符优先文法 p89
算符文法:一个文法,如果它的任一产生式的右部都不含两个相继(并列)的非终结符,即不含如下形式的产生式右部: …QR…,则我们称该文法为算符文法。
算符优先文法:

10.YACC:编译程序自动产生工具,输入用户提供的语言的语法描述规格说明,基于 LALR 语法分析的原理,自动构造一个该语言的语法分析器。
计算
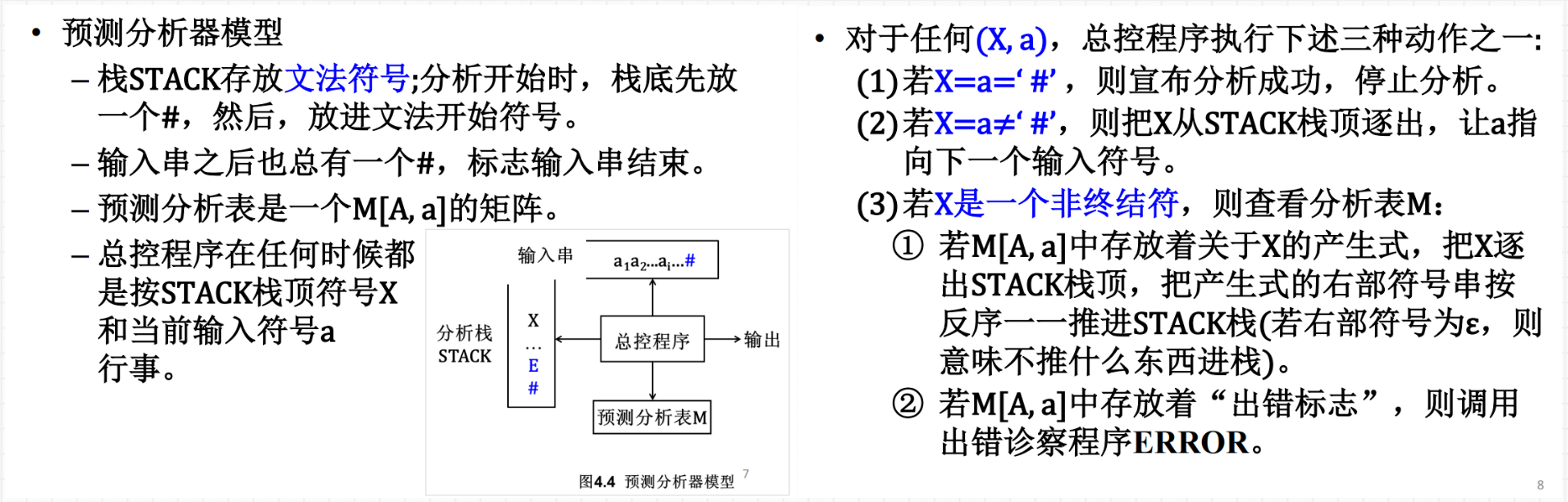
**1.短语、直接短语、句柄:例 5.1、5.2。 p85 / ppt 5-1 末尾 **
该概念是相对与句型而言的


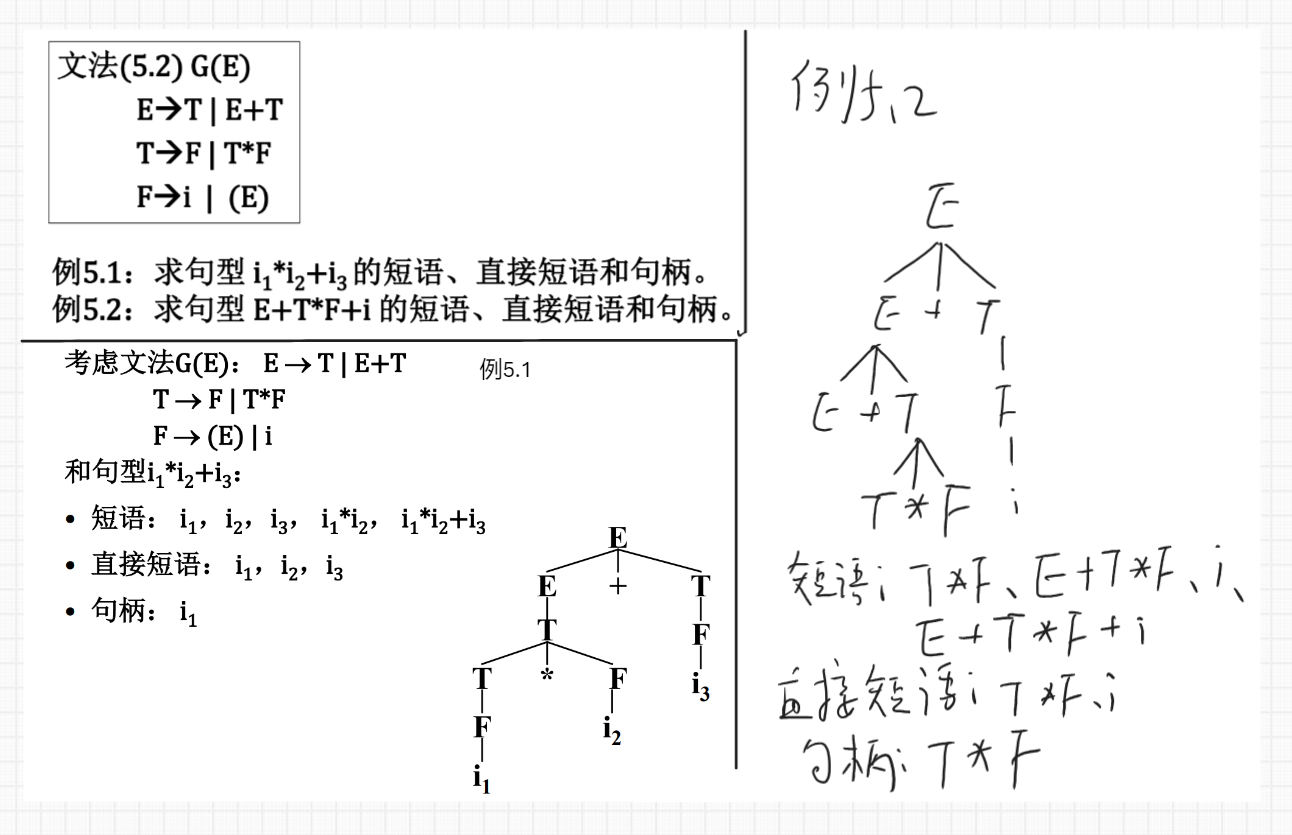
2.FirstVT、LastVT、构造优先关系表:例 5.4 p90 / ppt 5-2 p12

由此构造优先关系表


可以利用一个二维表和一个栈实现 FIRSTVT 集和 LASTVT 集的构造

例:
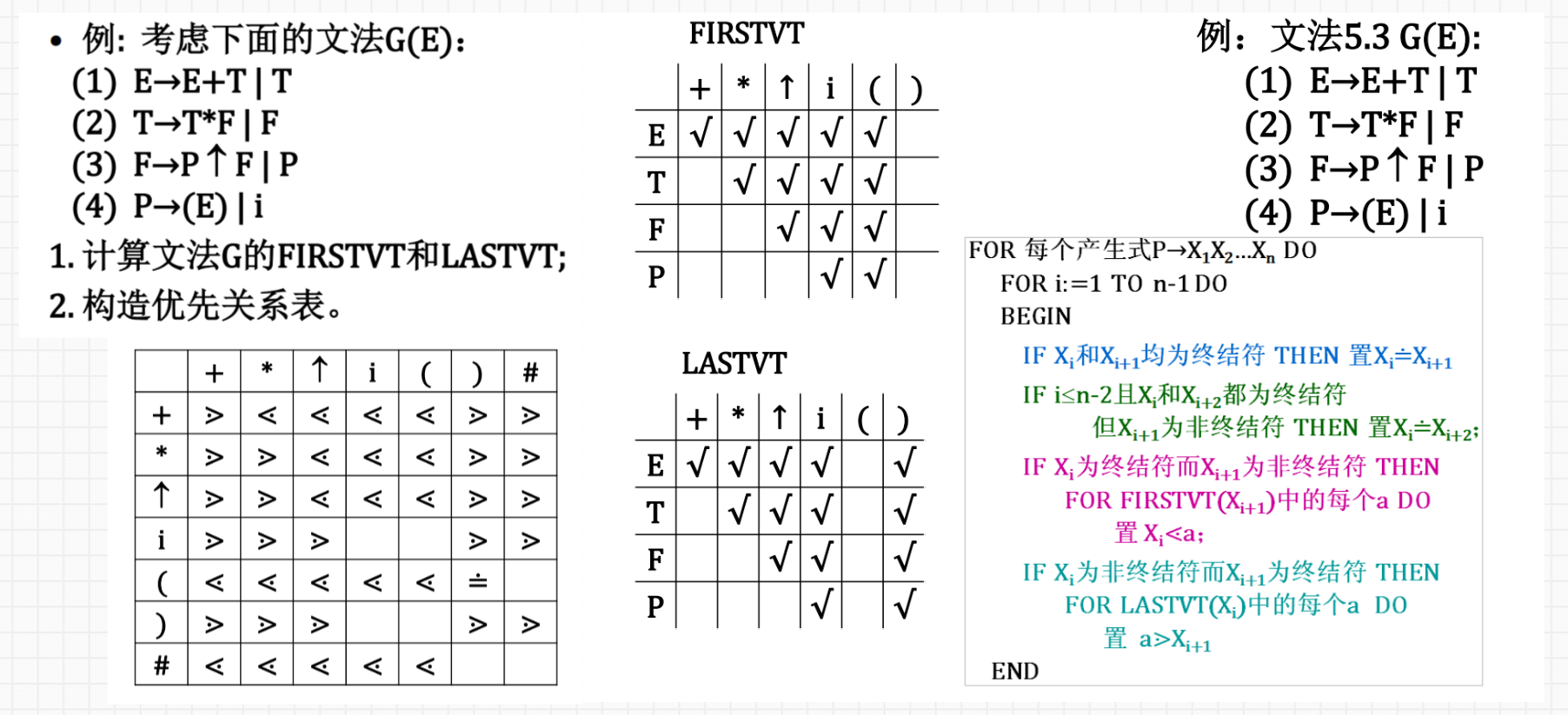
3.最左素短语:见 ppt 书 p92
素短语: 是指一个短语,它至少含有一个终结符,并且,除它自身之外不再含任何更小的素短语。
最左素短语: 处于句型最左边的素短语。
4.算符优先分析算法:见 ppt5-2 p31 / p92


5.利用 LR 分析表,写出 LR 分析器的工作过程:例 5.7 p102
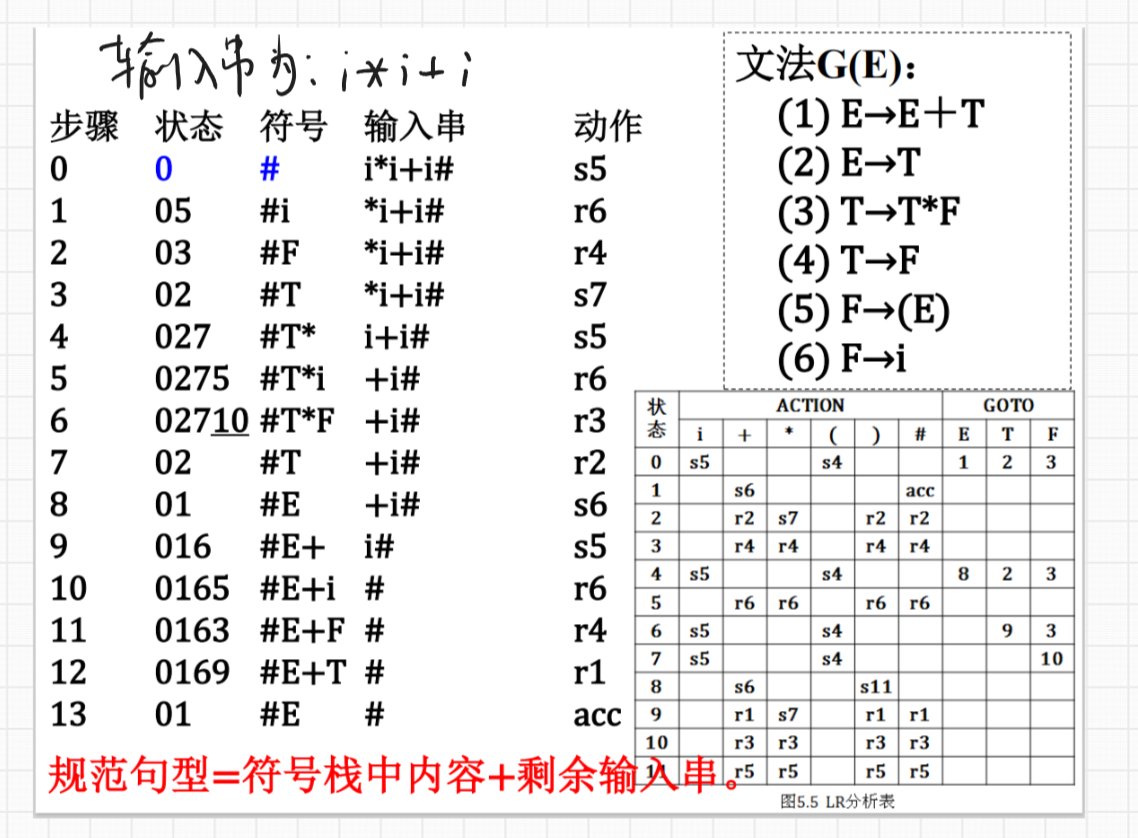
6.LR(0)项目集规范族的构造:例 5.9 p107
文法G的每个产生式的右部添加一个圆点称为G的一个LR(0)项目

构成识别一个文法活前缀的DFA的项目集(状态)的全体称为文法的LR(0)项目集规范族
LR(0)项目集规范族的构造:
- 项目集: CLOSURE函数
- 状态转换: GO函数



LR(0)分析表的构造 p109
7.SLR(1)分析表的构造:见 ppt 5-4 p7 / p110
如果构造出的LR(0)项目集规范族含有“移进-归约”冲突时,可考虑SLR(1)分析表
当存在下图情况时,可以考虑SLR(1)分析表



8.LR(1)项目集族的构造:例 5.13 p115 / ppt 5-5 p3
构造LR(1)项目集族:
- 闭包函数 CLOSURE
- 状态转换函数 GO



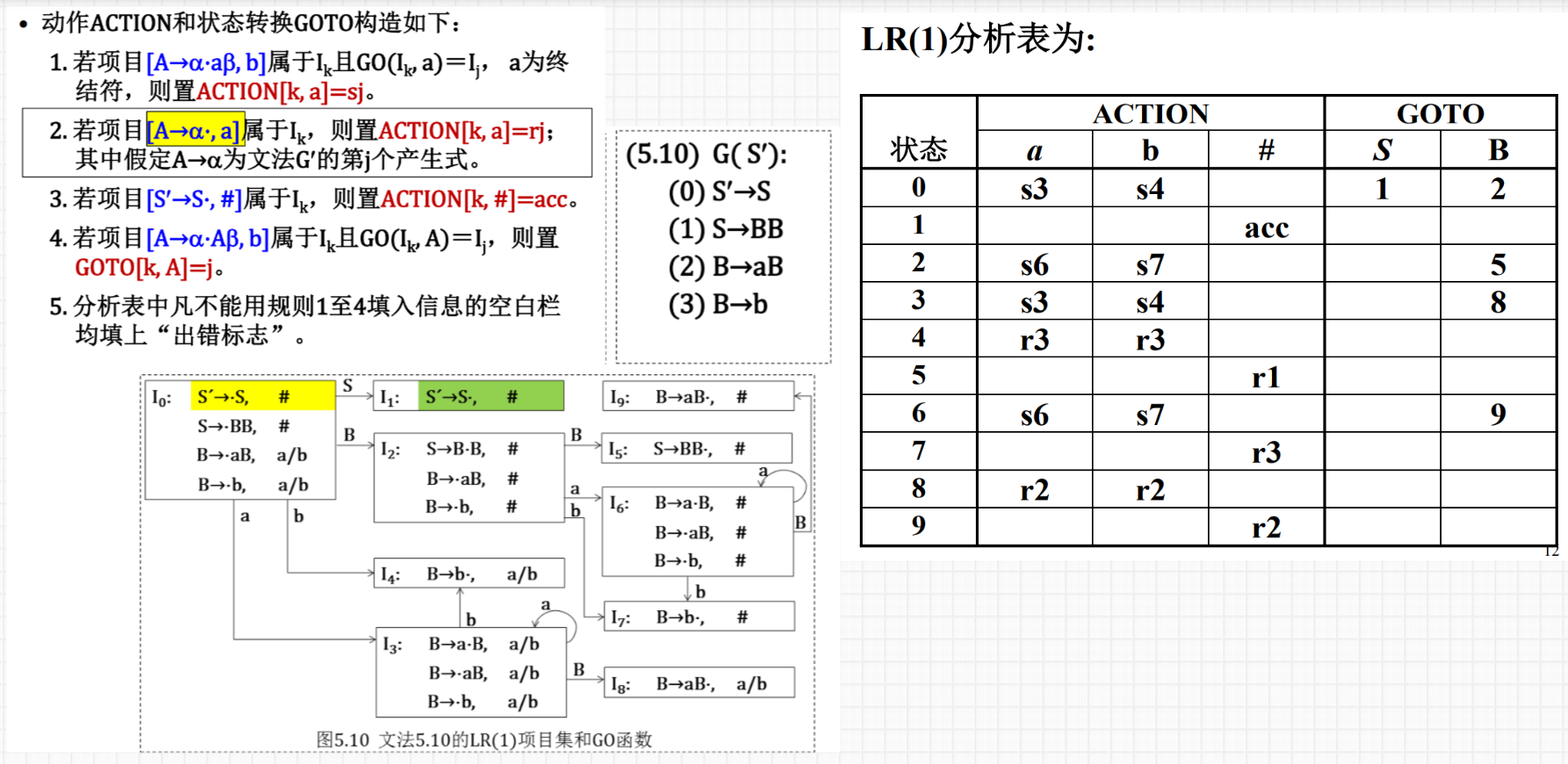
9.LR(1)分析表的构造:见 ppt5-5 p10 / p115
第六章 属性文法和语法制导翻译
-
基于属性文法的处理方法:依赖图、树遍历的属性计算方法、一遍扫描的处理方法、抽象语法树 p144
-
属性文法:语言翻译的规范说明,隐去实现细节。
翻译模式:给出了使用语义规则进行计算的次序, 这样就可把某些实现细节表示出来
基本概念
1.属性文法:在上下文无关文法的基础上,为每个文法符号(终结符或非终结符)配备若干相关的“值” (称为属性)
2.语义规则:对于文法的每个产生式都配备了一组属性的计算规则
3.综合属性和继承属性
综合属性:“自下而上”传递信息
继承属性:“自上而下”传递信息
4.抽象语法树:在语法树中去掉那些对翻译不必要的信息,从 而获得更有效的源程序中间表示。这种经变换后的语法树称之为抽象语法树。在抽象语法树中,操作符和关键字不作为叶结 点出现,而是作为内部结点。 p144
5.S-属性文法:只含有综合属性
6.L-属性文法:

计算
1.S-属性文法的自下而上计算:例 6.9 p148
S-属性文法的翻译器借助于LR分析器实现,综合属性在每次归约前计算

2.消除左递归的翻译模式:p153
在翻译模式中,和文法符号相关的属性和语义规则 (这里我们也称语义动作),用花括号{ }括起来, 插入到产生式右部的合适位置上
为了构造不带回溯的自顶向下语法分析,必须消 除文法中的左递归。当消除一个翻译模式的基本文法的左递归时同时考虑属性

3.递归下降翻译器的设计:见 ppt 6-3 p27
如何在递归下降分析中实现翻译模式,构造递归下降翻译器


第七章 语义分析和中间代码产生
- 中间语言(复杂性界于源语言和目标语言之间)的好处:便于进行与机器无关的代码优化工作、易于移植、使编译程序的结构在逻辑上更为简单明确
基本概念
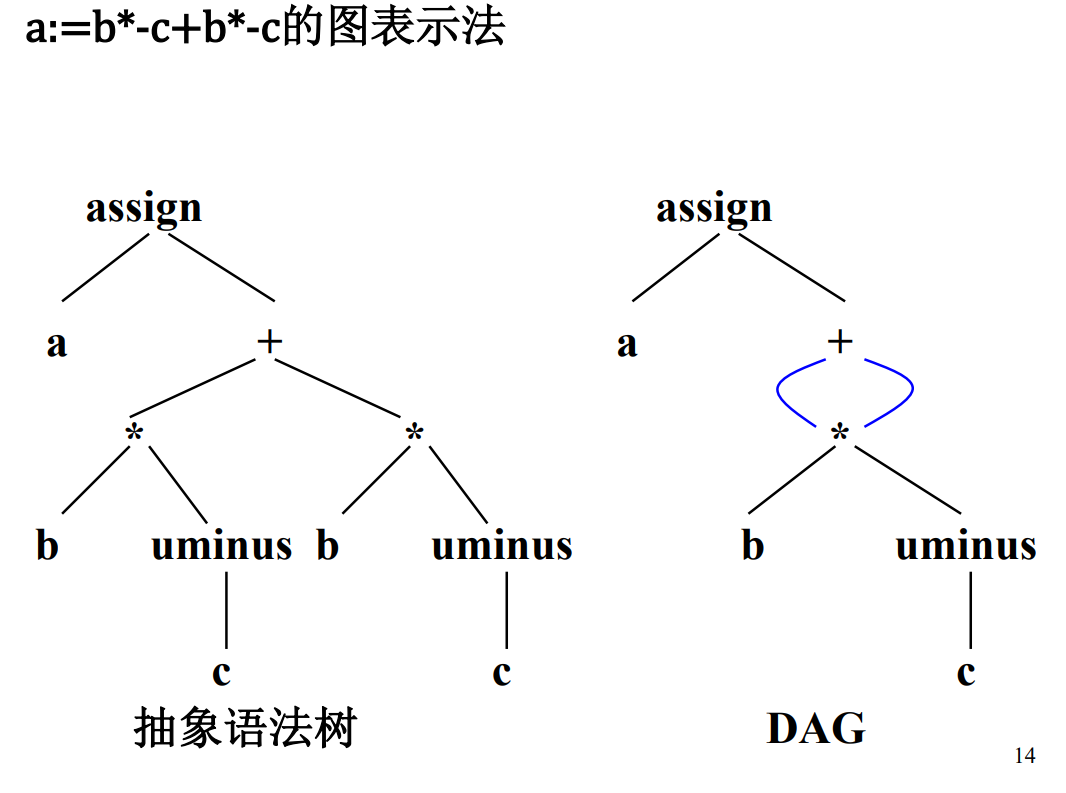
1.中间语言的形式:后缀式、三地址代码、DAG 图和抽象语法树。
2.DAG 与抽象语法树的区别
- 在语法树中去掉那些对翻译不必要的信息,从而获得更有效的源程序中间表示。这种经变换后的语法树称之为抽象语法树(Abstract Syntax Tree)。在抽象语法树中,操作符和关键字都不作为叶结点出现,而是把它们作为内部结点,即叶结点的父结点
- 无循环有向图(Directed Acyclic Graph,简称DAG):对表达式中的每个子表达式,DAG中都有一个结点;一个内部结点代表一个操作符,它的孩子代表操作数;在DAG中代表公共子表达式的结点具有多个父结点,在抽象语法树中公共子表达式被表示为重复的子树
3.三地址代码:'x := y op z'
x、y、z:名字、常数或编译时产生的临时变量;op:运算符号
每个语句右边只能有一个运算符
三地址代码可以看成是抽象语法树或DAG的一种线性表示,生成三地址代码时,临时变量的名字对应抽象语法树的内部结点
计算
1.后缀式:又称为逆波兰表达式,把运算量写在前面,把算符写在后面(后缀)
一个表达式 E 的后缀形式可以如下定义:
- 如果 E 是一个变量或常量,则 E 的后缀式是 E 自身
- 如果 E 是 $ E_1 \ op \ E_2 $ 形式的表达式,op 是二元操作符,则 E 的后缀表达式是 $ E_1' \ E_2' \ op $ ,$ E_1' $ 和 $ E_2' $ 分别是 $ E_1 $ 和 $ E_2 $ 的后缀式
- 如果 E 是 $ (E_1) $ 形式的表达式,则 $ E_1 $ 的后缀式就是 E 的后缀式
逆波兰表达式不需要括号
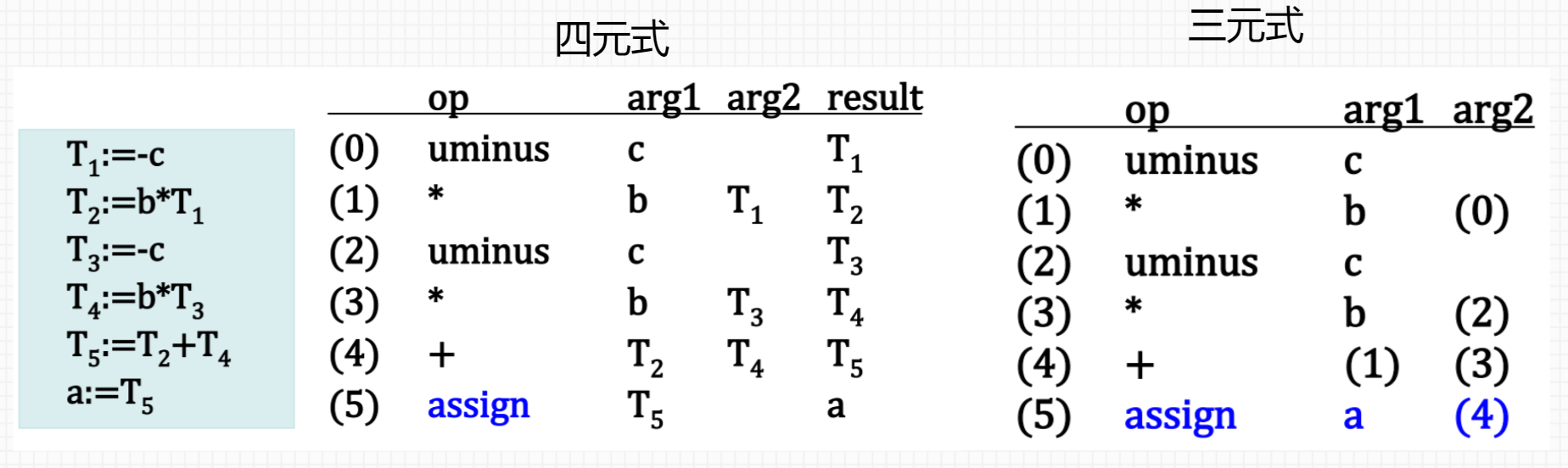
2.四元式、三元式 p172
四元式:一个带有四个域的记录结构,这四个域分别称为 op, arg1, arg2 及 result
三元式:三个域(op, arg1, arg2),避免把临时变量填入到符号表,通过计算这个临时变量值的语句的位置来引用这个临时变量
间接三元式:为了便于优化,用 三元式表 + 间接码表 表示中间代码;间接码表即为一张指示器表,按照运算的先后次序列出有关三元式在三元式表中的位置。
3.说明语句的翻译:见 ppt 7-2 p1 / p174
说明语句的翻译:对每个局部名字,在符号表中 建立相应的表项,并填入有关的信息如类型、在 存储器中的相对地址等
需要一个全程变量如 offset 来跟踪下一个可用的相对地址的位置

4.赋值语句的翻译:见 ppt 7-2 p8

**5.数组元素的引用:例 7.1 p183 / ppt 7-3 p8 **
有点难,理解需要时间,因为存在计算的部分,详细内容见书和 ppt
6.布尔表达式的翻译:例 7.4 ppt7-4 / p191
详见书或ppt
7.控制语句的翻译:例 7.5 p194 / ppt 7-5 p5
详见书或ppt
第八章 符号表
符号表的整理和查找方式:线性表、对折查找和二叉树、杂凑技术(哈希) p226
基本概念
1.符号表包含两大栏:名字栏和信息栏
2.符号表的操作 p222 即增删查改啦
3.符号表的组织方式 p222
第十章 优化
-
优化:对程序进行各种等价变换,使得从变换后的程序出发,能生成更有效的目标代码
-
基本块:指程序中一顺序执行的语句序列,其中只有一个入口和一个出口,入口是其中的第一个语句,出口是 其中的最后一个语句。执行时,只能从其入口进入,从其出口退出。
-
如果一条三地址语句为
x := y + z,则称为 x 定值并引用 y 和 z。在一个基本块中的一个名字,所谓在程序中的某个给定点是活跃的,是指如果在程序中(包括在本基本块中或在其它基本块中)它的值在该点以后被引用 -
对循环中的代码,可以是实行代码外提、强度削弱、删除归纳变量等优化
基本概念
1.优化须遵循的原则:等价原则、有效原则、合算原则。 p272
等价:不应改变程序运行的结果
有效:目标代码运行时间较短,占用的存储空间较小
合算:以较低的代价取得较好的优化成果
2.常用的优化技术 p273
1)删除公共子表达式
如果一个表达式E在前面已计算过,并且在这之后E中变量的值没有改变,则称E为公共子表达式
对于公共子表达式,可以避免对它的重复计算, 称为删除公共子表达式(删除多余运算)
2)复写传播
类似于如下情况:
...
t6 = t2;
x = a[t6];
t7 = t6;
... // t6 值未改变
a[t7] = t9;
...
可以改为:
...
t6 = t2;
x = a[t2];
t7 = t2;
... // t6 值未改变
a[t2] = t9;
...
复写传播的目的就是使对某些变量的赋值变为无用
3)删除无用代码
删除无用赋值或删除无用代码
4)代码外提
在循环中代码结果不变的代码可以提到循环外,以防止重复计算
5)强度削弱
例如乘法变加法:
for(int i = 0; i < 10; ++ i){
j = i * 4;
}
// 可以变为
j = 0;
for(int i = 0; i < 10; ++ i){
...
j += 4;
}
6)删除归纳变量 p277
如果说一个变量 t2 和变量 i 在代码执行过程中保持着 t2 = 4 * i 的线性关系,且变量 t3 和变量 j 在代码执行过程中保持着 t3 = 4 * i 的线性关系,则称变量 i 和 j 为归纳变量
代码中涉及 i 与 j 的比较地方的代码可以利用 t2 与 t3 代替,以减少代码量
详见书
第十一章 目标代码生成
- 简单的代码生成器:依次把每条中间代码变换成目标代码,并且在一个基本块范围内考虑如何充分利用寄存器的问题
基本概念
1.目标代码生成的任务
这一阶段的任务就是把中间代码(或经过优化处理之后)变换成特定机器上的低级语言代码。这阶段实现了最后的翻译,它的工作有赖于硬件系统结构和机器指令含义。
代码生成器的输入包括中间代码和符号表中的信息,输出即为等价的目标程序
2.目标代码的形式 p309
绝对机器代码:能够立即执行的机器语言代码, 所有地址均已定位
可再定位机器语言:当需要执行时,由连接装入程序把它们和某些运行程序连接起来,转换成能执行的机器语言代码
汇编语言代码:需经过汇编程序汇编,转换成可执行的机器语言代码
3.待用信息 p314
计算
1.计算变量待用信息算法

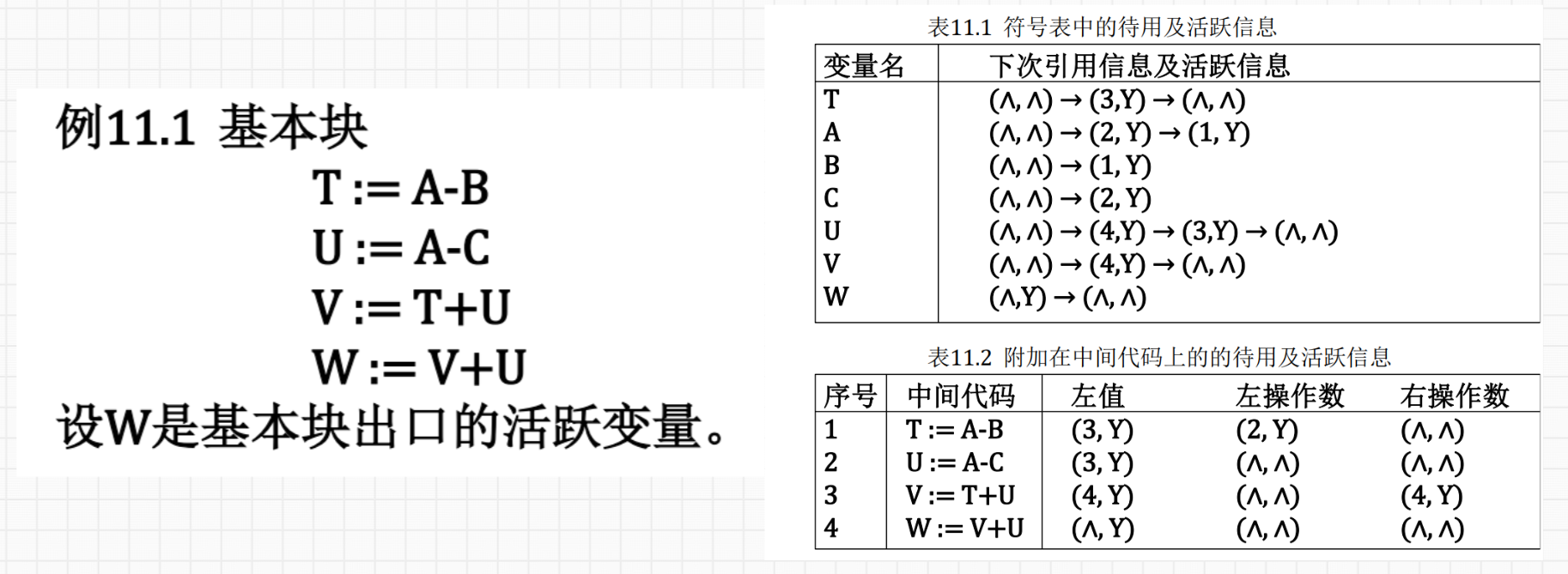
2.目标代码生成算法:例 11.2 p316

对于最后一行红字,一旦处理完基本块中所有中间代码,对现行值只在某寄存器中的每个变量,如果它在基本块出口之后是活跃的,则我们要用 ST 指令把它在寄存器中的值存放到它的主存单元中
作业
1-2-3 章练习
- T9
非终结符 用来代表语法范畴。 书 P27
- T33 p38 词法分析可以作为独立的一遍,也可以安排成一个子程序
- T37 p28 产生式是定义语法范畴的一种书写规则
语法和语义--标识符是语法概念,名字是语义概念 - guanyubo - 博客园 (cnblogs.com)
4-5 章练习
- T1
书p85
短语
直接短语:一步推导得到的短语
句柄:一个句型的最左直接短语
书 p92
素短语:是这样的一个短语,至少含有一个终结符,且除它自身以外不再含任何更小的素短语
最左素短语:
- T3
p89 算符优先分析法,特别有利于表达式分析
- T4
p66 从开始符号开始
- T5 p84
在算符优先分析中,利用“最左素短语”刻画“可归约串”;在“规范归约”中,利用“句柄”来刻画“可归约”串
- T7
p104 前缀、活前缀、项目
末尾标明:一个项目指明了在分析过程中某时刻能看到产生式多大一部分
-
T8 可能 p74 开头,每个过程对应文法的一个非终结符
-
T9 概念 p105
-
T10 优先函数 p94
-
T14 p86 规范归约的概念
-
T17 FIRST集概念 p71
-
T19 FOLLOW集概念 p73 FOLLOW的构造 p79
-
T20 ?
-
T22
设文法G(S): S→b|^|(T) T→T, S|S则FIRSTVT(T)为( )。
A. { b, ^, ( }
B. { b, ^, ) }
C. { , , b, ^, ( }
D. { , , b, ^, ) }
正确答案是:C
FIRSTVT 和 LASTVT 集 p91定义
- T27 p114中间
若项目集 \(I_k\) 含有项目A→α•,则在状态k时,仅当面临的输入符号a∈FOLLOW(A)时才采取“将α归约为A”动作的一定是( )。
A. LALR(1)文法
B. LR(0)文法
C. LR(1)文法
D. SLR(1)文法
正确答案:D
- T30 p76
- T32 每个SLR(1)文法都是LR(1)文法。 对
- T34 每个SLR(1)文法都是无二义的。 对
- T36 p89 所谓算符优先分析就是定义算符之间(确切地说,终结符之间)的某种优先关系,借助于这种优先关系寻找“可归约串”和进行归约
- T37 p76 末尾
预测分析程序的总控程序在任何时候都是按STACK栈底符号X和当前的输入符号a行事的。错,应该是栈顶符号
- T39 p79末尾
6-7 章练习
-
T1 p156 中间
-
T2 p140 属性文法处理方法
-
T5
- (单选题)间接三元式表示法的特点为( )。
A. 采用间接码表,便于优化处理 B. 节省存储空间,不便于表的修改
C. 便于优化处理,节省存储空间 D. 节省存储空间,不便于优化处理
选 A
8-10-11 章练习
实验
需要检查两次,语法分析一次,语义分析一次
词法分析
词法分析要求一遍扫描过,感觉这个要求就是要把词法分析器作为子程序实现
参考链接
编译原理 实验一 词法分析器_选择部分c语言的语法成分,设计其词法分析程序,要求能够识别关键字、运算符、分界-CSDN博客
编译原理——词法分析器 C++实现_词法分析器c++实现-CSDN博客
编译原理实验一 词法分析器C++实现 - SelmaS - 博客园 (cnblogs.com)
(C++)带你手肝词法分析器,容易理解,跟着思路有手就行-CSDN博客
这个仅看看,感觉不好 【编译原理-实验-1】词法分析器最详细设计报告(c++版)_牛客博客 (nowcoder.net)
语法分析
参考链接
编译原理之LL(1)语法分析实验(附完整C/C++代码与测试)_编译原理实验-CSDN博客
java语言编写,这篇仅参考 编译原理:LL(1)语法分析器的实现(内含代码详细注释)_语法分析程序流程图-CSDN博客
本文来自博客园,作者:Qiansui,转载请注明原文链接:https://www.cnblogs.com/Qiansui/p/18194312

 浙公网安备 33010602011771号
浙公网安备 33010602011771号